4.1. Experimental Setting
Implementation details.
Our framework is implemented in PyTorch 1.10.0 utilizing the Adam optimizer with the following parameters:
= 0.9;
= 0.999; weight decay
. The models are trained for 100 epochs, starting with an initial learning rate of
, which is gradually reduced to
using cosine annealing [
60]. We set the batch size to 8, with a fixed patch size of 128. The trade-off weights are
= 0.5,
= 0.1 and
= 0.1.
For the teacher networks, we select three state-of-the-art image restoration models: Restormer [
11], Uformer [
12], and DRSformer [
13]. These models are chosen for their exemplary performance across various image restoration tasks, providing robust supervisory signals for the student networks. The corresponding student models are named Res-SL, Ufor-SL, and DRS-SL, respectively. These student models maintain a similar architectural structure to their teacher counterparts but with fewer transformers and reduced feature dimensions in each encoder/decoder block, resulting in significantly lower computational complexity.
Table 1 presents the hyper-parameters of both the teacher and student models, detailing the number of layers and feature dimensions for each encoder/decoder block. Additionally, the table highlights the reductions in model complexity achieved through our proposed SLKD framework. These reductions include decreases in the FLOPs, inference time, and number of parameters, demonstrating the effectiveness of SLKD in compressing image restoration models.
By significantly lowering computational requirements without compromising performance, our student models achieve an optimal balance between efficiency and restoration quality, making them highly suitable for real-time applications on drones operating in dynamic environments.
Datasets. We conduct knowledge distillation experiments using five synthetic datasets and three real-world datasets, each tailored to specific image restoration tasks: Rain1400 [
14], Test1200 [
15], and SPA [
36] for deraining; GoPro [
16], HIDE [
17], and RWBI [
61] for deblurring; SOTS [
18] and RTTS [
18] for dehazing.
Rain1400 [
14]: This synthetic dataset comprises 14,000 pairs of rainy and corresponding clean images. It is designed to evaluate the effectiveness of deraining algorithms under controlled conditions with varying rain densities and patterns.
Test1200 [
15]: Consisting of 12,000 images, Test1200 assigns each image a label based on its rain-density level, categorized into three classes: light, medium, and heavy. This labeling facilitates the assessment of deraining models’ performance across different intensities of rainfall.
GoPro [
16]: The GoPro dataset includes 3214 pairs of blurry and sharp images captured at a resolution of
pixels. It is widely used for benchmarking deblurring algorithms, providing real-world motion blur scenarios derived from high-speed camera footage.
HIDE [
17]: Comprising 8422 pairs of realistic blurry images and their corresponding sharp ground truth images, HIDE leverages high-speed camera technology to obtain precise blur-free references. This dataset is instrumental for evaluating deblurring models under authentic motion blur conditions.
SOTS [
18]: SOTS contains 500 indoor and 500 outdoor images, with haze simulation applied using optical models and varying parameters for each image.
SPA [
36]: SPA is a large-scale dataset of 29.5K rain/rain-free image pairs, covering a wide range of natural rain scenes.
RWBI [
61]: RWBI includes 3112 blurry images from 22 sequences, captured with various devices (iPhone XS, Samsung S9 Plus, Huawei P30 Pro, GoPro Hero 5) to ensure diverse blur characteristics.
RTTS [
18]: RTTS consists of 4322 real-world hazy images from traffic scenarios, annotated with object categories and bounding boxes.
Metrics. To evaluate the restoration performance of our proposed SLKD framework, we use two widely recognized full-reference metrics, the Peak Signal-to-Noise Ratio (PSNR) [
62] and Structural Similarity Index (SSIM) [
63], along with two no-reference metrics: the Blind/Referenceless Image Spatial Quality Evaluator (BRISQUE) [
58] and Perception-based Image Quality Evaluator (PIQE) [
59].
Peak Signal-to-Noise Ratio (PSNR): PSNR is the most popular metric in image restoration, quantifying the pixel-wise differences between a degraded image and its corresponding clean image. It is calculated based on the Mean-Squared Error (MSE) between the two images, expressed in decibels (dB). A higher PSNR indicates a closer resemblance to the ground truth, reflecting better restoration quality [
62].
Structural Similarity Index (SSIM): SSIM assesses the similarity between degraded and clean images from three key aspects: luminance (brightness), contrast, and structural information. Unlike PSNR, which focuses solely on pixel-wise differences, SSIM aligns more closely with human visual perception by evaluating how well the restored image preserves the structural integrity of the original [
63].
Blind/Referenceless Image Spatial Quality Evaluator (BRISQUE): BRISQUE is a no-reference image quality metric that evaluates perceptual quality using natural scene statistics (NSS) of local patches, capturing distortions like blurring and noise without requiring a reference image.
Perception-based Image Quality Evaluator (PIQE): PIQE is a no-reference metric that assesses perceptual image quality by analyzing local distortions and using a perception-based model to predict how humans would perceive these distortions, also without needing a reference image.
Additionally, we evaluate model complexity by measuring the Floating Point Operations per Second (FLOPs) and inference time for each image, offering insights into the computational efficiency of the models. Furthermore, we assess the performance of the compressed models on a downstream object detection task using the mean Average Precision (mAP) metric, which reflects the models’ practical utility in real-world applications.
4.2. Comparisons with State-of-the-Art Methods
To demonstrate the effectiveness of our proposed Simultaneous Learning Knowledge Distillation (SLKD) framework, we conduct a comprehensive comparison against two state-of-the-art (SOTA) knowledge distillation methods designed for image-to-image transfer tasks and seven SOTA image restoration models. These comparisons are performed across three challenging restoration tasks: deraining, deblurring, and dehazing. The competing models are sourced from publicly available repositories or trained following the authors’ guidelines to ensure fair comparisons.
Comparison with Knowledge Distillation Methods. We compare our SLKD framework with two SOTA knowledge distillation methods for image-to-image transfer: DFKD [
19] and DCKD [
9].
The qualitative comparisons in
Figure 5 show that our framework excels at handling multiple types of degradation, including rain streaks, blur, and noise, producing restored images that closely match the ground truth. Notably, our method consistently achieves clearer and more natural-looking images compared to DFKD and DCKD, which often fail to fully remove severe degradations.
The quantitative results in
Table 2 further validate our framework’s superior performance across various teacher models and datasets. Our method outperforms both DFKD and DCKD in terms of PSNR [
62] and SSIM [
63], demonstrating its robustness across different restoration tasks. This indicates that SLKD effectively transfers knowledge from the teacher networks to the student network, resulting in better restoration quality with significantly reduced model complexity.
Comparison with Image Restoration Methods. We also compare our SLKD framework with seven SOTA image restoration models: PReNet [
64] and RCDNet [
65] for deraining; DMPHN [
66] and MT-RNN [
67] for deblurring; MSBDN [
34] and PSD [
50] for dehazing; and MPRNet [
10], a multi-purpose restoration model capable of handling various degradations.
The qualitative comparisons, presented in
Figure 6, show that our distilled models achieve superior restoration quality across all three tasks. Specifically, our models demonstrate remarkable effectiveness in mitigating various types of degradation, including rain streaks, motion blur, and noise, which are common challenges in real-world outdoor scenes. Unlike some of the competing models that leave residual artifacts or fail to fully restore the image, our models produce clean and detailed outputs that closely match the ground truth.
In terms of quantitative performance,
Table 3 indicates that our distilled models achieve significantly higher PSNR and SSIM scores compared to existing image restoration models, bridging the performance gap between image restoration methods and the more complex MPRNet [
10]. Despite the substantial reduction in model complexity, as in
Table 1, our method retains competitive restoration quality, demonstrating that SLKD can effectively compress models without sacrificing performance.
This balance between computational efficiency and restoration accuracy underscores the practical value of our framework for real-time deployment on resource-constrained drones. These systems require models that can process images efficiently in real-time while maintaining high restoration quality to ensure reliable operation in dynamic and challenging environments.
Comparison on Real degraded Images. For image restoration models used in drone applications, achieving reliable performance under real-world conditions is crucial, particularly given that most use cases involve outdoor environments. To evaluate this, we extend our assessment to real degraded images from SPA [
36], RWBI [
61], and RTTS [
18]. The qualitative results are presented in
Figure 7, while the quantitative analysis is summarized in
Table 4.
Although primarily trained on synthetic datasets, the Res-SL student model shows remarkable robustness in handling a variety of real-world degradations. As shown in
Figure 7, Res-SL effectively mitigates rain, blur, and haze artifacts, producing visually pleasing results that retain important fine details. Moreover, the no-reference quality metrics (BRISQUE and PIQE) in
Table 4 further confirm the high image quality achieved by the SLKD-based student models, even in the absence of ground-truth references.
These findings emphasize the adaptability and robustness of the proposed SLKD approach, demonstrating its effectiveness not only on synthetic datasets but also in tackling real-world challenges. This makes it particularly well suited for real-time deployment in UAV applications and other resource-constrained environments.
4.3. Task-Driven Evaluation
High-level computer vision tasks, such as object detection and semantic segmentation, are widely applied in various fields, including drone-related autonomous navigation [
68], turfgrass monitoring [
69], weed detection [
70], and levee inspection [
71]. However, the accuracy of these tasks is highly sensitive to image quality [
72]. The presence of degradation factors such as haze, rain, and blur can significantly impact the performance of these tasks, leading to substantial performance degradation in real-world applications. To evaluate the effectiveness of SLKD-based student models in enhancing image quality for downstream tasks, we conduct object detection on the RTTS dataset [
18] and semantic segmentation on the SOTS dataset [
18].
The object detection performance is evaluated using the YOLOv4 framework [
73], a widely adopted real-time object detection model known for its robustness and efficiency. As shown in
Table 5, SLKD-based student models outperform state-of-the-art image restoration methods, demonstrating superior capabilities in restoring degraded images while preserving the critical details required for reliable object detection. The visual results of object detection, presented in
Figure 8, further confirm the effectiveness of the proposed framework. It can be observed that, when using Res-SL-enhanced images, YOLOv4 accurately detects all objects with the highest confidence scores, even in challenging conditions.
Semantic segmentation is performed using Deeplabv3 [
75], pre-trained on the Cityscapes dataset [
76], with MobileNetV3 [
77] as the backbone. The results of the semantic segmentation are visualized in
Figure 9. It is evident that the segmentation on the hazy image loses substantial information and fails to identify the car within the red circle. In contrast, the segmentation results on the dehazed image are highly accurate and closely match those of the clear image.
These results highlight that SLKD-based student models not only achieve lightweight compression suitable for drones but also retain the image restoration model’s ability to enhance downstream tasks. This allows the compressed models to maintain robust performance in real-world applications, making them ideal for deployment on resource-constrained drones.
4.4. Ablation Studies
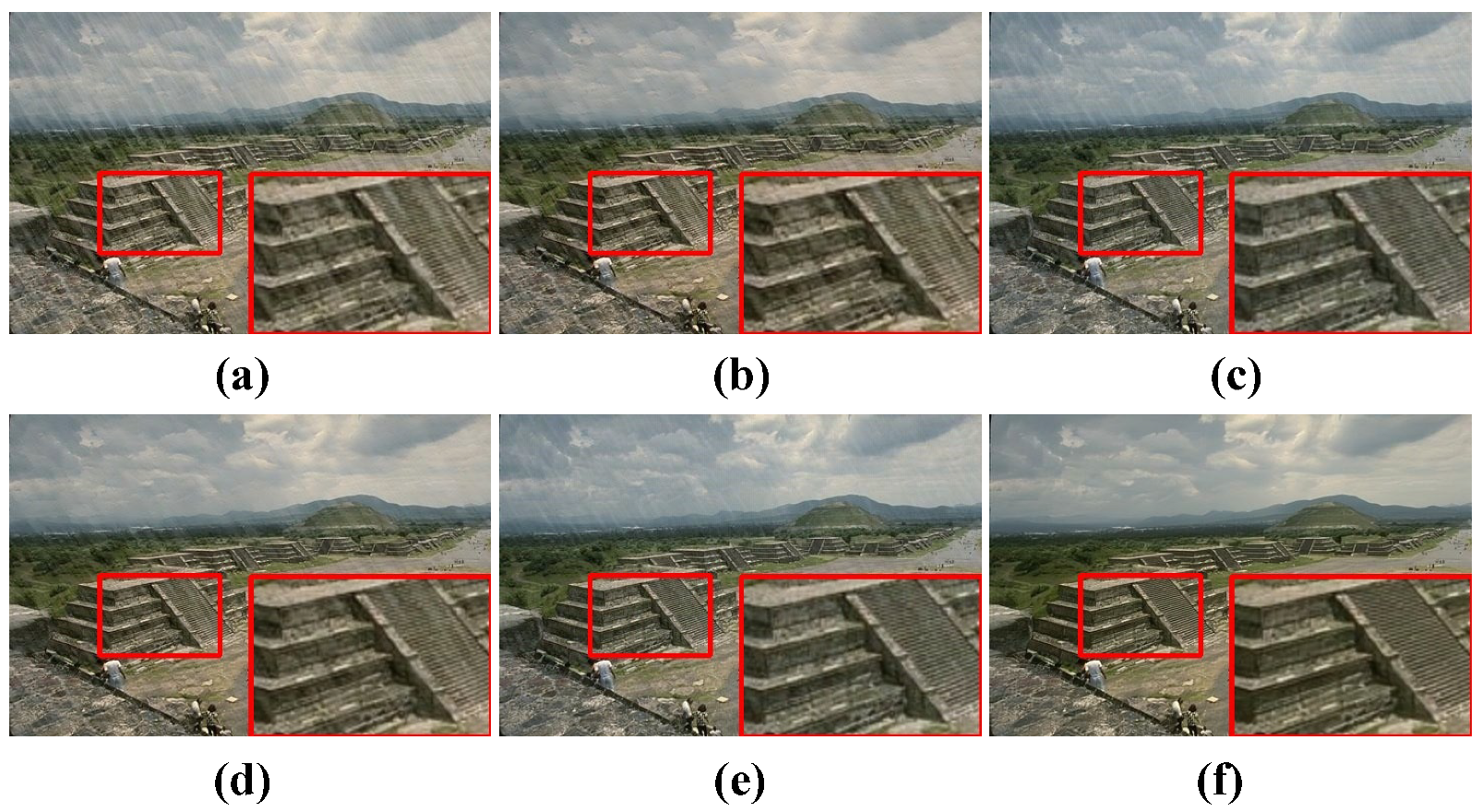
To evaluate the contribution of each component in our SLKD framework, we conduct ablation studies and present the results in
Figure 10 and
Table 6. These studies aim to isolate and analyze the impact of key design choices, including the knowledge distillation strategy, the use of clean images as inputs for Teacher B in Image Reconstruction Learning (IRL), and the effectiveness of the two feature-level losses
and
.
(a) in
Figure 10 and
Table 6 shows the results of directly training a lightweight student network without applying the knowledge distillation strategy. The restored image clearly exhibits more rain streak residue, and both the PSNR and SSIM values are significantly lower compared to all the knowledge distillation configurations. As shown in
Figure 10b,c and the corresponding rows, 2–3, in
Table 6, using clean images as inputs for teacher network B in IRL, instead of degraded images, leads to a noticeable improvement in the clarity and overall quality of the restored images. This adjustment ensures that the student decoder learns to reconstruct images based on high-quality references, resulting in more accurate restoration, particularly in edge and texture details. This improvement is reflected in higher PSNR and SSIM scores, demonstrating the importance of providing the student decoder with clean image guidance.
The contributions of the Degradation Removal Learning (DRL) and Image Reconstruction Learning (IRL) strategies, along with the two feature-level losses
and
, are analyzed individually. As illustrated in
Figure 10c–f and the corresponding rows, 3–6, in
Table 6, each learning strategy and loss independently enhances the student model’s ability to remove degradation and reconstruct clean images.
The ablation studies demonstrate that each component of our SLKD framework contributes to the overall performance of the student model. When both learning strategies (DRL and IRL) and both feature-level losses ( and ) are combined, the model achieves its best performance, significantly improving the clarity, sharpness, and overall quality of the restored images.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}