1. Introduction
Insulators, anti-vibration hammers, and arc sags are essential components of transmission lines. Each plays a distinct role: insulators fix charged conductors and provide electrical insulation [
1], anti-vibration hammers suppress inertial fluctuations between towers [
2], and arc sags help detect the status of transmission lines [
3]. Transmission lines, as links between power plants and distribution stations, are widely distributed in mountainous forests, rivers and lakes, fields and hills, etc. [
4]. The complex and variable nature of the geographic environment makes detecting insulators, anti-vibration hammers, and arc sags challenging. Transmission lines are exposed for long periods to adverse conditions such as drastic temperature changes, wind and sun exposure, and voltage and mechanical stresses [
5,
6], which are prone to undetectable potential hazards such as missing insulator sheds [
7], dislodged anti-vibration hammers [
8], and tilted arc sags [
3,
9]. Thus, it seriously affects the safe operation of the entire power grid system [
10]. Therefore, as preparation work for fault detection and high-voltage transmission line inspection tasks, inspecting insulators, anti-vibration hammers, and arc sags is vital.
In the past, the inspection of transmission lines mainly relied on manual visual inspection, which is inefficient and costly and prone to errors in leak detection and other situations [
5]. Technological progress has driven the sustained development of intelligent robots [
11] such as unmanned vehicles [
12], unmanned aerial vehicles [
13], and unmanned boats [
14]. In particular, UAVs have made breakthroughs in high flexibility [
15], safer operation [
16], and cost reduction [
17], which gives them broad application scenarios in the fields of search and rescue [
10], military surveillance [
18], urban planning [
19], transportation [
20], ecological security [
21], and agricultural vegetation [
22]. Regarding transmission line inspection, using UAVs is also of great value. For example, the use of drones is not only unaffected by whether the surrounding environment is harsh or not [
12] but also allows drones to obtain a large number of image data exponentially more tremendously than humans at the same time [
23]. Therefore, this paper focuses on accurately identifying high-voltage transmission line insulators, anti-vibration hammers, and arc sags: targets that UAVs take.
Compared to hyperspectral sensors, radar sensors, and infrared thermal sensors, optical sensors have the characteristics of low costs, fast imaging speeds, and easy operation [
24]. Therefore, the task of the inspection of transmission lines based on optical sensors loaded on drones has attracted much attention [
25]. Although UAVs can capture a large number of optical image data [
23], due to the different shooting distances and angles [
26,
27], lighting [
25], and other factors [
26,
27], which make the captured target images of insulators, anti-vibration hammers, and arc sags have problems such as mutual occlusion and small image proportions, inspecting transmission lines targets task such as insulators, anti-vibration hammers, and arc sags, which is complicated.
With the vigorous development of computer vision and deep learning technologies, more and more research has been using these technologies for object localization and detection. The object detection methods based on deep neural networks include two-stage Faster R-CNN [
28], Mask R-CNN [
29], single-stage SSD [
30], YOLO [
31], and the anchor-free models CornerNet [
32] and CenterNet [
33]. Lu et al. [
34] combined a Multi-Granular Fusion Network (MGFNet) and Object Detection Network to identify minor defects in insulators under complex backgrounds accurately. Zhao et al. [
8] used an improved YOLOv7 model to identify the corrosion of anti-vibration hammers in complex backgrounds. Song et al. [
3] achieved the accurate segmentation of arc sags on transmission lines using CM-Mask RCNN. The more complicated the image background is, and the smaller the target proportion is, the worse the model recognition effect will be. Varghese et al. [
35] detected insulator strings quickly in transmission lines by combining lightweight EfficientNetB0 and weight-based attention mechanisms. However, these methods require a series of designs for hyperparameters, such as anchor boxes.
The Facebook AI Research (FAIR) team has proposed an end-to-end object detection algorithm, Detection Transformer (DETR) [
36], which avoids a series of post-processing processes such as NMS. It transforms object detection problems into ensemble prediction problems, opening up a new direction for using transformers for visual tasks. Lu et al. [
37] used the CSWin transformer to obtain image features at different levels to achieve multi-scale representation and assist in multi-scale object detection. Rao et al. [
38] proposed a Siamese transformer network (STTD)-based method that achieves unique advantages in suppressing image background to a lower level and highlighting targets with high probability. Huang et al. [
39] used DETR as a baseline and combined it with the dense pyramid pooling module DPPM to detect smoke objects in forest fires at different scales. However, the DETR-series methods still face the issue of balancing accuracy and speed in detecting small targets in complex backgrounds.
To accurately identify small targets in transmission lines under complex backgrounds, this paper proposes a detection method for the insulator, vibration damper, and arc sag based on a deep neural network. The main contributions of this paper are as follows:
This paper proposes a transmission line insulator, anti-vibration hammer, and arc sag detection model called TLI-DETR. As an end-to-end target detection model, this model can accurately locate transmission line targets in complex backgrounds and achieves the best balance between calculation speed and detection accuracy, which would supply the basis for an overhead transmission line inspection strategy according to the existing standard, DL/T 741-2019 [
40].
Considering the transmission line’s complex topography, this paper adopts the IMSRCR algorithm to enhance the edge feature while effectively suppressing noise, which assures subsequent image feature extraction.
This paper introduces MoCo’s extracted edge and semantic information into the feature extraction network as incremental information, which significantly enhances the robustness of the feature extraction from detection targets and effectively boosts the detection accuracy of transmission-line small targets.
Aiming at the rectangular features of transmission line targets in drone aerial images and the size changes caused by shooting angles and distances, this paper conducts statistical analysis on the area and aspect ratio of the dataset. Based on this prior information, the TLI-DETR model generates object query vectors to better adapt to the detection needs of transmission line targets.
2. Related Work
The detection of transmission line components based on optical images is mainly realized based on image processing and vision technology.
The traditional detection of transmission line components is mainly achieved through image processing technology. Zhai et al. [
41] regarded the insulator fault detection problem as a morphological detection problem, first locating the insulator by fusing its color and gradient features, then separating the insulator through its salient color features, and finally using adaptive morphology to identify and locate faulty insulators. Huang et al. [
42] used image gray-scale processing, local difference processing, edge intensity mapping, and image fusion to enhance the features of the shockproof hammer, followed by threshold segmentation and morphological processing to segment the shockproof hammer. Finally, they identified the shockproof hammer accurately using the rusting area ratio and color difference index parameters. Song et al. [
1] used a segmentation algorithm to obtain the center coordinates of the arc sag and then combined beam-method leveling, the spatial front rendezvous, and spatial curve fitting methods to achieve the purpose of the economical and efficient inspection of the arc sag. Wu et al. [
43], considering that a bird’s nest’s branches are characterized by disorder and distribution diversity, proposed to use two different types of histograms, the histogram of strip direction (HOS) and histogram of strip length (HLS), to capture and learn the bird’s nest’s direction distribution and length distribution, using a vector machine to model and understand the bird’s nest patterns.
Neural-network-based transmission line component detection is mainly achieved using existing and relatively advanced methods. To solve the problem that the same category defects of vibration-proof hammers behave diversely and various category defects are highly similar, Zhai et al. [
2] introduced the geometric feature learning region into the Faster R-CNN network, and this can improve the model’s ability to distinguish between ordinary anti-vibration hammers and defective anti-vibration hammers. Song et al. [
3] effectively solved the problems of the high cost and low efficiency of existing arc sag detection algorithms for power lines by combining the CAB attention mechanism and MHSA self-attention mechanism in the Mask R-CNN network. Li et al. [
5] solved the problem of low accuracy in bird’s nest detection on high-voltage transmission lines by introducing a coordinate attention mechanism, zoom loss function, and SCYLLA-IoU loss function into the YOLOv3 network. In the work of Feng et al. [
44], to solve the problem of having many insulators in the distribution network with slight differences between classes, the detail feature enhancement module and the auxiliary classification module were introduced into the Faster R-CNN network to improve the ability to distinguish similar insulators. To solve the poor robustness of existing target detection algorithms in complex environments, Dian et al. [
45] proposed a Faster R-Transformer insulation detection algorithm that combines CNN and self-attention mechanisms to improve the accuracy of insulator detection under different lighting scenarios and angles.
In addition, some studies currently address issues such as complex backgrounds and small target proportions in UAV-captured images. To solve the problem of the difficulty of detecting small target faults in insulators in a complex environment, Ming et al. [
1] introduced an attention mechanism fusing the channel and the position in the YOLOv5 model, and this can improve the detection accuracy of insulators by the strategy of first achieving identification and then fault detection. To solve the problem that neural networks do not pay enough attention to the regions of tiny defective insulators, Lu et al. [
34] proposed a network that integrates a progressive multi-granularity learning strategy and a region relationship attention module, and this can achieve the goal of providing a more accurate diagnosis of the faulty insulator regions. Bao et al. [
46] introduced a parallel attention mechanism (PMA) module in the YOLOv4 network to solve the problems of the small proportion and sparse distribution of shockproof hammers in images in a complex environment, allowing the network to focus more attention on the location areas of faulty shock absorbers in images. To solve the problem of the difficulty in identifying the location information of bird nests and risk level information, Liao et al. [
47] used Faster R-CNN to locate the towers. Then, they mined each tower’s structural information and found its key points. Finally, they used the high-resolution network HRNet to detect tiny bird nests accurately and discriminate risk levels.
It can be inferred from previous studies that complex backgrounds and small target proportions generally limit the current transmission line inspection methods. Our summary of these studies is as follows.
Algorithms based on traditional image processing mainly achieve target detection by learning a lot of a priori knowledge and manually designing target features. Conventional image processing methods can achieve target detection and fault warning to a certain extent. Still, the algorithms’ robustness could be better, the model structures are relatively complex, and the detection accuracy could be higher, especially under complex background and small target proportions, where misdetection and wrong detection often occur.
Compared with traditional image processing methods, the key to the excellent performance of the method based on deep neural networks lies in its strong ability to extract image features, characterize image potential information, and train large amounts of data. However, most of the current research is aimed at the personalized design detection of the features of one or two categories of components of transmission lines. There are also models specifically designed to detect small target components of transmission lines. Nevertheless, in the task of simultaneously detecting multiple small targets such as transmission line insulators, anti-vibration hammers, and arc sags, most existing methods with significant detection effects require complex post-processing processes such as NMS; that is, there are few end-to-end models, and most consume more time.
In summary, we hope to provide a method based on computer vision technology with fast computing speed, high accuracy in detecting multiple small objects under complex backgrounds, and strong model generalization. Therefore, we focus on the Detection Transformer target detection method based on a transformer. Then, combined with the actual background of the UAV’s image and the detection targets’ visual characteristics, we propose a detection method for transmission line targets.
3. Basic Components of TLI-DETR
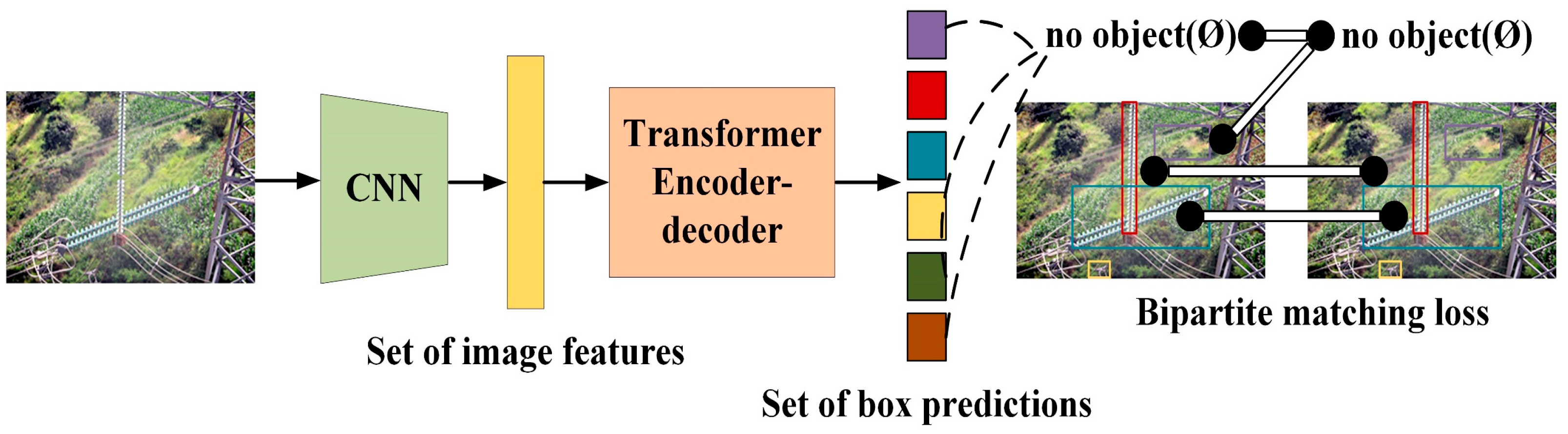
The transmission line inspection images of UAV aerial photography have complex backgrounds; the target occupies a small percentage and is easily occluded, making extracting the target features challenging. As depicted in
Figure 1, this article constructs a convolutional neural network (CNN), a feature extraction network based on the Darknet53 [
48], and an encoder and a decoder module based on the transformer. Finally, a detector based on DETR is used to construct the model. The TLI-DETR model in this research can explore subtle details in transmission line targets, which is beneficial for optimizing the model and providing a new approach for transmission line inspection work.
Target detection models often rely on backbone networks such as ResNet, VGG16, and Darknet53 to mine image feature information. Darknet effectively alleviates the common problems of gradient explosion and vanishing in network training by integrating residual structures and omitting the use of residual layers. Unlike the ResNet series, Darknet53 maintains excellent classification accuracy while streamlining the network architecture and accelerating the computing speed.
Consequently, this paper constructs the backbone network for the TLI-DETR model based on Darknet53. It is worth noting that this article focuses on small object detection for overhead transmission lines, which contrasts with the data characteristics of universal targets. The deeper the network layers are, the more abstract the extracted image features will be, which is unfavorable for small object detection. As shown in
Table 1, the backbone network in this article significantly reduces the use of residual structures. In addition, a lightweight design can accelerate the inference speed of the model.
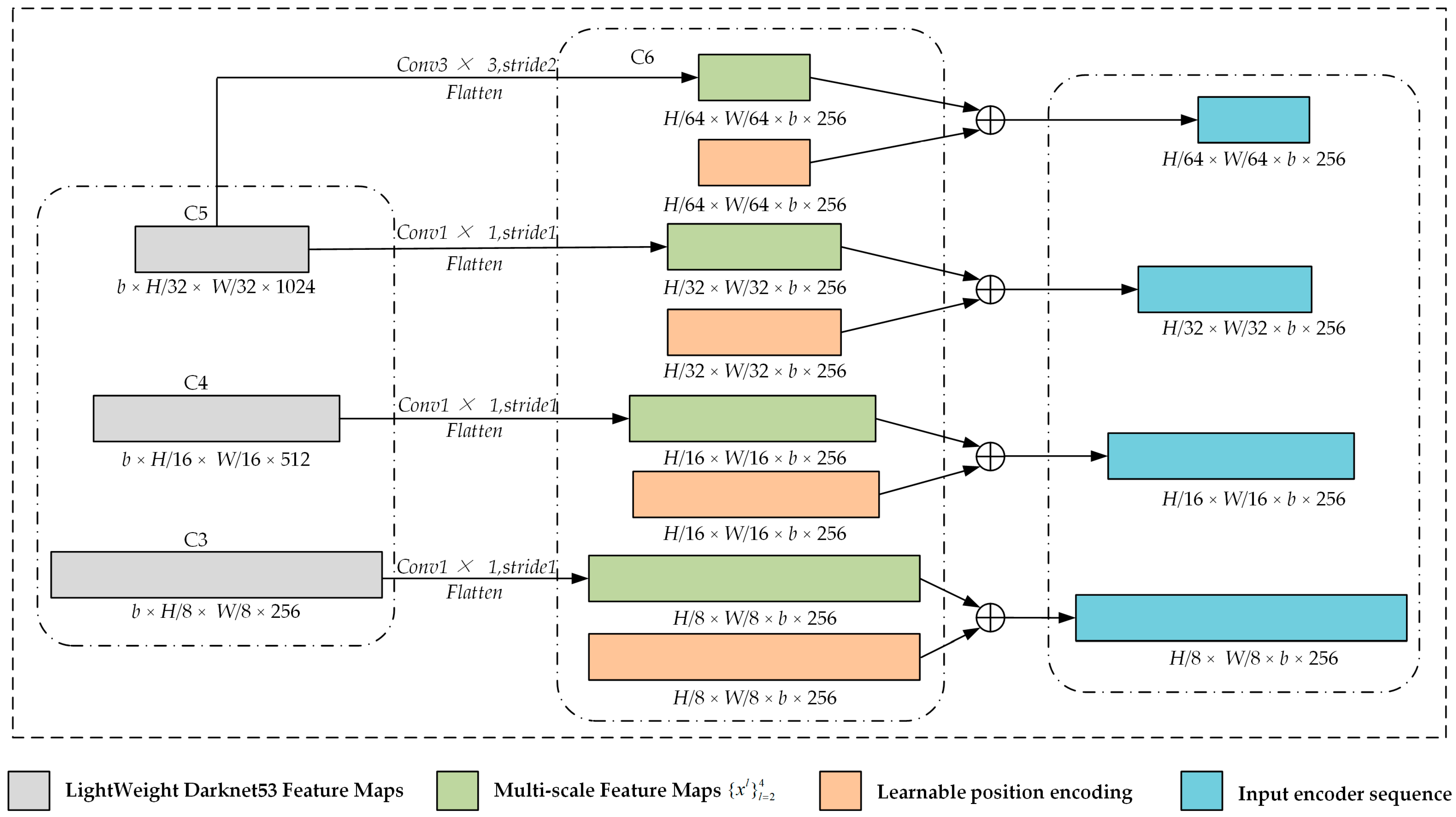
To detect the diversity of target sizes in transmission lines, as depicted in
Figure 2, TLI-DETR extracts feature maps at different levels from the backbone network to obtain multi-scale and multi-semantic-level feature maps. Deeper-level feature maps have larger receptive fields and higher semantic information but lower spatial resolution while shallow-level feature maps have higher spatial resolution and more detailed local information.
This paper uses learnable positional encoding to embed global and local positional information to capture the target’s positional features. This assists the model in capturing the image features of transmission lines at different scales. Adding feature information and positional encoding features together and using the added result as input for the encoder effectively improves the feature extraction performance.
A multi-head deformable attention module, an encoder for the TLI-DETR model, can process features of different scales. By utilizing multi-scale deformable attention, we can concentrate on processing local regions closely related to the target, efficiently capture local features, and significantly reduce the resource consumption required for processing. Then, by designing multiple encoder layers, the model gradually integrates local and global information, effectively highlighting target feature information at different scales in complex backgrounds. The expression of the attention mechanism is as follows:
Among the above variables, represents the number of multi-head attention points, represents the number of points sampled from the feature map, and represents the input feature level. In the feature layer and the sampling point in the multi-head attention, , , and represent the attention weight, standardized coordinates, and coordinate offset, respectively. It is worth noting that the normalization of attention weights and means that the normalized coordinates are re-normalized to the input feature map of the layer. In addition, the multi-scale deformable attention mechanism predicts the offset coordinates relative to the reference point rather than directly predicting the absolute coordinates, which is more conducive to model optimization and learning.
The decoder interacts with the encoder’s output features using the query vector and then progressively updates the target query vector through multi-layer decoding and attention mechanisms, ultimately generating a set of feature representations containing the target bounding box and category prediction.
The TLI-DETR model’s prediction head uses a binary matching algorithm to eliminate processes such as NMS processing. This significantly improves the model’s accuracy and reduces the detection time, thus meeting the demand for the real-time monitoring of transmission lines.
TLI-DETR considers the transmission line’s predicted and actual targets as independent sets with N elements. It includes all possible permutations and combinations of N elements (N is larger than the number of targets in the image. If the number of targets in an image is not enough to be N, it is acquiesced to be the background). Then, it uses the Hungarian algorithm for bipartite graph matching; that is, it compares each element of the predicted set
and the actual set
individually, hoping to find an optimal arrangement and combination
to minimize the matching loss
between the two sets.
The matching loss
considers the class prediction loss and the similarity between the predicted and actual boxes.
Here, each element
of the labeling box is regarded as
,
represents the category number of the labeling target (which can be
), and
represents the central coordinate of the annotation box and its width and height vector relative to the image size. The prediction set index element
defines its category
probability as
and the prediction box as
.
Upon matching the predicted and actual sets, the Hungarian algorithm establishes a one-to-one correspondence between the transmission line bounding boxes and their corresponding predicted target boxes. Then, it calculates the loss function of DETR. The loss function of TLI-DETR consists of the loss of the prediction of the detection target categorization and the loss of the accuracy of the size of the prediction of the target detection boxes, which is shown in (4):
Here,
is the optimal match in Formula (2), and it is worth mentioning that to solve the issue of classification imbalance in the target detection of transmission lines, this paper adopts a reduction of the logarithmic probability value in its classification loss by a factor of 10 when predicting the category
.
In the regression loss of the predicted size of the detection box, most of the previous regression targets consist of calculating the offset between the predicted value and the actual value. At the same time, this paper uses the direct regression method, which positively impacts the accuracy of prediction boxes, simplifies the learning process, and improves computational efficiency. Additionally, considering that
is sensitive to the size of the scale and
is insensitive to the size of the scale, to mitigate the influence of the loss function on the prediction boxes of different scales, the regression loss of the target detection box in this paper uses the weighted sum of the
loss and the
loss.
Here, the weight value
of the loss function between boxes is 2; the center coordinates, width, and height loss functions have weights (
) of 5.
4. Transmission Line Detection Using TLI-DETR
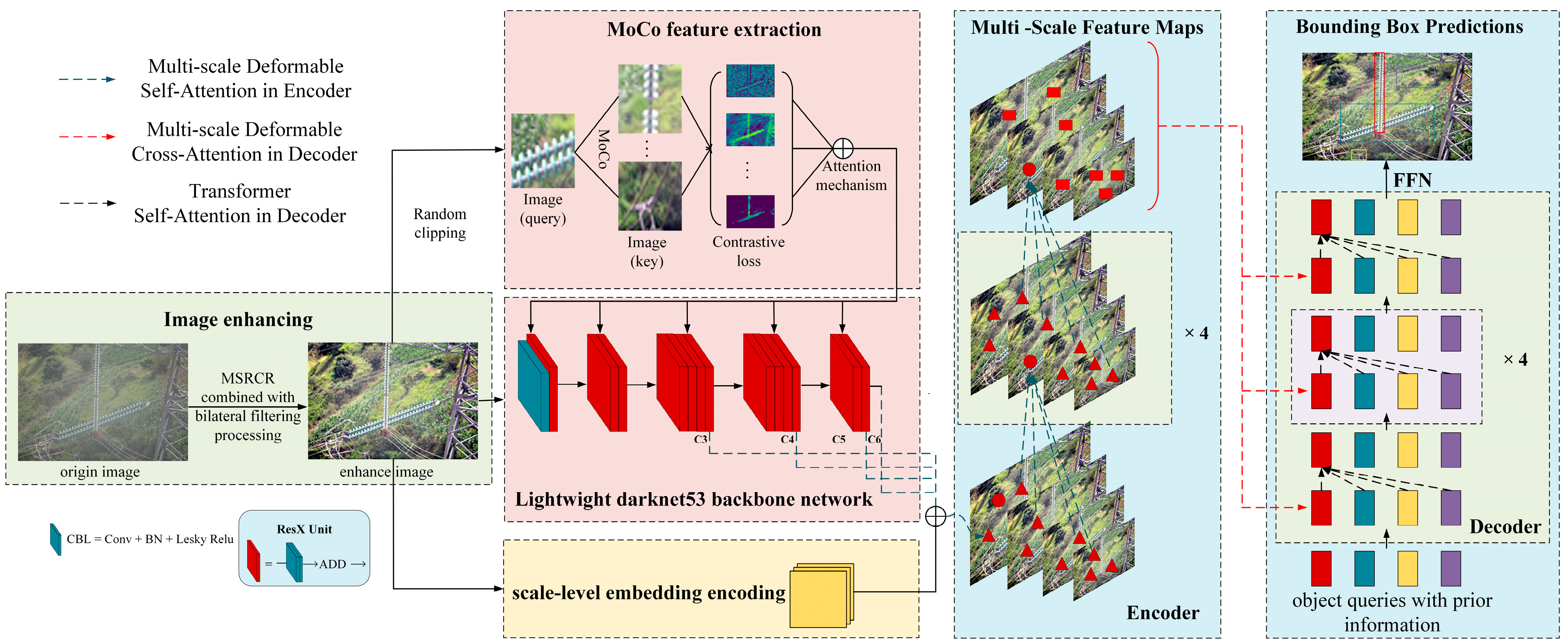
Transmission line detection tasks using TLI-DETR have achieved good results, but there is still potential for improvement in the accuracy of small target detection. Therefore, as depicted in
Figure 3, the transmission line detection task using TLI-DETR has achieved good results. However, there is still potential for improvement in the accuracy of small object detection. Consequently, the structured TLI-DETR model is more suitable for target detection tasks in transmission lines. As shown in
Figure 3, the model can highlight details such as edges and suppress noise through IMSMCR. This paper, through MoCo, extracts small objects’ edge and texture details and inputs them as auxiliary features into TLI-DETR. It then conducts a statistical analysis of the area and aspect ratio of transmission line targets, generating an object query vector with prior information to more accurately match the task of detecting transmission line targets.
4.1. Image Enhancement
The image quality dramatically affects the detection accuracy of the TLI-DETR model. Transmission lines are located in complex environments such as mountainous forests, rivers, and lakes, with few differences between transmission line targets and backgrounds. This research adopts the IMSCRR algorithm to obtain cleaner and more accurate edges and then provide assurance for subsequent feature extraction.
Optical images will inevitably be disturbed by noise, and the process of removing noise is image denoising. Common image denoising methods include median filtering [
49], Gaussian filtering [
50], and bilateral filtering [
51]. The effect of median filtering depends on the noise’s density; dense noise can cause problems such as blurred details and overlapping edges. The Gaussian filtering method has significant advantages in retaining image edge information and avoiding the ringing phenomenon; however, the adjustment process is very troublesome. Bilateral filtering usually requires similarity processing involving a certain pixel point in an image and its surrounding proximity pixels. Bilateral filtering can obtain corresponding Gaussian variance and preserve the image edge information better. The formula for bilateral filtering is presented in (6).
Here,
,
, and
refer to the output image after processing, the pixel value of the point, and the domain pixel value of the center pixel point, respectively.
is the multiplication of the distance template coefficient
and the value domain template coefficient
.
After image denoising, this paper performs enhancement operations on images to reduce the influence of complex backgrounds and other factors on the detection effect. Common image enhancement techniques include histogram equalization and the Retinex algorithm. As shown in
Figure 4, the histogram equalization algorithm has an excellent overall enhancement effect. However, it is prone to problems such as the local over-enhancement of images, which leads to the loss of local details. Although MSR can solve the negative impact of local over-enhancement, it can also cause the problem of color distortion. The MSRCR [
52] algorithm compensates for color information to represent details such as edges and textures better. The MSRCR processing result is as follows:
Here,
refers to the gain constant and
is used to adjust the nonlinear transformation; Jobsen’s [
52] experiment shows that when
and
, one can obtain more ideal results in most images.
refers to the pixel value of the original image and
represents the colorimetric transformation factor.
The MSRCR algorithm can make image details more prominent, but its shortcomings are also evident. For example, MSRCR fails to effectively enhance the entire image’s details and is often accompanied by “artifacts”. IMSCRR uses bilateral filtering to denoise the image, obtaining a rough denoised image divided by the original image to extract detailed images. The rough image is subjected to MSRCR processing and the detailed parts are restored to the processed image. IMSCRR not only leverages the advantages of MSRCR by preserving image color information but also effectively suppresses the impact of different lighting conditions on the image. Adding details can solve the problems of the reduced richness and clarity of image information caused by the loss of detail information in MSRCR. The processing is as follows:
- 1.
Bilateral filtering is used to denoise the input image
and obtain the desired rough image
.
- 2.
The input image
is divided by the rough image
to obtain the desired detailed image
.
- 3.
Using MSRCR to process the rough image
after bilateral filtering denoising, the image enhancement is performed to obtain the enhanced image
.
- 4.
The detail image
obtained in step (2) is multiplied with the MSRCR-enhanced image
obtained in step (3) to obtain the final image
.
The purpose of IMSRCR is mainly to add the detailed information of the detail map in . The edge details of have a higher weight and the multiplication has a reinforcing effect on the details of .
4.2. Momentum Contrast (MoCo)
After image enhancement, transmission line images’ edge and semantic information will have been effectively enriched. This research aims to introduce this information into model training to boost the accuracy of the TLI-DETR model in the tasks of detecting transmission line insulators, anti-vibration hammers, and arc sags. As shown in
Figure 5, this paper enhances the discrimination between the small target image and the background and the expressive ability of the model, which uses MoCo [
53] to pre-extract the image features before sending the image of the transmission line into the feature extraction network and then enhances the robustness of the model.
Through contrastive loss learning, the MoCo model makes positive sample pairs of image features as similar as possible in the feature space and negative sample feature pairs as far away as possible. In other words, it makes the features between similar objects as close as possible and those between dissimilar objects as far away as possible. MoCo includes a query encoder and a momentum encoder. The query encoder processes samples from the current batch while the momentum encoder processes historical samples and stores them in a dictionary. The parameter update of the momentum encoder is performed by querying the weighted average of the encoder parameters. The query encoder encodes query samples while the momentum encoder encodes key samples.
Here,
is a momentum parameter in the range of [0,1); backpropagation only updates the coding parameter of the image query. The encoding parameters of the current image key are slowly updated based on the previous key encoding parameters and the current query encoding parameters.
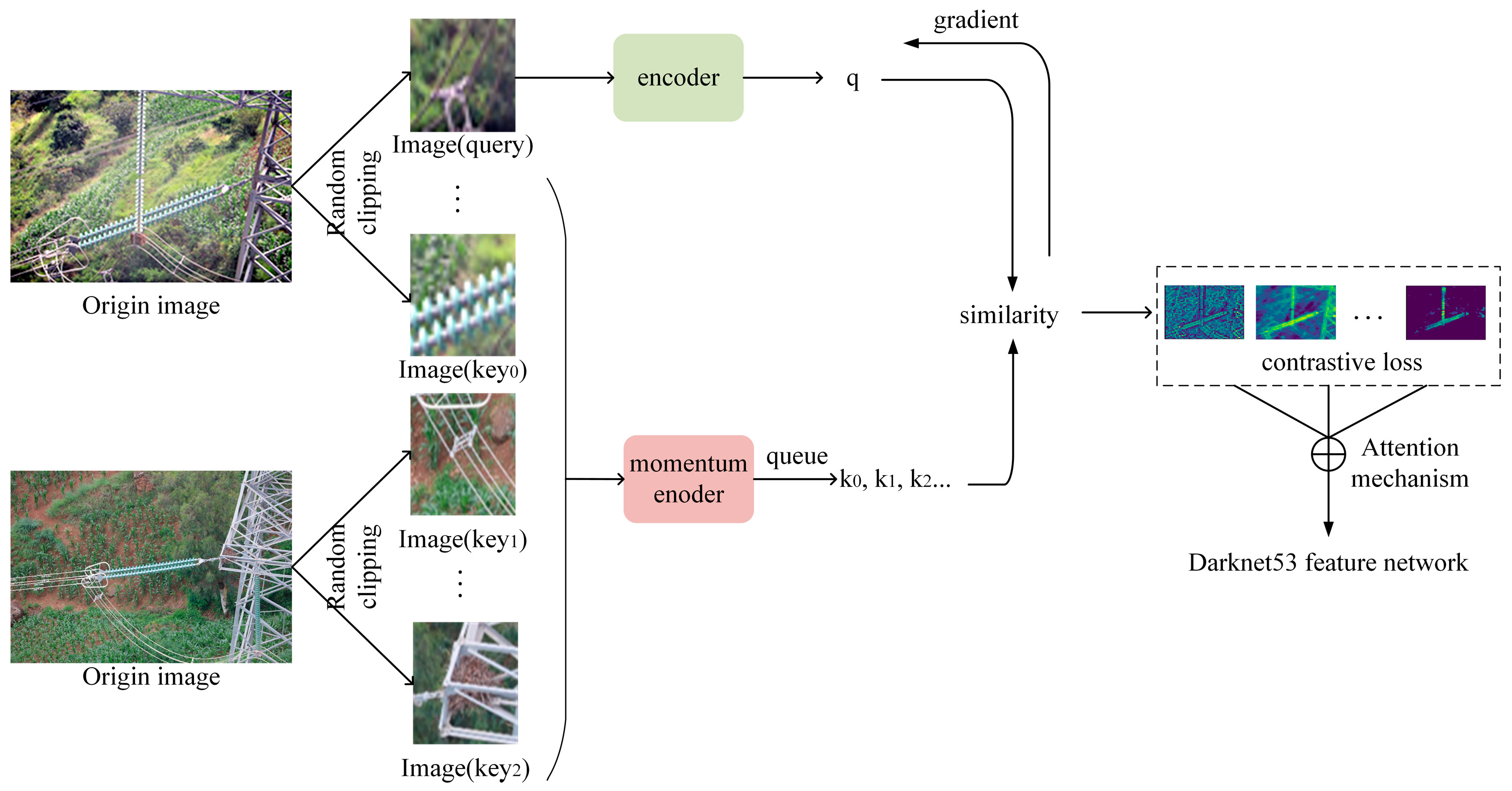
As depicted in
Figure 6, MoCo randomly crops two images with the same scale (48 × 48) from any two images (512 × 512) in the transmission line and encodes them as the query and key, respectively. Among them, different views of the same image (such as image (query) and image (key
0)) and views of other images (such as image (key
1) and image (key
2)) are referred to as positive sample pairs and negative sample pairs, respectively. MoCo uses momentum contrast loss to train the matching of the query and key and calculates the similarity between query samples and all key samples. It obtains different vectors by calculating the momentum contrast loss between two images. Then, an attention mechanism is used to compress this vector information, subjected to linear layer projection or dimension expansion operations. Finally, this vector information is used as a parameter for the residual layer in the lightweight Darknet53 network to help in model training.
4.3. Object Query Vector with Prior Information
Most detectors adopt pre-training strategies on ImageNet and COCO datasets to obtain prior information on generic targets. However, the insulators, anti-vibration hammers, and arc sags captured by drone aerial photography fall outside the scope of universal targets as they only appear in power systems. Considering the shape characteristics of transmission line targets, this paper generates an object query vector with prior information before network training, which makes it more suitable for the target detection task involving the UAV aerial photography of transmission lines.
The proportion and shapes of transmission line targets in the image are relatively low and long, respectively. As shown in
Table 2, the statistical analysis of the area of the labeled box for power line targets reveals that the majority of transmission line target areas range from 30 to 300. As shown in
Table 3, according to the aspect ratio statistics, most transmission line target aspect ratios are concentrated around 0.3 and 3.
Meanwhile, considering the impact of randomly initializing the target query vector on the difficulty and convergence speed of model optimization, we set [50, 80, 120, 240, 320] and [0.3, 1, 3] as the initial positions and biases of the target query vector to precisely narrow down the search space for the mapping relationship between the target query vector and the target truth.
Subsequently, the image is mapped into a feature map with dimensions of
through convolution operation. Then, the vector dimension is compressed by flattening operation to obtain
i. To ensure consistency between the target query vector and the decoder feature space, this paper uses a linear layer to map feature
:
Among the above variables, denotes the prior target query vector of the final input decoder, represents the Gaussian-error linear unit activation function, and and represent the linear layer weight matrix and bias, respectively. By utilizing target query vectors with prior knowledge, the model accurately captures critical features of transmission line images, thereby efficiently identifying and detecting targets.
6. Conclusions
This research proposes a transmission line detection model, TLI-DETR. To counteract interference in complex environments such as mountainous forests and lakes, this paper has used IMSRCR technology to enhance the stability of edge information and reduce the adverse effects of noise. Based on the feature extraction network, the MoCo method has been used to introduce this edge and semantic information into the model to enhance the ability to capture small target features. In addition, in response to the problem of small target proportion and occlusion caused by different angles and distances of drone shooting, this paper has statistically analyzed the areas and aspect ratios of transmission line targets, generated target query vectors containing prior information, and more accurately adapted to detection needs, especially in small target detection. The experimental results demonstrate that TLI-DETR performs well in high-voltage transmission line detection tasks, with accuracy and detection speed reaching 91.65% and 55FPS, respectively, providing solid technical support for the real-time online detection of transmission lines. This article has added further discussion on future research directions in its conclusion. This research has only identified insulators, anti-vibration hammers, and arc sags on high-voltage transmission lines. Our model is also applicable for identifying tunnel cracks and agricultural products. Therefore, in the following research, not only will the detection performance of the proposed method continue to be improved but experiments will also be conducted on faulty target components with sufficient data volumes. Of course, we will also focus on detecting and recognizing occluded targets to solve the problem of object occlusion detection in complex backgrounds.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}