Abstract
Visual navigation based on image matching has become one of the most important research fields for UAVs to achieve autonomous navigation, because of its low cost, strong anti-jamming ability, and high performance. Currently, numerous positioning and navigation methods based on visual information have been proposed for UAV navigation. However, the appearance, shape, color, and texture of objects can change significantly due to different lighting conditions, shadows, and surface coverage during different seasons, such as vegetation cover in summer or ice and snow cover in winter. These changes pose greater challenges for feature-based image matching methods. This encouraged us to overcome the limitations of previous works, which did not consider significant seasonal changes such as snow-covered UAV aerial images, by proposing an image matching method using season-changing UAV aerial images and satellite imagery. Following the pipeline of a two-channel deep convolutional neural network, we first pre-scaled the UAV aerial images, ensuring that the UAV aerial images and satellite imagery had the same ground sampling distance. Then, we introduced attention mechanisms to provide additional supervision for both low-level local features and high-level global features, resulting in a new season-specific feature representation. The similarity between image patches was calculated using a similarity measurement layer composed of two fully connected layers. Subsequently, we conducted template matching to estimate the UAV matching position with the highest similarity. Finally, we validated our proposed method on both synthetic and real UAV aerial image datasets, and conducted direct comparisons with previous popular works. The experimental results demonstrated that our method achieved the highest matching accuracy on multi-temporal and multi-season images.
1. Introduction
Recently, unmanned aerial vehicles (UAVs) have been extensively utilized in both civilian and military applications []. When a UAV is performing a task, it needs to constantly verify its position through the navigation system, in order to make adjustments. Currently, there are three main categories of navigation method: inertial navigation [], satellite navigation, and vision-based navigation [,]. Inertial navigation is prone to accumulating positioning errors over time, resulting in poor long-term accuracy []. Satellite navigation is susceptible to interference, due to its reliance on radio communication. Therefore, selecting an appropriate UAV navigation method according to the specific task is crucial. Presently, navigation in GNSS (global navigation satellite system) denial environments heavily relies on vision sensors, lidar, and inertial units []. In recent years, with the rapid advancement of computer vision, vision-based navigation has emerged as a promising research direction, due to its excellent anti-interference ability and capability to capture richer environmental information. UAV visual navigation involves matching ground area images obtained from an image sensor with stored reference images, to obtain the flight position and other data. Image matching is critical in UAV visual navigation, as it directly influences the performance of the navigation system.
Obtaining UAV aerial images and satellite imagery typically involves different sensors and is done during different seasons. The non-linear differences arising from variations in imaging time and imaging mechanisms pose challenges for image matching. UAV aerial images are digital images captured through continuous shooting of the ground using a camera mounted on a UAV during flight. The optical lens and sensor in the camera convert the light in the scene into digital signals. On the other hand, satellite imagery is generated by remote sensing sensors on satellites that continuously scan the ground and convert the light into digital signals using optical lenses and sensors. The distinct imaging mechanisms of UAV aerial images and satellite images result in differences in data quality, resolution, and remote sensing information. Furthermore, seasonal changes also contribute to disparities between drone aerial images and satellite images. Lighting, tone, texture, and shape may differ due to seasonal variations, such as changes in vegetation growth, color, ground object coverage, and weather conditions. For instance, in summer, dense vegetation may cause occlusion or partial occlusion of ground objects. In winter, snow and ice cover may significantly alter the texture and shape of ground objects. These seasonal fluctuations can obscure keypoints with similar features, rendering many feature-based image matching methods ineffective.
With the rapid advancement of deep learning, particularly the widespread adoption of convolutional neural networks (CNNs) [,], CNN-based image matching methods have become commonplace, including their application to unmanned aerial vehicle (UAV) aerial image matching []. In response to the issue of light changes, scale transformations, complex backgrounds, etc., Ref. [] presented a novel UAV visual positioning algorithm based on A-YOLOX and combining deep learning methods. However, there is currently a dearth of publicly available, realistic databases of UAV aerial images that capture seasonal changes, especially datasets containing images of winter scenes with snow. This paucity of data severely hampers research on matching UAV aerial images with satellite imagery in different seasons.
By conducting research on the matching technology of UAV aerial images and satellite imagery in different seasons, positional estimation of UAVs in complex seasonal environments can be achieved. This improves the navigational ability of UAVs in complex seasonal environments and provides technical support for their practical application in various challenging environments. The objective of this paper was to address the limitations of previous studies, particularly in the context of complex seasonal changes such as snow-covered UAV aerial images. A block matching method for UAV aerial images and satellite imagery in different seasons, based on a deep learning similarity measurement network, is proposed in this paper. The investigation of matching technology between UAV aerial images and satellite imagery in different seasons is of significant importance to the field of UAV visual navigation in complex seasonal environments.
The contributions of this paper are summarized below:
- This paper represents one of the few dedicated works on the challenging task of matching season-changing UAV aerial images with satellite imagery. To the best of our knowledge, limited research has been conducted in this area, making our work a valuable contribution to the field;
- A method is proposed for estimating the scaling factor of UAV aerial images, with the aim of mitigating the influence of scale differences between UAV aerial images and satellite images on the matching results;
- A two-channel deep convolutional neural network, combined with a convolutional block attention model, is proposed, to learn specific seasonal feature representations of heterogeneous images in different seasons, particularly for snowy UAV aerial images and satellite imagery.
The rest of this paper is organized as follows: Section 2 provides a review of the related literature, with a particular focus on image matching methods. In Section 3, we elaborate on the design process of our proposed method, 2chADCNN, including details on the scale transformation of UAV aerial images, network model structure, and parameter settings. Section 4 presents the specific experimental details and reports the experimental results. In Section 5, we evaluate the performance of our method through comparative experiments. Finally, in Section 6, we conclude our study and provide our thoughts on the experiments.
2. Related Works
Image matching refers to establishing reliable feature correspondences between two or more images, it is widely used in tasks such as image alignment, 3D reconstruction, and target localization and recognition []. As a pre-processing step, a correct image matching result is crucial for 3D reconstruction and other computer vision tasks.
The existing image matching methods can be classified into three categories: area-based, feature-based, and learning-based methods []. Area-based methods [,] typically use a small template image and compare its similarity with a large target image, to search for the most similar position. The traditional area-based matching methods based on gray information usually employ pixel-by-pixel comparisons, such as SAD (sum-of-absolute-differences) [], SSD (sum-of-squared-differences) [], and NCC (normalized-cross-correlation) []. These methods have the advantages of simple operation and fast calculation; however, the accuracy is significantly reduced when image distortion, different lighting, and different sensors are present. Meanwhile, they require that the template and the target image have the same scale. In practical applications, it is crucial to choose an appropriate similarity measurement based on specific application scenarios and requirements, as the similarity measurement method is the core for template matching.
The feature-based matching method [] refers to extracting certain features from two or more images, then describing the extracted features in a specific way, and using a specific metric function for comparison, to determine whether they match or not. Point features, line features, and surface features are common image features. Meanwhile, feature-based matching methods can be divided into two types: traditional and learning-based. The traditional matching process based on feature points generally includes three steps: feature point detection, feature description, and feature matching. In 2004, David Lowe [] developed the SIFT (scale-invariant feature transform) algorithm, which addresses the limitation of scale invariance in the Harris [] corner detection operator. This algorithm enables the detection of feature points beyond corner points, while maintaining invariance for translation, rotation, and scaling. Subsequently, the authors of [,] proposed solutions for the high time complexity to the SIFT algorithm. In recent years, Li Jiayuan [] proposed the RIFT algorithm, which enhances the repeatability and accuracy of feature point detection through a feature description method based on local orientation statistics and a feature matching method based on rotation invariance. The above traditional methods have shown good performance. However, they still face challenges in handling large viewing angles, temporal differences, as well as scale and illumination variations between images [].
In recent years, motivated by the rapid advancement of deep learning networks, researchers have proposed various innovative learning-based methods to overcome the limitations of traditional feature matching techniques. These learning-based approaches can be categorized into three categories.
The first type of methods are learnable feature point detection approaches, such as Key.Net [] and TILDE []. Among these, TILDE designs a repeatable key point detection framework that can extract feature points that are robust to changes in illumination and weather conditions. However, the training of candidate feature points in this framework relies on reproducible keypoints being extracted by the SIFT algorithm and prior knowledge to identify possible feature points.
The second type of methods are learnable local descriptor extraction approaches. The key to feature description in this type of methods is measuring the similarity between image patches. Learnable local descriptor extraction methods can be categorized into two categories based on the presence of a metric layer: metric learning and descriptor learning. Metric learning typically employs the Sigmoid function in the last layer to convert the continuous-valued output into a matching probability score ranging from 0 to 1. In 2015, Han [] proposed the MatchNet similarity measurement network, which utilizes two branch networks for feature extraction, and subsequently merges the two feature vectors via the measurement layer to generate a similarity score. The training process of MatchNet employs a contrastive loss function, which causes similar images to have close similarity scores and dissimilar images to have distinct similarity scores, thereby facilitating effective image similarity measurement. The study in [] improved on the two-channel model of DeepCompare [], and proposed BBS-2chDCNN. Satellite image matching based on a deep convolutional neural network is realized by learning the matching patterns between satellite images. This method is suitable for the matching of heterogeneous, multi-temporal, and different resolution satellite images. Descriptor learning methods without metric layers include PN-Net [], DeepCD [], L2-Net [], HardNet [], etc. This type of model outputs feature descriptors, which can directly replace traditional feature descriptors in some applications, while the similarity measure still uses traditional methods to calculate the distance between descriptors. The descriptor extraction effect directly affects the matching performance, so the design of the loss function and the selection of the input format of the training data are very important.
The third method is an end-to-end deep learning-based image matching approach. End-to-end methods such as LIFT [], D2-Net [], and LF-Net [] aim to jointly train the feature point detection and feature extraction networks to automate the process of detecting feature points and extracting features. This approach effectively enhances the stability of key points and the accuracy of features. Among these methods, SuperPoint [] performs feature point detection using an encoder–decoder network structure, which includes a feature localization decoder and a feature description decoder. It is first trained on synthetic images using a self-supervised learning method and then fine-tuned on real images, thereby avoiding the need for a large number of manual annotations. This algorithm extracts the position and descriptor of feature points simultaneously, resulting in improved feature extraction performance. Superglue [] employs a graph neural network (GNN) to learn the correspondence between image pairs, which can be used to match the feature points and feature descriptors extracted by the SuperPoint model. Instead of sequentially performing image feature detection, description, and matching, LoFTR [] builds pixel-level dense matches at a coarse level, and then refines good matches at a fine level. Considering that a lot of information will be lost when using methods based on a CNN structure, Ref. [] proposed a transformer-based network to extract more contextual information, which effectively improved the matching accuracy.
In recent years, an increasing number of methods have been proposed for UAV aerial image matching. Ref. [] was based on the RANSAC feature matching method, which utilizes SURF feature points to match UAV aerial images with Google satellite imagery. In response to the issue of redundant points in traditional matching algorithms based on local invariant features, Ref. [] proposed a UAV aerial image matching algorithm based on CenSurE-star, where the CenSurE-star filter was employed to extract feature points in the images. Ref. [] searched for matching positions of UAV aerial images on satellite imagery using a mutual information similarity measurement. Meanwhile, Ref. [] used normalized cross-correlation to calculate the similarity, while [] improved upon mutual information by employing the normalized information distance as a similarity measurement to achieve more accurate matching results. Additionally, Ref. [] proposed an image matching framework based on region division, utilizing an improved SIFT algorithm to merge the detected of Harris corners into keypoint sets. Notably, Ref. [] addressed the matching problem of season-changing UAV aerial images but ultimately employed remote sensing images to simulate UAV aerial images. In response to the issue of weather, light condition, and seasonal changes, Ref. [] proposed an image matching framework that exploited a CNN-based Siamese neural network with a contrastive learning method, but the situation of ice and snow cover in winter was not effectively resolved. As a consequence, limited research has been conducted on snow-covered UAV aerial images during winter, making further investigation in this area highly relevant.
Nowadays, the challenge of achieving absolute visual positioning of UAVs needs to overcome the differences in image features caused by seasonal changes in heterogeneous images. The traditional methods lack the ability to address the nonlinear differences introduced by seasonal changes. Deep learning-based methods, on the other hand, can learn different levels of feature representation through convolutional layers at various positions, making them more robust to seasonal changes. However, the selection of training samples significantly impacts the matching effectiveness of deep learning-based methods. Currently, there is a lack of publicly available and authentic UAV aerial image datasets with seasonal changes in the research field of UAV absolute visual localization, particularly datasets that include winter snowy images. To further advance research in this field, this paper focuses on the matching of UAV aerial images and satellite images (including winter snowy images) in different seasons.
3. Proposed Methodology
Seasonal changes pose significant challenges for matching UAV aerial images with satellite imagery, particularly in snow-covered scenes, where UAV aerial images often lack details compared to images from other seasons. Please refer to Figure 1.

Figure 1.
Comparison of different seasonal UAV aerial images and the corresponding satellite imagery. (a) UAV aerial image in summer. (b) UAV aerial image in winter. (c) satellite imagery in spring.
Based on a two-channel deep convolutional neural network [], this paper proposes a patch matching method dubbed 2chADCNN for UAV aerial images and satellite imagery in different seasons, to address the challenge of UAV visual positioning with changing seasons. A flowchart of the proposed algorithm is illustrated in Figure 2.
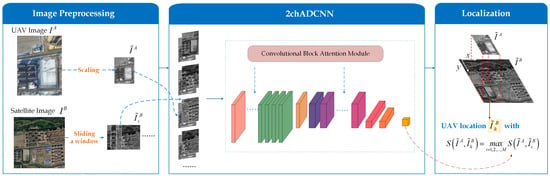
Figure 2.
Flowchart of the proposed method.
First, the scaling factor of UAV aerial images is estimated based on the GSD (ground sampling distance) [] of both UAV aerial images and satellite imagery. The UAV aerial images are then scaled to enable image matching at consistent scales. Next, an attention model is integrated with the two-channel deep convolutional neural network model to provide additional supervision on low-level and high-level features of the images. A 2chADCNN similarity measurement network model is designed to learn similarity measures between UAV aerial image patches and satellite imagery sub-image patches in different seasonal scenes. Finally, a template matching scheme with a traversal search strategy is utilized to calculate and compare the similarity between a UAV aerial image patch and satellite imagery sub-image patch to complete the image matching task.
3.1. Problem Formulation
In this study, our aim was to solve the problem of UAV visual positioning in GNSS-denied environments via image matching. In what follows, we briefly formulate the problem in a formal way and then outline the general flow of processing.
Let be a UAV aerial image with dimensions of and be a satellite imagery. In order to eliminate the disparity in scales between UAV aerial images and satellite imagery, a scaling factor is proposed, to resize to , which is used as a template for searching for corresponding areas in the larger satellite imagery (with dimensions of 256 × 256, where 256 is greater than both and ). will be combined with a sub-image of to form a pair of image patches , where is obtained using a search strategy that involves sliding a window in the satellite imagery , with a fixed step size of pixels. The window size is set to match the size of the UAV aerial image .
Next, a two-channel pair of image patches is fed into the trained 2chADCNN network in Section 3.3 to obtain the similarity score for each pair of image patches . Finally, the position of corresponding to the sub-image patch with the highest similarity is found and saved through similarity comparison, expressed as:
where is the step size (5 pixels was chosen based on experience). The position of is the final location of in the satellite imagery .
In the following sections, we will present the scaling processing and 2chADCNN architecture.
3.2. Scaling
The disparity in scales between the aerial images captured by unmanned aerial vehicles (UAVs) and satellite images poses a common challenge in UAV absolute visual positioning. To address this issue, this paper proposes a scaling transformation method for UAV aerial images.
GSD is a metric that is very useful for photogrammetry and measurements, especially for UAV mapping and surveying. It represents the actual distance on the ground represented by each pixel. GSD is defined as the ground distance corresponding to the midpoint of two adjacent pixels in an image. This metric is related to the camera focal length, the resolution of the camera sensor, and the distance between the camera and object. The bigger the value of the image GSD, the lower the spatial resolution of the image and the less visible details. In this paper, we calculate the scale factor of the UAV aerial image based on the GSD ratio between the UAV aerial image and the satellite imagery.
The scaling factor of the UAV aerial image can be calculated using the following formula:
where [] is the GSD of the UAV aerial images captured by the on-board camera of one drone and [] is the GSD of satellite imagery,
where f is the focal length of the lens. is the distance from the center of the camera to the ground, and d is the pixel size of the camera. represents latitude information, and it is the latitude value of the geographic center of the area where the UAV collects data. is the Earth’s equatorial length. l is the satellite imagery level. (In this paper, l is 15).
The UAV aerial image is scaled via to ensure consistency in scale with the satellite imagery. This can enhance the accuracy of image matching between the two heterogeneous modalities. Then, let the resized UAV aerial image be with , and the size can be obtained by
where w and h are the width and height of the image before resizing, and and are the width and height of the image after resizing.
3.3. Network Architecture
Due to dense and powerful representations, feature points are key for various computer vision tasks. However, the world consists of higher-level geometric structures that are semantically more meaningful compared to points. Therefore, here, we need to explore how to extract better, more natural geometric cues about the structure of a scene. Considering that, in challenging conditions such as with significant variations in the image radiometric content (extreme illumination changes, historical vs. modern sensor, light vs. shadows etc.), deep-learning approaches work far better. In this paper, we propose a deep-learning approach with attention modules for place recognition for UAV navigation under challenging conditions. This focuses on multi-temporal and multi-season image matching and, in particular, deals with the impact of snow coverage.
The two-channel network architecture is a fast and accurate convolutional neural network (CNN) that requires less training and offers significant advantages in network response time compared to other deep learning networks. As a result, it is often employed for image matching problems. The 2chADCNN model deepens the network architecture and incorporates an attention model based on the two-channel approach to enhance its ability for nonlinear expression and feature learning.
The proposed 2chADCNN similarity measurement network consists of five commonly used layers in computer vision networks: a convolutional layer (conv), a fully connected layer (dense), a pooling layer, an activation function layer, and a flattening layer (flatten), along with a convolutional block attention model []. Each attention module includes a channel attention module and a spatial attention module, as detailed in Section 3.3.1. The input of 2chADCNN is a two-channel image synthesized from the preprocessed UAV template image patch and satellite sub-image patch. The output feature map is a one-dimensional scalar that represents the similarity score. The network structure is depicted in Figure 3.
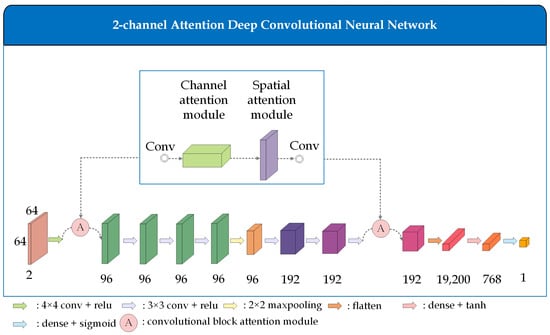
Figure 3.
Overview of the two-channel attention deep convolutional neural network.
The image passes through the first layer of convolution and the first attention module to extract basic local features, such as edges and corners, in the lower layers, and assign weights to them. Subsequently, features are further extracted through three convolutional layers. Then, a maxpooling layer is employed for downsampling, to reduce the dimensions of the feature map, which can accelerate the model calculation speed and increase rotation invariance, thereby improving the model’s robustness. Global features are then extracted through three additional convolution layers, and a second attention module is connected after the last convolutional layer, to assign weights to the high-level image semantic features. Finally, the outputting feature map is a one-dimensional scalar through a flattening layer and two fully connected layers, which yields a similarity score ranging from 0 to 1. This score indicates the probability that two images belong to the same class, thus providing a classification result of either similar or dissimilar (a score close to 1 denotes similarity, while a score close to 0 implies dissimilarity).
The second to fourth convolutional layers of the 2chADCNN network use the same padding mode to fill the edge pixel of the image with zeros, in order to increase the image resolution. The ReLU activation function is used in all convolutional layers to enhance the nonlinear capability of the network. The first fully connected layer uses the tanh activation function to scale the extracted features to [−1, 1], enabling the last fully connected layer to better capture relationships between different features and improve the model classification accuracy. The sigmoid activation function is used in the last fully connected layer to map the output results to [0, 1] and produce classification probabilities. The sigmoid activation function is denoted as follows:
where the input x is the single node value of the final output of the network. The range of is from 0 to 1, which is the similarity probability of the output.
3.3.1. Attention Module
The convolutional block attention module (CBAM) [] represents a method for fusing channel attention and spatial attention; refer to Figure 3.
The channel attention is focused on “what” is meaningful, depending on the feature map.Each channel of the input feature map F of is regarded as a feature (e.g., texture, style). First, the small blocks in each channel are compressed into a single block through max pooling and average pooling. They are then fed into the multi-layer perceptron MLP, which outputs the weight matrix of through the sigmoid function. Finally, a mask operation with the original input image F is performed. The channel attention part is expressed as
where
and represents the sigmoid function. is the average pooling function, is the max pooling function, is the multi-layer perceptron, and F is the input feature map.
The spatial attention is focused on “where” is meaningful in the feature map. In the spatial layer, first, the feature map of processed by the channel layer is also subjected to max pooling and average pooling, to compress multiple channels into a single channel. They are then fed into the two-dimensional convolution of , which outputs the weight matrix with through the sigmoid function. Finally, we perform a mask operation with the original input image . The channel attention part is expressed as
where
and represents the sigmoid function. is the average pooling function, is the max pooling function, is the convolution function of , and is the input feature map.
The input feature map size and output feature map size of the attention model are exactly the same. Thus, it can be applied in the middle of any convolutional layer. In this paper, an attention module is added after the first convolutional layer and the last convolutional layer, to emphasize attention to meaningful low-level and high-level features in the two main dimensions of channel and space.
3.3.2. Training
2chADCNN is straightforward to construct and simple to train, enabling automatic learning of the image matching mode and realization of the object-oriented matching process. In this paper, the model is trained in a supervised manner, using binary cross-entropy loss, which is represented by the following function:
where N is the number of network output nodes, is the label, and is the predicted probability that N nodes are labeled . In this experiment, the output node , and the labels are 1 and 0.
The experiment was conducted on a machine with 8GB of RAM, equipped with an Intel i5 quad-core processor. The 2chADCNN network was implemented using TensorFlow. Input images were resized, stacked to a size of , and normalized before being fed into the network. A mini-batch size of 20 and an initial learning rate of were used. Different learning rates and optimizers were experimented with, and it was observed that using an Adam optimizer with a learning rate of resulted in a better validation accuracy compared to larger learning rates, despite the latter converging faster. To mitigate the issue of forgetting in neural networks, the loading order of samples was randomly shuffled. The Adam optimizer was employed for network training, and the network was trained for 10 epochs.
In order to account for the significant variations in image features caused by seasonal changes, it is essential to obtain images of the same scene captured during different seasons for the training dataset. Therefore, we utilized historical Google satellite imagery of selected areas in Shenyang, China, spanning four seasons. The training and validation sets were then created by cropping these images to a size of pixels, resulting in 20,000 pairs each. Each pair consisted of two images from the same scene captured during different seasons, which served as positive samples, while pairs of images from different scenes were used as negative samples. The labels were set to 1 for positive samples and 0 for negative samples, ensuring an equal number of positive and negative samples.
4. Results
Datasets serve as the cornerstone of data-driven deep learning approaches. Over the past decades, various research institutions have released numerous high-quality datasets for UAV aerial images, which have provided impartial platforms for validating research into UAV vision and have significantly accelerated the development of related fields. However, there is a scarcity of benchmarks designed specifically for UAV visual localization in different seasons, particularly in winter. To address this limitation, we proposed a method to synthesize winter UAV aerial images using an image enhancement technique based on brightness thresholding, which adjusts the local pixel brightness to 255 in the HLS color space. Our synthetic dataset was generated from a captured summer image dataset and the Village dataset [], totaling 210 images. Some examples of the synthetic images are presented in Figure 4.
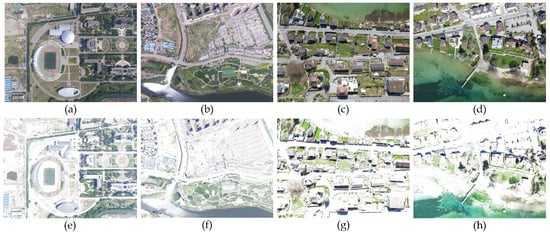
Figure 4.
(a–d) part of the original UAV aerial images. (e–h) part of the synthetic images.
Real UAV aerial images were collected from DJI UAVs flying over the northern region of Shenyang in China, with a resolution of . The flight heights ranged from 100 to 500 m. Aerial images were collected during both summer and snowy winter seasons, as these two seasons exhibit significant differences in image features compared to other seasons, as depicted in Figure 5.

Figure 5.
Part of the season-changing UAV aerial images. (a) UAV aerial images in summer. (b) UAV aerial images in winter.
We tested the trained model on algorithmically synthesized UAV aerial images and satellite imagery datasets, as well as real UAV aerial images and satellite imagery datasets. Among them, there were UAV aerial images and corresponding satellite imagery datasets in different seasons, including synthetic winter snowy UAV aerial images paired with real spring satellite imagery (Syn-Winter), real summer UAV aerial images paired with real spring satellite imagery (Summer), and real winter snowy UAV aerial images paired with real spring satellite imagery (Winter).
In this paper, we utilized the overlapping rate of the predicted area of the UAV aerial image on the satellite image and the actual area on the ground as a measure of matching accuracy, expressed as
where represents the area of the prediction area, represents the area of the real area, and calculates the area of the overlapping area between the prediction area and the real area. The larger the area of the overlapping area, the higher the accuracy of the overlap rate; that is, the better the matching result. In this chapter, the predicted area is represented by a purple box, and the real area is represented by a green box.
First, Figure 6 presents the results of the positioning of four summer aerial images captured by UAVs at various flight heights. It is evident from the figure that the proposed method accurately determined the position of the UAV, with overlap rates exceeding 0.9 for all four pairs of test images.
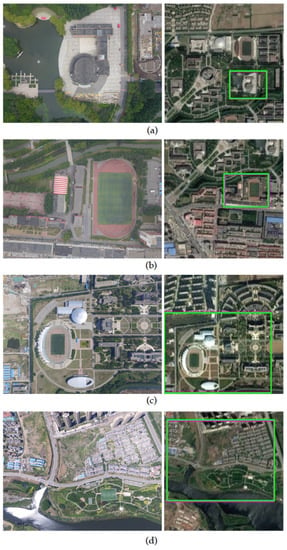
Figure 6.
Matching results on the Summer dataset. (a) A summer UAV aerial image at 252 m high and the corresponding spring satellite imagery, Accuracy was 0.9197. (b) Summer UAV aerial image at 304 m high, and the corresponding spring satellite imagery, Accuracy was 0.9522. (c) Summer UAV aerial image at 498 m high and the corresponding spring satellite imagery, Accuracy was 0.9884. (d) Summer aerial image at 500 m high and the corresponding spring satellite imagery, Accuracy was 0.9716.
Second, we conducted experiments on synthetic datasets. The accuracy of the overlap rate for the test images was greater than 0.8, which verified the effectiveness of the proposed method for matching the simulated snow scene images in winter with different flight heights. The matching results for the four pairs of syn-winter images are shown in Figure 7.
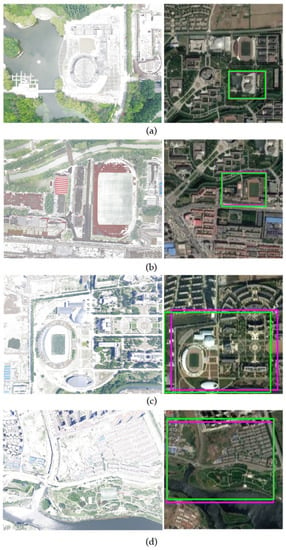
Figure 7.
Matching results on the Syn-Winter dataset. (a) A synthetic snow-covered UAV aerial image at 252 m high and the corresponding spring satellite imagery, Accuracy was 0.9522. (b) A synthetic snow-covered UAV aerial image at 304 m high and the corresponding spring satellite imagery, Accuracy was 0.9227. (c) A synthetic snow-covered UAV aerial image at 498 m high and the corresponding spring satellite imagery, Accuracy was 0.8247. (d) A synthetic snow-covered aerial image at 500 m high and the corresponding spring satellite imagery, Accuracy was 0.9197.
Finally, we tested real winter snow scene drone aerial images and real spring satellite images. The matching results for the four pairs of real winter images are shown in Figure 8. It can be observed from Figure 8 that the accuracies of the overlap rates of the test images for matching real winter snowy UAV aerial images at different heights with spring satellite imagery were all greater than 0.8. This result confirmed the efficacy of the method proposed in this chapter for real winter snowy UAV aerial image matching. Next, we further validated the performance of the proposed method through a comparative experimental analysis.
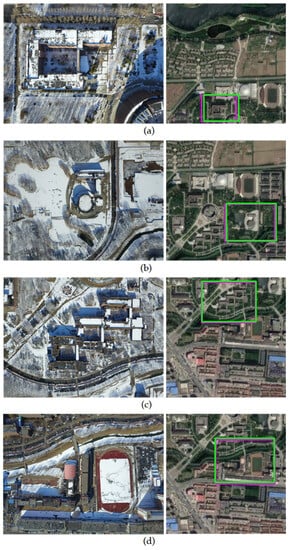
Figure 8.
Matching results on the Winter dataset. (a) A winter UAV aerial image at 190 m high and the corresponding spring satellite imagery, Accuracy was 0.8223. (b) A winter UAV aerial image at 270 m high and the corresponding spring satellite imagery, Accuracy was 0.9273. (c) A winter UAV aerial image at 292 m high and the corresponding spring satellite imagery, Accuracy was 0.9226. (d) A winter UAV aerial image at 320 m high and the corresponding spring satellite imagery, Accuracy was 0.9238.
5. Discussion
5.1. Comparisons with Other Methods
In the comparative experiment, we chose to compare the proposed 2chADCNN method with other related image matching methods in the same experimental environment. To ensure fairness, the input UAV aerial images for all comparison methods were pre-scaled to have the same ground resolution as the satellite imagery. Similarly to our matching method, the experiment used UAV aerial images as a template, and employed the same step-length traversal search strategy to match the template with the satellite imagery. The similarity value between the UAV aerial image patch and the satellite imagery sub-image patch was output using different methods. Several local feature point matching methods were compared, and the number of successfully matched feature point pairs in the image block pairs to be matched was used as the similarity measure. For all network models based on deep learning comparison methods, the network structure and parameter settings of the original algorithm were adopted.
We compared the 2chADCNN method with three established datasets: synthetic winter snowy UAV aerial images—real spring satellite imagery (Syn-Winter), real summer UAV aerial images—real spring satellite imagery (Summer), and real winter snowy UAV aerial images—real spring satellite imagery (Winter), respectively, against SIFT [], SSD [], SAD [], NCC [], SuperGlue [], LoFTR [], MatchNet [], and 2chDCNN [] matching algorithms. We present some results as examples, as shown in Figure 9, Figure 10 and Figure 11.
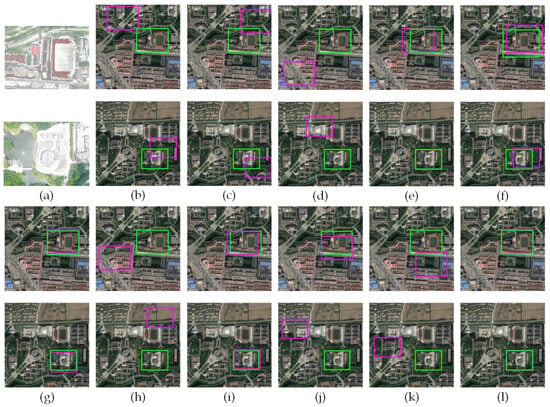
Figure 9.
Example results on synthetic UAV aerial images: (a) Two synthetic snow-covered UAV aerial images; (b) SIFT; (c) SSD; (d) SAD; (e) NCC; (f) SuperGlue; (g) LoFTR; (h) MatchNet; (i) RORD; (j) LightGlue; (k) 2chDCNN; (l) the proposed method.
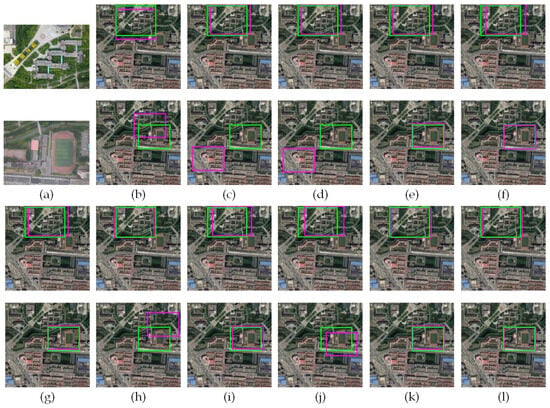
Figure 10.
Example matching results of UAV aerial images in summer: (a) Two synthetic snow-covered UAV aerial images; (b) SIFT; (c) SSD; (d) SAD; (e) NCC; (f) SuperGlue; (g) LoFTR; (h) MatchNet; (i) RORD; (j) LightGlue; (k) 2chDCNN; (l) the proposed method.
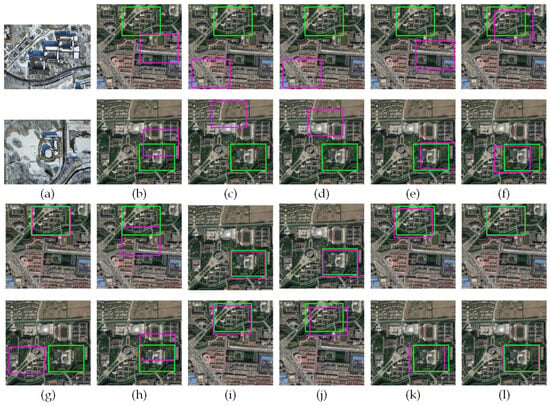
Figure 11.
Example matching results of snow-covered UAV aerial images in winter: (a) Two synthetic snow-covered UAV aerial images; (b) SIFT; (c) SSD; (d) SAD; (e) NCC; (f) SuperGlue; (g) LoFTR; (h) MatchNet; (i) RORD; (j) LightGlue; (k) 2chDCNN; (l) the proposed method.
From Figure 9, Figure 10 and Figure 11, it can be seen that the prediction area of the matching results of the method in this paper was closer to the real area for the matching results of UAV aerial images and satellite images in different seasons. The average Accuracy of the different methods on the three datasets is shown in Table 1.

Table 1.
Comparison of Accuracy on Syn-Winter, Winter, and Summer datasets with relevant methods.
It can be seen from Table 1 that the overlap rate of the method proposed in this paper on the three datasets exceeded that of the other methods, which proved the effectiveness of the method in this paper.
This paper also presents ROC (receiver operating characteristic) curves for overlap rate evaluation, which assess the matching performance. The curve plots different overlap thresholds on the x-axis and the ratio of successful matches to total samples on the y-axis. Successful matches are determined by comparing the evaluation index Accuracy with varying overlap thresholds. As the overlap threshold increases from low to high, the success rate on the y-axis changes, and the ROC curve is adjusted accordingly. A larger overlap threshold signifies a more stringent matching criterion, resulting in a decrease in the matching success rate. The area under the curve (AUC) score indicates the matching performance, with a larger AUC score denoting better performance. Figure 12 shows the overlap rate ROC curves for different methods using the Syn-Winter dataset, while Figure 13 displays the curves for the Summer dataset, and Figure 14 exhibits the curves for the Winter dataset.
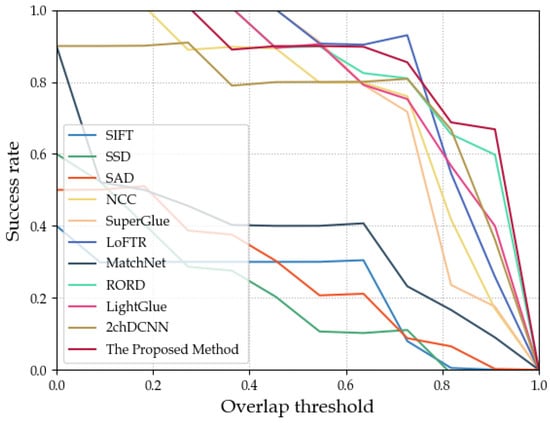
Figure 12.
ROC curves of various methods on the Syn-Winter dataset.
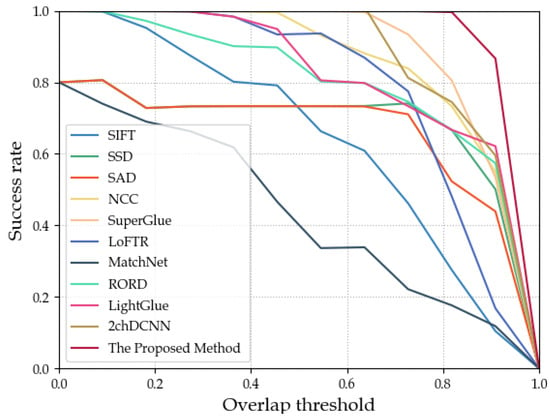
Figure 13.
ROC curves of various methods on the Summer dataset.
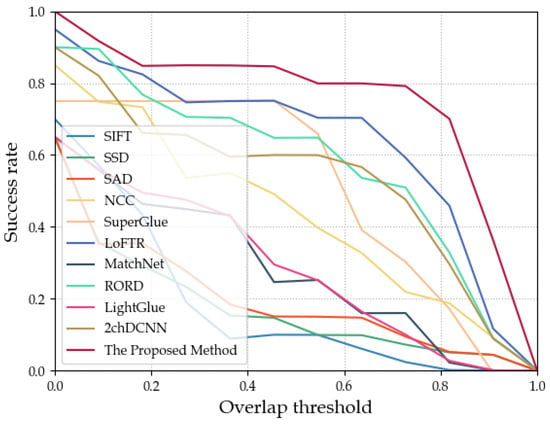
Figure 14.
ROC curves of various methods on the Winter dataset.
According to the overlap rate ROC curves of the above-mentioned different methods matched on the four datasets, we could obtain the AUC value corresponding to each method, and we compared the processing time of all algorithms, as shown in Table 2.
Table 2.
Comparison of AUC and Time/s on the Syn-Winter, Winter, and Summer datasets with relevant methods.
It can be observed from Table 2 that all algorithms exhibited excellent performance in matching real summer UAV aerial images without snow cover and real spring satellite imagery. However, for real and synthetic winter snowy images, the other algorithms performed poorly, confirming that snow cover significantly affects feature matching in UAV aerial images. The method proposed in this paper achieved the highest AUC score across all datasets, outperforming the other algorithms significantly. Through detailed analysis of the experimental results, we attribute this success to the ingenious combination of an attention model and a two-channel deep convolutional neural network in our method. By focusing on low-level features, the model learns seasonally invariant representations of object structure and texture, while leveraging high-level features to learn semantic representations of scene, enabling a better distinction of different regions. The deep network structure facilitates feature representation learning at multiple levels, allowing the fusion of local and global features and enhancing model robustness to seasonal changes. Additionally, our method incorporates optimization measures in preprocessing, network training, and other aspects, resulting in improved matching accuracy between UAV aerial images and satellite imagery in different seasons, and achieving excellent performance in evaluation metrics.
In conclusion, our method demonstrated significant advantages in the comparative experiments, providing further evidence of its effectiveness and stability. However, we also identified areas for improvement during the experiments, and we plan to optimize our method in future work to enhance its performance and broaden its application range.
5.2. Ablation Study
To verify the rationality and effectiveness of our proposed 2chADCNN, we conducted an ablation study for each attention module. All ablation studies were performed using the same experimental setup. We mainly used the three metrics of AUC, accuracy, and time/s to evaluate model performance. Therefore, the BASE model was 2chDCNN. Three schemes were proposed based on the “BASE” model: plugging an attention module after the first convolutional layer named “BASE + CBAM(after the first conv)” model; plugging an attention module after the last convolutional layer named “BASE + CBAM(after the last conv)” model; and plugging an attention module in the first and the last convolutional layers at the same time, named “BASE + CBAM(after the first conv) + CBAM(after the last conv)” model. The quantitative results when introducing attention modules on the Syn-Winter, Winter, and Summer datasets are shown in Table 3.
Table 3.
Quantitative results of ablation studies for AUC, time/s, and Accuracy on the Syn-Winter, Winter, and Summer datasets.
From Table 3, we can see that the results of the “BASE” model were the lowest on the Syn-Winter and Winter datasets. On the Summer dataset, by plugging one attention module after the first convolution or the last convolution, the results slightly decreased, and the “BASE + CBAM(after the first conv)” model became the lowest.
Among them, the “BASE + CBAM(after the first conv) + CBAM(after the last conv)” models performed the best on the three datasets for the three indicators. The AUC and Accuracy on the Syn-Winter dataset increased by 23% and 9.6%. The AUC and Accuracy on the Summer dataset increased by 6% and 6.9%. The AUC and Accuracy on the Winter dataset increased by 22% and 21.7%. The time/s decreased by 0.001 with the “BASE + CBAM(after the first conv)” model, decreased by 0.0036 with the “BASE + CBAM(after the last conv)” model, and decreased by 0.0035 with the “BASE + CBAM(after the first conv) + CBAM(after the last conv)” model.
On the Syn-Winter and Winter datasets, the performance of the “BASE + CBAM(after the first conv)” model improved for both AUC and Accuracy. For the “BASE + CBAM(after the last conv)” model, the metrics of AUC and Accuracy improved on the Syn-Winter dataset, but were slightly degraded on the Winter dataset. Both the “BASE + CBAM(after the first conv)” model and “BASE + CBAM(after the last conv)” model improved for Time/s. Observing the results in Table 3, we can conclude that the attention module could focus on the details that were ignored by the “BASE” model, achieving the extraction of effective features, with the same noise and improving the stability and robustness of the model. Meanwhile, the addition of two attention modules at the same time made this effect more remarkable.
It is noteworthy that the performance of both the “BASE + CBAM(after the first conv)” model and “BASE + CBAM(after the last conv)” model decreased on the Summer dataset, but the “BASE + CBAM(after the first conv) + CBAM(after the last conv)” model had the best performance, which we explained as the images may have been more sharply characterized in summer. Adding only one attention module made the model more sensitive and instead it paid too much attention to the noise, leading to a decrease in model performance. However, two attention models may complement each other, to help the model better understand the input data, which brings a better matching performance.
In order to demonstrate the role of the attention module more intuitively, Figure 15 shows a visualization of the changes in features extracted by the “BASE + CBAM(after the first conv) + CBAM(after the last conv)” model.

Figure 15.
Comparison on the features of the “BASE + CBAM(after the first conv) + CBAM(after the last conv)” model in the different layers on the Winter and Summer datasets. Visualization of features on the Winter dataset at (a) the first conv; (b) CBAM(after the first conv); (e) the last conv; (f) CBAM(after the last conv). Visualization of features on the Summer dataset at (c) the first conv; (d) CBAM(after the first conv); (g) the last conv; (h) CBAM(after the last conv).
Figure 15 shows the variation of extracted features for the “BASE + CBAM(after the first conv) + CBAM(after the last conv)” model with the influence of the attention module. In winter, the performance of the model in extracting features improved after the first attention module, and the further addition of a second attention module made this effect more remarkable. In summer, after the first attention module, the model began to ignore part of the effective features, but after adding the second attention module, the two attention models could complement each other and the model’s feature extraction performance improved, resulting in a better matching performance.
6. Conclusions
This paper presents a feasible framework for image matching between UAV aerial images and satellite imagery in season-changing scenes. We introduced attention mechanisms to construct a network architecture, and this architecture provided additional supervision of both low-level local features and high-level global features, resulting in a new season-specific feature representation. We validated our contributions in image matching between UAV aerial images and satellite imagery in different seasons. The experimental results showed that this network enabled accurate matching between the same scene under heterogeneous and different seasons, particularly in the case of snow-covered UAV images in winter and satellite imagery in spring. The experimental results and the comparisons with other literature works on both synthetic and real datasets verified the rationality and effectiveness of our proposed method. Future research is needed to improve the real-time capability of our method and further explore its application in GPS-denied UAV localization and navigation.
7. Future Works
Although satellite imagery and UAV images are both optical images, they exhibit significant differences, such as spectral variations, varying ground resolutions, parallax, and image distortion. The method proposed in this paper specifically addresses these differences and overcomes the challenges they pose, resulting in improved image matching performance. In our future work, we plan to construct a snowy image database using more efficient algorithms, to generate realistic snowy UAV aerial images. We hope that this database will facilitate researchers in exploring novel approaches in this field. Meanwhile, we will continue to extend our research by exploring the application of image matching in other types of non-urban areas, such as deserts, forests, mono-cropping areas, and other areas, to further validate and generalize the applicability and performance of our method in different situations. Additionally, we plan to conduct more robust training, to enhance our network’s ability to handle rotation-invariant characteristics.
Author Contributions
Conceptualization, Y.R.; methodology, Y.R.; software, Y.L.; validation, Y.L. and Z.H.; formal analysis, W.L. and W.W.; investigation, Y.L.; resources, Y.R. and W.W.; data curation, Y.L.; writing—original draft preparation, Y.L. and Z.H.; writing—review and editing, Y.R., W.L. and W.W.; visualization, Y.L. and Z.H.; supervision, Y.R.; project administration, Y.R.; funding acquisition, Y.R. and W.W. All authors have read and agreed to the published version of the manuscript.
Funding
This work was partially supported by the Natural Science Foundation of Liaoning Province (2021-MS-265), the Science Research Fund of Liaoning Province Education Department (Youth Fund LJKZ0219), the Natural Science Foundation of China (62266046), and the Natural Science Foundation of Jilin Province (YDZJ202201ZYTS603).
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Elmeseiry, N.; Alshaer, N.; Ismail, T. A Detailed Survey and Future Directions of Unmanned Aerial Vehicles (UAVs) with Potential Applications. Aerospace 2021, 8, 363. [Google Scholar] [CrossRef]
- Petritoli, E.; Leccese, F.; Leccisi, M. Inertial Navigation Systems for UAV: Uncertainty and Error Measurements. In Proceedings of the 2019 IEEE 5th International Workshop on Metrology for AeroSpace (MetroAeroSpace), Torino, Italy, 19–21 June 2019; pp. 1–5. [Google Scholar]
- Lu, Y.; Xue, Z.; Xia, G.S.; Zhang, L. A survey on vision-based UAV navigation. Geo-Spat. Inf. Sci. 2018, 21, 21–32. [Google Scholar] [CrossRef]
- Arafat, M.Y.; Alam, M.M.; Moh, S. Vision-based navigation techniques for unmanned aerial vehicles: Review and challenges. Drones 2023, 7, 89. [Google Scholar] [CrossRef]
- Welcer, M.; Szczepanski, C.; Krawczyk, M. The Impact of Sensor Errors on Flight Stability. Aerospace 2022, 9, 169. [Google Scholar] [CrossRef]
- Qiu, Z.; Lin, D.; Jin, R.; Lv, J.; Zheng, Z. A Global ArUco-Based Lidar Navigation System for UAV Navigation in GNSS-Denied Environments. Aerospace 2022, 9, 456. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xu, C.; Liu, C.; Li, H.; Ye, Z.; Sui, H.; Yang, W. Multiview Image Matching of Optical Satellite and UAV Based on a Joint Description Neural Network. Remote Sens. 2022, 14, 838. [Google Scholar] [CrossRef]
- Xu, Y.; Zhong, D.; Zhou, J.; Jiang, Z.; Zhai, Y.; Ying, Z. A Novel UAV Visual Positioning Algorithm Based on A-YOLOX. Drones 2022, 6, 362. [Google Scholar] [CrossRef]
- Chen, Q.; Yao, J. Outliers rejection in similar image matching. Virtual Real. Intell. Hardw. 2023, 5, 171–187. [Google Scholar] [CrossRef]
- Barroso-Laguna, A.; Riba, E.; Ponsa, D.; Mikolajczyk, K. Key. net: Keypoint detection by handcrafted and learned cnn filters. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5836–5844. [Google Scholar]
- Yin, Z.; Shi, J. Geonet: Unsupervised learning of dense depth, optical flow and camera pose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1983–1992. [Google Scholar]
- Bian, J.; Lin, W.Y.; Matsushita, Y.; Yeung, S.K.; Nguyen, T.D.; Cheng, M.M. GMS: Grid-Based Motion Statistics for Fast, Ultra-Robust Feature Correspondence. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2828–2837. [Google Scholar] [CrossRef]
- Bahrami, F.; Shiri, N.; Pesaran, F. A new approximate sum of absolute differences unit for bioimages processing. IEEE Embed. Syst. 2023. early access. [Google Scholar] [CrossRef]
- Chen, Y.; Medioni, G. Object modelling by registration of multiple range images. Image Vis. Comput. 1992, 10, 145–155. [Google Scholar] [CrossRef]
- Hisham, M.; Yaakob, S.N.; Raof, R.; Nazren, A.A.; Wafi, N. Template matching using sum of squared difference and normalized cross correlation. In Proceedings of the 2015 IEEE Student Conference on Research and Development (SCOReD), Kuala Lumpur, Malaysia, 13–14 December 2015; pp. 100–104. [Google Scholar]
- Wu, X.; Fu, K.; Liu, Z.; Chen, W. A Brief Survey of Feature Based Image Matching. In Proceedings of the 2022 IEEE 17th Conference on Industrial Electronics and Applications (ICIEA), Chengdu, China, 16–19 December 2022; pp. 1634–1639. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Harris, C.G.; Stephens, M.J. A combined corner and edge detector. In Proceedings of the Alvey Vision Conference, Manchester, UK, 31 August–2 September 1988. [Google Scholar]
- Ke, Y.; Sukthankar, R. PCA-SIFT: A more distinctive representation for local image descriptors. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2004, Washington, DC, USA, 27 June–2 July 2004; Volume 2, pp. II–II. [Google Scholar]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Li, J.; Hu, Q.; Ai, M. RIFT: Multi-modal image matching based on radiation-variation insensitive feature transform. IEEE Trans. Image Process. 2019, 29, 3296–3310. [Google Scholar] [CrossRef] [PubMed]
- Remondino, F.; Morelli, L.; Stathopoulou, E.; Elhashash, M.; Qin, R. Aerial triangulation with learning-based tie points. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2022, 43, 77–84. [Google Scholar] [CrossRef]
- Verdie, Y.; Yi, K.; Fua, P.; Lepetit, V. Tilde: A temporally invariant learned detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5279–5288. [Google Scholar]
- Han, X.; Leung, T.; Jia, Y.; Sukthankar, R.; Berg, A.C. Matchnet: Unifying feature and metric learning for patch-based matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3279–3286. [Google Scholar]
- Fan, D.; Dong, Y.; Zhang, Y. Satellite Image Matching Method Based on Deep Convolution Neural Network. Cehui Xuebao/Acta Geod. Cartogr. Sin. 2018, 47, 844–853. [Google Scholar] [CrossRef]
- Zagoruyko, S.; Komodakis, N. Learning to compare image patches via convolutional neural networks. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4353–4361. [Google Scholar] [CrossRef]
- Balntas, V.; Johns, E.; Tang, L.; Mikolajczyk, K. PN-Net: Conjoined Triple Deep Network for Learning Local Image Descriptors. arXiv 2016, arXiv:1601.050300. [Google Scholar]
- Yang, T.Y.; Hsu, J.H.; Lin, Y.Y.; Chuang, Y.Y. DeepCD: Learning Deep Complementary Descriptors for Patch Representations. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 27–29 October 2017; pp. 3334–3342. [Google Scholar] [CrossRef]
- Tian, Y.; Fan, B.; Wu, F. L2-Net: Deep Learning of Discriminative Patch Descriptor in Euclidean Space. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6128–6136. [Google Scholar] [CrossRef]
- Mishchuk, A.; Mishkin, D.; Radenović, F.; Matas, J. Working Hard to Know Your Neighbor’s Margins: Local Descriptor Learning Loss. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 4829–4840. [Google Scholar]
- Yi, K.M.; Trulls, E.; Lepetit, V.; Fua, P. Lift: Learned invariant feature transform. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part VI 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 467–483. [Google Scholar]
- Dusmanu, M.; Rocco, I.; Pajdla, T.; Pollefeys, M.; Sivic, J.; Torii, A.; Sattler, T. D2-net: A trainable cnn for joint description and detection of local features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8092–8101. [Google Scholar]
- Ono, Y.; Trulls, E.; Fua, P.; Yi, K.M. Lf-net: Learning local features from images. In Advances in Neural Information Processing Systems; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; Volume 31, Available online: https://proceedings.neurips.cc/paper_files/paper/2018/file/f5496252609c43eb8a3d147ab9b9c006-Paper.pdf (accessed on 23 August 2023).
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. Superpoint: Self-supervised interest point detection and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 224–236. [Google Scholar]
- Sarlin, P.E.; DeTone, D.; Malisiewicz, T.; Rabinovich, A. Superglue: Learning feature matching with graph neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4938–4947. [Google Scholar]
- Sun, J.; Shen, Z.; Wang, Y.; Bao, H.; Zhou, X. LoFTR: Detector-free local feature matching with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8922–8931. [Google Scholar]
- Zhuang, J.; Chen, X.; Dai, M.; Lan, W.; Cai, Y.; Zheng, E. A Semantic Guidance and Transformer-Based Matching Method for UAVs and Satellite Images for UAV Geo-Localization. IEEE Access 2022, 10, 34277–34287. [Google Scholar] [CrossRef]
- Seema, B.; Kumar, H.S.P.; Naidu, V.P.S. Geo-registration of aerial images using ransac algorithm. 2014. Available online: https://api.semanticscholar.org/CorpusID:73618596 (accessed on 23 August 2023).
- Zhang, W.; Li, Z.; Wang, Y. UAV scene matching algorithm based on CenSurE-star feature. Yi Qi Yi Biao Xue Bao/Chin. J. Sci. Instrum. 2017, 38, 462–470. [Google Scholar]
- Yol, A.; Delabarre, B.; Dame, A.; Dartois, J.E.; Marchand, E. Vision-based Absolute Localization for Unmanned Aerial Vehicles. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014. [Google Scholar] [CrossRef]
- Van Dalen, G.J.; Magree, D.P.; Johnson, E.N. Absolute localization using image alignment and particle filtering. In Proceedings of the AIAA Guidance, Navigation, and Control Conference, San Diego, CA, USA, 4–8 January 2016; p. 0647. [Google Scholar]
- Patel, B. Visual Localization for UAVs in Outdoor GPS-Denied Environments; University of Toronto (Canada): Toronto, ON, Canada, 2019. [Google Scholar]
- Liu, X.; Li, J.B.; Pan, J.S.; Wang, S.; Xudong, L.; Shuanglong, C. Image-matching framework based on region partitioning for target image location. Telecommun. Syst. 2020, 74, 269–286. [Google Scholar] [CrossRef]
- Ahn, S.; Kang, H.; Lee, J. Aerial-Satellite Image Matching Framework for UAV Absolute Visual Localization using Contrastive Learning. In Proceedings of the 2021 21st International Conference on Control, Automation and Systems (ICCAS), Jeju, Republic of Korea, 12–15 October 2021; pp. 143–146. [Google Scholar]
- Micheletti, N.; Chandler, J.; Lane, S.N. Structure from motion (SFM) photogrammetry. 2015. Available online: https://repository.lboro.ac.uk/articles/journal_contribution/Structure_from_motion_SFM_photogrammetry/9457355 (accessed on 23 August 2023).
- Zbontar, J.; LeCun, Y. Stereo matching by training a convolutional neural network to compare image patches. J. Mach. Learn. Res. 2016, 17, 2287–2318. [Google Scholar]
- Cebecauer, T.; Šúri, M. Exporting geospatial data to web tiled map services using grass gis. Osgeo J. 2008, 5. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Goforth, H.; Lucey, S. GPS-denied UAV localization using pre-existing satellite imagery. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 2974–2980. [Google Scholar]
- Parihar, U.S.; Gujarathi, A.; Mehta, K.; Tourani, S.; Garg, S.; Milford, M.; Krishna, K.M. RoRD: Rotation-Robust Descriptors and Orthographic Views for Local Feature Matching. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September 2021–1 October 2021; pp. 1593–1600. [Google Scholar]
- Lindenberger, P.; Sarlin, P.E.; Pollefeys, M. LightGlue: Local Feature Matching at Light Speed. arXiv 2023, arXiv:2306.13643. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).