


Power Transmission Lines Foreign Object Intrusion Detection Method for Drone Aerial Images Based on Improved YOLOv8 Network


Abstract
:1. Introduction
- (1)
- Swin Transformer is adopted as the high-resolution feature extraction layer to enhance the feature extraction capability of small objects.
- (2)
- An Adaptive Feature Pyramid Network (AFPN) is designed, combining multi-scale features to improve the model’s detection capability at different scales.
- (3)
- The Focal-SIoU loss function is used to balance the distribution of positive and negative samples, thereby accelerating algorithm convergence and improving detection accuracy.
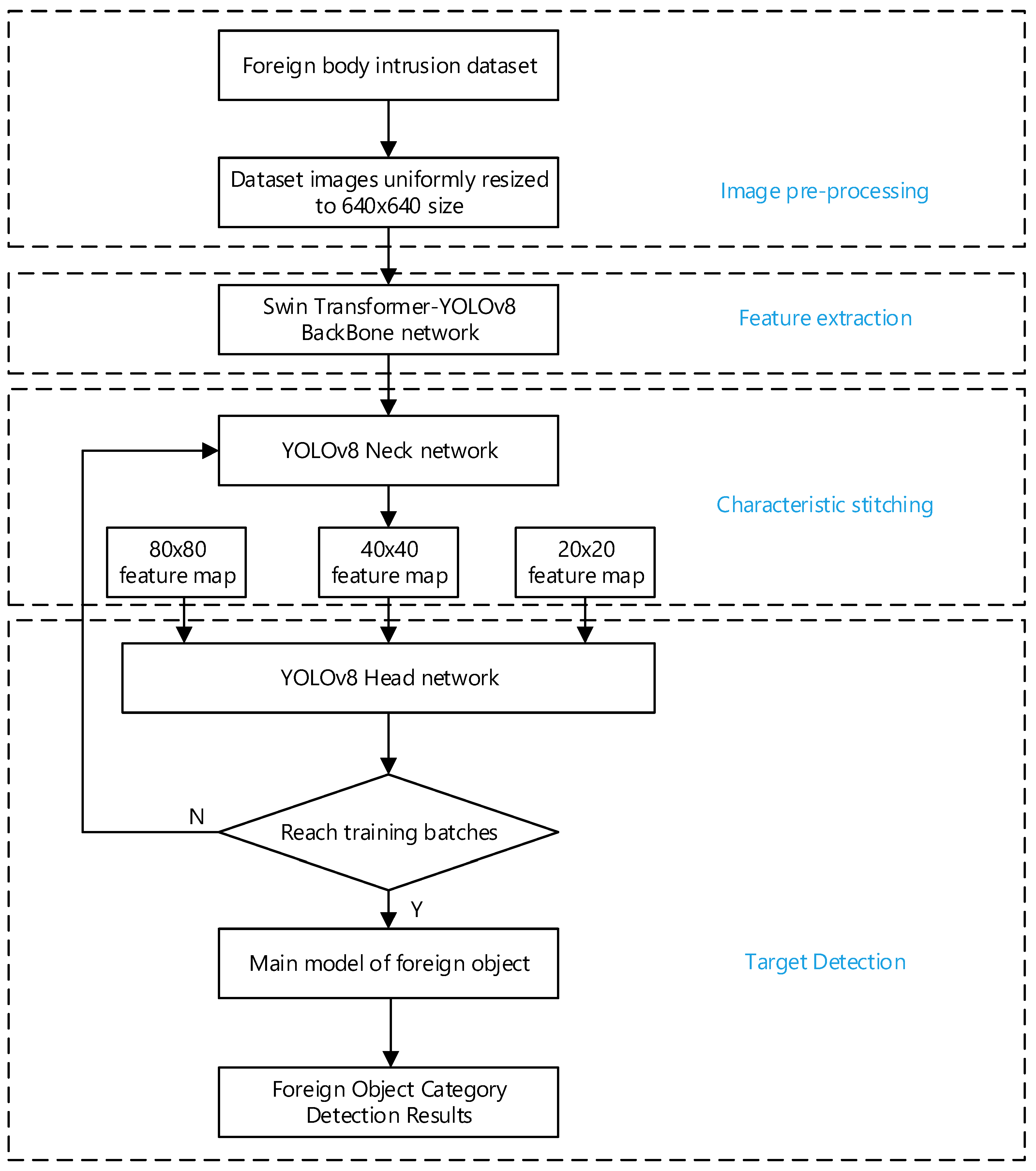
2. YOLOv8 Network
2.1. Principle of YOLOv8 Algorithm
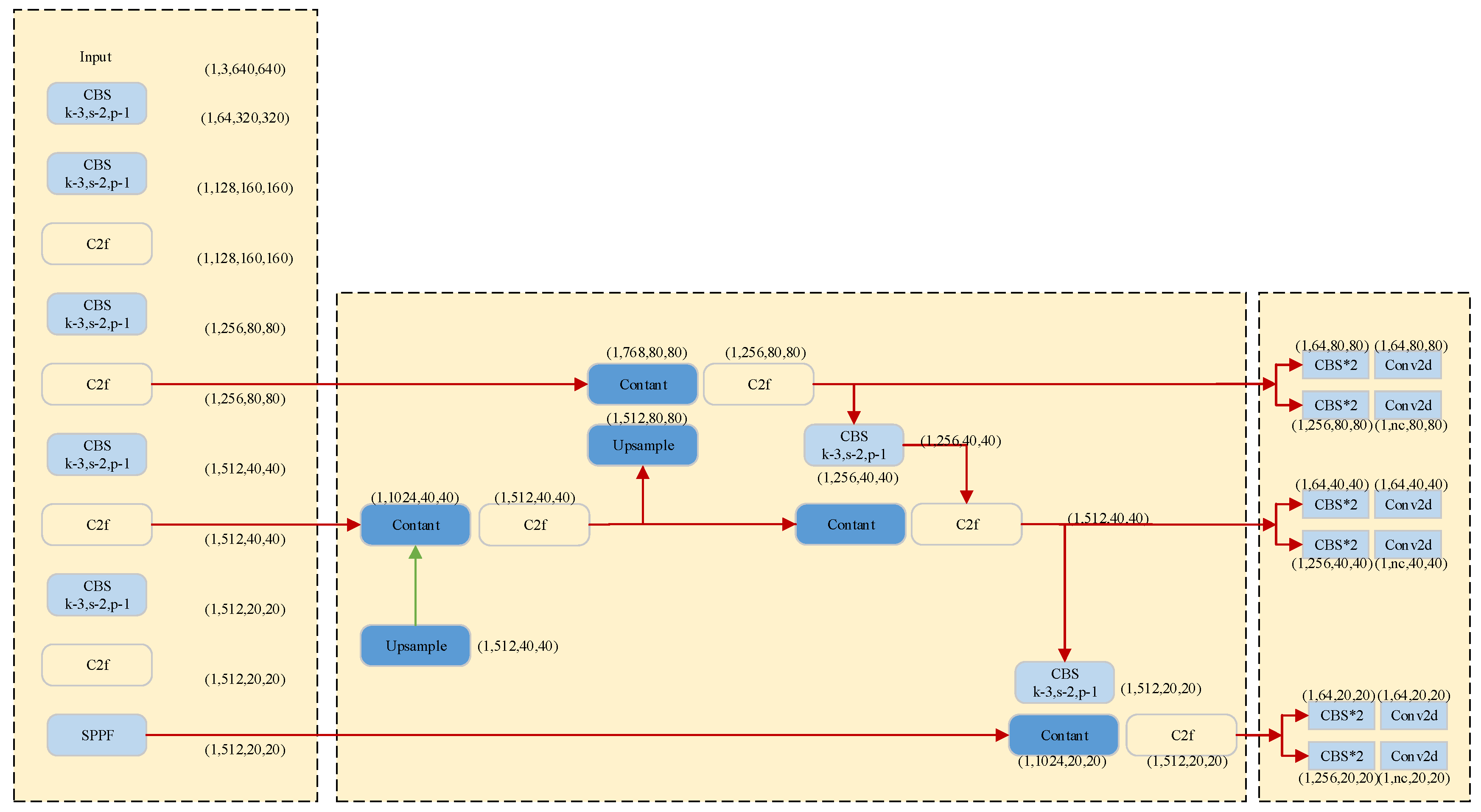
2.2. YOLOv8 Backbone Network
3. Improvements
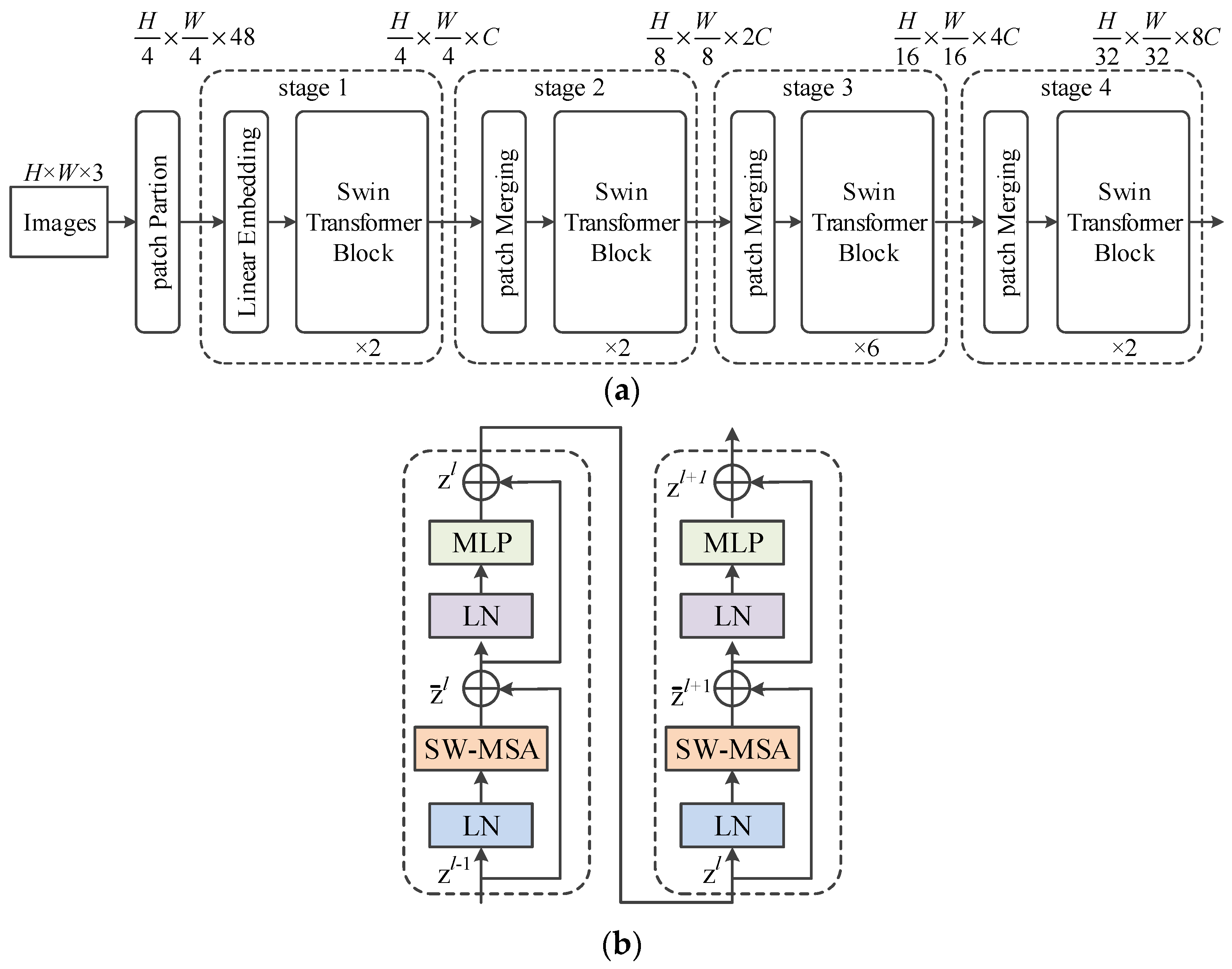
3.1. Swin Transformer Overall Framework
3.2. Improved Progressive Feature Pyramid Network (AFPN)
3.2.1. Traditional Feature Fusion
3.2.2. Asymptotic Feature Pyramid Network (AFPN)
3.3. Improved Loss Function
4. Experimental Analysis
4.1. Dataset


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Number |
|---|---|
| Nest | 364 |
| Kite | 374 |
| Balloon | 370 |
4.2. Experimental Setup
4.3. Evaluation Criteria
4.4. Comparative Experiments with Other Algorithms
4.4.1. Effect of Swin Transformer on YOLOv8
4.4.2. Effect of AFPN on YOLOv8
4.4.3. Effect of Improved Loss Functions on YOLOv8
4.5. Ablation Study
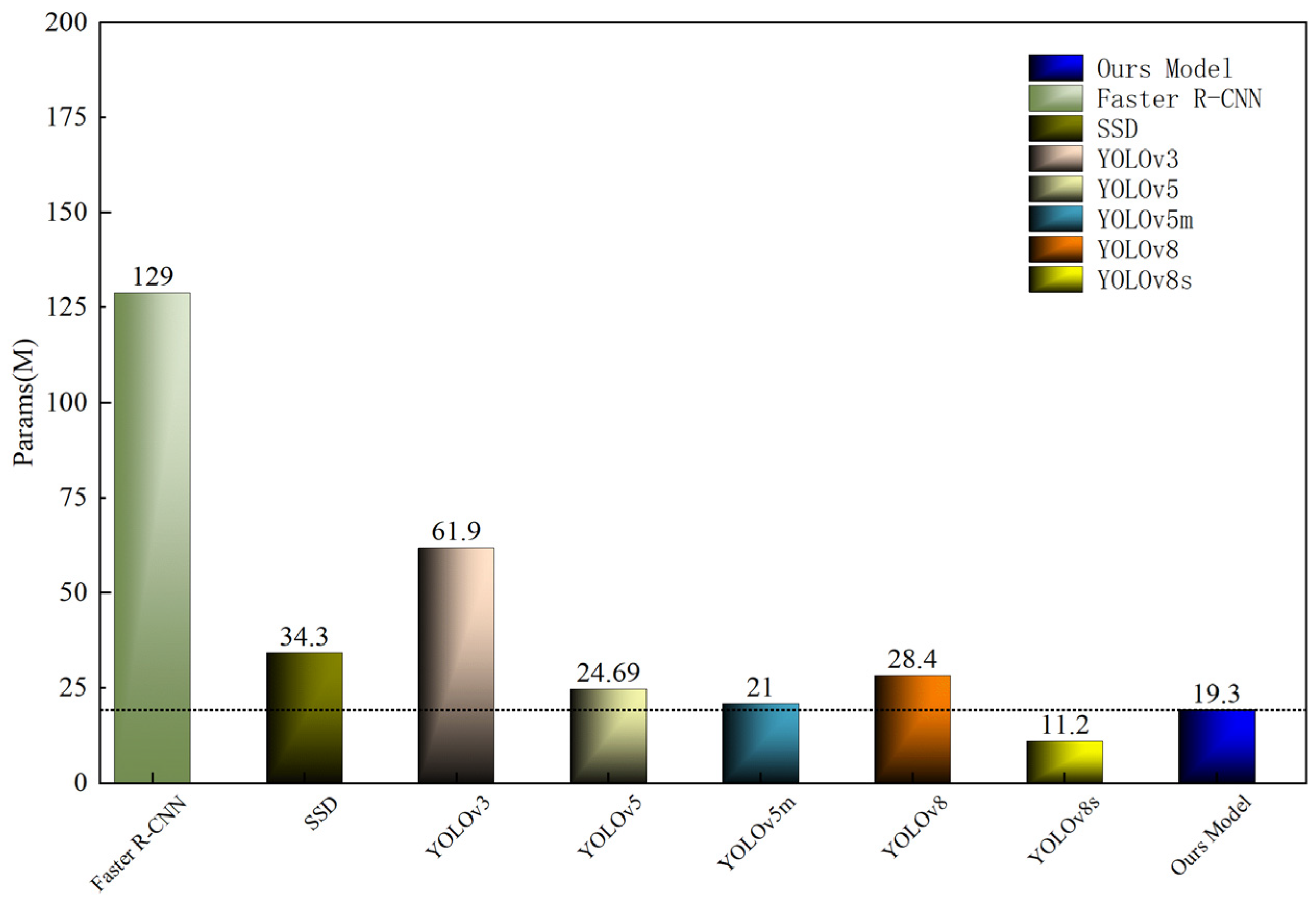
4.6. Comparison of the Combined Model with Other Advanced Algorithms
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, D.; Zhang, Z.; Zhao, N.; Wang, Z. A Lightweight Modified YOLOv5 Network Using a Swin Transformer for Transmission-Line Foreign Object Detection. Electronics 2023, 12, 3904. [Google Scholar] [CrossRef]
- Yu, Y.; Qiu, Z.; Liao, H.; Wei, Z.; Zhu, X.; Zhou, Z. A Method Based on Multi-Network Feature Fusion and Random Forest for Foreign Objects Detection on Transmission Lines. Appl. Sci. 2022, 12, 4982. [Google Scholar] [CrossRef]
- Wu, M.; Guo, L.; Chen, R.; Du, W.; Wang, J.; Liu, M.; Kong, X.; Tang, J. Improved YOLOX Foreign Object Detection Algorithm for Transmission Lines. Wirel. Commun. Mob. Comput. 2022, 2022, 5835693. [Google Scholar] [CrossRef]
- Tasnim, S.; Qi, W. Progress in Object Detection: An In-Depth Analysis of Methods and Use Cases. Eur. J. Electr. Eng. Comput. Sci. 2023, 7, 39–45. [Google Scholar] [CrossRef]
- Ren, J.; Wang, J. Overview of Object Detection Algorithms Using Convolutional Neural Networks. J. Comput. Commun. 2022, 10, 115–132. [Google Scholar]
- Mishra, D. Deep Learning based Object Detection Methods: A Review. J. Comput. Commun. 2022, 10, 115–132. [Google Scholar]
- Janiesch, C.; Zschech, P.; Heinrich, K. Machine learning and deep learning. Electron. Mark. 2021, 31, 685–695. [Google Scholar] [CrossRef]
- Shi, Y.; Jia, Y.; Zhang, X. FocusDet: An efficient object detector for small object. Sci. Rep. 2024, 14, 10697. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Wang, A.; Yi, J.; Song, Y.; Chehri, A. Small Object Detection Based on Deep Learning for Remote Sensing: A Comprehensive Review. Remote Sens. 2023, 15, 3265. [Google Scholar] [CrossRef]
- Min, L.; Fan, Z.; Lv, Q.; Reda, M.; Shen, L.; Wang, B. YOLO-DCTI: Small Object Detection in Remote Sensing Base on Contextual Transformer Enhancement. Remote Sens. 2023, 15, 3970. [Google Scholar] [CrossRef]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep Learning for Generic Object Detection: A Survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef]
- Zhang, Y.; Shen, T. Small Object Detection with Multiple Receptive Fields. IOP conference series. Earth Environ. Sci. 2020, 440, 32093. [Google Scholar]
- Cheng, G.; Yuan, X.; Yao, X.; Yan, K.; Zeng, Q.; Xie, X.; Han, J. Towards Large-Scale Small Object Detection: Survey and Benchmarks. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 13467–13488. [Google Scholar] [CrossRef] [PubMed]
- Terven, J.; Córdova-Esparza, D.-M.; Romero-González, J.-A. A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Flores-Calero, M.; Astudillo, C.A.; Guevara, D.; Maza, J.; Lita, B.S.; Defaz, B.; Ante, J.S.; Zabala-Blanco, D.; Moreno, J.M.A. Traffic Sign Detection and Recognition Using YOLO Object Detection Algorithm: A Systematic Review. Mathematics 2024, 12, 297. [Google Scholar] [CrossRef]
- Kumawat, D.; Abhayankar, D.; Tanwani, S. Exploring Object Detection Algorithms and implementation of YOLOv7 and YOLOv8 based model for weapon detection. Int. J. Intell. Syst. Appl. Eng. 2024, 12, 877–886. [Google Scholar]
- Shao, Y.; Zhang, R.; Lv, C.; Luo, Z.; Che, M. TL-YOLO: Foreign-Object Detection on Power Transmission Line Based on Improved Yolov8. Electronics 2024, 13, 1543. [Google Scholar] [CrossRef]
- Tang, J.; Li, B. Power System to Prevent External Damage Detection Method. Acad. J. Sci. Technol. 2024, 9, 189–193. [Google Scholar] [CrossRef]
- Shi, Q.; Deng, K. Privacy-Preserving Detection Method for Transmission Line Based on Edge Collaboration. In Proceedings of the 2023 IEEE 22nd International Conference, Exeter, UK, 1–3 November 2023. [Google Scholar]
- Li, M.; Ding, L. DF-YOLO: Highly Accurate Transmission Line Foreign Object Detection Algorithm. IEEE Access 2023, 11, 108398–108406. [Google Scholar] [CrossRef]
- Liu, Y.; Gao, M.; Zong, H.; Wang, X.; Li, J. Real-Time Object Detection for the Running Train Based on the Improved YOLO V4 Neural Network. J. Adv. Transp. 2022, 2022, 4377953. [Google Scholar] [CrossRef]
- Nayak, R.; Behera, M.M.; Pati, U.C.; Das, S.K. Video-based Real-time Intrusion Detection System using Deep-Learning for Smart City Applications. In Proceedings of the 2019 IEEE International Conference on Advanced Networks and Telecommunications Systems (ANTS), Goa, India, 16–19 December 2019. [Google Scholar]
- Chen, W.; Li, Y.; Li, C. A Visual Detection Method for Foreign Objects in Power Lines Based on Mask R-CNN. Int. J. Ambient. Comput. Intell. 2020, 11, 34–47. [Google Scholar] [CrossRef]
- Sevi, M.; Aydin, İ. Detection of Foreign Objects Around the Railway Line with YOLOv8. Comput. Sci. 2023, 25, 19–23. [Google Scholar] [CrossRef]
- Shan, H.; Song, Y.; Wang, H.; Chen, Y. Research on Efficient Detection Method of Foreign Objects on Transmission Lines Based on Improved YOLOv4 Network. J. Phys. Conf. Ser. 2022, 2404, 012040. [Google Scholar] [CrossRef]
- Li, S.; Xie, J.; Zhou, F.; Liu, W.; Li, H. Foreign Object Intrusion Detection on Metro Track Using Commodity WiFi Devices with the Fast Phase Calibration Algorithm. Sensors 2020, 20, 3446. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Yuan, G.; Zhou, H.; Ma, Y.; Ma, Y. Foreign-Object Detection in High-Voltage Transmission Line Based on Improved YOLOv8m. Appl. Sci. 2023, 13, 12775. [Google Scholar] [CrossRef]
- Zhao, L.; Liu, C.A.; Qu, H. Transmission Line Object Detection Method Based on Contextual Information Enhancement and Joint Heterogeneous Representation. Sensors 2022, 22, 6855. [Google Scholar] [CrossRef] [PubMed]
- Chien, C.T.; Ju, R.Y.; Chou, K.Y.; Lin, C.S.; Chiang, J.S. YOLOv8-AM: YOLOv8 with Attention Mechanisms for Pediatric Wrist Fracture Detection. 2024, Cornell University Library. arXiv 2024, arXiv:2402.09329. [Google Scholar]
- Liu, Q.; Ye, H.; Wang, S.; Xu, Z. YOLOv8-CB: Dense Pedestrian Detection Algorithm Based on In-Vehicle Camera. Electronics 2024, 13, 236. [Google Scholar] [CrossRef]
- Ren, R.; Sun, H.; Zhang, S.; Wang, N.; Lu, X.; Jing, J.; Xin, M.; Cui, T. Intelligent Detection of Lightweight “Yuluxiang” Pear in Non-Structural Environment Based on YOLO-GEW. Agronomy 2023, 13, 2418. [Google Scholar] [CrossRef]
- Ju, R.Y.; Cai, W. Fracture detection in pediatric wrist trauma X-ray images using YOLOv8 algorithm. Sci. Rep. 2023, 13, 20077. [Google Scholar] [CrossRef]
- Baek, J.; Chung, K. Swin Transformer-Based Object Detection Model Using Explainable Meta-Learning Mining. Appl. Sci. 2023, 13, 3213. [Google Scholar] [CrossRef]
- Huo, D.; Kastner, M.A.; Liu, T.; Kawanishi, Y.; Hirayama, T.; Komamizu, T.; Ide, I. Small Object Detection for Birds with Swin Transformer. In Proceedings of the 2023 18th International Conference on Machine Vision and Applications (MVA), Hamamatsu, Japan, 23–25 July 2023. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Peng, Y.; Ren, J.; Wang, J.; Shi, M. Spectral-Swin Transformer with Spatial Feature Extraction Enhancement for Hyperspectral Image Classification. Remote Sens. 2023, 15, 2696. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Schuster, R.; Battrawy, R.; Wasenmüller, O.; Stricker, D. ResFPN: Residual Skip Connections in Multi-Resolution Feature Pyramid Networks for Accurate Dense Pixel Matching. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021. [Google Scholar]
- Dimitrakopoulos, P.; Sfikas, G.; Nikou, C. Nuclei Detection Using Residual Attention Feature Pyramid Networks. In Proceedings of the 2019 IEEE 19th International Conference on Bioinformatics and Bioengineering (BIBE), Athens, Greece, 28–30 October 2019. [Google Scholar]
- Wang, B.; Ji, R.; Zhang, L.; Wu, Y. Bridging Multi-Scale Context-Aware Representation for Object Detection. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 2317–2329. [Google Scholar] [CrossRef]
- Zhang, D.; Zhang, H.; Tang, J.; Wang, M.; Hua, X.; Sun, Q. Feature Pyramid Transformer. In Computer Vision–ECCV 2020. ECCV 2020. Lecture Notes in Computer Science; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Yang, G.; Lei, J.; Zhu, Z.; Cheng, S.; Feng, Z.; Liang, R. AFPN: Asymptotic Feature Pyramid Network for Object Detection. In Proceedings of the 2023 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Honolulu, HI, USA, 1–4 October 2023. [Google Scholar]
- Hu, D.; Yu, M.; Wu, X.; Hu, J.; Sheng, Y.; Jiang, Y.; Huang, C.; Zheng, Y. DGW-YOLOv8: A small insulator target detection algorithm based on deformable attention backbone and WIoU loss function. IET Image Process. 2024, 18, 1096–1108. [Google Scholar] [CrossRef]












| Parameter | Setup |
|---|---|
| PyTorch | 2.3.0 |
| Python | 3.8 |
| GPU | NVIDIA GeForce RTX 4060 Ti (16 GB) |
| CPU | 13th Gen Intel Core i5-13400 |
| RAM | 16 GB |
| CUDA | 12.1 |
| Parameter | Setup |
|---|---|
| Initial Learning Rate | 0.001 |
| Final Learning Rate | 0.001 |
| Epoch | 200 |
| Momentum | 0.937 |
| Patience | 100 |
| IoU | 0.5 |
| Weight Decay | 0.005 |
| Image Size | 640 × 640 |
| Model | AP (%) | FPS (G) | Params (M) | mAP@0.5 (%) | ||
|---|---|---|---|---|---|---|
| Kite | Balloon | Nest | ||||
| Faster R-CNN | 73.2 | 85.4 | 77.5 | 38.7 | 129 | 78.7 |
| SSD | 80.3 | 78.2 | 83.6 | 46.1 | 34.3 | 80.6 |
| YOLOv3 | 81.2 | 78.3 | 85.4 | 45.5 | 61.9 | 81.6 |
| YOLOv5 | 81.7 | 84.3 | 85.2 | 109.8 | 24.69 | 83.7 |
| YOLOv5m | 94.3 | 86.2 | 79.8 | 89.9 | 21 | 86.7 |
| YOLOv8 | 83.2 | 92.1 | 91.2 | 150.7 | 28.40 | 88.8 |
| YOLOv8s | 91.6 | 82.3 | 87.7 | 130.7 | 11.20 | 88.5 |
| Ours Model | 90.3 | 92.7 | 95.6 | 181.4 | 23.21 | 92.8 |
| Model | AP (%) | mAP@0.5 (%) | |||
|---|---|---|---|---|---|
| Trash | Ribbon | Shade Net | Nest | ||
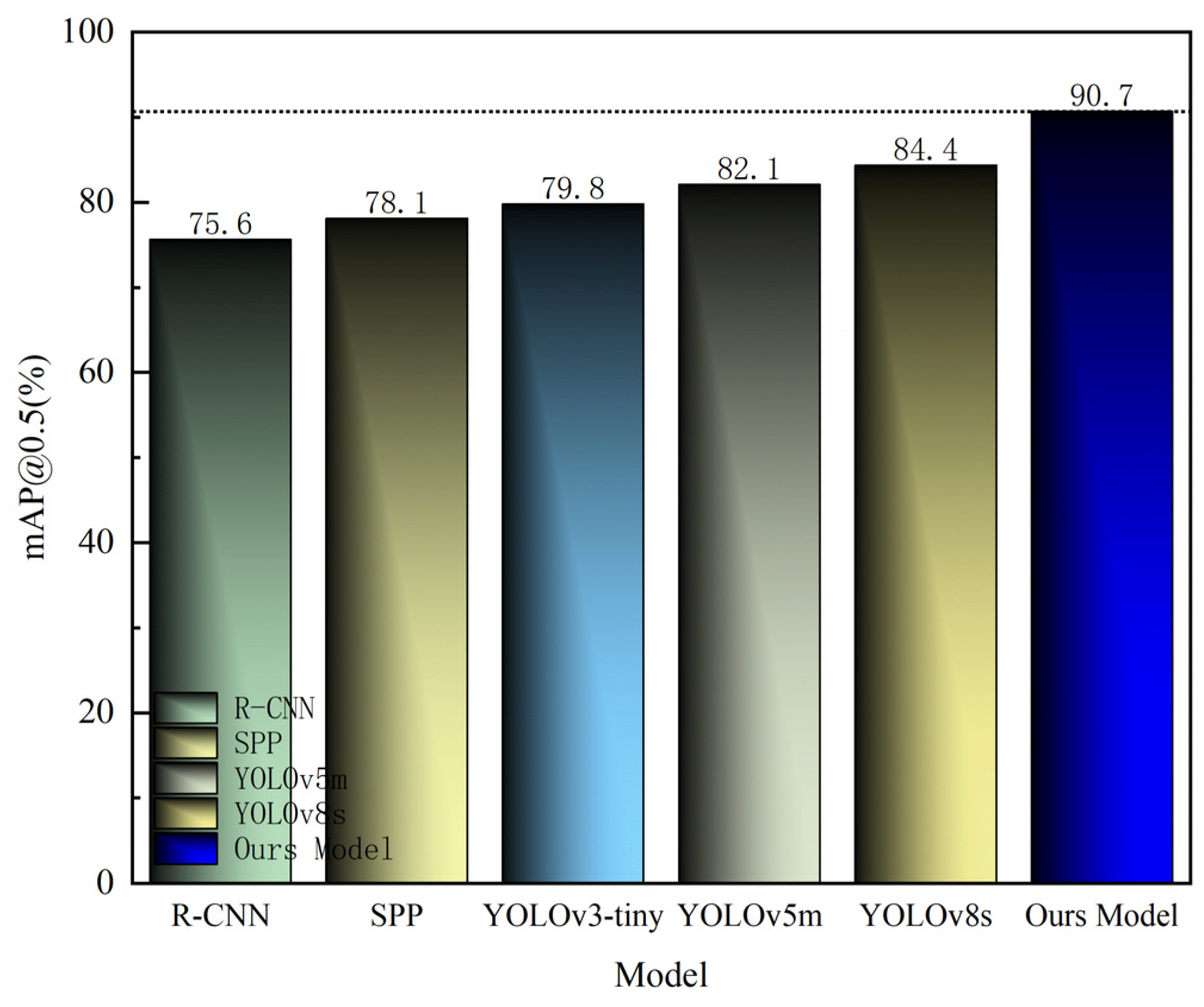
| R-CNN | 78.2 | 75.1 | 73.4 | 76.0 | 75.6 |
| SPP | 80.5 | 77.8 | 75.9 | 78.2 | 78.1 |
| YOLOv3-tiny | 82.3 | 79.6 | 77.5 | 80.1 | 79.8 |
| YOLOv5m | 85.4 | 81.2 | 79.8 | 82.7 | 82.1 |
| YOLOv8s | 87.1 | 83.4 | 82.6 | 84.5 | 84.4 |
| Ours Model | 91.2 | 90.5 | 89.3 | 92.0 | 90.7 |
| Model | Precision% | Recall% | F1-Score% | mAP@0.5 | FPS | Inference Speed |
|---|---|---|---|---|---|---|
| R-CNN | 77.5 | 75.3 | 76.4 | 74.5 | 180 | 200 |
| SPP | 79.8 | 77.6 | 78.7 | 77.2 | 90 | 151.3 |
| YOLOv3-tiny | 81.0 | 78.9 | 79.9 | 78.5 | 17.9 | 30.8 |
| YOLOv5m | 83.2 | 81.0 | 82.1 | 81.0 | 36 | 25.6 |
| YOLOv8s | 85.0 | 83.2 | 84.1 | 83.5 | 27 | 16.5 |
| Ours Model | 88.5 | 87.0 | 87.7 | 89.3 | 14.3 | 11.2 |
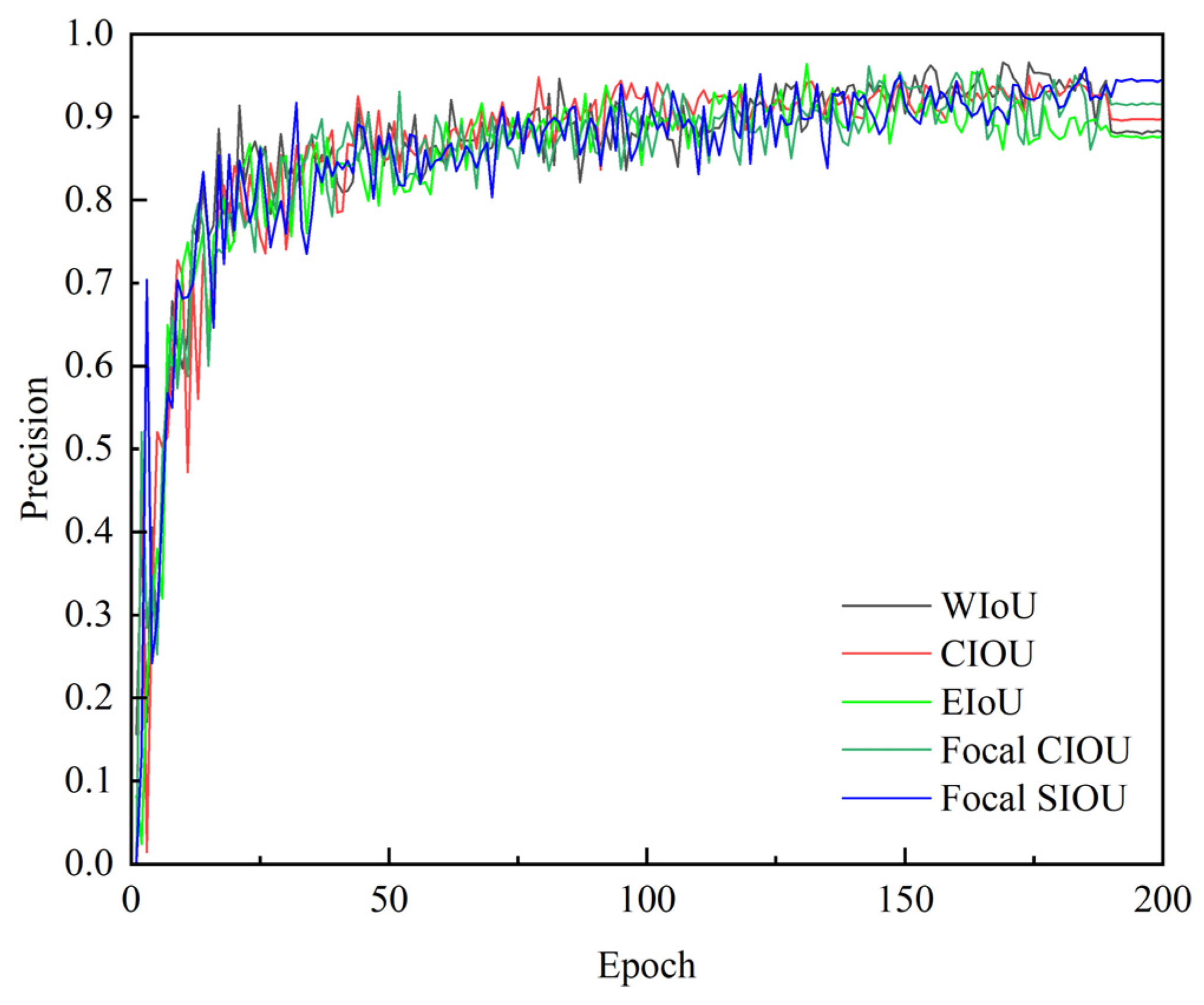
| LossFunction Type | Precision% | Recall% | mAP@0.5 | Loss |
|---|---|---|---|---|
| WIoU | 88.1 | 78.2 | 85.9 | 0.608 |
| CIoU(Initial) | 89.7 | 79.3 | 86.7 | 0.412 |
| EIoU | 87.6 | 80.5 | 86.3 | 0.317 |
| Focal CIoU | 91.5 | 80.9 | 88.2 | 0.425 |
| Focal SIoU | 94.4 | 82.0 | 89.9 | 0.218 |
| Model | mAP@0.5 (%) | |||
|---|---|---|---|---|
| Experiment Number | SwinTransformer | AFPN | Focal SIoU | |
| 1 | ✓ | 82.3 | ||
| 2 | ✓ | 81.7 | ||
| 3 | ✓ | 81.5 | ||
| 4 | ✓ | ✓ | 83.1 | |
| 5 | ✓ | ✓ | 84.6 | |
| 6 | ✓ | ✓ | 86.5 | |
| 7 | ✓ | ✓ | ✓ | 89.7 |
| Model | |||||
|---|---|---|---|---|---|
| Model | Precision (%) | Recall (%) | mAP@0.5 (%) | FPS | Params (M) |
| Faster R-CNN | 61.3 | 42.5 | 74.3 | 38.7 | 129 |
| YOLOv3-tiny | 71.8 | 69.2 | 76.5 | 46.1 | 34.3 |
| YOLOv3 | 82.8 | 75.5 | 83.8 | 45.5 | 61.9 |
| YOLOv5 | 84.8 | 80.4 | 84.7 | 109.8 | 24.69 |
| YOLOv7 | 86.2 | 80.45 | 87.1 | 117.5 | 28.67 |
| YOLOv8 | 87.2 | 83.9 | 88.2 | 150.7 | 28.40 |
| Ours Model | 90.8 | 89.1 | 89.7 | 181.4 | 28.88 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, H.; Shen, Q.; Ke, H.; Duan, Z.; Tang, X. Power Transmission Lines Foreign Object Intrusion Detection Method for Drone Aerial Images Based on Improved YOLOv8 Network. Drones 2024, 8, 346. https://doi.org/10.3390/drones8080346
Sun H, Shen Q, Ke H, Duan Z, Tang X. Power Transmission Lines Foreign Object Intrusion Detection Method for Drone Aerial Images Based on Improved YOLOv8 Network. Drones. 2024; 8(8):346. https://doi.org/10.3390/drones8080346
Chicago/Turabian StyleSun, Hongbin, Qiuchen Shen, Hongchang Ke, Zhenyu Duan, and Xi Tang. 2024. "Power Transmission Lines Foreign Object Intrusion Detection Method for Drone Aerial Images Based on Improved YOLOv8 Network" Drones 8, no. 8: 346. https://doi.org/10.3390/drones8080346
APA StyleSun, H., Shen, Q., Ke, H., Duan, Z., & Tang, X. (2024). Power Transmission Lines Foreign Object Intrusion Detection Method for Drone Aerial Images Based on Improved YOLOv8 Network. Drones, 8(8), 346. https://doi.org/10.3390/drones8080346