1. Introduction
Infrared object detection has become a significant research topic in recent years due to its wide range of applications in military surveillance, maritime rescue, and fire monitoring [
1,
2,
3,
4,
5,
6]. Infrared sensors offer robust performance under varying illumination conditions, capturing the outlines of objects emitting thermal radiation even in dark or low-light environments, which provides considerable advantages over visible-light imaging.
Detecting infrared weak objects presents significant challenges due to their low contrast against complex backgrounds and the absence of distinct structural or textural features, often rendering them as blurry, discrete, point-like objects [
7,
8,
9]. Detection methodologies are broadly categorized into motion-based and appearance-based approaches. Motion-based methods [
10,
11] analyze inter-frame relationships to identify objects; however, they struggle with stationary objects. Appearance-based methods are further divided into traditional techniques and deep learning approaches. Traditional methods [
12,
13] rely on handcrafted mathematical functions to extract object features, performing adequately in specific contexts but lacking adaptability to diverse environments. Deep learning [
14,
15,
16] approaches train models on large-scale datasets to detect objects through feature learning, demonstrating rapid detection speeds and exceptional accuracy on well-defined, large-scale datasets. However, these methods typically exhibit lower accuracy when applied to infrared weak object detection datasets. This is because infrared weak objects typically occupy only a few pixels in the image, making high-level feature extraction challenging due to their small size and low signal-to-noise ratio. Furthermore, insufficient receptive fields lead to the loss of local details, resulting in confusion between objects and background, thereby degrading detection performance. Additionally, in drone imagery, the significant scale variation of objects further complicates detection. To address these issues, context-enhancing approaches can be employed to improve the utilization of both low- and high-level features, ultimately enhancing detection robustness.
Background noise frequently obscures object features, making effective suppression crucial in infrared weak object detection [
17,
18,
19]. Current research on background noise suppression is divided into traditional and deep learning methods. Traditional approaches [
20,
21] are less effective in complex backgrounds, such as urban structures, forests, and cloud cover. In contrast, deep learning methods [
22,
23,
24], which often incorporate segmentation algorithms, require extensive datasets to effectively differentiate between background and objects. Moreover, the constrained receptive fields of many detection models hinder their ability to capture global context, further impairing the localization of weak objects.
To address these challenges, a new model IRWT-YOLO is developed in this study. It incorporates a segmentation-based data augmentation strategy and multiple architectural innovations designed to enhance the model’s ability to detect infrared weak objects.
The main contributions of this work are summarized as follows:
To address background interference in infrared weak object detection, we propose a segmentation-based augmentation strategy that enhances object–background separation using the Segment Anything Model (SAM), thereby improving detection performance for UAV targets.
A novel YOLO-based detection framework, IRWT-YOLO, is proposed. It integrates DCPPA and RCSCAA modules, with BiFormer embedded into the backbone to enrich contextual information. An additional detection head is included to improve performance for weak objects.
A dual-branch receptive field expansion module, DCPPA, is designed to preserve weak object features and improve detection robustness in complex scenes.
To enhance feature extraction and improve weak object detection performance, we integrate the RCSCAA module into the network’s neck and replace part of the C2f in the backbone with BiFormer, effectively boosting feature extraction capabilities.
The remainder of this paper is organized as follows:
Section 2 reviews related work on infrared weak object detection and background suppression techniques. In
Section 3, the overall architecture of the proposed IRWT-YOLO model and the structural details of the DCPPA and RCSCAA modules are introduced.
Section 4 presents the experimental setup, results, and comparisons with existing state-of-the-art methods on several public datasets.
Section 5 provides a discussion of the findings. Finally,
Section 6 concludes the paper and outlines future research directions.
2. Related Work
Section 2 reviews the current research status, with
Section 2.1 summarizing infrared weak object detection methods and
Section 2.2 reviewing recent progress in background suppression techniques.
2.1. Infrared Weak Object Detection
The task of infrared weak object detection is to identify low-contrast objects in complex backgrounds. Infrared weak object detection can be divided into two types: motion-based methods [
25] and appearance-based methods [
26]. The motion-based approach is well suited for processing continuous dynamic video image information but relies on certain necessary prior assumptions. However, as a consequence of limitations in sensor hardware and the issue of significant positional shifts occurring within a few frames during high-speed UAV flight, leading to tracking loss, these assumptions are challenging to satisfy [
20]. In contrast, the appearance-based detection method identifies UAVs on a single frame, offering simplicity and ease of implementation. Therefore, we have opted for the appearance-based method to identify UAV objects.
Appearance-based methods include both traditional approaches and deep learning techniques. Traditional methods include TopHat [
27], the LCM method [
28], Max-Median [
29], WSLCM [
30], and MSLSTIPT [
31]. However, traditional methods struggle to handle clutter and noise interference and are often limited by application scenarios, leading to poor generalizability of the model.
With the advancement of hardware devices, deep learning methods have gradually become mainstream and can be categorized into two-stage and single-stage methods. Two-stage detectors, such as R-CNN [
32], Fast R-CNN [
33], Faster R-CNN [
34], Cascade R-CNN [
35], and Libra R-CNN [
36], focus on resolving overfit merges to reduce computational effort for higher accuracy.
Single-stage detectors, such as YOLO [
37], are known for their fast detection speed and real-time performance. These methods perform well in general object detection scenarios but often struggle with false positives, missed detections, and misdetections, particularly when dealing with a weak object in infrared images. As one of the widely used standards in the field of object detection, YOLOv5 [
38] effectively balances detection accuracy and speed. YOLOv8 [
39] further optimizes the backbone network enhancing the model’s ability to capture and integrate multi-scale information, thereby improving the detection of small objects in complex scenes. Liu propose the dab-detr [
40] model, an end-to-end object detection model which aims to reintroduce an anchor box in detr [
41] and accelerated convergence. Deformerdetr introduces the DeformableTransformer [
42] to alleviate the calculation cost and improve the precision of small object detection. Although the aforementioned methods have improved the detection accuracy of infrared objects, they still have limitations, such as difficulties in handling complex backgrounds, weak contextual relationships, and restricted receptive field size. To address these challenges, we propose the IRWT-YOLO model, which aims to enhance weak object detection performance. By strengthening contextual relationships, improving feature utilization, and enhancing multi-scale object detection capabilities, the model expands the receptive field while preserving the low-level object features to improve small object detection. The proposed method suppresses false alarm rates and improves mean accuracy, achieving precise detection of UAV objects with limited resources.
2.2. Background Suppression Methods
Background suppression encompasses traditional methods and deep learning approaches. Traditional background suppression methods, which are based on unsupervised algorithms, achieve background suppression through the manual design of spatial filters. Traditional methods can be divided into two types. One type of method assumes that the background neighborhood is homogeneous, and the micro-objects disrupt the local correlation. It includes top-hat filtering [
43,
44], maximum mean filtering/maximum median filtering [
29], Two-Dimensional Least Mean Square [
45] and Quaternion Discrete Cosine Transform [
46]. Therefore, it is necessary to design an appropriate filter to extract the weak objects from the background. However, in practical applications, there are many restrictions from the background, making it difficult to construct a universal adaptive filter. Some researchers emphasize feature extraction based on the assumption that the background neighborhood is homogeneous, including color features [
47], texture features [
48], motion features [
49], and texture features [
50] and operates them separately, and then uses hierarchical fusion for shadow detection and removal, thereby reducing the influence of light conditions. RLCM [
51] proposes a local contrast calculation method. Multi-scale RLCM is computed for each pixel to enhance the true object and suppress all types of interference. The background suppression method based on wavelet transformation suppresses the background by separating the low-frequency sub-image and the high-frequency sub-image, and then selects the appropriate threshold to detect the object [
52]. EGMM [
53] places a greater emphasis on feature representation, enhancing the representational capacity of features through the introduction of belief function theory and evidential Gaussian mixture distributions, thereby more effectively handling uncertainties and complex data.
Another type of method assumes that infrared images are composed of low-rank background signals, sparse object signals, and noise signals, and extracts the sparse object signals from the original data [
54]. Li [
55] assumed that the infrared background image was a low-rank matrix, and the infrared object image was a sparse matrix. They reconstructed the object image and background image by optimizing the two matrices, and then obtained the small object by the threshold segmentation method. However, the above two traditional methods are difficult to apply to the case of variable object size, and the fixed filter will result in a high false alarm rate when the object size is changeable.
Deep learning-based methods have gained significant attention due to their ability to automatically learn hierarchical features from raw data, eliminating the need for manual feature extraction [
56,
57]. KCPNet [
58] can enhance the object mask information and suppress background interference through dual mask attention. SMPISD-MTPNet [
59] uses a two-layer sliding window structure to calculate background pixel changes and local contrast of the object by layers. Tian [
60] proposed to reduce the interference of background clutter on mask generation by introducing structural information constraints, and to assist in determining the object location by constraining the context information of subsequent frames in the previous frame. Zhang [
61] effectively improved model accuracy and generalization ability in small-sample scenarios by integrating PatchUp, self-supervised auxiliary loss, and feature preprocessing. A4-UNET [
62] integrates the Combined Attention Module and attention gates in its skip connections, enhancing pixel grouping to suppress background-irrelevant information and highlight the target.
Traditional methods define infrared object detection as a segmentation problem [
63]. However, in pursuit of higher detection rates, they sacrifice the integrity of the segmented objects [
64], which contradicts the original intent of segmentation. To address this issue, we continue the idea of traditional methods by combining deep learning methods. We integrate the Segment Anything Model [
65], which combines interactivity and zero-shot capabilities, enabling it to be directly applied to downstream tasks.
3. Methods
This section provides a detailed description of the proposed methodology.
Section 3.1 outlines the background suppression approach. The IRWT-YOLO model architecture is introduced in
Section 3.2.
Section 3.3 and
Section 3.4 elaborate on the construction details of the DCPPA and RCSCAA modules, respectively.
3.1. Background Suppression as an Image Enhancement Strategy
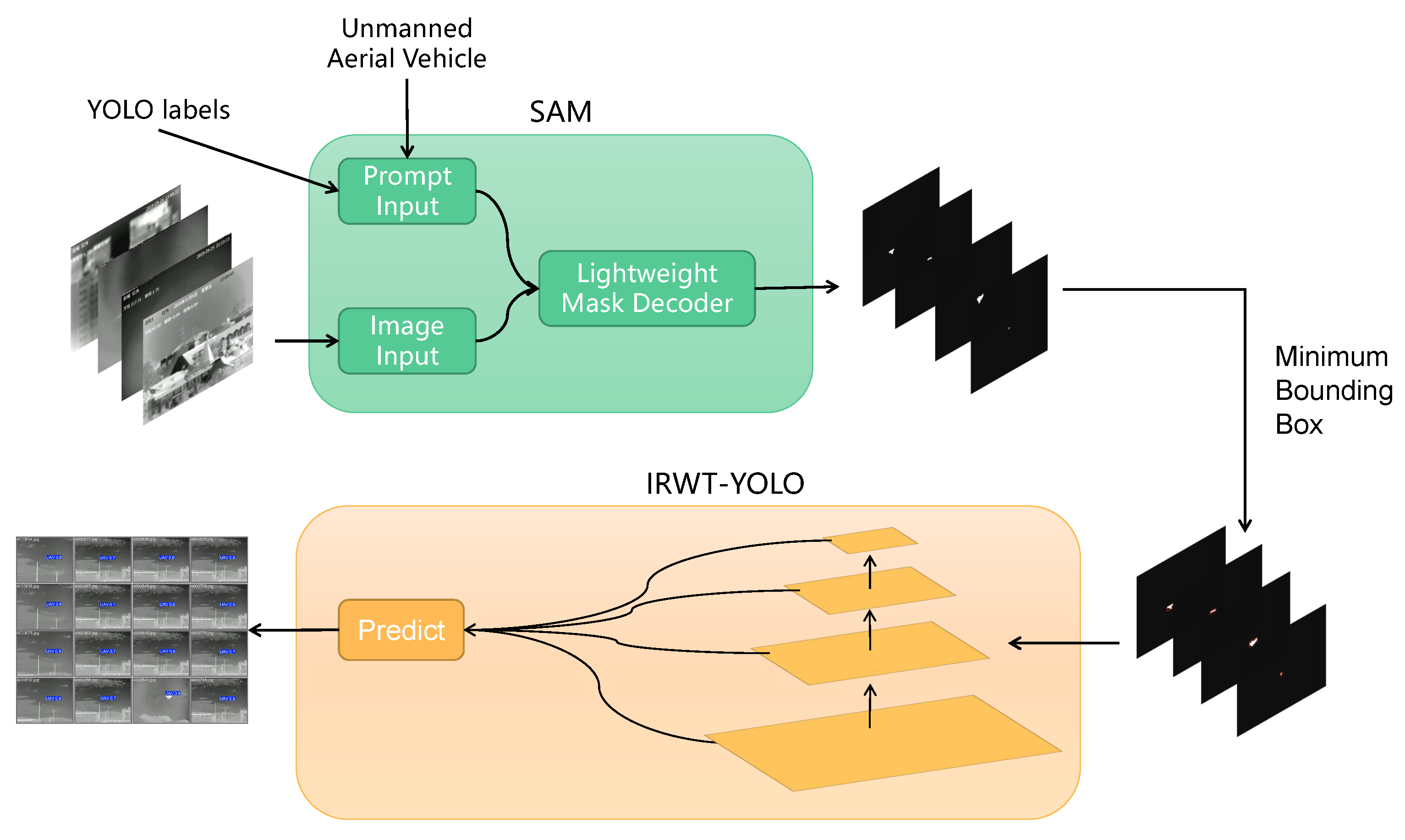
Although the original bounding boxes may contain irrelevant information, the object’s center point generally remains within the object area, with minimal offset. Therefore, in this section, we propose an image enhancement method that decreases background interference by segmenting the weak object from the infrared image. The proposed method’s process is shown in
Figure 1.
We choose the Segment Anything Model (SAM) [
65] for background suppression and image enhancement. SAM has been proven to be effective in the field of image segmentation, offering superior efficiency and better preservation of object information compared to previous background suppression methods [
66]. As a pre-trained model, SAM with zero training samples can combine user-provided image and text prompts to identify the corresponding objects within the image.
In the image encoder, a Vision Transformer (ViT) is pre-trained using the Masked Autoencoder (MAE) approach. The prompt encoder is designed to process both sparse and dense input prompts. Leveraging the powerful text encoder from CLIP, the model performs positional encoding on both image and text prompts. After convolutional processing of the dense input (mask), it is element-wise summed with the image embedding. The mask decoder is a bidirectional Transformer decoder, which utilizes both self-attention and cross-attention mechanisms for refining segmentation masks.
The original labels contain
, which is the percentage of the center’s x-coordinate in the image width, and
which is the percentage of the center’s y-coordinate in the image height.
and
represent the object’s width and height as relative proportions of the image’s width and height, ranging from 0 to 1. Based on the original labels in the dataset, we extract the center point coordinates and the object’s width and height, and calculate the number of pixels occupied by the object. The following formula calculates the process from the YOLO format coordinates to actual pixel coordinates, where
and
denote the width and height of the original images,
represents the left
x value of the bounding box,
represents the right
x value of the bounding box,
represents the upper
y value of the bounding box, and
represents the lower y value of the bounding box:
We set the center point as a positive label point and use both the bounding box and center point as the input prompt, ensuring that even in cases of blurred object edges, no additional background information is included.
Additionally, we input UAV as semantic prompt information to assist in locating the object’s shape. To resolve semantic ambiguity, SAM outputs three masks by default, from which the one with the highest score is selected as the optimal mask for generating mask information. Subsequently, the minimum bounding box of the mask pattern is calculated and used as the new bounding box to recalculate the YOLO-format object label information. The minimum bounding box is defined as the smallest rectangle that completely encloses a binary mask while maintaining edges parallel to the image coordinate axes. This geometric representation effectively suppresses irrelevant background interference by preserving only the essential spatial extent of the target object. The minimum bounding box extraction process enhances detection robustness through two key mechanisms: elimination of extraneous background pixels that may introduce noise, and preservation of the object’s fundamental geometric characteristics.
In summary, by applying SAM as an image enhancement method, we effectively enhance the accuracy of positive sample information, reduce background interference, and make weak objects more prominent. This provides an effective background suppression technique for infrared weak object detection, improving the model’s ability to detect objects in various challenging background environments.
3.2. IRWT-YOLO Model
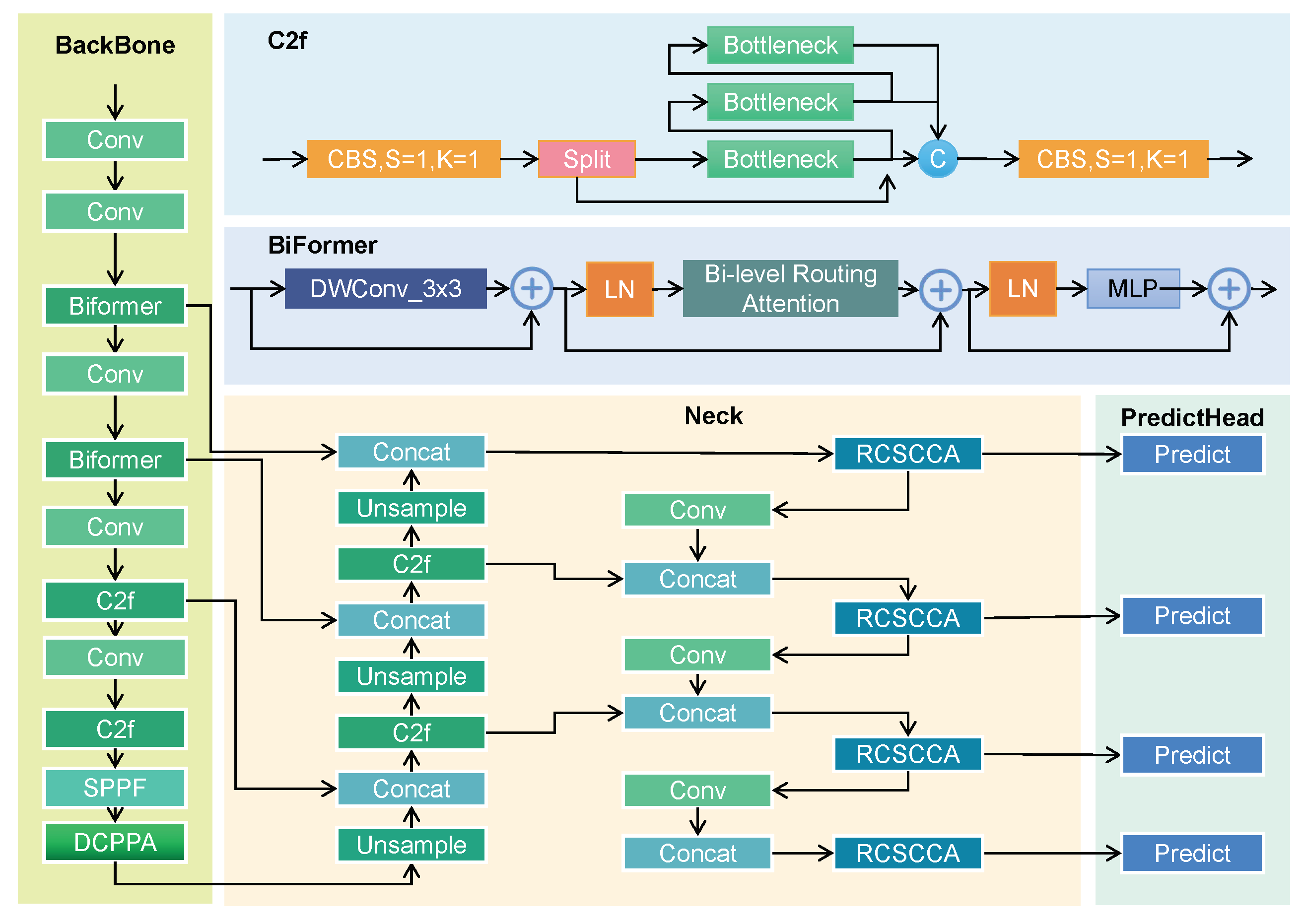
In infrared weak object detection, because of camera zoom and UAV flight, the features are not universal due to the large change in object size, and the small size object occupies too few pixels to extract effective features. The lower-level features may not provide enough contextual information to detect small objects accurately. To address the challenge, we propose a novel model IRWT-YOLO, making improvement on three aspects: the backbone, neck, and head networks. We propose an enhanced backbone network for YOLOv8, integrating both BiFormer and C2f as convolutional layers within the backbone architecture. In this framework, C2f performs the feature extraction task in YOLOv8, generating feature maps through convolution after the bottleneck-generated feature maps are concatenated. By employing bi-level routing attention, BiFormer mitigates the influence of background noise.
This mechanism enhances the detection performance of weak objects and small-scale objects in infrared images. By effectively integrating the C2f module with the BiFormer structure, the model preserves critical low-level features during multi-scale feature extraction, thereby improving robustness in weak object detection. However, due to the high computational complexity of the BiFormer structure, replacing all C2f modules with BiFormer would lead to excessive model parameters. Replacing the module at the second layer enhances fine-grained feature representation, while implementing it at the fourth layer strengthens global attention mechanisms through interaction with contextual features. Considering the balance between computational efficiency and detection accuracy, this study ultimately replaces the C2f modules with BiFormer structures in the second and fourth layers of the network.
Figure 2 illustrates the overall architecture of the proposed IRWT-YOLO model.
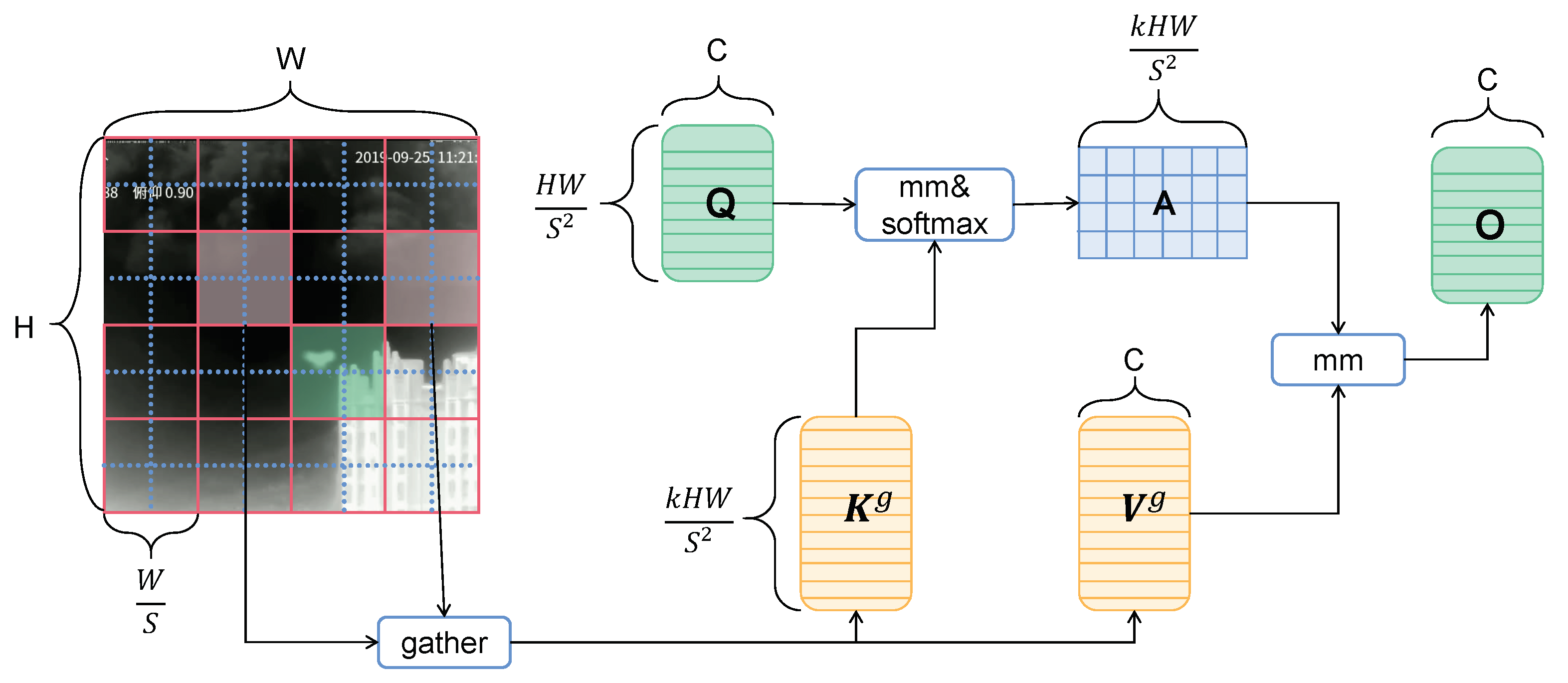
The Bi-level Routing Attention(BRA) module in BiFormer leverages sparse sampling, which not only reduces computational overhead but also preserves fine-grained information at the particle level, ensuring that weak object features are retained. The BRA structure is shown in the
Figure 3. By incorporating a sparse self-attention mechanism, we focus on the most relevant key-value pairs, effectively mitigating the loss of fine-grained details typically encountered in conventional downsampling techniques. This modification contributes to the retention of more detailed information from the input image. First, the input image is partitioned into smaller patches through convolutional operations, which maintains the relative spatial relationships of the image. Subsequently, key features are extracted via progressively expanded feature channels. The BRA module learns the interrelationships between spatial positions, and finally, an MLP (Multi-Layer Perceptron) module is utilized to further enhance the extraction of detailed feature representations at each spatial location.
To further improve the accuracy of small object detection and address the challenge of large-scale variations in the dataset, we add an additional detection head specifically designed for small objects. This increases the number of detection heads from three to four. The new small-object detection head is more sensitive to lower-level features, effectively mitigating the issue of small object feature loss caused by excessively deep networks. While the addition of an extra detection head increases computational cost and memory consumption, it significantly enhances the detection performance for small objects, making the model more robust and accurate.
3.3. Dual Convolution Paralleled Patch-Aware Attention Module
Weak objects often present challenges because of their limited feature representation, which makes it difficult to extract semantic features. After multiple downsampling operations, these features tend to become blurred, leading to the loss of critical information. To address this issue, we propose the DCPPA module to enhance the detection of weak objects by extracting more detailed information. The architecture of the DCPPA module is shown in
Figure 4.
The DCPPA module utilizes a multi-branch strategy to improve the detection accuracy of a weak object. One of the branches incorporates a Local-Global Attention mechanism with two different scales. This approach allocates extra attention to small objects by considering both local and global contexts at varying levels of granularity. Furthermore, to overcome the computational inefficiency of traditional 5 × 5 convolutions, we replace them with dual-branch, dual-layer 3 × 3 convolutions. This substitution ensures that the receptive field remains consistent while reducing the computational cost.
By employing dual convolution branches, the module extracts features from the original images, enabling a more comprehensive representation of weak object characteristics. This helps mitigate false alarm rates caused by erroneous positioning, where objects blend with the background as a result of their subtle appearance. Additionally, by concatenating information from different branches and integrating multi-scale features, the model can better process objects of various sizes, ensuring more accurate multi-scale object detection. The input feature tensor
is convolved twice to obtain
. The process is shown in the formula, where
represents the weights of the first layer convolution kernel,
is the bias term of the first layer convolution, and the convolution result
of the first layer is also used as input to the second layer:
The Local-Global Attention method is used to extract global features. To minimize interference from irrelevant information, two dual-layer 3 × 3 convolutions are employed for feature extraction, ensuring that the network captures essential patterns without being distracted by noise or unrelated background details. The equations are as follows:
Once features from different scales and branches are extracted, they are fused through the channel attention map and spatial attention map mechanisms to integrate multi-scale features effectively. This feature fusion step helps the model focus on important regions and strengthens the detection of weak objects across multiple scales. By integrating features from multiple branches, the module learns to prioritize crucial information, allowing the model to better distinguish weak objects from the background and improving its overall detection performance.
In summary, the DCPPA module enhances weak object detection by increasing the capacity to extract detailed features and addressing the challenges posed by the blurry or ambiguous appearance of a weak object.
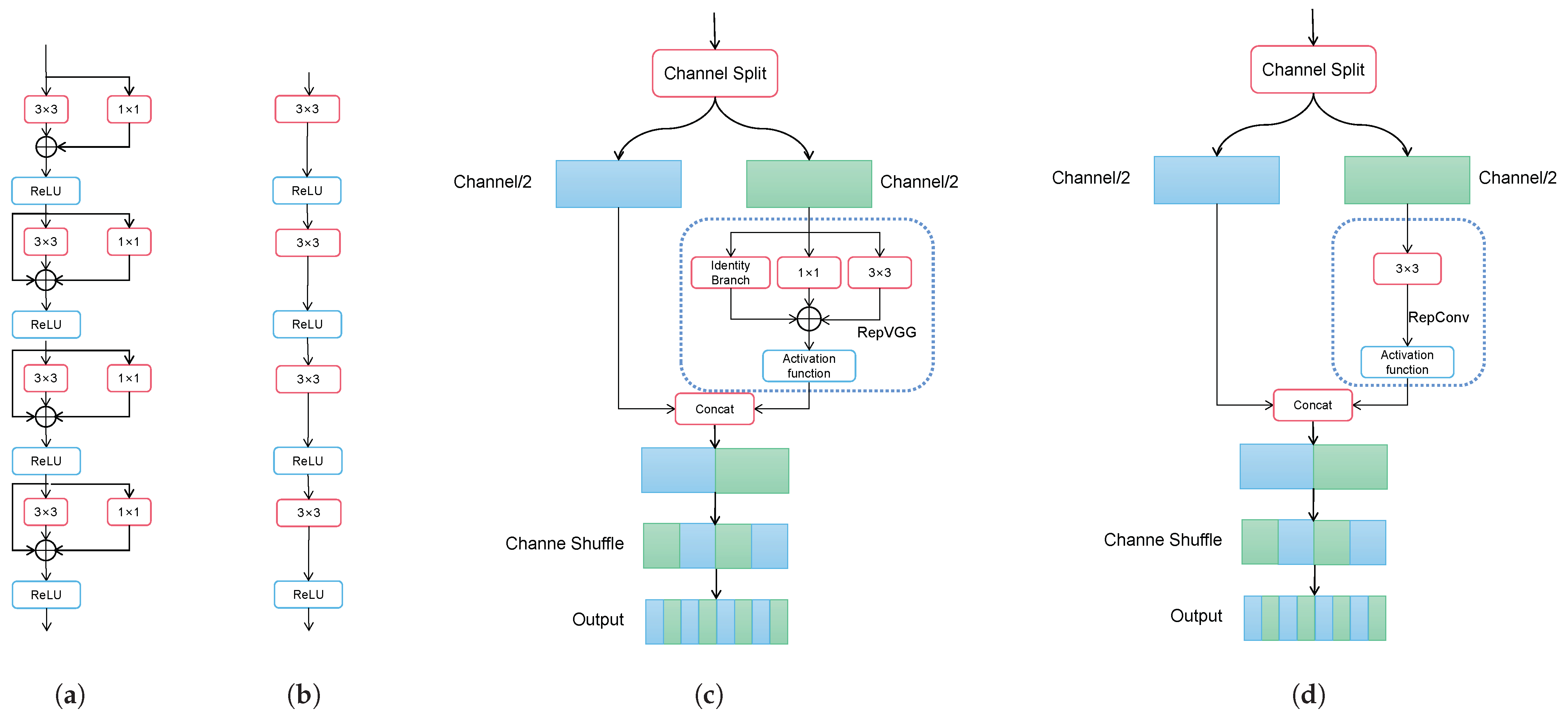
3.4. RCSCAA Module
To enhance the utilization of features at different scales of a weak object in infrared images, we propose an improved version of the RepVGG/RepConv ShuffleNet-Based One-Shot Aggregation module, called the RCSCAA module. The RCSOSA module is a module optimized for object detection tasks, which aims to enhance the feature representation ability and improve the detection accuracy. We design a new module RCSCAA based on the original RCSOSA module to improve the performance of the neck. RCSCAA uses RCS and the RepVGG module as the basic module, and splits the input tensor
F into two identical parts with the number of channels of
to obtain branch
A and branch
B. One of the branches
A is processed in parallel, and the obtained branches are convolved separately to obtain
and branch
B which are spliced to obtain a new feature map. The detailed structure of RCSCAA is presented in
Figure 5.
In order to solve the problem of information isolation caused by grouped convolution, channel shuffle is used to rearrange the channels, reshape the dimensions of branch
A and branch
B, and transpose or cross-mix the channels. The working process of RCS is shown in the following formula, where the
and
are obtained after branch parallel processing of the A branch, the branch A′ is obtained after concatenation, and the features obtained by the A′ and B concatenation are rearranged to facilitate information exchange:
The architecture of RCS is shown in
Figure 6. RCS modules are sequentially stacked to perform feature extraction progressively.
To capture the long-range contextual information, we introduce the Context Anchor Attention (CAA) module [
67]. In the formula below, we employ Average Pool and 1 × 1 convolution to extract the location region feature, with
denoting the average pooling operation:
The utilization of global average pooling and one-dimensional strip convolutions facilitates the combination of local and global information, making it particularly suitable for multi-scale objects and enabling more efficient extraction of semantic information. When
,
. Then, we apply two depthwise strip convolutions as an approximation to a standard large-kernel depth-wise convolution:
We set
to increase the receptive field with increasing depth. Finally, we produce a weight and enhance the weight before output:
The sigmoid function ensures that the attention map is in the range . ⊙ represents the element-wise multiplication, and ⊕ represents the element-wise summation.
4. Experiment and Results
First,
Section 4.1 briefly describes the experimental setup, including the datasets for comparison with other advanced models, evaluation metrics, baseline methods, and parameter configurations, with additional implementation details provided in
Section 4.2.
Section 4.3 presents external comparative experiments with ten state-of-the-art object detection methods. To validate the effectiveness of each component in the proposed detector, ablation studies are conducted in
Section 4.4. For intuitive demonstration of IRWT-YOLO’s advantages, visualization results are presented in
Section 4.5. Finally,
Section 4.6 reports additional experiments on two public datasets to verify the method’s generalizability.
4.1. Datasets and Evaluation Metrics
We train our model using the 3rd Anti-UAV public dataset [
68] and evaluate its performance on the test set. The evaluation metrics include
(average of all 10 Intersection over Union (IoU) thresholds, ranging from [0.5: 0.95]) and
. The input image size is set to 640 × 512 pixels, and label 0 is assigned to UAV objects, as shown in
Figure 7.
In this paper, we select precision, recall,
,
, and FLOPs as the evaluation metrics to compare the detection performance of the model and determine its strengths and weaknesses. The precision and recall are calculated based on the following formulae, using IoU = 0.5 as the threshold:
In the formula, represents the number of true positives, represents the number of false positives, represents the number of false negatives, C is the total number of categories, and is the average precision for the i-th category. These metrics help assess how well the model detects true objects (precision) and how effectively it identifies all relevant objects (recall). The Mean Average Precision () is used to evaluate the overall accuracy of a model. IoU assesses model performance by calculating the ratio of the intersection to the union between the predicted bounding box and the ground truth. refers to the proportion of correct detections when the IoU threshold is set to 0.5. computes the values at IoU thresholds ranging from 0.5 to 0.95, with a step size of 0.05, and takes the average of these values. provides a more comprehensive assessment of the model’s accuracy and robustness, as higher IoU values indicate greater overlap between the predicted and ground truth bounding boxes, thereby increasing the difficulty of the detection task.
4.2. Implementation Details
We conducted experiments on the model using an NVIDIA TITAN Xp Founders (NVIDIA, Santa Clara, CA, USA) Edition with CUDA 11.8. We used a batch size of 4 and trained the model for 300 epochs. Since each image contains only one object, the mixup factor was set to 1.0 to optimize performance with fewer images. Because of the large size of the 3rd Anti-UAV training set and hardware limitations, we randomly selected 15,000 images from the training set and 5000 images from the validation set for training and evaluation.
4.3. Comparisons with the State-of-the-Art
We enhance the detection capability of the model by introducing a novel module and method. To validate the effectiveness of these improvements, the dataset we constructed after random selection on the 3rd Anti-UAV dataset was unified for the experiment after SAM processing.
In this study, we employed several advanced models, including Faster R-CNN [
34], Libra R-CNN [
36], Cascade R-CNN [
35], DAB-DETR [
40], YOLOv5 [
69], YOLOv8 [
70], YOLOX [
71], YOLOv8-World [
72], YOLOv10 [
73], and YOLO11 [
74]. All methods are evaluated on the 3rd Anti-UAV dataset, and the same evaluation metrics are used to ensure fair comparisons. The results for methods are reproduced using their publicly available code.
The results demonstrate that the proposed model achieves excellent performance, with validation of its effectiveness across four metrics. As shown in
Table 1, the precision of the method reaches 89.5%, the recall reaches 59.3%, the
reaches 62.2%, and the
reaches 44.8%, which is superior to the current advanced algorithms.
4.4. Ablation Studies
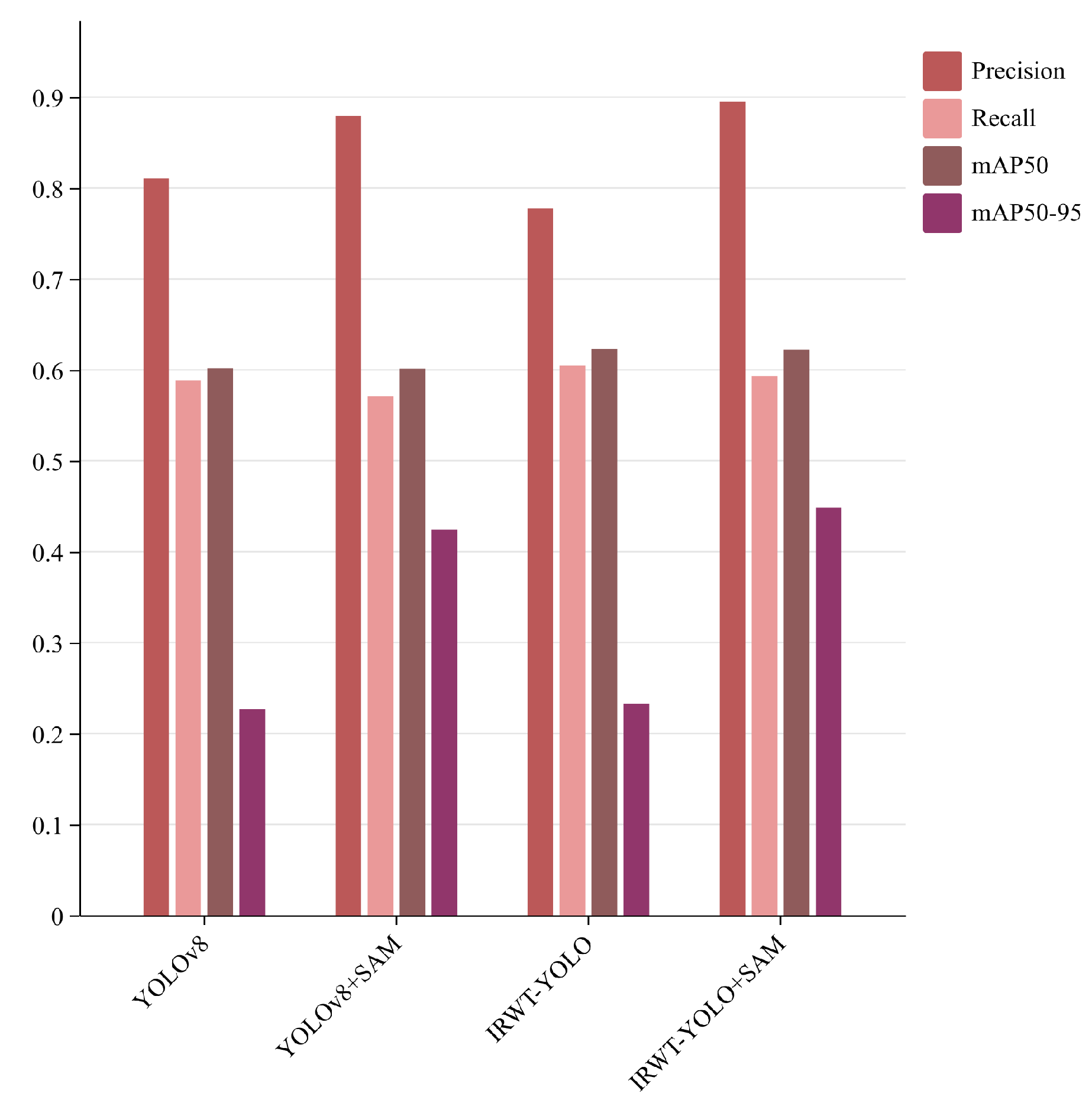
To validate the effectiveness of each module, we conducted ablation experiments for each component and presented the results in
Table 2 and
Figure 8. In
Figure 8, we demonstrate that the modified SAM significantly improves accuracy by reducing the amount of irrelevant negative sample information. Although precision slightly decreased after incorporating DCPPA, while
increased, we believe that DCPPA enhances detection accuracy by expanding the receptive field to gather more information, thereby suppressing noise and reducing the false positive rate. Additionally, RCSCAA enhances the accuracy of weak object detection, and BiFormer strengthens overall detection accuracy through bidirectional routing. After adding the DCPPA module, the
improves by 1.2%. The DCPPA module helps significantly improve the detection of a weak object, making it particularly useful for handling small and difficult-to-detect objects. By replacing the C2f module with the BiFormer module in the backbone network, the context relationship ability of the model is strengthened, the detection ability of the model under multi-scale conditions is strengthened, and the feature mismatch problem caused by large-scale changes is alleviated.
Figure 8 illustrates the qualitative comparisons. By applying SAM to improve the bounding boxes of the object detection task, we shrink the object bounding box area while retaining the UAV object information and reducing irrelevant background noise. As a result, the
for the standard YOLOv8 model increases from 22.7% to 42.5%, and the
for the standard IRWT-YOLO model increases from 23.3% to 44.8%, demonstrating that the integration of segmentation improves the detection performance, especially in complex environments with cluttered backgrounds.
We not only improved the detection accuracy but also maintained other metrics consistent with the baseline. This suggests that the integration of the Segment Anything Model enhances the accuracy of boundary localization and improves the detection performance at higher IoU thresholds. , which evaluates performance across multiple IoU thresholds, is more sensitive to such improvements, particularly at higher IoU values. In contrast, metrics like precision and recall, which are influenced more by classification and overall detection performance, remain less affected. These findings underscore the value of SAM in enhancing detection accuracy in scenarios demanding high localization precision, despite limited impact on global detection metrics, such as precision and recall.
4.5. Results Visualization
To verify the effectiveness of the model, we adopted Grad-CAM to generate a visual heatmap of the model. In this figure, we observed that when UAVs appear at the edges of buildings, the detection process is often interfered with. YOLOv8 detects a potential object in these regions, but with very low confidence, making it unable to confirm the presence of a UAV. On the other hand, YOLOv11 fails to detect potential positions altogether. Furthermore, both models allocate attention to irrelevant areas of the image, leading to inefficient use of resources. When the UAV is further away and occupies only a few pixels, making feature extraction difficult, the model still demonstrates superior detection capabilities, while the other two models fail to detect the UAV.
Additionally, we conducted experiments with complex background interference, selecting scenarios with mountain forests, clouds, and buildings as backgrounds. In these complex environments, distinguishing UAVs becomes challenging for the models. UAVs with low contrast against similarly low-contrast complex backgrounds are particularly difficult to identify. As shown in the images, YOLOv11 allocates a significant portion of its attention to irrelevant areas in an attempt to locate the object, while YOLOv8 can detect the UAV but with much lower confidence compared to the IRWT-YOLO model. To demonstrate the superiority of the IRWT-YOLO model, we use heatmaps to validate its performance in
Figure 9.
4.6. Experiments on Publicly Available Datasets
We note that most of the current datasets of infrared faint objects are small sample datasets. To address this issue, we additionally evaluate the IRWT-YOLO model on the SIRSTv2 [
9,
75,
76] and IRSTD-1k [
77] datasets. The SIRSTv2 and IRSTD-1k datasets both contain significantly fewer samples compared to the 3rd dataset. The IRSTD-1k dataset includes 640 training images, 160 validation images, and 200 test images, while the SIRSTv2 dataset consists of 511 training images, 255 validation images, and 255 test images. Both datasets feature diverse cluttered backgrounds that introduce interference challenges.
The IRWT-YOLO model demonstrates substantial accuracy improvements over the baseline YOLOv8 model on both datasets. The results are represented in
Table 3. On the IRSTD-1k dataset, IRWT-YOLO achieves a 13.6% improvement in
and a 7.0% improvement in
. On the SIRSTv2 dataset, it achieves a 19.6% increase in
and a 9.6% increase in
. These results highlight the significant performance gains of the IRWT-YOLO model across multiple datasets, particularly under low-data and small-training scenarios. The model effectively mitigates overfitting, a common challenge under limited sample conditions, and converges more rapidly. It is confirmed that the IRWT-YOLO model maintains excellent performance even in the absence of sufficient training samples, demonstrating its outstanding transferability and adaptability, making it a robust solution for small-sample and complex-background scenarios.
5. Discussion
The experimental results show that the proposed method effectively enhances the accuracy of infrared weak object detection, achieving higher average precision than existing methods. It addresses the challenges of irrelevant background interference and the difficulty of detecting weak objects, significantly improving detection accuracy. By applying image segmentation for background suppression, we enhance the object’s visibility, eliminate background interference, and strengthen the model’s detection performance. We designed the IRWT-YOLO model specifically for infrared UAV images. By integrating BiFormer into the backbone, the model’s ability to understand and relate contextual information is improved, mitigating the issue of large object size variations due to camera zoom and other factors.
Furthermore, to address the difficulty of extracting features from weak small objects, we propose the DCPPA module, which uses dual convolution branches to expand the receptive field and enhance small object detection capabilities. We also introduce the RCSCAA module to strengthen long-range semantic feature extraction. The improvement in IRWT-YOLO’s detection performance can be attributed to the combination of background suppression, global and local context enhancement, and enhanced feature extraction capabilities. The effective integration of image segmentation reduces background clutter, allowing the model to focus on weak objects. These results align with previous studies, confirming the effectiveness of background suppression in infrared imaging tasks. Compared to earlier background suppression methods, the proposed approach demonstrates superior robustness under various environmental conditions. Previous methods often struggle with complex backgrounds, whereas this approach, leveraging image segmentation, maintains strong performance across different datasets.
However, despite the improvement in detection accuracy, the IRWT-YOLO model introduces additional parameters and increased computational complexity. Future research will focus on optimizing the model architecture and exploring lightweight configurations to accelerate inference speed and enhance practical deployment feasibility. Moreover, while the background suppression strategy has effectively reduced interference, some residual background noise remains. To address this, future work will further refine the background suppression mechanism to minimize background interference and enhance the detection capability of infrared weak objects.
6. Conclusions
Infrared UAV image detection is challenged by weak object visibility and background interference, which complicate the detection process. To address this issue, we propose using image segmentation methods to refine the object bounding boxes in the training dataset and introduce a new model, IRWT-YOLO. By applying image segmentation to improve the label information, we ensure that the bounding boxes represent the object’s minimal bounding box, reducing background clutter and enabling the model to focus more effectively on UAV-related information. This approach is particularly suitable for handling discrete, hard-to-annotate fuzzy object points and complex objects with low contrast relative to the background.
In the IRWT-YOLO model, we design new modules and structures, including the integration of BiFormer into the backbone network and introduction of the RCSCAA and DCPPA modules to enhance weak object detection performance. BiFormer utilizes a dual-route mechanism to effectively link and leverage contextual information, strengthening multi-scale object detection capabilities and improving the flow of features across different scales. RCSCAA strengthens feature extraction by introducing the CAA mechanism, which effectively captures long-range dependencies and enhances the ability to extract semantic features of the object. The DCPPA module, through a multi-branch structure, more comprehensively captures feature information from the input image, enhancing the model’s ability to handle complex images.
We conduct extensive experiments and validations using the 3rd Anti-UAV infrared UAV dataset, demonstrating the superiority of the proposed method from multiple angles. We also address supplementary matters on the SIRSTv2 and IRSTD-1k datasets. The results show that the proposed approach outperforms traditional segmentation and deep learning models. Compared to the baseline model YOLOv8, IRWT-YOLO achieves precision improvements of up to 15.5% on SIRSTv2, recall improvements of up to 14.5% on IRSTD-1k, and improvements of up to 21.0% on the 3rd Anti UAV dataset. Furthermore, we compare the IRWT-YOLO model with ten other state-of-the-art single-stage and two-stage object detection models and achieve the best performance in the results.
While IRWT-YOLO significantly enhances detection accuracy, the increased model complexity presents challenges for real-time applications. Future work will focus on developing lightweight architectures through techniques such as model pruning, quantization, and knowledge distillation, aiming to accelerate inference while maintaining high detection performance.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}