Abstract
Deploying high-performance image restoration models on drones is critical for applications like autonomous navigation, surveillance, and environmental monitoring. However, the computational and memory limitations of drones pose significant challenges to utilizing complex image restoration models in real-world scenarios. To address this issue, we propose the Simultaneous Learning Knowledge Distillation (SLKD) framework, specifically designed to compress image restoration models for resource-constrained drones. SLKD introduces a dual-teacher, single-student architecture that integrates two complementary learning strategies: Degradation Removal Learning (DRL) and Image Reconstruction Learning (IRL). In DRL, the student encoder learns to eliminate degradation factors by mimicking Teacher A, which processes degraded images utilizing a BRISQUE-based extractor to capture degradation-sensitive natural scene statistics. Concurrently, in IRL, the student decoder reconstructs clean images by learning from Teacher B, which processes clean images, guided by a PIQE-based extractor that emphasizes the preservation of edge and texture features essential for high-quality reconstruction. This dual-teacher approach enables the student model to learn from both degraded and clean images simultaneously, achieving robust image restoration while significantly reducing computational complexity. Experimental evaluations across five benchmark datasets and three restoration tasks—deraining, deblurring, and dehazing—demonstrate that, compared to the teacher models, the SLKD student models achieve an average reduction of 85.4% in FLOPs and 85.8% in model parameters, with only a slight average decrease of 2.6% in PSNR and 0.9% in SSIM. These results highlight the practicality of integrating SLKD-compressed models into autonomous systems, offering efficient and real-time image restoration for aerial platforms operating in challenging environments.
1. Introduction
Deploying high-performance image restoration models on drones is essential for numerous real-world applications, including autonomous navigation, environmental monitoring, and disaster response, as shown in Figure 1. These systems operate in dynamic and often harsh environments, where visual data can be severely degraded by factors such as rain, blur, noise, and low lighting conditions. However, the computational and memory constraints of drones pose significant challenges to deploying complex, high-capacity image restoration models in these scenarios. Thus, compressing image restoration models to achieve both high efficiency and strong performance is a critical area of research.
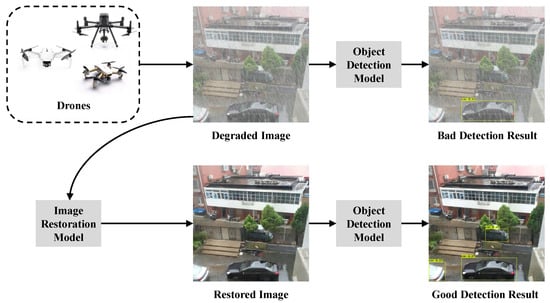
Figure 1.
An illustration of the importance of image restoration models for drones. Tasks such as object detection have significantly better results with restored images.
Recent advancements in model compression techniques, particularly through knowledge distillation, have shown significant promise in reducing the computational complexity of deep learning models while maintaining their performance. Knowledge distillation, first introduced by Hinton et al. [1], involves transferring knowledge from a large, pre-trained teacher model to a smaller, more efficient student model. The student model is trained to mimic the behavior of the teacher model, achieving comparable performance with a fraction of the computational cost. While knowledge distillation has been widely explored in classification tasks [2,3] and segmentation tasks [4], its potential in image-to-image translation tasks, particularly in image restoration, remains under-explored.
Image restoration tasks differ significantly from classification and segmentation tasks due to their reliance on encoder/decoder architectures. These models aim to remove various types of degradation from images, such as noise, blur, and artifacts, and reconstruct a clean, high-quality image. In this context, traditional knowledge distillation methods that focus on logits or intermediate features are less effective because they overlook the unique requirements of image restoration. Effective image restoration requires not only removing degradation factors but also accurately reconstructing fine details such as edges and textures, which are critical for perceptual quality.
Recent studies have explored knowledge distillation in image-to-image tasks, particularly in image transfer [5,6,7] and super-resolution tasks [8,9]. However, most of these methods focus solely on either degradation removal or image reconstruction, failing to comprehensively address both aspects simultaneously. Moreover, many existing methods rely on a single teacher model, limiting their capacity to handle the complex, multi-faceted nature of real-world image degradation.
To address these limitations, we propose the Simultaneous Learning Knowledge Distillation (SLKD) framework, a novel dual-teacher, single-student architecture designed specifically for compressing image restoration models. SLKD introduces two distinct learning strategies: Degradation Removal Learning (DRL) and Image Reconstruction Learning (IRL). In DRL, the student encoder learns to remove degradation factors by mimicking the teacher encoder from Teacher A, which processes degraded images. This process is guided by a BRISQUE-based extractor, which captures degradation-sensitive natural scene statistics to enhance the student’s ability to handle real-world degradations. In parallel, IRL focuses on reconstructing clean images by training the student decoder to mimic the decoder of Teacher B, which processes clean images. A PIQE-based extractor is employed in IRL to emphasize the preservation of edge and texture features, ensuring high-quality image reconstruction.
Our SLKD framework effectively addresses the dual challenges of degradation removal and image reconstruction by enabling the student network to learn from both degraded and clean images. This simultaneous learning approach not only improves the model’s restoration quality but also significantly reduces its computational complexity, making it suitable for real-time applications on resource-constrained drones.
We validate our method through extensive experiments on five public benchmark datasets across three image restoration tasks: deraining, deblurring, and dehazing. The results demonstrate that, compared to the teacher model Restormer, Uformer, and DRSformer, the corresponding SLKD student models achieve reductions of 86.3%, 83.6%, and 86.4% in FLOPs and 86.6%, 84.5%, and 86.4% in model parameters (detailed in Table 1), with only slight decreases of 2.9%, 2.5%, and 2.4% in PSNR and 0.7%, 1.3%, and 0.7% in SSIM, respectively (detailed in Table 2). Our distilled student models outperform several state-of-the-art image restoration models and achieve performance comparable to complex models such as MPRNet [10], making SLKD an ideal solution for real-time image restoration on drones.

Table 1.
Hyper-parameters and complexity of teachers and corresponding students.
Table 2.
Quantitative comparison with knowledge distillation methods on five datasets. The best results are highlighted in bold, and the suboptimal results are underlined.
In summary, this work makes the following key contributions:
- We introduce the SLKD framework, a dual-teacher, single-student knowledge distillation strategy tailored for image restoration tasks.
- We propose two complementary learning strategies, Degradation Removal Learning (DRL) and Image Reconstruction Learning (IRL), each guided by task-specific feature extractors (BRISQUE and PIQE).
- We demonstrate that SLKD achieves substantial reductions in model complexity while maintaining high restoration performance, making it practical for deployment on resource-constrained drones.
2. Related Work
This section provides an overview of key approaches relevant to image restoration and knowledge distillation, focusing on prior-based, learning-based, and semi-supervised methods.
2.1. Image Restoration
2.1.1. Prior-Based Methods
Early image restoration methods primarily relied on hand-crafted priors to address specific types of degradation [20,21,22,23,24,25,26]. For instance, He et al. [20] proposed the dark channel prior (DCP), a widely used method for image dehazing. This approach estimates transmission maps and global atmospheric light based on the observation that at least one channel in most patches of a haze-free image has values close to zero. To address the potential loss of image details, Xu et al. [27] developed a refined guidance image to improve the accuracy of snow removal, preserving more image details. Similarly, Li et al. [26] proposed a layer prior-based method to remove rain streaks from images, providing a robust solution for rain removal tasks. For image deblurring, Pan et al. [24] integrated the dark channel prior to improve the removal of motion blur. Further refinements to the DCP method were proposed by other researchers to enhance its efficiency and robustness [28,29,30].
While prior-based methods have demonstrated promising results in addressing specific degradations, their robustness is often limited by the failure of priors in complex or diverse scenarios. As a result, these approaches have been largely replaced by learning-based methods.
2.1.2. Learning-Based Methods
The advent of deep learning, particularly Convolutional Neural Networks (CNNs) and visual transformers, has significantly advanced the field of image restoration. These learning-based methods can be broadly categorized into parameter-estimated approaches [31,32,33] and end-to-end approaches [34,35,36,37,38,39,40,41].
For example, Li et al. [39] proposed a Depth Refinement Network (DRN) for dynamic scene deblurring. Their method leverages a spatial feature transform layer to extract depth features, enhancing the reconstruction of structural details and edges. Furthermore, Zamir et al. [10] proposed MPRNet, which introduces a per-pixel adaptive design that uses supervised attention mechanisms to re-weight local features at each stage of the restoration process. Duong et al. [41] proposed a U-shaped backbone with several stacked pyramid depthwise separable convolution (PDC) modules for low-light image enhancement. To overcome the challenges in image deblurring, Ho et al. [42] proposed an Efficient Hybrid Network (EHNet) that employs CNN encoders for local feature extraction and Transformer decoders with a dual-attention module to capture spatial and channel-wise dependencies. For ill-posed image denoising tasks, Duong et al. [43] proposed a multi-branch network to improve the performance of the denoising method.
2.1.3. Semi-Supervised and Unsupervised Methods
In recent years, domain adaptation techniques have been explored to address the domain gap between synthetic and real-world degraded images. These approaches aim to improve restoration performance by aligning the source (synthetic) and target (real-world) domains at either the feature or pixel level [44,45,46].
For example, Wei et al. [47] proposed a semi-supervised rain removal approach that utilizes a Gaussian mixture model to characterize rain streaks. Their method includes an unsupervised branch, trained by minimizing the KL divergence between rain streak distributions in real and synthetic images. Similarly, Shao et al. [48] introduced a domain adaptation framework that incorporates real hazy images into the training process using a cycle-GAN. A similar approach was employed by Wei et al. [49] for image deraining, where they proposed a rain attention mechanism to enhance restoration performance. Chen et al. [50] explored various physical priors and introduced a loss committee to guide training on real hazy images, ensuring better alignment between synthetic and real-world data. Their method incorporates a self-supervised memory module that captures prototypical rain patterns from both synthetic and real data, enabling the model to generalize better across different rain conditions.
While learning-based methods have achieved state-of-the-art performance across various image restoration tasks, their computational complexity and large model sizes limit their applicability on resource-constrained drones.
2.2. Knowledge Distillation
The concept of learning a small model from a large model, later formally popularized as knowledge distillation, was introduced by Hinton et al. [1]. In this paradigm, a small student model is supervised by a larger teacher model, with the goal of transferring knowledge from the teacher to the student. The fundamental idea is that the student model can mimic the teacher model’s behavior to achieve competitive, or even superior, performance. Since its inception, various knowledge distillation frameworks have been proposed, such as multi-teacher, single-student [51] and self-distillation [52]. Moreover, research by Adriana et al. [2] showed that the teacher model does not necessarily have to be larger than the student model, suggesting that distillation can also be effective in smaller-to-larger model configurations.
2.2.1. Knowledge Distillation in High-Level Tasks
Knowledge distillation has found extensive applications in high-level computer vision tasks, including object detection [53], face recognition [54], and semantic segmentation [55]. For instance, Wang et al. [53] proposed a fine-grained feature imitation method that exploits the cross-location discrepancy of feature responses. Their method focused on local regions near objects, which are critical for detectors. In face recognition, Ge et al. [54] selectively distilled the most informative facial features from a teacher model, employing a sparse graph optimization approach to avoid performance degradation. Additionally, for semantic segmentation, Liu et al. [55] proposed a framework to distill structured knowledge from large networks to smaller ones, addressing the structured nature of segmentation tasks.
2.2.2. Knowledge Distillation in Low-Level Tasks
Knowledge distillation has also been effectively applied to low-level vision tasks, including image-to-image translation [5,7] and image super-resolution [9,19]. For example, Li et al. [5] introduced a novel method that combines knowledge distillation with a semantic relation-preserving matrix to improve the performance of the student model. Zhang et al. [19] employed discrete wavelet transform to decompose images into different frequency bands and then focused distillation on the high-frequency components, enhancing the student’s ability to restore fine details. Furthermore, Fang et al. [9] introduced a cross-knowledge distillation framework, where the student model is cascaded into the teacher network, allowing for the effective transfer of multi-level features.
While knowledge distillation has shown promise in enhancing image restoration performance [56] and integrating multiple restoration capabilities [57], these efforts have often concentrated on improving restoration quality rather than model efficiency.
In contrast, we propose the Simultaneous Learning Knowledge Distillation (SLKD) framework, which utilizes knowledge distillation to compress image restoration models, reducing both the model parameters and computational complexity. This makes SLKD more suitable for deployment on lightweight drones, where computational and memory resources are limited.
3. Proposed Method
3.1. Overall Architecture
As illustrated in Figure 2, we propose a Simultaneous Learning Knowledge Distillation (SLKD) framework to train an efficient student image restoration network by leveraging two pre-trained teacher networks. This approach aims to distill the knowledge of the teacher networks into a smaller, computationally efficient student network, making it suitable for deployment on resource-constrained drones. The architecture consists of three key components: two teacher networks and one student network.
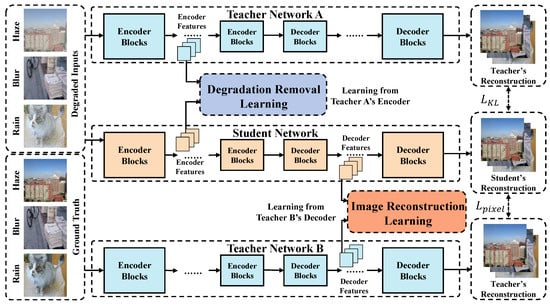
Figure 2.
The overall architecture of our proposed Simultaneous Learning Knowledge Distillation (SLKD) framework for image restoration. SLKD includes Degradation Removal Learning (DRL) and an Image Reconstruction Learning (IRL).
- 1.
- Teacher Networks (A and B): Teacher network A is trained to restore degraded images, while teacher network B is trained to reconstruct clean images. These teacher networks are large and computationally expensive, having been trained on high-resolution images with complex architectures capable of handling various degradation types (e.g., rain, blur, and haze). They serve as the source of knowledge for the student network.
- 2.
- Student Network: The student network shares a similar structural design to the teacher networks, with the same basic encoder/decoder architecture. However, it has been optimized by reducing the number of transformers and lowering the feature dimensions in each encoder/decoder block. This reduction in complexity significantly lowers the number of parameters and the computational requirements of the model, while still retaining the capability to restore high-quality images.
The SLKD framework aims to distill the knowledge from both teacher networks into the student network through two complementary learning strategies:
Given a pair of degraded and clean images , teacher network A and the student network both take the degraded image I as an input, while teacher network B uses the clean image G.
In DRL, the student encoder learns to remove degradation factors by mimicking the degradation removal process of the Teacher A encoder. The goal is to progressively restore the degraded features to a clean background representation.
In IRL, the student decoder learns to reconstruct a clean background image by emulating the restoration process of teacher network B. This focuses on restoring high-level structures, such as edges and textures, from the extracted features.
The SLKD process ensures that the student network effectively learns to perform image restoration tasks at a fraction of the computational cost, by transferring knowledge from both teacher networks. The final output of the student network is a high-quality restored image that reflects the combined knowledge of the teacher networks while being efficient enough for real-time applications.
3.2. Degradation Removal Learning
In typical encoder/decoder architectures for image restoration tasks, the encoder’s primary role is to extract essential features from the input image. In the case of image restoration, these features should correspond to a clean and uncorrupted feature map, effectively removing degradation factors such as noise, blur, or other distortions. The goal of Degradation Removal Learning (DRL) is to train the student encoder to progressively remove degradation and recover clean background features, aligning its process with that of the teacher network.
The student encoder is tasked with learning the degradation removal process from Teacher A, which is trained specifically for this purpose, as shown in Figure 3a. Teacher A’s encoder takes the degraded image as the input and outputs a feature map corresponding to the clean image by effectively removing degradation. The student encoder mimics this process through knowledge distillation. In DRL, the student encoder learns to extract and refine degraded features using a multi-step procedure:
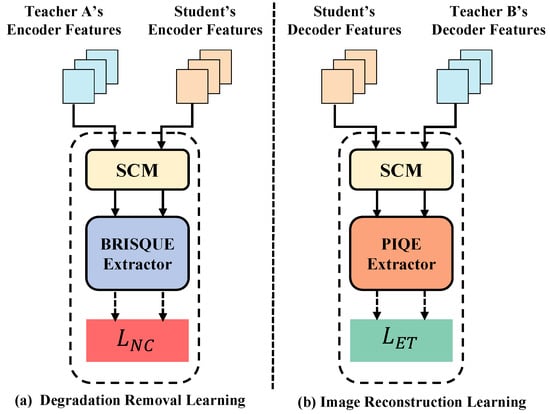
Figure 3.
The architecture of the Degradation Removal Learning (DRL) and Image Reconstruction Learning (IRL) strategies.
The first step involves mapping the encoder features of both the teacher network (Teacher A) and the student network into a unified scale space. The Scale Conversion Module (SCM) operates at each encoder block level to ensure that both the teacher and student features are on the same scale, allowing for an efficient comparison of the learned features across networks, as shown in Figure 4.
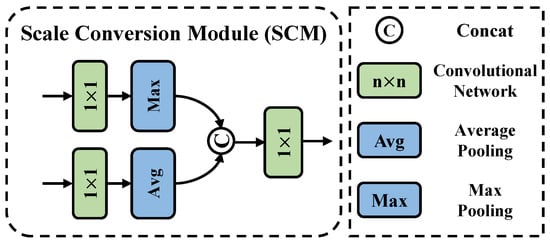
Figure 4.
The architecture of the Scale Conversion Module (SCM).
Specifically, for the k-th-level encoder features, the features from Teacher A () and the student network () are mapped to a unified scale space:
where and represent the scaled feature maps from the teacher and student networks, respectively.
To focus on natural scene statistics, the BRISQUE-based extractor (Blind/Referenceless Image Spatial Quality Evaluator) is employed to capture natural and color features from the encoded representations. BRISQUE is particularly effective at measuring perceptual image quality, and it helps to identify the key characteristics of clean images that the student should learn to extract.
The BRISQUE extractor computes the Mean-Subtracted Contrast-Normalized (MSCN) coefficients for the scaled feature maps:
where represents the pixel value at , and are the local mean and variance of the image, and C is a small constant to avoid division by zero. The MSCN coefficients help to normalize the image contrast and extract meaningful features, which are essential for capturing the image quality.
Using the MSCN map, the natural and color features ( and ) are extracted for both the teacher and student networks, as detailed in [58]:
These features are modeled using generalized Gaussian and asymmetric generalized Gaussian distributions, which provide a statistical representation of the image content.
The natural and color loss quantifies the difference between the natural and color features of the student network and the teacher network. This loss ensures that the student encoder effectively learns to remove degradation and produce a clean feature map. The loss is computed as follows:
where n is the total number of encoder/decoder blocks, and the sum is taken over all spatial locations of the feature maps. This loss function promotes the alignment of the natural and color features between the teacher and student networks.
3.3. Image Reconstruction Learning
In image restoration tasks, the decoder in an encoder/decoder architecture plays a crucial role in transforming the extracted features into a complete and high-quality image. While the encoder focuses on removing degradation and extracting useful features, the decoder is responsible for reconstructing the image from these features. The primary goal of Image Reconstruction Learning (IRL) is to train the student decoder to restore a clean, high-quality image by learning to reconstruct critical edge and texture features, with guidance from the teacher network.
The student decoder is trained by mimicking Teacher B’s decoder, which operates on clean images and aims to reconstruct the final high-quality image, as shown in Figure 3b. Teacher B’s decoder is pre-trained to perform this task with high fidelity, providing an excellent source of knowledge for the student network. The student decoder learns to restore the image by progressively refining edge and texture features in a manner similar to the teacher.
Just as in DRL, the first step in IRL involves mapping the decoder features of both the teacher and student networks into a unified scale space using the Scale Conversion Module (SCM). This ensures that the teacher and student decoder features are on the same scale and can be compared effectively.
Specifically, for the k-th-level decoder features, the features from Teacher B () and the student decoder () are mapped to a unified scale space:
where and are the unified scale representations of the teacher and student decoder features, respectively.
To ensure that the student decoder is focusing on restoring critical edge and texture features, we employ a PIQE-based extractor (Perceptual Image Quality Evaluator). The PIQE extractor is used to capture the most relevant perceptual image features that contribute to the perceived quality of an image, specifically targeting sharpness, edge clarity, and texture fidelity.
Similar to the BRISQUE-based feature extraction in DRL, the PIQE extractor computes Mean-Subtracted Contrast-Normalized (MSCN) coefficients for the unified decoder feature maps. These coefficients normalize the contrast of the image and make it easier to compare the features of the teacher and student decoders as in Equation (2).
The MSCN coefficients obtained from both the teacher and student decoders are used to extract edge and texture features. These features are crucial for image reconstruction as they capture the fine details, sharpness, and structural integrity of the image. The edge and texture features are derived based on distortion estimation and block variance methods, as described in [59], which allow us to identify the areas of the image that need refinement:
The edge and texture loss quantifies the difference between the edge and texture features of the student network and the teacher network. This loss function ensures that the student decoder learns to restore fine image details, such as edges and textures, which are often the most perceptually important aspects of an image. The edge and texture loss is computed as follows:
This loss encourages the student decoder to match the edge and texture features from Teacher B, thereby improving the image reconstruction process.
3.4. Overall Loss
In addition to the feature-level losses and , we incorporate two image-level loss functions to further enhance the training process. The KL divergence loss and pixel-level L1 loss are employed to align the student’s reconstruction with the teacher networks. The KL divergence loss between the student’s reconstruction and Teacher Network A’s reconstruction is calculated as follows:
This loss ensures that the student network’s output distribution matches that of Teacher A, promoting statistical alignment between the two networks.
The pixel-level loss between the student’s reconstruction and Teacher B’s reconstruction is formulated as follows:
This loss measures the absolute pixel-wise error, directly minimizing discrepancies between the student’s reconstruction and the clean image from Teacher B.
Finally, the overall loss combines these image-level and feature-level losses to train the student network:
where , , and are hyper-parameters that control the relative importance of each loss component. By optimizing this combined loss, the student network learns to efficiently remove degradation and reconstruct high-quality images while also ensuring that the computational burden is minimized for deployment on lightweight drones.
4. Experiments and Analysis
4.1. Experimental Setting
Implementation details.
Our framework is implemented in PyTorch 1.10.0 utilizing the Adam optimizer with the following parameters: = 0.9; = 0.999; weight decay . The models are trained for 100 epochs, starting with an initial learning rate of , which is gradually reduced to using cosine annealing [60]. We set the batch size to 8, with a fixed patch size of 128. The trade-off weights are = 0.5, = 0.1 and = 0.1.
For the teacher networks, we select three state-of-the-art image restoration models: Restormer [11], Uformer [12], and DRSformer [13]. These models are chosen for their exemplary performance across various image restoration tasks, providing robust supervisory signals for the student networks. The corresponding student models are named Res-SL, Ufor-SL, and DRS-SL, respectively. These student models maintain a similar architectural structure to their teacher counterparts but with fewer transformers and reduced feature dimensions in each encoder/decoder block, resulting in significantly lower computational complexity.
Table 1 presents the hyper-parameters of both the teacher and student models, detailing the number of layers and feature dimensions for each encoder/decoder block. Additionally, the table highlights the reductions in model complexity achieved through our proposed SLKD framework. These reductions include decreases in the FLOPs, inference time, and number of parameters, demonstrating the effectiveness of SLKD in compressing image restoration models.
By significantly lowering computational requirements without compromising performance, our student models achieve an optimal balance between efficiency and restoration quality, making them highly suitable for real-time applications on drones operating in dynamic environments.
Datasets. We conduct knowledge distillation experiments using five synthetic datasets and three real-world datasets, each tailored to specific image restoration tasks: Rain1400 [14], Test1200 [15], and SPA [36] for deraining; GoPro [16], HIDE [17], and RWBI [61] for deblurring; SOTS [18] and RTTS [18] for dehazing.
Rain1400 [14]: This synthetic dataset comprises 14,000 pairs of rainy and corresponding clean images. It is designed to evaluate the effectiveness of deraining algorithms under controlled conditions with varying rain densities and patterns.
Test1200 [15]: Consisting of 12,000 images, Test1200 assigns each image a label based on its rain-density level, categorized into three classes: light, medium, and heavy. This labeling facilitates the assessment of deraining models’ performance across different intensities of rainfall.
GoPro [16]: The GoPro dataset includes 3214 pairs of blurry and sharp images captured at a resolution of pixels. It is widely used for benchmarking deblurring algorithms, providing real-world motion blur scenarios derived from high-speed camera footage.
HIDE [17]: Comprising 8422 pairs of realistic blurry images and their corresponding sharp ground truth images, HIDE leverages high-speed camera technology to obtain precise blur-free references. This dataset is instrumental for evaluating deblurring models under authentic motion blur conditions.
SOTS [18]: SOTS contains 500 indoor and 500 outdoor images, with haze simulation applied using optical models and varying parameters for each image.
SPA [36]: SPA is a large-scale dataset of 29.5K rain/rain-free image pairs, covering a wide range of natural rain scenes.
RWBI [61]: RWBI includes 3112 blurry images from 22 sequences, captured with various devices (iPhone XS, Samsung S9 Plus, Huawei P30 Pro, GoPro Hero 5) to ensure diverse blur characteristics.
RTTS [18]: RTTS consists of 4322 real-world hazy images from traffic scenarios, annotated with object categories and bounding boxes.
Metrics. To evaluate the restoration performance of our proposed SLKD framework, we use two widely recognized full-reference metrics, the Peak Signal-to-Noise Ratio (PSNR) [62] and Structural Similarity Index (SSIM) [63], along with two no-reference metrics: the Blind/Referenceless Image Spatial Quality Evaluator (BRISQUE) [58] and Perception-based Image Quality Evaluator (PIQE) [59].
Peak Signal-to-Noise Ratio (PSNR): PSNR is the most popular metric in image restoration, quantifying the pixel-wise differences between a degraded image and its corresponding clean image. It is calculated based on the Mean-Squared Error (MSE) between the two images, expressed in decibels (dB). A higher PSNR indicates a closer resemblance to the ground truth, reflecting better restoration quality [62].
Structural Similarity Index (SSIM): SSIM assesses the similarity between degraded and clean images from three key aspects: luminance (brightness), contrast, and structural information. Unlike PSNR, which focuses solely on pixel-wise differences, SSIM aligns more closely with human visual perception by evaluating how well the restored image preserves the structural integrity of the original [63].
Blind/Referenceless Image Spatial Quality Evaluator (BRISQUE): BRISQUE is a no-reference image quality metric that evaluates perceptual quality using natural scene statistics (NSS) of local patches, capturing distortions like blurring and noise without requiring a reference image.
Perception-based Image Quality Evaluator (PIQE): PIQE is a no-reference metric that assesses perceptual image quality by analyzing local distortions and using a perception-based model to predict how humans would perceive these distortions, also without needing a reference image.
Additionally, we evaluate model complexity by measuring the Floating Point Operations per Second (FLOPs) and inference time for each image, offering insights into the computational efficiency of the models. Furthermore, we assess the performance of the compressed models on a downstream object detection task using the mean Average Precision (mAP) metric, which reflects the models’ practical utility in real-world applications.
4.2. Comparisons with State-of-the-Art Methods
To demonstrate the effectiveness of our proposed Simultaneous Learning Knowledge Distillation (SLKD) framework, we conduct a comprehensive comparison against two state-of-the-art (SOTA) knowledge distillation methods designed for image-to-image transfer tasks and seven SOTA image restoration models. These comparisons are performed across three challenging restoration tasks: deraining, deblurring, and dehazing. The competing models are sourced from publicly available repositories or trained following the authors’ guidelines to ensure fair comparisons.
Comparison with Knowledge Distillation Methods. We compare our SLKD framework with two SOTA knowledge distillation methods for image-to-image transfer: DFKD [19] and DCKD [9].
The qualitative comparisons in Figure 5 show that our framework excels at handling multiple types of degradation, including rain streaks, blur, and noise, producing restored images that closely match the ground truth. Notably, our method consistently achieves clearer and more natural-looking images compared to DFKD and DCKD, which often fail to fully remove severe degradations.
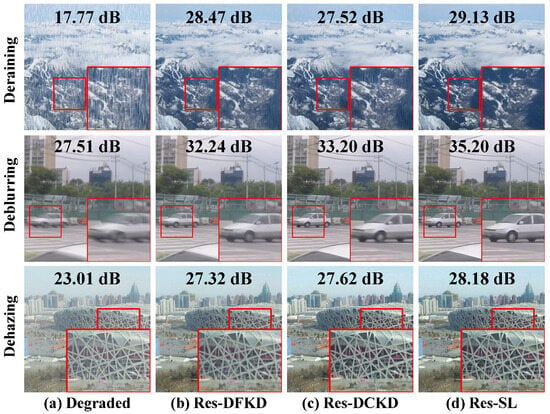
Figure 5.
Qualitative comparison with knowledge distillation methods across image deraining, deblurring, and dehazing.
The quantitative results in Table 2 further validate our framework’s superior performance across various teacher models and datasets. Our method outperforms both DFKD and DCKD in terms of PSNR [62] and SSIM [63], demonstrating its robustness across different restoration tasks. This indicates that SLKD effectively transfers knowledge from the teacher networks to the student network, resulting in better restoration quality with significantly reduced model complexity.
Comparison with Image Restoration Methods. We also compare our SLKD framework with seven SOTA image restoration models: PReNet [64] and RCDNet [65] for deraining; DMPHN [66] and MT-RNN [67] for deblurring; MSBDN [34] and PSD [50] for dehazing; and MPRNet [10], a multi-purpose restoration model capable of handling various degradations.
The qualitative comparisons, presented in Figure 6, show that our distilled models achieve superior restoration quality across all three tasks. Specifically, our models demonstrate remarkable effectiveness in mitigating various types of degradation, including rain streaks, motion blur, and noise, which are common challenges in real-world outdoor scenes. Unlike some of the competing models that leave residual artifacts or fail to fully restore the image, our models produce clean and detailed outputs that closely match the ground truth.

Figure 6.
Quantitative comparison with image restoration methods on synthetic datasets.
In terms of quantitative performance, Table 3 indicates that our distilled models achieve significantly higher PSNR and SSIM scores compared to existing image restoration models, bridging the performance gap between image restoration methods and the more complex MPRNet [10]. Despite the substantial reduction in model complexity, as in Table 1, our method retains competitive restoration quality, demonstrating that SLKD can effectively compress models without sacrificing performance.
Table 3.
Quantitative comparison with image restoration methods on five datasets. The best results are highlighted in bold, and the suboptimal results are underlined.
This balance between computational efficiency and restoration accuracy underscores the practical value of our framework for real-time deployment on resource-constrained drones. These systems require models that can process images efficiently in real-time while maintaining high restoration quality to ensure reliable operation in dynamic and challenging environments.
Comparison on Real degraded Images. For image restoration models used in drone applications, achieving reliable performance under real-world conditions is crucial, particularly given that most use cases involve outdoor environments. To evaluate this, we extend our assessment to real degraded images from SPA [36], RWBI [61], and RTTS [18]. The qualitative results are presented in Figure 7, while the quantitative analysis is summarized in Table 4.

Figure 7.
Quantitative comparison with image restoration methods on real-world datasets.
Table 4.
Quantitative comparison (BRISQUE↓/PIQE↓) with image restoration methods across three real-world datasets. The best results are highlighted in bold, and the suboptimal results are underlined.
Although primarily trained on synthetic datasets, the Res-SL student model shows remarkable robustness in handling a variety of real-world degradations. As shown in Figure 7, Res-SL effectively mitigates rain, blur, and haze artifacts, producing visually pleasing results that retain important fine details. Moreover, the no-reference quality metrics (BRISQUE and PIQE) in Table 4 further confirm the high image quality achieved by the SLKD-based student models, even in the absence of ground-truth references.
These findings emphasize the adaptability and robustness of the proposed SLKD approach, demonstrating its effectiveness not only on synthetic datasets but also in tackling real-world challenges. This makes it particularly well suited for real-time deployment in UAV applications and other resource-constrained environments.
4.3. Task-Driven Evaluation
High-level computer vision tasks, such as object detection and semantic segmentation, are widely applied in various fields, including drone-related autonomous navigation [68], turfgrass monitoring [69], weed detection [70], and levee inspection [71]. However, the accuracy of these tasks is highly sensitive to image quality [72]. The presence of degradation factors such as haze, rain, and blur can significantly impact the performance of these tasks, leading to substantial performance degradation in real-world applications. To evaluate the effectiveness of SLKD-based student models in enhancing image quality for downstream tasks, we conduct object detection on the RTTS dataset [18] and semantic segmentation on the SOTS dataset [18].
The object detection performance is evaluated using the YOLOv4 framework [73], a widely adopted real-time object detection model known for its robustness and efficiency. As shown in Table 5, SLKD-based student models outperform state-of-the-art image restoration methods, demonstrating superior capabilities in restoring degraded images while preserving the critical details required for reliable object detection. The visual results of object detection, presented in Figure 8, further confirm the effectiveness of the proposed framework. It can be observed that, when using Res-SL-enhanced images, YOLOv4 accurately detects all objects with the highest confidence scores, even in challenging conditions.
Table 5.
Object detection results on RTTS [18]. The best results are highlighted in bold, and the suboptimal results are underlined.

Figure 8.
Visualization of object detection results on RTTS [18].
Semantic segmentation is performed using Deeplabv3 [75], pre-trained on the Cityscapes dataset [76], with MobileNetV3 [77] as the backbone. The results of the semantic segmentation are visualized in Figure 9. It is evident that the segmentation on the hazy image loses substantial information and fails to identify the car within the red circle. In contrast, the segmentation results on the dehazed image are highly accurate and closely match those of the clear image.

Figure 9.
Visualization of semantic segmentation results on SOTS [18]: (a) hazy image and its corresponding semantic segmentation result, (b) image dehazed by Res-SL and its corresponding semantic segmentation result, (c) ground truth image and its corresponding semantic segmentation result.
These results highlight that SLKD-based student models not only achieve lightweight compression suitable for drones but also retain the image restoration model’s ability to enhance downstream tasks. This allows the compressed models to maintain robust performance in real-world applications, making them ideal for deployment on resource-constrained drones.
4.4. Ablation Studies
To evaluate the contribution of each component in our SLKD framework, we conduct ablation studies and present the results in Figure 10 and Table 6. These studies aim to isolate and analyze the impact of key design choices, including the knowledge distillation strategy, the use of clean images as inputs for Teacher B in Image Reconstruction Learning (IRL), and the effectiveness of the two feature-level losses and .
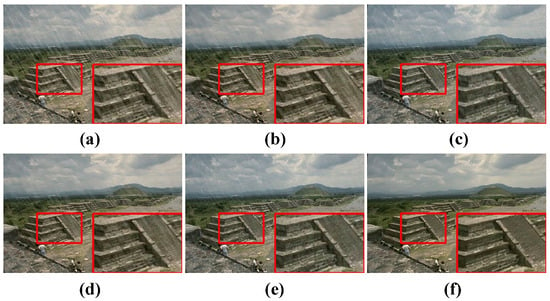
Figure 10.
Qualitative ablation study results on Rain1400 [14].
Table 6.
Ablation study results on Rain1400 [14]. The best result is highlighted in bold.
(a) in Figure 10 and Table 6 shows the results of directly training a lightweight student network without applying the knowledge distillation strategy. The restored image clearly exhibits more rain streak residue, and both the PSNR and SSIM values are significantly lower compared to all the knowledge distillation configurations. As shown in Figure 10b,c and the corresponding rows, 2–3, in Table 6, using clean images as inputs for teacher network B in IRL, instead of degraded images, leads to a noticeable improvement in the clarity and overall quality of the restored images. This adjustment ensures that the student decoder learns to reconstruct images based on high-quality references, resulting in more accurate restoration, particularly in edge and texture details. This improvement is reflected in higher PSNR and SSIM scores, demonstrating the importance of providing the student decoder with clean image guidance.
The contributions of the Degradation Removal Learning (DRL) and Image Reconstruction Learning (IRL) strategies, along with the two feature-level losses and , are analyzed individually. As illustrated in Figure 10c–f and the corresponding rows, 3–6, in Table 6, each learning strategy and loss independently enhances the student model’s ability to remove degradation and reconstruct clean images.
The ablation studies demonstrate that each component of our SLKD framework contributes to the overall performance of the student model. When both learning strategies (DRL and IRL) and both feature-level losses ( and ) are combined, the model achieves its best performance, significantly improving the clarity, sharpness, and overall quality of the restored images.
4.5. Comparison of Complexity
The complexity comparison between the SLKD-based student models and other image restoration models is presented in Table 7. The comparison focuses on two key metrics: Floating Point Operations per Second (FLOPs) and inference time.
Table 7.
Comparison of complexity. The best results are highlighted in bold, and the suboptimal results are underlined.
As shown in the table, the SLKD-based student models achieve a significant a reduction in both FLOPs and inference time compared to other image restoration models. The inference time required by the student models is lower than that required by most competing image restoration models, while the FLOPs are markedly lower than those of all of the evaluated image restoration models.
These results demonstrate that our knowledge distillation method effectively compresses image restoration models, substantially reducing their computational overhead while retaining most of their restoration performance. The reduced complexity achieved by SLKD makes the student models highly suitable for real-time deployment on resource-constrained drones, where low latency and efficient processing are critical.
4.6. Hyper-Parameter Analysis
The proposed SLKD framework includes three key hyper-parameters, , , and , which are used in the overall loss calculation. These parameters control the balance between different loss components, directly influencing the training dynamics and final performance of the student model. We conducted experiments with various combinations of , , and values to evaluate their impact on the student model’s performance. The detailed results of these experiments are presented in Table 8, showing the influence of different hyper-parameter settings on the model’s performance metrics. We can observe that using and with equal weights to balance learning from teachers A and B results in the optimal strategic outcome.
Table 8.
Comparison of hyper-parameters on Rain1400 [14]. The best result is highlighted in bold.
4.7. Deployment
To assess the effectiveness of the proposed Simultaneous Learning Knowledge Distillation method for deploying image restoration models on drones, we implemented the distilled student model on the NVIDIA Jetson Xavier NX and NVIDIA Jetson Orin Nano, two platforms widely used in drones and other edge devices. The performance results are summarized in Table 9.
Table 9.
Inference time and power consumption on NVIDIA Jetson Xavier NX and NVIDIA Jetson Orin Nano. The best results are highlighted in bold.
The results shown in Table 9 highlight the average inference time and power consumption of several distilled student models on the Jetson Xavier NX and Jetson Orin Nano. These models demonstrate efficient image restoration performance on drones and other low-power, low-computing devices, confirming the effectiveness of the proposed distillation method in optimizing both computational and energy efficiency.
5. Conclusions
In this paper, we introduced the Simultaneous Learning Knowledge Distillation (SLKD) framework, specifically designed to compress image restoration models for deployment on drones. By integrating Degradation Removal Learning (DRL) and Image Reconstruction Learning (IRL), SLKD effectively addresses the challenges of model compression in image restoration. This dual-teacher approach allows the student network to learn from both degraded and clean images, ensuring high-quality image restoration while significantly reducing model complexity. Our experiments across five benchmark datasets and three restoration tasks—deraining, deblurring, and dehazing—demonstrate that, compared to the teacher models, the SLKD student models achieve an average reduction of 85.4% in FLOPs and 85.8% in model parameters, with only a slight average decrease of 2.6% in PSNR and 0.9% in SSIM. The ablation studies validate the effectiveness of DRL and IRL in enhancing image clarity and model robustness, highlighting the importance of our proposed learning strategies. SLKD provides a practical solution for integrating advanced image restoration capabilities into autonomous systems operating under strict computational and energy constraints. High-quality image restoration is critical for applications such as autonomous navigation, surveillance, and environmental monitoring, where clear and accurate visual data are essential for decision-making. By enabling real-time, high-performance image restoration on drones, SLKD enhances the reliability and efficiency of these autonomous systems in dynamic outdoor environments.
Funding
This research received no external funding.
Data Availability Statement
The dataset is available on request from the author.
DURC Statement
This article is a revised and expanded version of a paper entitled “Knowledge Distillation for Image Restoration: Simultaneous Learning from Degraded and Clean Images [78]”, which will be presented at ICASSP2025, Hyderabad, India, on 6–11 April 2025.
Conflicts of Interest
The author declares no conflicts of interest.
References
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. Fitnets: Hints for thin deep nets. arXiv 2014, arXiv:1412.6550. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. arXiv 2016, arXiv:1612.03928. [Google Scholar]
- Zhao, B.; Cui, Q.; Song, R.; Qiu, Y.; Liang, J. Decoupled knowledge distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11953–11962. [Google Scholar]
- Li, Z.; Jiang, R.; Aarabi, P. Semantic relation preserving knowledge distillation for image-to-image translation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Part XXVI 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 648–663. [Google Scholar]
- Jin, Q.; Ren, J.; Woodford, O.J.; Wang, J.; Yuan, G.; Wang, Y.; Tulyakov, S. Teachers do more than teach: Compressing image-to-image models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 13600–13611. [Google Scholar]
- Zhang, L.; Chen, X.; Tu, X.; Wan, P.; Xu, N.; Ma, K. Wavelet knowledge distillation: Towards efficient image-to-image translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12464–12474. [Google Scholar]
- Hui, Z.; Wang, X.; Gao, X. Fast and accurate single image super-resolution via information distillation network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 723–731. [Google Scholar]
- Fang, H.; Long, Y.; Hu, X.; Ou, Y.; Huang, Y.; Hu, H. Dual cross knowledge distillation for image super-resolution. J. Vis. Commun. Image Represent. 2023, 95, 103858. [Google Scholar] [CrossRef]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H.; Shao, L. Multi-stage progressive image restoration. In Proceedings of the IEEE/CVF Conference on CVPR, Nashville, TN, USA, 20–25 June 2021; pp. 14821–14831. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar]
- Wang, Z.; Cun, X.; Bao, J.; Zhou, W.; Liu, J.; Li, H. Uformer: A general u-shaped transformer for image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 17683–17693. [Google Scholar]
- Chen, X.; Li, H.; Li, M.; Pan, J. Learning a sparse transformer network for effective image deraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 5896–5905. [Google Scholar]
- Fu, X.; Huang, J.; Zeng, D.; Huang, Y.; Ding, X.; Paisley, J. Removing rain from single images via a deep detail network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3855–3863. [Google Scholar]
- Zhang, H.; Patel, V.M. Density-aware single image de-raining using a multi-stream dense network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 695–704. [Google Scholar]
- Nah, S.; Hyun Kim, T.; Mu Lee, K. Deep multi-scale convolutional neural network for dynamic scene deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3883–3891. [Google Scholar]
- Shen, Z.; Wang, W.; Lu, X.; Shen, J.; Ling, H.; Xu, T.; Shao, L. Human-aware motion deblurring. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5572–5581. [Google Scholar]
- Li, B.; Ren, W.; Fu, D.; Tao, D.; Feng, D.; Zeng, W.; Wang, Z. Benchmarking single-image dehazing and beyond. IEEE Trans. Image Process. 2018, 28, 492–505. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, H.; Chen, X.; Deng, Y.; Xu, C.; Wang, Y. Data-free knowledge distillation for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 7852–7861. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 2341–2353. [Google Scholar]
- Fattal, R. Dehazing using color-lines. TOG 2014, 34, 1–14. [Google Scholar] [CrossRef]
- Chan, T.F.; Wong, C.K. Total variation blind deconvolution. IEEE Trans. Image Process. 1998, 7, 370–375. [Google Scholar] [CrossRef]
- Berman, D.; Treibitz, T.; Avidan, S. Non-local image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1674–1682. [Google Scholar]
- Pan, J.; Sun, D.; Pfister, H.; Yang, M.H. Blind image deblurring using dark channel prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1628–1636. [Google Scholar]
- Hu, Z.; Cho, S.; Wang, J.; Yang, M.H. Deblurring low-light images with light streaks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3382–3389. [Google Scholar]
- Li, Y.; Tan, R.T.; Guo, X.; Lu, J.; Brown, M.S. Rain streak removal using layer priors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2736–2744. [Google Scholar]
- Xu, J.; Zhao, W.; Liu, P.; Tang, X. An improved guidance image based method to remove rain and snow in a single image. Comput. Inf. Sci. 2012, 5, 49. [Google Scholar] [CrossRef]
- Meng, G.; Wang, Y.; Duan, J.; Xiang, S.; Pan, C. Efficient image dehazing with boundary constraint and contextual regularization. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 617–624. [Google Scholar]
- Li, Y.; Tan, R.T.; Brown, M.S. Nighttime haze removal with glow and multiple light colors. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 226–234. [Google Scholar]
- Chen, B.H.; Huang, S.C. An advanced visibility restoration algorithm for single hazy images. TOMM 2015, 11, 1–21. [Google Scholar] [CrossRef]
- Ren, W.; Liu, S.; Zhang, H.; Pan, J.; Cao, X.; Yang, M.H. Single image dehazing via multi-scale convolutional neural networks. In Proceedings of the Computer Vision—ECCV 2016, 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2016; pp. 154–169. [Google Scholar]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. Dehazenet: An end-to-end system for single image haze removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef]
- Zhang, H.; Patel, V.M. Densely connected pyramid dehazing network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3194–3203. [Google Scholar]
- Dong, H.; Pan, J.; Xiang, L.; Hu, Z.; Zhang, X.; Wang, F.; Yang, M.H. Multi-scale boosted dehazing network with dense feature fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2157–2167. [Google Scholar]
- Li, H.; Li, J.; Zhao, D.; Xu, L. DehazeFlow: Multi-scale Conditional Flow Network for Single Image Dehazing. In Proceedings of the ACM Multimedia, Chengdu, China, 20–24 October 2021; pp. 2577–2585. [Google Scholar]
- Wang, T.; Yang, X.; Xu, K.; Chen, S.; Zhang, Q.; Lau, R.W. Spatial attentive single-image deraining with a high quality real rain dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12270–12279. [Google Scholar]
- Jiang, K.; Wang, Z.; Yi, P.; Chen, C.; Huang, B.; Luo, Y.; Ma, J.; Jiang, J. Multi-scale progressive fusion network for single image deraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 8346–8355. [Google Scholar]
- Ren, W.; Ma, L.; Zhang, J.; Pan, J.; Cao, X.; Liu, W.; Yang, M.H. Gated fusion network for single image dehazing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3253–3261. [Google Scholar]
- Li, L.; Pan, J.; Lai, W.S.; Gao, C.; Sang, N.; Yang, M.H. Dynamic scene deblurring by depth guided model. IEEE Trans. Image Process. 2020, 29, 5273–5288. [Google Scholar] [CrossRef]
- Guo, C.L.; Yan, Q.; Anwar, S.; Cong, R.; Ren, W.; Li, C. Image dehazing transformer with transmission-aware 3d position embedding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5812–5820. [Google Scholar]
- Duong, M.T.; Lee, S.; Hong, M.C. Learning to Concurrently Brighten and Mitigate Deterioration in Low-Light Images. IEEE Access 2024, 12, 132891–132903. [Google Scholar] [CrossRef]
- Ho, Q.T.; Duong, M.T.; Lee, S.; Hong, M.C. EHNet: Efficient Hybrid Network with Dual Attention for Image Deblurring. Sensors 2024, 24, 6545. [Google Scholar] [CrossRef]
- Duong, M.T.; Nguyen Thi, B.T.; Lee, S.; Hong, M.C. Multi-Branch Network for Color Image Denoising Using Dilated Convolution and Attention Mechanisms. Sensors 2024, 24, 3608. [Google Scholar] [CrossRef] [PubMed]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M. Learning transferable features with deep adaptation networks. In Proceedings of the 32nd International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 97–105. [Google Scholar]
- Bousmalis, K.; Silberman, N.; Dohan, D.; Erhan, D.; Krishnan, D. Unsupervised pixel-level domain adaptation with generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3722–3731. [Google Scholar]
- Tsai, Y.H.; Hung, W.C.; Schulter, S.; Sohn, K.; Yang, M.H.; Chandraker, M. Learning to adapt structured output space for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7472–7481. [Google Scholar]
- Wei, W.; Meng, D.; Zhao, Q.; Xu, Z.; Wu, Y. Semi-supervised transfer learning for image rain removal. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3877–3886. [Google Scholar]
- Shao, Y.; Li, L.; Ren, W.; Gao, C.; Sang, N. Domain adaptation for image dehazing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2808–2817. [Google Scholar]
- Wei, Y.; Zhang, Z.; Wang, Y.; Xu, M.; Yang, Y.; Yan, S.; Wang, M. DerainCycleGAN: Rain attentive cycleGAN for single image deraining and rainmaking. IEEE Trans. Image Process. 2021, 30, 4788–4801. [Google Scholar] [CrossRef]
- Chen, Z.; Wang, Y.; Yang, Y.; Liu, D. PSD: Principled synthetic-to-real dehazing guided by physical priors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 7180–7189. [Google Scholar]
- Tan, X.; Ren, Y.; He, D.; Qin, T.; Zhao, Z.; Liu, T.Y. Multilingual neural machine translation with knowledge distillation. arXiv 2019, arXiv:1902.10461. [Google Scholar]
- Zhang, L.; Song, J.; Gao, A.; Chen, J.; Bao, C.; Ma, K. Be your own teacher: Improve the performance of convolutional neural networks via self distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3713–3722. [Google Scholar]
- Wang, T.; Yuan, L.; Zhang, X.; Feng, J. Distilling object detectors with fine-grained feature imitation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4933–4942. [Google Scholar]
- Ge, S.; Zhao, S.; Li, C.; Li, J. Low-resolution face recognition in the wild via selective knowledge distillation. IEEE Trans. Image Process. 2018, 28, 2051–2062. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, K.; Liu, C.; Qin, Z.; Luo, Z.; Wang, J. Structured knowledge distillation for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2604–2613. [Google Scholar]
- Hong, M.; Xie, Y.; Li, C.; Qu, Y. Distilling image dehazing with heterogeneous task imitation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 3462–3471. [Google Scholar]
- Chen, W.T.; Huang, Z.K.; Tsai, C.C.; Yang, H.H.; Ding, J.J.; Kuo, S.Y. Learning multiple adverse weather removal via two-stage knowledge learning and multi-contrastive regularization: Toward a unified model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 17653–17662. [Google Scholar]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-reference image quality assessment in the spatial domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef]
- Venkatanath, N.; Praneeth, D.; Bh, M.C.; Channappayya, S.S.; Medasani, S.S. Blind image quality evaluation using perception based features. In Proceedings of the Twenty First National Conference on Communications (NCC), Mumbai, India, 27 February–1 March 2015; pp. 1–6. [Google Scholar]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Zhang, K.; Luo, W.; Zhong, Y.; Ma, L.; Stenger, B.; Wei, L.; Li, H. Deblurring by Realistic Blurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2737–2746. [Google Scholar]
- Huynh-Thu, Q.; Ghanbari, M. Scope of validity of PSNR in image/video quality assessment. Electron. Lett. 2008, 44, 800–801. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Ren, D.; Zuo, W.; Hu, Q.; Zhu, P.; Meng, D. Progressive image deraining networks: A better and simpler baseline. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3937–3946. [Google Scholar]
- Wang, H.; Xie, Q.; Zhao, Q.; Meng, D. A model-driven deep neural network for single image rain removal. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 3103–3112. [Google Scholar]
- Zhang, H.; Dai, Y.; Li, H.; Koniusz, P. Deep stacked hierarchical multi-patch network for image deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5978–5986. [Google Scholar]
- Park, D.; Kang, D.U.; Kim, J.; Chun, S.Y. Multi-temporal recurrent neural networks for progressive non-uniform single image deblurring with incremental temporal training. In Proceedings of the European Conference on Computer Vision, ECCV 2020; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany; 2020; pp. 327–343. [Google Scholar] [CrossRef]
- Zhang, B.; Chen, W.; Xu, C.; Qiu, J.; Chen, S. Autonomous Vehicles Traversability Mapping Fusing Semantic–Geometric in Off-Road Navigation. Drones 2024, 8, 496. [Google Scholar] [CrossRef]
- Parra, L.; Ahmad, A.; Zaragoza-Esquerdo, M.; Ivars-Palomares, A.; Sandra, S.; Lloret, J. A Comprehensive Survey of Drones for Turfgrass Monitoring. Drones 2024, 8, 563. [Google Scholar] [CrossRef]
- Shahi, T.B.; Dahal, S.; Sitaula, C.; Neupane, A.; Guo, W. Deep Learning-Based Weed Detection Using UAV Images: A Comparative Study. Drones 2024, 7, 624. [Google Scholar] [CrossRef]
- Su, S.; Yan, L.; Xie, H.; Chen, C.; Zhang, X.; Gao, L.; Zhang, R. Multi-Level Hazard Detection Using a UAV-Mounted Multi-Sensor for Levee Inspection. Drones 2024, 8, 90. [Google Scholar] [CrossRef]
- Yang, W.; Yuan, Y.; Ren, W.; Liu, J.; Scheirer, W.J.; Wang, Z.; Zhang, T.; Zhong, Q.; Xie, D.; Pu, S.; et al. Advancing image understanding in poor visibility environments: A collective benchmark study. IEEE Trans. Image Process. 2020, 29, 5737–5752. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhu, Y.; Wang, T.; Fu, X.; Yang, X.; Guo, X.; Dai, J.; Qiao, Y.; Hu, X. Learning Weather-General and Weather-Specific Features for Image Restoration Under Multiple Adverse Weather Conditions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 21747–21758. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1802.02611v3. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Zhang, Y.; Yan, D. Knowledge Distillation for Image Restoration: Simultaneous Learning from Degraded and Clean Images. arXiv 2025, arXiv:2501.09268. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).