1. Introduction
The study of tree characteristics is one of the most important applications in various ecological sciences, such as forestry and agriculture [
1,
2]. Assessing the health of trees is perhaps the most significant and widely used application in studies that focus on assessing tree properties. The health of trees can effectively be assessed using remote sensing data from satellite sensors. These sensors are essentially satellite cameras that utilize the spectrum from ultraviolet to the far-infrared. Therefore, the estimation of their health can be accomplished by calculating vegetation indices from remote sensing data collected in the electromagnetic spectrum of visible and near-infrared [
3]. In recent years, studies evaluating the health of trees and vegetation using such data have been increasing, highlighting the contribution of remote sensing systems. Recent increased developments in unmanned aerial systems have further enhanced these applications by providing the capability to use very high-resolution spatial data [
4].
In the recent past, the detection of individual trees was accompanied by significant difficulty, as it depended on the homogeneity of the data, and accuracy tended to decrease as the variety of natural elements increased [
1]. This problem was possible to easily overcome by using hyperspectral data in combination with LiDAR (Light Detection and Ranging) data. However, challenges in tree detection persisted due to the influence of atmospheric conditions. The use of unmanned aerial vehicles (UAVs) successfully addressed this obstacle. UAVs have the capability to adjust their flight altitude, eliminating limitations posed by atmospheric conditions and cloud cover. Simultaneously, these aircraft are equipped with exceptionally high spatial resolution and can provide data quickly and reliably. Unlike satellite systems limited to specific orbits around the Earth, UAVs can swiftly capture and acquire aerial images, thus providing information much faster. Furthermore, these systems are easily adaptable to capturing images with the best possible clarity while considering noise limitations [
5].
The isolation of tree information has traditionally relied on classifiers that categorized pixels based on their spectral characteristics. However, in recent years, these classifiers have been replaced by ML techniques, such as convolutional neural networks, which aim to identify objects in images [
6,
7]. Convolutional neural networks were originally designed for object recognition in ground-based images, but some researchers have adapted these algorithms for object recognition from aerial images using remote sensing data. Nevertheless, most researchers have focused on pattern recognition through computer vision for the detection of objects such as buildings or infrastructure with distinctive shapes such as airports, vehicles, ships, and aircraft [
8,
9]. For instance, Xuan et al. [
10] used convolutional networks for ship recognition from satellite systems. One of the most popular applications is the detection and segmentation of trees in agricultural fields [
11,
12,
13]. For this application, the use of remote sensing data from UAV platforms is recommended. The aerial images provided by such systems are particularly suitable for these applications due to their high spatial resolution. These applications are of significant utility in precision agriculture.
Many researchers have used convolutional neural networks for tree detection from RGB aerial photographs, aiming to assess the performance of those networks in applications involving a wide variety of tree species and developmental stages. Most of them have utilized the Mask R-CNN algorithm [
7,
14,
15,
16]. Additionally, many researchers and practitioners have applied these techniques to precision agriculture applications, such as assessing tree health [
16] and estimating biomass [
15]. The Mask R-CNN algorithm was preferred over others for object detection in remote sensing products due to its additional capability of object segmentation by creating masks, thereby providing precise object boundaries. Consequently, in this study, tree detection and segmentation were performed using the Detectron2 algorithm based on the Mask R-CNN algorithm. Detectron2 offers the ability to create masks for each detectable object and delivers better performance in terms of speed and accuracy [
17].
By having precise boundaries for each tree, it is possible to estimate their health. This can be achieved by calculating specific vegetation indices using remote sensing data. These indices are computed by combining spectral channels in the visible and near-infrared regions. Vegetation appears to be better represented in the green and red channels of the visible spectrum and in the near-infrared channel, as these channels capture its characteristics and morphology effectively [
18,
19]. Therefore, vegetation indices can be utilized for assessing vegetation health, detecting parasitic diseases, estimating crop productivity, and for other biophysical and biochemical variables [
20]. Calculating these indices from data collected by unmanned aerial vehicles (UAVs) provides extremely high accuracy in assessing vegetation health, eliminating the need for field-based research. The use of UAV systems for forestry and/or crop health using machine learning techniques for tree detection has been previously conducted by various researchers. For instance, Safonova et al. [
15] and Sandric et al. [
16] utilized images acquired from UAV systems to study the health of cultivated trees.
Based on the above, in the present study, an automated method is proposed for assessing vegetation health, providing its accurate boundaries. Accordingly, the Detectron2 algorithm is configured to read UAV imagery, recognize the trees present in it, and segment their boundaries by creating a mask of boundaries. The accuracy of the herein proposed algorithm is compared against the Support Vector Machine (SVM) method, which is a widely used and accurate technique for isolating information in remote sensing data. A further accuracy assessment step involves the comparisons of the outputs produced from the two methods against those obtained from the direct digitization method using photointerpretation. To the authors’ knowledge, this comparison is conducted for the first time, and this constitutes one of the unique aspects of contribution of the present research study.
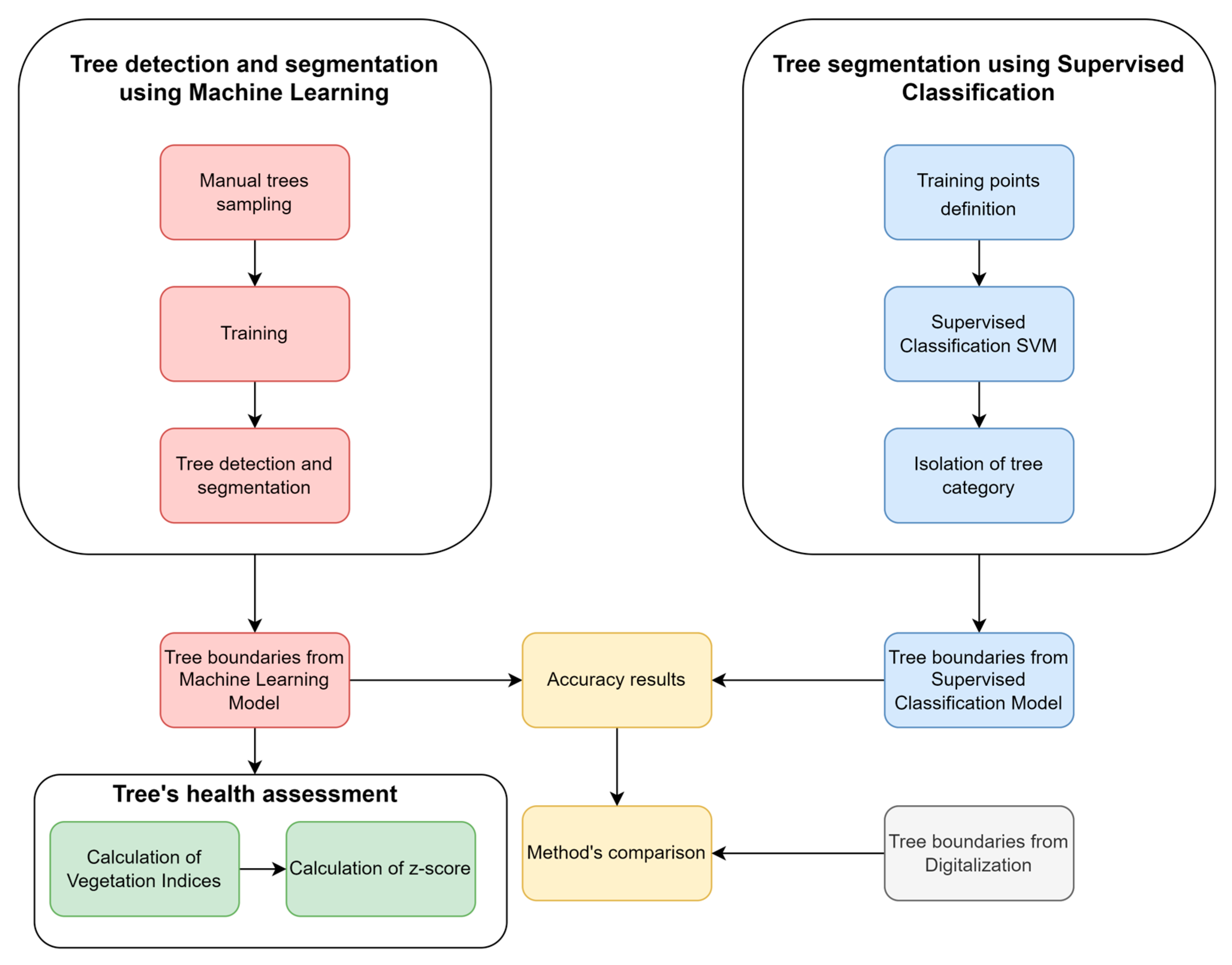
4. Methodology
4.1. Tree Crown Detection Using a Machine Learning Model
During the first part of the analysis (
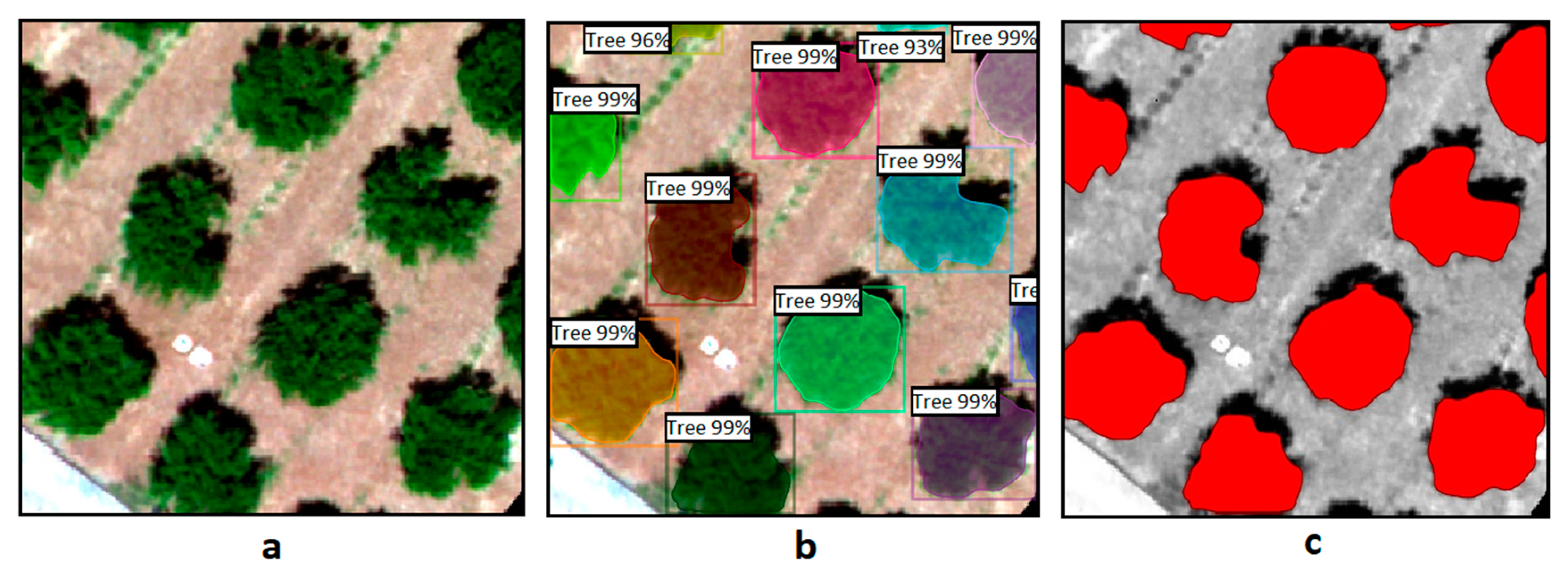
Figure 2), the objective is to detect the boundaries of trees through the training of a Detectron2 algorithm written in the Python programming language. This algorithm represents a parameterized (tailored to the needs of the current study) version of the Detectron2 algorithm. By taking images in which objects have been defined, essentially setting boundaries on their image elements, the algorithm undergoes training and subsequently gains the ability to autonomously set the boundaries of these objects in new images. The training for tree detection was conducted using an already trained model capable of recognizing various living and non-living objects such as humans, cars, books, dogs, airplanes, etc. It should be noted that the class of trees is absent from this specific model. Even if this class were present, it would not be able to recognize the trees in aerial photographs, as the model is not trained to observe objects from a vertical perspective above the ground. The algorithm’s code was developed herein in the Google Colab environment due to the availability of free GPU resources it provides, with the code running on Google’s servers.
It is essential for the training process to define the boundaries of trees so that the algorithm can correctly identify whether the object presented to it is a tree or not. To facilitate the algorithm in terms of the computational power required, the aerial photograph was divided into equal-sized regions (300 × 300 pixels). This division was performed using the “Raster Divider” plugin in the QGIS environment. Tree boundary delineation was accomplished through digitization using the “label studio” program. This choice was made because it has the capability to export data in COCO (Common Objects in Context) format [
23]. This format was necessary, as it is the most widely used format for defining large-scale data for object detection and segmentation applications in computer vision utilizing neural networks. The more trees presented to the algorithm, the more accurate it becomes in detecting them. Therefore, two-thirds of the trees in the area were utilized for training. The code sequence result described is the storage of images representing the boundaries. The next necessary step is to extract this information. The images were first georeferenced to restore their coordinates (which were lost during their introduction to the algorithm). Afterward, they were merged into a new mosaic. Subsequently, only the information presenting the trees was isolated. The georeferencing of the images and the conversion into a unified mosaic were carried out in the QGIS environment, while tree extraction was performed in SNAP software. Finally, this information was transformed from raster format to vector format.
4.2. Tree Crown Detection Using Supervised Classification
It is crucial to examine the accuracy of the algorithm, i.e., its ability to correctly delineate the trees it detects, compared to other methods for isolating this information. Therefore, in this study it was decided to compare the results against those of the supervised classification method. Such a method relies on the reflective characteristics of image pixels (pixel-based) in an image [
24]. Specifically, the chosen supervised classification method is SVM, which is based on machine learning. The algorithm essentially uses kernel functions to map non-linear decision boundaries from the primary data to linear decisions in higher dimensions [
25]. It was selected, among other methods, because it is associated with high precision results and handles classes with similar spectral characteristics and data with high noise (Noisy Data) more effectively [
26].
For the implementation, spectral characteristics of each pixel in the aerial photograph were utilized across all available channels, including eight channels in the visible spectrum and one channel in the near-infrared spectrum. Each pixel was classified into one of the predefined categories (classes) based on the entities (natural and man-made) observed in the aerial photograph. These categories were as follows:
Trees.
Tree shadow.
Grass.
Bare Soil.
Road.
In the class of trees, it is expected that all the trees in the aerial photograph will be classified. This is the most crucial class because it is the one against which the algorithm will be compared. Due to the sun’s position, most trees cast shadows that are ignored by the Detectron2 algorithm. Therefore, it is important to create a corresponding class (tree shadow) to avoid any confusion with the class of trees. Additionally, three other classes were created to represent the soil, the grass observed in various areas, and the road passing through the cultivated area. For each class, a sufficient number of training points (ROIs) are defined (approximately 6000 pixels) that are considered representative. Thus, the values displayed by these points in each spectral channel of the image are considered as thresholds for classifying all other pixels. It is essential to examine the values of the training points to ensure they exhibit satisfactory separability to avoid confusion between the values of different classes. During this process, the spectral similarities of the training points are compared to determine how well they match. The lower the similarity between two spectral signatures, the higher the separability they exhibit. The supervised classification process results in a thematic map where each pixel of the aerial photograph has been classified into one of the five classes. From those classes, only the information related to the class of trees that are detected is isolated. Thus, this information, as was the case with the algorithm, is transformed from a raster into a polygonal format.
4.3. Calculation of Accuracy for Each Method and Method Comparison
4.3.1. Accuracy of the Machine Learning Algorithm
It is important to assess the accuracy of each method individually and to compare the accuracy of the results among them. The accuracy of the Detectron2 algorithm was evaluated in terms of its correct recognition of objects, based on three statistical indicators that were calculated [
7,
16].
where Precision is calculated as the number of correctly identified trees (True Positive) divided by the sum of correctly identified trees (True Positive) and objects that were incorrectly identified as trees (False Negative). Recall is calculated as the number of correctly identified trees (True Positive) divided by the sum of correctly identified trees (True Positive) and the number of objects that were identified as trees in areas with zero tree presence (False Positive). The F1 score represents the overall accuracy (OA) of the model and is calculated as twice the product of the two aforementioned indicators divided by their sum.
4.3.2. Supervised Classification Accuracy
Regarding supervised classification accuracy, it is important to calculate its OA, i.e., how well the pixels of the aerial image have been classified correctly into the various assigned classes [
24,
27,
28]. To achieve this, certain validation samples (approximately 2000 pixels) are defined for each class. The pixels of the validation samples are evaluated for their correct classification into each of the classification classes, thus giving the OA. A significant factor in the accuracy presented by the classification is the Kappa coefficient. This index indicates to what extent the accuracy of the classification is due to random agreements and how statistically significant it is [
29]. It is beneficial to examine the producer’s accuracy (PA) and user accuracy (UA). The PA shows how well the training points of the classification were classified into each class. It is calculated as the percentage of correctly classified pixels compared to the total number of control pixels for each class. UA indicates the probability that the classified pixels actually belong to the class into which they were classified. It is calculated as the percentage of correctly classified pixels compared to the total number of classified pixels for each class.
4.3.3. Comparison of the Two Methods
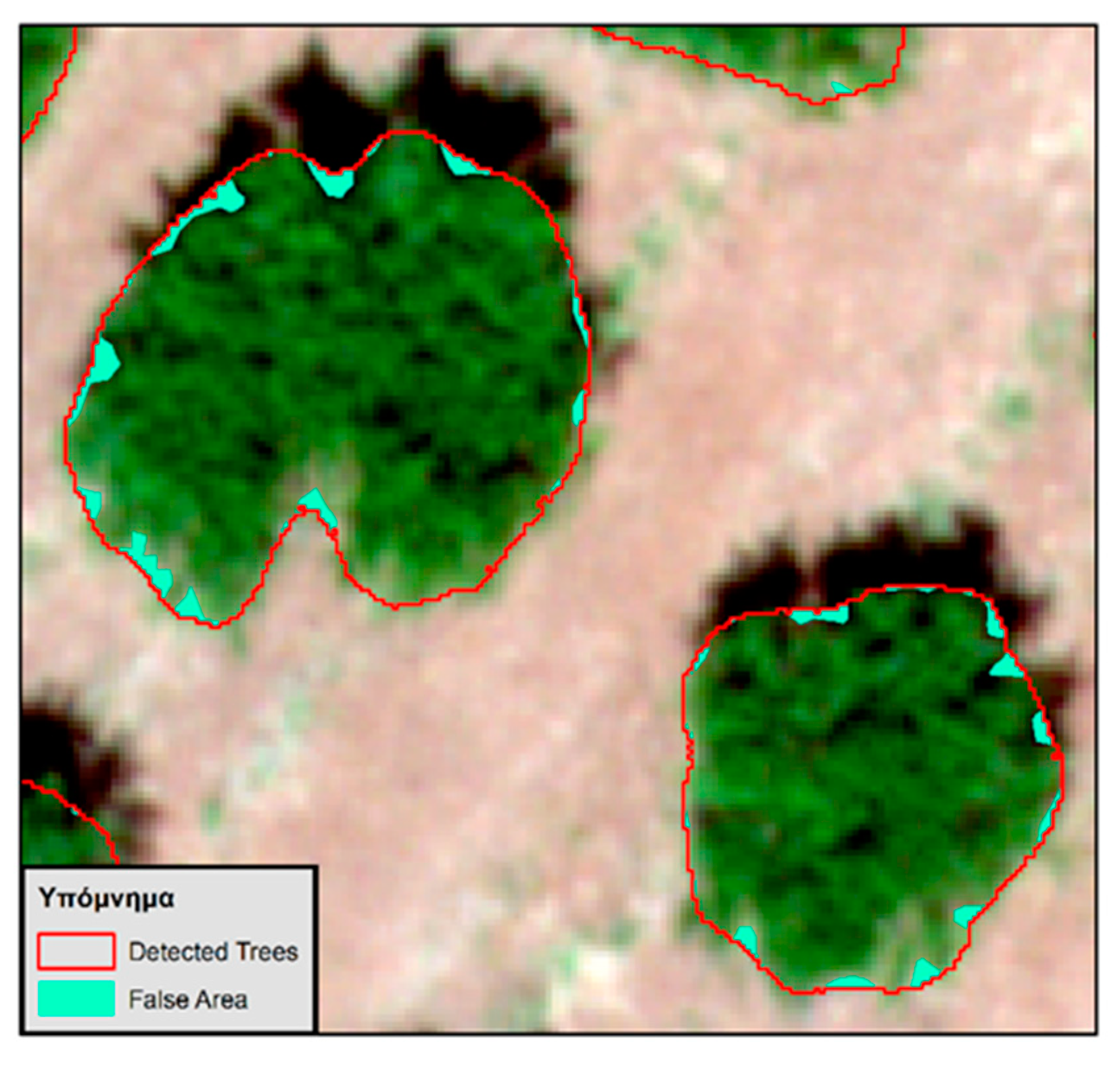
It is important to compare the Detectron2 algorithm with one of the most common methods for vegetation boundary delineation in aerial imagery, the supervised classification method, in order to assess its performance. The results of this comparison demonstrate the performance of the model, highlighting its significance. The two models are compared in terms of their accuracy with the digitization method. While the results of digitization, although more accurate as they are carefully executed by the researcher, lack automation and are thus considered a very time-consuming method. Therefore, three accuracy indexes are calculated [
30,
31].
From the above equations, the detected area is the common area between the trees generated by the algorithm and the trees resulting from the digitization process. The false area (or commission error) is the area present in the algorithm’s trees but absent from the digitization trees. Finally, the skipped area (or omission error) is the area in the digitization trees that exists but is missing in the algorithm’s trees. The above equations, in addition to the algorithm’s trees, are also calculated for the trees that result from the classification process. This enables the comparison of the two methods.
4.4. Assessment of Vegetation Health in Detected Trees
The next step involved the calculation of the health of the trees identified by the Detectron2 algorithm in the second section. This step essentially constitutes an application whereby the detection and segmentation of trees within a cultivation could find a useful application. Such an application could provide quick updates to the grower regarding the health status of their crop, enabling them to take necessary actions. To calculate the health, three different vegetation health indices are defined: NDVI, VARI, and GLI. The implementation steps are described in more detail next.
4.4.1. Normalized Difference Vegetation Index (NDVI)
The index presented by Rouse et al. (1974) [
32] was introduced to indicate a vegetation index that distinguishes vegetation from soil brightness using Landsat MSS satellite data. This index minimizes the impact of topography. Due to this property, it is considered the most widely used vegetation index. The index is expressed as the difference between the near-infrared and red bands of visible light, divided by their sum. It yields values between −1 (indicating the absence of vegetation) and 1 (indicating the presence of vegetation), with 0 representing the threshold for the presence of vegetation [
32].
4.4.2. Visible Atmospherically Resistant Index (VARI)
Introduced by Kaufman & Tanre (1992) [
33], this index was designed to represent vegetation among the channels of the visible spectrum. The index is less sensitive to atmospheric conditions due to the presence of the blue band in the equation, which reduces the influence of water vapor in the atmospheric layers. Because of this characteristic, the index is often used for detecting vegetation health [
33].
4.4.3. Green Leaf Index (GLI)
Presented by Lorenzen & Madsen (1986) [
34], this index was designed to depict vegetation using the three spectral channels of visible light, taking values from −1 to 1. Negative values indicate areas with the absence of vegetation, while positive values indicate areas with the presence of vegetation [
34].
4.4.4. Standard Score
For the calculation of vegetation health, the Standard Score, or z-score, of all three vegetation indices is computed. The z-score is calculated as the difference between the values of each tree’s vegetation index and the mean value of these indices for all trees, divided by the standard deviation of these indices for all trees.
6. Discussion
Over the past decade, the use of unmanned systems in precision agriculture has experienced significant growth for monitoring crops and real-time disease prevention [
35,
36]. Utilizing artificial intelligence has brought unprecedented computational time savings, adding an automation element. This study successfully managed to detect and segment the boundaries of trees presented in an UAV aerial image through an automated process, by fine-tuning a ML object detection algorithm. This algorithm demonstrated exceptionally high accuracy in tree recognition, achieving a 100% F1 score. It correctly identified all trees without classifying other objects as trees or falsely detecting trees in areas with no presence of trees. In comparison, other similar studies where soil and vegetation colors were very similar also reported very high accuracy [
7,
14,
15,
16]. This highlights the high precision exhibited by convolutional neural networks in such applications.
The supervised classification method of SVM demonstrated practical high accuracy in classifying pixels based on their spectral characteristics. The separability of the training points yielded excellent results, with the majority of them approaching absolute separability (a value equal to 2). The OA reached a very high percentage, and the kappa coefficient showed a very satisfactory result. Both the PA and UA indices exhibited high accuracy in the context of efficient classification. Their results indicated a generally high likelihood of correctly classifying the training points into various classes. However, the classes of trees and grass showed lower values in these indices. It is highly likely that the pixels pertaining to this class may belong to both the tree and grass classes and vice versa. These two classes are closely related as they both belong to the vegetation of the area. Therefore, the spectral signatures of their pixels have the highest similarity compared to any other pair of classes, potentially leading to confusion between these two classes.
The accuracy of the algorithm’s model, compared to the supervised classification SVM model, was found to be superior in segmenting the boundaries of trees. When comparing the results of these two models with the digitization process, the algorithm’s model exhibited higher accuracy in the common boundary detection index and the missed boundary detection index. However, the classification model showed greater accuracy in the false boundary detection index. This can be attributed to the fact that the algorithm appeared to be less capable of detecting abrupt changes in the boundaries of trees, making them appear more rounded.
The estimation of vegetation was conducted using three different vegetation indices. Two of these indices were calculated exclusively from the visible spectrum channels. Although the VARI index is primarily used for detecting the vigor of trees and the development of their branches, and the GLI index is used for detecting chlorophyll in their foliage, the two indices did not show significant differences. Despite the small difference between them, the GLI index is considered more reliable due to its ability to capture the interaction of the green spectral channel with the tree foliage [
16]. On the other hand, the NDVI vegetation index, which includes the near-infrared channel in its calculation, appeared to produce contrasting results compared to the other two indices. The major differences were observed mainly in extreme values, with trees that exhibited relatively high vegetation health in the two visible indices showing relatively low vegetation health in the NDVI, and vice versa. However, the NDVI index is considered the most reliable among the three indices because it utilizes the near-infrared spectrum, which provides better information about vegetation characteristics and morphology than other parts of the spectrum [
18,
19]. Regarding tree health, all three indices indicated their health as moderate, as none of the indices showed extreme z-score values at a 95% confidence level.
Another particularly important factor influencing the results of this study is the flight conditions of the UAV, such as flight altitude and acquisition angles. The flight altitude of the UAV is proportional to the spatial resolution of the UAV’s imagery. Segmentation methods, in this case Detectron2, are influenced by the spatial resolution of the imagery. As the altitude of the UAV’s imagery increases, the detection accuracy of the algorithm will be deteriorated. In addition, increased altitude can lead to geometric distortions and reduced image resolution, further complicating object identification. Apart from flight altitude, the imagery acquisition angle also impacts the results and the performance of the algorithm. UAV images captured from non-vertical angles can introduce perspective distortion, making it difficult to accurately determine object dimensions and orientations. For example, in a recent study by [
37] are discussed the key challenges in UAV imagery object detection, including small object detection, object detection under complex backgrounds, object rotation, and scale change. As the detection and segmentation effect of deep learning (DL) algorithms from UAV images is affected by the different heights and shooting angles of the UAV images acquisition, it would be interesting to perform an evaluation of the algorithms herein at different altitudes and shooting angles to determine its sensitivity to changes in object size and image quality.
All in all, from the results obtained herein, it is evident that the Detectron2 algorithm, upon which the analysis algorithm relied, is capable of object detection and segmentation in aerial images beyond ground-based images. The detection of trees achieved perfect accuracy (F1 score = 100%), and the segmentation of their boundaries also yielded satisfactory results. However, it is essential to note that the algorithm may exhibit reduced accuracy when dealing with tree species that differ significantly in shape and color from citrus trees. This limitation of the model can be effectively resolved through further training on other types of trees. Although the training process requires a significant amount of time for both data preparation and computational time, the more the algorithm is trained, the more accurate it becomes. Therefore, while training the algorithm demands time and a vast amount of data, after extensive training on various datasets, the algorithm will be capable of detecting and segmenting objects with the same accuracy as a human researcher. This process clearly demonstrates the significant contribution of artificial intelligence to the automation of processes through machine learning in the context of UAV data exploitation for environmental studies.
7. Conclusions
The present study proposed a new algorithm to detect and segment the boundaries of trees in an aerial image of a cultivated area with mandarin trees using an automated approach, using a ML algorithm developed in the Python programming language. The outcome of the algorithm was utilized in assessing tree health. The innovation of the methodology is highly significant, as it demonstrates that, by employing artificial intelligence techniques, it is possible to create a tool for automated object recognition and boundary delineation in an image, thereby saving valuable time for researchers. Moreover, perhaps for the first time, there is a presentation of the comparison of the accuracy of an object segmentation algorithm with the SVM method.
Following the methodology presented herein, the detection and segmentation of trees in the cultivated area became feasible. The use of the tool makes it possible to save valuable time by offering automation for a similar research study, where object detection and segmentation would otherwise be performed manually by the researcher through the digitization process. The algorithm successfully detected all the trees presented in the study, assigning the correct classification category to each tree without falsely categorizing them into any other existing categories of the training model. The detection accuracy was exceptionally high, achieving an F1 score of 100%. The comparison of the accuracy results shows that the Detectron2 algorithm is more efficient in segmenting the relevant data when compared to the supervised classification model in the indices of common detected and skipped area rate.
In summary, this study credibly demonstrated the significant contribution of artificial intelligence in precision agriculture, utilizing high-resolution data for the timely monitoring of crop conditions. The combination of remote sensing data with ML algorithms provides cost-effective and rapid solutions, eliminating the need for field research while introducing automation. Technological advancements have led to unprecedented growth in agriculture development and modernization over the last decade. Artificial intelligence, as exemplified in this article, is poised to further accelerate this progress by offering solutions that save both time and money. The development of artificial intelligence has already demonstrated its value and is expected to gain higher recognition in the future as it finds applications in an increasingly diverse range of fields. The latter remains to be seen.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}