
Object Detection in Drone Video with Temporal Attention Gated Recurrent Unit Based on Transformer


Abstract
:1. Introduction
- We proposed an effective and efficient TA-GRU module to model the temporal context between videos. It is very effective to handle appearance deterioration in drone vision, and it can easily be used to promote existing static image object detectors to effective video object detection methods.
- We proposed a new state-of-the-art video object detection method, which not only achieves top performance on the VisDrone2019-VID dataset, but also runs in real-time.
- Compared to previous works, we integrated recurrent neural networks, transformer layers, and feature alignment and fusion modules to create a more effective module for handling temporal features in drone videos.
2. Related Work
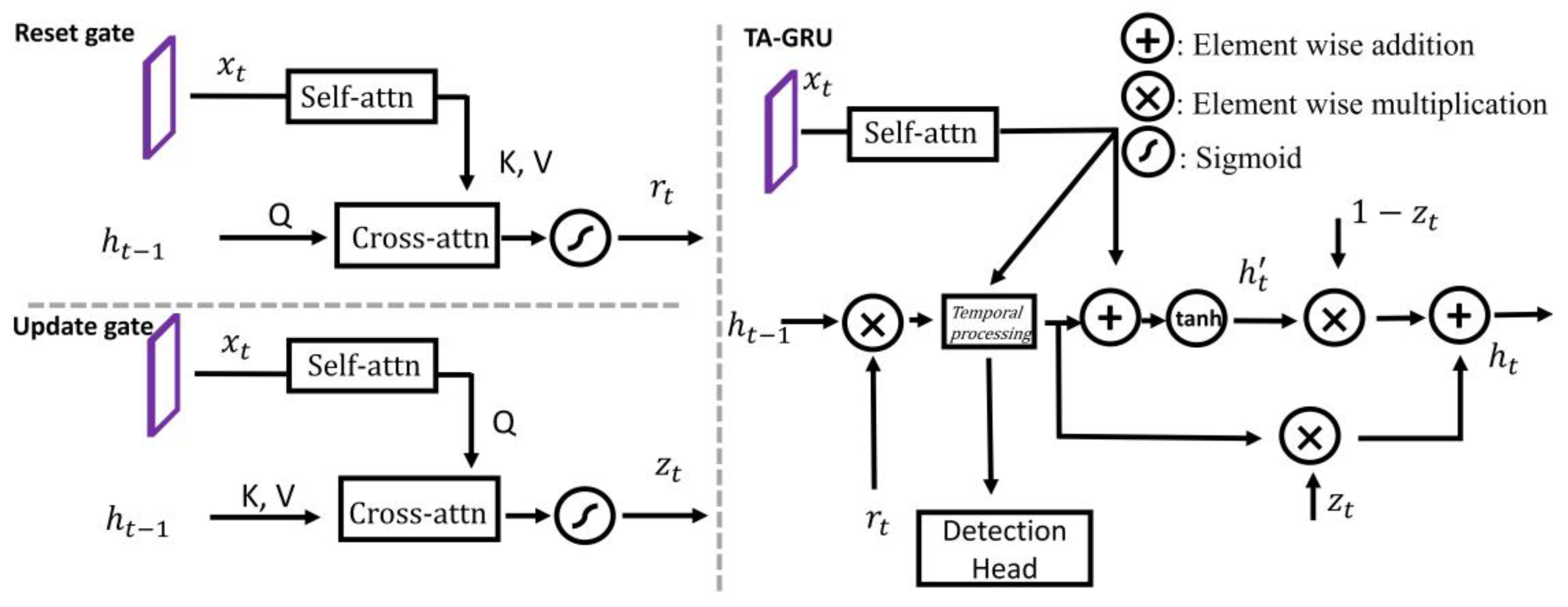
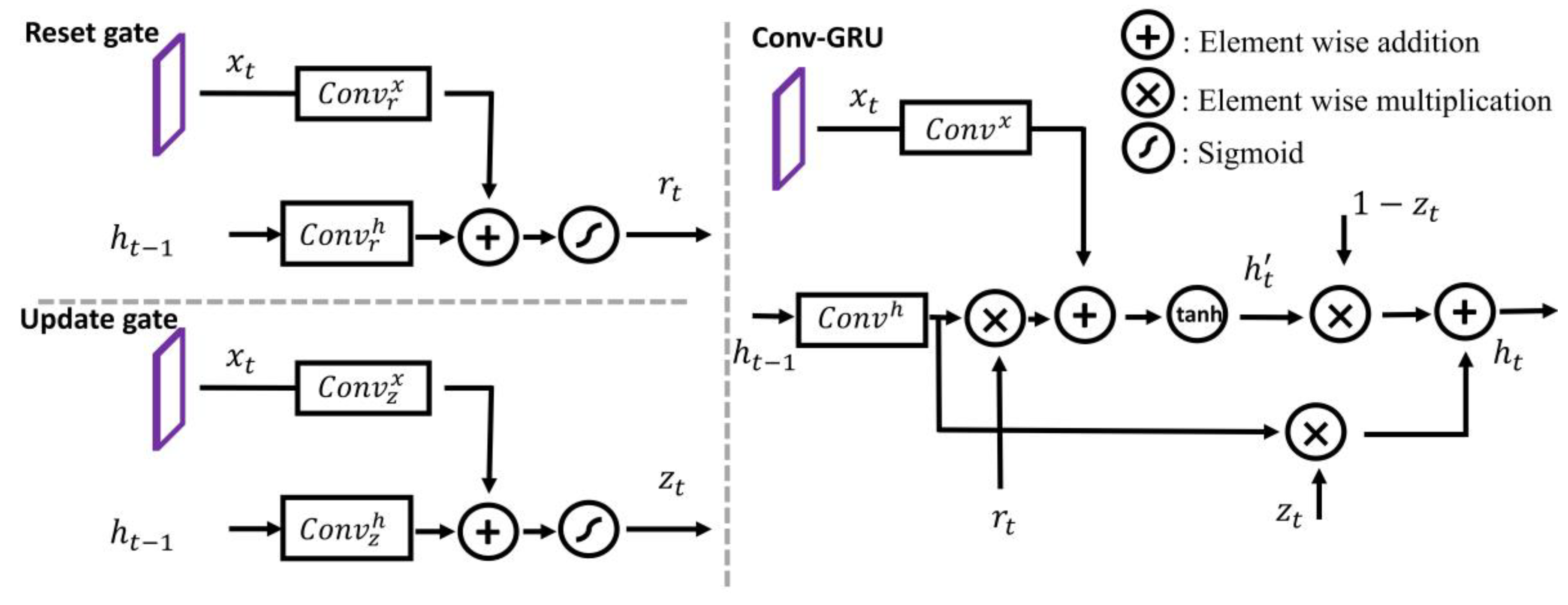
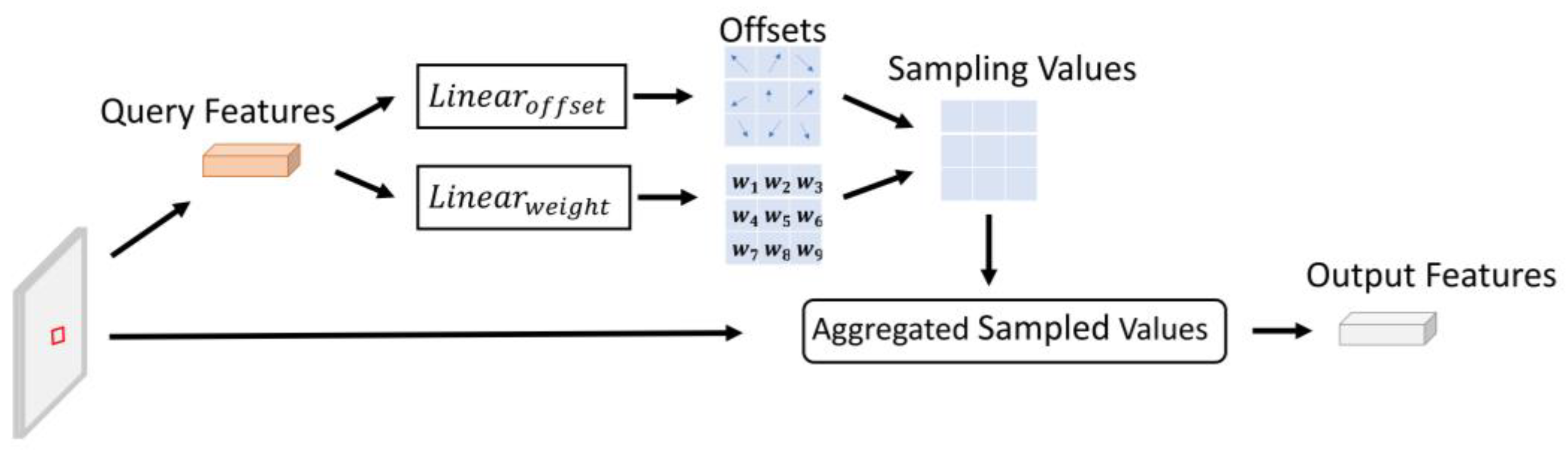
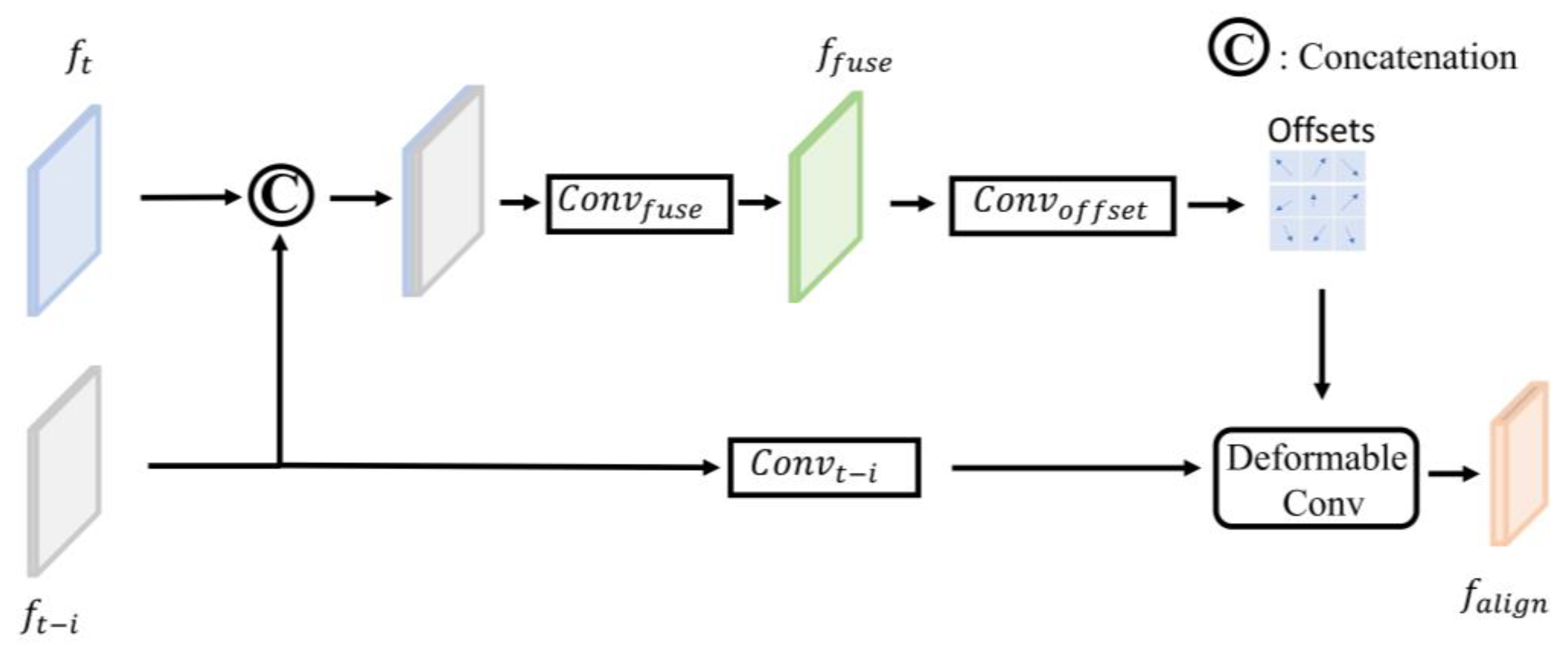
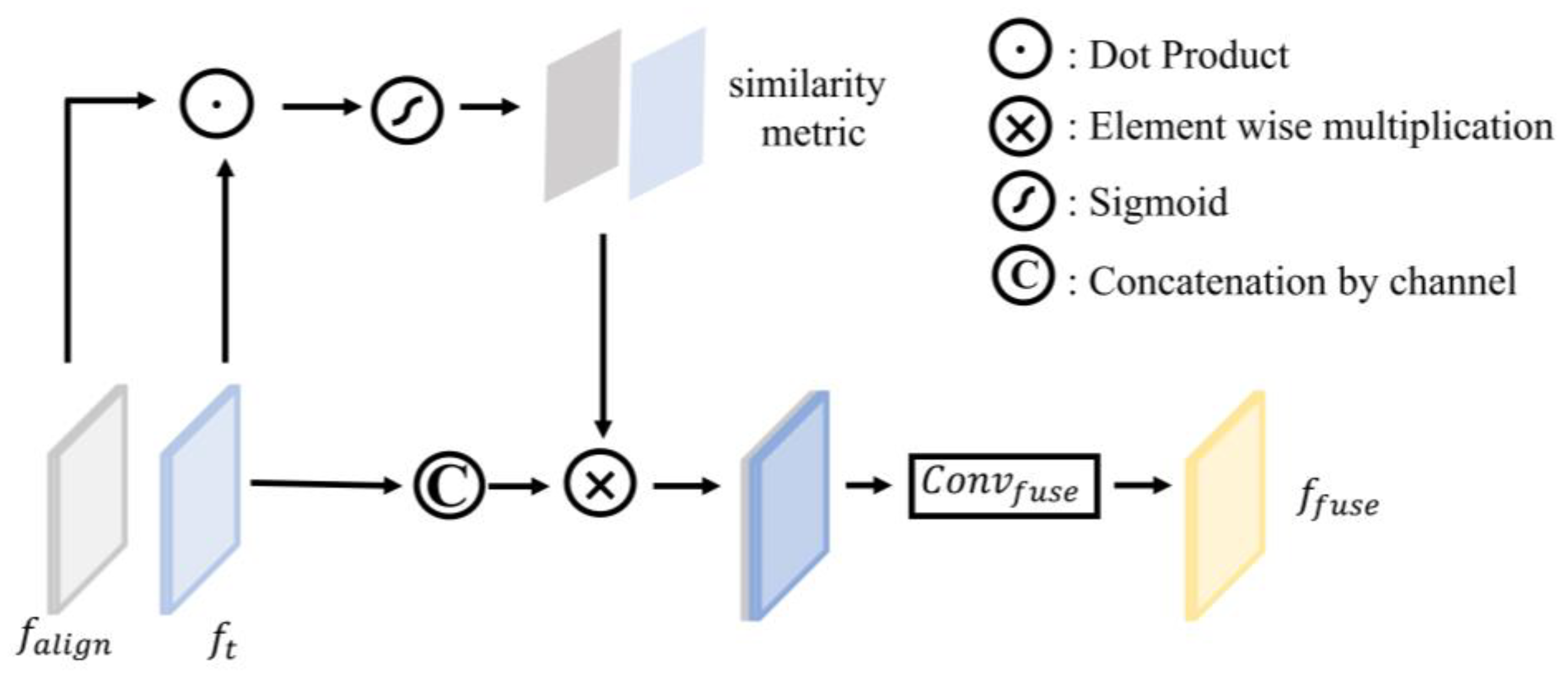
3. Proposed Method
3.1. Overview of TA-GRU YOLOv7
3.2. Model Design
4. Experiments
4.1. Training Dataset and DETAILS
4.2. Comparisons to State-of-the-Art
4.3. Ablation Study and Analysis
Ablation for TA-GRU YOLOv7
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- He, F.; Gao, N.; Li, Q.; Du, S.; Zhao, X.; Huang, K. TCE-Net. In Proceedings of the AAAI Conference on Artificial Intelligence, Hilton, NY, USA, 7–12 February 2020; pp. 10941–10948. [Google Scholar] [CrossRef]
- Shi, Y.; Wang, N.; Guo, X. YOLOV: Making Still Image Object Detectors Great at Video Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 2254–2262. [Google Scholar]
- Zhou, Q.; Li, X.; He, L.; Yang, Y.; Cheng, G.; Tong, Y.; Ma, L.; Tao, D. TransVOD: End-to-End Video Object Detection with Spatial-Temporal Transformers. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 7853–7869. [Google Scholar] [CrossRef] [PubMed]
- Zhu, X.; Wang, Y.; Dai, J.; Yuan, L.; Wei, Y. Flow-Guided Feature Aggregation for Video Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef] [Green Version]
- Fan, L.; Zhang, T.; Du, W. Optical-Flow-Based Framework to Boost Video Object Detection Performance with Object Enhancement. Expert Syst. Appl. 2020, 170, 114544. [Google Scholar] [CrossRef]
- Xiao, F.; Lee, Y.J. Video Object Detection with an Aligned Spatial-Temporal Memory. In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2018; pp. 494–510. [Google Scholar] [CrossRef] [Green Version]
- Lu, Y.; Lu, C.; Tang, C.-K. Online Video Object Detection Using Association LSTM. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef]
- Bertasius, G.; Torresani, L.; Shi, J. Object detection in video with spatiotemporal sampling networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 331–346. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation; Cornell University: Ithaca, NY, USA, 2013. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast R-CNN. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dosovitskiy, A.; Fischer, P.; Ilg, E.; Hausser, P.; Hazirbas, C.; Golkov, V.; Van Der Smagt, P.; Cremers, D.; Brox, T. FlowNet: Learning Optical Flow with Convolutional Networks. arXiv 2015, arXiv:1504.06852. [Google Scholar]
- Zhu, X.; Dai, J.; Yuan, L.; Wei, Y. Towards high performance video object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7210–7218. [Google Scholar]
- Kang, K.; Li, H.; Xiao, T.; Ouyang, W.; Yan, J.; Liu, X.; Wang, X. Object Detection in Videos with Tubelet Proposal Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef] [Green Version]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-Captured Scenarios. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef] [Green Version]
- Zhu, P.; Du, D.; Wen, L.; Bian, X.; Ling, H.; Hu, Q.; Peng, T.; Zheng, J.; Wang, X.; Zhang, Y.; et al. VisDrone-VID2019: The Vision Meets Drone Object Detection in Video Challenge Results. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Detect to Track and Track to Detect. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; ICCV: Paris, France, 2017; pp. 3057–3065. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; CVPR: New Orleans, LA, USA, 2017; pp. 936–944. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting Objects as Paired Keypoints. In Proceedings of the 15th European Conference on Computer Vision, Munich, German, 8–14 September 2018; ECCV: Aurora, CO, USA, 2018; pp. 765–781. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Zhao, Q.; Sheng, T.; Wang, Y.; Ni, F.; Cai, L. Cfenet: An accurate and efficient single-shot object detector for autonomous driving. arXiv 2018, arXiv:1806.09790. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Setup |
|---|---|
| Epochs | 70 |
| Batch Size | 4 |
| Image Size | |
| Initial Learning Rate | |
| Final Learning Rate | |
| Momentum | 0.937 |
| Weight-Decay | |
| Image Scale | 0.6 |
| Image Flip Left-Right | 0.5 |
| Mosaic | 0 |
| Image Translation | 0.2 |
| Image Rotation | 0.2 |
| Image Perspective |
| Methods | mAP (%) | AP50 (%) | Aggregate Frames | FPS |
|---|---|---|---|---|
| TA-GRU YOLOv7 | 24.57 | 48.79 | 2 | 24 |
| YOLOv7 [22] | 18.71 | 40.26 | - | 45 |
| TA-GRU YOLOX | 19.41 | 40.59 | 2 | - |
| YOLOX [23] | 16.86 | 35.62 | - | - |
| TA-GRU YOLOv7-tiny | 0.165 | 0.296 | 2 | - |
| YOLOv7-tiny | 0.103 | 0.212 | - | - |
| FGFA [4] | 18.33 | 39.71 | 21 | 4 |
| STSN [8] | 18.52 | 39.87 | 27 | - |
| D&T [24] | 17.04 | 35.37 | - | - |
| FPN [25] | 16.72 | 39.12 | - | - |
| CornerNet [26] | 16.49 | 35.79 | - | - |
| CenterNet [27] | 15.75 | 34.53 | - | - |
| CFE-SSDv2 [28] | 21.57 | 44.75 | - | 21 |
| Classification | mAP (%) | AP50 (%) | P | R |
|---|---|---|---|---|
| all | 24.57 | 48.79 | 0.577 | 0.513 |
| pedestrian | 29.1 | 68.1 | 0.658 | 0.668 |
| people | 18.5 | 49.7 | 0.56 | 0.579 |
| bicycle | 30.1 | 65.0 | 0.572 | 0.663 |
| car | 40.1 | 63.6 | 0.737 | 0.636 |
| van | 26.0 | 43.7 | 0.725 | 0.422 |
| truck | 32.1 | 56.1 | 0.636 | 0.578 |
| tricycle | 16.7 | 37.8 | 0.537 | 0.428 |
| awning-tricycle | 12.9 | 25.8 | 0.496 | 0.261 |
| bus | 25.4 | 33.4 | 0.368 | 0.345 |
| motor | 14.3 | 42.3 | 0.481 | 0.547 |
| Methods | (a) | (b) | (c) | (d) | (e) | (f) |
|---|---|---|---|---|---|---|
| Conv-GRU? | √ | √ | √ | |||
| TA-GRU? | √ | √ | ||||
| DeformAlign? | √ | √ | √ | √ | ||
| Temporal Attention and Temporal Fusion module? | √ | √ | √ | |||
| end-to-end training? | √ | √ | √ | √ | √ | |
| mAP (%) | 18.71 | 16.55 | 20.03 | 23.96 | 24.57 | 23.82 |
| AP50 (%) | 40.26 | 37.29 | 41.68 | 47.61 | 48.79 | 47.23 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Z.; Yu, X.; Chen, X. Object Detection in Drone Video with Temporal Attention Gated Recurrent Unit Based on Transformer. Drones 2023, 7, 466. https://doi.org/10.3390/drones7070466
Zhou Z, Yu X, Chen X. Object Detection in Drone Video with Temporal Attention Gated Recurrent Unit Based on Transformer. Drones. 2023; 7(7):466. https://doi.org/10.3390/drones7070466
Chicago/Turabian StyleZhou, Zihao, Xianguo Yu, and Xiangcheng Chen. 2023. "Object Detection in Drone Video with Temporal Attention Gated Recurrent Unit Based on Transformer" Drones 7, no. 7: 466. https://doi.org/10.3390/drones7070466
APA StyleZhou, Z., Yu, X., & Chen, X. (2023). Object Detection in Drone Video with Temporal Attention Gated Recurrent Unit Based on Transformer. Drones, 7(7), 466. https://doi.org/10.3390/drones7070466