
Research on Cooperative Obstacle Avoidance Decision Making of Unmanned Aerial Vehicle Swarms in Complex Environments under End-Edge-Cloud Collaboration Model


Abstract
1. Introduction
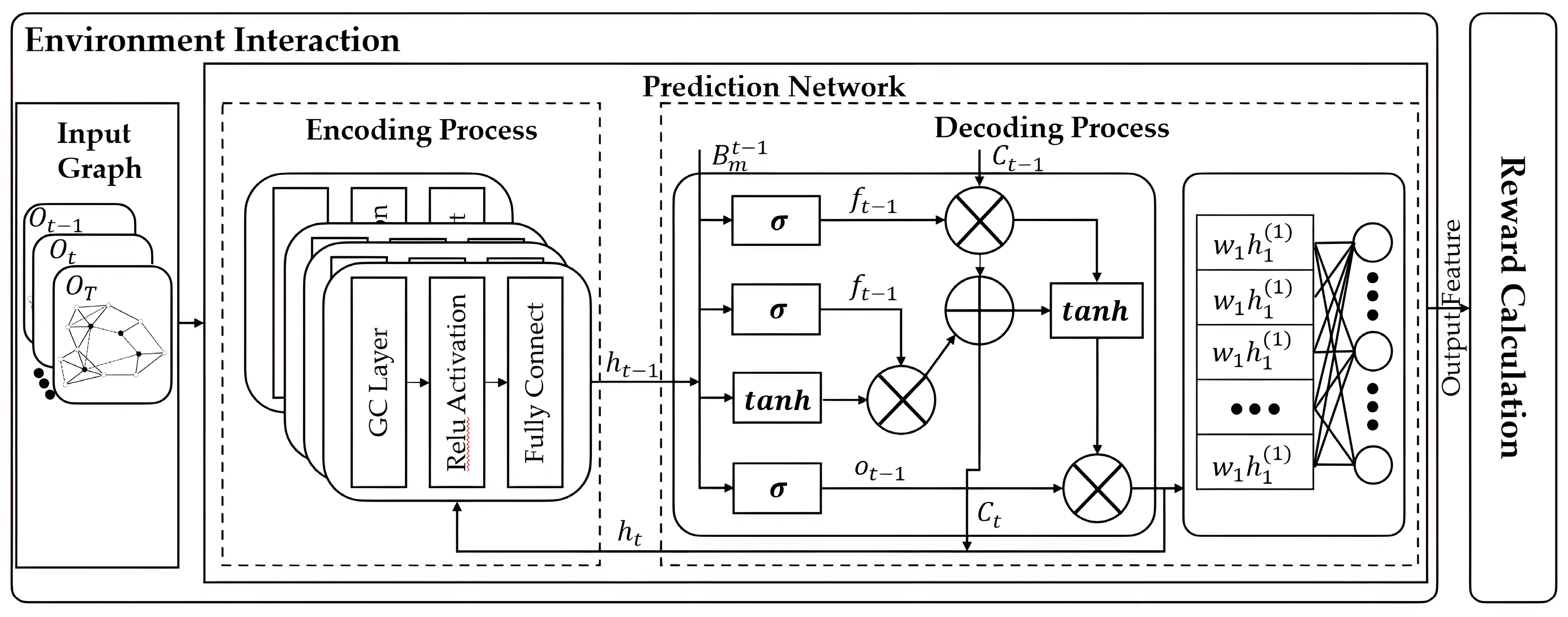
- This paper proposes an environmental information prediction network leveraging dynamic spatiotemporal graph convolution, designed to overcome the challenge of low obstacle prediction accuracy in complex environments due to frequent spatiotemporal variations. By integrating the spatial relationships among drone nodes and applying constraints from dynamic models, the network achieves precise predictions of complex environmental states, thereby enhancing both the understanding and predictive capabilities in these challenging scenarios.
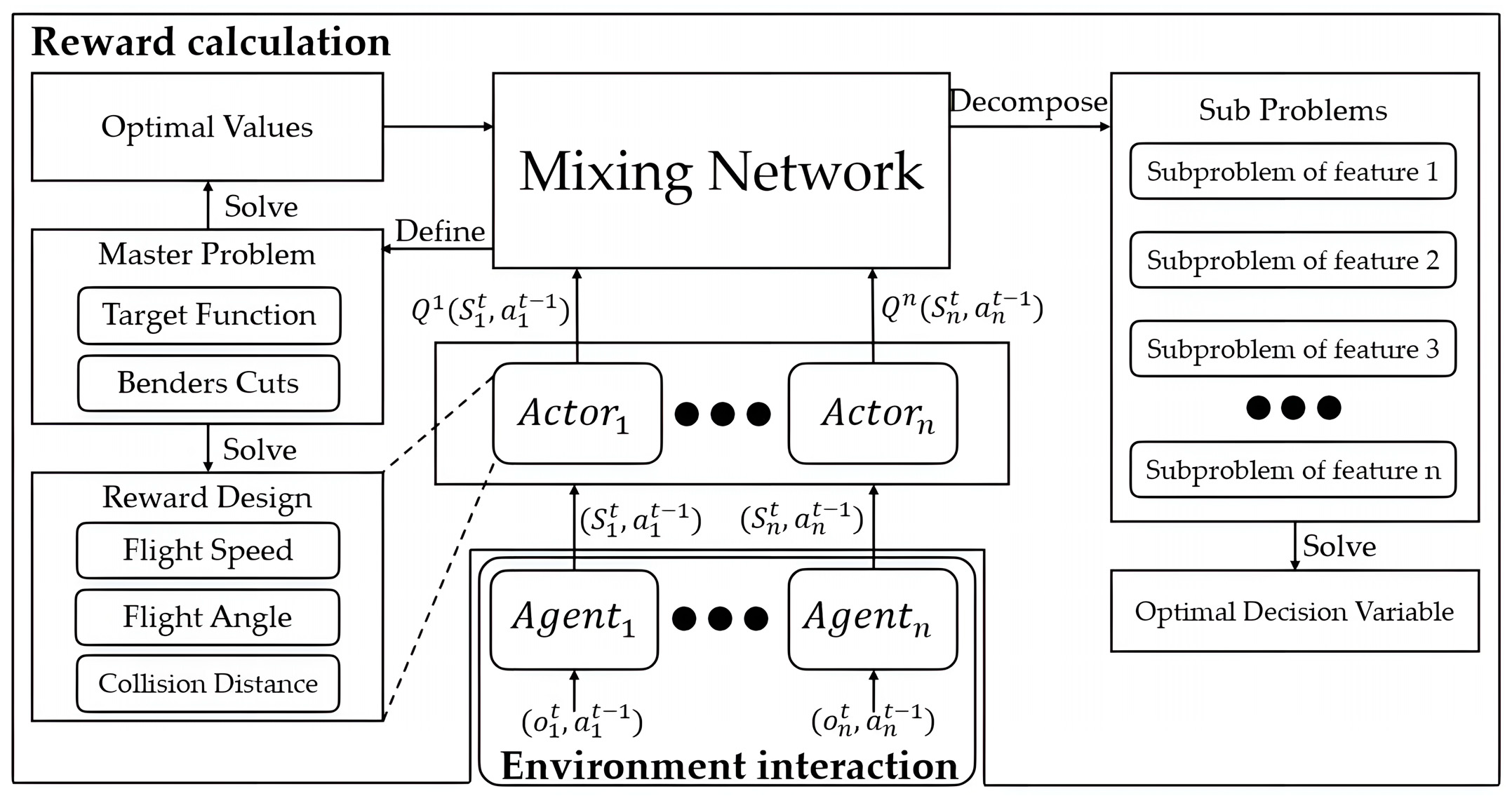
- Utilizing the state information generated by the prediction network, this paper proposes a reward decomposition strategy based on hybrid credit allocation, which transforms sparse rewards in the flight environment into dense rewards. This approach provides more refined feedback for intelligent decision making, enabling more accurate assessment of multi-agent decisions and optimizing the strategy update process, ultimately leading to more reliable swarm control.
- To expedite the learning and optimization of decision-making processes, this paper proposes a dual-experience pool with a prioritized parallel-replay structure. By categorizing experience data into safe and dangerous samples and prioritizing high-priority samples for training, this structure fully utilizes historical data, improving data learnability and accelerating model convergence.
2. Related Work
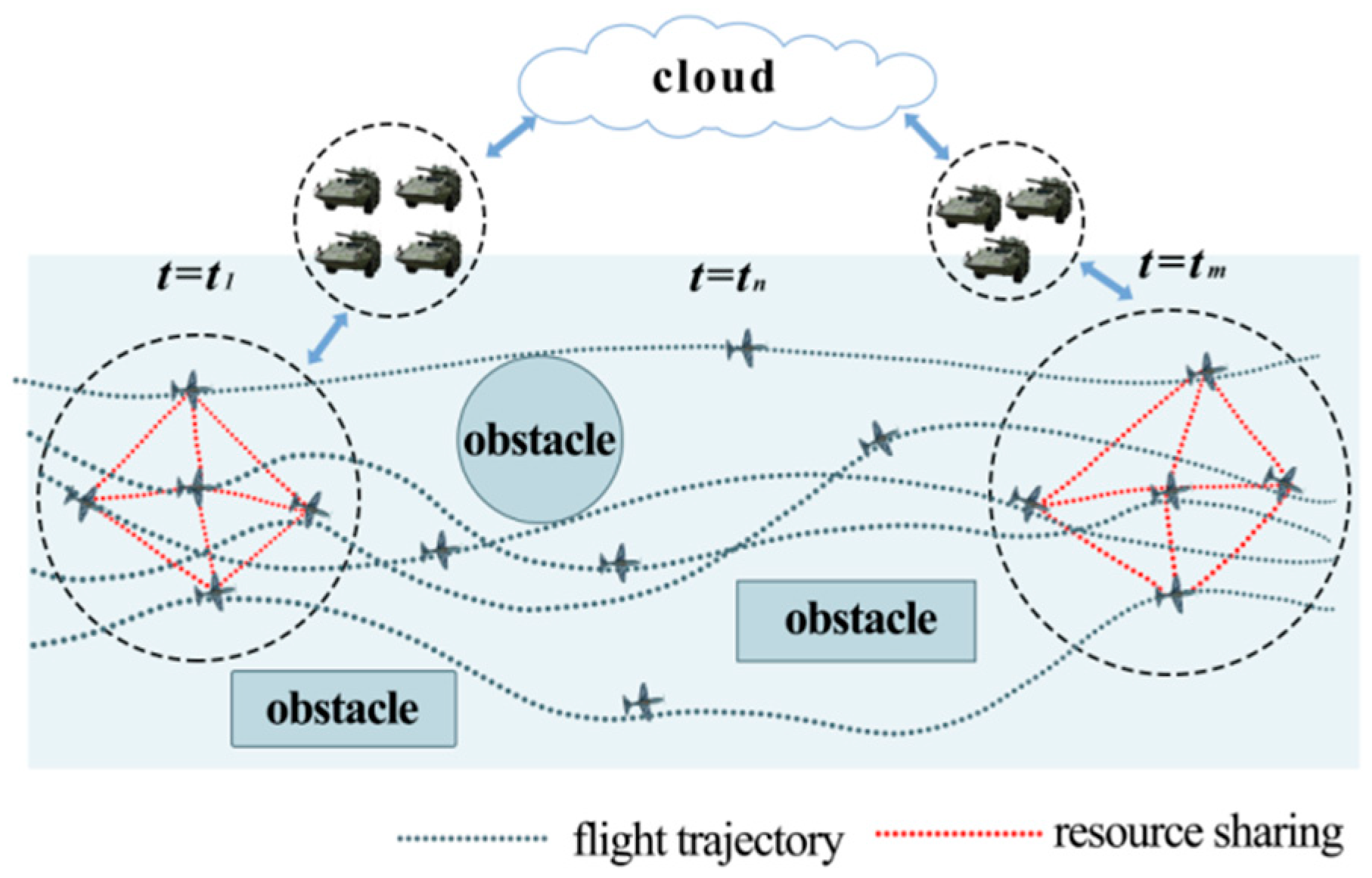
3. UAV Swarm Obstacle Avoidance Decision-Making Method Based on End-Edge-Cloud Collaboration Model
3.1. Problem Statement
3.2. Problem Modeling and Analysis
3.3. System Structure
3.4. Resources and Environment
3.5. Reward Calculation
3.6. Policy Update
3.7. Pseudo-Code of Collaborative Obstacle Avoidance Decision-Making Algorithm
| Algorithm 1. Obstacle avoidance decision-making method for UAV swarms. |
| function EdgeServer (): Observe state satisfies the constraints of the drone dynamics model for k = 0 to train_steps_limits do env.reset() for t = 0 to max_episode do For each agent i, choose action Extracted the global action feature based on GCN () w.r.t Equation (5) Concatenate into Take into UAV swarm graph and get save state-action history for agent i in N do The total reward value for each drone. w.r.t Equation (6) end for Iterative solve master problem and sub problems w.r.t Equations (7) and (8) Store (, a, r, ) in replay buffer D w.r.t Equations (9) and (10) end for = CloudServer(D) end for select action according to the current policy return end function ray.init(address = CloudServer_config[‘cloud_node_ip_address’] @ray.remote function CloudServer (D): if |D| > batch_size then for t = 1 to T do Sample minibatch B from D Generate flight state information s Update critic network w.r.t Equation (12) Update policy network Update encoding network Update temperature parameter w.r.t. Equation (13) if time_to_update_target_network then end if end for end if return end function |
4. Experimental Analysis
- Obstacle avoidance efficiency: The obstacle avoidance efficiency of the UAV swarm is evaluated, specifically in terms of the swarm’s ability to quickly and safely navigate around obstacles within a predefined operational timeframe.
- Formation stability: The stability of the relative position and attitude among the UAVs in the swarm is evaluated, which can be measured by the stability of the position deviation, and attitude deviation of the swarm.
- Formation integrity: The degree to which the overall structure of a drone swarm maintains its integrity during flight is evaluated, ensuring the safety and effectiveness of the drone swarm while performing tasks.
4.1. Experimental Setup
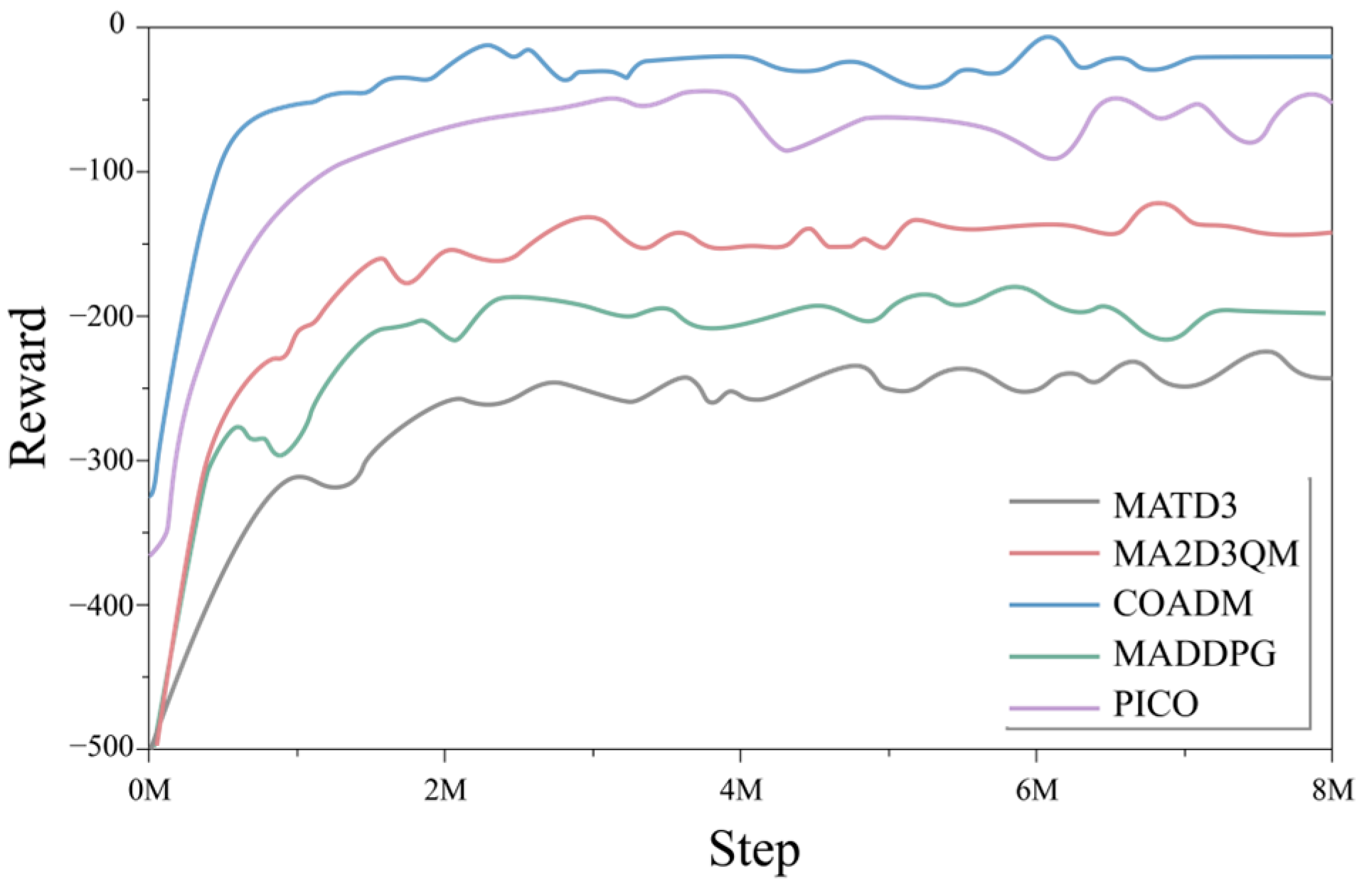
4.2. Experimental Results
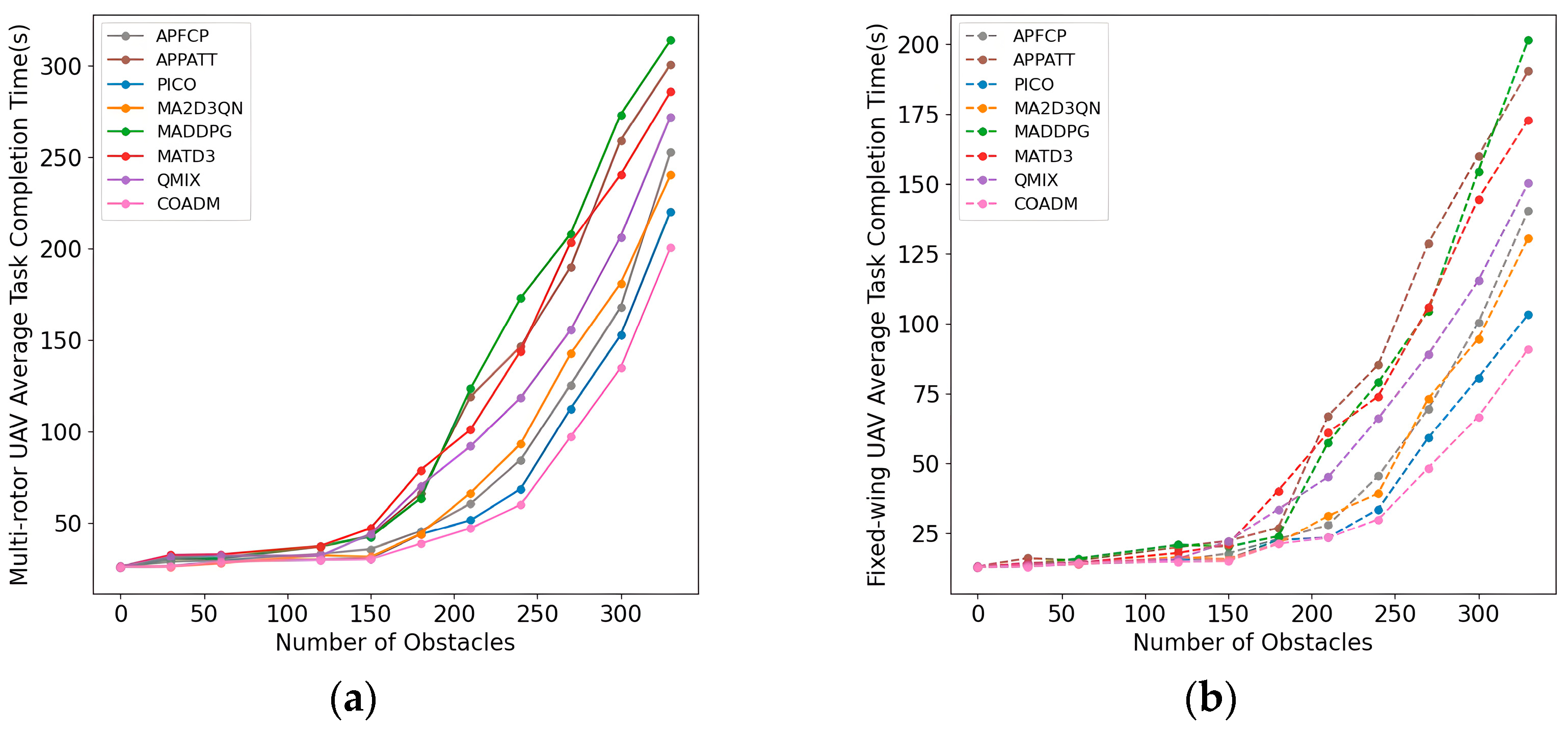
- Research indicator 1: Obstacle avoidance efficiency
- Research indicator 2: swarm stability
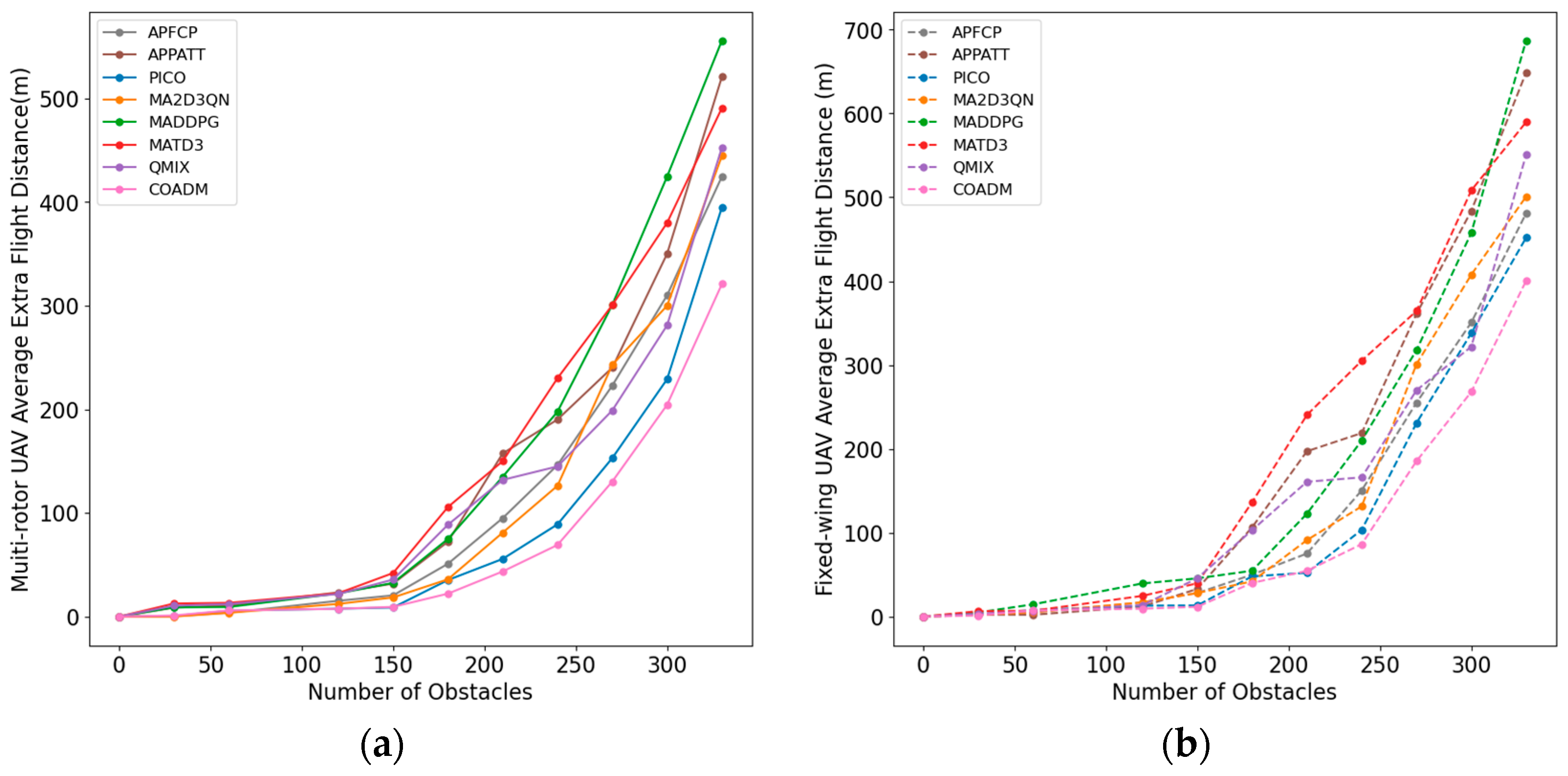
- Research indicator 3: swarm integrity
5. Future Work
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hacohen, S.; Shoval, S.; Shvalb, N. Navigation function for multi-agent multi-target interception missions. IEEE Access 2024, 12, 56321–56333. [Google Scholar] [CrossRef]
- D’Ippolito, F.; Garraffa, G.; Sferlazza, A.; Zaccarian, L. A hybrid observer for localization from noisy inertial data and sporadic position measurements. Nonlinear Anal. Hybrid Syst. 2023, 49, 101360. [Google Scholar] [CrossRef]
- Alvarez-Horcajo, J.; Martinez-Yelmo, I.; Rojas, E.; Carral, J.A.; Noci-Luna, V. MuHoW: Distributed protocol for resource sharing in collaborative edge-computing networks. Comput. Netw. 2024, 242, 110243. [Google Scholar] [CrossRef]
- John, J.; Harikumar, K.; Senthilnath, J.; Sundaram, S. An efficient approach with dynamic multiswarm of UAVs for forest firefighting. IEEE Trans. Syst. Man Cybern. Syst. 2024, 54, 2860–2871. [Google Scholar] [CrossRef]
- Marek, D.; Paszkuta, M.; Szyguła, J.; Biernacki, P.; Domański, A.; Szczygieł, M.; Król, M.; Wojciechowski, K. Swarm of drones in a simulation environment—Efficiency and adaptation. Appl. Sci. 2024, 14, 3703. [Google Scholar] [CrossRef]
- Phadke, A.; Medrano, F.A.; Chu, T.; Sekharan, C.N.; Starek, M.J. Modeling wind and obstacle disturbances for effective performance observations and analysis of resilience in UAV swarms. Aerospace 2024, 11, 237. [Google Scholar] [CrossRef]
- Phillips, G.; Bradley, J.M.; Fernando, C. A deployable, decentralized hierarchical reinforcement learning strategy for trajectory planning and control of UAV swarms. In Proceedings of the AIAA SCITECH 2024 Forum, Orlando, FL, USA, 8–12 January 2024; American Institute of Aeronautics and Astronautics: Orlando, FL, USA, 2024; p. AIAA 2024-2761. [Google Scholar] [CrossRef]
- Liu, H.; Li, X.; Fan, M.; Wu, G.; Pedrycz, W.; Nagaratnam Suganthan, P. An autonomous path planning method for unmanned aerial vehicle based on a tangent intersection and target guidance strategy. IEEE Trans. Intell. Transp. Syst. 2022, 23, 3061–3073. [Google Scholar] [CrossRef]
- Wu, Y.; Low, K.H. Discrete space-based route planning for rotary-wing UAV formation in urban environments. ISA Trans. 2022, 129, 243–259. [Google Scholar] [CrossRef] [PubMed]
- Zhou, X.; Wang, Z.; Wen, X.; Zhu, J.; Xu, C.; Gao, F. Decentralized spatial-temporal trajectory planning for multicopter swarms. arXiv 2021, arXiv:2106.12481. [Google Scholar] [CrossRef]
- Zhang, Z.; Dai, W.; Li, G.; Chen, X.; Deng, Q. Cooperative obstacle avoidance algorithm based on improved artificial potential field and consensus protocol. J. Comput. Appl. 2023, 43, 2644–2650. [Google Scholar] [CrossRef]
- Ko, Y.-C.; Gau, R.-H. UAV velocity function design and trajectory planning for heterogeneous visual coverage of terrestrial regions. IEEE Trans. Mobile Comput. 2023, 22, 6205–6222. [Google Scholar] [CrossRef]
- Quan, L.; Yin, L.; Xu, C.; Gao, F. Distributed swarm trajectory optimization for formation flight in dense environments. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; IEEE: Philadelphia, PA, USA, 2022; pp. 4979–4985. [Google Scholar] [CrossRef]
- Tong, X.; Yu, S.; Liu, G.; Niu, X.; Xia, C.; Chen, J.; Yang, Z.; Sun, Y. A hybrid formation path planning based on A* and multi-target improved artificial potential field algorithm in the 2D random environments. Adv. Eng. Inf. 2022, 54, 101755. [Google Scholar] [CrossRef]
- Yan, C.; Wang, C.; Xiang, X.; Lan, Z.; Jiang, Y. Deep reinforcement learning of collision-free flocking policies for multiple fixed-wing UAVs using local situation maps. IEEE Trans. Industr. Inform. 2022, 18, 1260–1270. [Google Scholar] [CrossRef]
- Lu, C.; Shi, Y.; Zhang, H.; Zhang, M.; Wang, T.; Yue, T.; Ali, S. Learning configurations of operating environment of autonomous vehicles to maximize their collisions. IEEE Trans. Softw. Eng. 2023, 49, 384–402. [Google Scholar] [CrossRef]
- Wang, T.; Du, X.; Chen, M.; Li, K. Hierarchical relational graph learning for autonomous multirobot cooperative navigation in dynamic environments. IEEE Trans. Comput. Aided Des. Integr. Circuit Syst. 2023, 42, 3559–3570. [Google Scholar] [CrossRef]
- Xia, X.; Chen, F.; He, Q.; Cui, G.; Grundy, J.; Abdelrazek, M.; Bouguettaya, A.; Jin, H. OL-MEDC: An online approach for cost-effective data caching in mobile edge computing systems. IEEE Trans. Mobile Comput. 2023, 22, 1646–1658. [Google Scholar] [CrossRef]
- Chen, Q.; Meng, W.; Quek, T.Q.S.; Chen, S. Multi-tier hybrid offloading for computation-aware IoT applications in civil aircraft-augmented SAGIN. IEEE J. Sel. Areas Commun. 2023, 41, 399–417. [Google Scholar] [CrossRef]
- Sagor, M.; Haroon, A.; Stoleru, R.; Bhunia, S.; Altaweel, A.; Chao, M.; Jin, L.; Maurice, M.; Blalock, R. DistressNet-NG: A resilient data storage and sharing framework for mobile edge computing in cyber-physical systems. ACM Trans. Cyber Phys. Syst. 2024, 8, 37. [Google Scholar] [CrossRef]
- Saifullah, M.; Papakonstantinou, K.G.; Andriotis, C.P.; Stoffels, S.M. Multi-agent deep reinforcement learning with centralized training and decentralized execution for transportation infrastructure management. arXiv 2024, arXiv:2401.12455. [Google Scholar] [CrossRef]
- Wu, R.-Y.; Xie, X.-C.; Zheng, Y.-J. Firefighting drone configuration and scheduling for wildfire based on loss estimation and minimization. Drones 2024, 8, 17. [Google Scholar] [CrossRef]
- Sönmez, S.; Rutherford, M.J.; Valavanis, K.P. A survey of offline- and online-learning-based algorithms for multirotor UAVs. Drones 2024, 8, 116. [Google Scholar] [CrossRef]
- Sharma, M.; Tomar, A.; Hazra, A. Edge computing for industry 5.0: Fundamental, applications and research challenges. IEEE Internet Things J. 2024, 11, 19070–19093. [Google Scholar] [CrossRef]
- Zhou, X.; Yu, X.; Guo, K.; Zhou, S.; Guo, L.; Zhang, Y.; Peng, X. Safety flight control design of a quadrotor UAV with capability analysis. IEEE Trans. Cybern. 2023, 53, 1738–1751. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Zhang, X.; Zhao, X.; Zhong, Z.; Zhu, X. Land battlefield intelligent information system design under distributed operation conditions. J. Command Control 2023, 9, 192–203. [Google Scholar] [CrossRef]
- Shao, J.; Lou, Z.; Zhang, H.; Jiang, Y.; He, S.; Ji, X. Self-organized group for cooperative multi-agent reinforcement learning. In Proceedings of the 36th Conference on Neural Information Processing Systems (NeurIPS 2022), New Orleans, LA, USA, 28 November–9 December 2022; Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A., Eds.; Neural Information Processing Systems Foundation: New Orleans, LA, USA, 2022; pp. 5711–5723. [Google Scholar]
- Duan, J.; Guan, Y.; Li, S.E.; Ren, Y.; Sun, Q.; Cheng, B. Distributional soft actor-critic: Off-policy reinforcement learning for addressing value estimation errors. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 6584–6598. [Google Scholar] [CrossRef] [PubMed]
- Hu, S.; Zhong, Y.; Gao, M.; Wang, W.; Dong, H.; Liang, X.; Li, Z.; Chang, X.; Yang, Y. MARLlib: A scalable and efficient multi-agent reinforcement learning library. J. Mach. Learn. Res. 2023, 24, 1–23. [Google Scholar]
- Zhou, M.; Wan, Z.; Wang, H.; Wen, M.; Wu, R.; Wen, Y.; Yang, Y.; Yu, Y.; Wang, J.; Zhang, W. MALib: A parallel framework for population-based multi-agent reinforcement learning. J. Mach. Learn. Res. 2023, 24, 1–12. [Google Scholar]
- Wang, Q.; Ju, F.; Wang, H.; Qian, Y.; Zhu, M.; Zhuang, W.; Wang, L. Multi-agent reinforcement learning for ecological car-following control in mixed traffic. IEEE Trans. Transp. Electrif. 2024. [Google Scholar] [CrossRef]
- Guo, W.; Liu, G.; Zhou, Z.; Wang, L.; Wang, J. Enhancing the robustness of QMIX against state-adversarial attacks. Neurocomputing 2024, 572, 127191. [Google Scholar] [CrossRef]
- Zhao, E.; Zhou, N.; Liu, C.; Su, H.; Liu, Y.; Cong, J. Time-aware MADDPG with LSTM for multi-agent obstacle avoidance: A comparative study. Complex Intell. Syst. 2024, 10, 4141–4155. [Google Scholar] [CrossRef]
- Zhao, R.; Liu, X.; Zhang, Y.; Li, M.; Zhou, C.; Li, S.; Han, L. CraftEnv: A flexible collective robotic construction environment for multi-agent reinforcement learning. In Proceedings of the 2023 International Conference on Autonomous Agents and Multiagent Systems, London, UK, 29 May–2 June 2023; pp. 1164–1172. [Google Scholar]
- Tariverdi, A.; Côté-Allard, U.; Mathiassen, K.; Elle, O.J.; Kalvoy, H.; Martinsen, Ø.G.; Torresen, J. Reinforcement learning-based switching controller for a milliscale robot in a constrained environment. IEEE Trans. Autom. Sci. Eng. 2024, 21, 2000–2016. [Google Scholar] [CrossRef]
- Teng, M.; Gao, C.; Wang, Z.; Li, X. A communication-based identification of critical drones in malicious drone swarm networks. Complex Intell. Syst. 2024, 10, 3197–3211. [Google Scholar] [CrossRef]
- Chen, D.; Qi, Q.; Fu, Q.; Wang, J.; Liao, J.; Han, Z. Transformer-based reinforcement learning for scalable multi-UAV area coverage. IEEE Trans. Intell. Transp. Syst. 2024, 25, 10062–10077. [Google Scholar] [CrossRef]
- Zeng, T.; Zhang, X.; Duan, J.; Yu, C.; Wu, C.; Chen, X. An offline-transfer-online framework for cloud-edge collaborative distributed reinforcement learning. IEEE Trans. Parallel. Distrib. Syst. 2024, 35, 720–731. [Google Scholar] [CrossRef]
- Wang, S.; Feng, T.; Yang, H.; You, X.; Chen, B.; Liu, T.; Luan, Z.; Qian, D. AtRec: Accelerating recommendation model training on CPUs. IEEE Trans. Parallel. Distrib. Syst. 2024, 35, 905–918. [Google Scholar] [CrossRef]
- Luo, F.-M.; Xu, T.; Lai, H.; Chen, X.-H.; Zhang, W.; Yu, Y. A survey on model-based reinforcement learning. Sci. China Inf. Sci. 2024, 67, 121101. [Google Scholar] [CrossRef]
- Grosfils, P. Information transmission in a drone swarm: A temporal network analysis. Drones 2024, 8, 28. [Google Scholar] [CrossRef]
- Javed, S.; Hassan, A.; Ahmad, R.; Ahmed, W.; Ahmed, R.; Saadat, A.; Guizani, M. State-of-the-art and future research challenges in UAV swarms. IEEE Internet Things J. 2024, 11, 19023–19045. [Google Scholar] [CrossRef]
- Galliera, R.; Möhlenhof, T.; Amato, A.; Duran, D.; Venable, K.B.; Suri, N. Distributed autonomous swarm formation for dynamic network bridging. arXiv 2024, arXiv:2404.01557. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Advantages | Limitations |
|---|---|---|
| APPATT | Uses the elliptical tangent graph method to quickly generate two obstacle avoidance trajectories when encountering obstacles. | Requires many parameters and relies on expert experience and experimental validation, leading to difficulties in parameter tuning. |
| APFCP | Uses normalization and high-order exponential scaling transformations to address the oscillation failure of potential field forces. | Repulsive field effects make it difficult for UAVs to adjust the direction near trajectory points when avoiding obstacles. |
| PICO | Adapts the formation shape in narrow spaces adaptively by measuring formation similarity. | Requires a large storage space, leading to issues such as flight trajectory fluctuations and paths that are not flyable. |
| MA2D3QN | Improves model learning efficiency through adaptive mechanisms and reference point guidance strategies. | Complex neural network structures and multi-agent parallel learning require significant computational resources. |
| COADM | Proposes a cluster obstacle avoidance method with high efficiency and strong flexibility, reducing decision biases. | Advanced perception algorithms are needed to enhance UAV perception accuracy in complex environments. |
| Type | Parameter | Value |
|---|---|---|
| Edge server | Operating system | Ubuntu 18.04 |
| Processor | Intel Core i7-1260P | |
| Memory | 8 GB | |
| Hard disk | 50 GB | |
| Network card | I219-V | |
| Graphics card | NVIDIA Tesla K80 | |
| Cloud server | Operating system | Ubuntu 20.04 |
| Processor | Intel Xeon Gold 6328H | |
| Memory | 372 GB | |
| Hard disk | 10 TB | |
| Network card | I350-US | |
| Graphics card | NVIDIA T4 | |
| UAV simulation platform | Operating system | Ubuntu 18.04 |
| Processor | Intel Core i7-1260P | |
| Memory | 8 GB | |
| Hard disk | 50 GB | |
| Network card | I219-V | |
| Graphics card | NVIDIA Tesla K80 |
| Type | ID | Mass | |||||
|---|---|---|---|---|---|---|---|
| Multi−rotor | 100 m | 1.05 kg | 0.48 | ||||
| 100 m | 1.05 kg | 0.48 | |||||
| 100 m | 1.05 kg | 0.48 | |||||
| 100 m | 1.05 kg | 0.48 | |||||
| 100 m | 1.05 kg | 0.48 | |||||
| 100 m | 1.05 kg | 0.48 | |||||
| 100 m | 1.05 kg | 0.48 | |||||
| Fixed-wing | 250 m | 3.2 kg | 0.054 | ||||
| 250 m | 3.2 kg | 0.054 | |||||
| 250 m | 3.2 kg | 0.054 | |||||
| 250 m | 3.2 kg | 0.054 | |||||
| 250 m | 3.2 kg | 0.054 | |||||
| 250 m | 3.2 kg | 0.054 | |||||
| 250 m | 3.2 kg | 0.054 |
| Parameter | Value | Description |
|---|---|---|
| actor_learning_rate | 0.0003 | Actor network learning rate |
| critic_learning_rate | 0.0003 | Critic network learning rate |
| alpha_learning_rate | 0.0003 | Alpha network learning rate |
| agent_num | 7 | Number of agents |
| safety_buffer | 50,000 | Safe-sample experience pool |
| danger_buffer | 50,000 | Dangerous-sample experience pool |
| network_noise | 0.8 | Network noise |
| rnn_hidden_dim | 128 | RNN hidden-layer dimensions |
| qmix_hidden_dim | 128 | Mixed-network hidden-layer dimensions |
| gamma | 0.99 | Discount rate |
| entropy | 0.2 | Policy entropy |
| episodes | 60,000 | Episodes |
| net_update_rate | 0.001 | Network update rate |
| stepsize | 3,000,000 | Maximum step size for a single experiment |
| simulation_stepsize | 0.01 | Simulation step size/s |
| Type | Algorithm | |
|---|---|---|
| Multi-rotor | APPATT | 0.173 |
| APFCP | 0.171 | |
| MA2D3QN | 0.162 | |
| PICO | 0.160 | |
| QMIX | 0.193 | |
| MATD3 | 0.210 | |
| MADDPG | 0.232 | |
| COADM | 0.130 | |
| Fixed-wing | APPATT | 0.332 |
| APFCP | 0.283 | |
| MA2D3QN | 0.294 | |
| PICO | 0.243 | |
| QMIX | 0.356 | |
| MATD3 | 0.425 | |
| MADDPG | 0.399 | |
| COADM | 0.197 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, L.; Chen, B.; Hu, F. Research on Cooperative Obstacle Avoidance Decision Making of Unmanned Aerial Vehicle Swarms in Complex Environments under End-Edge-Cloud Collaboration Model. Drones 2024, 8, 461. https://doi.org/10.3390/drones8090461
Zhao L, Chen B, Hu F. Research on Cooperative Obstacle Avoidance Decision Making of Unmanned Aerial Vehicle Swarms in Complex Environments under End-Edge-Cloud Collaboration Model. Drones. 2024; 8(9):461. https://doi.org/10.3390/drones8090461
Chicago/Turabian StyleZhao, Longqian, Bing Chen, and Feng Hu. 2024. "Research on Cooperative Obstacle Avoidance Decision Making of Unmanned Aerial Vehicle Swarms in Complex Environments under End-Edge-Cloud Collaboration Model" Drones 8, no. 9: 461. https://doi.org/10.3390/drones8090461
APA StyleZhao, L., Chen, B., & Hu, F. (2024). Research on Cooperative Obstacle Avoidance Decision Making of Unmanned Aerial Vehicle Swarms in Complex Environments under End-Edge-Cloud Collaboration Model. Drones, 8(9), 461. https://doi.org/10.3390/drones8090461