
A Novel Multi-Scale Transformer for Object Detection in Aerial Scenes


Abstract
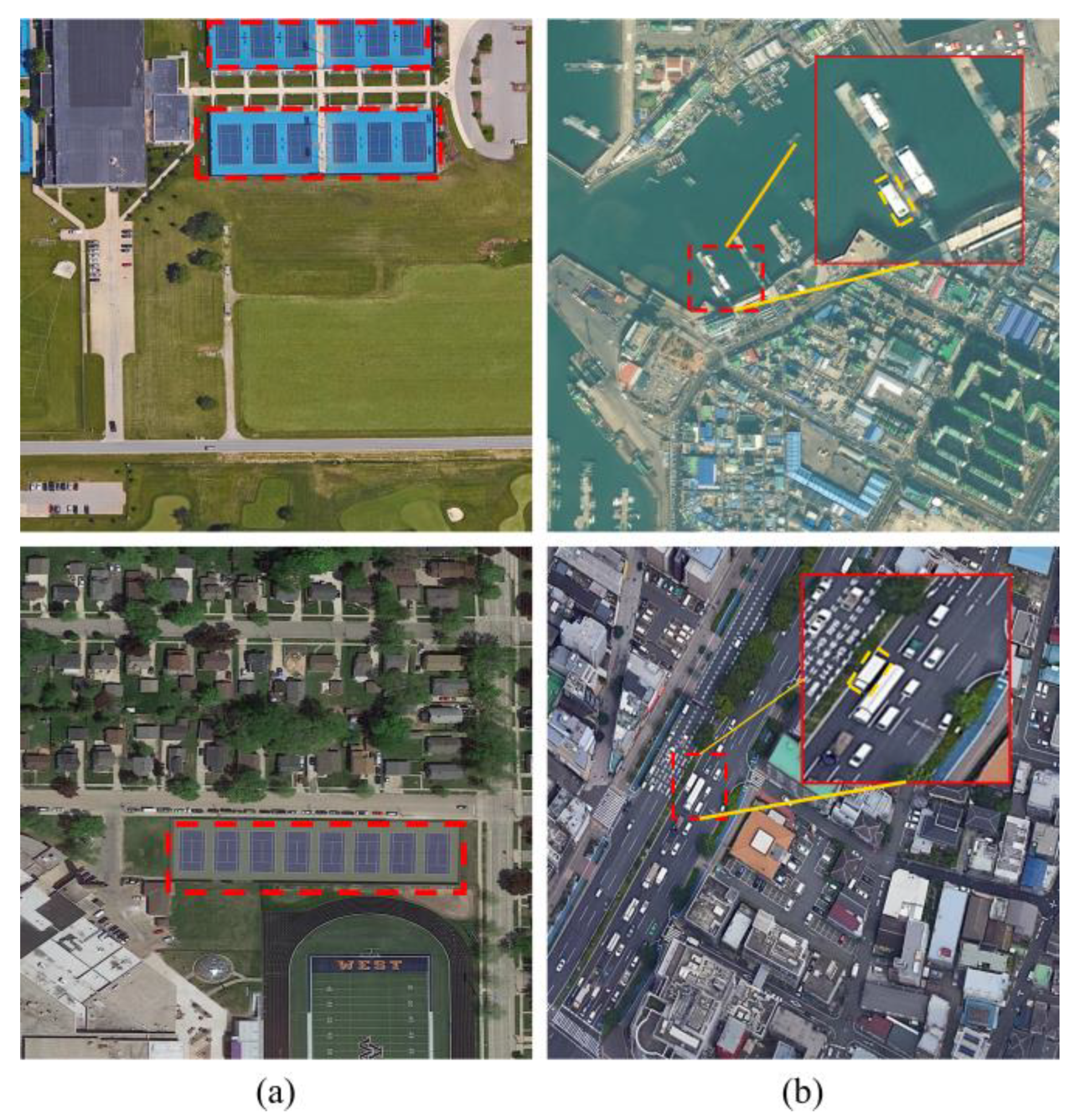
:1. Introduction
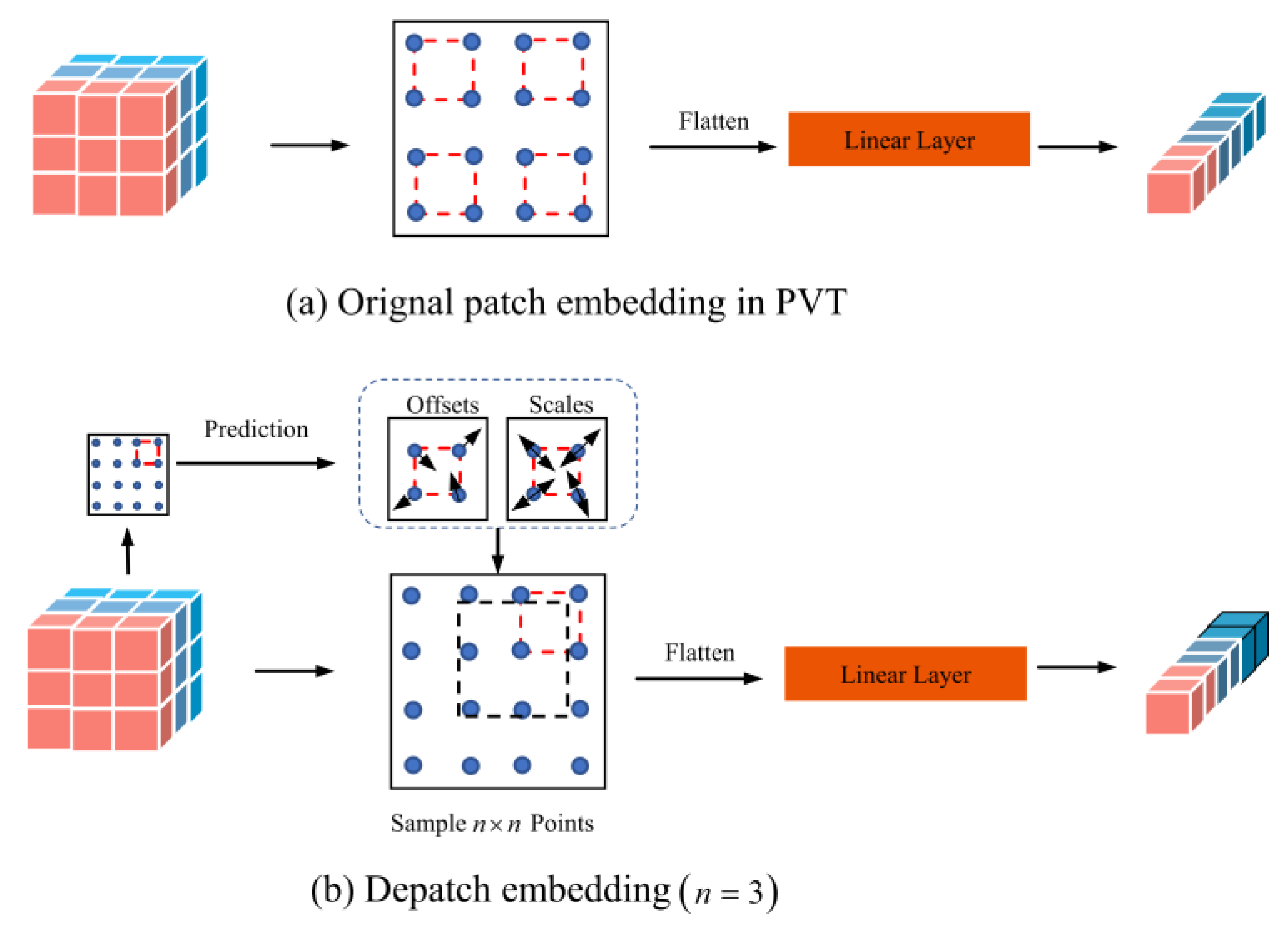
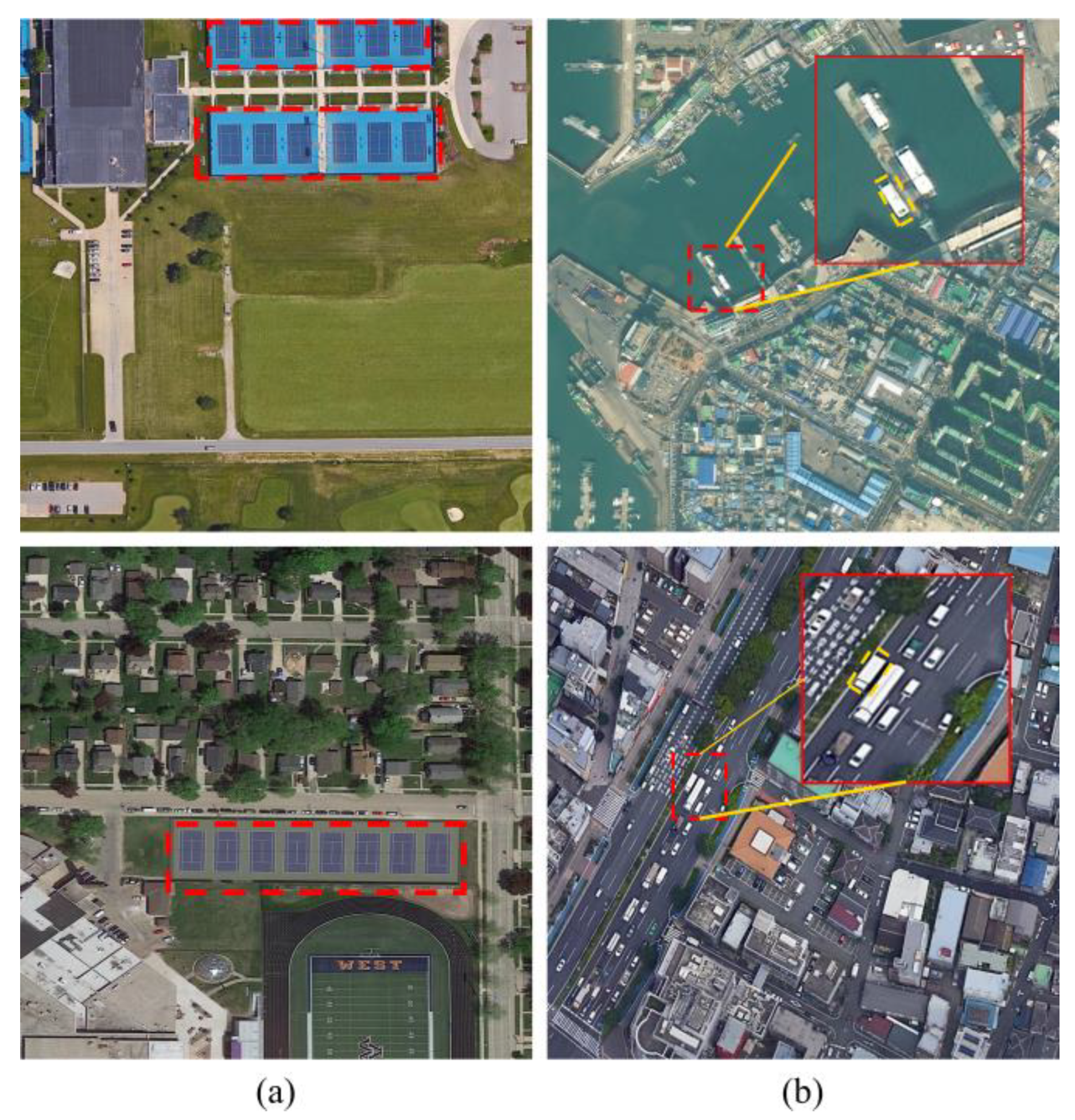
- A backbone network combining deformable patch embedding and a multi-scale visual converter is proposed to improve the ability to capture the details of multi-scale aerial targets in complex scenes.
- The cross-layer feature reconciliation guidance component enhances the semantic information of crucial features on different layers, which helps to alleviate category confusion and realize accurate classification and regression.
- The attention-based feature fusion mechanism strengthens the information integration between multi-scale and multi-semantic features and overcomes the limitation of category confusion on network accuracy.
2. Related Work
2.1. ConvNets for Object Detection
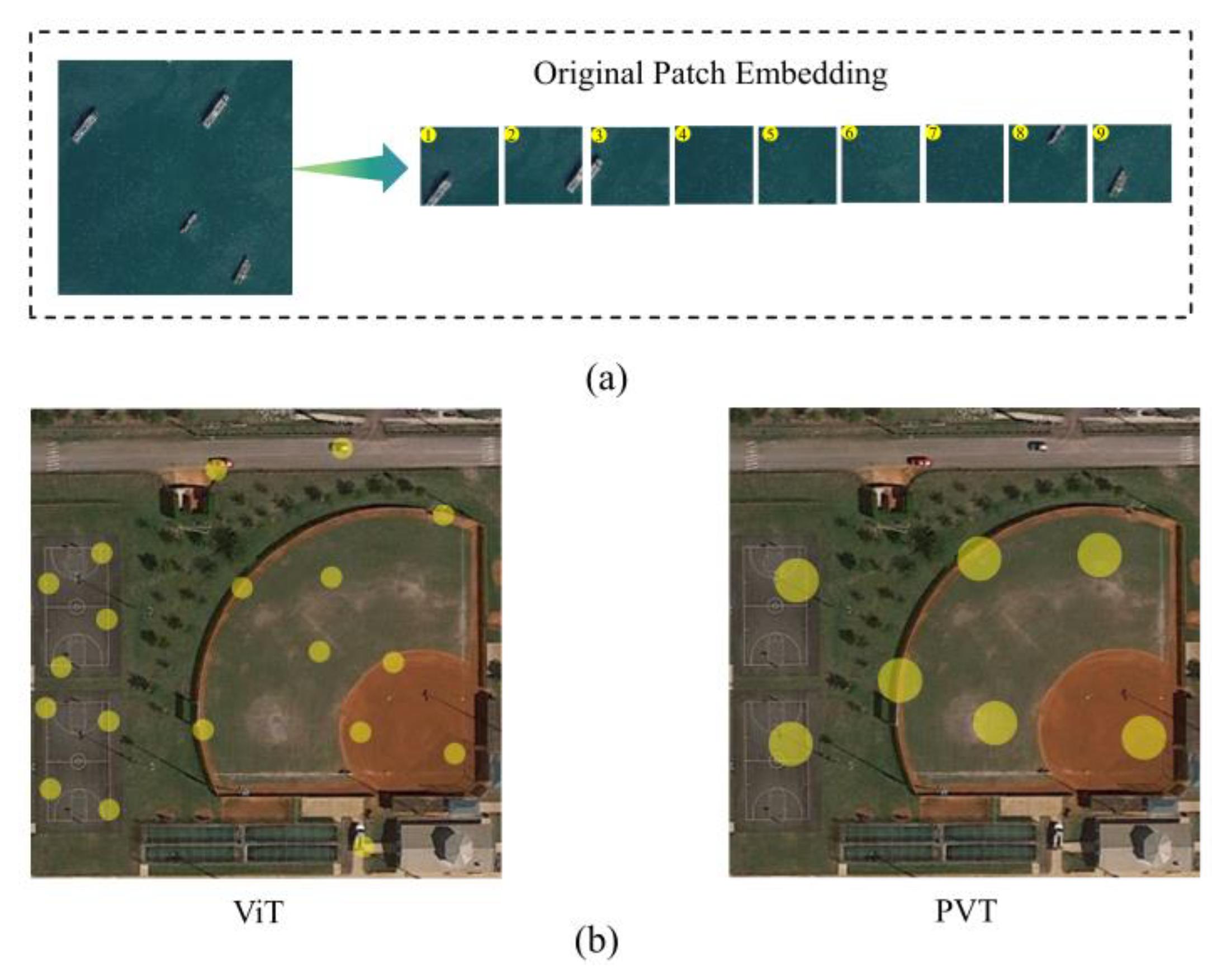
2.2. Vision Transformer for Object Detection
2.3. Aerial Object Detection
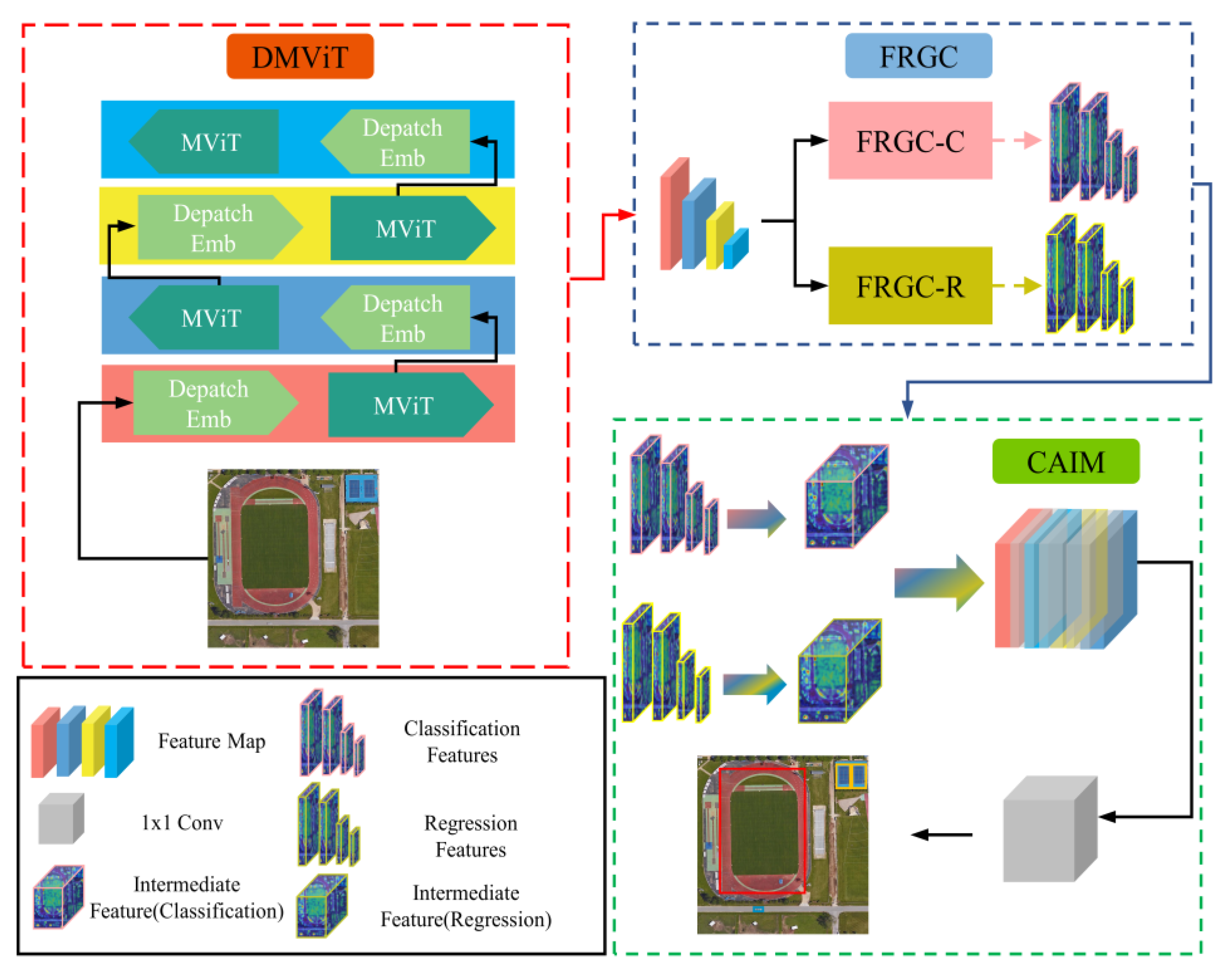
3. Methods
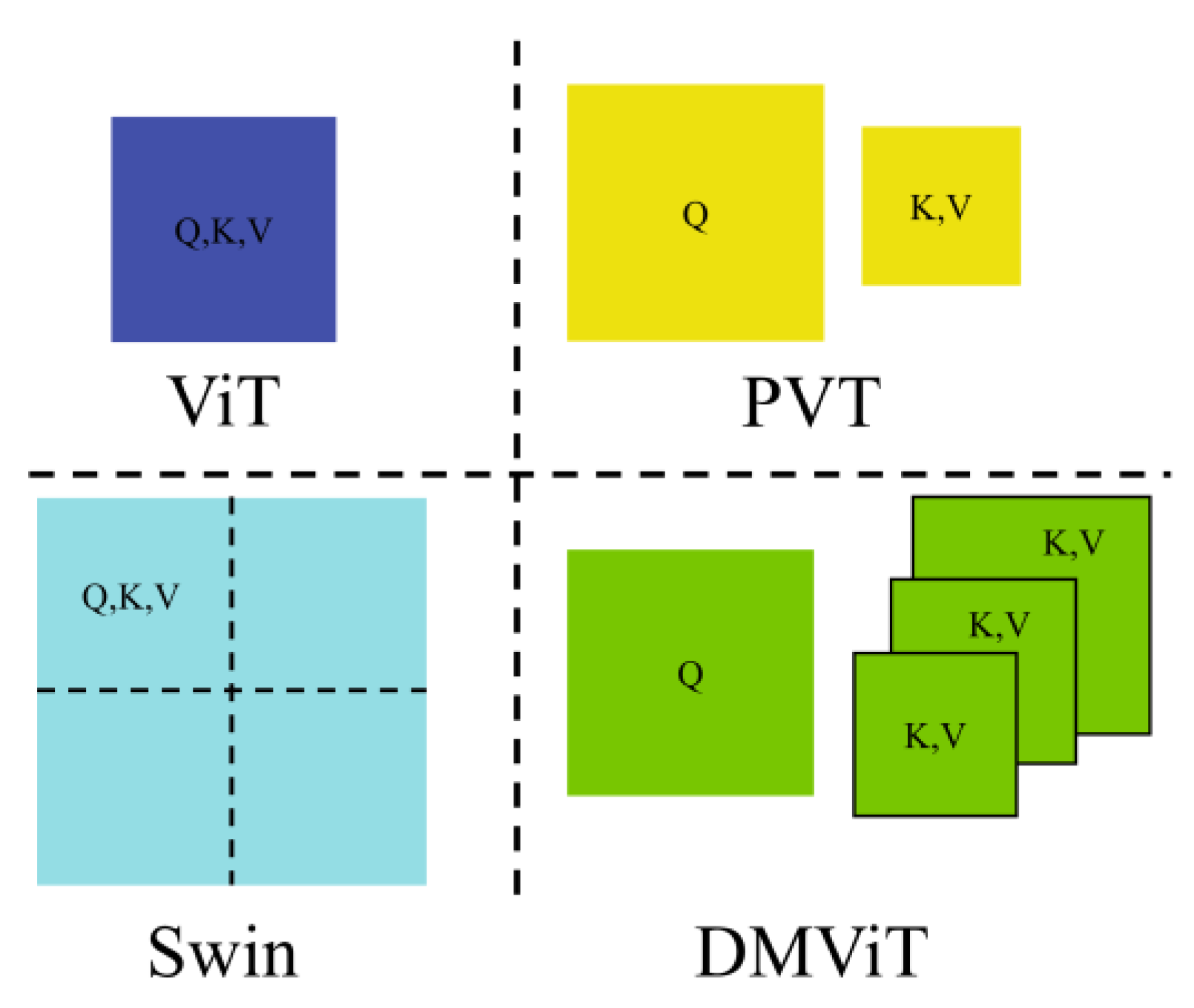
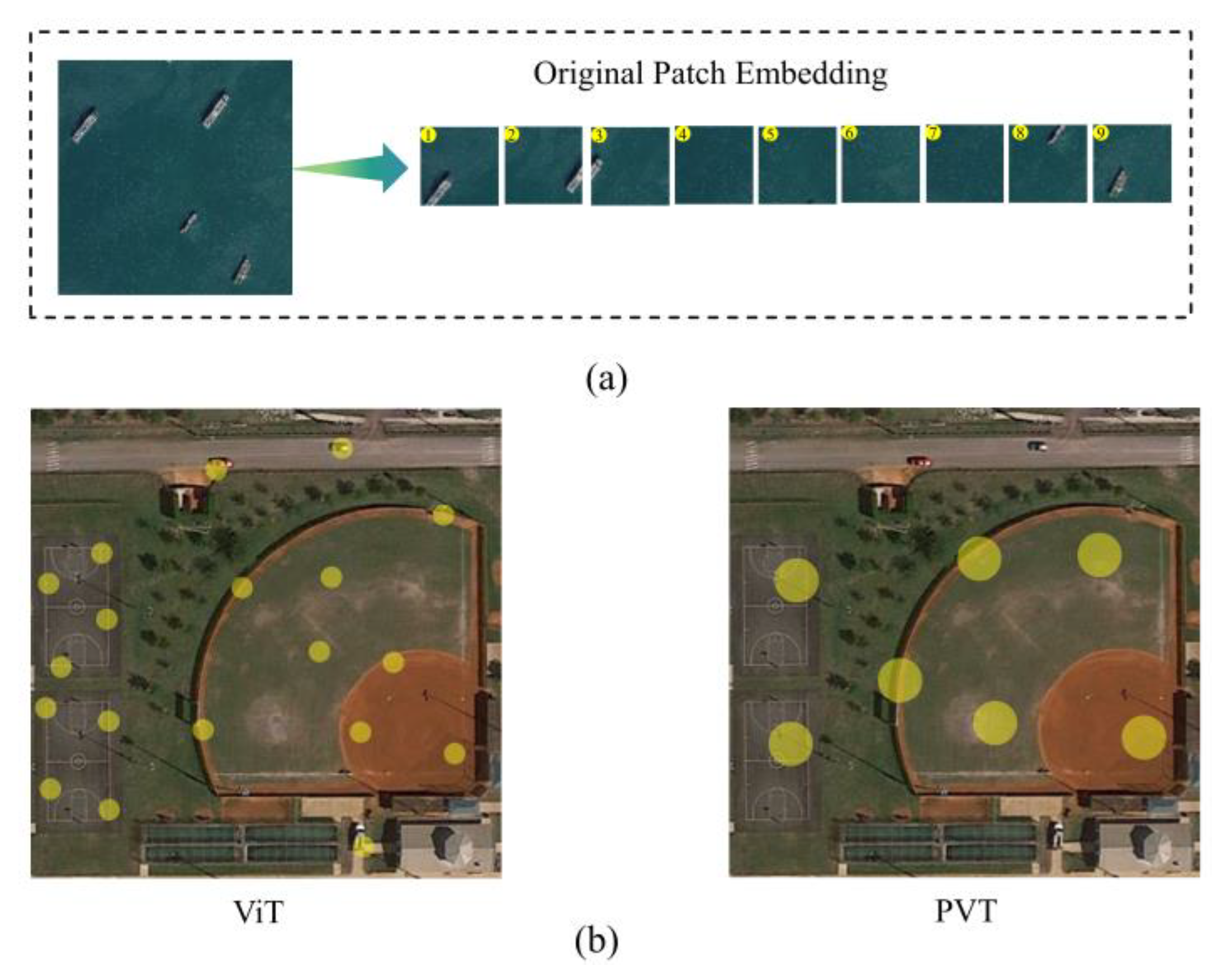
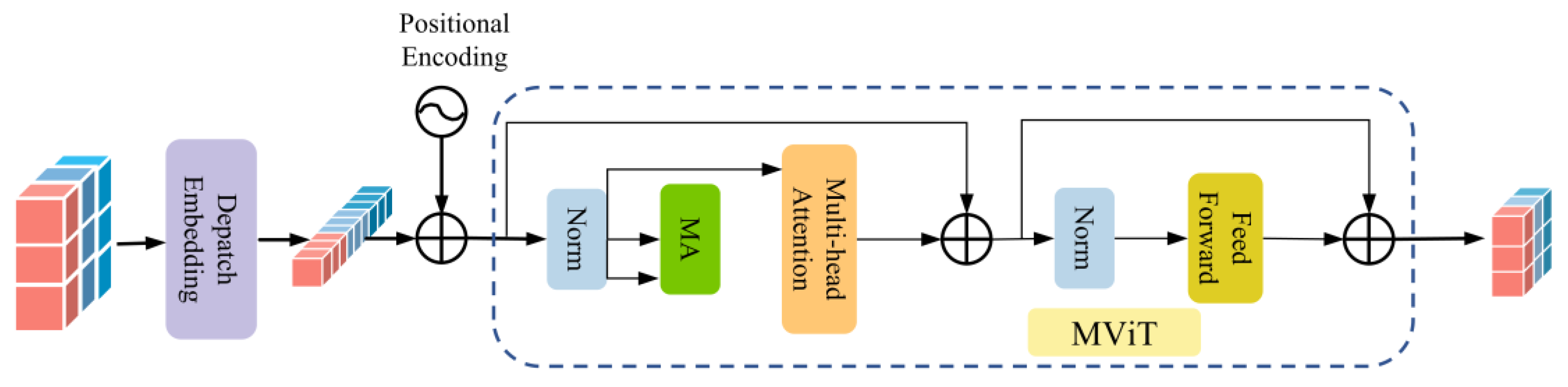
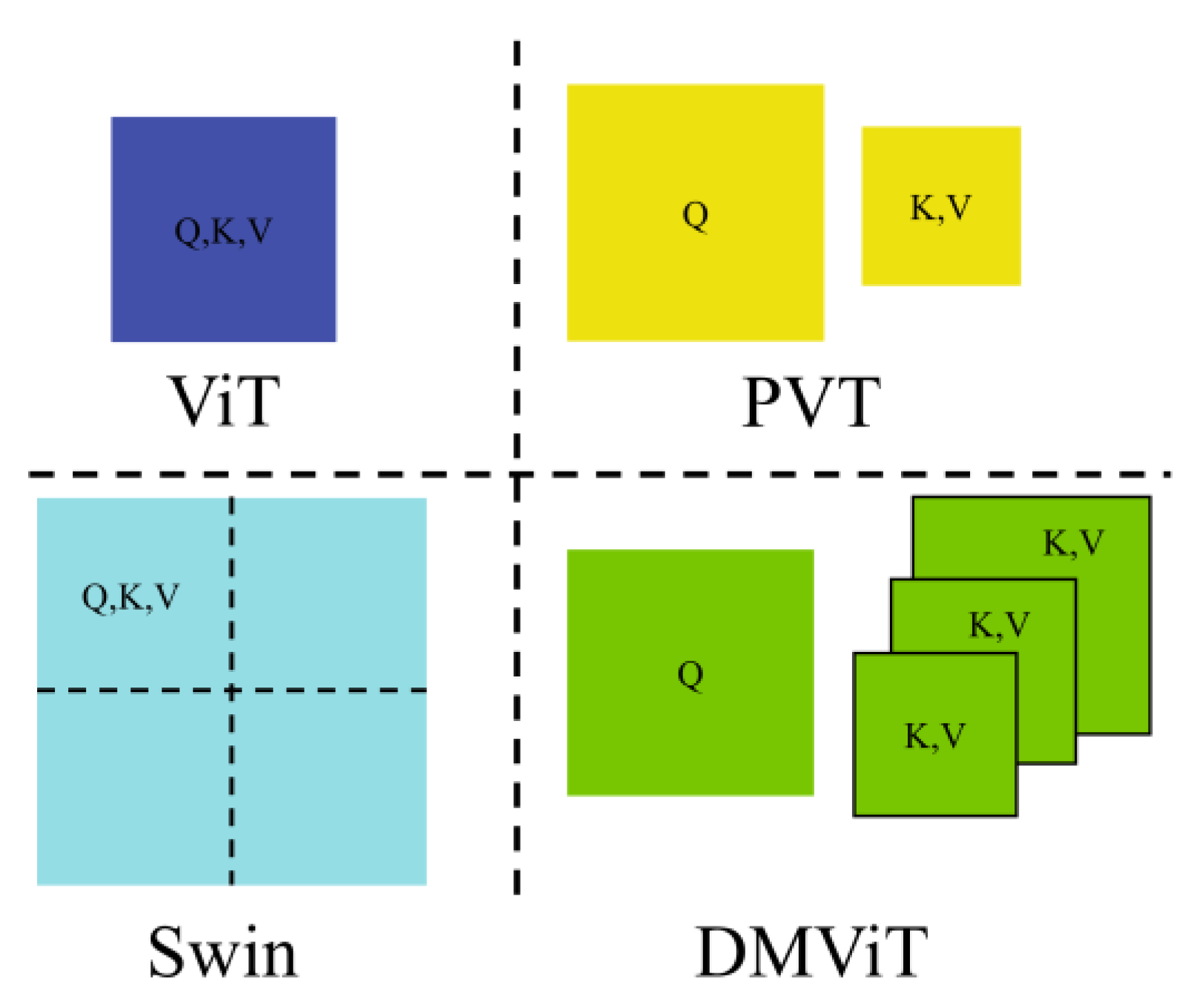
3.1. DMViT
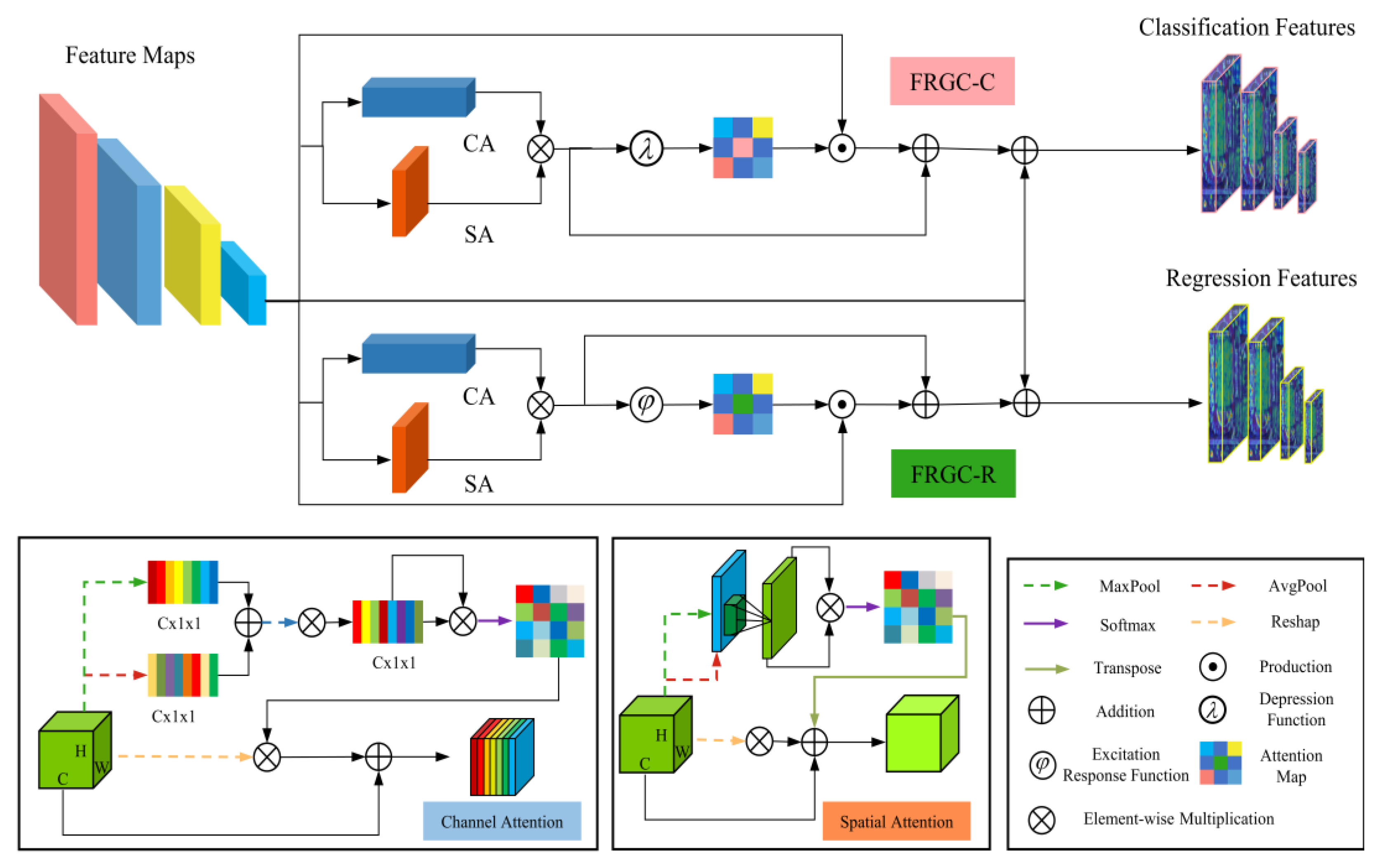
3.2. FRGC
3.3. CAIM
3.4. Network Configuration
3.5. Multi-Task Learning
4. Experiment
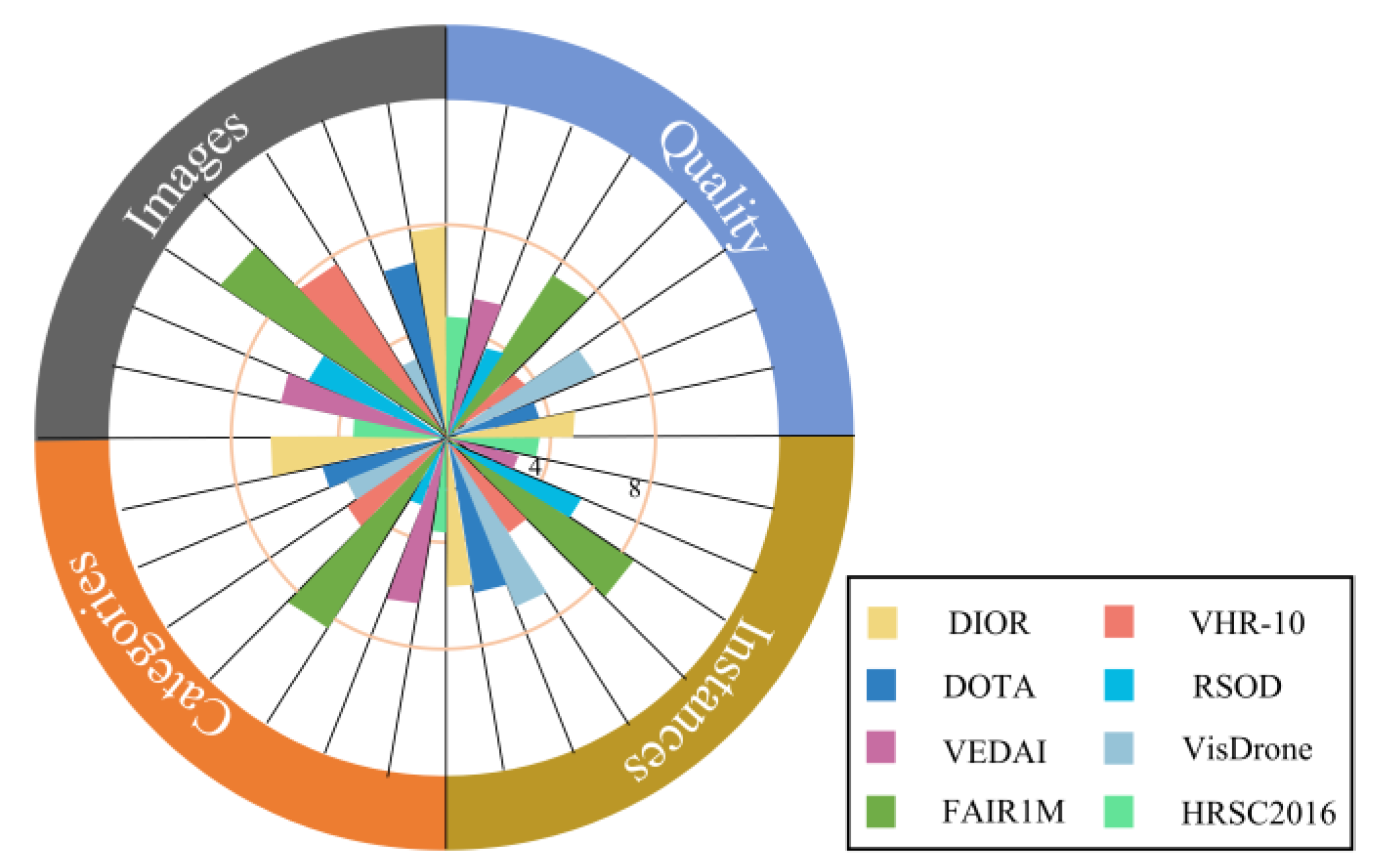
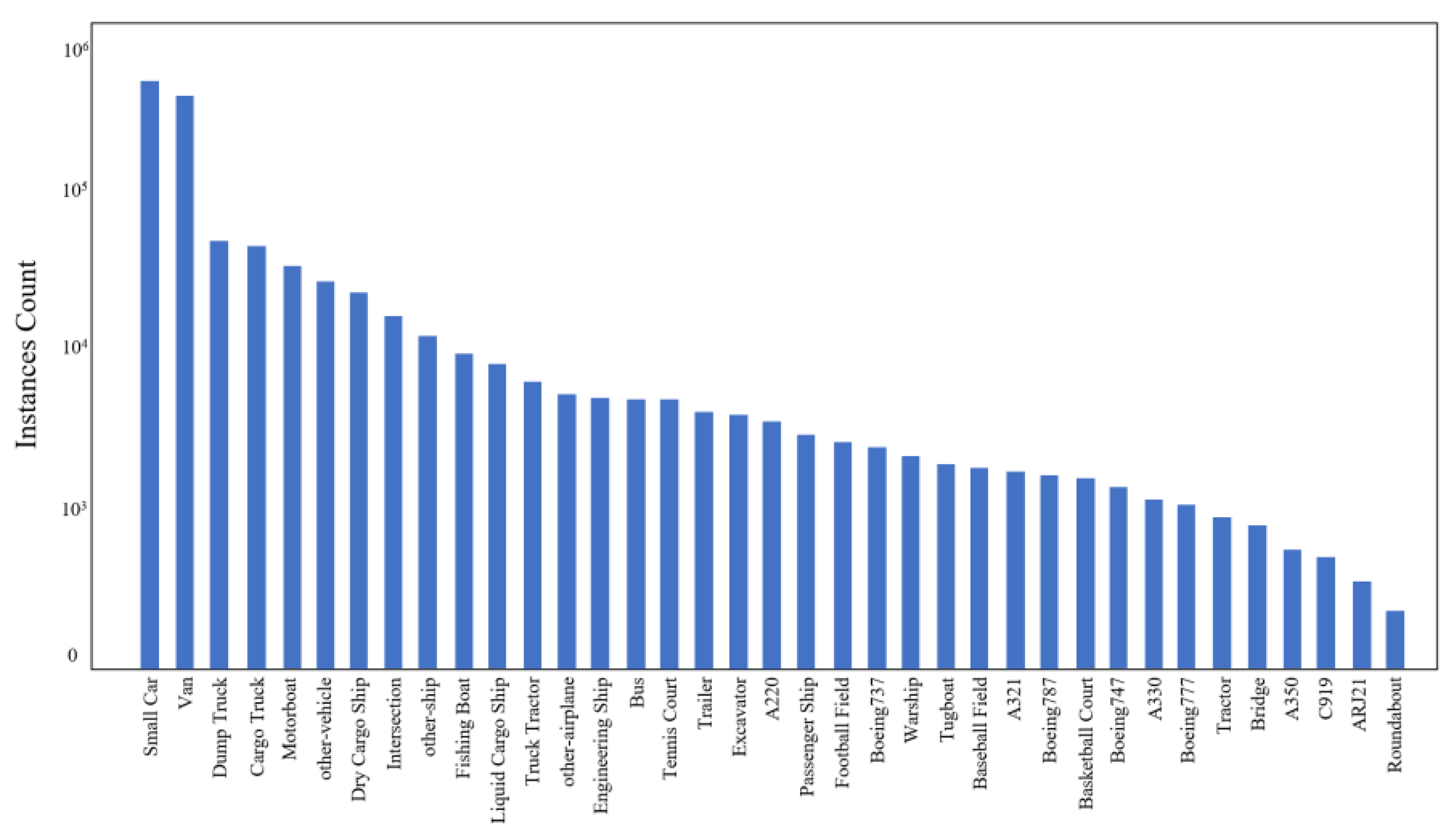
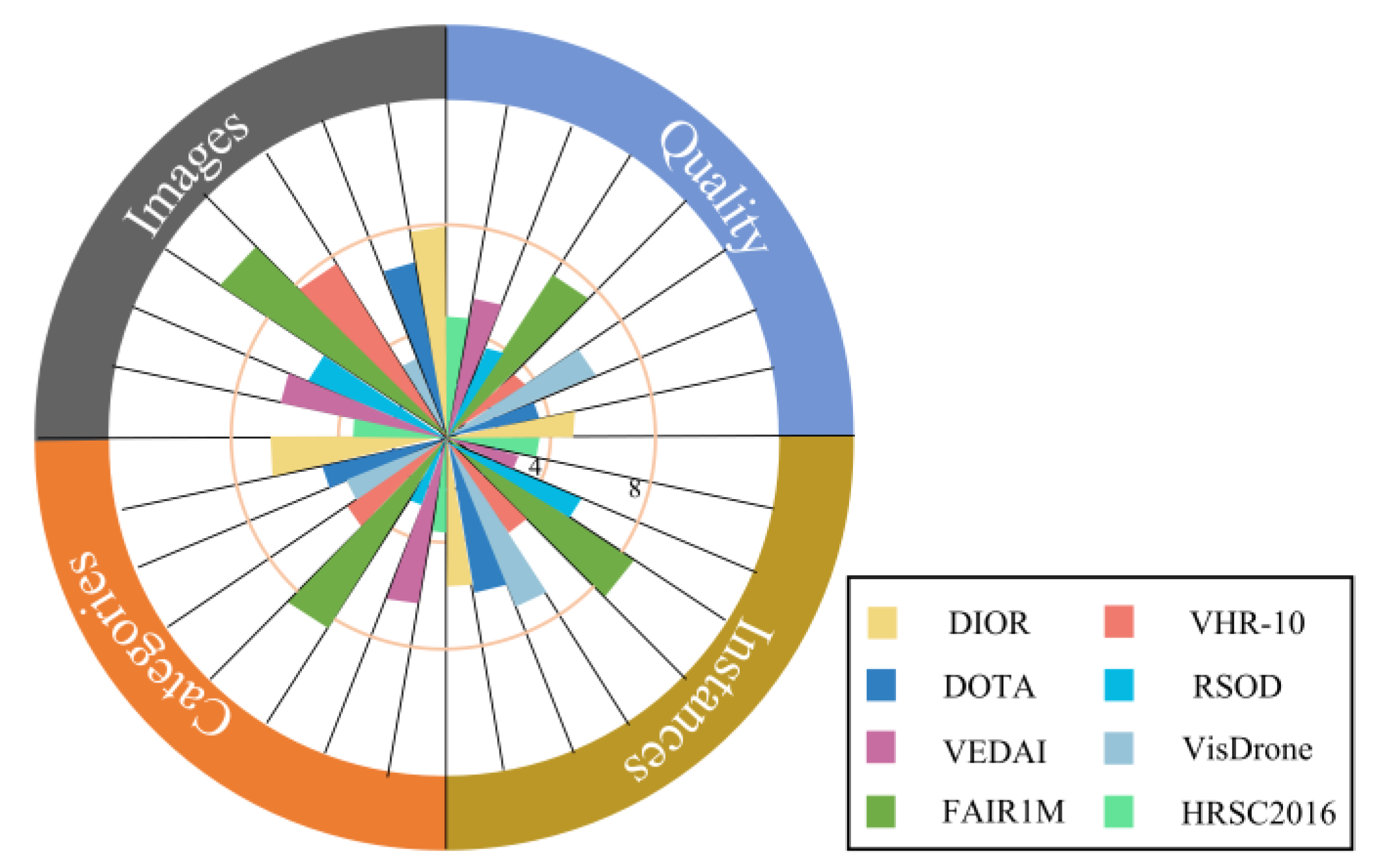
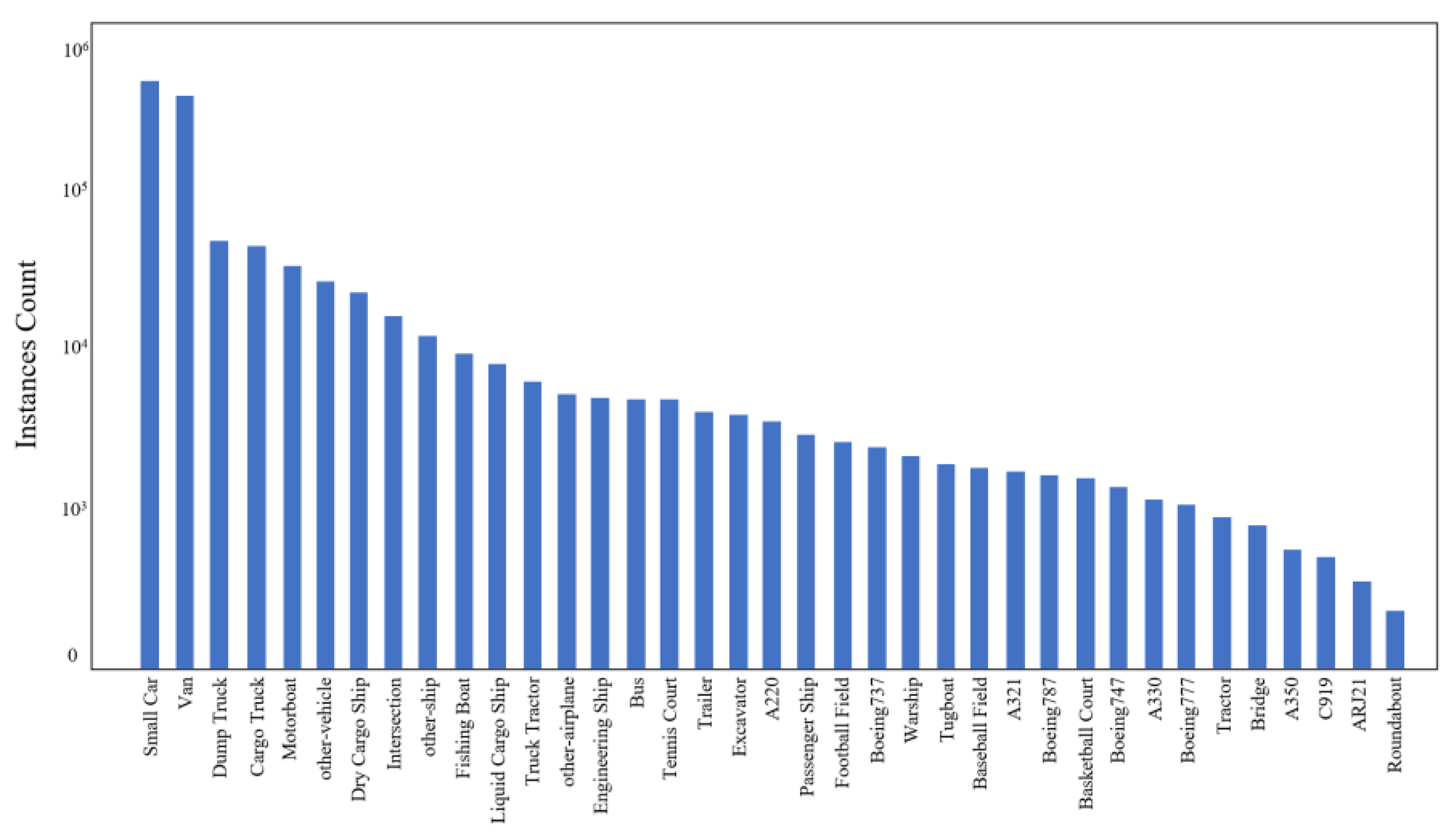
4.1. Dataset
- The scale of the dataset is huge. With the increasing demand for aerial object detection, the detector needs higher critical generalization. Many algorithms have been proposed and perform well on small datasets, but their performance decreases rapidly on large datasets. Therefore, to train the detector more comprehensively, the corresponding dataset needs a large volume of object instances and images.
- Data samples are rich in detail. The similarity within the aerial class increases the demand for fine-grained recognition. An excellent detection algorithm should be able to correctly identify objects belonging to specific subcategories. Most of the existing datasets contain coarse-grained information and lack detailed information, which makes it difficult to improve the detection performance of deep learning methods.
- The image quality of data samples is high. Factors such as rain, fog, cloud, and jitter may interfere with the quality of aerial images. It is challenging to train excellent algorithms with low-quality samples to meet the requirements of aerial object detection.
4.2. Evaluations Metrics
4.3. Implementation Details
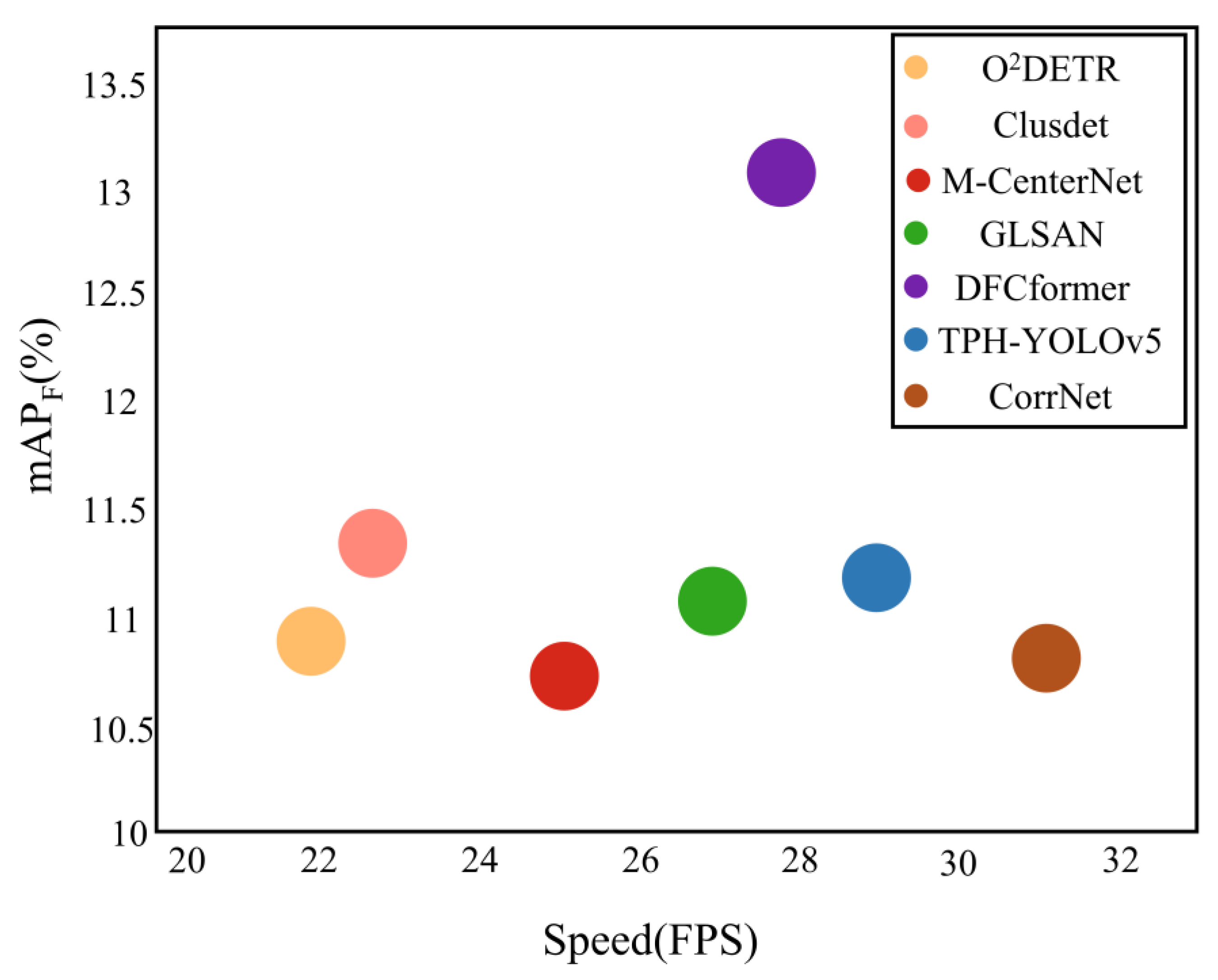
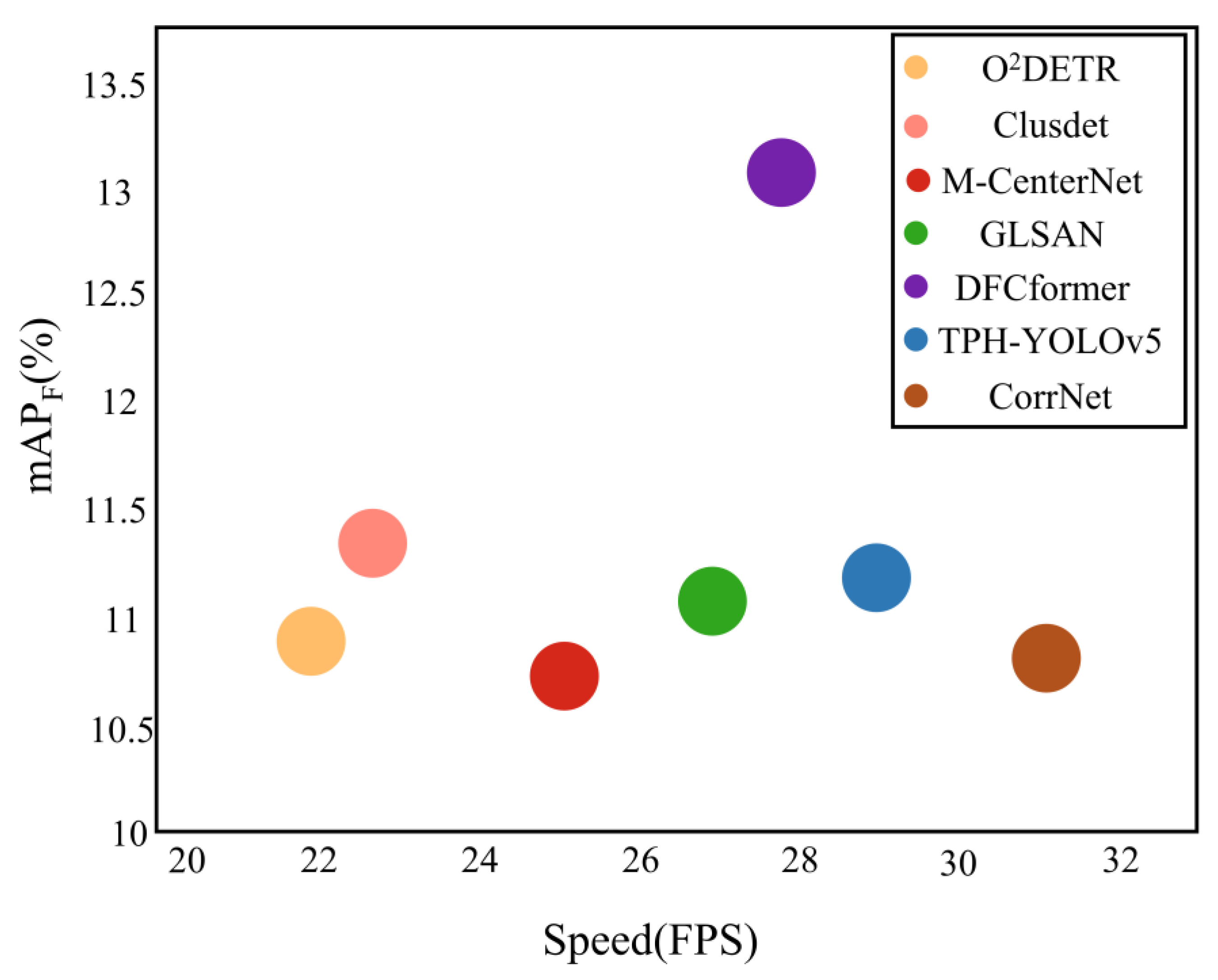
4.4. Comparison with the State-of-the-Art
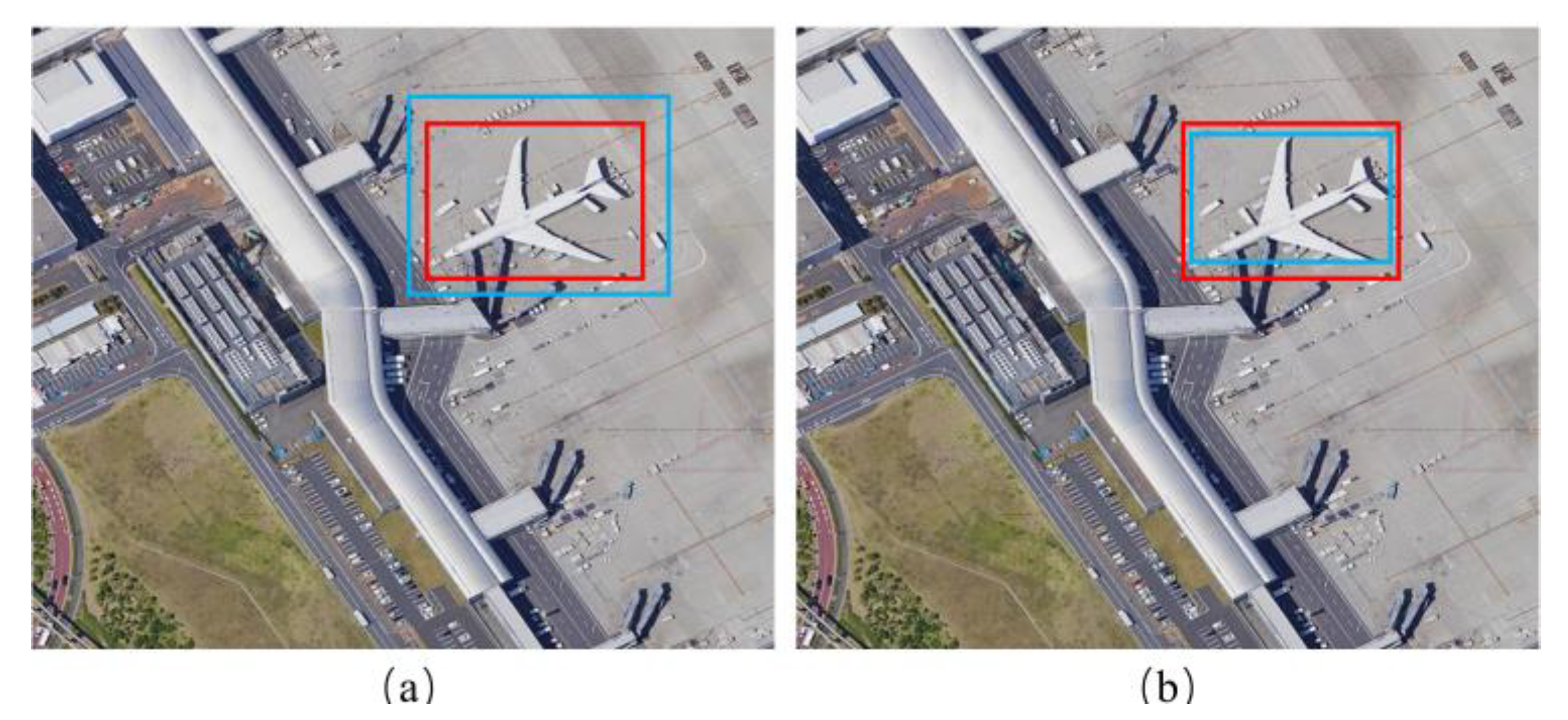
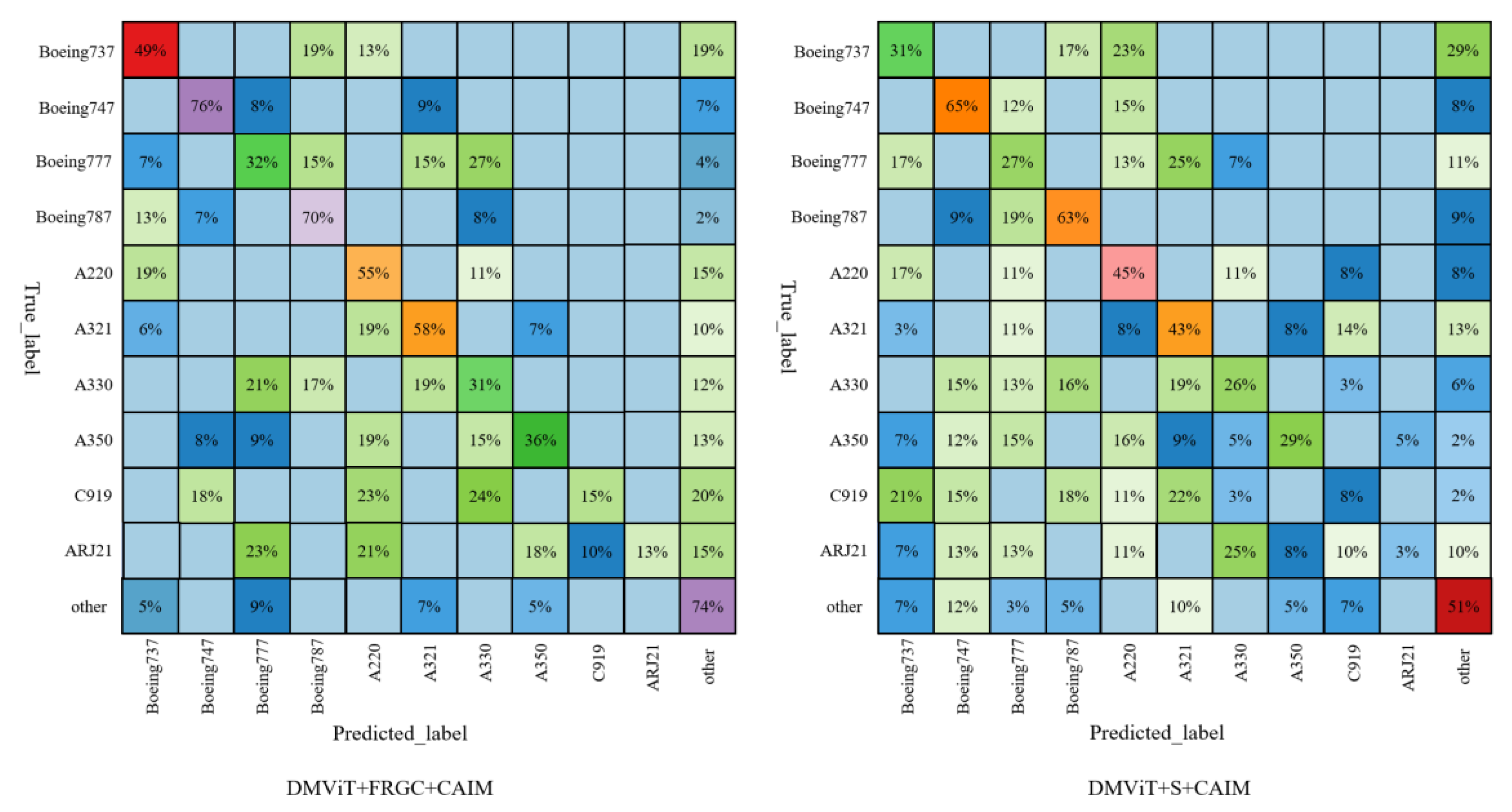
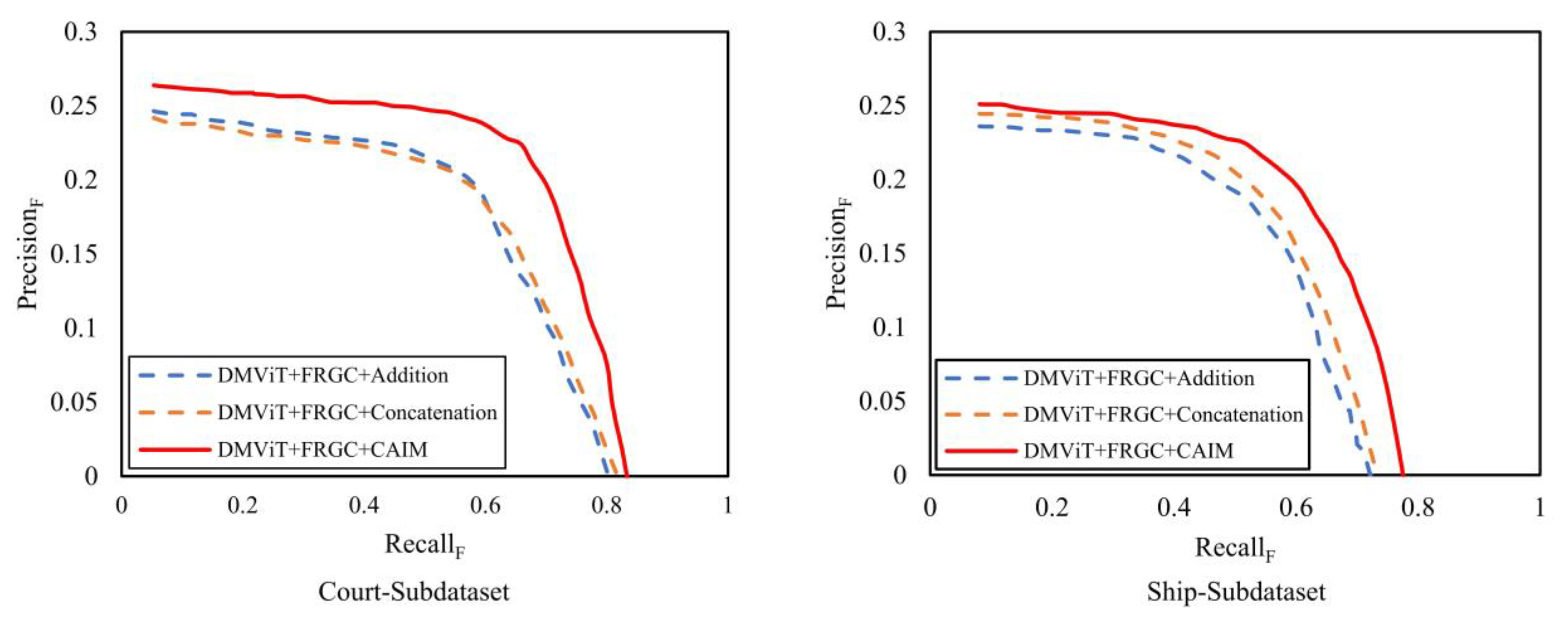
4.5. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bi, Q.; Qin, K.; Li, Z.; Zhang, H.; Xu, K.; Xia, G.S. A multiple-instance densely-connected ConvNet for aerial scene classification. IEEE Trans. Image Process. 2020, 29, 4911–4926. [Google Scholar] [CrossRef]
- Pérez-Álvarez, R.; Sedano-Cibrián, J.; de Luis-Ruiz, J.M.; Fernández-Maroto, G.; Pereda-García, R. Mining exploration with UAV, low-cost thermal cameras and GIS tools—application to the specific case of the complex sulfides hosted in Carbonates of Udías (Cantabria, Spain). Minerals 2022, 12, 140. [Google Scholar] [CrossRef]
- Padró, J.C.; Muñoz, F.J.; Planas, J.; Pons, X. Comparison of four UAV georeferencing methods for environmental monitoring purposes focusing on the combined use with airborne and satellite remote sensing platforms. Int. J. Appl. Earth Obs. Geoinf. 2019, 75, 130–140. [Google Scholar] [CrossRef]
- Latha, T.P.; Sundari, K.N.; Cherukuri, S.; Prasad, M.V.V.S.V. Remote sensing UAV/Drone technology as a tool for urban development measures in APCRDA. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 42, 525–529. [Google Scholar] [CrossRef] [Green Version]
- Delavarpour, N.; Koparan, C.; Nowatzki, J.; Bajwa, S.; Sun, X. A technical study on UAV characteristics for precision agriculture applications and associated practical challenges. Remote Sens. 2021, 13, 1204. [Google Scholar] [CrossRef]
- He, P.; Jiao, L.; Shang, R.; Wang, S.; Liu, X.; Quan, D.; Zhao, D. MANet: Multi-scale aware-relation network for semantic segmentation in aerial scenes. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5624615. [Google Scholar] [CrossRef]
- Swain, M.J.; Ballard, D.H. Color indexing. Int. J. Comput. Vis. 1991, 7, 11–32. [Google Scholar] [CrossRef]
- Gevers, T.; Smeulders, A.W.M. Pictoseek: Combining color and shape invariant features for image retrieval. IEEE Trans. Image Process. 2000, 9, 102–119. [Google Scholar] [CrossRef] [PubMed]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Philbin, J.; Chum, O.; Isard, M.; Sivic, J.; Zisserman, A. Object Retrieval with Large Vocabularies and Fast Spatial Matching. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Hofmann, T. Unsupervised learning by probabilistic latent semantic analysis. Mach. Learn. 2001, 42, 177–196. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Xu, X.; Feng, Z.; Cao, C.; Li, M.; Wu, J.; Wu, Z.; Shang, Y.; Ye, S. An improved Swin Transformer-Based Model for Remote Sensing Object Detection and Instance Segmentation. Remote Sens. 2021, 13, 4779. [Google Scholar] [CrossRef]
- Yang, F.; Fan, H.; Chu, P.; Blasch, E.; Ling, H. Clustered Object Detection in Aerial Images. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Li, C.; Yang, T.; Zhu, S.; Chen, C.; Guan, S. Density Map Guided Object Detection in Aerial Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Wang, J.; Yang, W.; Guo, H.; Zhang, R.; Xia, G.S. Tiny Object Detection in Aerial Images. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021. [Google Scholar]
- Deng, S.; Li, S.; Xie, K.; Song, W.; Liao, X.; Hao, A.; Qin, H. A global-local self-adaptive network for drone-view object detection. IEEE Trans. Image Process. 2020, 30, 1556–1569. [Google Scholar] [CrossRef] [PubMed]
- Li, G.; Liu, Z.; Bai, Z.; Lin, W.; Ling, H. Lightweight salient object detection in optical remote sensing images via feature correlation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5617712. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Hendria, W.F.; Phan, Q.T.; Adzaka, F.; Jeong, C. Combining transformer and CNN for object detection in UAV imagery. ICT Express 2021, in press. [CrossRef]
- Li, Q.; Chen, Y.; Zeng, Y. Transformer with transfer CNN for remote-sensing-image object detection. Remote Sens. 2022, 14, 984. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Zhang, Z.; Lu, X.; Cao, G.; Yang, Y.; Jiao, L.; Liu, F. ViT-YOLO: Transformer-Based YOLO for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on Transformer Prediction Head for Object Detection on Drone-Captured Scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Chen, Z.; Zhu, Y.; Zhao, C.; Hu, G.; Zeng, W.; Wang, J.; Tang, M. Dpt: Deformable Patch-based Transformer for Visual Recognition. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Conference, 20–24 October 2021. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single Shot Multibox Detector. In Proceedings of the European Conference on Computer Vision (ECCV 2016), Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Wang, D.; Zhang, J.; Du, B.; Xia, G.S.; Tao, D. An empirical study of remote sensing pretraining. IEEE Trans. Geosci. Remote Sens. 2022; early access. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. arXiv 2020, arXiv:2005.12872. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2021, arXiv:2010.04159. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Yuan, L.; Chen, Y.; Wang, T.; Yu, W.; Shi, Y.; Jiang, Z.H.; Tay, F.E.; Feng, J.; Yan, S. Tokens-to-Token Vit: Training Vision Transformers from Scratch on Imagenet. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Lee, Y.; Kim, J.; Willette, J.; Hwang, S.J. MPViT: Multi-path vision transformer for dense prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Baltimore, MD, USA, 17–23 July 2022. [Google Scholar]
- Yang, C.; Wang, Y.; Zhang, J.; Zhang, H.; Wei, Z.; Lin, Z.; Yuille, A. Lite vision transformer with enhanced self-attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Baltimore, MD, USA, 17–23 July 2022. [Google Scholar]
- Zhou, D.; Kang, B.; Jin, X.; Yang, L.; Lian, X.; Jiang, Z.; Hou, Q.; Feng, J. Deepvit: Towards deeper vision transformer. arXiv 2021, arXiv:2103.11886. [Google Scholar]
- Mao, X.; Qi, G.; Chen, Y.; Li, X.; Duan, R.; Ye, S.; He, Y.; Xue, H. Towards robust vision transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Baltimore, MD, USA, 17–23 July 2022. [Google Scholar]
- Pang, J.; Li, C.; Shi, J.; Xu, Z.; Feng, H. R2-CNN: Fast tiny object detection in large-scale remote sensing images. arXiv 2019, arXiv:1902.06042. [Google Scholar]
- Pan, X.; Ren, Y.; Sheng, K.; Dong, W.; Yuan, H.; Guo, X.; Ma, C.; Xu, C. Dynamic Refinement Network for Oriented and Densely Packed Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Ma, T.; Mao, M.; Zheng, H.; Gao, P.; Wang, X.; Han, S.; Doermann, D. Oriented object detection with transformer. arXiv 2021, arXiv:2106.03146. [Google Scholar]
- Ran, Q.; Wang, Q.; Zhao, B.; Wu, Y.; Pu, S.; Li, Z. Lightweight oriented object detection using multiscale context and enhanced channel attention in remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 5786–5795. [Google Scholar] [CrossRef]
- Xu, J.; Li, Y.; Wang, S. AdaZoom: Adaptive zoom network for multi-scale object detection in large scenes. arXiv 2021, arXiv:2106.10409. [Google Scholar]
- Ren, S.; Zhou, D.; He, S.; Feng, J.; Wang, X. Shunted Self-Attention via Multi-Scale Token Aggregation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 21–24 June 2022. [Google Scholar]
- Zhang, K.; Shen, H. Multi-stage feature enhancement pyramid network for detecting objects in optical remote sensing images. Remote Sens. 2022, 14, 579. [Google Scholar] [CrossRef]
- Lee, C.; Park, S.; Song, H.; Ryu, J.; Kim, S.; Kim, H.; Pereira, S.; Yoo, D. Interactive Multi-Class Tiny-Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Baltimore, MD, USA, 17–23 July 2022. [Google Scholar]
- Lu, X.; Ji, J.; Xing, Z.; Miao, Q. Attention and feature fusion SSD for remote sensing object detection. IEEE Trans. Instrum. Meas. 2021, 70, 5501309. [Google Scholar] [CrossRef]
- Yuan, W.; Xu, W. MSST-Net: A multi-scale adaptive network for building extraction from remote sensing images based on Swin transformer. Remote Sens. 2021, 13, 4743. [Google Scholar] [CrossRef]
- Dai, Y.; Gieseke, F.; Oehmcke, S.; Wu, Y.; Barnard, K. Attentional Feature Fusion. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Virtual Conference, 5–9 January 2021. [Google Scholar]
- Graham, B.; El-Nouby, A.; Touvron, H.; Stock, P.; Joulin, A.; Jégou, H.; Douze, M. LeViT: A Vision Transformer in ConvNet’s Clothing for Faster Inference. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Virtual Conference, 11–17 October 2021. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, J.L.; Li, K.; Li, F.F. Imagenet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Hamida, A.B.; Benoit, A.; Lambert, P.; Amar, C.B. 3-D Deep Learning Approach for Remote Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4420–4434. [Google Scholar] [CrossRef] [Green Version]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft Coco: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhu, P.; Du, D.; Wen, L.; Bian, X.; Ling, H.; Hu, Q.; Peng, T.; Zheng, J.; Wang, X.; Zhang, Y.; et al. VisDrone-VID2019: The Vision Meets Drone Object Detection in Video Challenge Results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Sun, X.; Wang, P.; Yan, Z.; Xu, F.; Wang, R.; Diao, W.; Fu, K. FAIR1M: A benchmark dataset for fine-grained object recognition in high-resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2022, 184, 116–130. [Google Scholar] [CrossRef]
- Xiao, Z.; Liu, Q.; Tang, G.; Zhai, X. Elliptic fourier transformation-based histograms of oriented gradients for rotationally invariant object detection in remote-sensing images. Int. J. Remote Sens. 2015, 36, 618–644. [Google Scholar] [CrossRef]
- Razakarivony, S.; Jurie, F. Vehicle detection in aerial imagery: A small target detection benchmark. J. Vis. Commun. Image Represent. 2016, 34, 187–203. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Yuan, L.; Weng, L.; Yang, Y. A High Resolution Optical Satellite Image Dataset for Ship Recognition and Some New Baselines. In Proceedings of the 6th International Conference on Pattern Recognition Applications and Methods, Porto, Portugal, 24–26 February 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DMViT-S | DMViT-M | DMViT-L | |
|---|---|---|---|
| Stage1 | Depatch Embedding | ||
| Stage2 | Depatch Embedding | ||
| Stage3 | Depatch Embedding | ||
| Stage4 | Depatch Embedding | ||
| General Categories | Categories | CorrNet [20] | ClusDet [16] | GLSAN [19] | M-CenterNet [17] | TPH-YOLOv5 [28] | O2DETR [48] | DFCformer |
|---|---|---|---|---|---|---|---|---|
| AP/APF (%) | AP/APF (%) | AP/APF (%) | AP/APF (%) | AP/APF (%) | AP/APF (%) | AP/APF (%) | ||
| Road | Bridge | 15.71/7.65 | 14.65/8.21 | 13.18/7.66 | 15.16/8.33 | 14.83/7.12 | 17.61/7.95 | 18.67/8.02 |
| Roundabout | 21.15/6.89 | 20.17/6.53 | 22.33/7.97 | 23.15/8.09 | 20.15/8.49 | 19.51/8.05 | 24.51/8.37 | |
| Intersection | 63.86/11.2 | 67.45/15.64 | 69.88/10.15 | 70.13/16.68 | 66.89/14.86 | 65.31/14.63 | 71.64/21.02 | |
| Court | Baseball Field | 69.5/11.5 | 66.8/13.46 | 65.27/15.11 | 65.33/14.49 | 70.15/19.68 | 69.94/19.34 | 70.05/22.67 |
| Tennis Court | 85.6/19.6 | 82.97/21.11 | 83.39/23.16 | 81.16/22.98 | 88.64/27.61 | 88.51/27.53 | 89.15/28.15 | |
| Football Field | 57.64/11.7 | 55.86/10.68 | 57.96/12.87 | 58.84/13.39 | 61.12/17.38 | 62.28/17.44 | 64.15/18.12 | |
| Basketball Field | 55.62/11.2 | 59.87/13.63 | 60.12/18.65 | 61.11/20.09 | 63.48/19.84 | 64.51/19.93 | 65.77/20.15 | |
| Vehicle | Bus | 25.16/10.8 | 23.12/9.06 | 19.14/5.23 | 20.07/9.58 | 23.16/8.73 | 22.02/8.62 | 38.61/15.28 |
| Van | 58.62/15.81 | 59.64/18.64 | 61.16/19.62 | 58.87/17.74 | 62.43/17.62 | 61.15/16.54 | 67.84/19.57 | |
| Trailer | 23.34/10.68 | 22.99/11.63 | 23.51/11.77 | 21.08/9.84 | 23.53/6.88 | 23.49/6.53 | 26.34/7.88 | |
| Tractor | 9.98/2.68 | 10.08/3.53 | 11.29/4.64 | 12.21/4.06 | 15.83/4.03 | 16.77/4.58 | 7.15/1.17 | |
| Excavator | 21.08/10.65 | 23.96/11.94 | 22.03/10.98 | 21.88/9.67 | 22.15/3.19 | 22.03/3.02 | 27.98/8.12 | |
| Small Car | 71.35/18.15 | 73.81/19.08 | 71.19/20.03 | 70.05/19.63 | 76.62/20.05 | 76.13/19.95 | 78.65/25.33 | |
| Cargo Truck | 50.32/12.42 | 51.21/15.89 | 52.21/17.83 | 50.56/18.34 | 52.27/18.62 | 50.06/18.12 | 55.87/23.17 | |
| Dump Truck | 41.63/10.35 | 45.19/12.37 | 47.55/13.38 | 43.15/11.89 | 49.31/16.15 | 47.35/15.48 | 49.86/16.53 | |
| Truck Tractor | 33.68/12.92 | 35.86/11.14 | 34.19/10.25 | 30.06/9.59 | 37.14/12.28 | 36.41/11.73 | 39.97/13.08 | |
| Other-vehicle | 13.86/5.91 | 15.12/7.26 | 17.62/8.21 | 15.31/8.87 | 15.09/6.34 | 15.98/6.87 | 15.12/7.15 | |
| Ship | Warship | 23.41/10.38 | 20.17/9.64 | 19.56/9.25 | 20.06/8.93 | 23.98/7.57 | 22.08/7.21 | 27.88/9.54 |
| Tugboat | 24.89/10.56 | 22.35/9.12 | 20.11/8.64 | 19.59/7.32 | 24.64/7.63 | 26.18/8.05 | 30.54/9.35 | |
| Motorboat | 28.62/12.62 | 25.64/11.05 | 24.66/9.25 | 23.65/8.74 | 30.04/9.83 | 31.25/9.95 | 39.88/10.05 | |
| Passenger Ship | 13.62/6.17 | 9.52/2.51 | 10.67/3.84 | 9.93/2.08 | 15.09/6.35 | 16.17/6.68 | 19.97/7.41 | |
| Fishing Boat | 5.21/1.84 | 3.12/0.87 | 5.11/1.12 | 6.09/1.46 | 3.21/1.01 | 3.05/0.87 | 1.08/0.15 | |
| Engineering Ship | 23.31/10.96 | 25.16/11.26 | 22.86/9.55 | 13.65/2.18 | 12.05/2.97 | 10.25/2.18 | 28.97/12.15 | |
| Liquid Cargo Ship | 17.86/12.61 | 15.64/8.76 | 13.06/7.74 | 5.34/0.63 | 12.75/3.16 | 11.34/2.75 | 15.35/3.45 | |
| Dry Cargo Ship | 29.86/12.37 | 30.16/13.62 | 28.62/12.19 | 22.61/7.15 | 25.09/5.93 | 22.97/5.36 | 24.15/4.51 | |
| other-ship | 6.11/2.86 | 5.11/1.29 | 3.26/0.25 | 4.88/1.01 | 4.35/0.61 | 4.18/0.86 | 2.86/0.48 | |
| Airplane | C919 | 2.56/1.86 | 5.87/1.75 | 6.51/1.61 | 3.36/0.41 | 2.18/0.37 | 2.01/0.53 | 0.95/0.08 |
| A220 | 45.62/16.55 | 44.12/18.31 | 47.12/19.58 | 49.62/15.32 | 51.86/19.96 | 50.54/19.17 | 55.37/20.09 | |
| A321 | 43.98/12.35 | 45.86/14.12 | 46.16/15.02 | 41.15/13.68 | 42.15/15.52 | 43.66/15.95 | 57.86/21.15 | |
| A330 | 22.14/6.85 | 27.85/7.86 | 26.68/8.05 | 21.67/8.84 | 26.04/6.53 | 25.37/6.28 | 31.17/7.68 | |
| A350 | 22.69/8.31 | 22.83/9.37 | 21.16/7.78 | 23.36/7.42 | 25.12/5.01 | 26.12/5.43 | 35.57/8.69 | |
| ARJ21 | 3.69/0.98 | 5.89/0.46 | 6.09/1.05 | 7.05/1.88 | 9.54/2.26 | 9.36/2.09 | 2.84/0.61 | |
| Boeing737 | 42.67/15.58 | 45.98/17.67 | 44.89/18.52 | 46.94/15.61 | 48.68/16.83 | 49.15/16.97 | 48.97/17.02 | |
| Boeing747 | 58.98/23.19 | 61.31/22.18 | 63.33/23.14 | 67.95/24.57 | 69.91/24.16 | 70.18/24.83 | 75.56/27.86 | |
| Boeing777 | 27.98/7.18 | 25.46/9.56 | 28.96/6.88 | 29.05/6.34 | 27.58/7.53 | 28.69/7.74 | 31.25/11.37 | |
| Boeing787 | 55.64/16.67 | 53.88/19.95 | 57.97/20.18 | 59.91/18.86 | 61.86/19.94 | 63.87/20.26 | 69.87/22.16 | |
| other-airplane | 65.32/20.16 | 68.52/20.47 | 69.88/21.83 | 67.35/23.81 | 67.82/24.35 | 68.94/25.23 | 73.69/27.68 | |
| 34.66/10.82 | 34.95/11.34 | 35.1/11.24 | 34.09/10.81 | 36.41/11.25 | 36.34/10.94 | 40.14/13.12 | ||
| Combination | ||
|---|---|---|
| ResNet101 + FRGC + CAIM | 34.83 | 10.06 |
| PVT + FRGC + CAIM | 36.85 | 12.57 |
| DMViT + FRGC + CAIM (DFCformer) | 40.08 | 13.17 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, G.; He, X.; Wang, Q.; Shao, F.; Wang, H.; Wang, J. A Novel Multi-Scale Transformer for Object Detection in Aerial Scenes. Drones 2022, 6, 188. https://doi.org/10.3390/drones6080188
Lu G, He X, Wang Q, Shao F, Wang H, Wang J. A Novel Multi-Scale Transformer for Object Detection in Aerial Scenes. Drones. 2022; 6(8):188. https://doi.org/10.3390/drones6080188
Chicago/Turabian StyleLu, Guanlin, Xiaohui He, Qiang Wang, Faming Shao, Hongwei Wang, and Jinkang Wang. 2022. "A Novel Multi-Scale Transformer for Object Detection in Aerial Scenes" Drones 6, no. 8: 188. https://doi.org/10.3390/drones6080188
APA StyleLu, G., He, X., Wang, Q., Shao, F., Wang, H., & Wang, J. (2022). A Novel Multi-Scale Transformer for Object Detection in Aerial Scenes. Drones, 6(8), 188. https://doi.org/10.3390/drones6080188