
A Comprehensive Survey of Transformers for Computer Vision



Abstract
1. Introduction
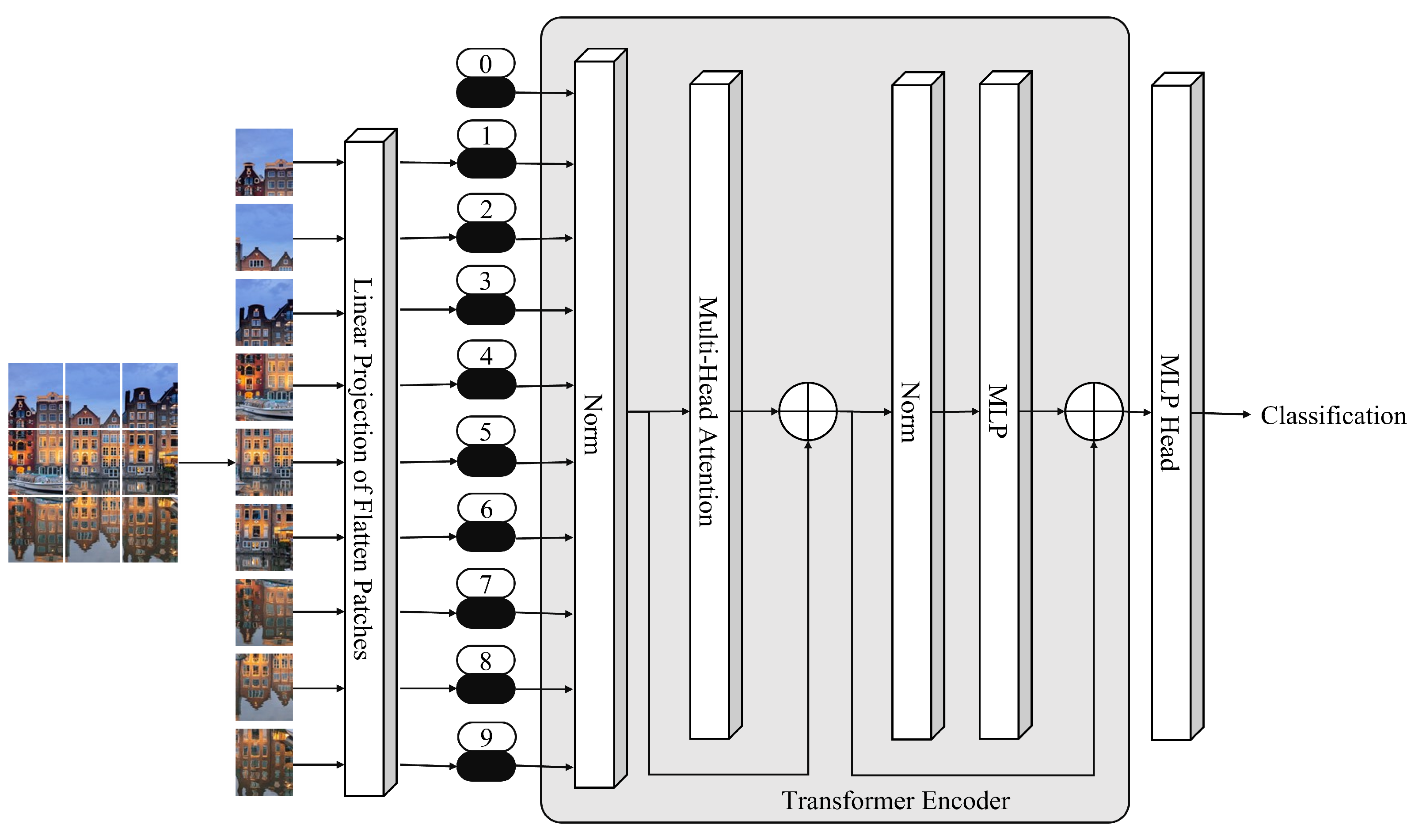
- ViTs divide the full image into a grid of small image patches.
- ViTs apply linear projection to embed each patch.
- Then, each embedded patch becomes a token, and the resulting sequence of embedded patches is passed to the transformer encoder (TE).
- Then, TE encodes the input patches, and the output is given to the multilayer perceptron (MLP) head, with the output of the MLP head being the input class.
- Image classification;
- Anomaly detection;
- Object detection;
- Image compression;
- Image segmentation;
- Video deepfake detection;
- Cluster analysis.
2. Related Work
2.1. Bibliometric Analysis and Methodology
2.1.1. Bibliometric Analysis
2.1.2. Methodology
| Algorithm 1 Article Selection Criteria |
| Require: Search on databases Ensure: Article from 2017 to 2023 while keyword—transformers in computer vision do if Discuss new architectures of ViTs | Evaluate performance of ViTs | Variants of ViTs then Consider for analysis else if Does not discuss ViTs architectures in vision then Exclude from the analysis end if end while |
3. Applications of ViTs in CV
3.1. ViTs for Image Classification
3.2. ViTs for Object Detection
3.3. ViTs for Image Segmentation
3.4. ViTs for Image Compression
3.5. ViTs for Image Super-Resolution
3.6. ViTs for Image Denoising
3.7. ViTs for Anomaly Detection
4. Advanced ViTs
- Task-based ViTs;
- Problem-based ViTs.
4.1. Task-Based ViTs
4.2. Problem-Based ViTs
5. Open Source ViTs
6. ViTs and Drone Imagery
7. Open Research Challenges and Future Directions
7.1. High Computational Cost
7.2. Large Training Dataset
7.3. Neural Architecture Search (NAS)
7.4. Interpretability of the Transformers
7.5. Hardware-Efficient Designs
7.6. Large CV Model
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AID | Aerial image dataset |
| AP | Average precision |
| AQI | Air quality index |
| AUC | Area under the curve |
| AUROC | Area under receiver operating characteristic curve |
| Box average precision | |
| BERT | Bidirectional encoder representations from transformers |
| bpp | Bits per pixel |
| BrT | Bridged transformer |
| BTAD | BeanTech anomaly detection |
| CIFAR | Canadian Institute for Advanced Research |
| CV | Computer vision |
| CNN | Convolutional neural network |
| DHViT | Deep hierarchical ViT |
| DOViT | Double output ViT |
| ES-GSNet | Excellent teacher guiding small networks |
| GAOs-1 | Get AQI in one shot-1 |
| GAOs-2 | Get AQI in one shot-2 |
| GPT-3 | Generative pretrained transformer 3 |
| HD | Hausdorff distance |
| IoU | Intersection over union |
| JI | Jaccord index |
| LiDAR | Light detection and ranging |
| mAP | Mean average precision |
| MLP | Multilayer perceptron |
| MIL-ViT | Multiple instance-enhanced ViT |
| MIM | Masked image modeling |
| MITformer | Multi-instance ViT |
| MSE | Mean squared error |
| MS-SSIM | Multiscale structural similarity |
| NLP | Natural language processing |
| NWPU | Northwestern Polytechnical University |
| PSNR | Peak signal to noise ratio |
| PRO | Per region overlap |
| PUAS | Planet Understanding the Amazon from Space |
| RFMiD2020 | 2020 retinal fundus multidisease image dataset |
| R-CNN | Region-based convolutional neural network |
| RMSE | Root mean square error |
| SSIM | Structural similarity |
| TE | Transformer encoder |
| UCM | UC-Mered land use dataset |
| ViTs | Vision transformers |
| VT-ADL | ViT network for image anomaly detection and localization |
| ViT-PP | ViT with postprocessing |
| YOLOS | You only look at one sequence |
References
- Heo, B.; Yun, S.; Han, D.; Chun, S.; Choe, J.; Oh, S.J. Rethinking spatial dimensions of vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 11936–11945. [Google Scholar]
- Tenney, I.; Das, D.; Pavlick, E. BERT rediscovers the classical NLP pipeline. arXiv 2019, arXiv:1905.05950. [Google Scholar]
- Floridi, L.; Chiriatti, M. GPT-3: Its nature, scope, limits, and consequences. Minds Mach. 2020, 30, 681–694. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Jamil, S.; Rahman, M.; Ullah, A.; Badnava, S.; Forsat, M.; Mirjavadi, S.S. Malicious UAV detection using integrated audio and visual features for public safety applications. Sensors 2020, 20, 3923. [Google Scholar] [CrossRef]
- Wu, Z.; Shen, C.; Van Den Hengel, A. Wider or deeper: Revisiting the resnet model for visual recognition. Pattern Recognit. 2019, 90, 119–133. [Google Scholar] [CrossRef]
- Hammad, I.; El-Sankary, K. Impact of approximate multipliers on VGG deep learning network. IEEE Access 2018, 6, 60438–60444. [Google Scholar] [CrossRef]
- Yao, X.; Wang, X.; Karaca, Y.; Xie, J.; Wang, S. Glomerulus classification via an improved GoogLeNet. IEEE Access 2020, 8, 176916–176923. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Wang, C.; Chen, D.; Hao, L.; Liu, X.; Zeng, Y.; Chen, J.; Zhang, G. Pulmonary image classification based on inception-v3 transfer learning model. IEEE Access 2019, 7, 146533–146541. [Google Scholar] [CrossRef]
- Jamil, S.; Fawad; Abbas, M.S.; Habib, F.; Umair, M.; Khan, M.J. Deep learning and computer vision-based a novel framework for himalayan bear, marco polo sheep and snow leopard detection. In Proceedings of the 2020 International Conference on Information Science and Communication Technology (ICISCT), Karachi, Pakistan, 8–9 February2020; pp. 1–6. [Google Scholar]
- Zhang, K.; Guo, Y.; Wang, X.; Yuan, J.; Ding, Q. Multiple feature reweight densenet for image classification. IEEE Access 2019, 7, 9872–9880. [Google Scholar] [CrossRef]
- Wang, J.; Yang, L.; Huo, Z.; He, W.; Luo, J. Multi-label classification of fundus images with efficientnet. IEEE Access 2020, 8, 212499–212508. [Google Scholar] [CrossRef]
- Hossain, M.A.; Nguyen, V.; Huh, E.N. The trade-off between accuracy and the complexity of real-time background subtraction. IET Image Process. 2021, 15, 350–368. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf (accessed on 18 April 2023).
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wu, B.; Xu, C.; Dai, X.; Wan, A.; Zhang, P.; Yan, Z.; Tomizuka, M.; Gonzalez, J.; Keutzer, K.; Vajda, P. Visual transformers: Token-based image representation and processing for computer vision. arXiv 2020, arXiv:2006.03677. [Google Scholar]
- Xiao, T.; Singh, M.; Mintun, E.; Darrell, T.; Dollár, P.; Girshick, R. Early convolutions help transformers see better. Adv. Neural Inf. Process. Syst. 2021, 34, 30392–30400. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 10012–10022. [Google Scholar]
- Bertasius, G.; Wang, H.; Torresani, L. Is space-time attention all you need for video understanding? In ICML; PMLR, 2021; Volume 2, p. 4. Available online: https://proceedings.mlr.press/v139/bertasius21a.html (accessed on 18 April 2023).
- Raghu, M.; Unterthiner, T.; Kornblith, S.; Zhang, C.; Dosovitskiy, A. Do vision transformers see like convolutional neural networks? Adv. Neural Inf. Process. Syst. 2021, 34, 12116–12128. [Google Scholar]
- Naseer, M.M.; Ranasinghe, K.; Khan, S.H.; Hayat, M.; Shahbaz Khan, F.; Yang, M.H. Intriguing properties of vision transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 23296–23308. [Google Scholar]
- Dai, Z.; Liu, H.; Le, Q.V.; Tan, M. Coatnet: Marrying convolution and attention for all data sizes. Adv. Neural Inf. Process. Syst. 2021, 34, 3965–3977. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. Cvt: Introducing convolutions to vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 22–31. [Google Scholar]
- Coccomini, D.A.; Messina, N.; Gennaro, C.; Falchi, F. Combining efficientnet and vision transformers for video deepfake detection. In International Conference on Image Analysis and Processing; Springer: Cham, Switzerland, 2022; pp. 219–229. [Google Scholar]
- Tay, Y.; Dehghani, M.; Bahri, D.; Metzler, D. Efficient transformers: A survey. ACM Comput. Surv. (CSUR) 2020, 55, 1–28. [Google Scholar] [CrossRef]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in vision: A survey. ACM Comput. Surv. (CSUR) 2022, 54, 1–41. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, Y.; Wang, Y.; Hou, F.; Yuan, J.; Tian, J.; Zhang, Y.; Shi, Z.; Fan, J.; He, Z. A survey of visual transformers. arXiv 2021, arXiv:2111.06091. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.; Wang, Y.; Liu, X.; Qiu, X. A survey of transformers. AI Open 2022, 3, 111–132. [Google Scholar] [CrossRef]
- Xu, Y.; Wei, H.; Lin, M.; Deng, Y.; Sheng, K.; Zhang, M.; Tang, F.; Dong, W.; Huang, F.; Xu, C. Transformers in computational visual media: A survey. Comput. Vis. Media 2022, 8, 33–62. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.F.R.; Fan, Q.; Panda, R. Crossvit: Cross-attention multi-scale vision transformer for image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 357–366. [Google Scholar]
- Deng, P.; Xu, K.; Huang, H. When CNNs meet vision transformer: A joint framework for remote sensing scene classification. IEEE Geosci. Remote. Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Yu, S.; Ma, K.; Bi, Q.; Bian, C.; Ning, M.; He, N.; Li, Y.; Liu, H.; Zheng, Y. Mil-vt: Multiple instance learning enhanced vision transformer for fundus image classification. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2021; pp. 45–54. [Google Scholar]
- Graham, B.; El-Nouby, A.; Touvron, H.; Stock, P.; Joulin, A.; Jégou, H.; Douze, M. Levit: A vision transformer in convnet’s clothing for faster inference. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 12259–12269. [Google Scholar]
- Xu, K.; Deng, P.; Huang, H. Vision transformer: An excellent teacher for guiding small networks in remote sensing image scene classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Xue, Z.; Tan, X.; Yu, X.; Liu, B.; Yu, A.; Zhang, P. Deep Hierarchical Vision Transformer for Hyperspectral and LiDAR Data Classification. IEEE Trans. Image Process. 2022, 31, 3095–3110. [Google Scholar] [CrossRef]
- Kaselimi, M.; Voulodimos, A.; Daskalopoulos, I.; Doulamis, N.; Doulamis, A. A Vision Transformer Model for Convolution-Free Multilabel Classification of Satellite Imagery in Deforestation Monitoring. IEEE Trans. Neural Netw. Learn. Syst. 2022; Online ahead of print. [Google Scholar]
- Chen, Y.; Gu, X.; Liu, Z.; Liang, J. A Fast Inference Vision Transformer for Automatic Pavement Image Classification and Its Visual Interpretation Method. Remote Sens. 2022, 14, 1877. [Google Scholar] [CrossRef]
- Jamil, S.; Abbas, M.S.; Roy, A.M. Distinguishing Malicious Drones Using Vision Transformer. AI 2022, 3, 260–273. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In International Conference on Machine Learning; PMLR: Cambridge, MA, USA, 2019; pp. 6105–6114. [Google Scholar]
- Tanzi, L.; Audisio, A.; Cirrincione, G.; Aprato, A.; Vezzetti, E. Vision Transformer for femur fracture classification. Injury 2022, 53, 2625–2634. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Luo, T.; Wu, J.; Wang, Z.; Zhang, H. A Vision Transformer network SeedViT for classification of maize seeds. J. Food Process. Eng. 2022, 45, e13998. [Google Scholar] [CrossRef]
- Wang, Z.; Yang, Y.; Yue, S. Air Quality Classification and Measurement Based on Double Output Vision Transformer. IEEE Internet Things J. 2022, 9, 20975–20984. [Google Scholar] [CrossRef]
- Sha, Z.; Li, J. MITformer: A Multi-Instance Vision Transformer for Remote Sensing Scene Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Kim, K.; Wu, B.; Dai, X.; Zhang, P.; Yan, Z.; Vajda, P.; Kim, S.J. Rethinking the self-attention in vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 3071–3075. [Google Scholar]
- Lee, S.H.; Lee, S.; Song, B.C. Vision transformer for small-size datasets. arXiv 2021, arXiv:2112.13492. [Google Scholar]
- Beal, J.; Kim, E.; Tzeng, E.; Park, D.H.; Zhai, A.; Kislyuk, D. Toward transformer-based object detection. arXiv 2020, arXiv:2012.09958. [Google Scholar]
- Fang, Y.; Liao, B.; Wang, X.; Fang, J.; Qi, J.; Wu, R.; Niu, J.; Liu, W. You only look at one sequence: Rethinking transformer in vision through object detection. Adv. Neural Inf. Process. Syst. 2021, 34, 26183–26197. [Google Scholar]
- Li, Y.; Xie, S.; Chen, X.; Dollar, P.; He, K.; Girshick, R. Benchmarking detection transfer learning with vision transformers. arXiv 2021, arXiv:2111.11429. [Google Scholar]
- Bao, H.; Dong, L.; Wei, F. Beit: Bert pre-training of image transformers. arXiv 2021, arXiv:2106.08254. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June2022; pp. 16000–16009. [Google Scholar]
- Horváth, J.; Baireddy, S.; Hao, H.; Montserrat, D.M.; Delp, E.J. Manipulation detection in satellite images using vision transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1032–1041. [Google Scholar]
- Wang, Y.; Ye, T.; Cao, L.; Huang, W.; Sun, F.; He, F.; Tao, D. Bridged Transformer for Vision and Point Cloud 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12114–12123. [Google Scholar]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Nießner, M. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5828–5839. [Google Scholar]
- Song, S.; Lichtenberg, S.P.; Xiao, J. Sun rgb-d: A rgb-d scene understanding benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 567–576. [Google Scholar]
- Liu, Z.; Zhang, Z.; Cao, Y.; Hu, H.; Tong, X. Group-free 3D object detection via transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 2949–2958. [Google Scholar]
- Prangemeier, T.; Reich, C.; Koeppl, H. Attention-based transformers for instance segmentation of cells in microstructures. In Proceedings of the 2020 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Seoul, Republic of Korea, 16–19 December 2020; pp. 700–707. [Google Scholar]
- Chen, T.; Saxena, S.; Li, L.; Fleet, D.J.; Hinton, G. Pix2seq: A language modeling framework for object detection. arXiv 2021, arXiv:2109.10852. [Google Scholar]
- Wang, Y.; Zhang, X.; Yang, T.; Sun, J. Anchor detr: Query design for transformer-based detector. AAAI Conf. Artif. Intell. 2022, 36, 2567–2575. [Google Scholar] [CrossRef]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Sagar, A. Vitbis: Vision transformer for biomedical image segmentation. In Clinical Image-Based Procedures, Distributed and Collaborative Learning, Artificial Intelligence for Combating COVID-19 and Secure and Privacy-Preserving Machine Learning; Springer: Cham, Switzerland, 2021; pp. 34–45. [Google Scholar]
- Huttenlocher, D.P.; Klanderman, G.A.; Rucklidge, W.J. Comparing images using the Hausdorff distance. IEEE Trans. Pattern Anal. Mach. Intell. 1993, 15, 850–863. [Google Scholar] [CrossRef]
- Yang, Z.; Wang, J.; Tang, Y.; Chen, K.; Zhao, H.; Torr, P.H. LAVT: Language-Aware Vision Transformer for Referring Image Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18155–18165. [Google Scholar]
- Yu, L.; Poirson, P.; Yang, S.; Berg, A.C.; Berg, T.L. Modeling context in referring expressions. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 69–85. [Google Scholar]
- Nagaraja, V.K.; Morariu, V.I.; Davis, L.S. Modeling context between objects for referring expression understanding. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 792–807. [Google Scholar]
- Mao, J.; Huang, J.; Toshev, A.; Camburu, O.; Yuille, A.L.; Murphy, K. Generation and comprehension of unambiguous object descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 11–20. [Google Scholar]
- Gu, J.; Kwon, H.; Wang, D.; Ye, W.; Li, M.; Chen, Y.H.; Lai, L.; Chandra, V.; Pan, D.Z. Multi-scale high-resolution vision transformer for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12094–12103. [Google Scholar]
- Cheng, B.; Schwing, A.; Kirillov, A. Per-pixel classification is not all you need for semantic segmentation. Adv. Neural Inf. Process. Syst. 2021, 34, 17864–17875. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In European Conference on Computer Vision (ECCV); Springer: Cham, Switzerland, 2018; pp. 801–818. [Google Scholar]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified perceptual parsing for scene understanding. In European Conference on Computer Vision (ECCV); Springer: Cham, Switzerland, 2018; pp. 418–434. [Google Scholar]
- Yuan, Y.; Chen, X.; Wang, J. Object-contextual representations for semantic segmentation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part VI 16. Springer: Cham, Switzerland, 2020; pp. 173–190. [Google Scholar]
- Yuan, Y.; Huang, L.; Guo, J.; Zhang, C.; Chen, X.; Wang, J. OCNet: Object context for semantic segmentation. Int. J. Comput. Vis. 2021, 129, 2375–2398. [Google Scholar] [CrossRef]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6881–6890. [Google Scholar]
- Wang, H.; Zhu, Y.; Adam, H.; Yuille, A.; Chen, L.C. Max-deeplab: End-to-end panoptic segmentation with mask transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5463–5474. [Google Scholar]
- Hatamizadeh, A.; Xu, Z.; Yang, D.; Li, W.; Roth, H.; Xu, D. UNetFormer: A Unified Vision Transformer Model and Pre-Training Framework for 3D Medical Image Segmentation. arXiv 2022, arXiv:2204.00631. [Google Scholar]
- Antonelli, M.; Reinke, A.; Bakas, S.; Farahani, K.; Kopp-Schneider, A.; Landman, B.A.; Litjens, G.; Menze, B.; Ronneberger, O.; Summers, R.M.; et al. The medical segmentation decathlon. Nat. Commun. 2022, 13, 4128. [Google Scholar] [CrossRef]
- Baid, U.; Ghodasara, S.; Mohan, S.; Bilello, M.; Calabrese, E.; Colak, E.; Farahani, K.; Kalpathy-Cramer, J.; Kitamura, F.C.; Pati, S.; et al. The rsna-asnr-miccai brats 2021 benchmark on brain tumor segmentation and radiogenomic classification. arXiv 2021, arXiv:2107.02314. [Google Scholar]
- Zhao, H.; Jia, J.; Koltun, V. Exploring self-attention for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10076–10085. [Google Scholar]
- Ramachandran, P.; Parmar, N.; Vaswani, A.; Bello, I.; Levskaya, A.; Shlens, J. Stand-alone self-attention in vision models. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Mishra, D.; Singh, S.K.; Singh, R.K. Deep architectures for image compression: A critical review. Signal Process. 2022, 191, 108346. [Google Scholar] [CrossRef]
- Jamil, S.; Piran, M. Learning-Driven Lossy Image Compression; A Comprehensive Survey. arXiv 2022, arXiv:2201.09240. [Google Scholar]
- Qian, Y.; Lin, M.; Sun, X.; Tan, Z.; Jin, R. Entroformer: A Transformer-based Entropy Model for Learned Image Compression. arXiv 2022, arXiv:2202.05492. [Google Scholar]
- Ballé, J.; Minnen, D.; Singh, S.; Hwang, S.J.; Johnston, N. Variational image compression with a scale hyperprior. arXiv 2018, arXiv:1802.01436. [Google Scholar]
- Koyuncu, A.B.; Gao, H.; Boev, A.; Gaikov, G.; Alshina, E.; Steinbach, E. Contextformer: A Transformer with Spatio-Channel Attention for Context Modeling in Learned Image Compression. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2022; pp. 447–463. [Google Scholar]
- Bross, B.; Wang, Y.K.; Ye, Y.; Liu, S.; Chen, J.; Sullivan, G.J.; Ohm, J.R. Overview of the versatile video coding (VVC) standard and its applications. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3736–3764. [Google Scholar] [CrossRef]
- Lu, M.; Guo, P.; Shi, H.; Cao, C.; Ma, Z. Transformer-based image compression. arXiv 2021, arXiv:2111.06707. [Google Scholar]
- Christensen, C.N.; Lu, M.; Ward, E.N.; Lio, P.; Kaminski, C.F. Spatio-temporal Vision Transformer for Super-resolution Microscopy. arXiv 2022, arXiv:2203.00030. [Google Scholar]
- Wang, D.; Wu, Z.; Yu, H. Ted-net: Convolution-free t2t vision transformer-based encoder-decoder dilation network for low-dose ct denoising. In International Workshop on Machine Learning in Medical Imaging; Springer: Cham, Switzerland, 2021; pp. 416–425. [Google Scholar]
- Luthra, A.; Sulakhe, H.; Mittal, T.; Iyer, A.; Yadav, S. Eformer: Edge enhancement based transformer for medical image denoising. arXiv 2021, arXiv:2109.08044. [Google Scholar]
- McCollough, C.H.; Bartley, A.C.; Carter, R.E.; Chen, B.; Drees, T.A.; Edwards, P.; Holmes, D.R., III; Huang, A.E.; Khan, F.; Leng, S.; et al. Low-dose CT for the detection and classification of metastatic liver lesions: Results of the 2016 low dose CT grand challenge. Med. Phys. 2017, 44, e339–e352. [Google Scholar] [CrossRef]
- Fan, C.M.; Liu, T.J.; Liu, K.H. SUNet: Swin Transformer UNet for Image Denoising. arXiv 2022, arXiv:2202.14009. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the Eighth IEEE International Conference on Computer Vision. ICCV 2001, Vancouver, BC, Canada, 7–14 July 2001; Volume 2, pp. 416–423. [Google Scholar]
- Franzen, R. Kodak Lossless True Color Image Suite. 1999, Volume 4. Available online: http://r0k.us/graphics/kodak (accessed on 19 April 2023).
- Yao, C.; Jin, S.; Liu, M.; Ban, X. Dense residual Transformer for image denoising. Electronics 2022, 11, 418. [Google Scholar] [CrossRef]
- Abdelhamed, A.; Lin, S.; Brown, M.S. A high-quality denoising dataset for smartphone cameras. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1692–1700. [Google Scholar]
- Plotz, T.; Roth, S. Benchmarking denoising algorithms with real photographs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1586–1595. [Google Scholar]
- Xu, K.; Li, W.; Wang, X.; Wang, X.; Yan, K.; Hu, X.; Dong, X. CUR Transformer: A Convolutional Unbiased Regional Transformer for Image Denoising. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2022, 19, 1–22. [Google Scholar] [CrossRef]
- Xue, T.; Ma, P. TC-net: Transformer combined with cnn for image denoising. Appl. Intell. 2022, 53, 6753–6762. [Google Scholar] [CrossRef]
- Zhao, M.; Cao, G.; Huang, X.; Yang, L. Hybrid Transformer-CNN for Real Image Denoising. IEEE Signal Process. Lett. 2022, 29, 1252–1256. [Google Scholar] [CrossRef]
- Pang, L.; Gu, W.; Cao, X. TRQ3DNet: A 3D Quasi-Recurrent and Transformer Based Network for Hyperspectral Image Denoising. Remote Sens. 2022, 14, 4598. [Google Scholar] [CrossRef]
- Chen, H.; Yang, G.; Zhang, H. Hider: A Hyperspectral Image Denoising Transformer With Spatial–Spectral Constraints for Hybrid Noise Removal. IEEE Trans. Neural Netw. Learn. Syst. 2022; Early Access. [Google Scholar]
- Yin, H.; Ma, S. CSformer: Cross-Scale Features Fusion Based Transformer for Image Denoising. IEEE Signal Process. Lett. 2022, 29, 1809–1813. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 391–407. [Google Scholar]
- Zhang, K.; Zuo, W.; Zhang, L. FFDNet: Toward a fast and flexible solution for CNN-based image denoising. IEEE Trans. Image Process. 2018, 27, 4608–4622. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning deep CNN denoiser prior for image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3929–3938. [Google Scholar]
- Zhang, K.; Li, Y.; Zuo, W.; Zhang, L.; Van Gool, L.; Timofte, R. Plug-and-play image restoration with deep denoiser prior. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6360–6376. [Google Scholar] [CrossRef]
- Wang, Z.; Cun, X.; Bao, J.; Zhou, W.; Liu, J.; Li, H. Uformer: A general u-shaped transformer for image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17683–17693. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 1833–1844. [Google Scholar]
- Mishra, P.; Verk, R.; Fornasier, D.; Piciarelli, C.; Foresti, G.L. VT-ADL: A vision transformer network for image anomaly detection and localization. In Proceedings of the 2021 IEEE 30th International Symposium on Industrial Electronics (ISIE), Kyoto, Japan, 20–23 June 2021; pp. 1–6. [Google Scholar]
- Bergmann, P.; Fauser, M.; Sattlegger, D.; Steger, C. MVTec AD–A comprehensive real-world dataset for unsupervised anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9592–9600. [Google Scholar]
- Lee, Y.; Kang, P. AnoViT: Unsupervised Anomaly Detection and Localization With Vision Transformer-Based Encoder-Decoder. IEEE Access 2022, 10, 46717–46724. [Google Scholar] [CrossRef]
- Yuan, H.; Cai, Z.; Zhou, H.; Wang, Y.; Chen, X. TransAnomaly: Video Anomaly Detection Using Video Vision Transformer. IEEE Access 2021, 9, 123977–123986. [Google Scholar] [CrossRef]
- Lee, Y.; Kim, J.; Willette, J.; Hwang, S.J. MPViT: Multi-path vision transformer for dense prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7287–7296. [Google Scholar]
- Mok, T.C.; Chung, A. Affine Medical Image Registration with Coarse-to-Fine Vision Transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 20835–20844. [Google Scholar]
- Yuan, K.; Guo, S.; Liu, Z.; Zhou, A.; Yu, F.; Wu, W. Incorporating convolution designs into visual transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 579–588. [Google Scholar]
- Sun, W.; Niessen, W.J.; Klein, S. Hierarchical vs. simultaneous multiresolution strategies for nonrigid image registration. In International Workshop on Biomedical Image Registration; Springer: Berlin/Heidelberg, Germany, 2012; pp. 60–69. [Google Scholar]
- Chen, J.; Frey, E.C.; He, Y.; Segars, W.P.; Li, Y.; Du, Y. TransMorph: Transformer for unsupervised medical image registration. Med. Image Anal. 2022, 82, 102615. [Google Scholar] [CrossRef] [PubMed]
- Fang, J.; Xie, L.; Wang, X.; Zhang, X.; Liu, W.; Tian, Q. Msg-transformer: Exchanging local spatial information by manipulating messenger tokens. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12063–12072. [Google Scholar]
- Chen, J.N.; Sun, S.; He, J.; Torr, P.H.; Yuille, A.; Bai, S. Transmix: Attend to mix for vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12135–12144. [Google Scholar]
- Dong, X.; Bao, J.; Chen, D.; Zhang, W.; Yu, N.; Yuan, L.; Chen, D.; Guo, B. Cswin transformer: A general vision transformer backbone with cross-shaped windows. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12124–12134. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. Swin transformer v2: Scaling up capacity and resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12009–12019. [Google Scholar]
- Wang, Y.; Huang, R.; Song, S.; Huang, Z.; Huang, G. Not all images are worth 16x16 words: Dynamic transformers for efficient image recognition. Adv. Neural Inf. Process. Syst. 2021, 34, 11960–11973. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 568–578. [Google Scholar]
- Chu, X.; Tian, Z.; Wang, Y.; Zhang, B.; Ren, H.; Wei, X.; Xia, H.; Shen, C. Twins: Revisiting the design of spatial attention in vision transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 9355–9366. [Google Scholar]
- Mehta, S.; Rastegari, M. Mobilevit: Light-weight, general-purpose, and mobile-friendly vision transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar]
- Zhou, D.; Shi, Y.; Kang, B.; Yu, W.; Jiang, Z.; Li, Y.; Jin, X.; Hou, Q.; Feng, J. Refiner: Refining self-attention for vision transformers. arXiv 2021, arXiv:2106.03714. [Google Scholar]
- Zhou, D.; Kang, B.; Jin, X.; Yang, L.; Lian, X.; Jiang, Z.; Hou, Q.; Feng, J. Deepvit: Towards deeper vision transformer. arXiv 2021, arXiv:2103.11886. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In International Conference on Machine Learning; PMLR: Cambridge, MA, USA, 2021; pp. 10347–10357. [Google Scholar]
- Chen, Z.; Xie, L.; Niu, J.; Liu, X.; Wei, L.; Tian, Q. Visformer: The vision-friendly transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 589–598. [Google Scholar]
- Zhang, L.; Zhang, L.; Du, B. Deep learning for remote sensing data: A technical tutorial on the state of the art. IEEE Geosci. Remote. Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote. Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Jozdani, S.; Chen, D.; Pouliot, D.; Johnson, B.A. A review and meta-analysis of generative adversarial networks and their applications in remote sensing. Int. J. Appl. Earth Obs. Geoinf. 2022, 108, 102734. [Google Scholar] [CrossRef]
- Zhou, H.Y.; Lu, C.; Yang, S.; Yu, Y. ConvNets vs. Transformers: Whose visual representations are more transferable? In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 2230–2238. [Google Scholar]
- Sangam, T.; Dave, I.R.; Sultani, W.; Shah, M. Transvisdrone: Spatio-temporal transformer for vision-based drone-to-drone detection in aerial videos. arXiv 2022, arXiv:2210.08423. [Google Scholar]
- Li, J.; Ye, D.H.; Chung, T.; Kolsch, M.; Wachs, J.; Bouman, C. Multi-target detection and tracking from a single camera in Unmanned Aerial Vehicles (UAVs). In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 4992–4997. [Google Scholar]
- Rozantsev, A.; Lepetit, V.; Fua, P. Detecting flying objects using a single moving camera. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 879–892. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; He, Z.; Wang, L.; Wang, W.; Yuan, Y.; Zhang, D.; Zhang, J.; Zhu, P.; Van Gool, L.; Han, J.; et al. VisDrone-CC2021: The vision meets drone crowd counting challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 2830–2838. [Google Scholar]
- Gibril, M.B.A.; Shafri, H.Z.M.; Al-Ruzouq, R.; Shanableh, A.; Nahas, F.; Al Mansoori, S. Large-Scale Date Palm Tree Segmentation from Multiscale UAV-Based and Aerial Images Using Deep Vision Transformers. Drones 2023, 7, 93. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 7262–7272. [Google Scholar]
- Ranftl, R.; Bochkovskiy, A.; Koltun, V. Vision transformers for dense prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 12179–12188. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 2778–2788. [Google Scholar]
- Cao, Y.; He, Z.; Wang, L.; Wang, W.; Yuan, Y.; Zhang, D.; Zhang, J.; Zhu, P.; Van Gool, L.; Han, J.; et al. VisDrone-DET2021: The vision meets drone object detection challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 2847–2854. [Google Scholar]
- Thai, H.T.; Tran-Van, N.Y.; Le, K.H. Artificial cognition for early leaf disease detection using vision transformers. In Proceedings of the 2021 International Conference on Advanced Technologies for Communications (ATC), Ho Chi Minh City, Vietnam, 14–16 October 2021; pp. 33–38. [Google Scholar]
- Yu, Q.; Xia, Y.; Bai, Y.; Lu, Y.; Yuille, A.L.; Shen, W. Glance-and-gaze vision transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 12992–13003. [Google Scholar]
- Bai, J.; Yuan, L.; Xia, S.T.; Yan, S.; Li, Z.; Liu, W. Improving Vision Transformers by Revisiting High-frequency Components. arXiv 2022, arXiv:2204.00993. [Google Scholar]
- Cao, Y.H.; Yu, H.; Wu, J. Training vision transformers with only 2040 images. arXiv 2022, arXiv:2201.10728. [Google Scholar]
- Liu, Y.; Sun, Y.; Xue, B.; Zhang, M.; Yen, G.G.; Tan, K.C. A survey on evolutionary neural architecture search. IEEE Trans. Neural Netw. Learn. Syst. 2021, 34, 550–570. [Google Scholar] [CrossRef]
- Ren, P.; Xiao, Y.; Chang, X.; Huang, P.Y.; Li, Z.; Chen, X.; Wang, X. A comprehensive survey of neural architecture search: Challenges and solutions. ACM Comput. Surv. (CSUR) 2021, 54, 1–34. [Google Scholar] [CrossRef]
- Hu, Y.Q.; Yu, Y. A technical view on neural architecture search. Int. J. Mach. Learn. Cybern. 2020, 11, 795–811. [Google Scholar] [CrossRef]
- Elsken, T.; Metzen, J.H.; Hutter, F. Neural architecture search: A survey. J. Mach. Learn. Res. 2019, 20, 1997–2017. [Google Scholar]
- Chitty-Venkata, K.T.; Emani, M.; Vishwanath, V.; Somani, A.K. Neural Architecture Search for Transformers: A Survey. IEEE Access 2022, 10, 108374–108412. [Google Scholar] [CrossRef]
- Chen, B.; Li, P.; Li, C.; Li, B.; Bai, L.; Lin, C.; Sun, M.; Yan, J.; Ouyang, W. Glit: Neural architecture search for global and local image transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 12–21. [Google Scholar]
- Li, C.; Tang, T.; Wang, G.; Peng, J.; Wang, B.; Liang, X.; Chang, X. Bossnas: Exploring hybrid cnn-transformers with block-wisely self-supervised neural architecture search. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: New York, NY, USA, 2021; pp. 12281–12291. [Google Scholar]
- Gong, C.; Wang, D.; Li, M.; Chen, X.; Yan, Z.; Tian, Y.; Chandra, V. NASViT: Neural Architecture Search for Efficient Vision Transformers with Gradient Conflict aware Supernet Training. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4–8 May 2021. [Google Scholar]
- Liu, Z.; Li, D.; Lu, K.; Qin, Z.; Sun, W.; Xu, J.; Zhong, Y. Neural architecture search on efficient transformers and beyond. arXiv 2022, arXiv:2207.13955. [Google Scholar]
- Wu, B.; Li, C.; Zhang, H.; Dai, X.; Zhang, P.; Yu, M.; Wang, J.; Lin, Y.; Vajda, P. Fbnetv5: Neural architecture search for multiple tasks in one run. arXiv 2021, arXiv:2111.10007. [Google Scholar]
- Ni, B.; Meng, G.; Xiang, S.; Pan, C. NASformer: Neural Architecture Search for Vision Transformer. In Asian Conference on Pattern Recognition; Springer: Cham, Switzerland, 2022; pp. 47–61. [Google Scholar]
- Chefer, H.; Gur, S.; Wolf, L. Transformer interpretability beyond attention visualization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 782–791. [Google Scholar]
- Rigotti, M.; Miksovic, C.; Giurgiu, I.; Gschwind, T.; Scotton, P. Attention-based Interpretability with Concept Transformers. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4–8 May 2021; Available online: https://openreview.net/forum?id=Qaw16njk6L (accessed on 18 April 2023).
- Sun, M.; Ma, H.; Kang, G.; Jiang, Y.; Chen, T.; Ma, X.; Wang, Z.; Wang, Y. VAQF: Fully Automatic Software-hardware Co-design Framework for Low-bit Vision Transformer. arXiv 2022, arXiv:2201.06618. [Google Scholar]
- Jamil, S.; Abbas, M.S.; Umair, M.; Hussain, Y. A review of techniques and challenges in green communication. In Proceedings of the 2020 International Conference on Information Science and Communication Technology (ICISCT), Karachi, Pakistan, 8–9 February 2020; pp. 1–6. [Google Scholar]
- Jamil, S.; Rahman, M. A Comprehensive Survey of Digital Twins and Federated Learning for Industrial Internet of Things (IIoT), Internet of Vehicles (IoV) and Internet of Drones (IoD). Appl. Syst. Innov. 2022, 5, 56. [Google Scholar] [CrossRef]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. Lora: Low-rank adaptation of large language models. arXiv 2021, arXiv:2106.09685. [Google Scholar]
- Dehghani, M.; Djolonga, J.; Mustafa, B.; Padlewski, P.; Heek, J.; Gilmer, J.; Steiner, A.; Caron, M.; Geirhos, R.; Alabdulmohsin, I.; et al. Scaling vision transformers to 22 billion parameters. arXiv 2023, arXiv:2302.05442. [Google Scholar]
- Fang, Y.; Sun, Q.; Wang, X.; Huang, T.; Wang, X.; Cao, Y. EVA-02: A Visual Representation for Neon Genesis. arXiv 2023, arXiv:2303.11331. [Google Scholar]
- Zheng, Z.; Ma, M.; Wang, K.; Qin, Z.; Yue, X.; You, Y. Preventing Zero-Shot Transfer Degradation in Continual Learning of Vision-Language Models. arXiv 2023, arXiv:2303.06628. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Survey | Year | Scope | Contributions and Limitations | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Class. | Det. | Seg. | Com. | Super Res. | Den. | AD. | |||
| [26] | 2020 |  |  | | | | | |
|
| [27] | 2022 |  | | | | | | |
|
| [28] | 2021 | | | | | | | |
|
| [30] | 2022 | | | | | | | |
|
| [31] | 2022 | | | | | | | |
|
| Our survey | 2023 | | | | | | | |
|
—fully explained; —partially explained; —not explained.| Research | Model | Dataset | Objective Classification | Accuracy |
|---|---|---|---|---|
| [32] | CrossViT-9† | ImageNet1K | Image | 77.100% |
| CrossViT-15† | 82.300% | |||
| CrossViT-18† | 82.800% | |||
| CrossViT-15 | CIFAR10 | Image | 99.000% | |
| CIFAR100 | 90.770% | |||
| Pet | Pet classification | 94.550% | ||
| Crop Diseases | Crop disease classification | 99.970% | ||
| ChestXRay8 | Chest X-ray classification | 55.890% | ||
| CrossViT-18 | CIFAR10 | Image | 99.110% | |
| CIFAR100 | 91.360% | |||
| Pet | Pet classification | 95.070% | ||
| Crop Diseases | Crop diseases | 99.970% | ||
| ChestXRay8 | Chest X-rays | 55.940% | ||
| [33] | CTNet | AID | Remote sensing scene | 97.700% |
| NWPU-RESISC45 | 95.490% | |||
| [34] | MIL-ViT | APTOS2019 | Fundus image | 97.900% |
| RFMiD2020 | 95.900% | |||
| [36] | ET-GSNet | AID | Remote sensing images | 96.880% |
| NWPU-RESISC45 | 94.500% | |||
| UCM | 99.290% | |||
| OPTIMAL-31 | 96.450% | |||
| [37] | DHViT | Trento | Hyperspectral & LiDAR | 99.580% |
| Houston 2013 | 99.550% | |||
| Houston 2018 | 96.400% | |||
| [38] | ForestViT | PUAS | Satellite imagery multilabel | 94.280% |
| [39] | LeViT | Chinese asphalt pavement | Pavement image | 91.560% |
| German asphalt pavement | 99.170% | |||
| [40] | ViT | Malicious drone | Malicious drones | 98.300% |
| [46] | ViT | Real X Rays | Femur fracture | 83.000% |
| [47] | SeedViT | Maize seeds | Maize seed quality | 96.700% |
| [48] | DOViT | GAOs-1 | Air quality | 90.320% |
| GAOs-2 | 92.780% | |||
| [49] | MITformer | UCM | Remote sensing scene | 99.830% |
| AID | 97.960% | |||
| NWPU | 95.930% |
| Research | Model | Dataset | Objective | Perf. Metric | Value |
|---|---|---|---|---|---|
| [53] | YOLOS | COCO | Object detection | 42.000 | |
| [57] | ViT | Satellite images | Manipulation detection | F1-score | 0.354 |
| JI | 0.275 | ||||
| [58] | BrT | ScanNet-V2 | 3D object detection | mAP@0.5 | 55.200 |
| SUN RGB-D | 48.100 | ||||
| [61] | ViT | ScanNet-V2 | 3D object detection | mAP@0.5 | 52.800 |
| SUN RGB-D | 45.200 |
| Research | Model | Dataset | Objective | Performance Metric | Value |
|---|---|---|---|---|---|
| [65] | TransUNet | MICCAI 2015 | Medical image segmentation | Dice score | 77.480% |
| [66] | ViTBIS | MICCAI 2015 | Medical image segmentation | Dice score | 80.450% |
| HD | 21.240% | ||||
| [68] | LAVT | RefCOCO | Image segmentation | IoU | 72.730% |
| RefCOCO+ | 62.140% | ||||
| G-Ref (UMD partition) | 61.240% | ||||
| G-Ref (Google partition) | 60.500% | ||||
| [80] | UNetFormer | MSD | Liver segmentation | Dice score | 96.030% |
| HD | 7.210% | ||||
| Tumor segmentation | Dice score | 59.160% | |||
| HD | 8.490% | ||||
| BraTS 2021 | Brain tumor segmentation | Dice score | 91.540% |
| Research | Model | Dataset | Objective | Perf. Metric | Value |
|---|---|---|---|---|---|
| [116] | VT-ADL | MNIST | Anomaly detection | PRO | 0.984 |
| MVTec | 0.807 | ||||
| BTAD | 0.890 | ||||
| [118] | AnoViT | MNIST | Anomaly detection | AUROC | 92.400% |
| CIFAR | 60.100% | ||||
| MVTec | 78.000% | ||||
| [119] | TransAnomaly | Pred1 | Anomaly detection | AUC | 84.000% |
| Pred2 | 96.100% | ||||
| Avenue | 85.800% | ||||
| TransAnomaly | Pred1 | 86.700% | |||
| Pred2 | 96.400% | ||||
| Avenue | 87.000% |
| Research | Year | Model Name | CV Application | Source Code |
|---|---|---|---|---|
| [1] | 2021 | PiT |
| https://github.com/naver-ai/pit (accessed on 19 April 2023) |
| [16] | 2020 | ViT |
| https://github.com/google-research/vision_transformer (accessed on 19 April 2023) |
| [19] | 2021 | Swin Transformer |
| https://github.com/microsoft/Swin-Transformer (accessed on 19 April 2023) |
| [32] | 2021 | Cross-ViT |
| https://github.com/IBM/CrossViT (accessed on 19 April 2023) |
| [122] | 2021 | CeiT |
| https://github.com/rishikksh20/CeiT-pytorch (accessed on 19 April 2023) |
| [128] | 2022 | Swin Transformer V2 |
| https://github.com/microsoft/Swin-Transformer (accessed on 19 April 2023) |
| [129] | 2021 | DVT |
| https://github.com/blackfeather-wang/Dynamic-Vision-Transformer (accessed on 19 April 2023) |
| [130] | 2021 | PVT |
| https://github.com/whai362/PVT (accessed on 19 April 2023) |
| [131] | 2021 | Twins |
| https://github.com/Meituan-AutoML/Twins (accessed on 19 April 2023) |
| [132] | 2021 | Mobile-ViT |
| https://github.com/apple/ml-cvnets (accessed on 19 April 2023) |
| [133] | 2021 | Refiner |
| https://github.com/zhoudaquan/Refiner_ViT (accessed on 19 April 2023) |
| [134] | 2021 | DeepViT |
| https://github.com/zhoudaquan/dvit_repo (accessed on 19 April 2023) |
| [135] | 2021 | DeiT |
| https://github.com/facebookresearch/deit (accessed on 19 April 2023) |
| [136] | 2021 | Visformer |
| https://github.com/danczs/Visformer (accessed on 19 April 2023) |
| Ref. | Model | Dataset | Objective | Perf. Metric | Value |
|---|---|---|---|---|---|
| [142] | TransVisDrone |
| Drone detection | AP@0.5IoU |
|
| [146] |
| Date palm trees | Segmentation | mIoU |
|
| [146] |
| Date palm trees | Segmentation | mF-Score |
|
| [146] |
| Date palm trees | Segmentation | mAcc |
|
| [150] | TPH-YOLOv5 | VisDrone2021 | Object detection | mAP |
|
| [151] |
| VisDrone-DET2021 | Object detection | AP |
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jamil, S.; Jalil Piran, M.; Kwon, O.-J. A Comprehensive Survey of Transformers for Computer Vision. Drones 2023, 7, 287. https://doi.org/10.3390/drones7050287
Jamil S, Jalil Piran M, Kwon O-J. A Comprehensive Survey of Transformers for Computer Vision. Drones. 2023; 7(5):287. https://doi.org/10.3390/drones7050287
Chicago/Turabian StyleJamil, Sonain, Md. Jalil Piran, and Oh-Jin Kwon. 2023. "A Comprehensive Survey of Transformers for Computer Vision" Drones 7, no. 5: 287. https://doi.org/10.3390/drones7050287
APA StyleJamil, S., Jalil Piran, M., & Kwon, O.-J. (2023). A Comprehensive Survey of Transformers for Computer Vision. Drones, 7(5), 287. https://doi.org/10.3390/drones7050287