
ST-YOLO: An Enhanced Detector of Small Objects in Unmanned Aerial Vehicle Imagery



Abstract
1. Introduction
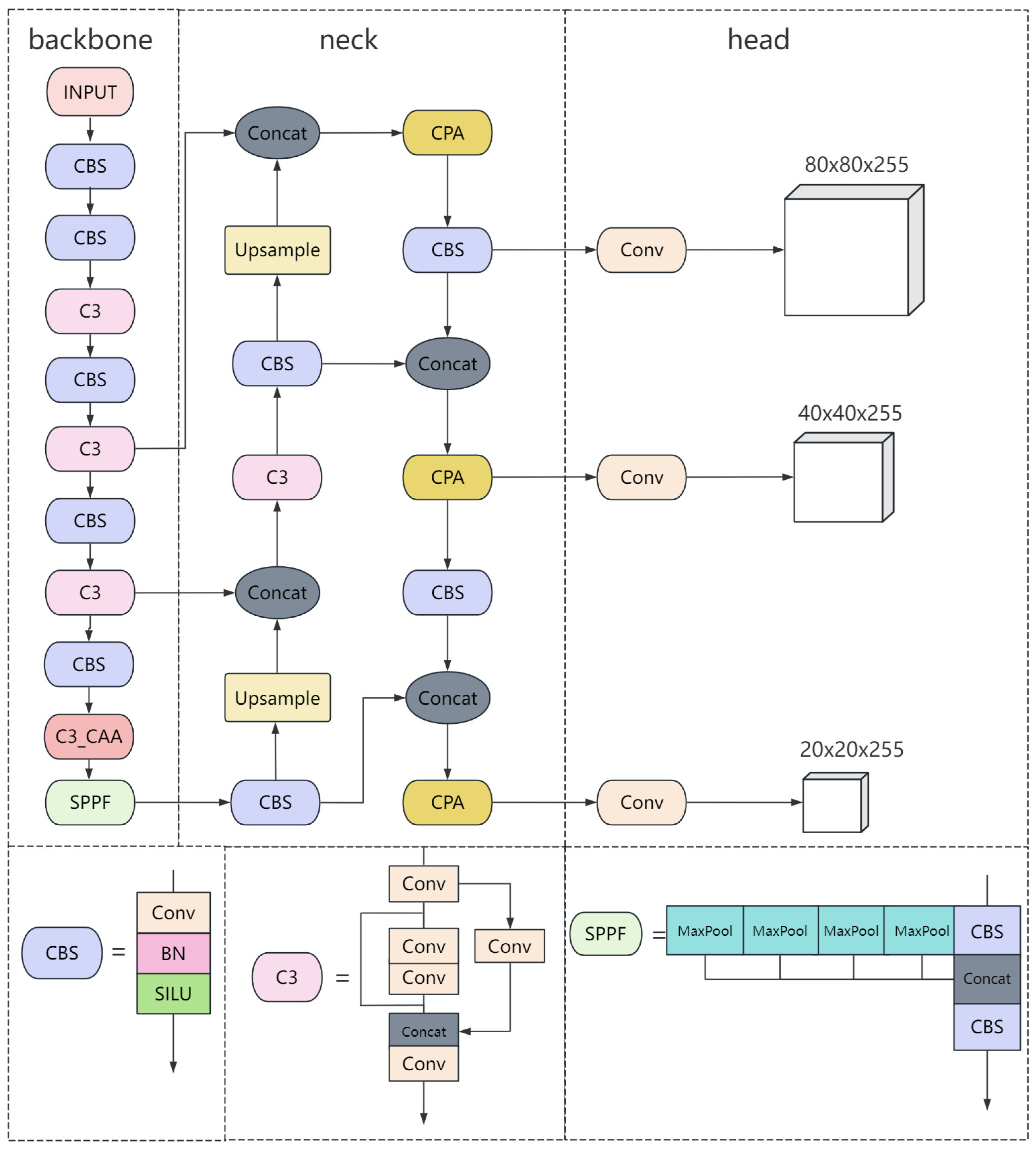
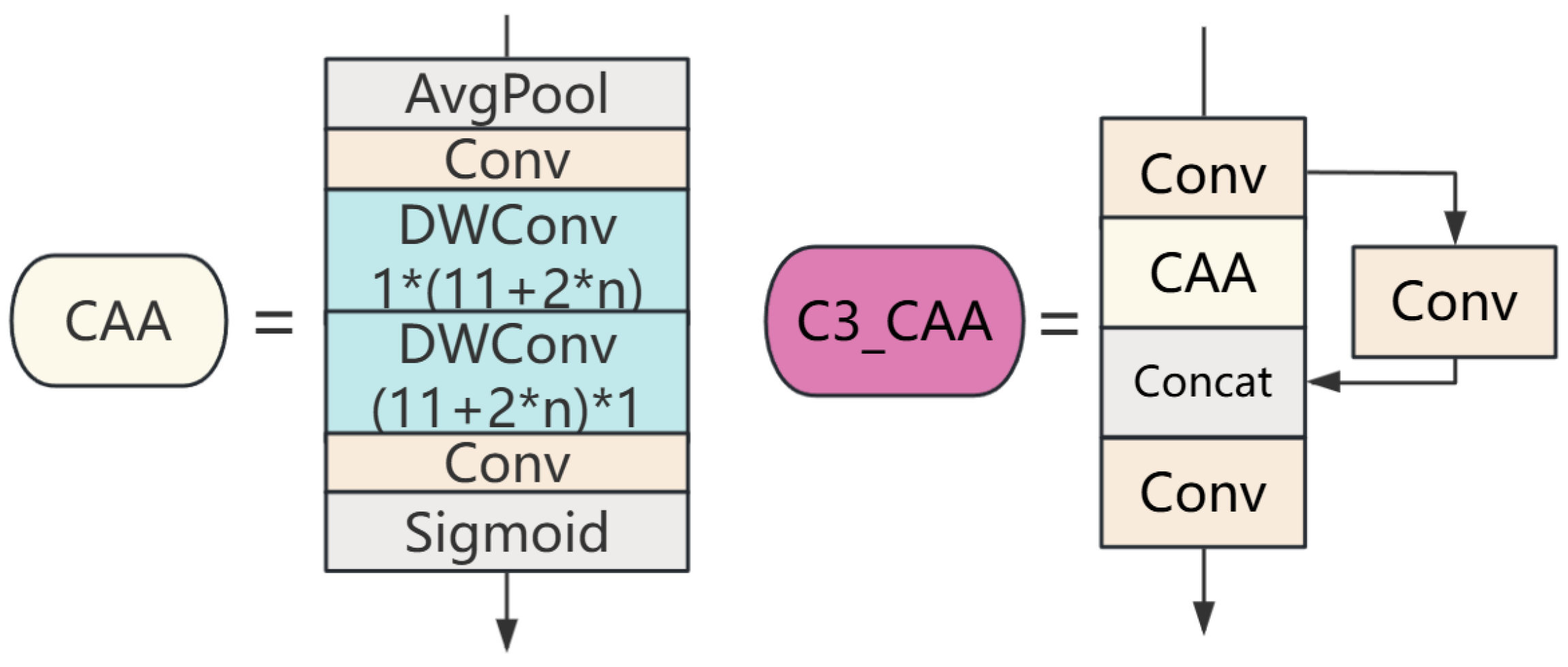
- To address the challenge of detecting small objects in aerial images, we incorporated the CAA mechanism into the C3 module of YOLO, resulting in the creation of the C3_CAA module. This new integration substantially boosts the feature extraction power of the YOLO backbone and achieves a considerable reduction in model size, all while preserving performance.
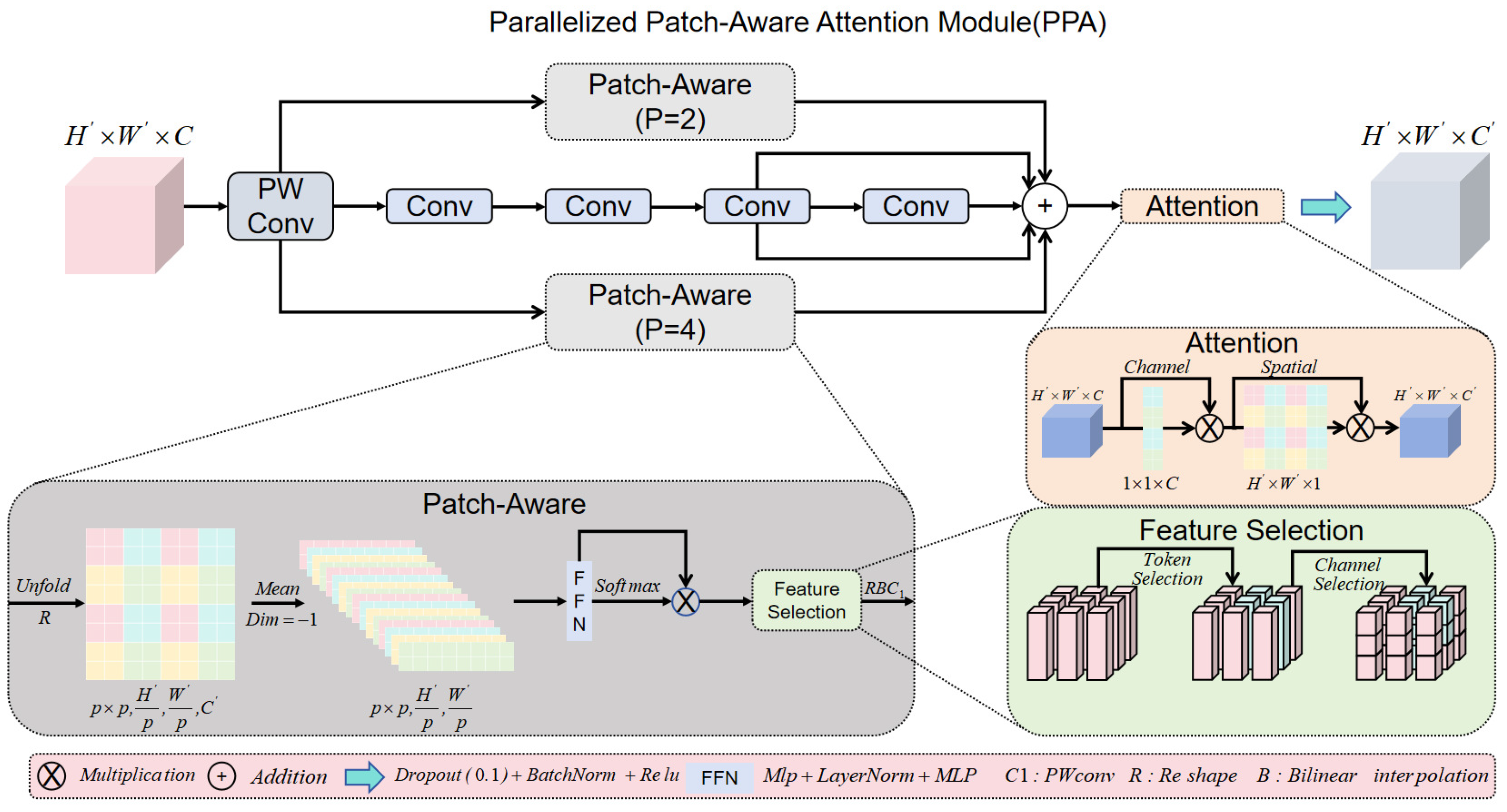
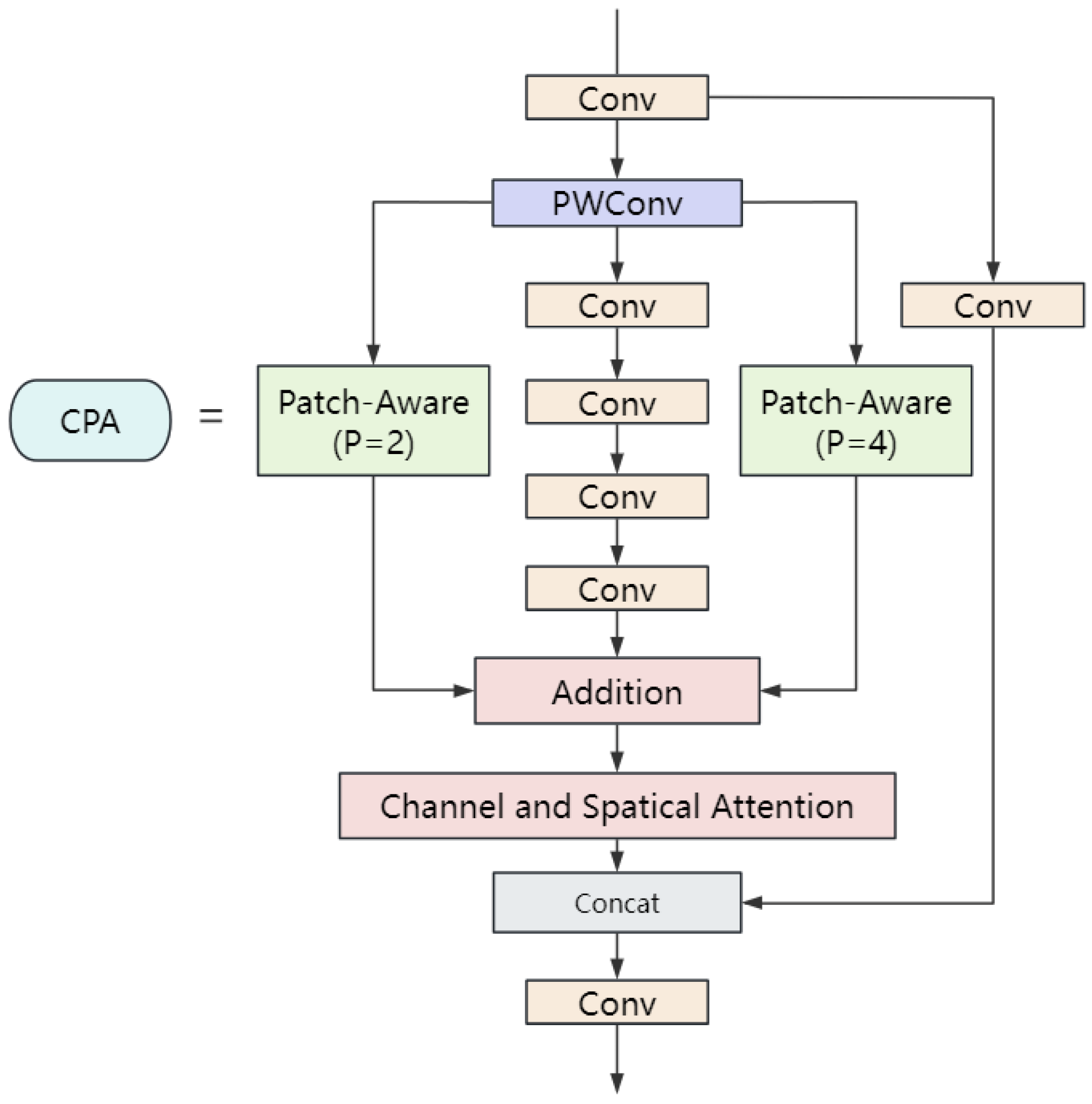
- Considering the potential for information loss due to continuous downsampling in the neck of the YOLO model, we integrated the PPA attention mechanism into the C3 module, creating the CPA module. This new module effectively captures and integrates features at different scales through a pyramid pooling structure and parallel multi-branch strategy, significantly improving the detection accuracy of small targets.
- Considering the challenges of multiple viewing angles in aerial images and the slow convergence rate of the standard IoU, we introduced a new method for IoU calculation. This approach concentrates on the shape and scale of bounding boxes to determine losses. By applying a scale factor ratio to adjust the creation of auxiliary bounding boxes, this method not only enhances the precision of bounding box localization but also improves the overall efficiency of detection.
- We validated our approach on multiple datasets, and the experimental results indicate that although the ST-YOLO model shows a slight increase in the number of model parameters and GFLOPs, it achieves a notable improvement in accuracy compared to the baseline.
2. Related Work
2.1. Traditional Object Detection
2.2. Object Detection Methods Based on Transformer
2.3. Attention Mechanism
2.4. IoU
3. Proposed Method
3.1. Overall Structure of ST-YOLO
3.2. Context Anchor Attention (CAA)
3.3. Parallelized Patch-Aware Attention (PPA)
3.4. SI-IoU
4. Experiment Settings
4.1. Datasets
4.2. Network Training
4.3. Evaluation Metrics
5. Experiments
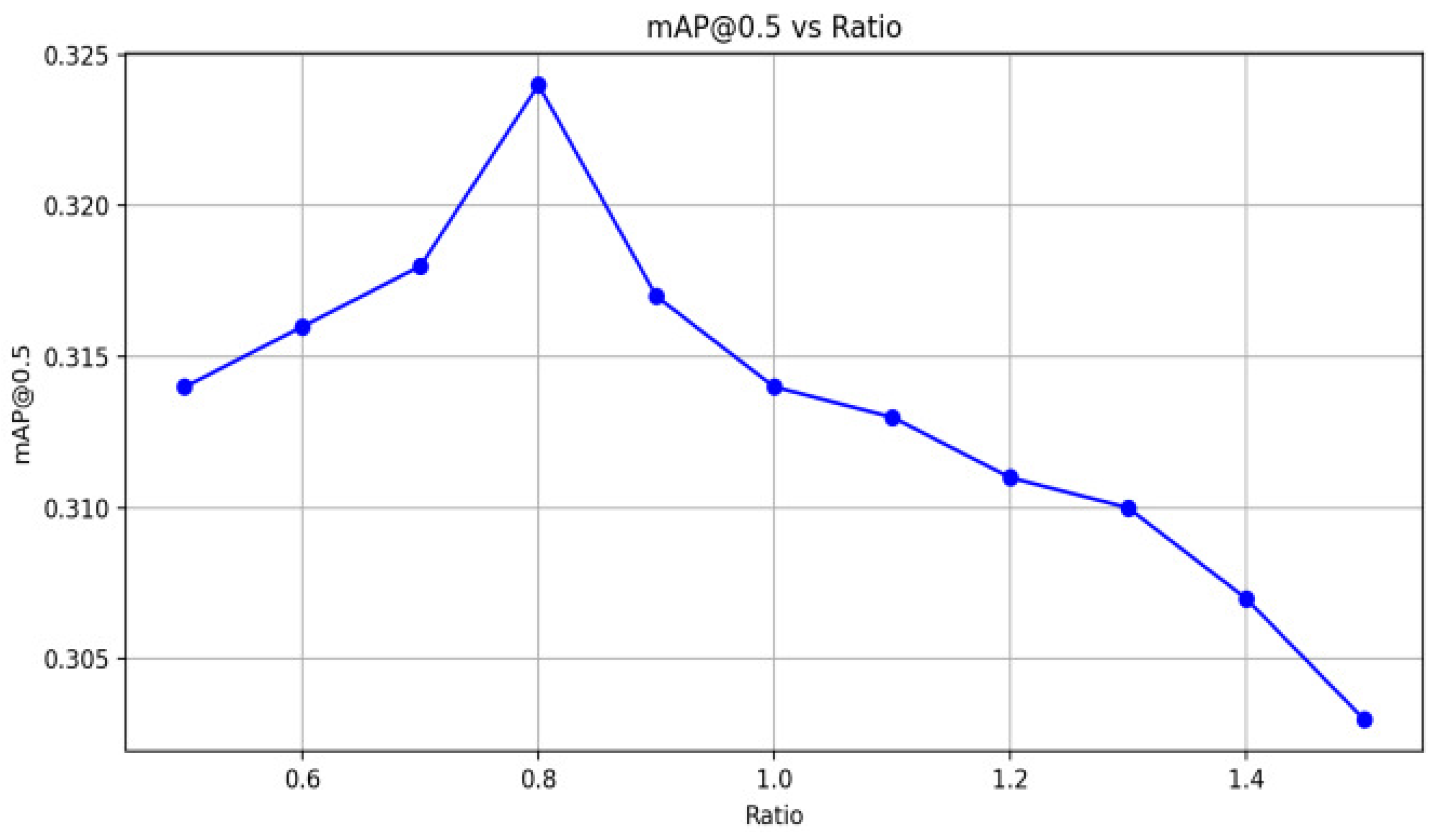
5.1. Impact of Ratio Value Adjustment on IoU Performance
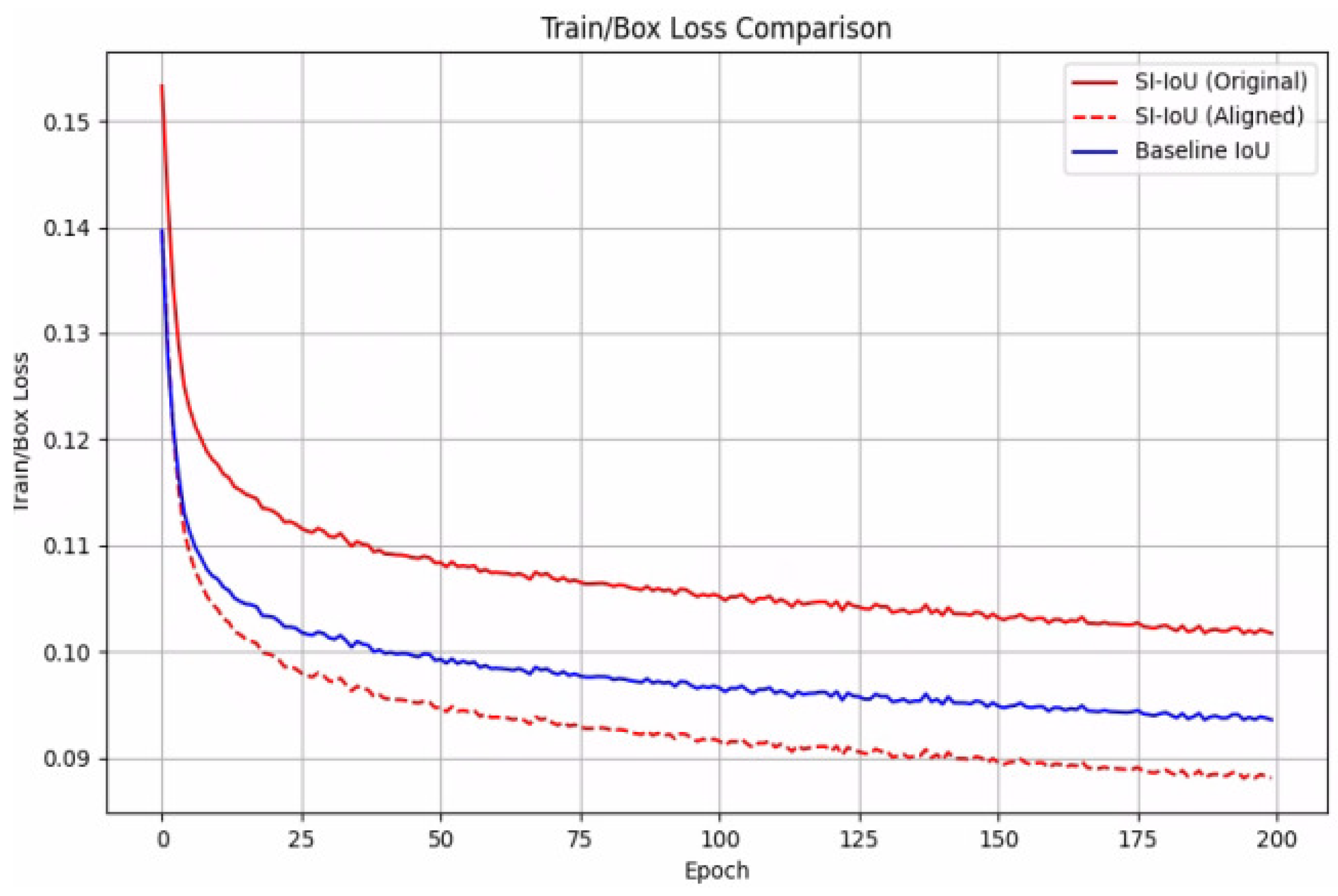
5.2. Comparison of IoU Loss
5.3. Comparison of SI-IoU with Other Advanced IoUs on the VisDrone2019 Dataset
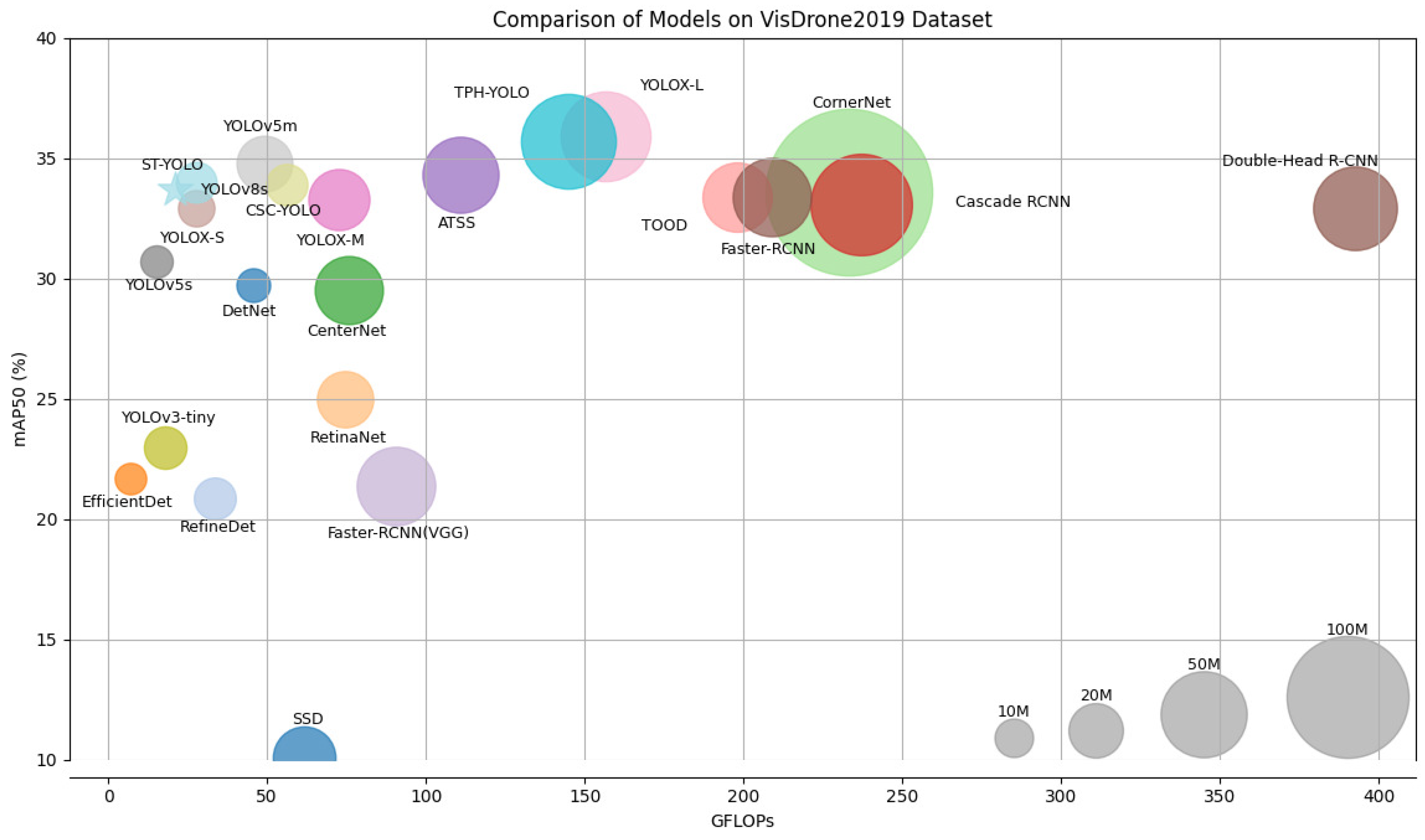
5.4. Comparison of ST-YOLO to State-of-the-Art Methods on the VisDrone2019 Dataset
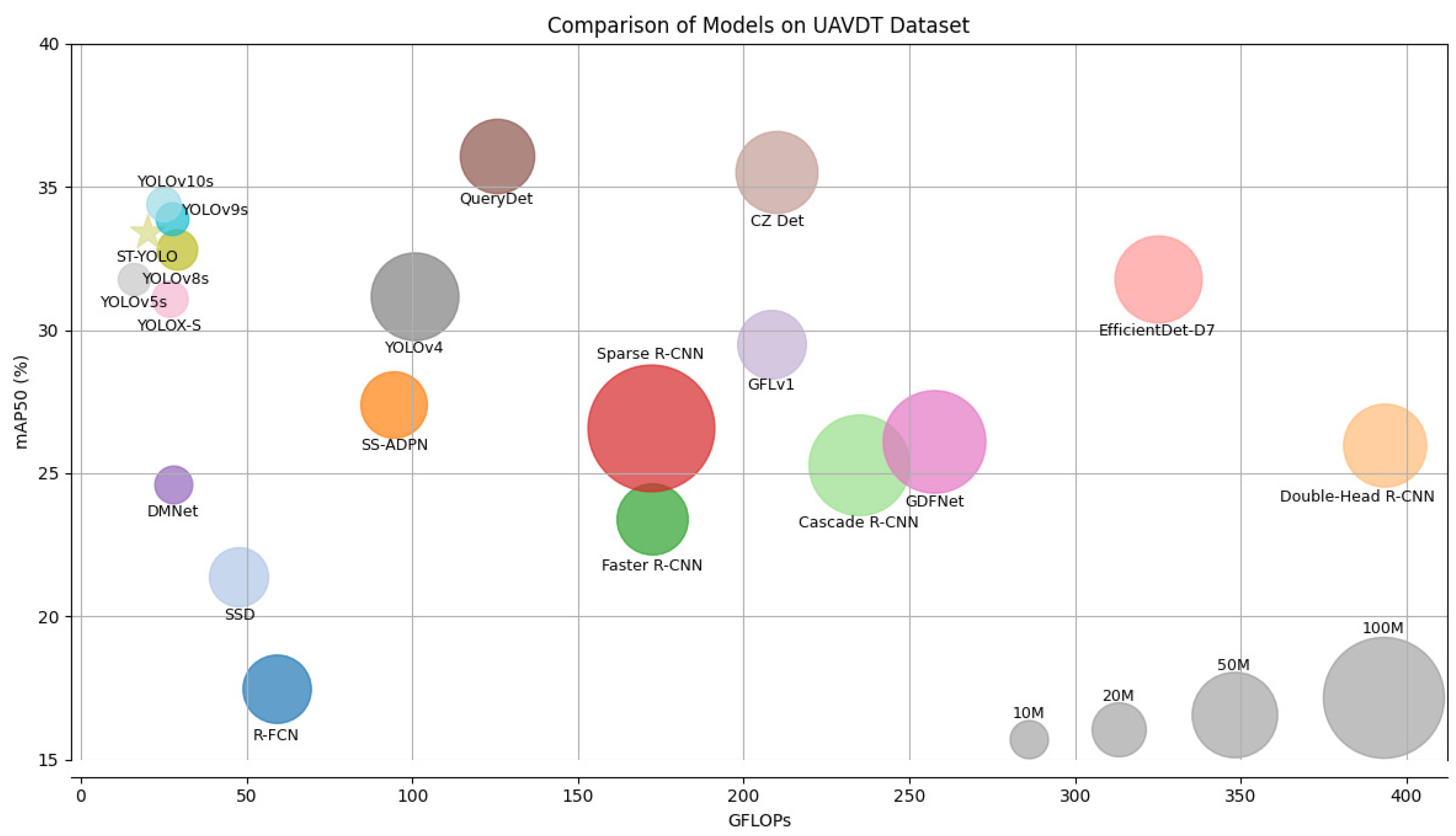
5.5. Comparison of ST-YOLO to State-of-the-Art Methods on the UAVDT Dataset
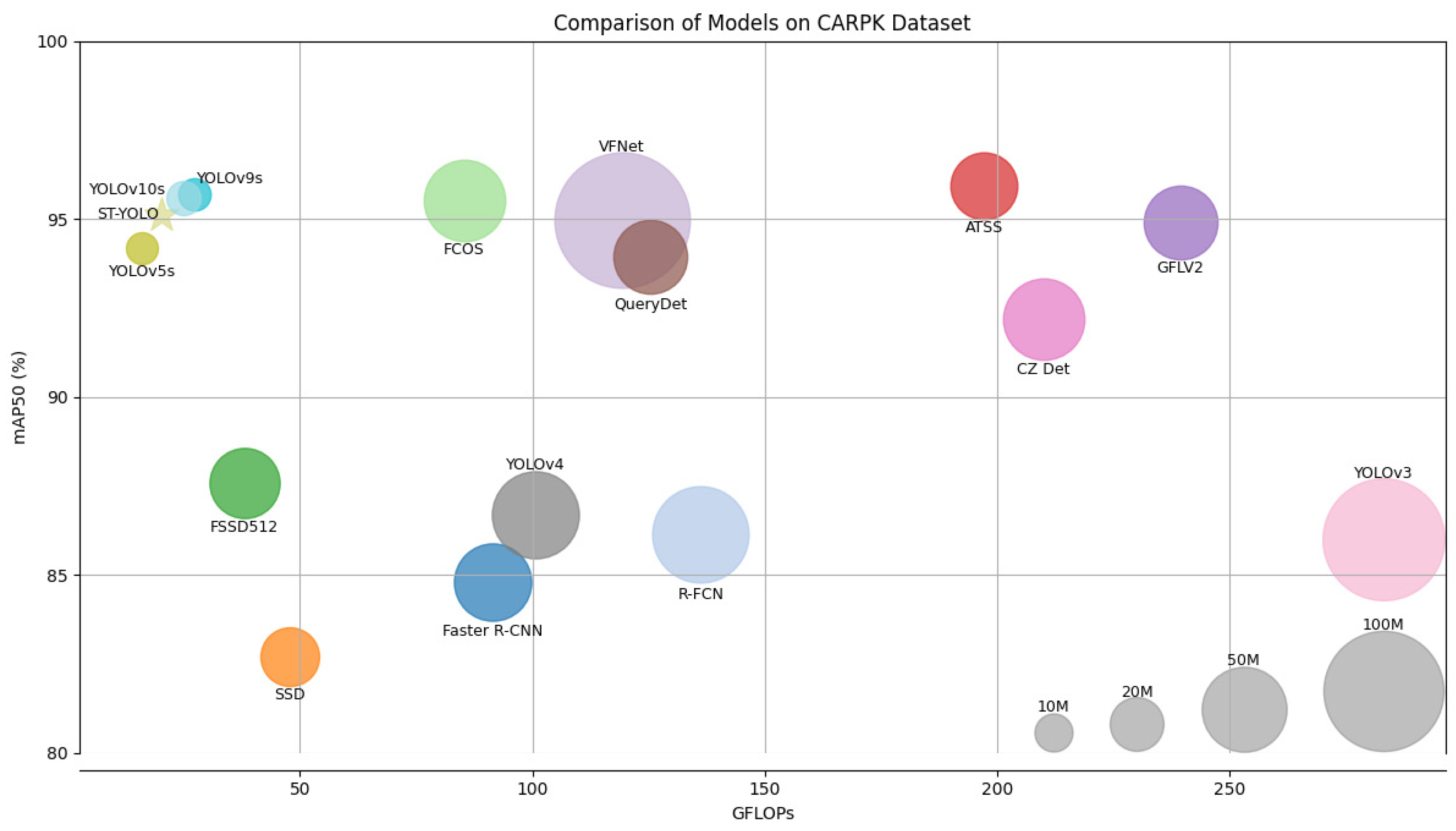
5.6. Comparison of ST-YOLO to State-of-the-Art Methods on the CARPK Dataset
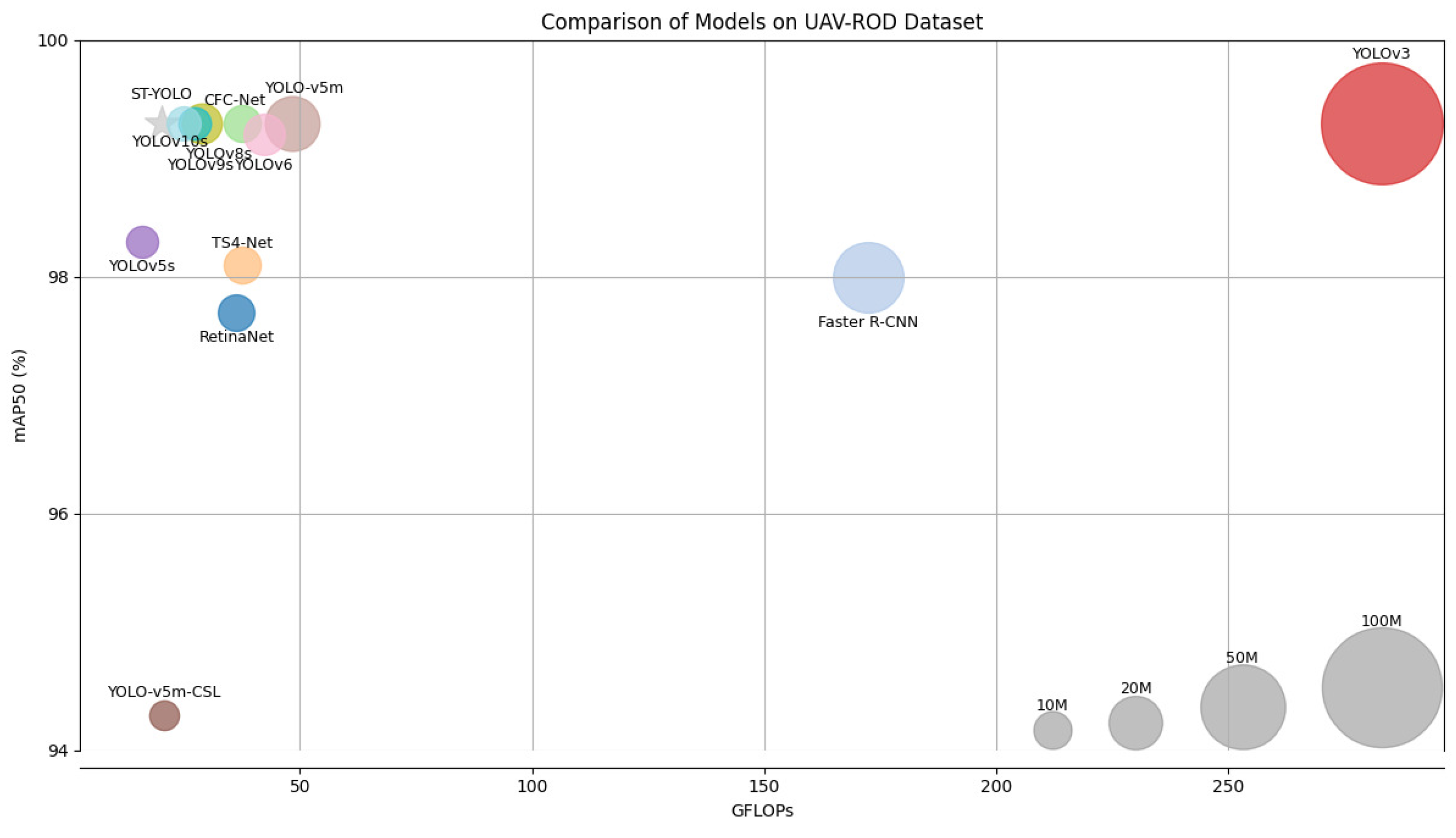
5.7. Comparison of ST-YOLO to State-of-the-Art Methods on the UAV-ROD Dataset
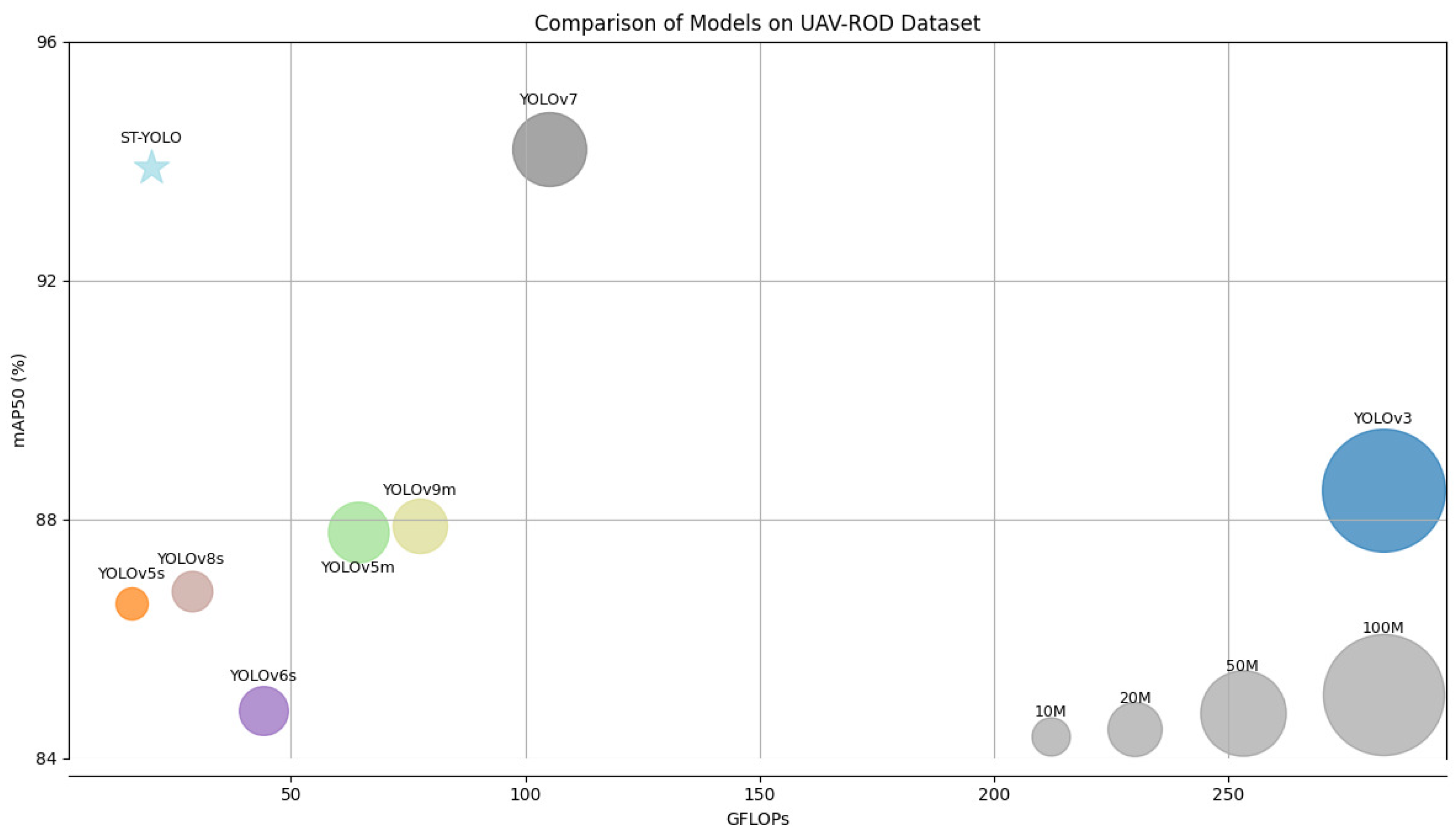
5.8. Comparison of ST-YOLO to State-of-the-Art Methods on the UTUAV-B Dataset
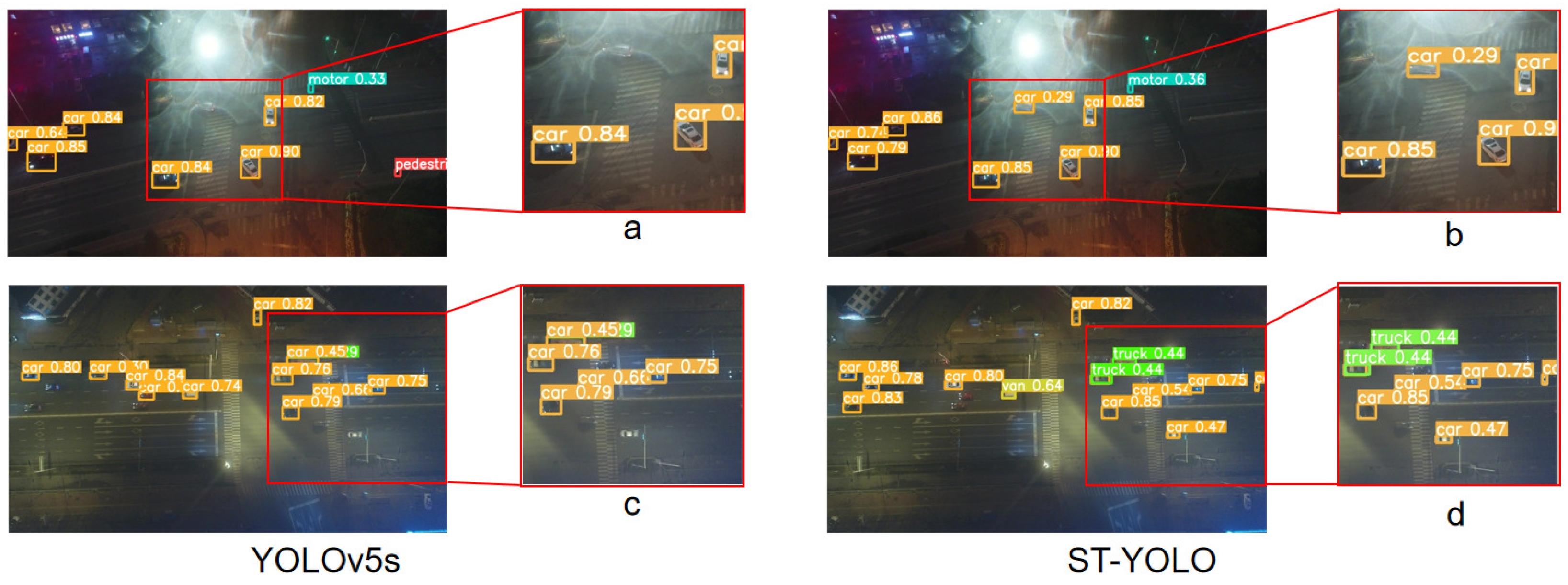
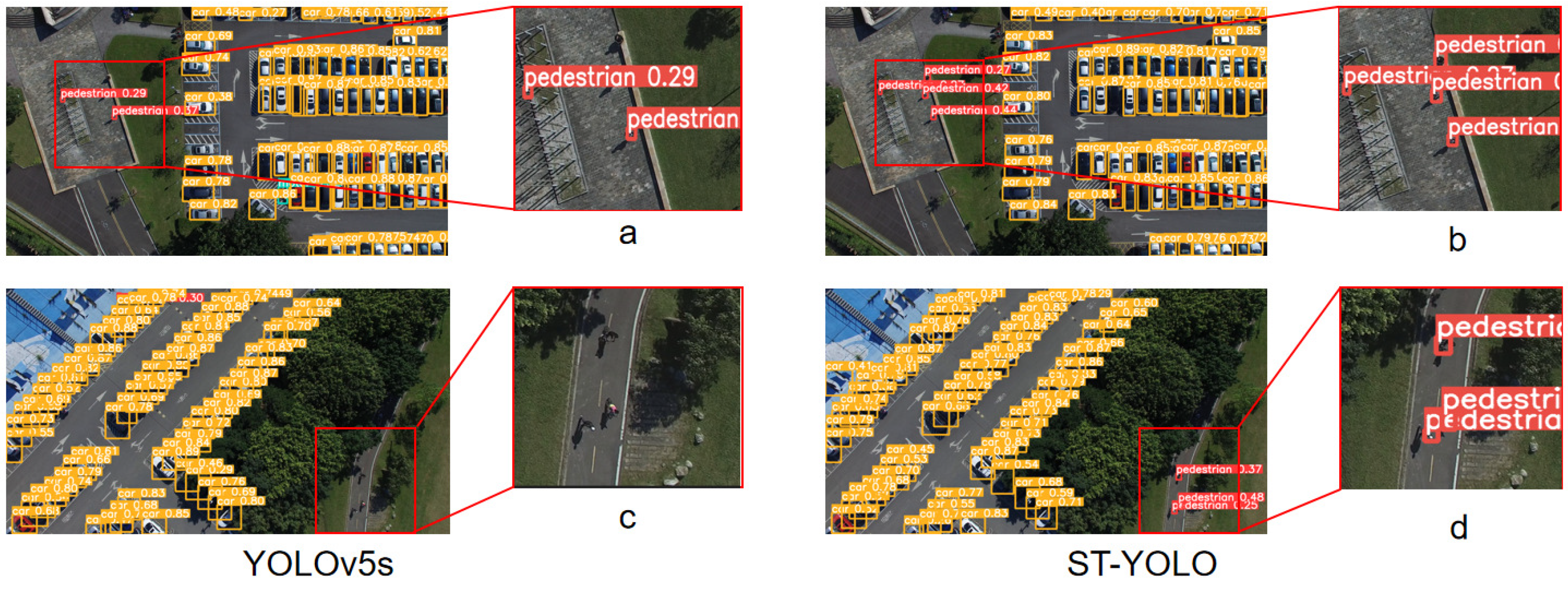
5.9. Ablation Studies and Visualization of Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tsouros, D.C.; Bibi, S.; Sarigiannidis, P.G. A Review on UAV-based Applications for Precision Agriculture. Information 2019, 10, 11. [Google Scholar] [CrossRef]
- Li, X.; Lian, Y. Design and Implementation of UAV Intelligent Aerial Photography System. In Proceedings of the International Conference on Intelligent Human-Machine Systems and Cybernetics, Nanchang, China, 26–27 August 2012. [Google Scholar]
- Wu, Y.; Wu, S.; Hu, X. Cooperative Path Planning of UAVs and UGVs for A Persistent Surveillance Task in Urban Environments. IEEE Internet Things J. 2020, 8, 4906–4919. [Google Scholar] [CrossRef]
- Lee, J.; Wang, J.; Crandall, D. Real-time, cloud-based object detection for unmanned aerial vehicles. In Proceedings of the IEEE International Conference on Robotic Computing, Taichung, Taiwan, 10–12 April 2017. [Google Scholar]
- Du, D.; Zhu, P.; Wen, L.; Bian, X.; Lin, H.; Hu, Q.; Peng, T.; Zheng, J.; Wang, X.; Zhang, Y.; et al. VisDrone-DET2019: The Vision Meets Drone Object Detection in Image Challenge Results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021. [Google Scholar]
- Sahin, O.; Ozer, S. Yolodrone: Improved Yolo Architecture for Object Detection in Drone Images. In Proceedings of the International Conference on Telecommunications and Signal Processing, Guntur, India, 11–12 June 2021. [Google Scholar]
- Hui, Y.; Wang, J.; Li, B. STF-YOLO: A Small Target Detection Algorithm for UAV Remote Sensing Images Based on Improved SwinTransformer and Class Weighted Classification Decoupling Head. Measurement 2024, 224, 113936. [Google Scholar] [CrossRef]
- Cai, X.; Lai, Q.; Wang, Y.; Wang, W.; Sun, Z.; Yao, Y. Poly Kernel Inception Network for Remote Sensing Detection. arXiv 2024, arXiv:2403.06258. [Google Scholar]
- Xu, S.; Zheng, S.C.; Xu, W.; Xu, R. HCF-Net: Hierarchical Context Fusion Network for Infrared Small Object Detection. arXiv 2024, arXiv:2403.10778. [Google Scholar]
- Zhang, H.; Zhang, S. Shape-IoU: More Accurate Metric Considering Bounding Box Shape and Scale. arXiv 2023, arXiv:2312.17663. [Google Scholar]
- Zhang, H.; Xu, C.; Zhang, S. Inner-IoU: More Effective Intersection Over Union Loss with Auxiliary Bounding Box. arXiv 2023, arXiv:2311.02877. [Google Scholar]
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. Light-head R-CNN: In Defense of Two-stage Object Detector. arXiv 2017, arXiv:1711.07264. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end Object Detection with Transformers. In Proceedings of the European Conference on Computer Vision, Online, 23–28 August 2020. [Google Scholar]
- Beal, J.; Kim, E.; Tzeng, E.; Park, D.H.; Zhai, A.; Kislyuk, D. Toward Transformer-based Object Detection. arXiv 2020, arXiv:2012.09958. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An Advanced Object Detection Network. In Proceedings of the ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016. [Google Scholar]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing Geometric Factors in Model Learning and Inference for Object Detection and Instance Segmentation. IEEE Trans. Cybern. 2021, 52, 8574–8586. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.Y.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and A Loss for Bounding Box Regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Du, D.; Qi, Y.; Yu, H.; Yang, Y.; Duan, K.; Li, G.; Zhang, W.; Huang, Q.; Tian, Q. The Unmanned Aerial Vehicle Benchmark: Object Detection and Tracking. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Hsieh, M.R.; Lin, Y.L.; Hsu, W.H. Drone-based Object Counting by Spatially Regularized Regional Proposal Network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- UAV-ROD. Available online: https://github.com/fengkaibit/UAV-ROD (accessed on 26 June 2024).
- Espinosa, J.E.; Jairo, E.; Sergio, A. Classification and Tracking of Vehicles Using Videos Captured by Unmanned Aerial Vehicles. In Machine Learning Techniques for Smart City Applications: Trends and Solutions; Springer International Publishing: Cham, Switzerland, 2022; pp. 59–73. [Google Scholar]
- Ma, S.; Yong, X. Mpdiou: A Loss for Efficient and Accurate Bounding Box Regression. arXiv 2023, arXiv:2307.07662. [Google Scholar]
- Wu, X.; Xu, J. P-IoU: Accurate Motion Prediction Based Data Association for Multi-object Tracking. In Proceedings of the International Conference on Neural Information Processing, New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A.C. SSD: Single Shot Multibox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. DetNet: Design Backbone for Object Detection. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-shot Refinement Neural Network for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.R.; Huang, W. TOOD: Task-aligned One-stage Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021. [Google Scholar]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the Gap between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Dai, X.; Chen, Y.; Xiao, B.; Chen, D.; Liu, M.; Yuan, L.; Zhang, L. Dynamic Head: Unifying Object Detection Heads with Attentions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Wu, Y.; Chen, Y.; Yuan, L.; Liu, Z.; Wang, L.; Li, H.; Fu, Y. Rethinking Classification and Localization for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ultralytics. YOLOv5: V6.0-YOLOv5n ’Nano’ Models, Roboflow Integration, TensorFlow Export, OpenCV DNN Support. Available online: https://zenodo.org/records/5563715 (accessed on 26 June 2024).
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Huang, Z.; Li, L.; Krizek, G.C.; Sun, L. Research on Traffic Sign Detection Based on Improved YOLOv8. Remote Sens. 2023, 11, 226–232. [Google Scholar] [CrossRef]
- Zhang, G.; Chen, T.; Wang, J. CSC-YOLO: An Image Recognition Model for Surface Defect Detection of Copper Strip and Plates. J. Shanghai Jiaotong Univ. (Sci.) 2024. [Google Scholar] [CrossRef]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Zhang, R.; Shao, Z.; Huang, X.; Wang, J.; Wang, Y.; Li, D. Adaptive Dense Pyramid Network for Object Detection in UAV Imagery. Neurocomputing 2022, 489, 377–389. [Google Scholar] [CrossRef]
- Hong, Q.; Liu, F.; Li, D.; Liu, J.; Tian, L.; Shan, Y. Sparse R-CNN: End-to-end Object Detection with Learnable Proposals. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021. [Google Scholar]
- Li, C.; Yang, T.; Zhu, S.; Chen, C.; Guan, S. Density Map Guided Object Detection in Aerial Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection. Adv. Neural Inf. Process. Syst. 2020, 33, 21002–21012. [Google Scholar]
- Yang, C.; Huang, Z.; Wang, N. QueryDet: Cascaded Sparse Query for Accelerating High-resolution Small Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Meethal, A.; Granger, E.; Pedersoli, M. Cascaded Zoom-in Detector for High Resolution Aerial Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Zhang, R.; Shao, Z.; Huang, X.; Wang, J.; Li, D. Object Detection in UAV Images via Global Density Fused Convolutional Network. Remote Sens. 2020, 12, 3140. [Google Scholar] [CrossRef]
- Wang, C.; Yeh, I.; Liao, H. Yolov9: Learning what you want to learn using programmable gradient information. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. Adv. Neural Inf. Process. Syst. 2024, 37, 107984–108011. [Google Scholar]
- Li, Z.; Yang, L.; Zhou, F. FSSD: Feature Fusion Single Shot Multibox Detector. arXiv 2017, arXiv:1712.00960. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: A Simple and Strong Anchor-free Object Detector. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1922–1933. [Google Scholar] [CrossRef]
- Li, X.; Wang, W.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized Focal Loss v2: Learning Reliable Localization Quality Estimation for Dense Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual Conference, 19–25 June 2021. [Google Scholar]
- Zhang, H.; Wang, Y.; Dayoub, F.; Sunderhauf, N. VarifocalNet: An IoU-aware Dense Object Detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual Conference, 19–25 June 2021. [Google Scholar]
- Zhou, J.; Feng, K.; Li, W.; Han, J.; Pan, F. TS4Net: Two-stage Sample Selective Strategy for Rotating Object Detection. Neurocomputing 2022, 501, 753–764. [Google Scholar] [CrossRef]
- Ming, Q.; Miao, L.; Zhou, Z.; Dong, Y. CFC-Net: A Critical Feature Capturing Network for Arbitrary-oriented Object Detection in Remote-sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5605814. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L. YOLOv6: A Single-stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.; Bochkovskiy, A.; Liao, H. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| IoU | Precision | Recall | mAP50 (%) | mAP50-95 (%) |
|---|---|---|---|---|
| SI-IoU | 0.448 | 0.331 | 32.4 | 17.3 |
| C-IoU | 0.435 | 0.320 | 31.2 | 16.4 |
| Inner-G | 0.433 | 0.301 | 30.2 | 16.4 |
| Inner-D | 0.423 | 0.315 | 30.8 | 16.4 |
| Inner-C | 0.441 | 0.315 | 31.2 | 16.7 |
| Inner-S | 0.437 | 0.329 | 31.7 | 16.9 |
| Inner-E | 0.440 | 0.328 | 32.1 | 17.1 |
| Shape-IoU | 0.436 | 0.324 | 31.6 | 16.8 |
| Mpd-IoU [29] | 0.432 | 0.327 | 31.3 | 16.8 |
| P-IoU [30] | 0.429 | 0.322 | 31.2 | 16.6 |
| Wise-IoU [31] | 0.426 | 0.327 | 31.3 | 16.5 |
| Model | Backbone | GFLOPs | Parameters (M) | mAP50 (%) |
|---|---|---|---|---|
| SSD [32] | ResNet-50 [33] | 62.70 | 26.30 | 10.60 |
| DetNet [34] | ResNet-50 [33] | 44.60 | 7.60 | 29.23 |
| RefineDet [35] | VGG-16 [36] | 34.40 | 11.80 | 21.37 |
| EfficientDet [37] | EfficientDet-D1 [37] | 6.10 | 6.63 | 21.20 |
| RetinaNet [38] | ResNet-50-FPN [39] | 75.50 | 21.30 | 25.50 |
| CenterNet [40] | ResNet-50 [33] | 74.90 | 31.20 | 29.00 |
| CornerNet [41] | Hourglass-104 [42] | 234.00 | 187.00 | 34.10 |
| Cascade RCNN [14] | ResNet-50-FPN [39] | 236.00 | 69.29 | 32.60 |
| TOOD [43] | ResNet-50 [33] | 199.00 | 32.40 | 33.90 |
| ATSS [44] | ResNet-50-FPN-DyHead [45] | 110.00 | 38.91 | 33.80 |
| Faster-RCNN [46] | VGG16 [36] | 91.40 | 41.50 | 21.90 |
| Faster-RCNN [46] | ResNet-50-FPN [39] | 208.00 | 41.39 | 32.90 |
| Double-Head R-CNN [47] | ResNeXt-101 [33] | 393.37 | 47.12 | 33.40 |
| YOLOX-S [48] | CSPDarkNet [49] | 26.80 | 8.90 | 32.40 |
| YOLOX-M [48] | CSPDarkNet [49] | 73.50 | 25.10 | 33.80 |
| YOLOX-L [48] | CSPDarkNet [49] | 155.60 | 54.20 | 35.40 |
| YOLOv5s [50] | CSPDarkNet [49] | 16.00 | 7.04 | 31.20 |
| YOLOv5m [50] | CSPDarkNet [49] | 48.30 | 20.90 | 34.30 |
| YOLOv3-tiny [51] | Darknet-19 [51] | 19.10 | 12.10 | 23.50 |
| YOLOv8s [52] | CSPDarkNet [49] | 28.80 | 11.10 | 34.00 |
| CSC-YOLO-S [53] | CSPDarkNet [49] | 55.10 | 11.50 | 33.40 |
| TPH-YOLO [6] | CSPDarkNet [49] | 145.70 | 60.40 | 36.20 |
| ST-YOLO | CSPDarkNet [49] | 20.07 | 8.96 | 33.20 |
| Model | Backbone | GFLOPs | Parameters (M) | mAP50 (%) |
|---|---|---|---|---|
| R-FCN [54] | ResNet50 [33] | 58.90 | 31.90 | 17.50 |
| SSD [32] | VGG16 [36] | 47.74 | 23.88 | 21.40 |
| SS-ADPN [55] | ResNet50 [33] | 94.49 | 30.11 | 27.40 |
| Double-Head R-CNN [47] | ResNeXt-101 [33] | 393.37 | 47.12 | 26.00 |
| Faster R-CNN [46] | ResNet50 [33] | 172.30 | 34.60 | 23.40 |
| Cascade R-CNN [14] | ResNet50 [33] | 234.71 | 69.17 | 25.30 |
| Sparse R-CNN [56] | Transformer [16] | 172.00 | 109.70 | 26.60 |
| EfficientDet-D7 [37] | Efficient-B7 [37] | 325.00 | 51.84 | 31.80 |
| DMNet [57] | ResNet50 [33] | 27.99 | 9.72 | 24.60 |
| GFLv1 [58] | ResNet50 [33] | 208.40 | 32.20 | 29.50 |
| QueryDet [59] | ResNet50 [33] | 125.40 | 37.74 | 36.10 |
| CZ Det [60] | ResNet50 [33] | 210.00 | 45.90 | 35.54 |
| GDFNet [61] | ResNet-50-FPN [39] | 257.60 | 72.00 | 26.10 |
| YOLOX-S [48] | CSPDarkNet [49] | 26.80 | 8.90 | 31.10 |
| YOLOv4 [49] | CSPDarkNet [49] | 100.60 | 52.50 | 31.20 |
| YOLOv5s [50] | CSPDarkNet [49] | 16.00 | 7.04 | 31.80 |
| YOLOv8s [52] | CSPDarkNet [49] | 28.80 | 11.10 | 32.80 |
| YOLOv9s [62] | CSPDarkNet [49] | 27.40 | 7.28 | 33.90 |
| YOLOv10s [63] | CSPDarkNet [49] | 24.80 | 8.06 | 34.20 |
| ST-YOLO | CSPDarkNet [49] | 20.07 | 8.96 | 33.40 |
| Model | Backbone | GFLOPs | Parameters (M) | mAP50 (%) |
|---|---|---|---|---|
| Faster R-CNN [46] | ResNet101 [33] | 91.40 | 41.50 | 84.80 |
| R-FCN [54] | ResNet101 [33] | 136.20 | 64.42 | 86.13 |
| SSD [32] | ResNet101 [33] | 47.74 | 23.88 | 82.72 |
| FSSD512 [64] | VGG16 [36] | 38.12 | 34.13 | 87.59 |
| FCOS [65] | ResNet101 [33] | 85.40 | 46.00 | 95.52 |
| ATSS [44] | ResNet101 [33] | 197.09 | 31.00 | 95.94 |
| GFLV2 [66] | ResNet101 [33] | 239.32 | 37.74 | 94.91 |
| VFNet [67] | ResNet101 [33] | 119.21 | 127.12 | 94.97 |
| QueryDet [59] | ResNet50 [33] | 125.4 | 37.74 | 93.96 |
| CZ Det [60] | ResNet50 [33] | 210.00 | 45.90 | 92.18 |
| YOLOv3 [51] | DarkNet53 [51] | 283.00 | 103.00 | 86.01 |
| YOLOv4 [49] | CSPDarkNet [49] | 100.60 | 52.50 | 86.70 |
| YOLOv5s [50] | CSPDarkNet [49] | 16.00 | 7.04 | 94.20 |
| YOLOv8s [52] | CSPDarkNet [49] | 28.80 | 11.10 | 95.60 |
| YOLOv9s [62] | CSPDarkNet [49] | 27.40 | 7.28 | 95.70 |
| YOLOv10s [63] | CSPDarkNet [49] | 24.80 | 8.06 | 96.10 |
| ST-YOLO | CSPDarkNet [49] | 20.07 | 8.96 | 95.10 |
| Model | Backbone | GFLOPs | Parameters (M) | mAP50 (%) |
|---|---|---|---|---|
| RetinaNet [38] | ResNet50 [33] | 36.30 | 9.20 | 97.70 |
| Faster R-CNN [43] | ResNet50 [33] | 172.30 | 34.60 | 98.00 |
| TS4-Net [68] | ResNet50 [33] | 37.60 | 9.40 | 98.10 |
| CFC-Net [69] | ResNet50 [33] | 37.50 | 9.40 | 99.30 |
| YOLOv3 [51] | Darknet53 [51] | 283.00 | 103.00 | 99.30 |
| YOLOv5s [50] | CSPDarkNet [49] | 16.00 | 7.04 | 98.30 |
| YOLO-v5m-CSL [50] | CSPDarkNet [49] | 20.80 | 6.10 | 94.30 |
| YOLO-v5m [50] | CSPDarkNet [49] | 48.20 | 20.80 | 99.30 |
| YOLOv6s [70] | CSPDarkNet [49] | 44.20 | 16.31 | 99.20 |
| YOLOv8s [52] | CSPDarkNet [49] | 28.80 | 11.10 | 99.30 |
| YOLOv9s [62] | CSPDarkNet [49] | 27.40 | 7.28 | 99.30 |
| YOLOv10s [63] | CSPDarkNet [49] | 24.80 | 8.06 | 99.30 |
| ST-YOLO | CSPDarkNet [49] | 20.07 | 8.96 | 99.30 |
| Model | Backbone | GFLOPs | Parameters (M) | mAP50 (%) |
|---|---|---|---|---|
| YOLOv3 [51] | Darknet53 [51] | 283.00 | 103.00 | 88.5 |
| YOLOv5s [50] | CSPDarkNet [49] | 16.00 | 7.04 | 86.6 |
| YOLOv5m [50] | CSPDarkNet [49] | 64.40 | 25.06 | 87.8 |
| YOLOv6s [70] | CSPDarkNet [49] | 44.20 | 16.31 | 84.8 |
| YOLOv7 [71] | CSPDarkNet [49] | 105.10 | 37.2 | 94.2 |
| YOLOv8s [60] | CSPDarkNet [49] | 28.80 | 11.10 | 86.8 |
| YOLOv9m [62] | CSPDarkNet [49] | 77.6 | 20.16 | 87.9 |
| ST-YOLO | CSPDarkNet [49] | 20.07 | 8.96 | 93.9 |
| Model | +CAA | +SI-IoU | +PPA | Precision | Recall | mAP50 (%) | mAP50-95 (%) |
|---|---|---|---|---|---|---|---|
| Baseline | - | - | - | 0.435 | 0.320 | 31.2 | 16.4 |
| ✓ | - | - | 0.428 | 0.326 | 31.6 | 16.6 | |
| - | ✓ | - | 0.448 | 0.331 | 32.4 | 17.3 | |
| - | - | ✓ | 0.434 | 0.331 | 31.9 | 17.2 | |
| ✓ | ✓ | - | 0.441 | 0.334 | 32.5 | 17.3 | |
| ✓ | - | ✓ | 0.453 | 0.331 | 32.6 | 17.4 | |
| - | ✓ | ✓ | 0.445 | 0.339 | 32.9 | 17.9 | |
| ST-YOLO | ✓ | ✓ | ✓ | 0.453 | 0.339 | 33.2 | 18.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, H.; Kong, X.; Wang, J.; Tomiyama, H. ST-YOLO: An Enhanced Detector of Small Objects in Unmanned Aerial Vehicle Imagery. Drones 2025, 9, 338. https://doi.org/10.3390/drones9050338
Yan H, Kong X, Wang J, Tomiyama H. ST-YOLO: An Enhanced Detector of Small Objects in Unmanned Aerial Vehicle Imagery. Drones. 2025; 9(5):338. https://doi.org/10.3390/drones9050338
Chicago/Turabian StyleYan, Haimin, Xiangbo Kong, Juncheng Wang, and Hiroyuki Tomiyama. 2025. "ST-YOLO: An Enhanced Detector of Small Objects in Unmanned Aerial Vehicle Imagery" Drones 9, no. 5: 338. https://doi.org/10.3390/drones9050338
APA StyleYan, H., Kong, X., Wang, J., & Tomiyama, H. (2025). ST-YOLO: An Enhanced Detector of Small Objects in Unmanned Aerial Vehicle Imagery. Drones, 9(5), 338. https://doi.org/10.3390/drones9050338