In order to evaluate the performance of the maneuver strategy solving method proposed in this paper, firstly, the parameter sensitivity analysis of the MMPA is carried out and the algorithm performance comparison experiments are implemented; secondly, six types of initial scenarios are set up to conduct the air combat simulation; and finally, the simulation results of the MMPA are statistically analyzed and discussed.
4.2. Air Combat Simulation
To test the effectiveness of the MMPA in the autonomous maneuver decision-making of UCAVs, five different initial scenarios are set up, and air combat simulation experiments are conducted based on the above scenarios, respectively. According to the settings of the initial positions of the two UCAVs, the initial confrontation scenarios are classified into the following five categories, namely, neutral, offensive, oppositional, defensive, and parallel. In addition, to test the effectiveness of the variable weight strategy for the superiority functions based on fuzzy inference in UCAV autonomous maneuver decision-making, one head-on scenario is selected based on the setup of the initial positions of two UCAVs, and air combat simulation experiments are conducted.
In the air combat confrontation scenario, the red UCAVs stand for the attacking aircraft, the blue UCAVs denote the target aircraft, and the green curves are the missile flight trajectory. The performances of both sides’ aircraft platforms and their mounted weapons are the same. The attacking aircraft and target aircraft always know each other’s position information. F-16 models are used as aircraft platforms, and their mounted weapons are two close-range air-to-air missiles. The maximum airspeed of the aircraft platform is 360 m/s, and the minimum is 82 m/s. The missile attack distances are dynamically solved by the fire control systems of both UCAVs. After the missile is launched, it approaches the target using proportional guidance methods. The decision time is
, and the simulation sampling time
. The parameter settings of the MMPA and its comparison methods, the MPA, DE, PSO, and HHO, are shown in
Table 2.
Case 1 is used to test the effect of the dominant initial situation on the autonomous maneuver decision-making of the UCAV. In Case 2, the MMPA and MPA are used for the maneuver decision-making methods of both sides, and the effectiveness of the modified algorithm is tested through air combat confrontation simulation experiments. Cases 3, 4, and 5 are used as comparison experiments, in which the maneuver decision-making methods used by the red UCAV are both the MMPA, and the blue UCAV are DE, PSO, and HHO, respectively. Case 6 is used to test the superiority of the variable weight strategy based on fuzzy inference for the superiority functions over the strategy that the weights of superiority functions are fixed. In Case 6, the maneuver decision-making methods employed by both sides are the MMPA. In the process of solving the optimized maneuver control variables, the red UCAV adopts the superiority function variable weight strategy to calculate the fitness values, while the blue UCAV adopts the superiority function fixed weight strategy. The detailed parameter settings for the six initial confrontation scenarios are listed in
Table 5. In this section, the typical adversarial simulation trajectories for the six types of initial scenarios are described, and the results are preliminarily analyzed. The repeated experiments and a discussion of the results are presented in
Section 4.3.
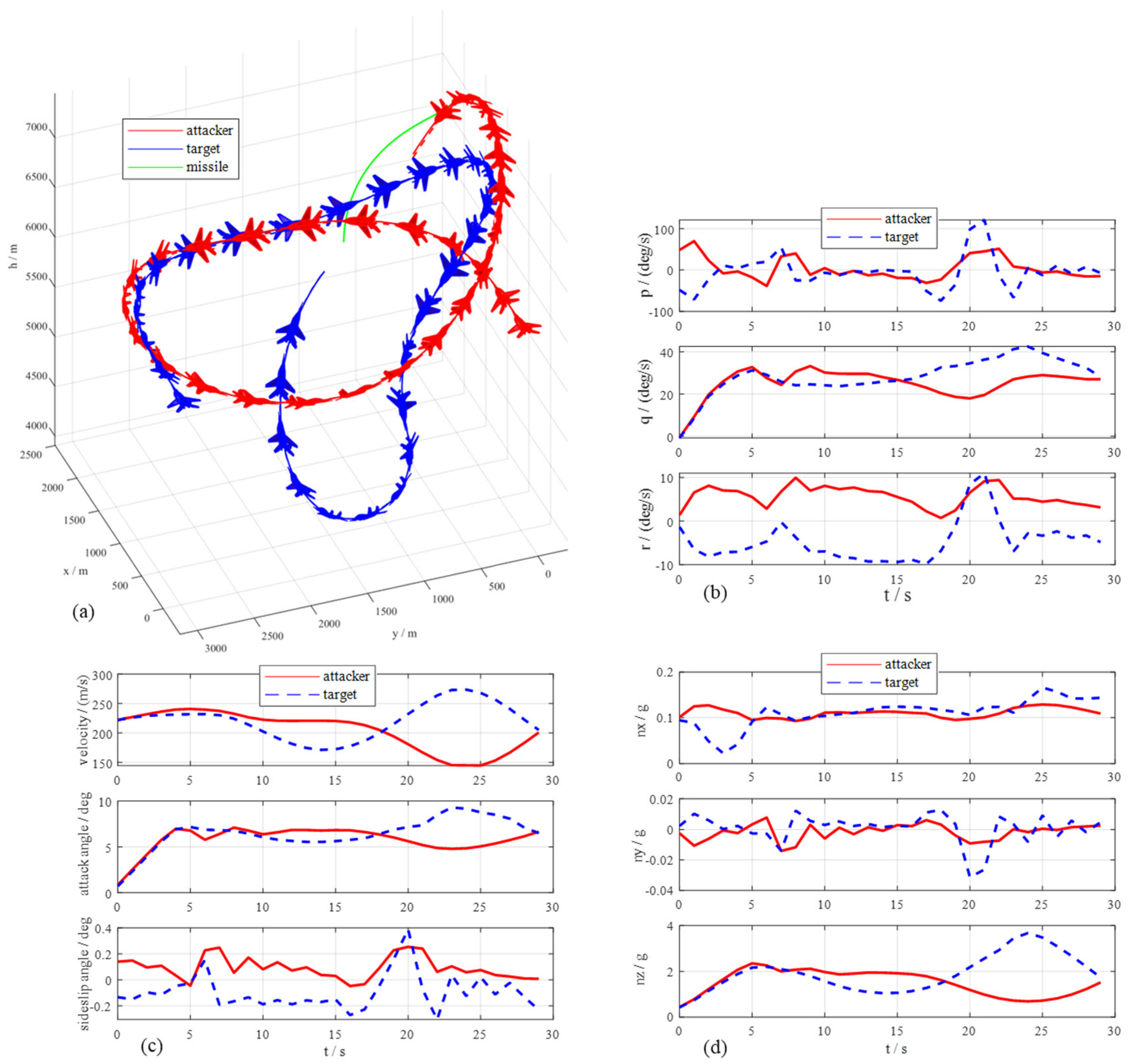
Case 1: Neutral scenario
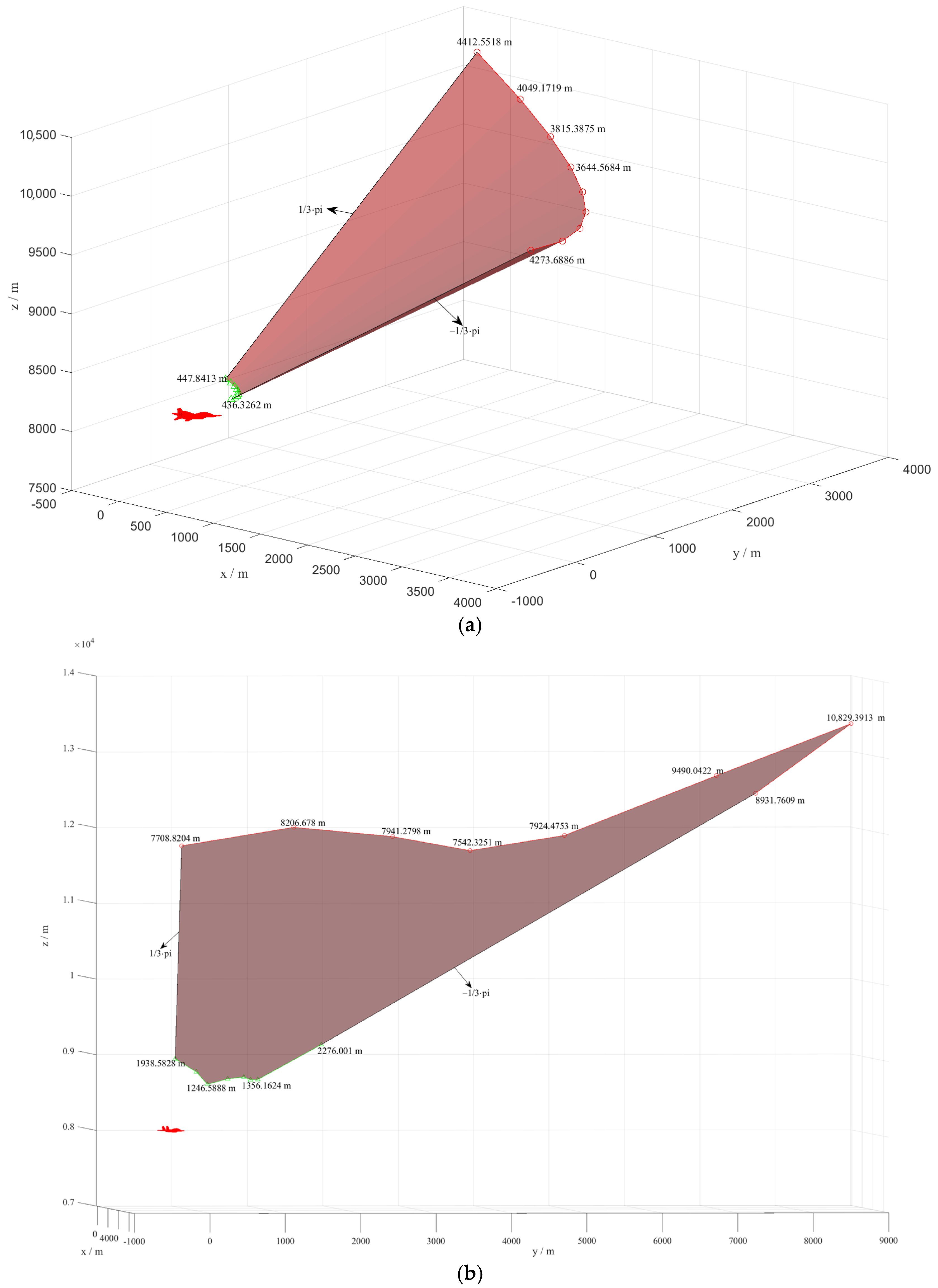
The initial heading angles for red and blue are 0° and 90°, respectively. Both sides are in orthogonal positions and have the same initial altitude and flight velocity. At the initial moment, both UCAVs use the MMPA to solve the optimized maneuver control variables. The blue side presses the slope to hover to the left to disrupt the red side’s stable tracking condition, making it impossible for the red side to satisfy the missile launch conditions. At 2 s, the red presses the slope to turn left, and by controlling the longitudinal overload, the red achieves faster acceleration. At 8 s, the red’s velocity is greater than the blue’s, and by obtaining a greater normal overload, it allows for greater pitch angle rates and achieves a faster turn for the red than the blue’s. During 10 s to 15 s, the red attempts to acquire stable tracking of the blue to reach the situation that the red is directly behind the blue by implementing a greater turn angle rate than the blue to achieve the missile launch conditions and then shoot down the blue side. At 16 s, the blue attempts to escape the passive situation of being tracked by the red through increasing velocity and changing head pointing. At 17 s, as a result of turning at a higher rate, the blue’s normal overload has reached 6 g. At 18 s, the blue is within the red’s missile attack zone, and the red launches a missile. At 20 s, the relative distance between the missile and the blue side is less than 100 m, and it is judged that the target has been successfully hit by the missile. At last, the red side wins the air combat, and the simulation is terminated.
As can be seen from
Figure 13b, the values of the roll angular rates are larger than those of the pitch and yaw angular rates. The change curves of the velocity, attack angle, and sideslip angle are shown in
Figure 13c. At the beginning of the confrontation, the red side starts to increase its velocity and maintains a faster acceleration. At 6 s, the increase rates of the red side’s velocity slow down. At 12 s, the blue side achieves a rapid increase in velocity by increasing the longitudinal overload, and at 14 s, the magnitude of its velocity exceeds that of the red side. In air combat confrontation, the increase in flight velocity indicates the rise in air combat energy. The values of the sideslip angles are small, and both sides keep the values of the sideslip angles fluctuating around zero. The change curves of the overload are shown in
Figure 13d. The overload is a key parameter to determine the maneuver performance of UCAVs. Due to the intensity of the close air combat confrontation, both sides may reach large values of overload to change the head pointing faster and maintain a large flight velocity. Taken together, the above analysis shows that the MMPA is effective in the autonomous maneuver decision-making of the UCAV, and due to the initial angle advantage of the red side, the red side wins the air combat finally.
Case 2: Offensive scenario
Both the red and blue sides have an initial heading angle of 0°. This means that both sides are flying in the same direction at the starting point, and the red is in an attacking position. Both sides have the same initial altitude and flight velocity. The red UCAV uses the MMPA to solve the optimized maneuver control variables, and the blue UCAV employs the MPA. At the initial moment, the red UCAV is at the right rear of the blue UCAV.
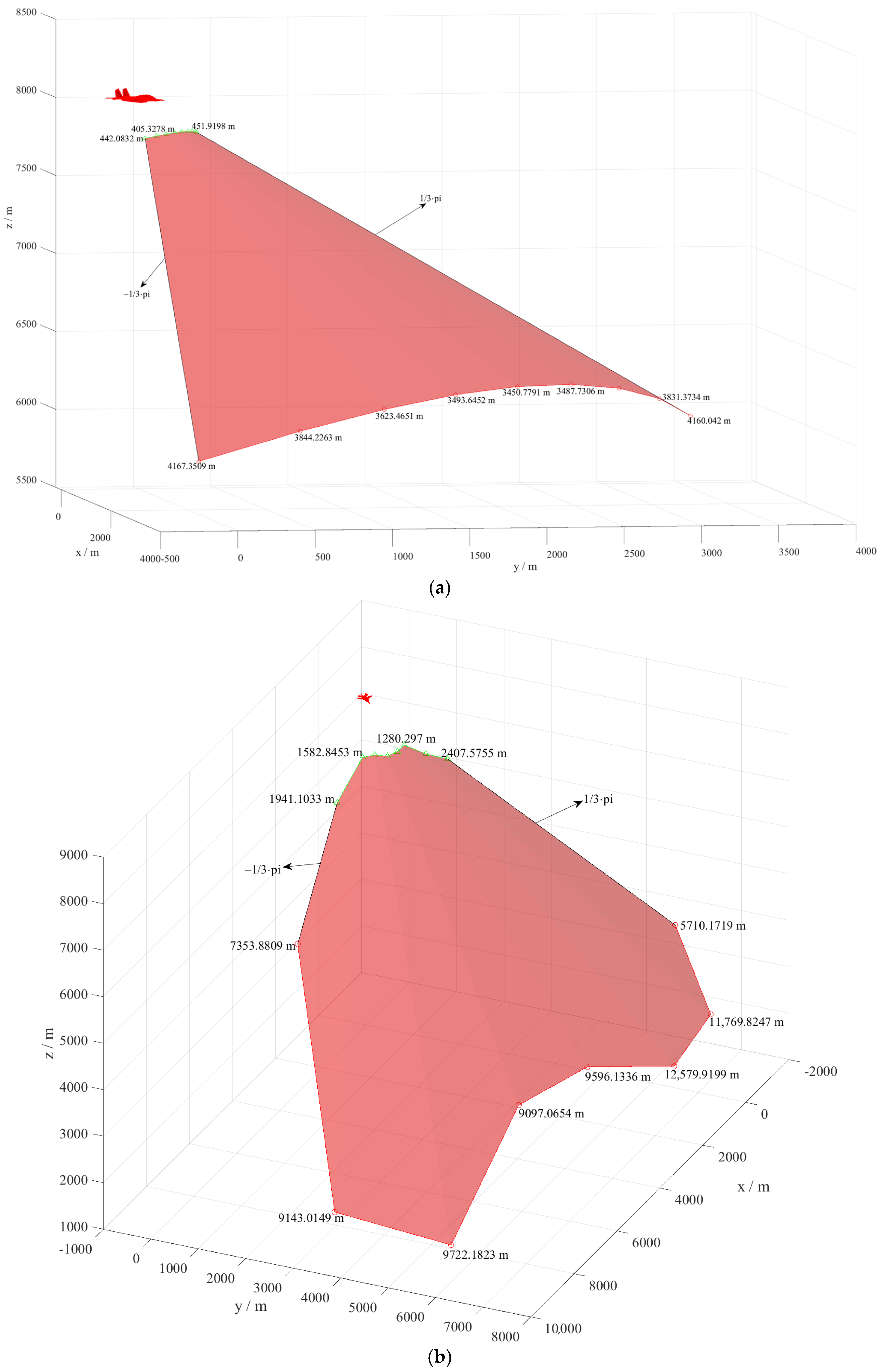
At 2 s, the red swings to the left to stabilize the tracking conditions, while the blue swings to the right and lowers the altitude to disrupt the red’s stabilizing tracking conditions. In response to the blue’s circling maneuver to the lower right, at 4 s, the red flattens out. From 5 s, the red presses the slope to the right and lowers the altitude to achieve stable tracking conditions. At 10 s, the red achieves a faster turn with larger pitch angle rates. During 11 to 32 s, both sides’ UCAV velocity and normal overload change patterns are similar. However, the red’s pitch angle rates are always larger than the blue’s, so the red follows the blue closely in the circling maneuver, and the red completes the head-turning more quickly. At 34 s, the blue increases the longitudinal overload to gain greater velocity. However, due to the unstable flight state of the blue at that moment, its value of attack angle fluctuates around zero, and the blue’s velocity does not increase but rather decreases. At 35 s, the red completes the turning maneuver with greater turning angle rates than the blue. At 36 s, the blue is within the red’s missile attack zone, and the red launches a missile. At 40 s, the relative distance between the missile and the blue side is less than 100 m, and it is judged that the target has been successfully hit by the missile. At last, the red side wins the air combat, and the simulation is terminated.
The change curves of the roll, pitch, and yaw angular rates based on the body-fixed coordinate frame are shown in
Figure 14b. As can be seen from
Figure 14c, at the beginning of the confrontation, the blue side first starts to increase the velocity. At 8 s, the blue side’s velocity reaches a peak, and then the blue side’s velocity decreases for 9 s to 15 s due to the circling maneuver, which is accompanied by energy loss. At 8 s, the red starts to increase its velocity. At 14 s, the red reaches a peak velocity and then decreases its velocity due to maneuvers. When both UCAVs maneuver to reduce their altitude, their velocity increases. The values of the sideslip angles are small. The overload variation curves are shown in
Figure 14d. From 1 s to 30 s, the overload change patterns of both UCAVs are similar because they are performing similar circling maneuvers. At 34 s, the change rules of the overload curves of the blue side are not consistent with those of the red side because the blue side tries to increase the longitudinal overload to gain greater velocity as well as to achieve the purpose of avoiding being attacked by the red side. In summary, in the offensive initial scenario, the MMPA assists the red UCAV with high accuracy to obtain optimized maneuver control variables continuously, and the red side finally succeeds in occupying a favorable attack position and wins the air combat.
Case 3: Oppositional scenario
At the initial moment of the air combat confrontation, the heading angle of the red UCAV is 0°, and the blue UCAV is 180°. Both sides in the confrontation are in opposing positions, and they have the same initial altitude and flight velocity. The red UCAV uses the MMPA to solve the optimized maneuver control variables, and the blue UCAV employs the DE algorithm. The initial straight-line distance between the two sides is 14.14 km. At 2 s, both sides hover to the left with a pressure slope to point their heads toward each other and search for each other as soon as possible. During 5 s to 10 s, both UCAVs perform the climb accompanied by velocity and energy reduction. During 11 s to 18 s, the blue gains acceleration by increasing the longitudinal overload. However, in 11 s to 15 s, the red gains greater pitch angle rates by increasing the normal overload, which helps the red to complete the head-turning faster. In 17 s to 20 s, the blue increases the normal overload to achieve a faster turn. At 25 s, both UCAVs increase their velocity by increasing the longitudinal overload and achieve a faster turn by increasing the normal overload. At this point, both UCAVs have similar longitudinal overload change curves, but the change rates of the red’s normal overload are greater than those of the blue. The red side is trying to achieve a faster turn by increasing the longitudinal overload. Aiming at achieving a faster head pointing to the blue, the red has a normal overload value greater than 3 g at 28 s. From 25 s to 30 s, the red completes the circling maneuver faster than the blue due to the greater value of the red’s pitch angle rates compared to the blue. The red gains less energy loss; therefore, it has a greater velocity. At 28 s, the red’s velocity is 267 m/s. At 29 s, the red has maintained stable tracking of the blue, and the blue is within the red’s missile attack zone. Furthermore, the red has an energy advantage at this time, so the red launches a missile to attack the blue. At 31 s, the relative distance between the missile and the blue side is less than 100 m, and it is judged that the missile has successfully hit the target. At last, the red side wins the air combat, and the simulation is terminated.
As can be seen from
Figure 15b, the values of the roll angular rates and yaw angular rates fluctuate on axis 0. The change curves of the velocity, attack angle, and sideslip angle are shown in
Figure 15c. In the first half of the confrontation, the velocity change curves of both UCAVs are similar. In the second half of the confrontation, the acceleration of the red side is larger than that of the blue side. After the circling maneuver, the red side has greater velocity. The values of both sides’ sideslip angles keep fluctuating around zero. The overload variation curves are shown in
Figure 15d. The normal overload determines the turning performance of the UCAVs, and from 23 s to 31 s, the continuous circling maneuvers make the normal overload values of both UCAVs greater than 2 g. At 28 s, to complete the possession before the blue side, the red side has a normal overload value of more than 3 g. The results of this case show that the MMPA outperforms the DE algorithm in the autonomous maneuver decision-making of UCAVs. Compared with the DE algorithm, the MMPA has better flexibility, and the information prediction of the target is effective.
Case 4: Defensive scenario
Both the red and the blue have an initial heading angle of 180°. This means that both UCAVs fly in similar directions, and the blue has an initial positional advantage. The red UCAV uses the MMPA, and the blue UCAV uses the PSO algorithm to solve the optimized maneuver control variables. To attack the red side, the blue side reduces its altitude. To avoid being attacked by the blue, the red increases its altitude, converting the kinetic energy of the initial moment into potential energy. Between 1 s and 10 s, the velocity of the blue increases steadily, while the red’s velocity decreases steadily. Between 11 s and 20 s, by applying a greater normal overload, the blue makes a downward turn at a greater angular rate than the red, while the red makes a downward turn at a radius smaller than the blue. At 22 s, when the red discovers that the blue has changed out of the downward turn, by increasing its normal overload and implementing a greater pitch angle rate, the red quickly changes out of the downward turn as well. At 22 s, the normal overload of the red is greater than 5 g. To reduce the energy loss due to the fast maneuver, the red increases its longitudinal overload while performing the change out of the downward maneuver to keep its velocity stable. Between 25 s and 35 s, the blue climbs in altitude, then dives and maintains a pressure slope to turn left in an attempt to track the red. In 25 s to 35 s, the red performs a climb followed by a downward dive to destabilize the blue’s tracking and prevent it from meeting the missile launch conditions. At 36 s, the blue continues to hover to the left, and the red follows suit with a spin to the left. The red completes the maneuver faster because it has a smaller radius of rotation. At 48 s, the blue switches to level flight and then climbs to the right by pressing the slope. At 47 s, the red changes out of the circling maneuver and then climbs up to the left by pressing the slope. At 61 s, the blue maneuvers to the apex and attempts to continue to complete the second half of the maneuver to increase velocity and gain energy advantage. At 59 s, the red switches to level flight, followed by pressing the slope to the right, then transferring to a diagonal somersault maneuver. At 65 s, the blue is within the red’s missile attack zone, and the red launches a missile to attack the blue. At 69 s, the relative distance between the missile and the blue side is less than 100 m; it is judged that the missile has successfully hit the target. At last, the red side wins the air combat, and the simulation is terminated.
The change curves of the roll, pitch, and yaw angular rates based on the body-fixed coordinate frame are shown in
Figure 16b. The change curves of the velocity, attack angle, and sideslip angle are shown in
Figure 16c. The air combat confrontation is intense, and the UCAVs on both sides have large velocity variations. At 62 s, due to implementing the climb maneuver, the velocity of the blue side is less than 100 m/s but greater than the minimum 82 m/s. At 22 s, due to executing the fast dive maneuver, the maximum velocity of the red side is more than 340 m/s. The values of both sides’ sideslip angles keep fluctuating around zero for most of the time. At 65 s, the blue side’s sideslip angle fluctuates due to lateral overload. The overload change curves are shown in
Figure 16d. The close air combat confrontation is intense, and both sides have a fast rhythm shift between attack and defense. To achieve the head of both sides rapidly pointing to the target aircraft, the normal overload values are sometimes greater than 5 g. The air combat simulation results of this case show that the MMPA is more effective than the PSO algorithm in solving the optimized maneuver control variables of the UCAVs. Although the PSO algorithm increases the diversity of the selection of the UCAV maneuver control variables by setting the mutation probability as well as the crossover probability, the MMPA has a greater advantage in selecting the optimized maneuver control variables. Therefore, the red side UCAV has a greater probability of winning the air combat confrontation.
Case 5: Parallel scenario
Both the initial heading angles for red and blue are 0°. Both sides are in parallel positions and have the same initial altitude and flight velocity. The red uses the MMPA to solve the optimized maneuver control variables, and the blue uses HHO. At the initial moment, the red presses the slope to hover to the left to search for the blue. At the same time, the blue presses the slope to hover to the right to search for the red. At 7 s, the blue performs a climb maneuver. At 14 s, the blue climbs to the top, then flattens the plane and executes a downward dive. During the first half of the confrontation, the red side maintains a hover maneuver. At 15 s, the red side climbs up. After gaining a velocity advantage by diving, the blue side performs a right circle maneuver at 23 s to change the head pointing and attempt to steadily track the red side. At 23 s, the red reaches its peak, followed by a dive maneuver. The red finds the blue during the dive and meets the missile attack conditions. The velocity of the blue is reduced due to the high overload turning maneuver. In order to change the head pointing faster, the maximum normal overload of the blue is 3.6 g. At 26 s, the red side launches a missile. At 29 s, the relative distance between the missile and the blue is less than 100 m, and it is judged that the missile has successfully hit the target. The red side wins the air combat, and the simulation is terminated.
The curves of the roll, pitch, and yaw angular rate variation based on the body-fixed co-ordinate frame are shown in
Figure 17b. As can be seen from
Figure 17c, at the beginning of the confrontation, both sides hover steadily, with small fluctuations in the velocity values. At 7 s, the velocity of the blue is reduced due to the implementation of the climb maneuver. At 23 s, the velocity of the red reaches its minimum due to the conversion of kinetic energy into potential energy. The values of the sideslip angles on both sides keep fluctuating around zero. The change curves of the overload are shown in
Figure 17d. Based on the above analysis, compared with HHO, the MMPA has advantages in terms of the UCAV’s autonomous maneuver decision-making.
Case 6: Head-on scenario
The initial heading angle of the red side is 0°, and the blue side is 180°. Both sides are in a head-on position with the same initial altitude and flight velocity, and the initial distance of both UCAVs is 14.14 km. The maneuver decision-making methods of both UCAVs are the MMPA, and the red UCAV adopts a superiority function variable weight strategy based on fuzzy inference to calculate the fitness values, while the blue UCAV adopts a superiority function fixed weight strategy. According to the results of the fitness values, the maneuver control variables that make the fitness values the largest are selected as the output of the algorithm and used as the maneuver control variables of the corresponding UCAVs at the next moment. From 1 s to 6 s, both sides hover to the left by pressing the slope to search and find each other as soon as possible. At 7 s, the blue reduces the slope and switches to an upward climb accompanied by a small reduction in its velocity. At 7 s, the red also begins to climb. At 10 s, the red climbs to the top and then dives. The change curves of the velocity of both sides are similar for the first 9 s. At 13 s, the red climbs to the apex, followed by a dive. At 16 s, the blue ends the dive, and its velocity reaches a peak at that moment, which has a value of 250 m/s, followed by turning left through pressing the slope. At 17 s, the red exits the dive, and its velocity also reaches a peak at that moment, then maintains level flight. During the dive of the UCAVs on both sides, the red exits the dive with greater velocity than the blue due to the red implementing greater longitudinal overload values than the blue. At 17 s, the blue performs a turn with smaller normal overload values than the red. The turning maneuver causes a loss of kinetic energy for the blue, and its velocity reaches a minimum at 28 s, which is less than 150 m/s at that moment. At 19 s, the red is circling to the left by pressing the slope. At this time, the red completes the head-turning faster than the blue by applying a larger normal overload during the circling maneuver, with larger pitch angle rates and flight velocity. When the red completes the turn in the vertical plane, at 30 s, the red begins to circle horizontally to the left to search for the blue. At 29 s, the blue increases the normal overload to achieve a quick change out of the maneuver in the vertical plane. At 36 s, the red points its head toward the blue; the blue is within the red’s missile attack zone, and the red launches a missile to attack the blue. At 38 s, the relative distance between the missile and the blue side is less than 100 m, and it is judged that the missile has successfully hit the target. At last, the red side wins the air combat, and the simulation is terminated.
The change curves of the roll, pitch, and yaw angular rates based on the body-fixed coordinate frame are shown in
Figure 18b. As can be seen from
Figure 18c, at the beginning of the confrontation, the change curves of the velocity of both UCAVs are similar. During the subsequent maneuvers, the change curves of the velocity of both UCAVs are different because the change curves of their overload values as well as the pitch and yaw angle rate values are not the same. At 30 s, the velocity of the red side remains steady with a small increase. Between 30 s and 35 s, although the velocity of the blue has a large increase, its velocity is smaller than that of the red. At this point, the red has a velocity advantage, which creates the conditions for the red to quickly complete the occupation attack of the missile. The values of the sideslip angles are small. The overload change curves are shown in
Figure 18d. The change curves of the lateral overload on both sides are similar. From 11 s to 20 s, the longitudinal overload values of the red side are larger than that of the blue side, together with both sides performing similar maneuvers, so the velocity of the red side is larger than that of the blue side. Between 19 s and 35 s, the values of the normal overload of the blue side are smaller than the red, which results in the blue being slower than the red to complete the circling maneuver in the vertical plane. The air combat confrontation results of this case show that the superiority function variable weight strategy based on fuzzy inference helps to guide the red UCAV to choose superior maneuver control variables. Combining the MMPA method with the above strategy can help the red UCAV win the air combat.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}