1. Introduction
The rapid development of the Internet of Things (IoT) and new communication technologies has driven the explosive growth of mobile devices, which has been accompanied by a wide variety of computationally intensive and latency-sensitive applications [
1,
2]. In [
3], Zhou et al. emphasize the significance of the convergence of communication, computing, and caching (3C) for future mobile networks, especially in the context of 6G. As an extension of cloud computing, Mobile Edge Computing (MEC) [
4] offloads compute-intensive tasks to servers deployed at the edge of the wire access networks, meeting the demand for low-latency communication and computing in an energy-saving and efficient manner [
5,
6,
7]. In [
8], Cai et al. analyze the challenges in collaborating among different edge computing paradigms and propose solutions such as blockchain-based smart contracts and software-defined networking/network function virtualization (SDN/NFV) to tackle resource isolation. In the early stages, fixed base stations (BSs) were mainly used as an edge server to provide computational services for mobile users [
9]. For example, in [
10], Zhang et al. equipped a Macro Base Station (MBS) with an edge server with better processing capability, and optimized the offloading of computing tasks in fifth-generation (5G) heterogeneous networks while satisfying the latency constraints. However, in practical situations such as complex environments, remote areas or disaster relief sites, terrestrial MEC systems with fixed locations usually suffer from severe performance degradation or even inoperativity due to communication obstruction [
11]. Fortunately, this dilemma is solved by unmanned aerial vehicle-enabled MEC. With the characteristics of high mobility, light weight, and no geographical constraints, we can utilize unmanned aerial vehicles (UAVs) as edge nodes to fulfill computational requirements across various scenarios [
12]. Wang et al. [
13] presented an iterative robust enhancement algorithm for a UAV-assisted ground–air cooperative MEC system, which minimized the system energy consumption by collectively optimizing the task offloading and flight trajectory of UAVs in a non-convex manner. To meet the low-latency demand for computational tasks in wireless sensor networks (WSNs), Yang et al. [
14] constructed a framework where edge UAV nodes carry intelligent surfaces (STAR-RISs) for computing offloading and content caching. By cooperatively optimizing UAV position, offloading strategy and passive beam-forming, they reduced the energy consumption of the system while achieving good convergence.
Nevertheless, due to the shortcomings of limited transmission power, low load capacity and few computing resources, traditional single or multiple UAVs cannot efficiently complete numerous multifarious tasks [
15]. In this case, UAV swarms are considered a viable solution. By managing and assigning tasks in cooperation under the leadership of the control unit, we can maximize energy utilization and minimize delay. With this advantage, UAV swarm-assisted MEC has become a popular trend in current research [
16,
17]. In [
18], an MEC system composed solely of UAVs is presented, in which member UAVs generate tasks, helper UAVs offload computation, and a header UAV aggregates the processed results. To mitigate the total energy expenditure of the UAV swarm, the authors optimized the communication channels, offloading objects and offloading rate through a two-stage resource allocation algorithm. Seid et al. [
19] considered a UAV cluster under an aerial-to-ground (A2G) network in response to emergencies, where member UAVs, under the coordination of header UCH, unload and compute independent tasks generated by Edge Internet of Things (EIoT) devices. Furthermore, a scheme based on deep reinforcement learning (DRL) for coordination computation offloading and resource allocation was proposed to control the total computation cost in terms of energy consumption and latency of EIoT, BSs, and UCH. In the research of Li et al. [
20], UAVs are allowed to dynamically gather into multiple swarms to assist in completing MEC. In order to maximize the long-term energy efficiency of the system, a comprehensive optimization problem addressing dynamic clustering and scheduling was developed, and a UAV swarm dynamic coordination method based on reinforcement learning is developed to attain equilibrium. To match mobile devices and plan UAV trajectories, Miao et al. [
21] put forward a global and local path planning algorithm based on ground station and onboard computer control in the framework of UAV swarm-assisted MEC task offloading, which minimizes the energy loss of global path planning for the UAV cluster while maximizing access and minimizing task completion delay. The issue of computational offloading and routing selection of UAV swarms under the UAV-Edge-Cloud computing architecture was highlighted in [
22], in which the authors developed a polynomial near-optimal approximation algorithm using Markov approximation techniques [
23], driven by the goal of maximizing the throughput while minimizing the routing and computational costs. To summarize, the research on UAV- or UAV swarm-assisted MEC for task offloading and resource allocation has been fully launched, but it is more reflected in scenario transformation and method update. In fact, the computational performance is related to the task size. Due to the temporal or spatial correlation of the tasks, the raw data generated by the user usually contain duplicates [
24], which causes a waste of computational time and resources. Thus, it is necessary to perform preprocessing, such as data compression, before task offloading to reduce the burden of the MEC and speed up the task completion [
25,
26]. Cheng et al. in [
26] investigated a scenario where a single UAV serves multiple wireless devices. The block coordinate descent (BCD) method is adopted to decompose the energy minimization problem into several subproblems for solution.
As an important field of modern information technology, data compression encodes data while retaining useful information, with the aim of reducing the size of data during storage and transmission [
27,
28,
29]. Typically, data compression is categorized into lossless and loss compression. Lossless compression maintains the integrity of the data, i.e., the decompressed data match the original data exactly, and loss compression sacrifices tiny details that are difficult for the human brain to perceive in order to achieve a higher compression ratio [
30,
31]. In the practical application of MEC, research on data compression technology has already made some progress. Han et al. [
32] considered introducing data compression to reduce offloading delay when using MEC to increase the computational energy of blockchain mining nodes, and then proposed a block coordinate descent (BCD) iterative algorithm to solve the problem of minimizing the total energy consumption of the system. In order to more accurately optimize the latency of the MEC system with multiple users and servers, Liang et al. [
33] performed lossless compression before task offloading and associated the reliability of edge servers with delay and energy consumption [
34], and then designed a distributed computational offloading strategy to make up for the shortcoming of centralized algorithms. Regarding the enhancement of data transmission efficiency in non-orthogonal multiple access (NOMA) MEC systems, Tu et al. [
35] proposed a partial compression mechanism, which allows users to send tasks to the BS in two ways: lossless compression followed by offloading, and direct offloading without preprocessing. Ultimately, this approach achieved a good effect. Ding et al. [
36] designed a multi-BS intelligent MEC system for the power grid, which utilizes two-level compression to ensure energy saving. Specifically, the small BSs receive information collected and losslessly compressed by MDs, and then transmit it to the micro-BS for processing after applying the same compression method. So far, it can be seen that MEC services benefit greatly from data compression strategies. Since the transmission of tasks typically consumes more energy than computation, data compression techniques are more advantageous in situations where the onboard energy budget is limited, especially in UAV swarm-supported MEC systems.
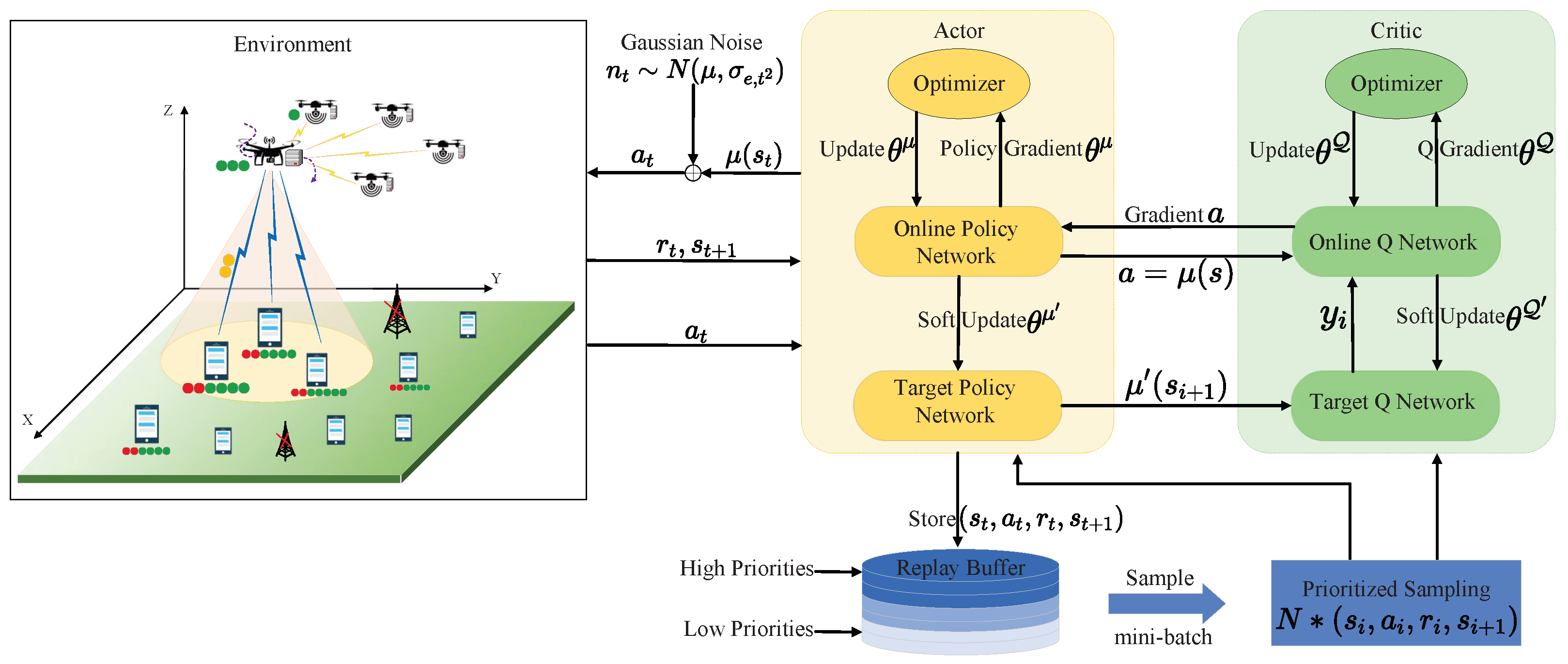
In this manuscript, we study the task offloading strategy of an MEC system that incorporates UAV swarms and data compression. The considered scenario focuses on the abnormal situation of BSs, mainly including one head UAV (USH), several member UAVs (USMs), and some randomly scattered user equipments (UEs). Since both the energy reserves and the processing capabilities of the edge servers carried are higher than those of the USMs, the USH can fly close to the UEs and offload tasks exceeding their capacity, then redistribute a small portion to the USM. In the process of data transmission, orthogonal frequency division multiple access (OFDMA) technology is employed to improve communication efficiency. To save communication bandwidth and maintain the value of the data, UEs first perform lossless compression on the calculated data, and the USH performs the corresponding decompression operation. Next, we formulate the task unloading strategy to the problem of minimizing the total energy and time expenditure, and adopt the Markov decision process model (MDP), the preferential experience playback mechanism (PER) and DRL to optimize the resource allocation, unloading rate and data compression ratio. Finally, simulation experiments are built to demonstrate the advantages of the proposed deep deterministic policy gradient offloading scheme with a prioritized experience replay mechanism (PER-DDPG) in saving system energy consumption, reducing latency and improving resource utilization efficiency. The main contributions are summarized as follows.
An MEC system with multi-user and multi-auxiliary co-existence (e.g., UAV swarm, task offloading, and lossless data compression) is proposed, in which UAVs can be classified into USH and USM according to their functional differences. Through a detailed analysis of task transmission, USH movement, computation execute and onboard energy, etc., an optimization problem of collaborative task offloading and data compression was formulated.
The optimization issue is modeled as MDP, and the action space, state space, and reward function are tailored to the specific requirements of the UAV swarm-enabled MEC system. Then, the deep deterministic strategy gradient (DDPG) algorithm in DRL is adopted to solve this issue, thus saving the delay and energy consumption during offloading. Furthermore, preferential experience replay is introduced into the DDPG algorithm to improve the efficiency of experience replay and speed up the training process, which increases the stability of the training process and is less sensitive to the changes of some hyperparameters.
Extensive numerical simulations are carried out to verify the convergence, stability and effectiveness of the proposed algorithm. As the total number of tasks increases, the proposed algorithm can obtain a lower cumulative system reward than other baseline comparison algorithms. In addition, compared with the non-compressed scheme, the compressed scheme can better save system costs and reduce the system delay and energy consumption when there are more user tasks.
The remainder of this manuscript is structured as follows.
Section 2 outlines the system model and formulates an optimization problem to minimize system energy usage and delay.
Section 3 builds the MDP model and proposes the PER-DDPG offloading algorithm to solve the above problems. In
Section 4, the performance of our proposed scheme is shown and compared with other schemes. Finally, we give the conclusion and future work in
Section 5.
2. System Model
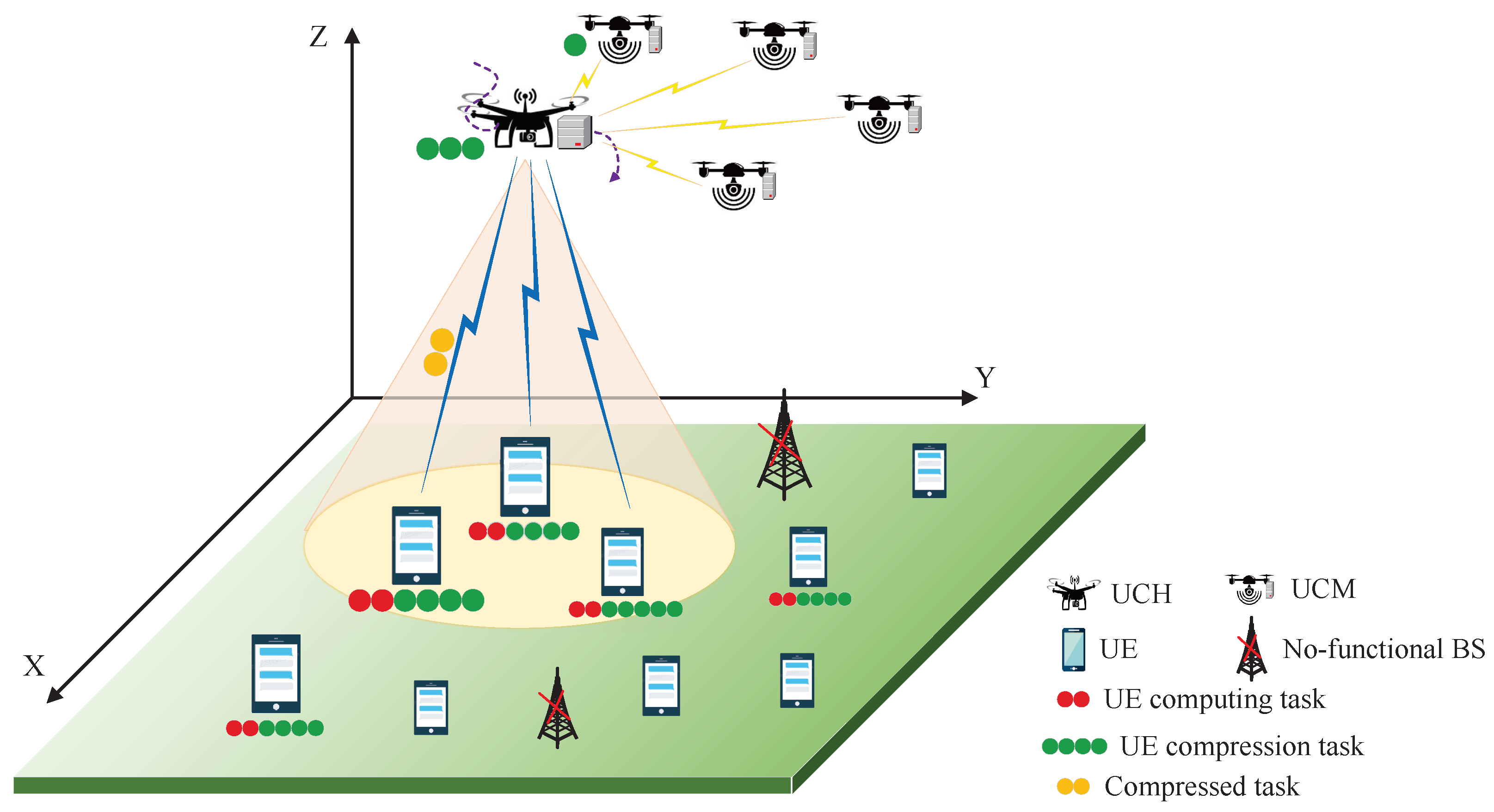
We consider an MEC network architecture enabled by a cluster of UAVs, as illustrated in
Figure 1, which mainly comprises
K UEs and
N UAVs. The UEs are arbitrarily scattered throughout a rectangular area on the ground, and always generate computational tasks that are too large for them to handle. In this case, an aerial UAV swarm containing a USH and several USMs can provide support. The USMs are randomly distributed within a 300 m radius around the USH while maintaining a minimum separation distance to ensure collision avoidance, where the USH selects the nearest USM for task offloading based on the shortest-path principle. Compared to USM, USH has more processing power, so USH is responsible for establishing a communication link with the UE and offloading most of the computational task, then assigning a limited number of tasks to the USM and keeping the rest to itself. Moreover, to optimize network transmission, reducing both time delay and energy expenditure, and ensure the accuracy and completeness of the computation results, it is necessary to implement a lossless compression technique on UE and then decompress it accordingly at USM. Let
and
denotes the set of UEs and USMs. To facilitate the analysis of the dynamic changes of the system, we utilize quasistatic network scenarios to model and discretize an observation period
D into
T slots with equal length
, indexed by
.
2.1. Data Compression
Assuming that the computational tasks generated by the UE k in time slot t are , where and represent the total amount of data to be processed and the CPU cycles consumed by , respectively, while the proportion of the local computation data to the total task is , then the amount of computation data that USH and USM must complete together is expressed as .
In order to prevent the loss of information contained in the computing tasks, and also to reduce the resources consumed by data transmission, it is necessary to use lossless compression technology on the UE side. Correspondingly, when the USH completes the offloading, the task reconstruction is performed first and then the computing is carried out. We use a continuous variable
to represent the compression ratio of the lossless compression algorithm adopted by UE, where
is the maximum compression ratio considering the network requirements, then the amount of data sent by the UE
k to the USH is reduced to
. As given in [
26,
37], the CPU cycles required to compress 1 bit of the original task can be approximated as
where
is a positive constant hinge on the lossless compression technique. Let
stand for the computing capability of UE
k in time slot
t, then the delay and energy expenditure due to the implementation of compression are derived by
where
is the computational efficiency of
, while we assume that each UE belonging to
has the same
. In addition, data decompression is much easier than compression, and the resulting latency is much smaller, so we can reasonably ignore it [
26,
38].
2.2. Task Transmission
Defining a 3D coordinate system with the ground as the reference plane, the location of UE k in time slot t is indicated by . At this point, the coordinates of USH and USM n are and , respectively, where and H is the current height of USH and USM relative to the ground.
2.2.1. Communication Between UEs and USH
Considering the impact of obstacles such as buildings, cars and terrain on radio propagation, we model the communication channel between UEs and USH as a superposition of the path loss of line of sight (LoS) and non-line of sight (NLoS) with different probabilities of occurrence. Let
f and
c represent the carrier frequency and the speed of light, while
and
denote the average additional attenuation, then the path loss
and
for LoS and NLoS at time slot
t are expressed as
where
is the distance from UE
k to USH, and can be acquired by
Next, the probability of existing LoS and NLoS connections between UE
k and USH can be calculated by
where
a and
b are variables that hinge on the operating environment. So far, the average path loss between UE and USH is formulated as
In order to avoid interference between channels, an orthogonal access scheme is used for both uplink and downlink communications. Assuming that the bandwidth resources allocated by USH for each UE are
B, and the noise power of the communication link is
and
, respectively, the wireless transmission rate of data between USH and UE
k at time slot
t is denoted as
Notably, our proposed framework employs a large-scale fading model that achieves analytical tractability. For enhanced modeling precision, the system accommodates potential integration of small-scale fading components, particularly Rayleigh and Rician fading variants, as well as advanced path loss modeling techniques [
39].
2.2.2. Communication Between USH and USMs
As part of the swarm, both USH and USMs communicate and compute in the air at height
H, which can be approximated as the presence of only LoS components. If the communication bandwidth provided by the USH for each USM is
B, the data transfer rate between USM
n and the USH can be denoted as
as long as it satisfies
, where
and
represent the data transmission power of the USH and the average channel power gain at a reference distance of 1
m, respectively.
2.3. USH Movement
The location of USH at the current time slot
t is known to be
,
, then after USH has flown a time slot of length
with uniform speed
, its location information is changed to
, where
is the angle formed by the projection of
in the horizontal plane with the
x-axis and satisfies
. If we use
to denote the maximum flight speed that USH can achieve, there is the following constraint:
It is important to note that the USH must avoid collisions with any USM during flight. To ensure safe operation within the same horizontal plane at a fixed altitude, we define a maximum distance threshold
between the USH and USM. External obstacles (e.g., buildings) are not considered in this study, as UAVs are assumed to operate at a sufficient height to avoid interference from ground-based objects.
To ensure that USH can smoothly offload the computational tasks generated by UEs, the UEs must be within the coverage area of USH. Assuming that the coverage area of USH is a circle with radius
, and using
to denote the maximum coverage angle of USH at time slot
t, then we have
and
. Meanwhile, the location of UE
k must satisfy the constraints
2.4. Task Execution
In the MEC system proposed in this manuscript, UEs, USH and USMs jointly complete the computing task. For each
, USH is preset to establish communication with only one UE or USM. Let
indicate the connection status between the UE
k and
, and
indicates that between the USH and USM
n, respectively, specifically as follows:
and with the constraints:
2.4.1. UE Implementation
As previously set,
represents the amount of CPU cycles needed for UE
k to perform the entire task independently,
is the proportion of computing tasks assigned to UE
k in the total,
is the computing capability of UE
k, and
is the computational efficiency of UE; we can obtain the time delay and energy consumption caused by local computing as follows:
In addition, the offloading of compressed data from the UE to the USH also generates time and energy consumption, which we represent as:
where
is the transmitting power of the UE
k.
2.4.2. USH Implementation
After the received task is decompressed, USH divides it into two parts; one is offloaded to USMs, and the other is left to calculate for itself. The corresponding delays of the former and the latter are expressed as
where
is the proportion of the task assigned to the USM
n by USH in the time slot
t and satisfies
, while
represents the computing capability of USH. Let
be the transmit power of USH in time slot
t; USH unloading and the calculation of the energy consumption can be expressed as
The USH performs calculations and communication while flying, so the flight time has no effect on the system delay but the flight energy consumption is a factor worth adding. We utilize
to denote the mass of the USH; the flight energy consumption of USH in time slot
t is
2.4.3. USM Implementation
Compared with UEs and USH, which both transmit tasks and calculate, USM has a relatively simple work type and only needs to execute computing task offloading from USH. Let
represent the computation capacity of USM; we can obtain the delay and energy usage of USM
n in time slot
t as
2.5. Problem Formulation
After determining the respective tasks, regardless of the UEs or USH, the modules used for computation and transmission are separated, which means that computation and transmission can be carried out simultaneously without interfering with each other; thus, the overall system delay is derived by
Regarding the overall energy usage of the system, it involves the components used by the UEs, USH and USMs for compression, communication and computation, expressed as
Our objective is to reduce the delay and energy usage of the entire system, which can be achieved by jointly optimizing parameters such as the compression ratio
, the association status during task offloading
and
, the offloading rates
and
, and the USH flight trajectory
M. Utilizing the wights
and
to indicate the degree of emphasis on delay and energy consumption, while
,
and
represent the energy possessed by UE, USH and USM in the system cycle, the optimization problem of the UAV swarm-enabled MEC system is formulated as
where Equations (
32b) and (
32c) constrain the flight speed, safe distance, coverage area and communication status of the USH, while (
32d), (
32e) and (
32f) limit the compression ratio and task offloading proportion. Moreover, the energy consumption requirements of UE, USH and USM are also specified by (
32g), (
32h) and (
32i).
4. Numerical Simulation
In this section, the offloading efficiency of PER-DDPG in the UAV swarm-assisted MEC system is verified by numerical simulation, and its performance advantage in the data compression scenario is demonstrated. The experiments use Python 3.7 and the TensorFlow1 framework to simulate the system environment on the Pycharm platform.
4.1. Parameter Settings
This study assumes a collaborative computing network consisting of 50 UEs, 1 USH, and 4 USMs within a rectangular area of 400 m × 400 m. The USH dynamically adjusts its flight path based on Line-of-Sight (LoS) and Non-Line-of-Sight (NLoS) communication conditions with the UEs, while the USMs remain fixed in position. The UEs’ positions are randomly updated in each time slot, and their assigned tasks are synchronously refreshed across the network. These parameters are primarily configured based on references from the literature [
26,
40]. Additional communication, computational and other related simulation parameters are detailed in
Table 1. The soft update coefficient
of the PER-DDPG algorithm is
, and the batch size for randomly sampled data is 64.
4.2. Convergence Analysis
To comprehensively evaluate the performance of the proposed PER-DDPG-based algorithm, this manuscript conducts a series of comparative experiments with three benchmark algorithms: the standard DDPG algorithm, the DQN algorithm, and the uncompressed PER-DDPG (PER-DDPG_Ncpr). The evaluation process in this manuscript consists of four main phases: (1) hyperparameter optimization for the PER-DDPG algorithm to identify the optimal configuration with superior convergence performance; (2) sensitivity analysis of delay and energy consumption metrics to determine the optimal weight coefficients; (3) performance comparison with the benchmark algorithms under identical experimental conditions; and (4) scalability analysis through varying data volumes and user numbers to assess the algorithm’s robustness.
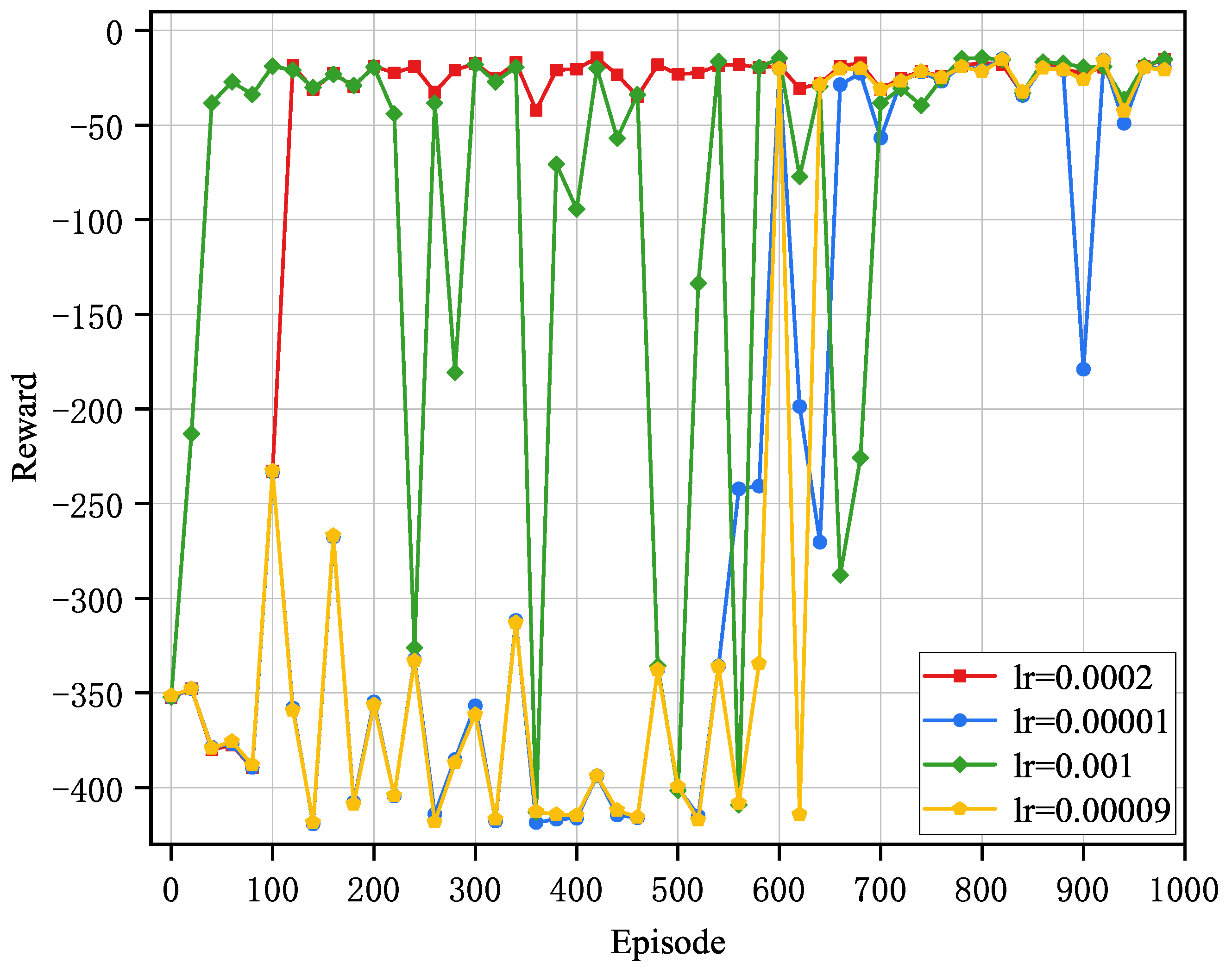
The impact of learning rate (
) variations on algorithm performance is demonstrated in
Figure 3. This study conducted systematic parameter tuning and comparative analysis, selecting a set of
demonstrating distinct performance characteristics for detailed evaluation, specifically
and
. The selection of an appropriate
significantly influences the training dynamics and ultimately determines the convergence behavior of the algorithm. As shown in
Figure 3, when using
of
,
, and
, the algorithm exhibits substantial oscillation amplitudes, slower convergence rates, and difficulties in stabilizing at optimal values. This phenomenon occurs because excessively large learning rates cause the algorithm to overshoot the optimal solution, while overly small learning rates result in insufficient updates and slow progress. In contrast, the
of
results in faster convergence, reduced oscillation amplitude, and superior computational offloading strategy performance, achieving the optimal reward convergence value. Consequently, the
in this study is established at
.
The appropriate configuration of the discount factor (
) significantly influences the algorithm’s convergence characteristics. A higher
value emphasizes long-term returns, potentially leading to overly conservative strategies and unstable performance in certain states. Conversely, a lower
value prioritizes immediate rewards, which may result in suboptimal long-term strategies and aggressive behavior, causing instability and fluctuations during training.
Figure 4 demonstrates the impact of varying discount factors, specifically
,
, and
, on algorithm performance. Experimental results indicate that when
is set to
or
, the algorithm produces substantial oscillation amplitudes and difficulties in achieving stable convergence. In contrast, setting
to
significantly reduces oscillation amplitude, thus achieving optimal convergence performance. Consequently, the
in this study is established at
.
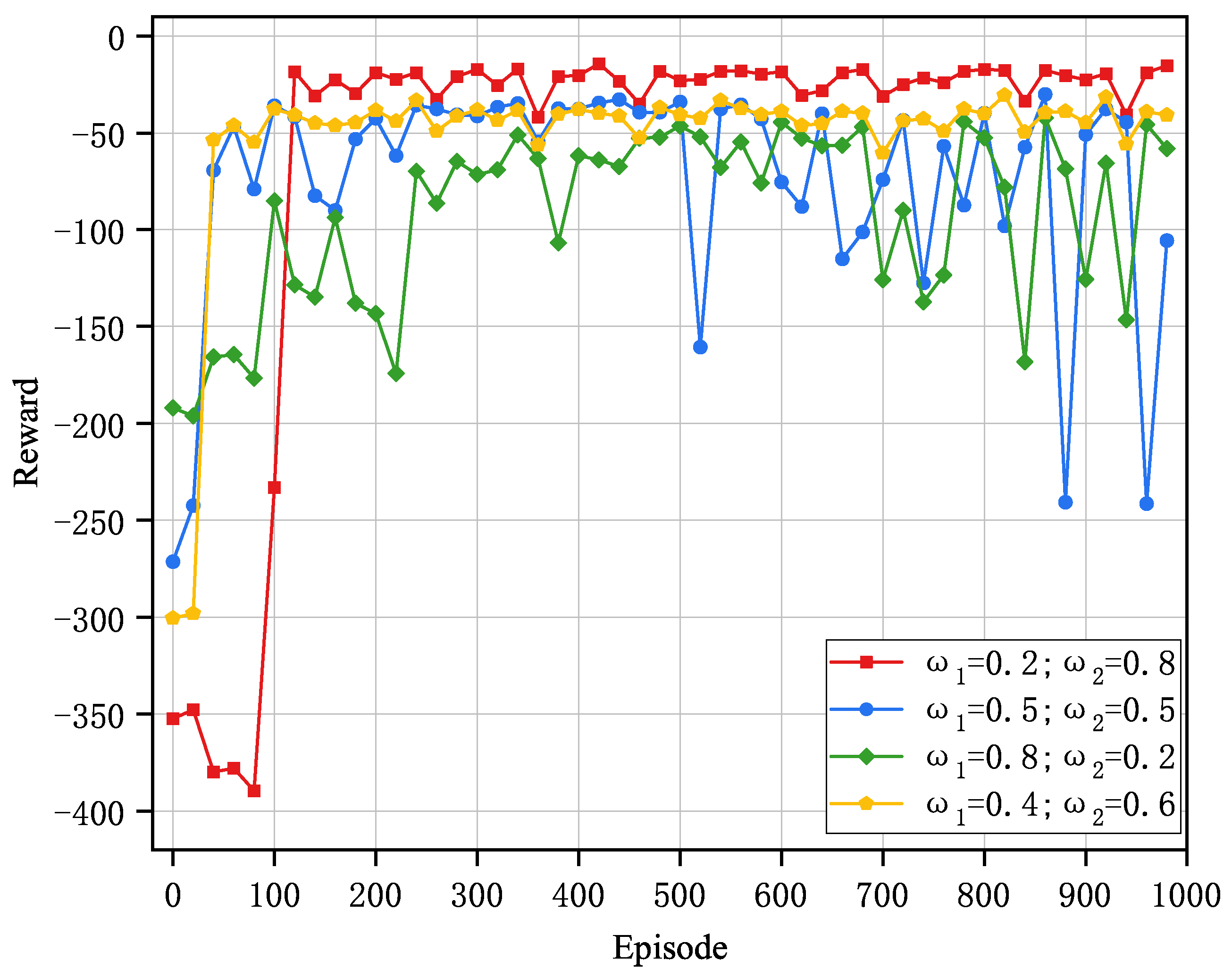
The setting of weighting values in a multi-objective optimization problem should account for the sensitivity of both energy consumption and delay. The system delay weights
and energy consumption weights
are set within the range of
. As shown in
Figure 5, it can be seen that the convergence of this algorithm is poor when the weights are evenly distributed. When the sensitivity is skewed towards delay, the optimal strategy cannot be obtained. However, when
,
, the algorithm’s convergence is more stable, and the optimal strategy can be achieved.
Based on the comparative analysis of the above experiments, the PER-DDPG algorithm demonstrates optimal performance metrics when , , , . Therefore, we will adopt this set of optimized hyperparameter configurations in subsequent experiments.
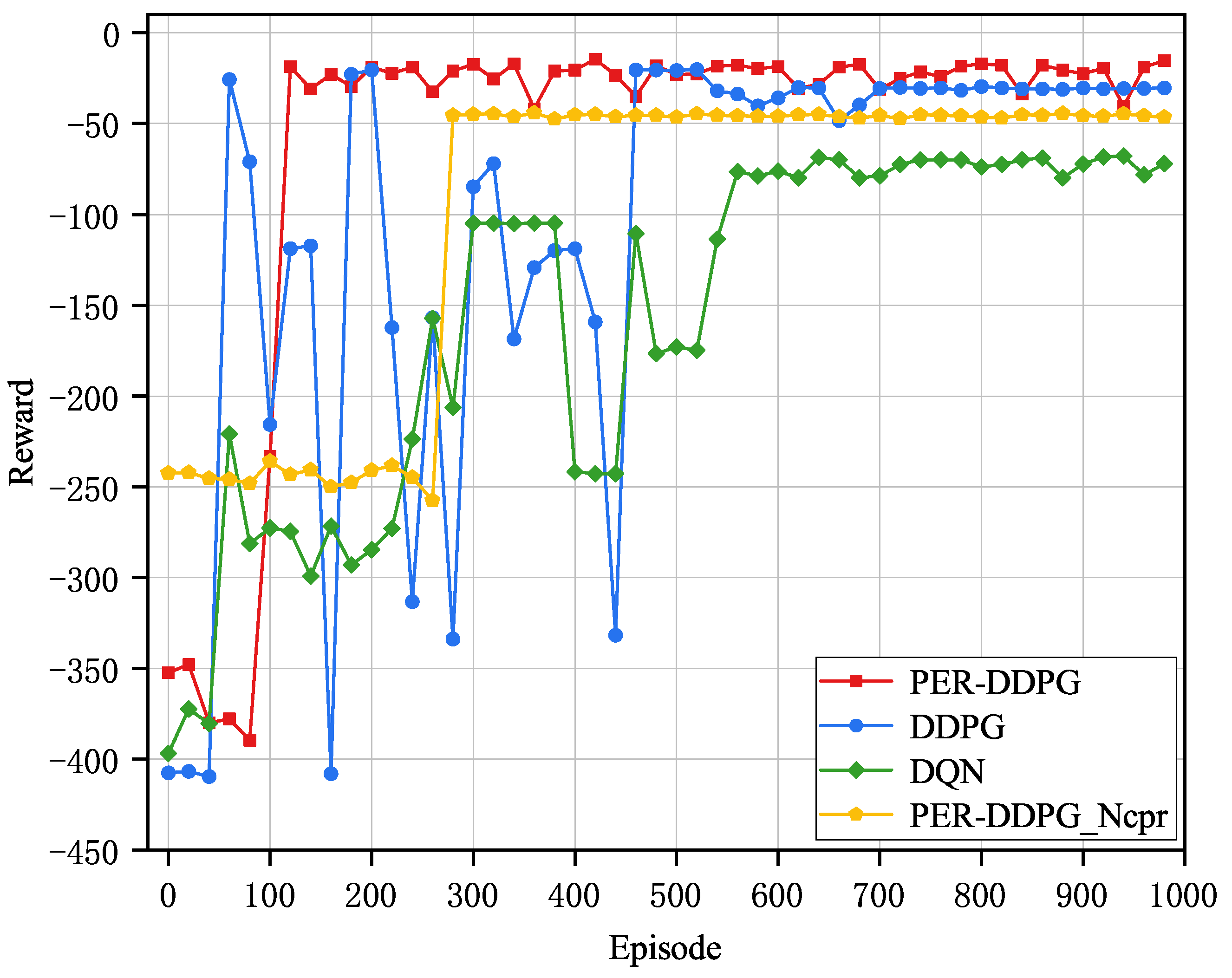
Figure 6 shows the reward convergence comparison graph of different algorithms. It can be observed that as the amount of training steps grows, the rewards of the four algorithms demonstrate a consistent upward trajectory, and eventually converge to a stable reward value, which indicates that the reinforcement learning agents are able to learn better strategies to minimize the latency and energy consumption of the UEs through interaction with the environment. The fluctuations observed in the performance curves are primarily caused by the dynamic nature of the optimization process, including the exploration–exploitation trade-off in DRL, the varying complexity of tasks, and the real-time adjustments in resource allocation and task offloading. These factors collectively contribute to the non-monotonic behavior of the algorithm’s performance over time.
Regarding convergence speed, the DDPG algorithm converges around 110 steps, while the other benchmark algorithms converge after 200 steps, which enables the proposed scheme to achieve superior convergence speed compared to the other algorithms. When considering convergence stability, the PER-DDPG_Ncpr algorithm exhibits the smoothest convergence, followed by the PER-DDPG algorithm. This is because the PER-DDPG_Ncpr algorithm has a smaller action space, which effectively reduces the policy search space and improves learning efficiency. Additionally, the DDPG algorithm solves the constraints of DQN in discrete action space through deterministic policy and policy gradient updates, and is suitable for solving continuous action space problems. In terms of overall performance, the PER-DDPG algorithm adopted in this manuscript achieves the highest reward and the smoothest convergence. This is attributed to the introduction of PER in PER-DDPG, which samples experiences based on their importance. This improves learning efficiency and sample utilization, further optimizing the algorithm’s performance in complex environments.
4.3. Performance Comparison
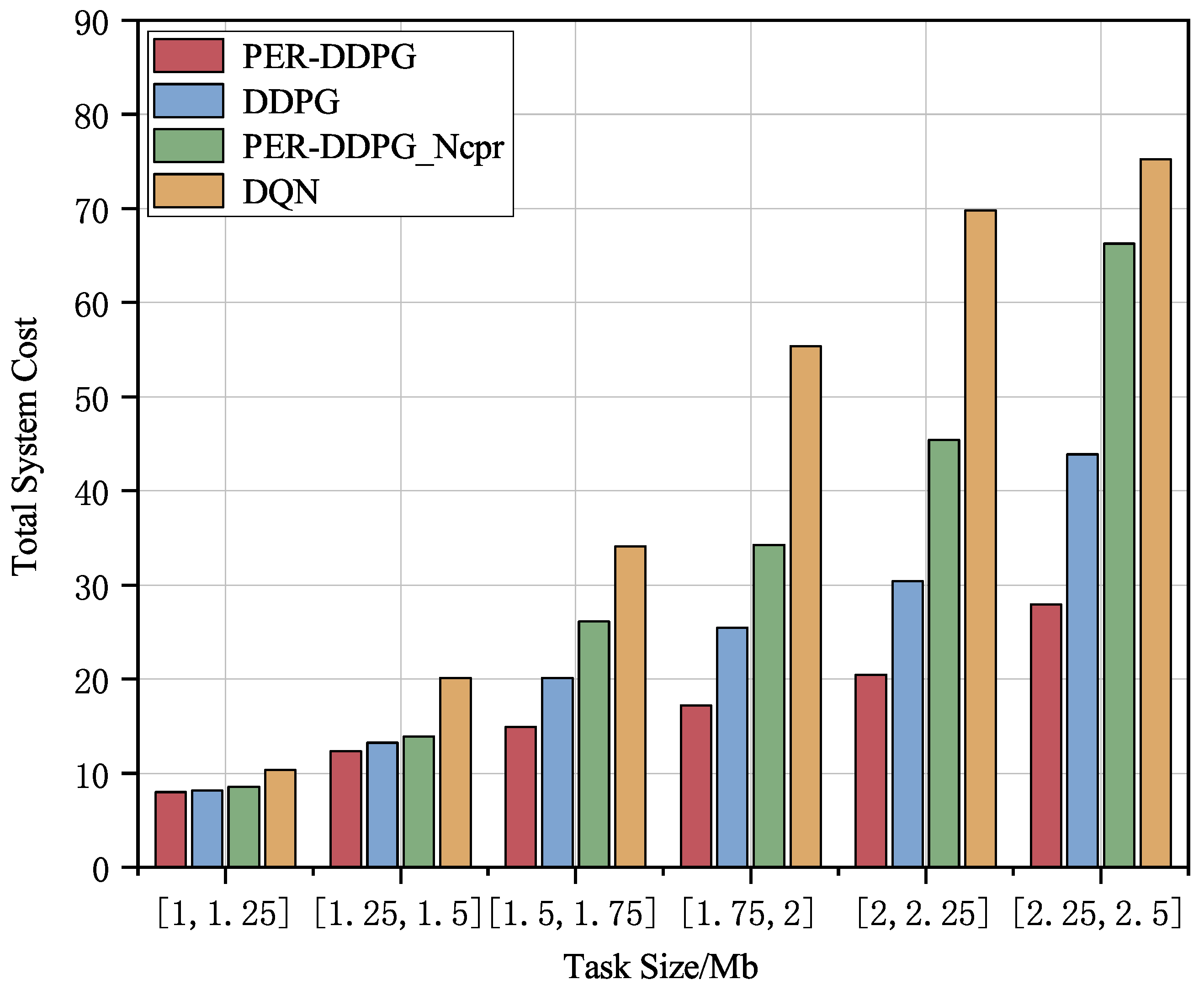
The performance of different algorithms under varying task volumes is compared in
Figure 7. We can see that when the task data volume increases from
Mb to
Mb, the proposed algorithms result in the lowest total delay and energy usage in the system. Compared to PER-DDPG_Ncpr, DDPG, and DQN algorithms, there is a minimum reduction of
,
, and
in total latency and energy consumption, respectively. This demonstrates that the approach explored by the proposed algorithm delivers better results than the other three baseline algorithms. Additionally, the adoption of the data compression technique significantly lowers the overall energy usage for users, and the benefits of data compression become more pronounced as the task data size increases.
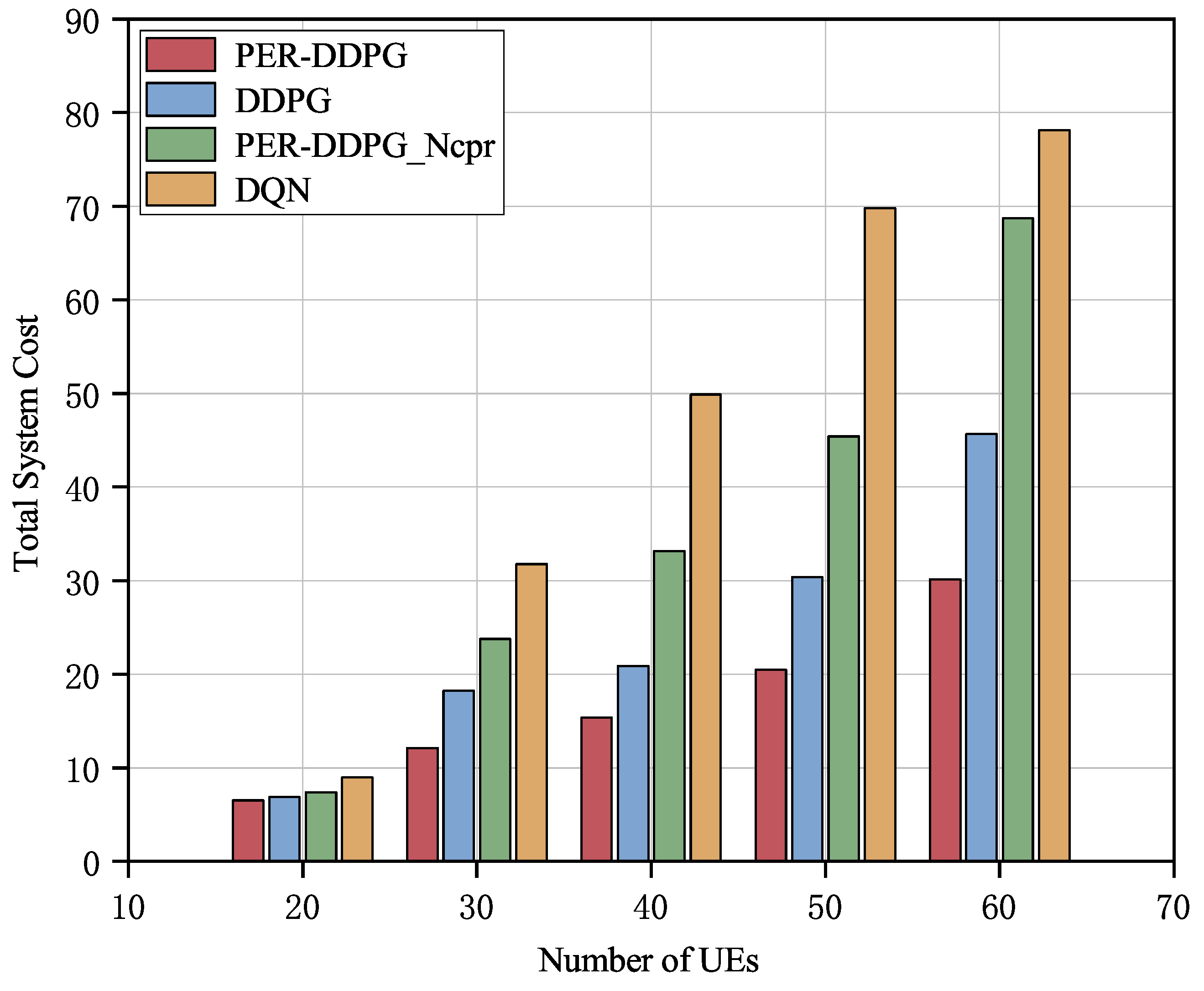
Figure 8 shows the system total cost and the relationship between the amount of UEs. With a growing number of UEs, the total energy usage exhibits a rising trend. This is primarily due to two factors: the increase in the total system cost caused by the growing number of UEs, combined with the limited communication resources of the system, which leads to resource competition among terminals and further increases the system cost. In contrast to the other three algorithms, the approach used in this article is able to allocate the system resources more rationally, and the total cost is always lower. For example, when the number of UEs is 50, the total system cost is reduced by at least
,
, and
compared to PER-DDPG_Ncpr, DDPG, and DQN algorithms, respectively.
Based on the above numerical analysis, the PER-DDPG algorithm introduced in this study demonstrates superior performance compared to the other three algorithms. By comprehensively optimizing task offloading, resource allocation, and data compression ratio, the algorithm can select the optimal strategy to achieve a relatively low maximum system processing cost.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}