
ITD-YOLOv8: An Infrared Target Detection Model Based on YOLOv8 for Unmanned Aerial Vehicles

Abstract
1. Introduction
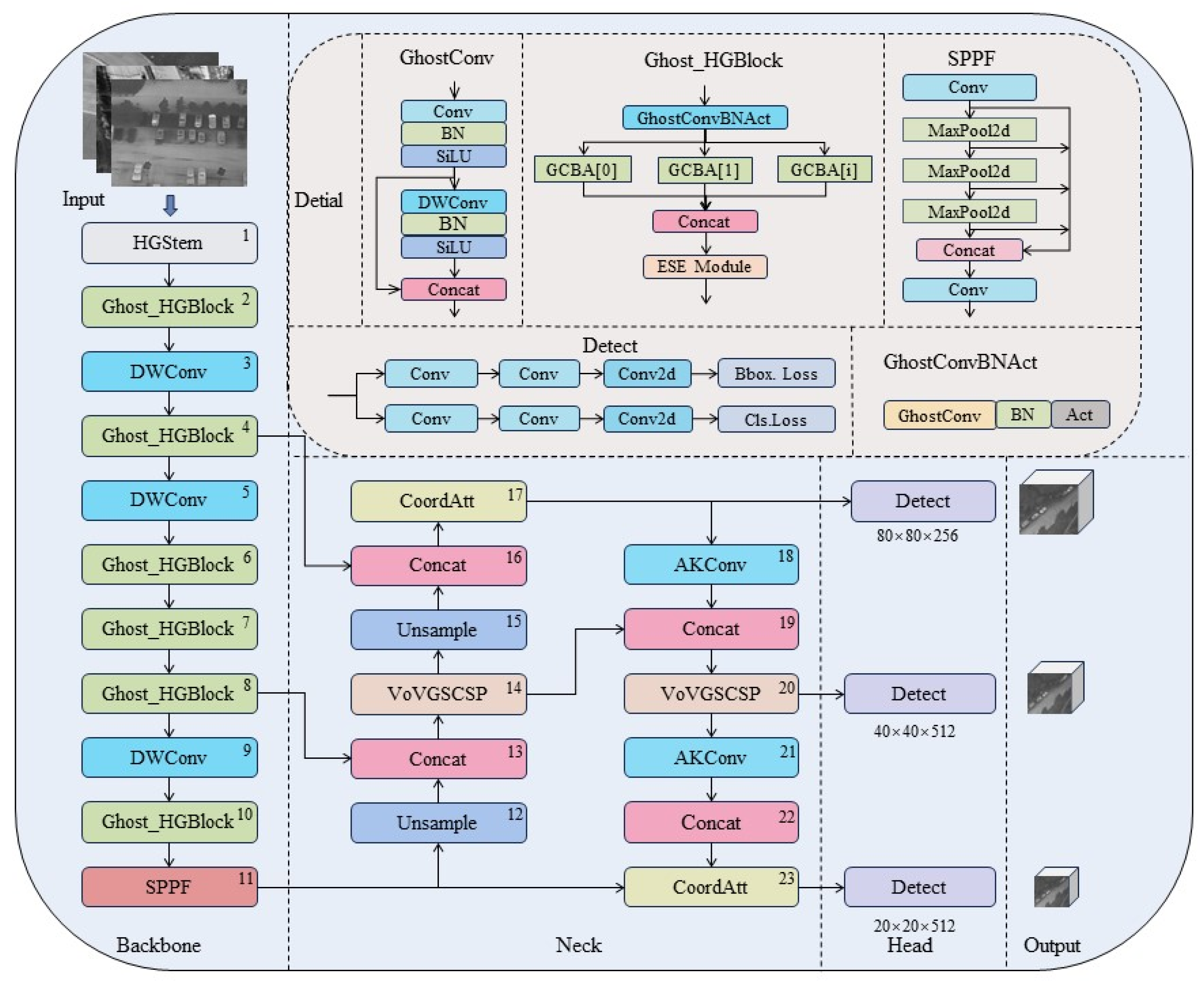
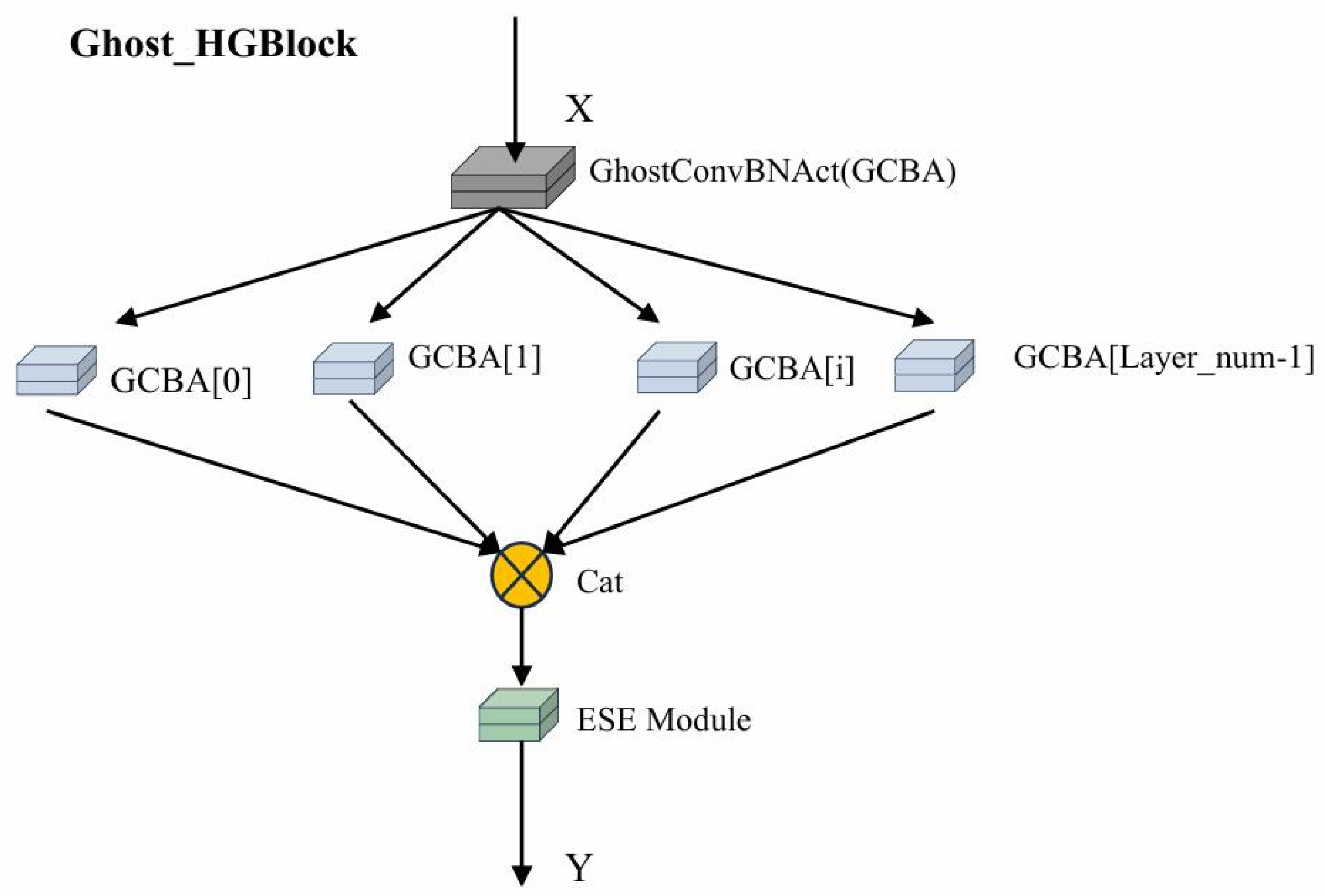
- This paper presents enhancements to the GhostHGNetV2 module for the object detection backbone network. The newly developed network backbone utilizes a combination of the Ghost and HGNetv2 modules. It achieves this by dividing input features into smaller subchannels, performing convolution operations on each subchannel, and then merging the results to produce the final output. And through downsampling, hourglass modules, and upsampling operations, features are extracted and fused at different scales. This enables the model to reduce computation and complexity while enhancing the model’s multi-scale target detection performance.
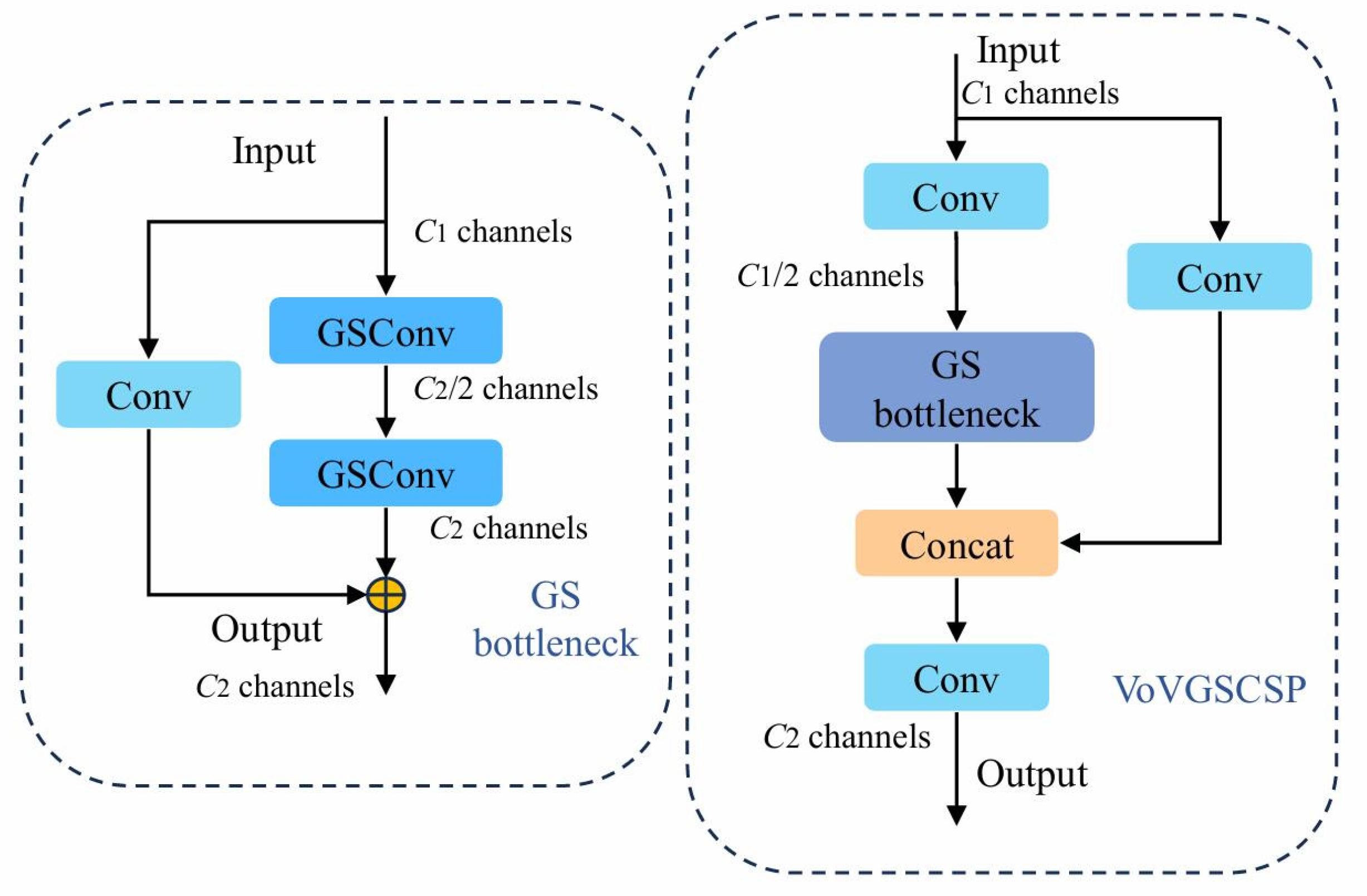
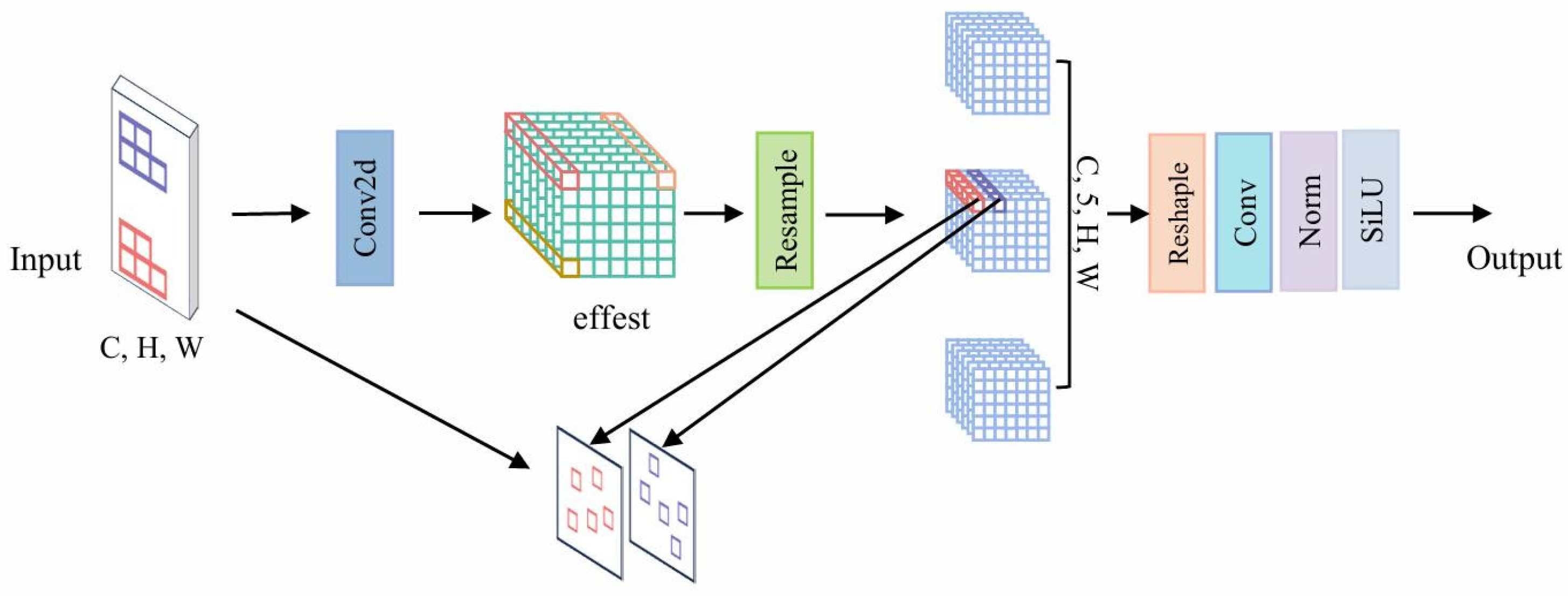
- By improving the neck structure through the VoVGSCSP module, different stage feature maps are effectively fused to reduce computational complexity and improve inference speed while maintaining the accuracy of the model detection. Replacing the Conv module with the AKConv module provides more efficient and flexible convolution operations in the model by dynamically changing the shape and size of the convolution kernel to adapt to different input data and task requirements. The attention mechanism known as CoordAtt is proposed to enhance the model’s ability to identify objectives by learning the spatial relationships between target objects and improving its attention towards various positional features.
- The utilization of the XIoU loss function enhances the precision of matching between the prediction frame and real frame by addressing their overlap, reaching enhanced detection accuracy for diminutive and compact targets.
2. Related Work
3. Proposed Methodologies, Tools, and Techniques
3.1. ITD-YOLOv8
3.1.1. Enhanced Core Network Utilizing GhostHGNetV2 Architecture
3.1.2. The VoVGSCSP Module
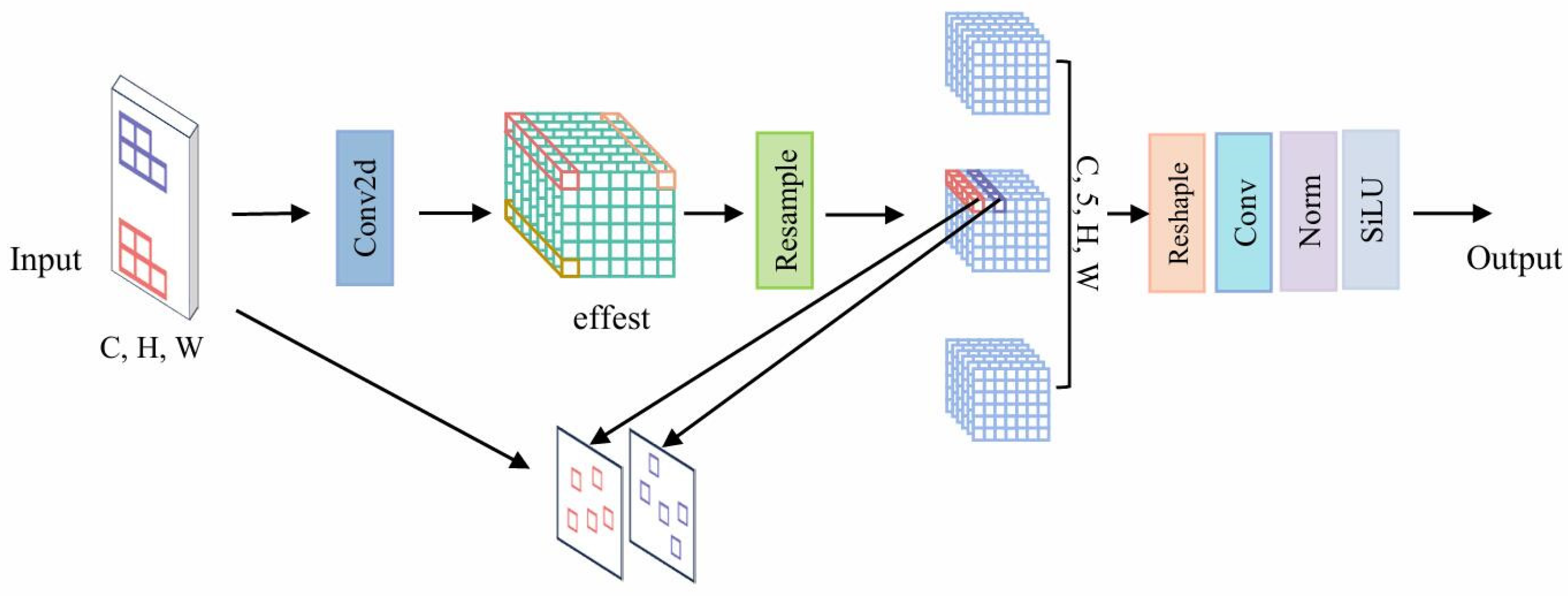
3.1.3. The Lightweight Convolution Module AXConv
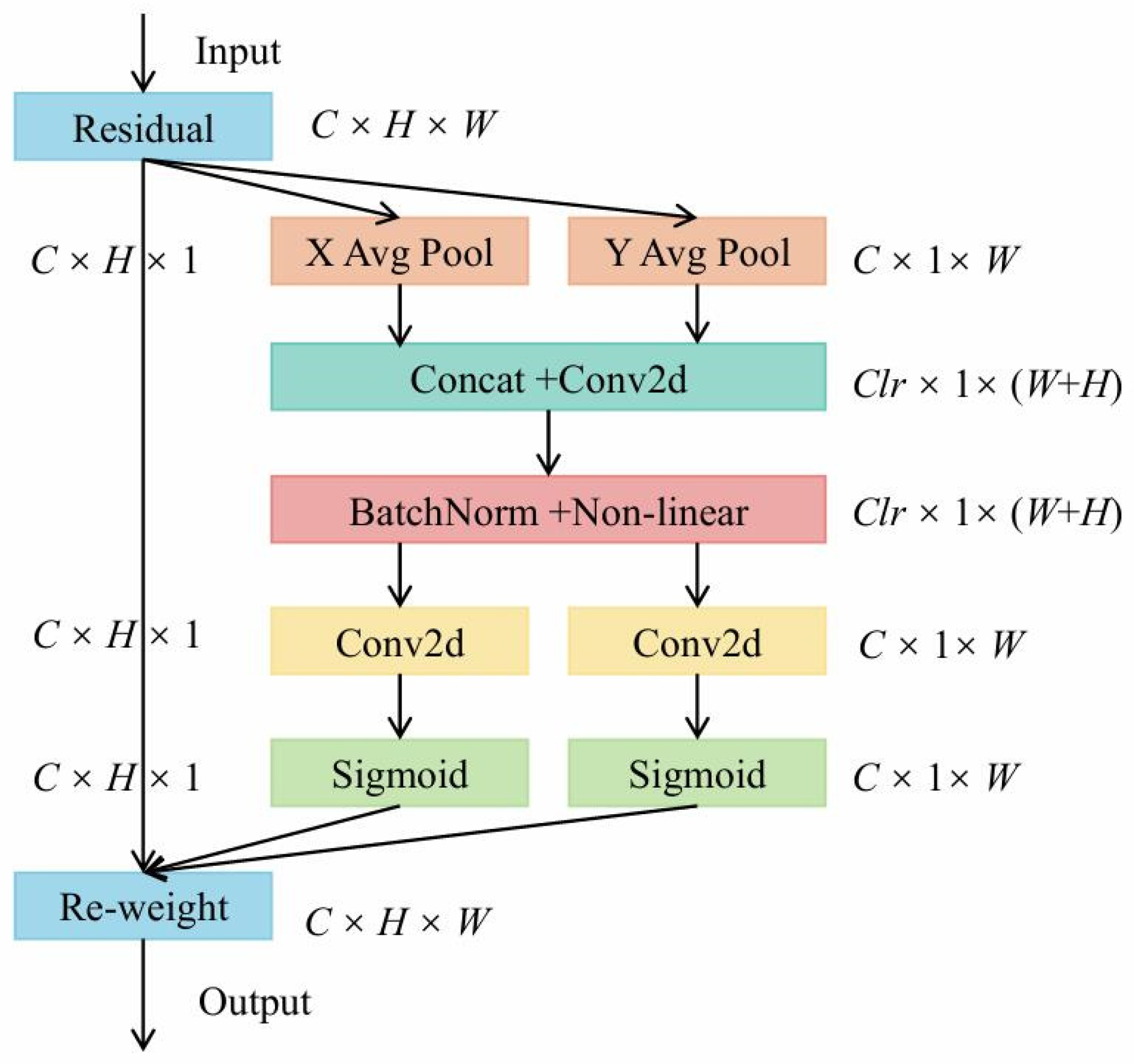
3.1.4. The Attention Mechanism CoordAtt
3.1.5. The Loss Function XIoU
3.2. Datasets
3.3. Evaluation Indicators
4. Experimental Findings
4.1. Platform for Conducting Experiments and Configuring Parameters
4.2. Comparison of Experiments
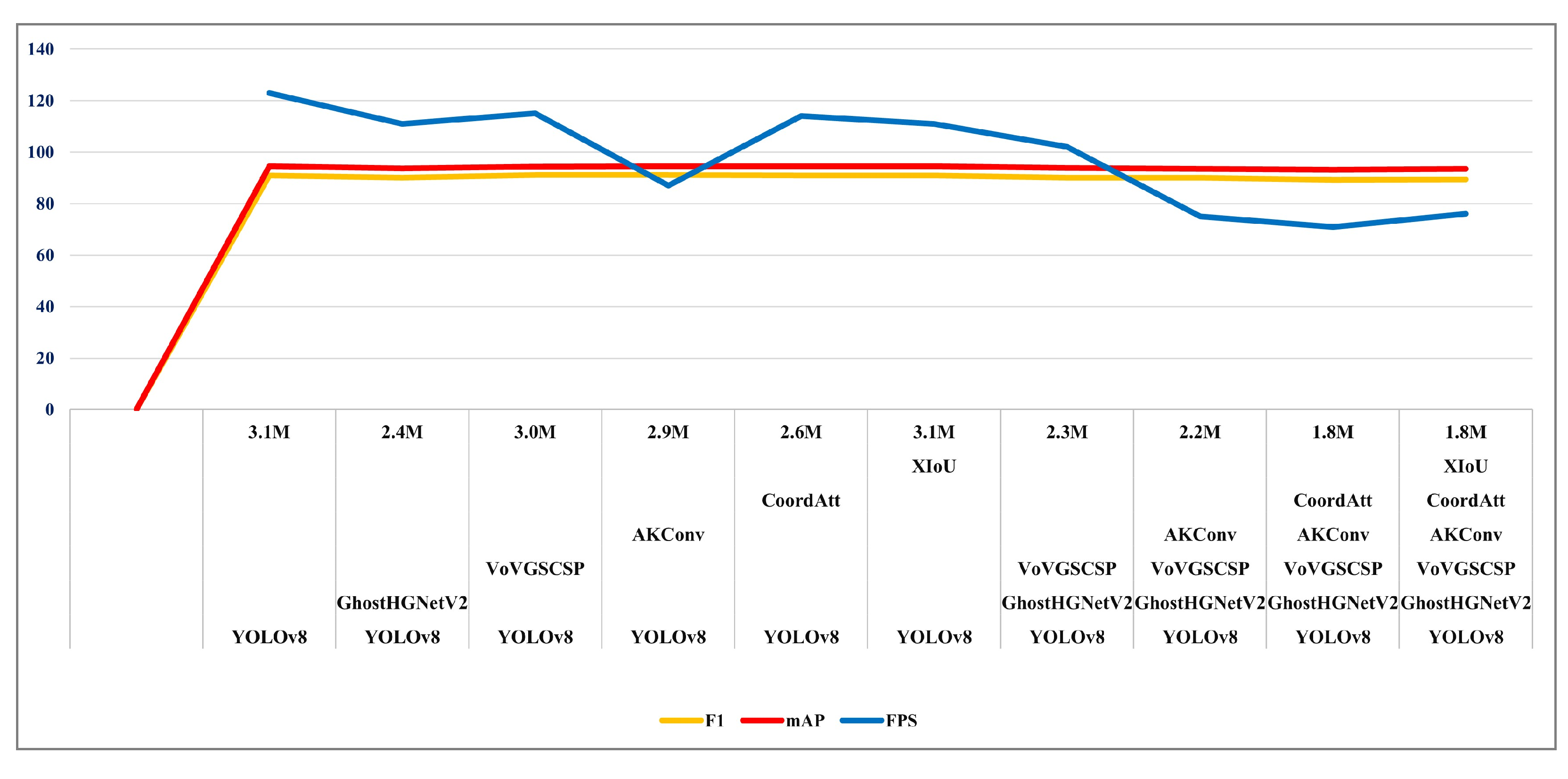
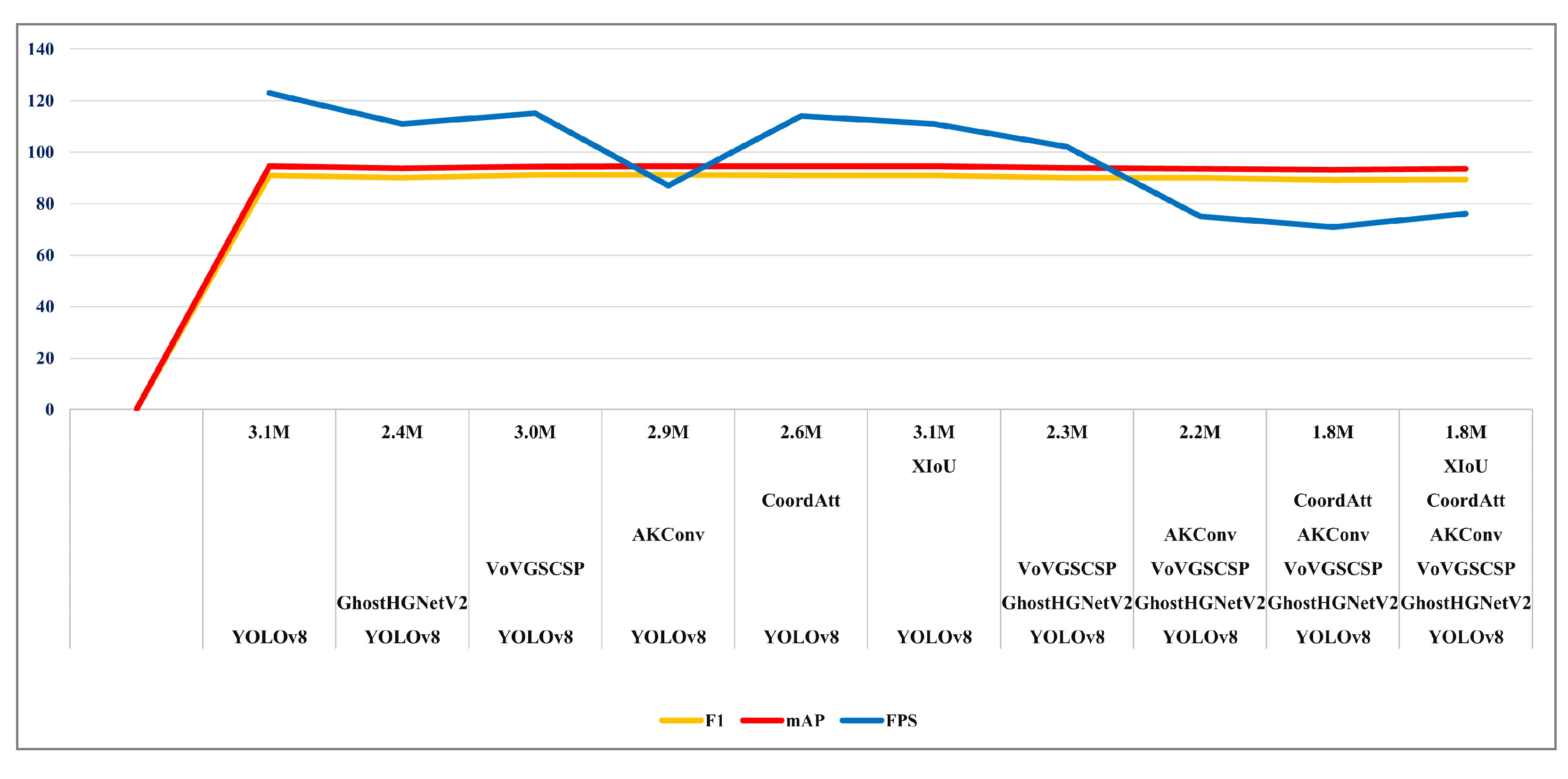
4.3. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, C.; Li, D.; Qi, J.; Liu, J.; Wang, Y. Infrared Small Target Detection Method with Trajectory Correction Fuze Based on Infrared Image Sensor. Sensors 2021, 21, 4522. [Google Scholar] [CrossRef] [PubMed]
- Cao, S.; Deng, J.; Luo, J.; Li, Z.; Hu, J.; Peng, Z. Local Convergence Index-Based Infrared Small Target Detection against Complex Scenes. Remote Sens. 2023, 15, 1464. [Google Scholar] [CrossRef]
- Fan, X.; Li, H.; Chen, Y.; Dong, D. UAV Swarm Search Path Planning Method Based on Probability of Containment. Drones 2024, 8, 132. [Google Scholar] [CrossRef]
- Oh, D.; Han, J. Smart Search System of Autonomous Flight UAVs for Disaster Rescue. Sensors 2021, 21, 6810. [Google Scholar] [CrossRef] [PubMed]
- Qiu, Z.; Bai, H.; Chen, T. Special Vehicle Detection from UAV Perspective via YOLO-GNS Based Deep Learning Network. Drones 2023, 7, 117. [Google Scholar] [CrossRef]
- Niu, C.; Song, Y.; Zhao, X. SE-Lightweight YOLO: Higher Accuracy in YOLO Detection for Vehicle Inspection. Appl. Sci. 2023, 13, 13052. [Google Scholar] [CrossRef]
- Shokouhifar, M.; Hasanvand, M.; Moharamkhani, E.; Werner, F. Ensemble Heuristic–Metaheuristic Feature Fusion Learning for Heart Disease Diagnosis Using Tabular Data. Algorithms 2024, 17, 34. [Google Scholar] [CrossRef]
- Zhang, Z. Drone-YOLO: An Efficient Neural Network Method for Target Detection in Drone Images. Drones 2023, 7, 526. [Google Scholar] [CrossRef]
- Yang, Z.; Lian, J.; Liu, J. Infrared UAV Target Detection Based on Continuous-Coupled Neural Network. Micromachines 2023, 14, 2113. [Google Scholar] [CrossRef]
- Fan, Y.; Qiu, Q.; Hou, S.; Li, Y.; Xie, J.; Qin, M.; Chu, F. Application of Improved YOLOv5 in Aerial Photographing Infrared Vehicle Detection. Electronics 2022, 11, 2344. [Google Scholar] [CrossRef]
- Tang, G.; Ni, J.; Zhao, Y.; Gu, Y.; Cao, W. A Survey of Object Detection for UAVs Based on Deep Learning. Remote Sens. 2024, 16, 149. [Google Scholar] [CrossRef]
- Wu, X.; Li, W.; Hong, D.; Tao, R.; Du, Q. Deep Learning for Unmanned Aerial Vehicle-Based Object Detection and Tracking: A survey. IEEE Geosci. Remote Sens. Mag. 2021, 10, 91–124. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Zitnick, C.L. Microsoft Coco: Common Objects in Context; Springer International Publishing: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Wang, Y.; Tian, Y.; Liu, J.; Xu, Y. Multi-Stage Multi-Scale Local Feature Fusion for Infrared Small Target Detection. Remote Sens. 2023, 15, 4506. [Google Scholar] [CrossRef]
- Chang, Y.; Li, D.; Gao, Y.; Su, Y.; Jia, X. An Improved YOLO Model for UAV Fuzzy Small Target Image Detection. Appl. Sci. 2023, 13, 5409. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation; IEEE Computer Society: Piscataway, NJ, USA, 2014. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 6. [Google Scholar] [CrossRef]
- Liu, M.; Wang, X.; Zhou, A.; Fu, X.; Ma, Y.; Piao, C. UAV-YOLO: Small Object Detection on Unmanned Aerial Vehicle Perspective. Sensors 2020, 20, 2238. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Hong, D.; Ghamisi, P.; Li, W.; Tao, R. MsRi-CCF: Multi-Scale and Rotation-Insensitive Convolutional Channel Features for Geospatial Object Detection. Remote Sens. 2018, 10, 1990. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot Multibox Detector; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Reis, D.; Kupec, J.; Hong, J.; Daoudi, A. Real-Time Flying Object Detection with YOLOv8. arXiv 2023, arXiv:2305.09972. [Google Scholar]
- Zeng, Y.; Zhang, T.; He, W.; Zhang, Z. YOLOv7-UAV: An Unmanned Aerial Vehicle Image Object Detection Algorithm Based on Improved YOLOv7. Electronics 2023, 12, 3141. [Google Scholar] [CrossRef]
- Zhao, X.; Xia, Y.; Zhang, W.; Zheng, C.; Zhang, Z. YOLO-ViT-Based Method for Unmanned Aerial Vehicle Infrared Vehicle Target Detection. Remote Sens. 2023, 15, 3778. [Google Scholar] [CrossRef]
- Wang, D.; He, D. Channel pruned YOLO V5s-based deep learning approach for rapid and accurate apple fruitlet detection before fruit thinning. Biosyst. Eng. 2021, 6, 210. [Google Scholar] [CrossRef]
- Qiu, M.; Huang, L.; Tang, B.-H. ASFF-YOLOv5: Multielement Detection Method for Road Traffic in UAV Images Based on Multiscale Feature Fusion. Remote Sens. 2022, 14, 3498. [Google Scholar] [CrossRef]
- Liu, F.; Qian, Y.; Li, H.; Wang, Y.; Zhang, H. Caffnet: Channel attention and feature fusion network for multi-target traffic sign detection. Int. J. Pattern Recognit. Artif. Intell. 2021, 35, 2152008. [Google Scholar] [CrossRef]
- Sahin, O.; Ozer, S. YOLODrone: Improved YOLO Architecture for Object Detection in Drone Images. In Proceedings of the 2021 44th International Conference on Telecommunications and Signal Processing (TSP), Brno, Czech Republic, 26–28 July 2021; pp. 361–365. [Google Scholar]
- Carrasco, D.P.; Rashwan, H.A.; García, M.Á.; Puig, D. T-YOLO: Tiny Vehicle Detection Based on YOLO and Multi-Scale Convolutional Neural Networks. IEEE Access 2023, 11, 22430–22440. [Google Scholar] [CrossRef]
- Zuo, Z.; Tong, X.; Wei, J.; Su, S.; Wu, P.; Guo, R.; Sun, B. AFFPN: Attention Fusion Feature Pyramid Network for Small Infrared Target Detection. Remote Sens. 2022, 14, 3412. [Google Scholar] [CrossRef]
- Zhang, M.; Li, B.; Wang, T.; Bai, H.; Yue, K.; Li, Y. CHFNet: Curvature Half-Level Fusion Network for Single-Frame Infrared Small Target Detection. Remote Sens. 2023, 15, 1573. [Google Scholar] [CrossRef]
- Dai, Y.; Wu, Y.; Zhou, F.; Barnard, K. Asymmetric Contextual Modulation for Infrared Small Target Detection. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 949–958. [Google Scholar]
- Li, S.; Yang, X.; Lin, X.; Zhang, Y.; Wu, J. Real-Time Vehicle Detection from UAV Aerial Images Based on Improved YOLOv5. Sensors 2023, 23, 5634. [Google Scholar] [CrossRef]
- Guo, Y.; Chen, S.; Zhan, R.; Wang, W.; Zhang, J. LMSD-YOLO: A Lightweight YOLO Algorithm for Multi-Scale SAR Ship Detection. Remote Sens. 2022, 14, 4801. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, Z.; Xu, G.; Cheng, S. Object Detection in UAV Aerial Images Based on Improved YOLOv7-tiny. In Proceedings of the 2023 4th International Conference on Computer Vision, Image and Deep Learning (CVIDL), Zhuhai, China, 12–14 May 2023; pp. 370–374. [Google Scholar]
- Chung, Y.H.; Su, C.Y. Object Detection Algorithm Based on Improved YOLOv7 for UAV Images. In Proceedings of the 2023 IEEE 5th Eurasia Conference on IOT, Communication and Engineering (ECICE), Yunlin, Taiwan, 27–29 October 2023; pp. 18–21. [Google Scholar]
- Suo, J.; Wang, T.; Zhang, X.; Chen, H.; Zhou, W.; Shi, W. HIT-UAV: A high-altitude infrared thermal dataset for Unmanned Aerial Vehicle-based object detection. Sci. Data 2023, 10, 227. [Google Scholar] [CrossRef] [PubMed]
- Aibibu, T.; Lan, J.; Zeng, Y.; Lu, W.; Gu, N. An Efficient Rep-Style Gaussian–Wasserstein Network: Improved UAV Infrared Small Object Detection for Urban Road Surveillance and Safety. Remote Sens. 2024, 16, 25. [Google Scholar] [CrossRef]
- Lv, W.; Xu, S.; Zhao, Y.; Wang, G.; Wei, J.; Cui, C.; Du, Y.; Dang, Q.; Liu, Y. DETRs Beat YOLOs on Real-time Object Detection. arXiv 2023, arXiv:2304.08069. [Google Scholar]
- Li, H.; Li, J.; Wei, H.; Liu, Z.; Zhan, Z.; Ren, Q. Slim-neck by GSConv: A better design paradigm of detector architectures for autonomous vehicles. arXiv 2022, arXiv:2206.02424. [Google Scholar]
- Zhang, X.; Song, Y.; Song, T.; Yang, D.; Ye, Y.; Zhou, J.; Zhang, L. AKConv: Convolutional Kernel with Arbitrary Sampled Shapes and Arbitrary Number of Parameters. arXiv 2023, arXiv:2311.11587. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13708–13717. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Small (0, 32 × 32) | Medium (32 × 32, 96 × 96) | Large (96 × 96, 640 × 512) | |
|---|---|---|---|
| HIT-UAV | 17,118 | 7249 | 384 |
| Train set | 12,045 | 5205 | 268 |
| Test set | 3331 | 1379 | 70 |
| Validation set | 1742 | 665 | 46 |
| Name | Related Configurations |
|---|---|
| Graphics processor | NVIDIA Quadro P6000 |
| Central processor | Intel(R) Core(TM) i9-9900k |
| Graphic processor memory size | 32 G |
| OS name | Win 10 |
| The computing platform | CUDA10.2 |
| Architecture for deep learning | Pytorch |
| Parameters | GFLOPs/G | Precision (%) | Recall (%) | F1 (%) | (%) | mAP50 (%) | |
|---|---|---|---|---|---|---|---|
| YOLOv8n | 3.1 M | 8.1 | 91.6 | 90.3 | 90.9 | 98.0 | 94.6 |
| ITD-YOLOv8 | 1.8 M | 6.0 | 90.3 | 88.6 | 89.4 | 98.2 | 93.5 |
| Model | Size | Parameters | F1 (%) | APPerson (%) | APVehicle (%) | APBicycle (%) | mAP50 (%) | FLOPs /G |
|---|---|---|---|---|---|---|---|---|
| YOLOv5s | 640 | 9.1 M | 91.1 | 93.2 | 98.3 | 93.1 | 94.9 | 23.8 |
| YOLOv5m | 640 | 25.0 M | 90.3 | 92.7 | 97.9 | 91.4 | 94.0 | 64.0 |
| YOLOv5l | 640 | 53.1 M | 91.2 | 92.5 | 98.1 | 91.1 | 93.9 | 134.7 |
| YOLOv7 | 640 | 36.5 M | 86.2 | 88.2 | 94.2 | 88.3 | 90.2 | 103.2 |
| YOLOv8s | 640 | 11.2 M | 91.1 | 93.0 | 98.2 | 91.4 | 94.2 | 28.4 |
| YOLO-ViT | 640 | 17.3 M | 90 | 91.3 | 98.1 | 90.6 | 94.5 | 33.1 |
| YOLOv5n | 640 | 2.5 M | 92.7 | 92.2 | 98.0 | 93.4 | 94.6 | 7.1 |
| YOLOv7-tiny | 640 | 6.1 M | 89.8 | 92.5 | 97.0 | 91.3 | 93.6 | 13.2 |
| YOLOv8n | 640 | 3.1 M | 90.9 | 92.4 | 98.0 | 93.4 | 94.6 | 8.1 |
| ITD-YOLOv8 | 640 | 1.8 M | 90.3 | 91.7 | 98.2 | 90.7 | 93.5 | 6.0 |
| YOLOv8 | GhostHGNetV2 | VoVGSCSP | AKConv | CoordAtt | XIoU | Parameters | FLOPs/G | F1 (%) | mAP (%) | FPS |
|---|---|---|---|---|---|---|---|---|---|---|
| √ | 3.1 M | 8.1 | 90.9 | 94.6 | 123 | |||||
| √ | √ | 2.4 M | 6.9 | 90.1 | 93.7 | 111 | ||||
| √ | √ | 3.0 M | 7.8 | 91.2 | 94.3 | 115 | ||||
| √ | √ | 2.9 M | 8.0 | 91.2 | 94.6 | 87 | ||||
| √ | √ | 2.6 M | 7.8 | 91.0 | 94.5 | 114 | ||||
| √ | √ | 3.1 M | 8.1 | 90.9 | 94.6 | 111 | ||||
| √ | √ | √ | 2.3 M | 6.6 | 90.1 | 93.9 | 102 | |||
| √ | √ | √ | √ | 2.2 M | 6.3 | 90.1 | 93.6 | 75 | ||
| √ | √ | √ | √ | √ | 1.8 M | 6.0 | 89.3 | 93.1 | 71 | |
| √ | √ | √ | √ | √ | √ | 1.8 M | 6.0 | 89.4 | 93.5 | 76 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, X.; Zhang, W.; Zhang, H.; Zheng, C.; Ma, J.; Zhang, Z. ITD-YOLOv8: An Infrared Target Detection Model Based on YOLOv8 for Unmanned Aerial Vehicles. Drones 2024, 8, 161. https://doi.org/10.3390/drones8040161
Zhao X, Zhang W, Zhang H, Zheng C, Ma J, Zhang Z. ITD-YOLOv8: An Infrared Target Detection Model Based on YOLOv8 for Unmanned Aerial Vehicles. Drones. 2024; 8(4):161. https://doi.org/10.3390/drones8040161
Chicago/Turabian StyleZhao, Xiaofeng, Wenwen Zhang, Hui Zhang, Chao Zheng, Junyi Ma, and Zhili Zhang. 2024. "ITD-YOLOv8: An Infrared Target Detection Model Based on YOLOv8 for Unmanned Aerial Vehicles" Drones 8, no. 4: 161. https://doi.org/10.3390/drones8040161
APA StyleZhao, X., Zhang, W., Zhang, H., Zheng, C., Ma, J., & Zhang, Z. (2024). ITD-YOLOv8: An Infrared Target Detection Model Based on YOLOv8 for Unmanned Aerial Vehicles. Drones, 8(4), 161. https://doi.org/10.3390/drones8040161