
Reinforcement-Learning-Based Multi-UAV Cooperative Search for Moving Targets in 3D Scenarios

Abstract
1. Introduction
- Model and problem formulation: A multi-UAV high–low altitude collaborative search architecture is proposed by taking into account the varied detection capabilities of UAVs at different flight altitudes. Under the constraints of UAVs’ flight distances, detection abilities, and collision avoidance, an optimization problem for multi-UAV cooperative search for moving targets in a 3D scenario is established to minimize the uncertainty of the search area and maximize the number of captured moving targets.
- Algorithm design: Firstly, a rule-based target capture mechanism is designed to fully utilize the advantages of the extensive field of view of high-altitude UAVs and the high detection quality of low-altitude UAVs. Secondly, an action-mask-based collision avoidance mechanism is designed to eliminate the risk of collisions between UAVs. Thirdly, a field-of-view-encoding-based state representation mechanism is introduced to address dynamic changes in the input dimensions of neural networks. Finally, to address the problem of low learning efficiency caused by the ineffective actions of UAVs in boundary states and the potential for dangerous actions in collision-risk situations, an improved MAPPO algorithm is proposed.
- Experimental verification: To verify the performance of our proposed algorithm, it is compared with other DRL-based methods, including VDN, QMIX, and MAPPO, through simulation. The simulation results demonstrate the proposed algorithm’s superiority. In addition, an ablation study is conducted to explore the effectiveness of the action mask mechanism, the target capture mechanism, and the collision avoidance mechanism.
2. Related Work
2.1. Cooperative Target Search Methods Based on Heuristic Algorithms
2.2. Cooperative Target Search Methods Based on Reinforcement Learning
2.3. Summary
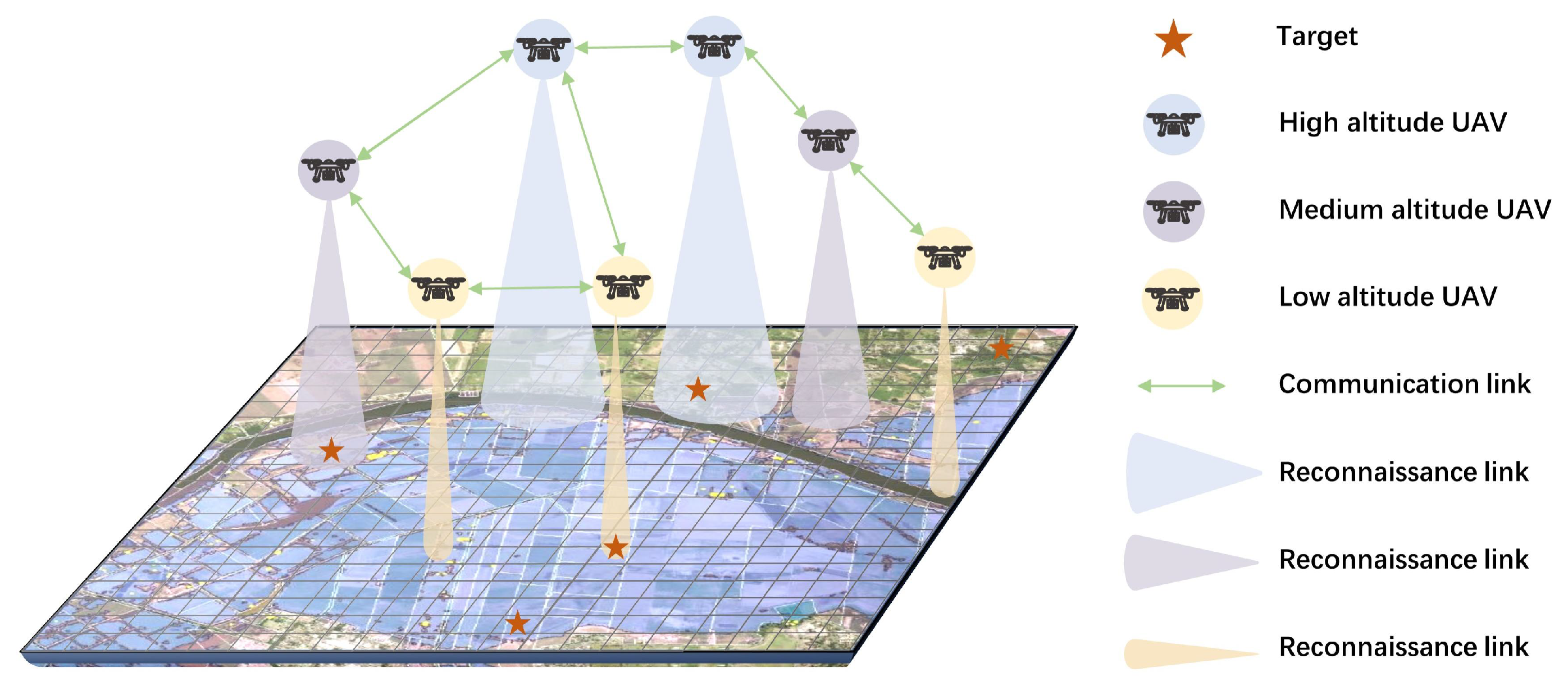
3. System Model
3.1. Environment Model
3.2. UAV Model
3.3. Belief Probability Map Update Model
3.4. Information Fusion Model
3.5. Problem Formulation
4. Proposed Multi-UAV Cooperative Search Method for Moving Targets
4.1. Rule-Based Target Capture Mechanism
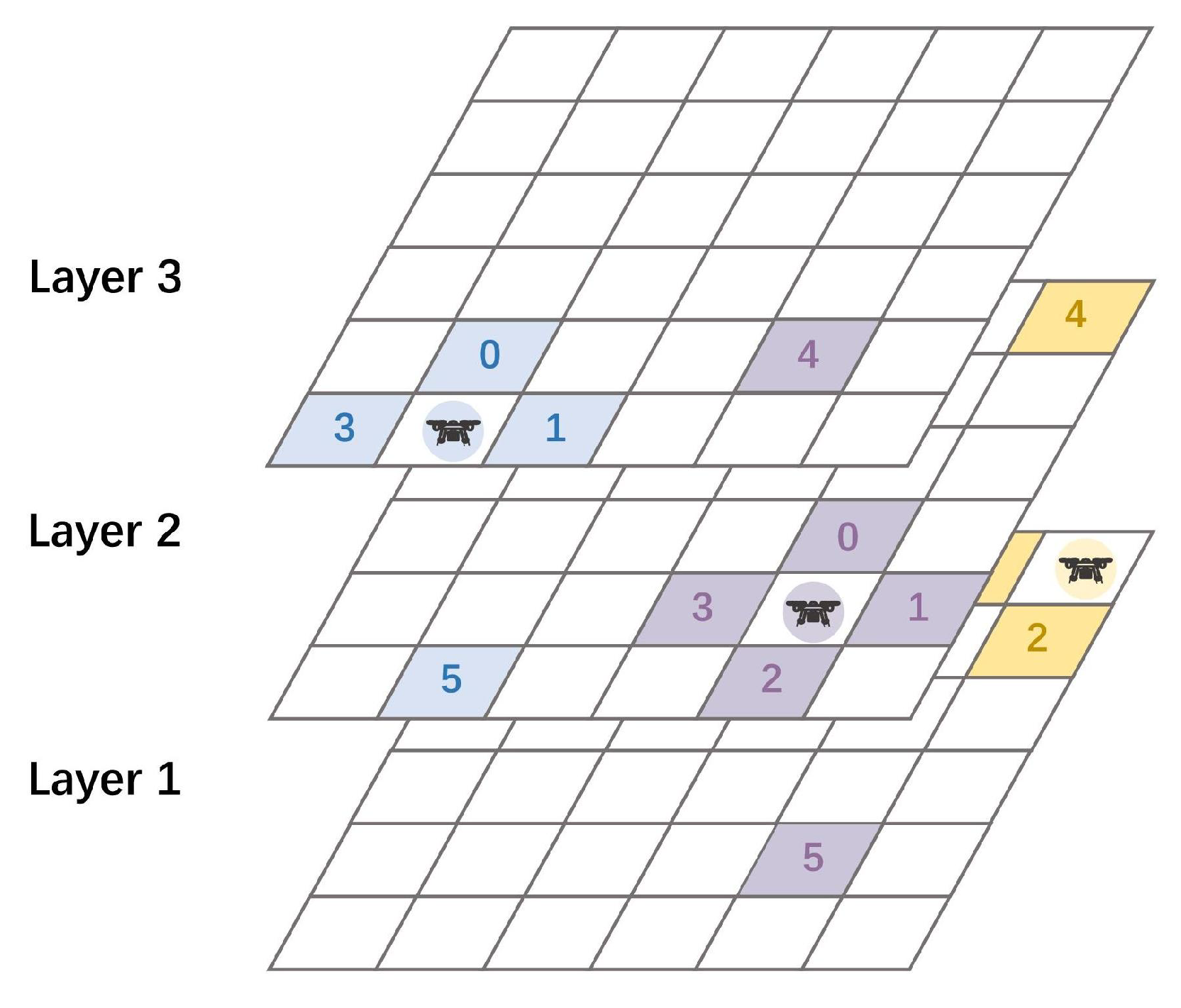
4.2. Action-Mask-Based Collision Avoidance Mechanism
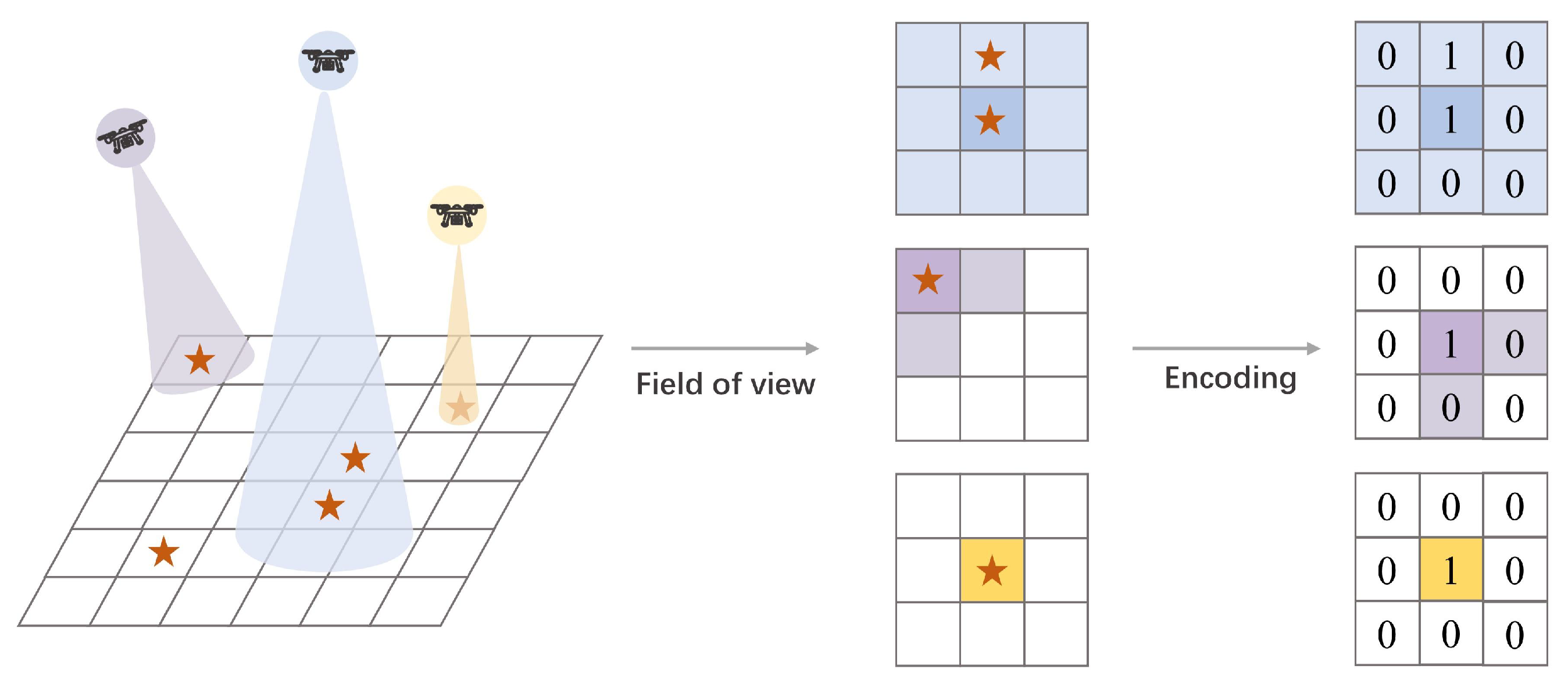
4.3. Field-of-View-Encoding-Based State Representation Mechanism
4.4. DEC-POMDP Formulation
- (1)
- State space: The environmental state at time t is represented as:
- (2)
- Action space: The joint actions taken by the UAVs at time t are defined as:
- (3)
- Observation space: The joint observations of the UAVs at time t are defined as follows:
- (4)
- Reward function: This reward function comprises two components: target discovery reward and cognitive reward. Additionally, to underscore the efficacy of the collision avoidance mechanism proposed herein, algorithms that incentivize UAVs towards collision avoidance via reward functions are compared. Consequently, for comparative algorithms lacking the action-mask-based collision avoidance mechanism, collision penalties are employed to steer UAVs away from collisions.
- The target discovery reward aims to incentivize UAVs to locate additional targets, noting that the target reward is exclusive to the initial discovery by any UAV.
- The cognitive reward encourages UAVs to achieve comprehensive area coverage. This reward is granted when the grid’s uncertainty falls below a predetermined threshold for the first time.
- The collision penalty serves to deter UAVs from colliding. It is applied when the inter-UAV distance falls below the safety threshold.
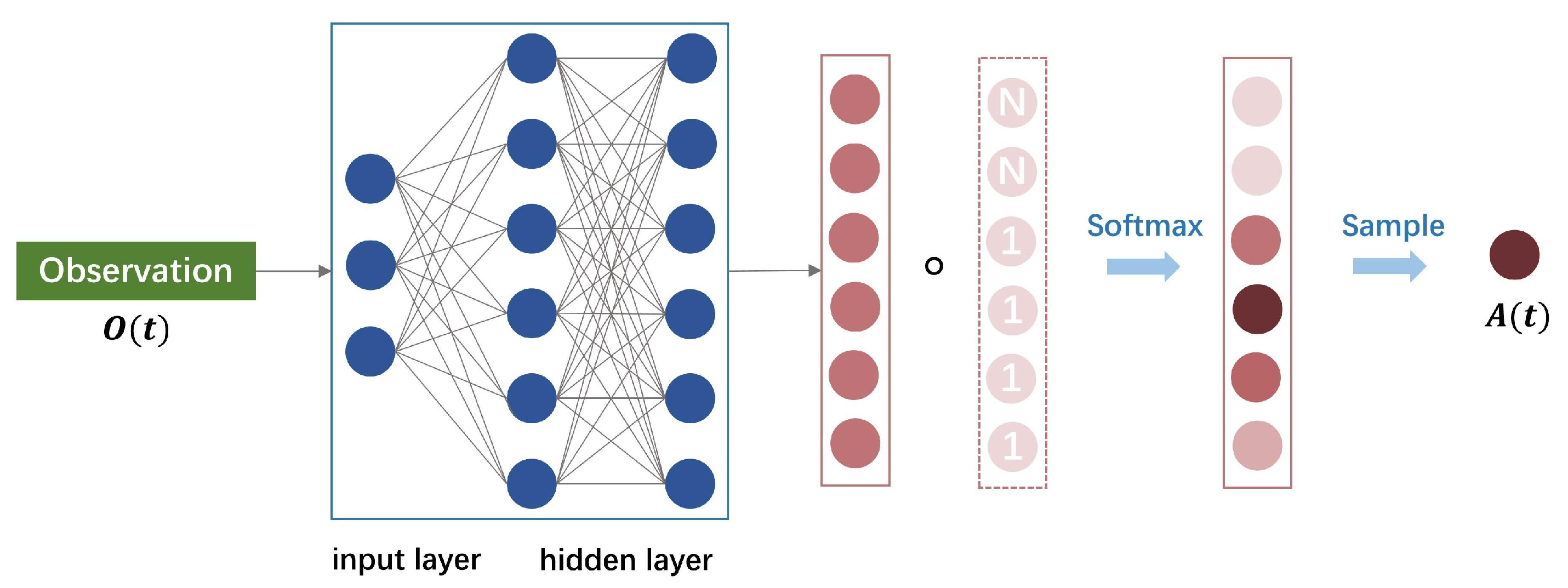
4.5. AM-MAPPO Algorithm
- (1)
- Action Selection Stage
- (2)
- Strategy Update Stage
| Algorithm 1: AM-MAPPO-based search algorithm |
 |
5. Performance Analysis
5.1. Parameter Setting
5.2. Performance Indicators
- Number of captured targets: This indicator evaluates the number of targets successfully captured by the algorithm within a given time. A higher number indicates greater efficiency in target capture.
- Number of covered grids: This indicator focuses on the specific number of grids in the search area where the uncertainty is reduced to a certain level or below. It reflects the coverage effect of multiple UAVs in specific areas. A higher number of low-uncertainty grids indicates better algorithm performance in these regions, reducing search blind spots.
- Average uncertainty: This indicator measures the degree to which the algorithm reduces the uncertainty of the entire region during the search process, reflecting the overall mastery of environmental information by all UAVs. A lower average uncertainty indicates more comprehensive and effective coverage of the search area by the UAVs.
- Reward: This indicator considers the total reward obtained by the algorithm throughout the entire task process. A higher reward typically indicates better performance in balancing broad area coverage and precise target capture.
5.3. Performance Evaluation
5.3.1. Effectiveness Analysis of the AM-MAPPO Algorithm
- A.
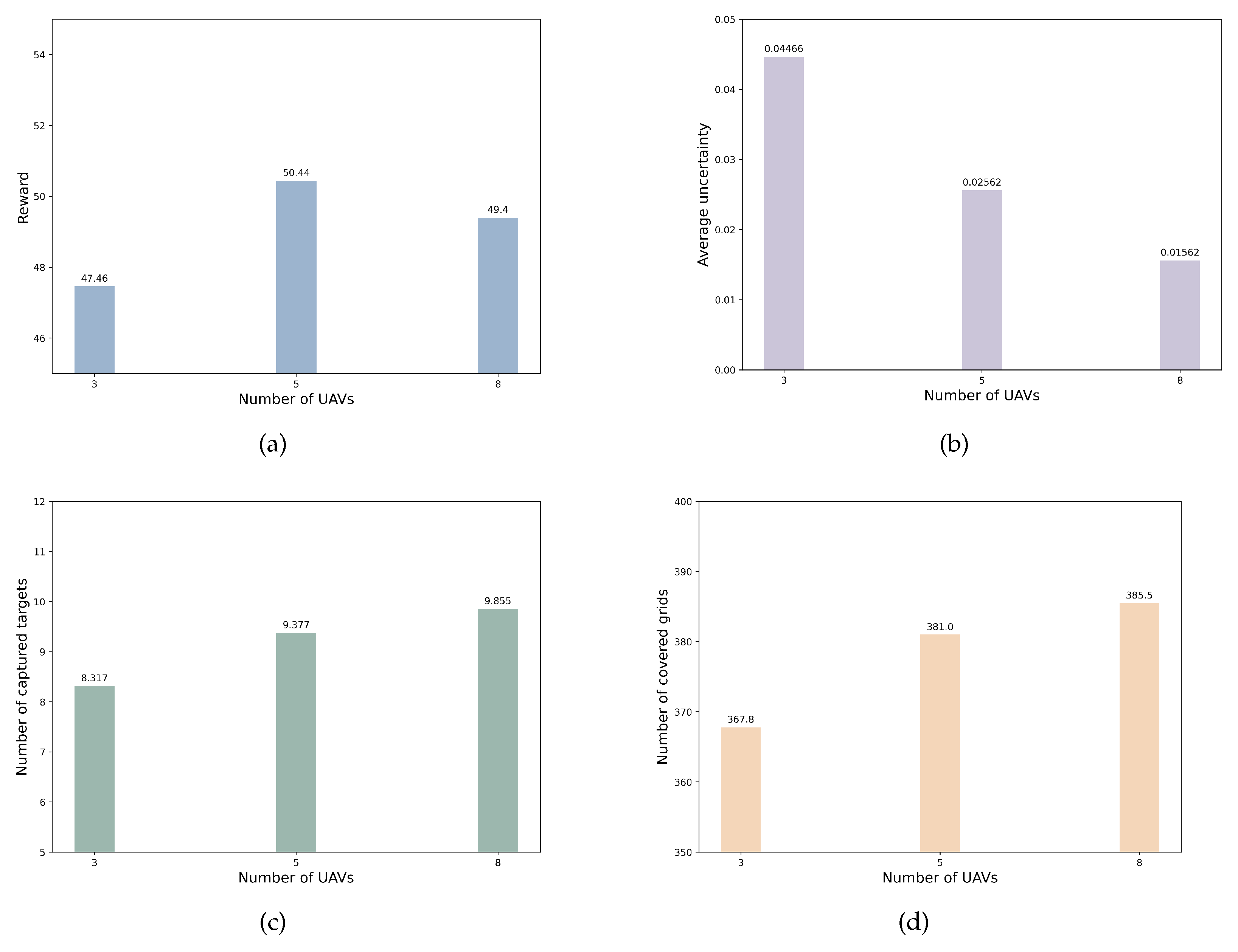
- The Effectiveness Analysis for Different Numbers of UAVs
- B.
- The Effectiveness Analysis for Different Numbers of Targets
5.3.2. Trajectory Analysis
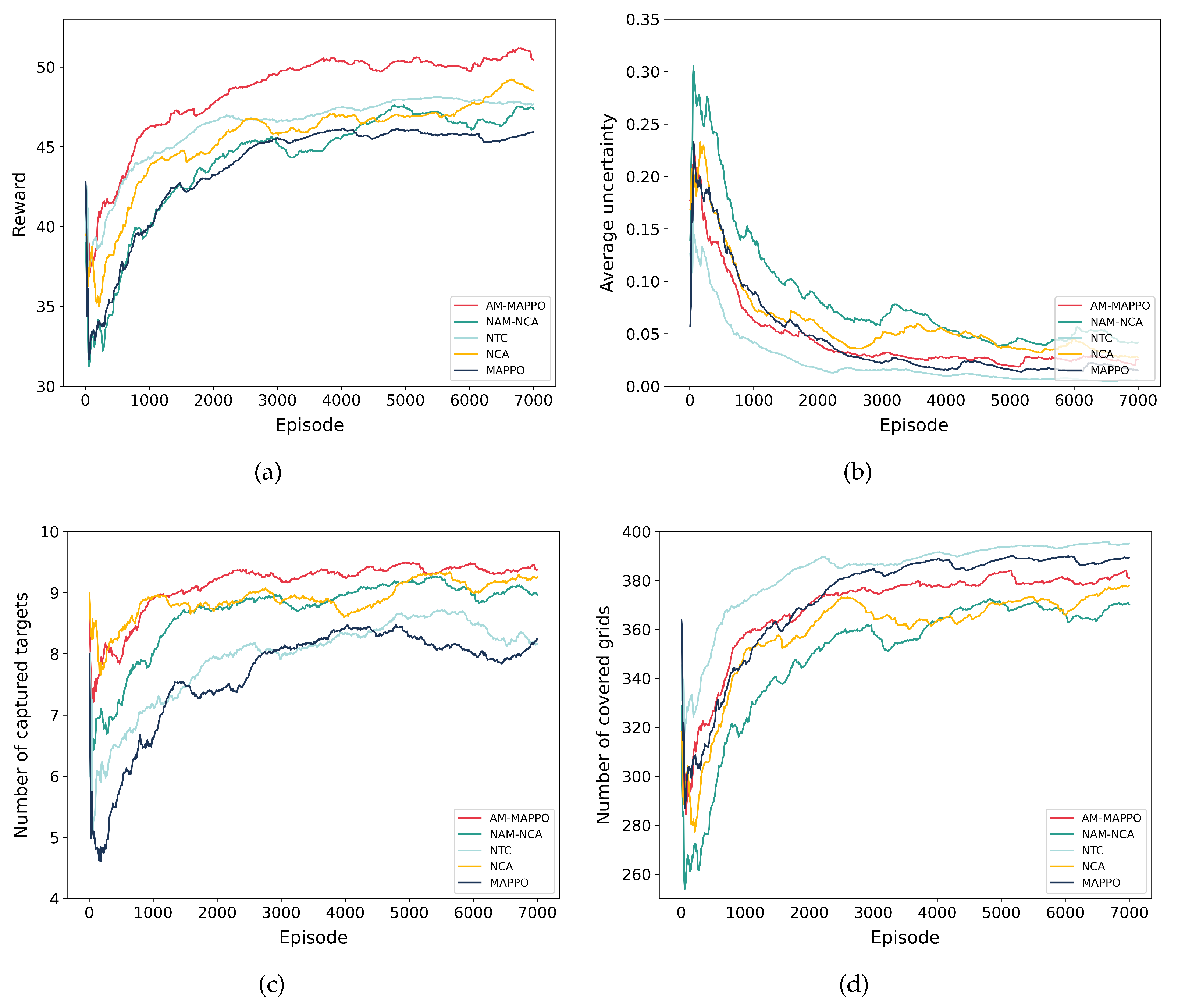
5.3.3. Ablation Experiment
5.3.4. Comparison with Other Algorithms
- MAPPO: a search method for multi-UAVs based on multi-agent proximal policy optimization [47]. Each UAV is considered an intelligent agent for deploying actor and critic network models. The structure of the critic network is the same as the settings of the AM-MAPPO algorithm. The architecture of the actor network is similar to the AM-MAPPO algorithm, but it does not include the action mask mechanism designed in this paper.
- VDN [48]: a search method for multi-UAVs based on a value decomposition network. Each UAV is considered an intelligent agent for deploying Q-network models. The network architecture of VDN is similar to the critic network of the AM-MAPPO algorithm. Its input is the local observation of the intelligent agent, and the global Q value is formed by adding up the local Q values of all intelligent agents.
- QMIX [49]: a search method for multi-UAVs based on a hybrid Q-network. Each UAV is considered an intelligent agent for deploying the Q-network model. The network architecture of QMIX is similar to the critic network of the AM-MAPPO algorithm. Its input is the local observation of the intelligent agent, which forms a global Q value by nonlinearly combining the local Q values of all intelligent agents through a hybrid network.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Muchiri, G.; Kimathi, S. A review of applications and potential applications of UAV. In Proceedings of the Sustainable Research and Innovation Conference, Pretoria, South Africa, 20–24 June 2022; pp. 280–283. [Google Scholar]
- Hu, X.; Assaad, R.H. The use of unmanned ground vehicles and unmanned aerial vehicles in the civil infrastructure sector: Applications, robotic platforms, sensors, and algorithms. Expert Syst. Appl. 2023, 232, 120897. [Google Scholar] [CrossRef]
- Kats, V.; Levner, E. Maximizing the average environmental benefit of a fleet of drones under a periodic schedule of tasks. Algorithms 2024, 17, 283. [Google Scholar] [CrossRef]
- Baniasadi, P.; Foumani, M.; Smith-Miles, K.; Ejov, V. A transformation technique for the clustered generalized traveling salesman problem with applications to logistics. Eur. J. Oper. Res. 2020, 285, 444–457. [Google Scholar] [CrossRef]
- He, H.; Yuan, W.; Chen, S.; Jiang, X.; Yang, F.; Yang, J. Deep reinforcement learning based distributed 3D UAV trajectory design. IEEE Trans. Commun. 2024, 72, 3736–3751. [Google Scholar] [CrossRef]
- Frattolillo, F.; Brunori, D.; Iocchi, L. Scalable and cooperative deep reinforcement learning approaches for multi-UAV systems: A systematic review. Drones 2023, 7, 236. [Google Scholar] [CrossRef]
- Lyu, M.; Zhao, Y.; Huang, C.; Huang, H. Unmanned aerial vehicles for search and rescue: A survey. Remote Sens. 2023, 15, 3266. [Google Scholar] [CrossRef]
- Qi, S.; Lin, B.; Deng, Y.; Chen, X.; Fang, Y. Minimizing maximum latency of task offloading for multi-UAV-assisted maritime search and rescue. IEEE Trans. Veh. Technol. 2024, 1–14. [Google Scholar] [CrossRef]
- Zhu, W.; Li, L.; Teng, L.; Yonglu, W. Multi-UAV reconnaissance task allocation for heterogeneous targets using an opposition-based genetic algorithm with double-chromosome encoding. Chin. J. Aeronaut. 2018, 31, 339–350. [Google Scholar]
- Kim, T.; Lee, S.; Kim, K.H.; Jo, Y.I. FANET routing protocol analysis for Multi-UAV-based reconnaissance mobility models. Drones 2023, 7, 161. [Google Scholar] [CrossRef]
- Li, K.; Yan, X.; Han, Y. Multi-mechanism swarm optimization for multi-UAV task assignment and path planning in transmission line inspection under multi-wind field. Appl. Soft Comput. 2024, 150, 111033. [Google Scholar] [CrossRef]
- Lu, F.; Jiang, R.; Bi, H.; Gao, Z. Order distribution and routing optimization for takeout delivery under drone–rider joint delivery mode. J. Theor. Appl. Electron. Commer. Res. 2024, 19, 774–796. [Google Scholar] [CrossRef]
- Lu, F.; Chen, W.; Feng, W.; Bi, H. 4PL routing problem using hybrid beetle swarm optimization. Soft Comput. 2023, 27, 17011–17024. [Google Scholar] [CrossRef]
- Yahia, H.S.; Mohammed, A.S. Path planning optimization in unmanned aerial vehicles using meta-heuristic algorithms: A systematic review. Environ. Monit. Assess. 2023, 195, 30. [Google Scholar] [CrossRef] [PubMed]
- Aljalaud, F.; Kurdi, H.; Youcef-Toumi, K. Bio-inspired multi-UAV path planning heuristics: A review. Mathematics 2023, 11, 2356. [Google Scholar] [CrossRef]
- Wang, X.; Fang, X. A multi-agent reinforcement learning algorithm with the action preference selection strategy for massive target cooperative search mission planning. Expert Syst. Appl. 2023, 231, 120643. [Google Scholar] [CrossRef]
- Yu, X.; Luo, W. Reinforcement learning-based multi-strategy cuckoo search algorithm for 3D UAV path planning. Expert Syst. Appl. 2023, 223, 119910. [Google Scholar] [CrossRef]
- Bai, Y.; Zhao, H.; Zhang, X.; Chang, Z.; Jäntti, R.; Yang, K. Towards autonomous multi-UAV wireless network: A survey of reinforcement learning-based approaches. IEEE Commun. Surv. Tutor. 2023, 25, 3038–3067. [Google Scholar] [CrossRef]
- Adoni, W.Y.H.; Lorenz, S.; Fareedh, J.S.; Gloaguen, R.; Bussmann, M. Investigation of autonomous multi-UAV systems for target detection in distributed environment: Current developments and open challenges. Drones 2023, 7, 263. [Google Scholar] [CrossRef]
- Seuken, S.; Zilberstein, S. Formal models and algorithms for decentralized decision making under uncertainty. Auton. Agents Multi-Agent Syst. 2008, 17, 190–250. [Google Scholar] [CrossRef]
- Zhang, B.; Lin, X.; Zhu, Y.; Tian, J.; Zhu, Z. Enhancing multi-UAV reconnaissance and search through double critic DDPG with belief probability maps. IEEE Trans. Intell. Veh. 2024, 9, 3827–3842. [Google Scholar] [CrossRef]
- Cui, J.; Liu, Y.; Nallanathan, A. Multi-agent reinforcement learning-based resource allocation for UAV networks. IEEE Trans. Wirel. Commun. 2019, 19, 729–743. [Google Scholar] [CrossRef]
- Shen, G.; Lei, L.; Zhang, X.; Li, Z.; Cai, S.; Zhang, L. Multi-UAV cooperative search based on reinforcement learning with a digital twin driven training framework. IEEE Trans. Veh. Technol. 2023, 72, 8354–8368. [Google Scholar] [CrossRef]
- Luo, Q.; Luan, T.H.; Shi, W.; Fan, P. Deep reinforcement learning based computation offloading and trajectory planning for multi-UAV cooperative target search. IEEE J. Sel. Areas Commun. 2022, 41, 504–520. [Google Scholar] [CrossRef]
- Hou, Y.; Zhao, J.; Zhang, R.; Cheng, X.; Yang, L. UAV swarm cooperative target search: A multi-agent reinforcement learning approach. IEEE Trans. Intell. Veh. 2023, 9, 568–578. [Google Scholar] [CrossRef]
- Yang, Y.; Polycarpou, M.M.; Minai, A.A. Multi-UAV cooperative search using an opportunistic learning method. J. Dyn. Syst. Meas. Control. 2007, 129, 716–728. [Google Scholar] [CrossRef]
- Fei, B.; Bao, W.; Zhu, X.; Liu, D.; Men, T.; Xiao, Z. Autonomous cooperative search model for multi-UAV with limited communication network. IEEE Internet Things J. 2022, 9, 19346–19361. [Google Scholar] [CrossRef]
- Zhou, Z.; Luo, D.; Shao, J.; Xu, Y.; You, Y. Immune genetic algorithm based multi-UAV cooperative target search with event-triggered mechanism. Phys. Commun. 2020, 41, 101103. [Google Scholar] [CrossRef]
- Ni, J.; Tang, G.; Mo, Z.; Cao, W.; Yang, S.X. An improved potential game theory based method for multi-UAV cooperative search. IEEE Access 2020, 8, 47787–47796. [Google Scholar] [CrossRef]
- Sun, X.; Cai, C.; Pan, S.; Zhang, Z.; Li, Q. A cooperative target search method based on intelligent water drops algorithm. Comput. Electr. Eng. 2019, 80, 106494. [Google Scholar] [CrossRef]
- Yue, W.; Tang, W.; Wang, L. Multi-UAV cooperative anti-submarine search based on a rule-driven MAC scheme. Appl. Sci. 2022, 12, 5707. [Google Scholar] [CrossRef]
- Pérez-Carabaza, S.; Besada-Portas, E.; López-Orozco, J.A. Minimizing the searching time of multiple targets in uncertain environments with multiple UAVs. Appl. Soft Comput. 2024, 155, 111471. [Google Scholar] [CrossRef]
- Duan, H.; Zhao, J.; Deng, Y.; Shi, Y.; Ding, X. Dynamic discrete pigeon-inspired optimization for multi-UAV cooperative search-attack mission planning. IEEE Trans. Aerosp. Electron. Syst. 2020, 57, 706–720. [Google Scholar] [CrossRef]
- Xu, L.; Cao, X.; Du, W.; Li, Y. Cooperative path planning optimization for multiple UAVs with communication constraints. Knowl.-Based Syst. 2023, 260, 110164. [Google Scholar] [CrossRef]
- Cao, X.; Luo, H.; Tai, J.; Jiang, R.; Wang, G. Multi-agent target search strategy optimization: Hierarchical reinforcement learning with multi-criteria negative feedback. Appl. Soft Comput. 2023, 149, 110999. [Google Scholar] [CrossRef]
- Waharte, S.; Trigoni, N. Supporting search and rescue operations with UAVs. In Proceedings of the IEEE 2010 International Conference on Emerging Security Technologies, Canterbury, UK, 6–7 September 2010; pp. 142–147. [Google Scholar]
- Gupta, A.; Bessonov, D.; Li, P. A decision-theoretic approach to detection-based target search with a UAV. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 5304–5309. [Google Scholar]
- Bertuccelli, L.F.; How, J.P. Robust UAV search for environments with imprecise probability maps. In Proceedings of the 44th IEEE Conference on Decision and Control, Seville, Spain, 12–15 December 2005; pp. 5680–5685. [Google Scholar]
- Millet, T.; Casbeer, D.; Mercker, T.; Bishop, J. Multi-agent decentralized search of a probability map with communication constraints. In Proceedings of the AIAA Guidance, Navigation, and Control Conference, Toronto, ON, Canada, 2–5 August 2010; p. 8424. [Google Scholar]
- Zhen, Z.; Chen, Y.; Wen, L.; Han, B. An intelligent cooperative mission planning scheme of UAV swarm in uncertain dynamic environment. Aerosp. Sci. Technol. 2020, 100, 105826. [Google Scholar] [CrossRef]
- Jin, Y.; Liao, Y.; Minai, A.A.; Polycarpou, M.M. Balancing search and target response in cooperative unmanned aerial vehicle (UAV) teams. IEEE Trans. Syst. Man, Cybern. Part B 2006, 36, 571–587. [Google Scholar] [CrossRef]
- Gao, Y.; Li, D. Unmanned aerial vehicle swarm distributed cooperation method based on situation awareness consensus and its information processing mechanism. Knowl.-Based Syst. 2020, 188, 105034. [Google Scholar] [CrossRef]
- Zhang, H.; Ma, H.; Mersha, B.W.; Zhang, X.; Jin, Y. Distributed cooperative search method for multi-UAV with unstable communications. Appl. Soft Comput. 2023, 148, 110592. [Google Scholar] [CrossRef]
- Huang, S.; Ontañón, S. A closer look at invalid action masking in policy gradient algorithms. arXiv 2020, arXiv:2006.14171. [Google Scholar] [CrossRef]
- Wang, H.; Yufeng, Z.; Wei, L.; Jiaqiang, T. Multi-UAV 3D collaborative searching for moving targets based on information map. Control. Decis. 2023, 38, 3534–3542. [Google Scholar]
- Yu, C.; Velu, A.; Vinitsky, E.; Gao, J.; Wang, Y.; Bayen, A.; Wu, Y. The surprising effectiveness of ppo in cooperative multi-agent games. Adv. Neural Inf. Process. Syst. 2022, 35, 24611–24624. [Google Scholar]
- Su, K.; Qian, F. Multi-UAV cooperative searching and tracking for moving targets based on multi-agent reinforcement learning. Appl. Sci. 2023, 13, 11905. [Google Scholar] [CrossRef]
- Sunehag, P.; Lever, G.; Gruslys, A.; Czarnecki, W.M.; Zambaldi, V.; Jaderberg, M.; Lanctot, M.; Sonnerat, N.; Leibo, J.Z.; Tuyls, K.; et al. Value-decomposition networks for cooperative multi-agent learning. arXiv 2017, arXiv:1706.05296. [Google Scholar]
- Rashid, T.; Samvelyan, M.; De Witt, C.S.; Farquhar, G.; Foerster, J.; Whiteson, S. Monotonic value function factorisation for deep multi-agent reinforcement learning. J. Mach. Learn. Res. 2020, 21, 1–51. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Target Model | Environment Model |
|---|---|---|
| [16] | Static target | 2D |
| [21] | Static target | 2D |
| [23] | Static target | 2D |
| [24] | Static target | 2D |
| [25] | Static target | 2D |
| [35] | Static target, randomly moving target, intelligent avoidance target | 2D |
| This work | Moving target | 3D |
| Flight Altitude | Field-of-View Size | Detection Probability | False Alarm Probability |
|---|---|---|---|
| 1 | 1 | 0.90 | 0.10 |
| 2 | 5 | 0.80 | 0.20 |
| 3 | 9 | 0.70 | 0.30 |
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| Threshold () | 0.99 | Discount factor () | 0.99 |
| Safe distance () | 141.4 m | Batch size (B) | 1024 |
| Target capture reward weight () | 1 | Learning rate () | |
| Cognitive reward weight () | 0.1 | Clip factor () | 0.2 |
| Collision penalty weight () | 0.01 | Gae lambda | 0.95 |
| Step | Location of UAV 1 | Location of Target 1 | Working Status of the Target Capture Mechanism |
|---|---|---|---|
| 24 | (2,12,1) | (0,8,0) | N |
| 25 | (1,12,1) | (0,8,0) | N |
| 26 | (0,12,1) | (0,8,0) | N |
| 27 | (0,11,1) | (0,8,0) | N |
| 28 | (0,10,1) | (0,8,0) | N |
| 29 | (0,10,2) | (0,8,0) | N |
| 30 | (0,9,2) | (0,8,0) | Y |
| 31 | (0,9,1) | (0,8,0) | Y |
| 32 | (0,9,0) | (0,8,0) | N |
| 33 | (0,8,0) | (0,8,0) | N |
| Step | Location of UAV 2 | Location of Target 2 | Working Status of the Target Capture Mechanism |
|---|---|---|---|
| 94 | (10,9,2) | (13,8,0) | N |
| 95 | (10,9,1) | (13,8,0) | N |
| 96 | (11,9,1) | (13,8,0) | N |
| 97 | (12,9,1) | (13,8,0) | N |
| 98 | (12,9,2) | (13,8,0) | N |
| 99 | (12,9,1) | (13,8,0) | N |
| 100 | (12,9,2) | (13,8,0) | Y |
| 101 | (12,9,1) | (13,9,0) | Y |
| 102 | (12,9,0) | (13,9,0) | N |
| 103 | (13,9,0) | (13,9,0) | N |
| Step | Location of UAV 3 | Location of Target 3 | Working Status of the Target Capture Mechanism |
|---|---|---|---|
| 165 | (17,6,1) | (15,3,0) | N |
| 166 | (17,5,1) | (15,3,0) | N |
| 167 | (17,4,1) | (15,3,0) | N |
| 168 | (17,3,1) | (15,3,0) | N |
| 169 | (17,2,1) | (15,3,0) | N |
| 170 | (17,1,1) | (15,3,0) | N |
| 171 | (17,2,1) | (16,3,0) | N |
| 172 | (17,3,1) | (16,3,0) | Y |
| 173 | (17,3,0) | (16,3,0) | N |
| 174 | (16,3,0) | (16,3,0) | N |
| Step | Location of UAV 4 | Location of Target 4 | Working Status of the Target Capture Mechanism |
|---|---|---|---|
| 182 | (12,9,1) | (9,9,0) | N |
| 183 | (11,9,1) | (9,9,0) | N |
| 184 | (11,8,1) | (9,9,0) | N |
| 185 | (11,8,0) | (9,9,0) | N |
| 186 | (11,8,1) | (9,9,0) | N |
| 187 | (11,8,2) | (9,9,0) | N |
| 188 | (10,8,2) | (9,9,0) | Y |
| 189 | (10,8,1) | (9,9,0) | Y |
| 190 | (9,8,1) | (9,9,0) | N |
| 191 | (9,8,0) | (9,8,0) | N |
| Step | Location of UAV 5 | Location of Target 5 | Working Status of the Target Capture Mechanism |
|---|---|---|---|
| 194 | (16,2,1) | (16,7,0) | N |
| 195 | (16,3,1) | (16,7,0) | N |
| 196 | (16,4,1) | (16,7,0) | N |
| 197 | (16,5,1) | (16,7,0) | N |
| 198 | (16,4,1) | (16,7,0) | N |
| 199 | (16,5,1) | (16,7,0) | N |
| 200 | (16,6,1) | (16,7,0) | Y |
| 201 | (16,6,0) | (16,8,0) | N |
| 202 | (16,7,0) | (16,8,0) | N |
| 203 | (16,8,0) | (16,8,0) | N |
| Algorithm | Action Mask Mechanism | Target Capture Mechanism | Collision Avoidance Mechanism |
|---|---|---|---|
| AM-MAPPO | • | • | • |
| NAM-NCA | ∘ | • | ∘ |
| NTC | • | ∘ | • |
| NCA | • | • | ∘ |
| MAPPO | ∘ | ∘ | ∘ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Li, X.; Wang, J.; Wei, F.; Yang, J. Reinforcement-Learning-Based Multi-UAV Cooperative Search for Moving Targets in 3D Scenarios. Drones 2024, 8, 378. https://doi.org/10.3390/drones8080378
Liu Y, Li X, Wang J, Wei F, Yang J. Reinforcement-Learning-Based Multi-UAV Cooperative Search for Moving Targets in 3D Scenarios. Drones. 2024; 8(8):378. https://doi.org/10.3390/drones8080378
Chicago/Turabian StyleLiu, Yifei, Xiaoshuai Li, Jian Wang, Feiyu Wei, and Junan Yang. 2024. "Reinforcement-Learning-Based Multi-UAV Cooperative Search for Moving Targets in 3D Scenarios" Drones 8, no. 8: 378. https://doi.org/10.3390/drones8080378
APA StyleLiu, Y., Li, X., Wang, J., Wei, F., & Yang, J. (2024). Reinforcement-Learning-Based Multi-UAV Cooperative Search for Moving Targets in 3D Scenarios. Drones, 8(8), 378. https://doi.org/10.3390/drones8080378