1. Introduction
Optical aerial image object detection involves locating and classifying typical ground objects, such as vehicles, airplanes, and ships, providing important references for decision making in areas like smart cities [
1,
2] and maritime monitoring [
3]. With the increasing number of unmanned aerial vehicles (UAVs) and improvements in image quality, the volume of acquired aerial image data has been growing exponentially. It holds practical value to leverage computer vision technologies to search, detect, and identify various typical objects.
Driven by massive datasets, deep convolutional neural networks (DCNNs) have been widely applied to aerial object detection [
4,
5]. The utilization of large images as input for training deep models requires substantial memory and GPU resources, increasing training time and reducing efficiency [
6]. The input size of deep learning-based aerial object detection models is typically limited to 800 × 800 pixels or smaller. However, images captured by UAV cameras are sometimes extremely large. As shown in
Figure 1a, the released DOTA v2.0 aerial image dataset [
7] contains images approximately 7000 × 5000 pixels in size.
As shown in
Figure 1, given a large-scale UAV image, our research aims to achieve efficient detection of typical objects, balancing both detection speed and accuracy. The objects detected are determined by the categories included in the dataset used to train the model. For example, the DOTA v2.0 dataset contains 18 categories, including planes, ships, storage tanks, and other common objects in aerial imagery.
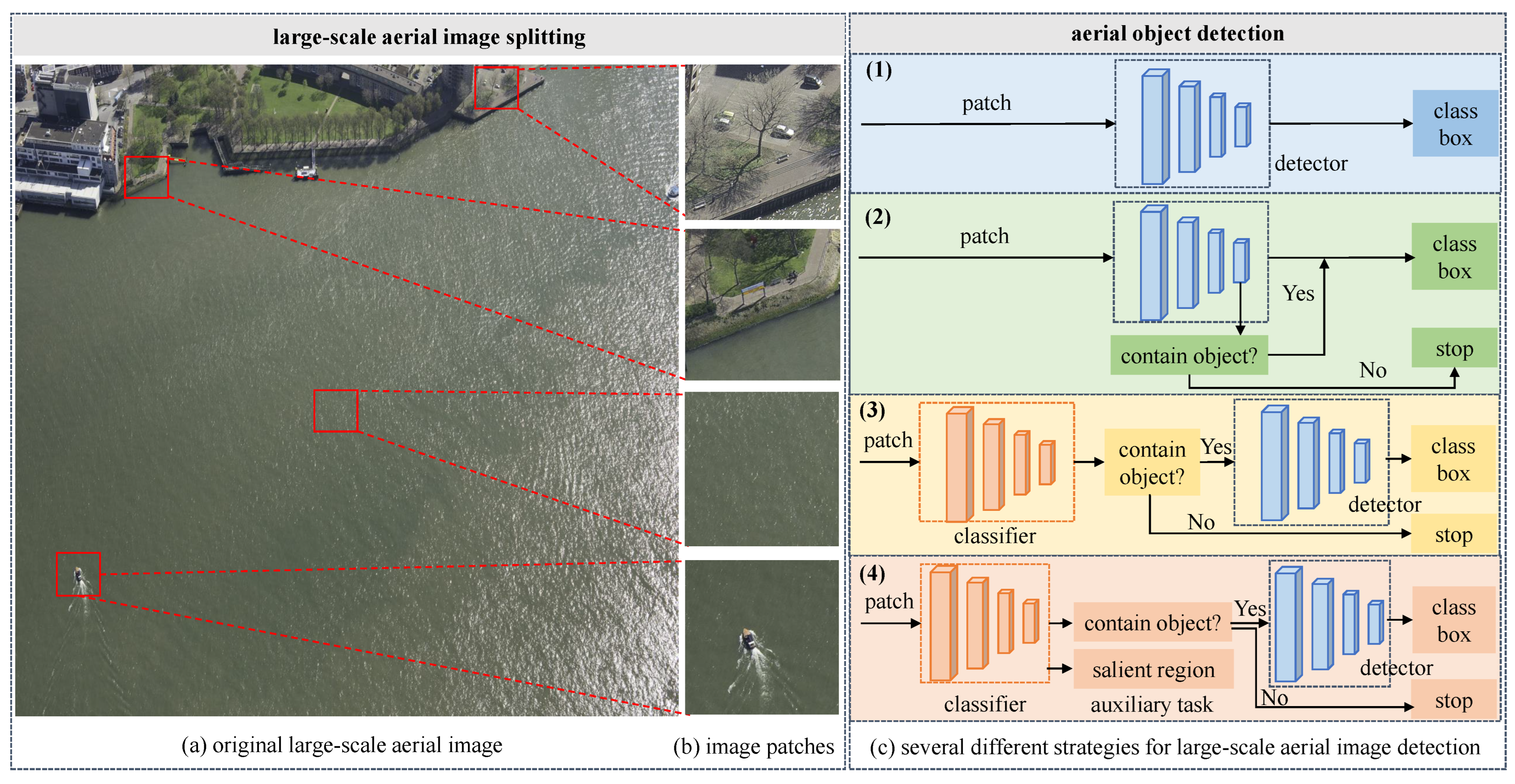
For object detection in large-scale UAV aerial imagery, an adopted approach is to split the original image into overlapping patches. An object detection method is applied on each patch, and the detection results across all patches are merged to achieve detection for the entire image, as illustrated in
Figure 1c(1). To ensure complete coverage of all regions, the YOLT algorithm [
8] segments images with a 15% overlap and uses non-maximum suppression to merge the detection results. For specific tasks such as aircraft and ship detection, domain knowledge can be utilized to improve the processing efficiency of wide-swath aerial images [
9,
10]. For example, aircraft are always distributed around airports, and ships are generally docked at ports or along shorelines. However, these detection methods using prior knowledge are only applicable to objects with distinct distribution characteristics.
As shown in
Figure 1a, large-scale UAV aerial images usually contain a large amount of background areas, with sparsely distributed objects. To address this characteristic, some studies propose a strategy of determining whether objects are present in each image patch before performing object detection. This strategy mainly has two types of network frameworks. The first type involves adding a classification branch to the detector to identify and filter out patches without objects, as illustrated in
Figure 1c(2). Xie et al. [
6] developed an Object Activation Network (OAN) on the final feature map of the detector, while Cao et al. [
11] integrated simple and lightweight object presence detectors into the feature maps at various stages of the backbone network. These methods improve classification accuracy through joint optimization of the classification branch and the detector. The second strategy is to construct a separate binary classifier to determine whether objects are present in the image patch, as depicted in
Figure 1c(3). Pang et al. [
12] designed a lightweight Tiny-Net, using a global attention mechanism to classify image patches. However, due to the independent optimization of the binary classification network and the relatively weakly supervised information, these methods tend to have lower classification accuracy, thereby impacting the detection performance.
To address the challenge of efficient object detection in large-scale UAV aerial imagery, we propose a classification-driven efficient object detection method and design a lightweight multi-task learning classification (MTC) network, as shown in
Figure 1c(4). The UAV cameras are oriented with their optical axes pointing downward, capturing images from a bird’s-eye view. This unique perspective results in objects with varying orientations and arbitrary directions. Most aerial image object detection tasks use oriented bounding boxes for dataset annotation, which compactly enclose the objects. We fully utilize the information embedded in these oriented bounding boxes by using an improved Gaussian function to generate salient regions. Through joint training of a classification network with a salient region generation branch, we improve the discriminative ability of the classification network. Moreover, the salient region generation branch only assists in network training without reducing the inference speed. Without retraining the detector, the constructed MTC performs classification on image patches before detection and is well suited as a preprocessing step for detection models. Additionally, we design a dynamic classification threshold (DCT) setting strategy for the inference, which can balance precision and recall by incorporating the classification confidence score. The proposed method shows strong potential for application in large-scale UAV images with sparse and single-type object distributions, which can achieve real-time detection while maintaining high detection performance. The main contributions of this paper are summarized as follows:
- (1)
We propose a lightweight multi-task learning classification network to rapidly determine the presence or absence of objects in aerial image patches.
- (2)
We construct a salient region generation branch, which is trained jointly with the network as an auxiliary branch to enhance feature learning ability.
- (3)
We propose an optimal threshold generation strategy incorporating confidence scores, which effectively filters backgrounds while maintaining a high object recall rate.
- (4)
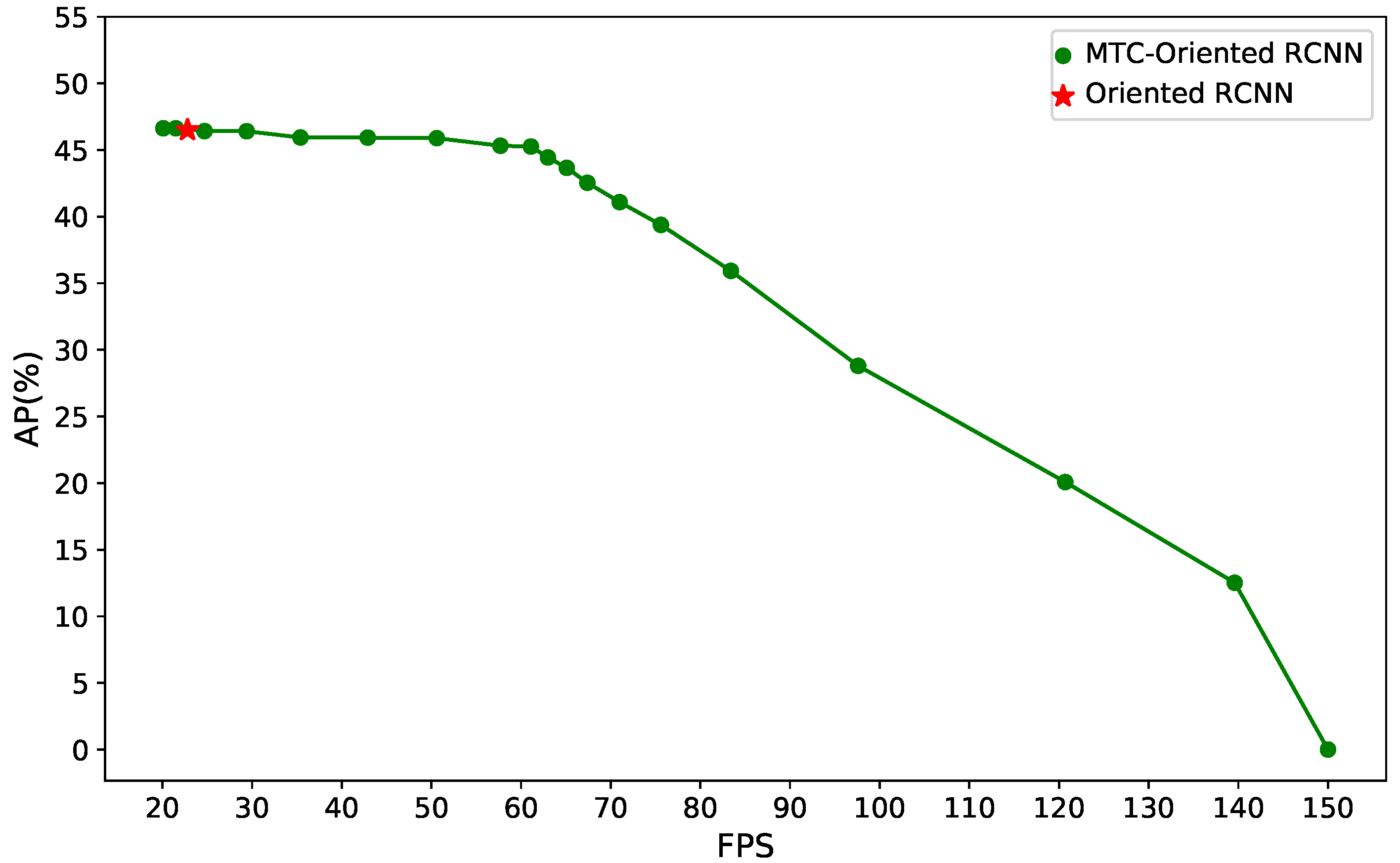
We validate the effectiveness and efficiency of the proposed method for processing large-scale UAV aerial images on three public datasets. On the ASDD dataset [
13], the object detection speed of our proposed method increases by more than 130%, with only a 0.9% decrease in detection performance.
The remainder of this article is structured as follows:
Section 2 provides a review of related works.
Section 3 outlines the overall framework of a classification-driven object detection method and its inference process.
Section 4 presents experimental details and results analysis. Finally,
Section 5 provides the conclusion.
3. Method
3.1. Overall Architecture
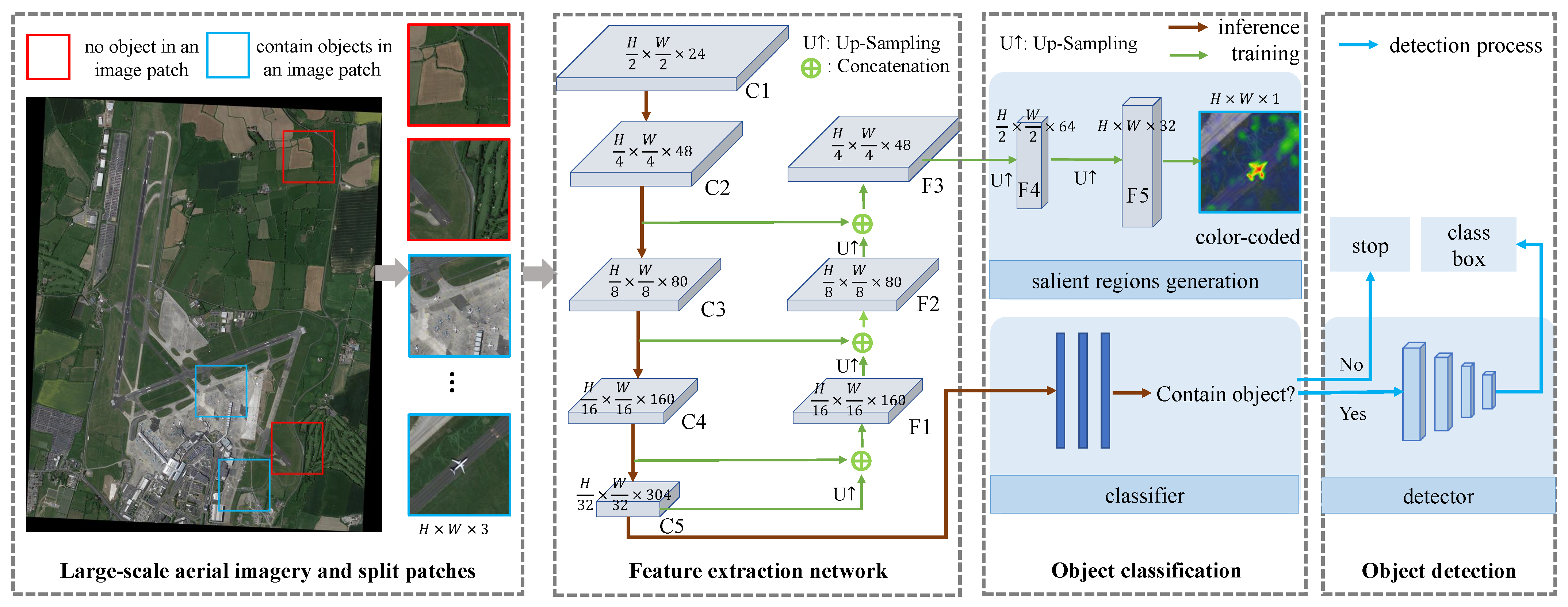
As shown in
Figure 2, the classification-driven MTC-based object detection framework mainly consists of three components: splitting a large-scale image into patches, feature extraction, and object classification. First, the original large-scale aerial image is split into smaller patches with an overlap ratio. Then, based on the information from the labeled bounding boxes, a salient region generation module is constructed as a network branch and jointly trained with the classification branch to improve the feature learning capability. Next, to improve the classification and recognition performance of small objects, a feature fusion module is added to the salient region generation branch. During training, the parameters of the salient region generation branch and the classification branch are optimized jointly. During the inference stage, only the parameters of the classification branch are used, improving classification accuracy while maintaining inference speed.
The lightweight EfficientNetV2 [
49] is used as the backbone for feature extraction. Given an input image of size
, the feature maps C1 (
), C2 (
), C3 (
), C4 (
), and C5 (
) are obtained after five convolutional layers. In the classification branch, the feature map C5 is the input for the fully connected network, and the corresponding output indicates whether an object is present. To improve the discriminative ability of the feature extraction network, a salient region generation branch with a multi-scale feature pyramid is constructed. Specifically, the feature map C5 is upsampled and aggregated with the feature map C4 to obtain the fused feature map F1 (
). Similarly, F2 (
) and F3 (
) are obtained. The feature map F3 is passed through two convolutional layers to generate the salient region result S (
). In
Figure 2, we visualize the salient region using a color-coded map.
3.2. Salient Region Enhancement Branch
In a previous research, Pang et al. [
12] used a lightweight binary classification network to determine whether an image patch contains an object. However, weak classification label supervision results in poor classification performance. To enhance the feature extraction capabilities, we add a salient region generation branch to assist in training the classification network. As shown in
Figure 2, during the upsampling process of the feature map C5, it is fused with the feature map from the previous layer. This fusion helps capture high-level semantic information while also enhancing local detail information. After five upsampling steps and multi-level information fusion, we obtain a mask that is the same size as the original input image. To train the salient region branch, mask supervision information is required. Since the object detection dataset does not provide mask annotations, we generate pseudo-mask supervision information using the object bounding boxes.
As shown in
Figure 3, the labeled bounding boxes used in an aerial object detection task closely enclose the objects, containing information about both the location and the category. We fully explore and utilize this annotation information to generate object salient regions within the oriented bounding box using an improved Gaussian distribution function.
Although the labeled bounding box encloses the object, it is unavailable to use the box region as a segmentation mask, which may result in pixel mislabeling. To represent the differences in salient regions within the oriented bounding box, we use an improved Gaussian-based mask to ensure that the object center has the highest confidence. The confidence values in the remaining regions of the labeled bounding box gradually decrease according to an improved Gaussian distribution. The salient region generation process for objects in UAV aerial images is shown in
Figure 3. First, the oriented bounding box of an object is transformed into a horizontal box by applying an angle rotation, defining the longer and shorter sides as height
h and width
w. Then, around the center of the horizontal box, a confidence value for each pixel within the bounding box is generated using an improved Gaussian distribution function. Finally, the generated confidence distribution map is rotated back by the specified angle to obtain the salient region mask for the original image. The confidence value for each pixel is calculated as follows:
where
and
represent the coordinates of the center point of an object, while
and
are control factors determined by the aspect ratio of the labeled bounding box. The parameters
and
are proportional to the width and height of an object, respectively. In our experiments, the parameters
and
are all set to 0.5. The designed Gaussian-based mask effectively mitigates pixel mislabeling issues and allows the inference of pixel position information based on confidence values.
The designed salient region generation branch leverages additional supervision information (Gaussian-based masks) and integrates multi-level feature map information, which enhances the feature extraction capability of the backbone in the classification network, particularly for discriminative features of small objects.
3.3. Multi-Task Optimization Loss Function
Our proposed classification-driven MTC network contains two learning tasks: image classification and salient region generation. The overall loss function is defined as follows:
where
and
are the classification loss and salient region generation loss, respectively.
is the balancing factor between the two loss functions.
During the preprocessing of large-scale aerial image patches, we categorize all images into two classes: images that contain objects or not. Considering the imbalance between positive and negative samples in large-scale aerial imagery, we employ focal loss to optimize the classification branch, balancing the impact of different samples on model training.
Here, y is the true label, and p denotes the predicted probability. is the Binary Cross Entropy (BCE) loss, is designed to balance positive and negative image patches, and is the predicted probability of the correct class. is the focusing factor, which adjusts the contribution of easily classified samples to the loss.
In the salient region generation branch, we apply BCE loss as the optimization objective. We utilize more comprehensive label information for joint optimization of the MTC network. The salient region generation branch contributes to improving the feature learning capability of the backbone.
3.4. Dynamic Classification Threshold During Inference
During inference, whether an image patch contains an object depends on a hyperparameter: the classification confidence threshold. The setting of this threshold affects the object detection performance. If the confidence threshold is set too low, the MTC network tends to identify more potential objects and will increase the recall rate. However, this also leads to redundant detections, which can slow down subsequent processing. Conversely, if the confidence threshold is set too high, only image patches with high confidence will be further detected. This reduces false positives and redundant detections, improving object detection speed. However, a high confidence threshold may also miss some low-confidence yet valid objects.
In conventional object classification tasks, the threshold is typically set at a fixed value of 0.5. Such a fixed threshold is not well suited for complex and dynamic real-world environments. Therefore, we propose a dynamic classification threshold generation strategy based on the confidence-F1 (
) score [
50]. Specifically,
,
, and
share the same mathematical formulas as
,
, and
, respectively. The difference is that they use continuous (rather than binary) positive and negative values, defined based on the confidence scores generated by the MTC network. In the evaluation metrics for classification tasks,
denotes the number of object images correctly classified,
represents the number of object images incorrectly classified as background, and
denotes the number of background images incorrectly identified as objects. The confidence-based
(
) and confidence-based
(
) are defined as follows:
where
denotes the confidence score output by the MTC network,
represents the image patch class, and
is the prediction class.
Based on the definitions of
and
, we calculate
,
, and
using the following formulas:
It can be seen that the denominator of remains the same as that of standard without incorporating the probabilistic extensions of and , as represents the total number of image patches. Based on the scores calculated at different threshold settings on a validation dataset, we select the threshold corresponding to the highest score as the optimal classification threshold for the inference stage. This strategy dynamically adjusts the confidence threshold by analyzing the data distribution characteristics in practical applications. The classification-driven detection model can adaptively balance the object recall rate and detection speed under different conditions.
3.5. Model Training and Inference
During the training stage, we jointly optimize the classification and the salient region generation branches using the loss function defined in
Section 3.3, promoting mutual enhancement through shared learning objectives. The additional supervision information provided by the salient region generation branch strengthens the feature extraction capability of the classification branch, improving the classification performance and robustness of the entire network.
In the inference stage, we only use the classification branch to determine whether the image patch contains an object. Additionally, we prune the parameters of the salient region generation branch to reduce the computational complexity and memory usage, which improves inference speed and overall object detection efficiency. In practical large-scale UAV application scenarios, our classification-driven method can achieve rapid and effective aerial object detection.
5. Conclusions
In this study, we propose a multi-task classification-driven object detection method to achieve fast and effective processing of large-scale UAV aerial images. We design a lightweight classification network with a salient region generation branch. By incorporating additional supervisory information and leveraging multi-task learning, our approach improves the classification accuracy in identifying whether aerial image patches contain objects. In addition, we develop a DCL strategy that allows flexible threshold adjustment during inference. Our proposed MTC network can be combined with various detectors without the need for retraining, improving the adaptability and applicability of the detectors. Our MTC-based detector can rapidly identify object-containing regions, focusing computational resources on these areas for further detection. Specifically, the proposed detection method is well suited for scenarios requiring rapid, efficient processing of large-scale UAV aerial imagery with extensive non-object areas. Experimental results demonstrate the effectiveness and efficiency of our proposed method, with detection performance for large aerial images from the DOTA v2.0 dataset slightly decreased while achieving an improvement of over 30% in detection speed. In future research, we will explore combining the proposed MTC with lightweight detectors to enable real-time processing on UAVs.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}