

Three-Dimensional Trajectory and Resource Allocation Optimization in Multi-Unmanned Aerial Vehicle Multicast System: A Multi-Agent Reinforcement Learning Method

Abstract
:1. Introduction
- On-demand deployment: While conventional terrestrial base stations are fixed and immovable, UAVs are able to be deployed more flexibly and on-demand in accordance with GUs’ locations.
- Better communication quality: Instead of more obstacle blocking between GBSs and GUs, the air-to-ground link is dominated more by the LoS link.
- Mobility over time: UAVs have the capacity to move over time, adjusting their positions to satisfy the demands of GUs and enhance communication performance.
- Trajectory design complexity: Since UAVs can move in multiple dimensions and need to be positioned to meet the needs of GUs; optimal deployment and trajectory design strategies need to be addressed.
- Energy limitation: How to optimize the performance with the restricted energy needs to be taken into account because UAVs consume energy both during their flight and communication.
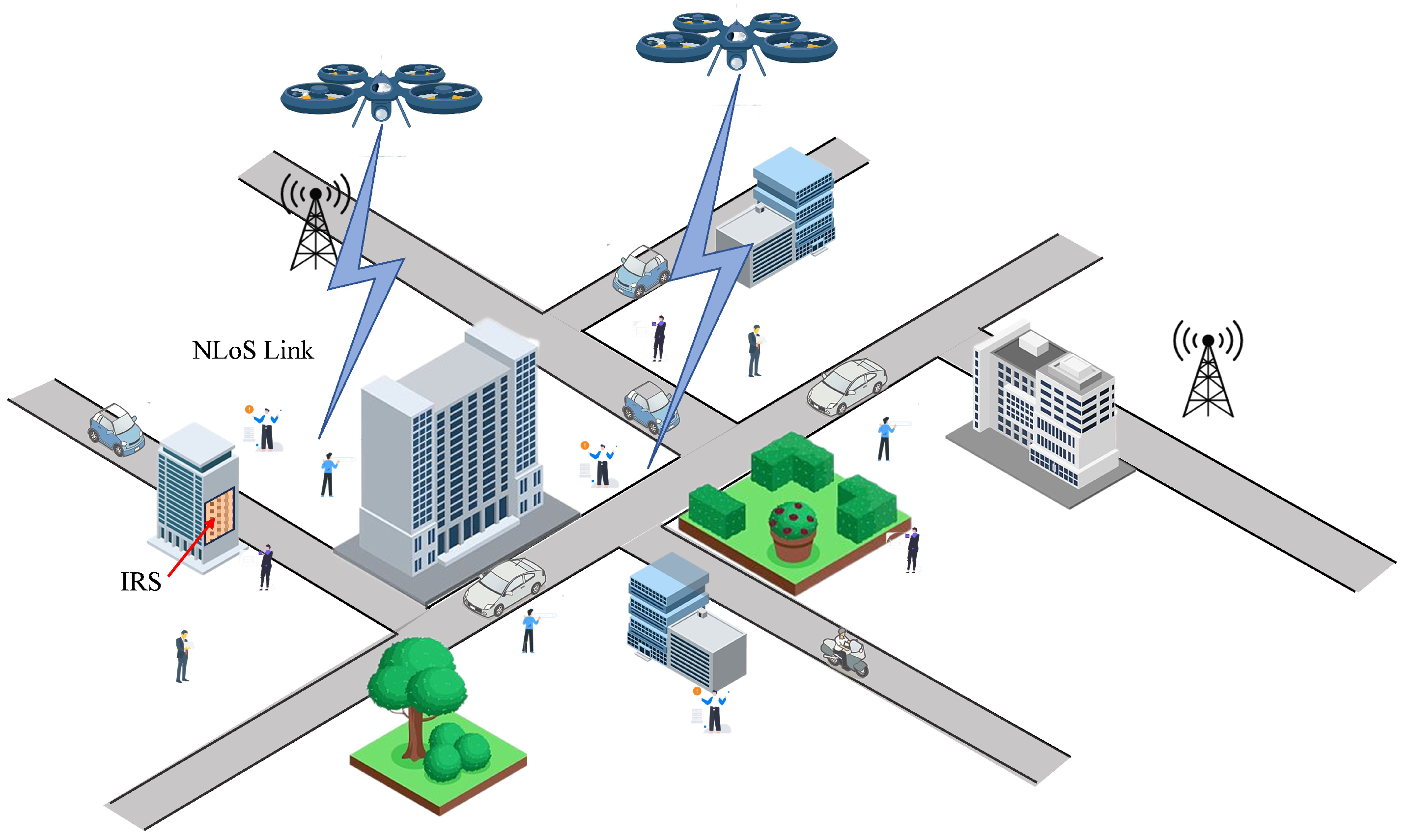
- Signal blocking: In practical applications, the air-to-ground link is more likely to be blocked by territorial obstacles when UAVs fly at low altitudes in complicated environments.
- We propose a multi-UAV multicast system assisted by IRSs in which we formulate the multicast grouping problem and an optimization problem aiming to minimize the UAVs’ energy consumption.
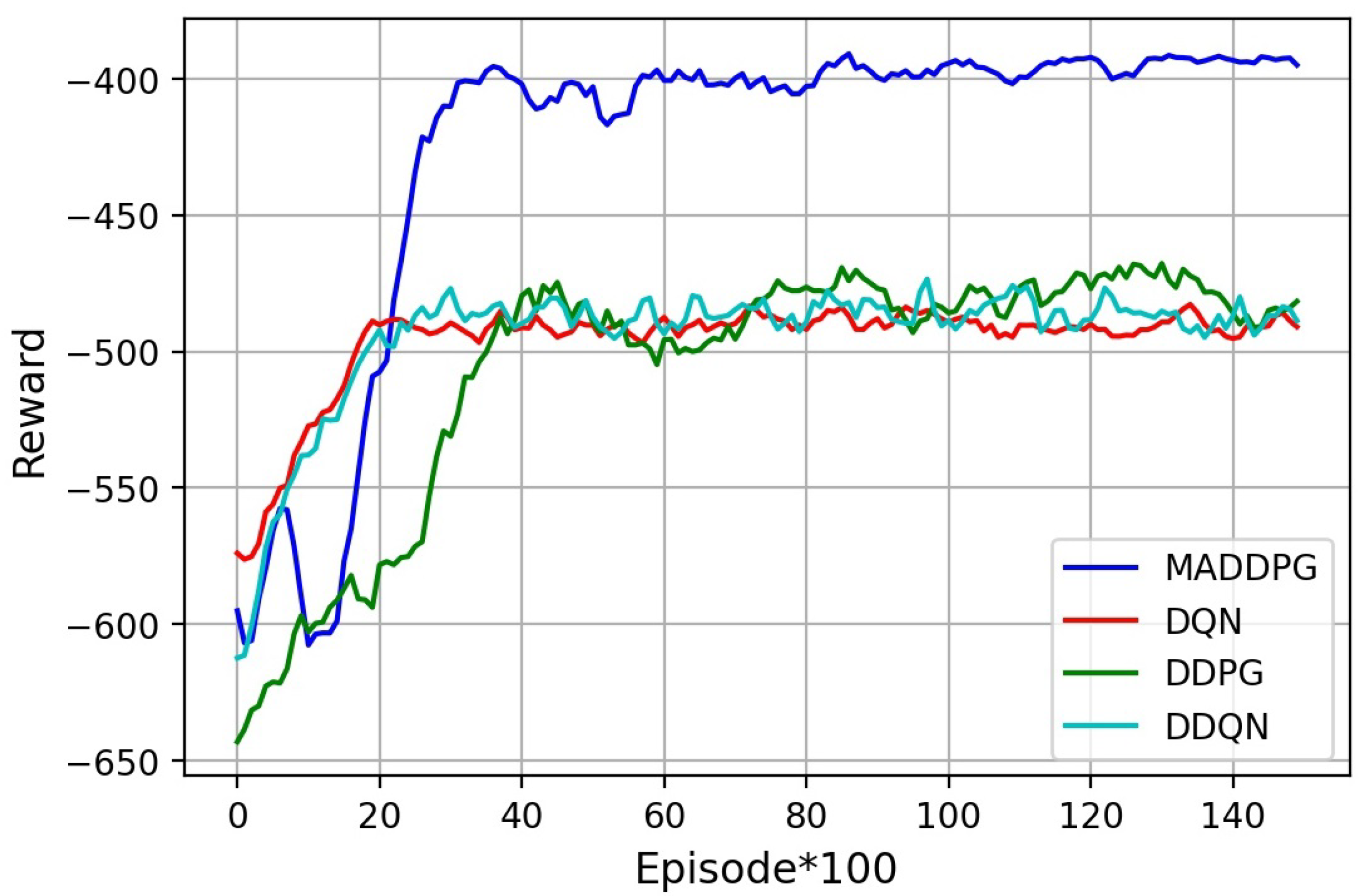
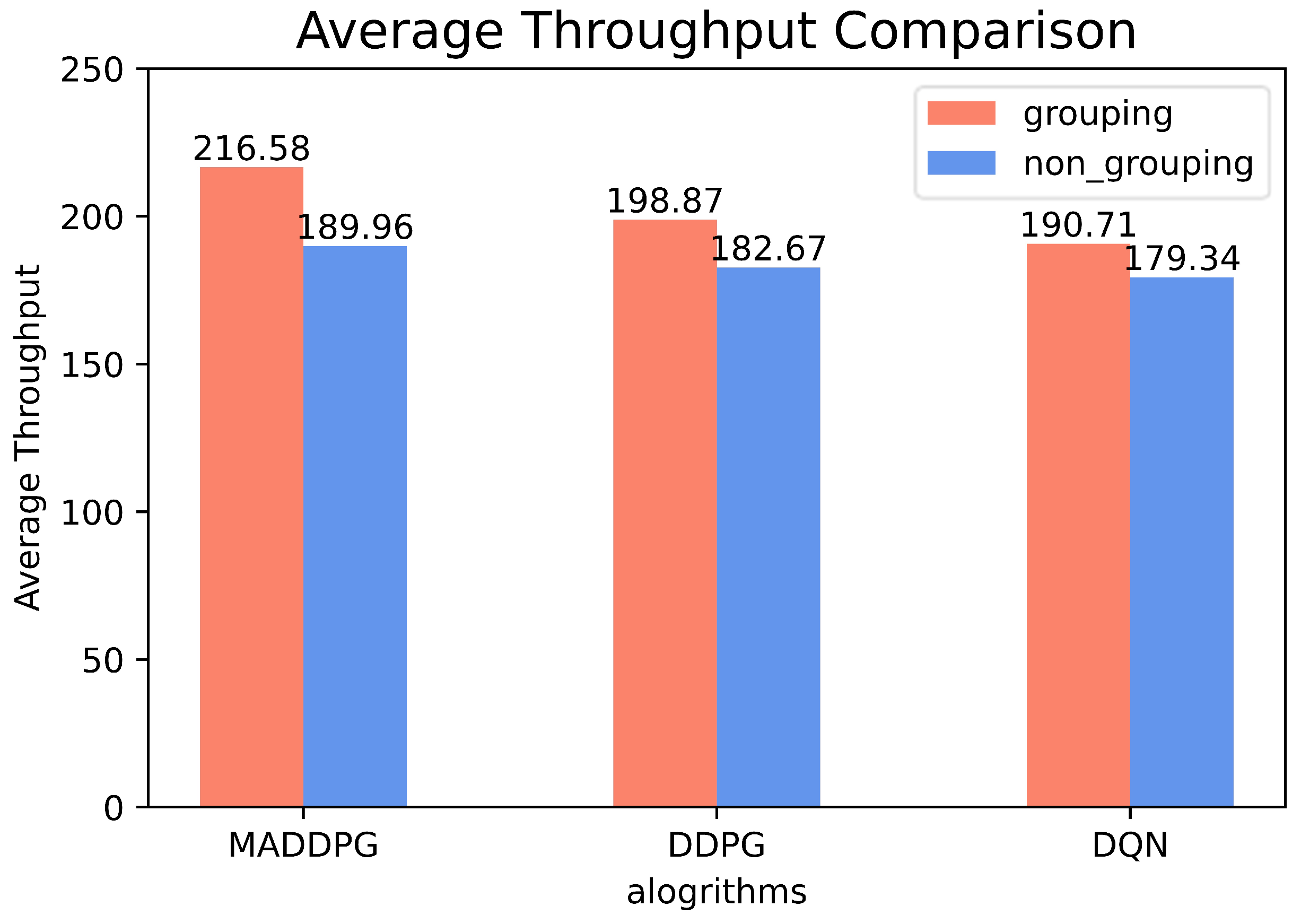
- The performance can be evaluated by the provided simulation results. We verify that the proposed system can improve the average throughput, and the MADDPG algorithm can reduce the energy consumption of UAVs effectively compared to traditional DRL methods.
2. Related Works
3. System Model
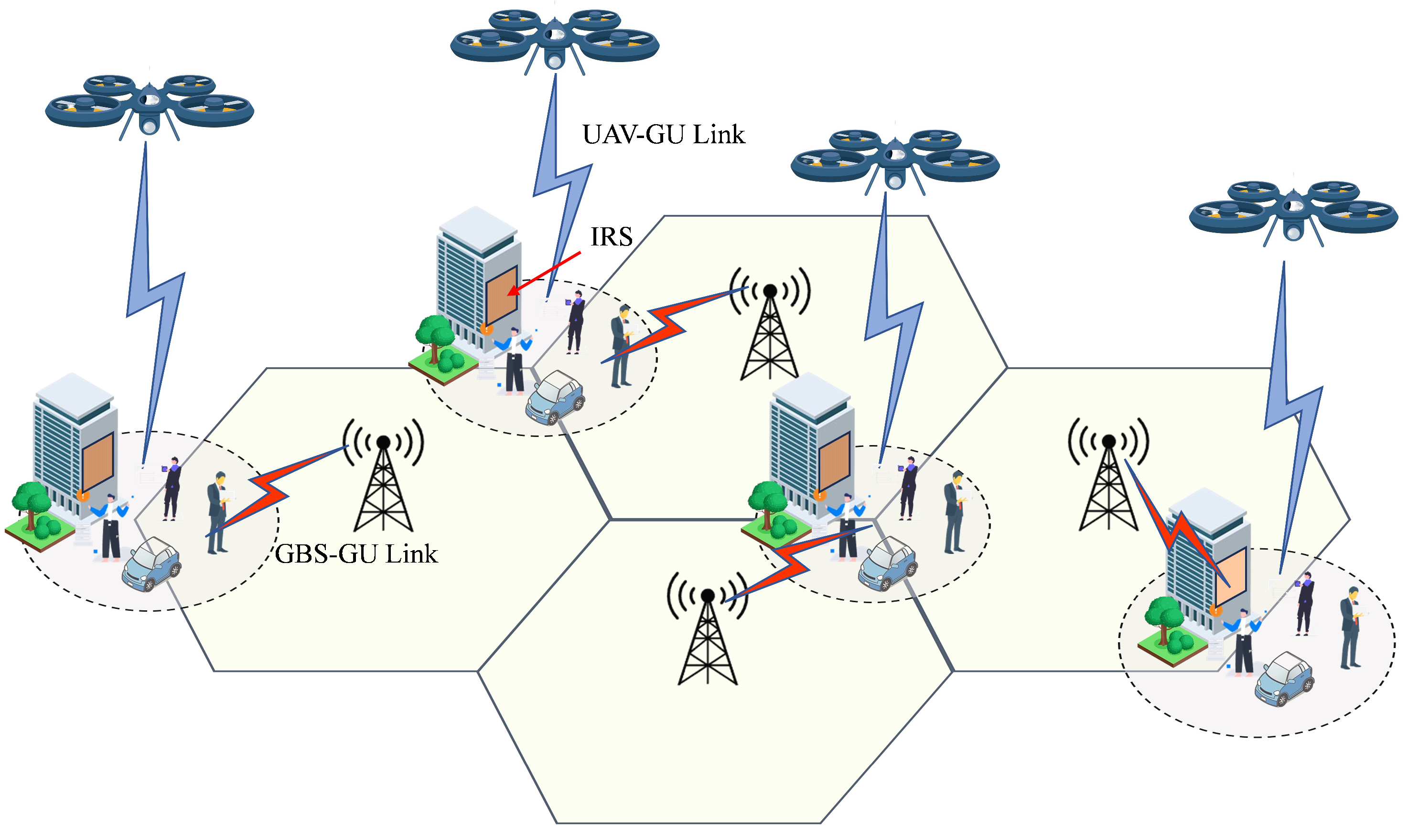
3.1. System Model
3.2. Transmission Model
3.2.1. GBS-GU Link
3.2.2. GBS-GU Link Outage Probability
3.2.3. UAV-GU Link
- (1)
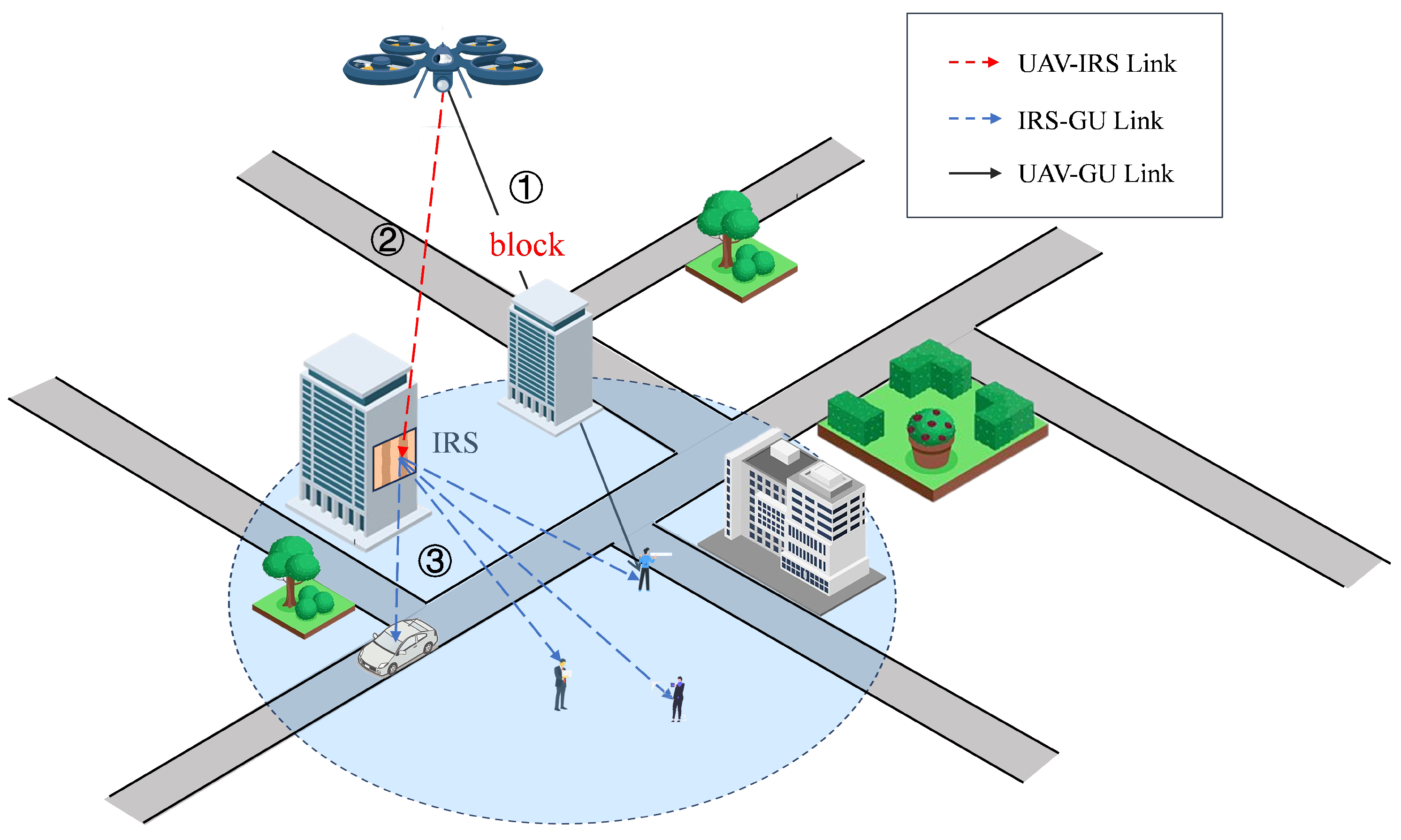
- UAV-IRS link
- (2)
- IRS-GU link
- (3)
- IRS-Assisted UAV-GU link
4. Problem Formulation
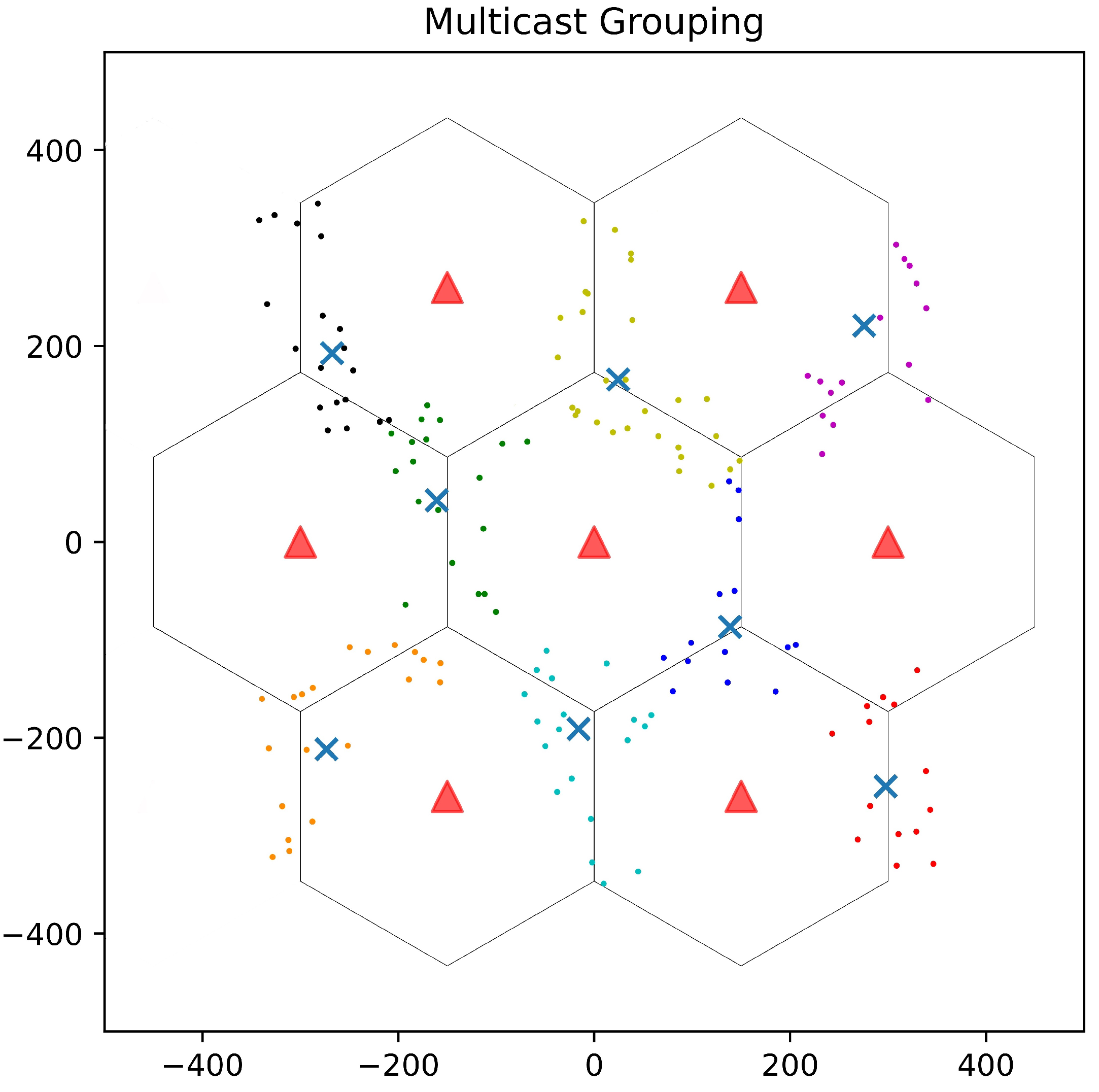
4.1. Multicast Grouping
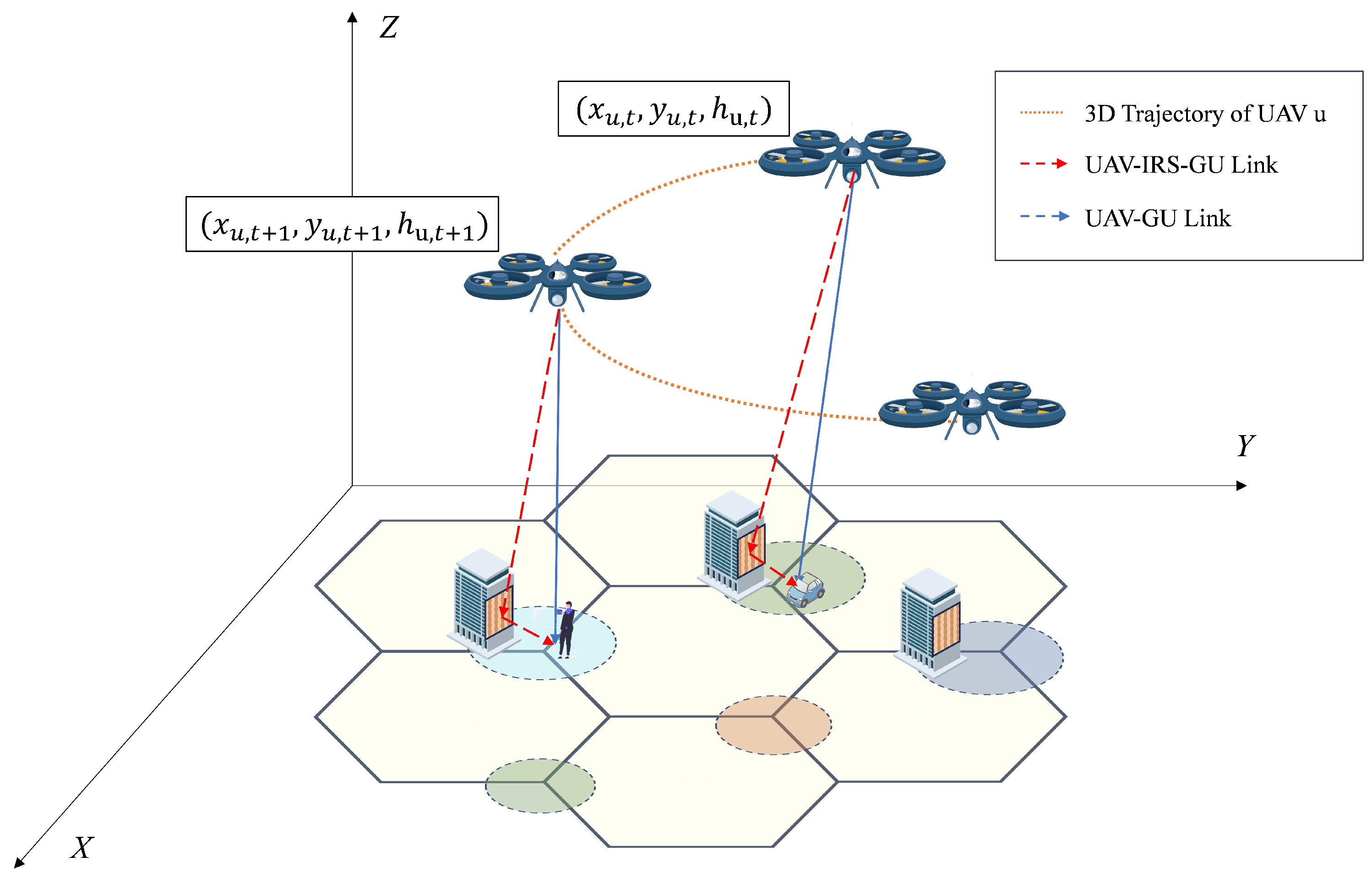
4.2. Trajectory Optimization and Resource Allocation
4.2.1. UAV Energy Consumption
4.2.2. Joint Trajectory Optimization and Power Allocation Problem
5. Proposed Solution
5.1. K-Medoids for Multicast Grouping
| Algorithm 1 Constrained K-medoids |
|
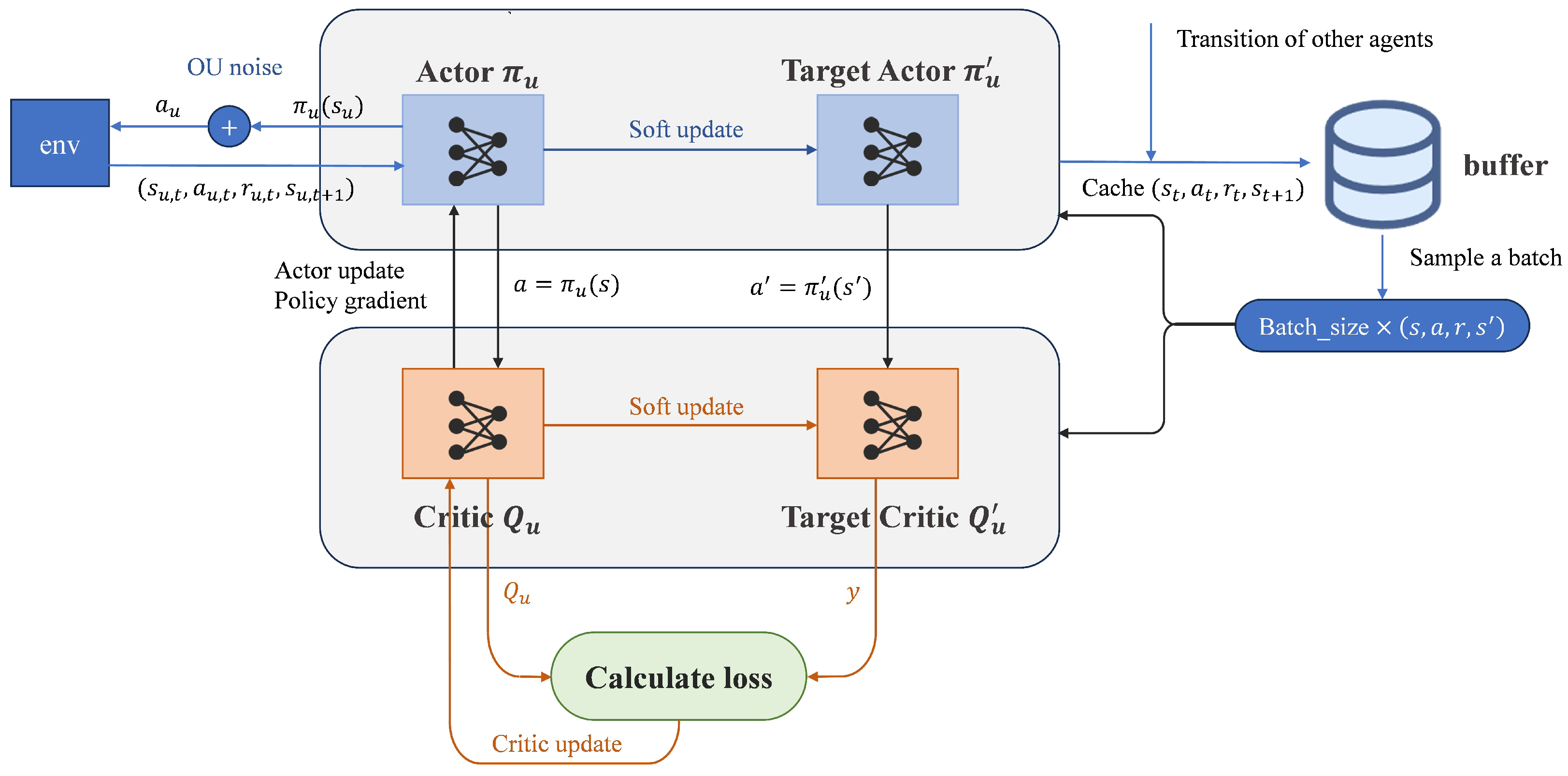
5.2. MADDPG for Optimization Problem
5.2.1. State, Action, and Reward
- (1)
- State
- (2)
- Action
- (3)
- Reward
5.2.2. MADDPG Algorithm
| Algorithm 2 MADDPG for Optimization Problem |
|
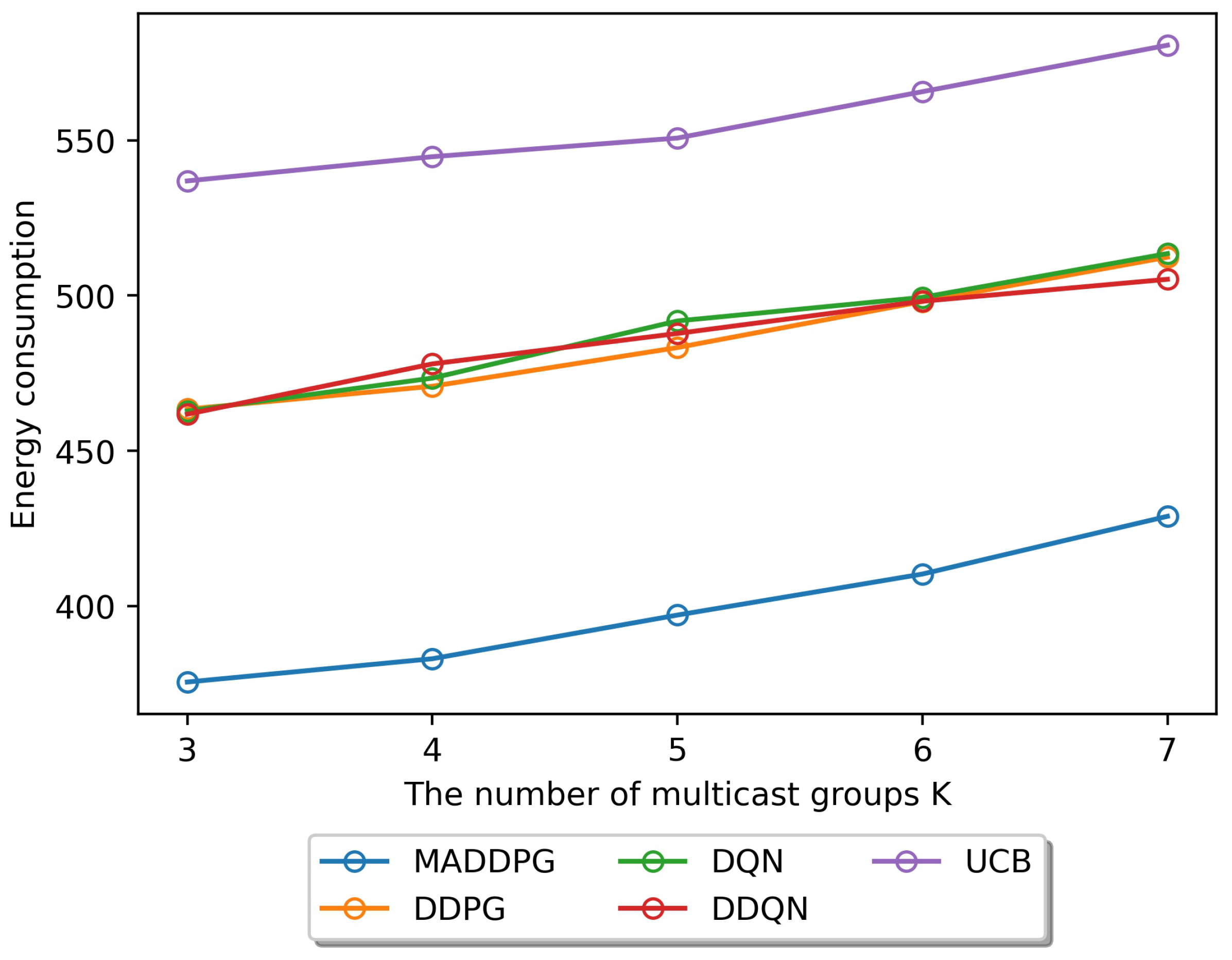
6. Simulation Results
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| DDQN | Double Deep Q-Network |
| DDPG | Deep Deterministic Policy Gradient |
| DQN | Deep Q-Network |
| MADDPG | Multi-Agent Deep Deterministic Policy Gradient |
References
- Abubakar, A.I.; Ahmad, I.; Omeke, K.G.; Ozturk, M.; Ozturk, C.; Abdel-Salam, A.M.; Mollel, M.S.; Abbasi, Q.H.; Hussain, S.; Imran, M.A. A Survey on Energy Optimization Techniques in UAV-Based Cellular Networks: From Conventional to Machine Learning Approaches. Drones 2023, 7, 214. [Google Scholar] [CrossRef]
- Wu, Y.; Xu, J.; Qiu, L.; Zhang, R. Capacity of UAV-Enabled Multicast Channel: Joint Trajectory Design and Power Allocation. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018; pp. 1–7. [Google Scholar] [CrossRef]
- Al-Hourani, A.; Kandeepan, S.; Lardner, S. Optimal LAP Altitude for Maximum Coverage. IEEE Wirel. Commun. Lett. 2014, 3, 569–572. [Google Scholar] [CrossRef]
- Bradley, P.S.; Bennett, K.P.; Demiriz, A. Constrained k-means clustering. Microsoft Res. 2000, 20, 8. Available online: https://www.microsoft.com/en-us/research/publication/constrained-k-means-clustering/ (accessed on 1 August 2023).
- Khamidehi, B.; Sousa, E.S. Trajectory Design for the Aerial Base Stations to Improve Cellular Network Performance. IEEE Trans. Veh. Technol. 2021, 70, 945–956. [Google Scholar] [CrossRef]
- Lowe, R.; Wu, Y.; Tamar, A.; Harb, J.; Abbeel, P.; Mordatch, I. Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments. In Proceedings of the 2017 Advances in Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 6379–6390. [Google Scholar] [CrossRef]
- Hu, J.; Zhang, H.; Song, L.; Schober, R.; Poor, H.V. Cooperative internet of UAVs: Distributed trajectory design by multi-agent deep reinforcement learning. IEEE Trans. Commun. 2020, 68, 6807–6821. [Google Scholar] [CrossRef]
- Deng, C.; Xu, W.; Lee, C.-H.; Gao, H.; Xu, W.; Feng, Z. Energy Efficient UAV-Enabled Multicast Systems: Joint Grouping and Trajectory Optimization. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Chen, B.; Liu, D.; Hanzo, L. Decentralized Trajectory and Power Control Based on Multi-Agent Deep Reinforcement Learning in UAV Networks. In Proceedings of the 2022 IEEE International Conference on Communications (ICC), Seoul, Republic of Korea, 16–20 May 2022; pp. 3983–3988. [Google Scholar] [CrossRef]
- Lee, J.; Friderikos, V. Multiple UAVs Trajectory Optimization in Multicell Networks with Adjustable Overlapping Coverage. IEEE Internet Things J. 2023, 10, 9122–9135. [Google Scholar] [CrossRef]
- Lee, J.; Friderikos, V. Path optimization for Flying Base Stations in Multi-Cell Networks. In Proceedings of the 2020 IEEE Wireless Communications and Networking Conference (WCNC), Seoul, Republic of Korea, 25–28 May 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Mei, H.; Yang, K.; Liu, Q.; Wang, K. 3D-Trajectory and Phase-Shift Design for RIS-Assisted UAV Systems Using Deep Reinforcement Learning. IEEE Trans. Veh. Technol. 2022, 71, 3020–3029. [Google Scholar] [CrossRef]
- Wei, Z.; Cai, Y.; Sun, Z.; Ng, D.W.K.; Yuan, J.; Zhou, M.; Sun, L. Sum-Rate Maximization for IRS-Assisted UAV OFDMA Communication Systems. IEEE Trans. Wirel. Commun. 2021, 20, 2530–2550. [Google Scholar] [CrossRef]
- Ji, Z.; Yang, W.; Guan, X.; Zhao, X.; Li, G.; Wu, Q. Trajectory and Transmit Power Optimization for IRS-Assisted UAV Communication Under Malicious Jamming. IEEE Trans. Veh. Technol. 2022, 71, 11262–11266. [Google Scholar] [CrossRef]
- Ge, Y.; Fan, J.; Zhang, J. Active Reconfigurable Intelligent Surface Enhanced Secure and Energy-Efficient Communication of Jittering UAV. IEEE Internet Things J. 2023, 20, 4962–4975. [Google Scholar] [CrossRef]
- Son, H.; Jung, M. Phase Shift Design for RIS-Assisted Satellite-Aerial-Terrestrial Integrated Network. IEEE Trans. Aerosp. Electron. Syst. 2023, 1–9. [Google Scholar] [CrossRef]
- Feng, W.; Tang, J.; Wu, Q.; Fu, Y.; Zhang, X.; So, D.K.C.; Wong, K.K. Resource Allocation for Power Minimization in RIS-assisted Multi-UAV Networks with NOMA. IEEE Trans. Commun. 2023. [Google Scholar] [CrossRef]
- Nguyen, T.L.; Kaddoum, G.; Do, T.N.; Haas, Z.J. Channel Characterization of UAV-RIS-Aided Systems with Adaptive Phase-Shift Configuration. IEEE Wirel. Commun. Lett. 2023. [Google Scholar] [CrossRef]
- Xue, Z.; Wang, J.; Ding, G.; Wu, Q. Joint 3D Location and Power Optimization for UAV-Enabled Relaying Systems. IEEE Access 2018, 6, 43113–43124. [Google Scholar] [CrossRef]
- Hosny, R.; Hashima, S.; Mohamed, E.M.; Zaki, R.M.; ElHalawany, B.M. Budgeted Bandits for Power Allocation and Trajectory Planning in UAV-NOMA Aided Networks. Drones 2023, 7, 518. [Google Scholar] [CrossRef]
- Fan, W.; Luo, K.; Yu, S.; Zhou, Z.; Chen, X. AoI-driven Fresh Situation Awareness by UAV Swarm: Collaborative DRL-based Energy-Efficient Trajectory Control and Data Processing. In Proceedings of the 2020 IEEE/CIC International Conference on Communications in China (ICCC), Chongqing, China, 9–11 August 2020; pp. 841–846. [Google Scholar] [CrossRef]
- Lyu, J.; Zeng, Y.; Zhang, Y. UAV-Aided Offloading for Cellular Hotspot. IEEE Trans. Wirel. Commun. 2018, 17, 3988–4001. [Google Scholar] [CrossRef]
- Wang, F.; Zhang, X. Active-IRS-Enabled Energy-Efficiency Optimizations for UAV-Based 6G Mobile Wireless Networks. In Proceedings of the 2023 57th Annual Conference on Information Sciences and Systems (CISS), Baltimore, MD, USA, 22–24 March 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Samir, M.; Chraiti, M.; Assi, C.; Ghrayeb, A. Joint Optimization of UAV Trajectory and Radio Resource Allocation for Drive-Thru Vehicular Networks. In Proceedings of the 2019 IEEE Wireless Communications and Networking Conference (WCNC), Marrakesh, Morocco, 15–18 April 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Wang, Y.; Hu, Z.; Wen, X.; Lu, Z.; Miao, J.; Qi, H. Three-Dimensional Aerial Cell Partitioning Based on Optimal Transport Theory. In Proceedings of the 2020 IEEE International Conference on Communications Workshops (ICC Workshops), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Mei, H.; Wang, K.; Zhou, D.; Yang, K. Joint trajectory-task-cache optimization in UAV-enabled mobile edge networks for cyber-physical system. IEEE Access 2019, 7, 156476–156488. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Number of ground users N | 100 |
| Number of UAVs K | 5 |
| Number of multicast groups k | 5 |
| Blocking parameters | 5, 0.35 |
| Bandwidth B | 2 MHz |
| UAV maximal power | 500 mW |
| Noise power | −100 dBm |
| Blade power | |
| Descending/Ascending power | 11.46 |
| , | 30, 200 |
| s, , G | 0.05, 1.225, 0.503 [26] |
| S, | 30, 20 m |
| Number of episodes | 15,000 |
| Length of an episode T | 25 |
| Batch size, Learning rate | 1024, 0.001 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, D.; Liu, Y.; Yu, H.; Hou, Y. Three-Dimensional Trajectory and Resource Allocation Optimization in Multi-Unmanned Aerial Vehicle Multicast System: A Multi-Agent Reinforcement Learning Method. Drones 2023, 7, 641. https://doi.org/10.3390/drones7100641
Wang D, Liu Y, Yu H, Hou Y. Three-Dimensional Trajectory and Resource Allocation Optimization in Multi-Unmanned Aerial Vehicle Multicast System: A Multi-Agent Reinforcement Learning Method. Drones. 2023; 7(10):641. https://doi.org/10.3390/drones7100641
Chicago/Turabian StyleWang, Dongyu, Yue Liu, Hongda Yu, and Yanzhao Hou. 2023. "Three-Dimensional Trajectory and Resource Allocation Optimization in Multi-Unmanned Aerial Vehicle Multicast System: A Multi-Agent Reinforcement Learning Method" Drones 7, no. 10: 641. https://doi.org/10.3390/drones7100641
APA StyleWang, D., Liu, Y., Yu, H., & Hou, Y. (2023). Three-Dimensional Trajectory and Resource Allocation Optimization in Multi-Unmanned Aerial Vehicle Multicast System: A Multi-Agent Reinforcement Learning Method. Drones, 7(10), 641. https://doi.org/10.3390/drones7100641