
SDWBF Algorithm: A Novel Pedestrian Detection Algorithm in the Aerial Scene

Abstract
:1. Introduction
- A weighted filtration algorithm for redundant frames is proposed to reduce redundant frames and calculations;
- A weighted fusion algorithm for static and dynamic bounding boxes is proposed to improve the detection accuracy;
- We introduced scale matching to reduce the loss of detector features and further improve the accuracy of the detector.
2. Related Work
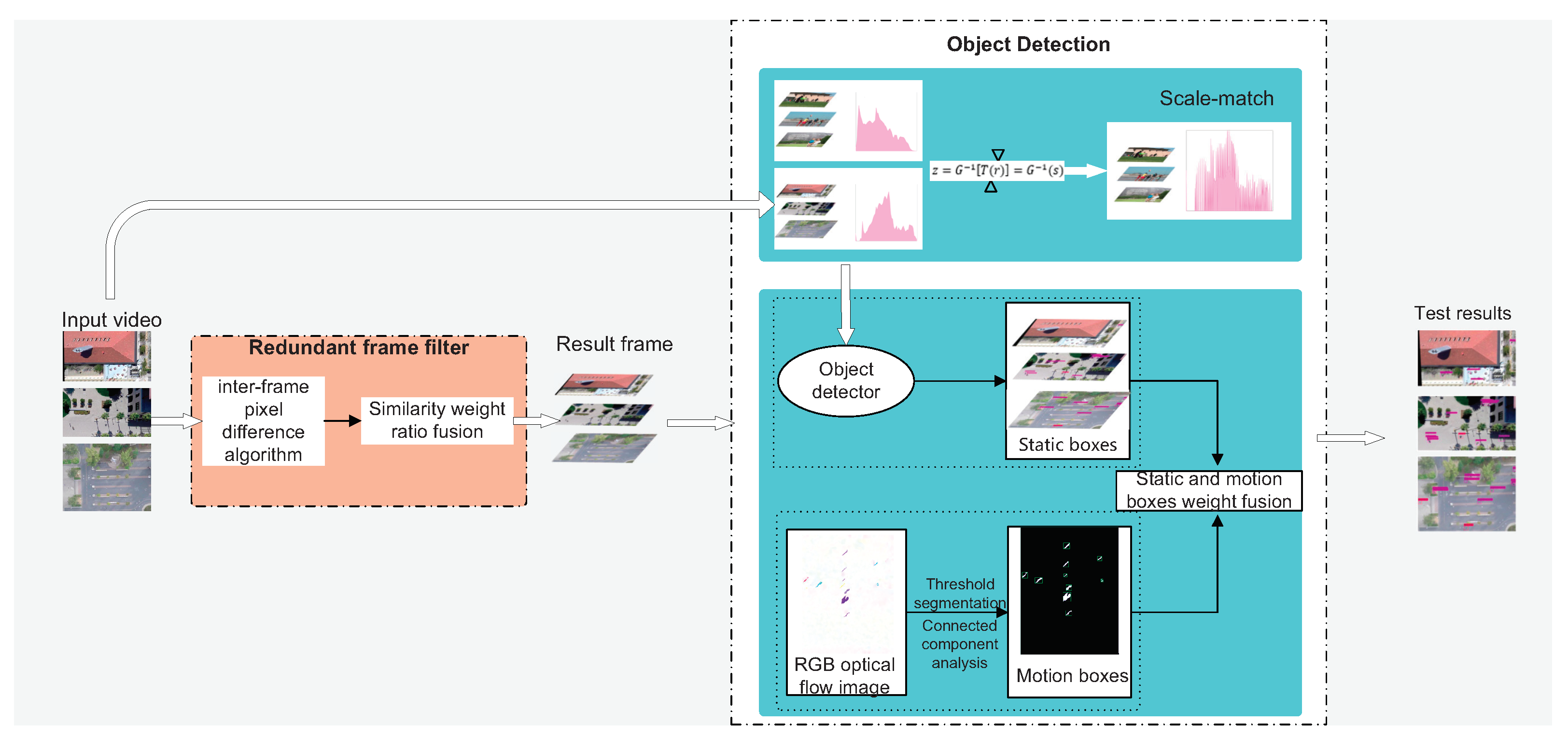
3. Proposed Method
3.1. Weighted Filtering Algorithm for Redundant Frames of Drone Video
3.2. Small-Sized Pedestrians Detection Method Based on the Weighted Fusion of Static and Dynamic Bounding Boxes
3.2.1. Scale Matching to Reduce the Loss of Detector Features
3.2.2. A Weighted Fusion Algorithm for Static and Dynamic Bounding Boxes
- (1)
- To obtain an RGB optical flow image, we convert the optical flow vector generated by LiteFlowNet3. Different colors in the RGB image represent different directions of motion, and the color depth indicates the speed of motion.
- (2)
- We perform threshold segmentation on the optical flow image to obtain a binary motion image. Threshold segmentation is divided into global and local threshold methods [28]. The global threshold method uses global information to find the optimal segmentation threshold for the entire image. However, for small-size pedestrian images, it is difficult to separate the object and background using the threshold of the whole image because of the small area that the objects occupied in the image. Therefore, this paper uses the local threshold method to obtain the binary motion image by segmenting the RGB optical flow image. Its idea is to self-adaptively calculate different thresholds according to the brightness distribution of different areas of the image. For image P, calculate the value of each pixel in the image through Gaussian filtering, the Gaussian filter function can denoize the optical flow image to a certain extent, and set as a constant, the Gaussian filter function [29] is Equation (8).Forward binarization point by value.where is the pixel value of in the RGB optical flow image, and is the binary image of the image P.
- (3)
- Analyzing the connected components of [30], the motion feature bounding box collectionset . Connected component analysis is to find a continuous subset of pixels in and mark them. These marked subsets constitute the motion feature box collection set of the object.
| Algorithm 1: A weighted fusion algorithm for static and dynamic bounding boxes. |
|
4. Experimental Section
4.1. Performance Evaluation Standard
4.2. Experimental Results and Analysis
4.2.1. Select the Best Weight Coefficient
4.2.2. Reduce Redundant Frames
4.2.3. Ablation Experiment
4.2.4. Test Result Comparison Experiment
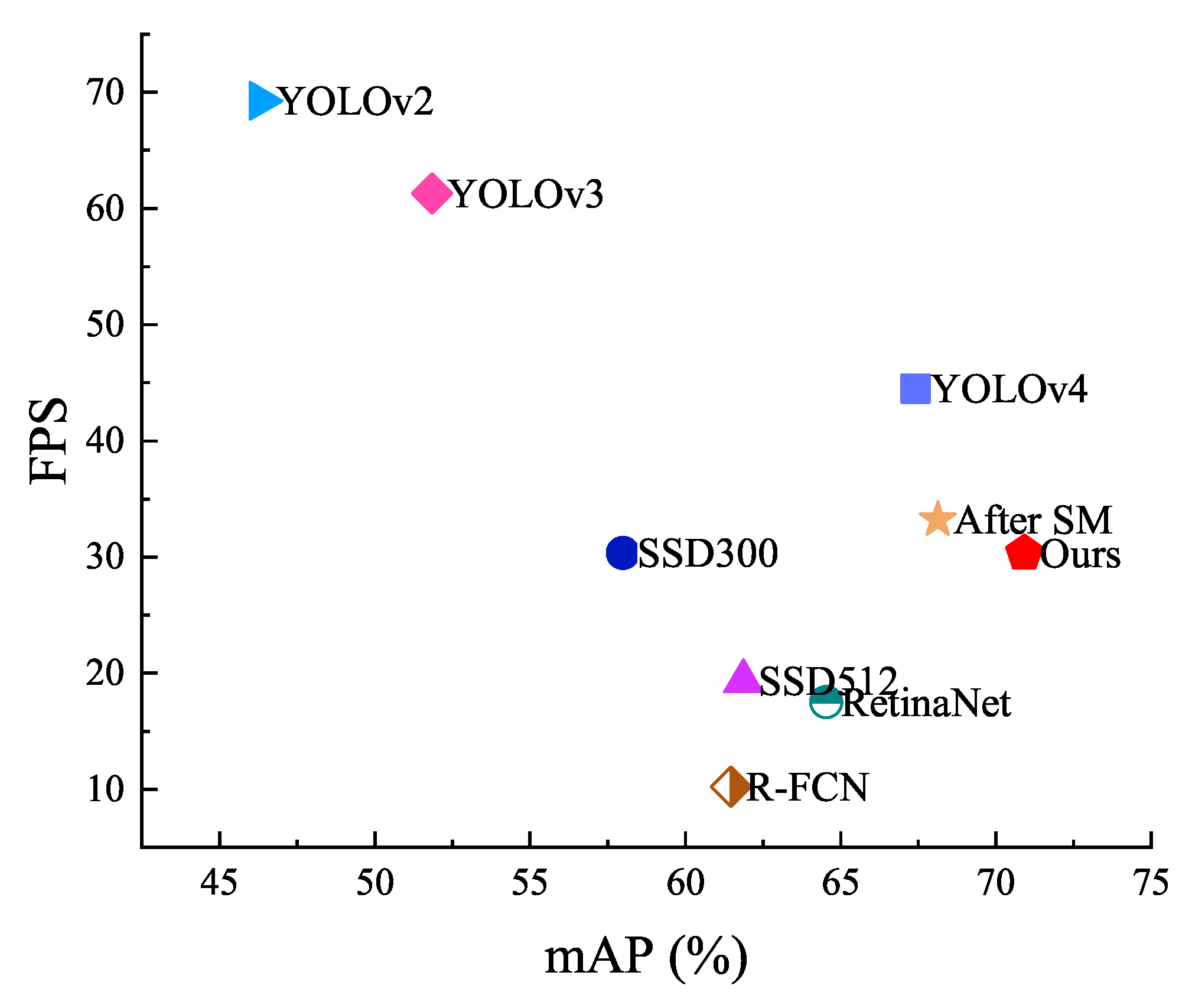
4.2.5. Compare Experiments with Advanced Detectors
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| UAV | Unmanned Aerial Vehicle |
| CNN | Convolutional Neural Network |
| SDD | Stanford Drone Dataset |
| EMD | Earth Movers Distance |
| SSIM | Structural Similarity |
References
- Hudson, L.; Sedlackova, A.N. Urban Sensing Technologies and Geospatial Big Data Analytics in Internet of Things-enabled Smart Cities. Geopolit. Hist. Int. Relations 2021, 13, 37–50. [Google Scholar]
- Kamate, S.; Yilmazer, N. Application of Object Detection and Tracking Techniques for Unmanned Aerial Vehicles. Procedia Comput. Sci. 2015, 61, 436–441. [Google Scholar] [CrossRef] [Green Version]
- Al-Sheary, A.; Almagbile, A. Crowd monitoring system using unmanned aerial vehicle (UAV). J. Civ. Eng. Archit. 2017, 11, 1014–1024. [Google Scholar] [CrossRef] [Green Version]
- Estrada, M.A.R.; Ndoma, A. The uses of unmanned aerial vehicles –UAV’s-(or drones) in social logistic: Natural disasters response and humanitarian relief aid. Procedia Comput. Sci. 2019, 149, 375–383. [Google Scholar] [CrossRef]
- Chen, C.; Liu, B.; Wan, S.; Qiao, P.; Pei, Q. An Edge Traffic Flow Detection Scheme Based on Deep Learning in an Intelligent Transportation System. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1840–1852. [Google Scholar] [CrossRef]
- Fromm, M.; Schubert, M.; Castilla, G.; Linke, J.; McDermid, G. Automated Detection of Conifer Seedlings in Drone Imagery Using Convolutional Neural Networks. Remote Sens. 2019, 11, 2585. [Google Scholar] [CrossRef] [Green Version]
- Kyrkou, C.; Plastiras, G.; Theocharides, T.; Venieris, S.I.; Bouganis, C. DroNet: Efficient convolutional neural network detector for real-time UAV applications. In Proceedings of the 2018 Design, Automation Test in Europe Conference Exhibition (DATE), Dresden, Germany, 19–23 March 2018; pp. 967–972. [Google Scholar] [CrossRef] [Green Version]
- Junos, M.H.; Mohd Khairuddin, A.S.; Thannirmalai, S.; Dahari, M. Automatic detection of oil palm fruits from UAV images using an improved YOLO model. Vis. Comput. 2021, 1–15. [Google Scholar] [CrossRef]
- Yu, X.; Gong, Y.; Jiang, N.; Ye, Q.; Han, Z. Scale Match for Tiny Person Detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision 2020, Snowmass Village, CO, USA, 1–5 March 2020. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-Based Fully Convolutional Networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2016; pp. 379–387. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Pang, J.; Li, C.; Shi, J.; Xu, Z.; Feng, H. R2 -CNN: Fast Tiny Object Detection in Large-Scale Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5512–5524. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Liang, X.; Wang, M.; Yang, L.; Zhuo, L. Coarse-to-fine object detection in unmanned aerial vehicle imagery using lightweight convolutional neural network and deep motion saliency. Neurocomputing 2020, 398, 555–565. [Google Scholar] [CrossRef]
- Liu, M.; Wang, X.; Zhou, A.; Fu, X.; Ma, Y.; Piao, C. UAV-YOLO: Small Object Detection on Unmanned Aerial Vehicle Perspective. Sensors 2020, 20, 2238. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, T.Y.H.; Ravindranath, L.; Deng, S.; Bahl, P.; Balakrishnan, H. Glimpse: Continuous, Real-Time Object Recognition on Mobile Devices. In Proceedings of the 13th ACM Conference on Embedded Networked Sensor Systems, Seoul, Korea, 1–4 November 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 155–168. [Google Scholar] [CrossRef] [Green Version]
- Canel, C.; Kim, T.; Zhou, G.; Li, C.; Lim, H.; Andersen, D.G.; Kaminsky, M.; Dulloor, S.R. Picking interesting frames in streaming video. In Proceedings of the 2018 SysML Conference, Stanford, CA, USA, 15–16 February 2018; pp. 1–3. [Google Scholar]
- Jiaheng, H.; Xiaowei, L.; Benhui, C.; Dengqi, Y. A Comparative Study on Image Similarity Algorithms Based on Hash. J. Dali Univ. 2017, 2, 32–37. [Google Scholar]
- Rubner, Y.; Tomasi, C.; Guibas, L.J. The earth mover’s distance as a metric for image retrieval. Int. J. Comput. Vis. 2000, 40, 99–121. [Google Scholar] [CrossRef]
- Horé, A.; Ziou, D. Image Quality Metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar] [CrossRef]
- Gao, Z.; Lu, G.; Lyu, C.; Yan, P. Key-frame selection for automatic summarization of surveillance videos: A method of multiple change-point detection. Mach. Vis. Appl. 2018, 29, 1101–1117. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Hui, T.W.; Loy, C.C. LiteFlowNet3: Resolving Correspondence Ambiguity for More Accurate Optical Flow Estimation. In Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 169–184. [Google Scholar]
- Dosovitskiy, A.; Fischer, P.; Ilg, E.; Häusser, P.; Hazirbas, C.; Golkov, V.; Smagt, P.; Cremers, D.; Brox, T. FlowNet: Learning Optical Flow with Convolutional Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015; pp. 2758–2766. [Google Scholar] [CrossRef] [Green Version]
- Sun, D.; Yang, X.; Liu, M.; Kautz, J. PWC-Net: CNNs for Optical Flow Using Pyramid, Warping, and Cost Volume. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Rahman, M.A.; Wang, Y. Optimizing Intersection-Over-Union in Deep Neural Networks for Image Segmentation. In Proceedings of the International Symposium on Visual Computing, Las Vegas, NV, USA, 12–14 December 2016. [Google Scholar]
- Zhao, X.M.; Deng, Z.M. The Energy Gradient Method Based on Two-Dimensional Discrete Wavelet to Extract the Feature of Pilling. In Affective Computing and Intelligent Interaction; Luo, J., Ed.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 779–787. [Google Scholar] [CrossRef]
- Haddad, R.A.; Akansu, A.N. A class of fast Gaussian binomial filters for speech and image processing. IEEE Trans. Signal Process. 1991, 39, 723–727. [Google Scholar] [CrossRef]
- Grana, C.; Borghesani, D.; Cucchiara, R. Optimized Block-Based Connected Components Labeling With Decision Trees. IEEE Trans. Image Process. 2010, 19, 1596–1609. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, H.; Tian, Q.; Zhuang, Q.; Li, L.; Liang, Q. Fast and robust key frame extraction method for gesture video based on high-level feature representation. Signal Image Video Process. 2021, 15, 617–626. [Google Scholar] [CrossRef]
- Rahman, M.A.; Wang, Y. Optimizing Intersection-Over-Union in Deep Neural Networks for Image Segmentation. In Advances in Visual Computing; Bebis, G., Boyle, R., Parvin, B., Koracin, D., Porikli, F., Skaff, S., Entezari, A., Min, J., Iwai, D., Sadagic, A., et al., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 234–244. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.B.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. arXiv 2016, arXiv:1612.08242. [Google Scholar]

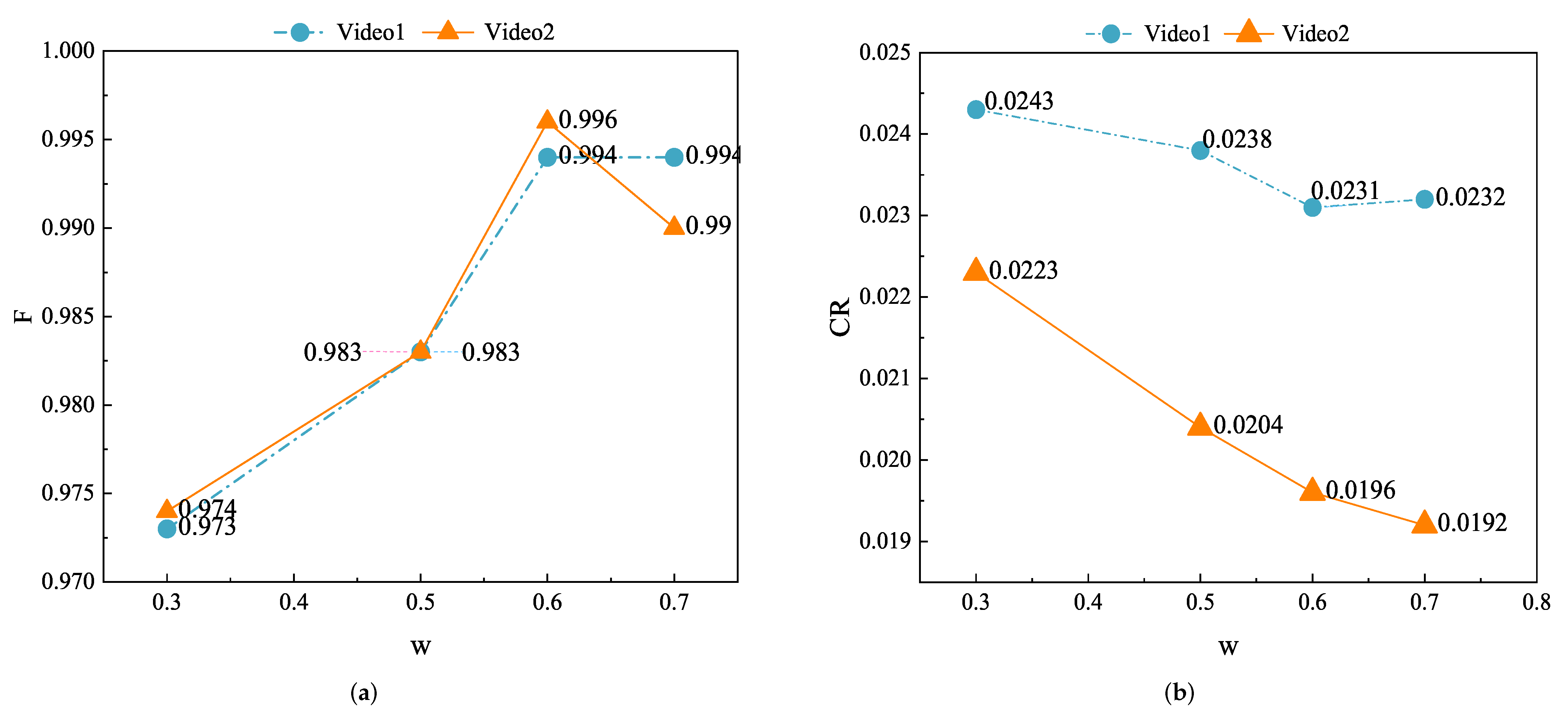
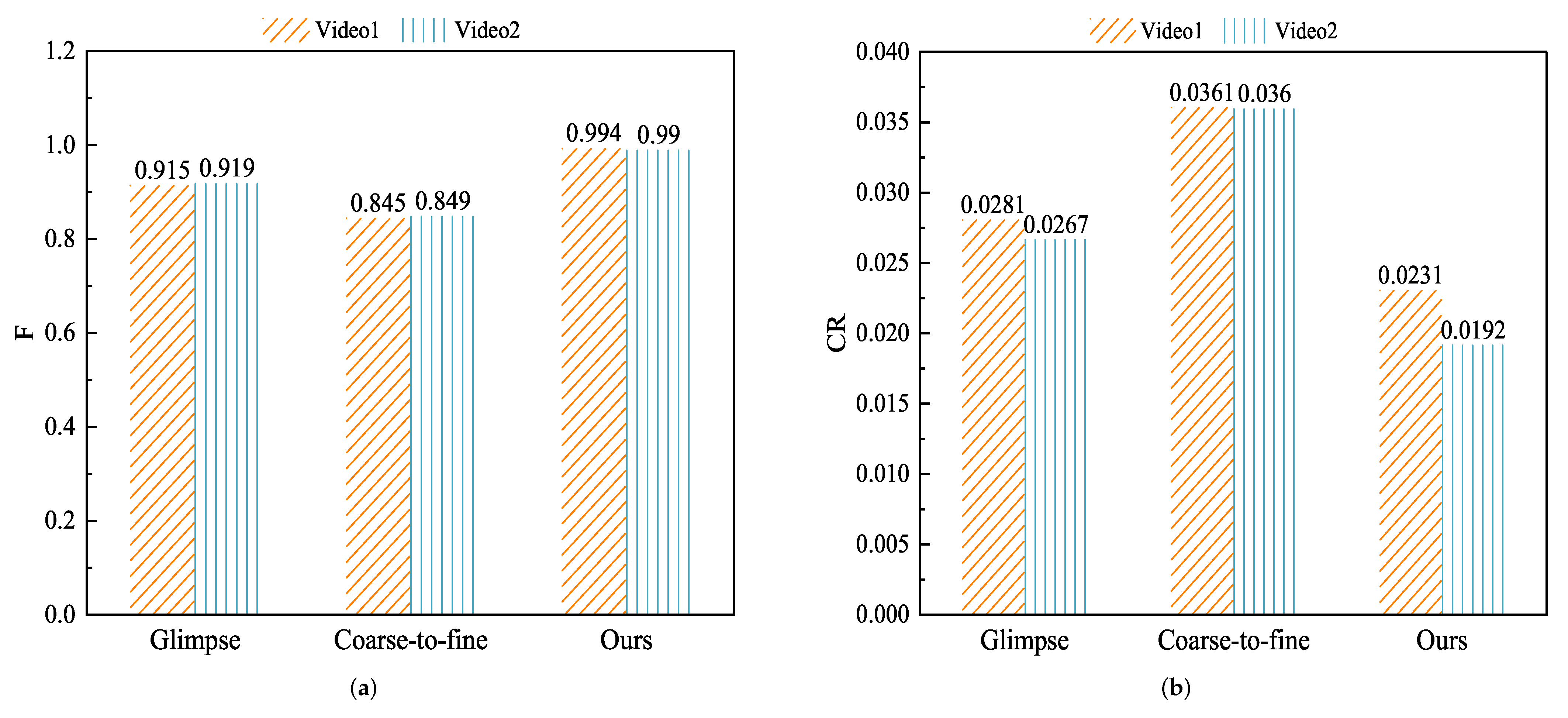


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| W | Frames | Initial | Result | Undetected | Redundant | F | CR |
|---|---|---|---|---|---|---|---|
| 0.3 | 11,966 | 729 | 291 | 0 | 16 | 0.973 | 2.43% |
| 0.5 | 11,966 | 729 | 285 | 0 | 10 | 0.983 | 2.38% |
| 0.6 | 11,966 | 729 | 277 | 0 | 3 | 0.994 | 2.31% |
| 0.7 | 11,966 | 729 | 274 | 2 | 1 | 0.994 | 2.32% |
| 0.3 | 12,721 | 619 | 284 | 0 | 15 | 0.974 | 2.23% |
| 0.5 | 12,721 | 619 | 260 | 0 | 9 | 0.983 | 2.04% |
| 0.6 | 12,721 | 619 | 249 | 0 | 2 | 0.996 | 1.96% |
| 0.7 | 12,721 | 619 | 244 | 3 | 2 | 0.990 | 1.92% |
| Methods | Frames | Result | Undetected | Redundant | F | CR | Average Time/s |
|---|---|---|---|---|---|---|---|
| Coarse-to-fine [15] | 11,966 | 336 | 0 | 62 | 0.915 | 2.81 | 0.027 |
| Glimpse [17] | 11,966 | 432 | 0 | 158 | 0.845 | 3.61 | 0.007 |
| Ours | 11966 | 277 | 0 | 3 | 0.994 | 2.31 | 0.055 |
| Coarse-to-fine [15] | 12,721 | 327 | 0 | 60 | 0.919 | 2.67 | 0.027 |
| Glimpse [17] | 12,721 | 459 | 0 | 167 | 0.847 | 3.60 | 0.007 |
| Ours | 12,721 | 249 | 0 | 0 | 0.990 | 1.92 | 0.055 |
| Methods | Pedestrian AP | Biker AP | mAP | Time/s |
|---|---|---|---|---|
| Baseline [13] | 74.34 | 60.45 | 67.40 | 268 |
| +Frame filtering | 74.34 | 60.45 | 67.40 | 29.12 |
| +Frame filtering and Feature fusion | 75.93 | 62.65 | 69.29 | 31.46 |
| +Frame filtering and Scale match | 75.14 | 61.11 | 68.13 | 31.25 |
| Ours | 77.53 | 64.28 | 70.91 | 32.05 |
| Methods | Input | Pedestrian AP/% | Biker AP/% | mAP/% | IoU | FPS |
|---|---|---|---|---|---|---|
| R-FCN (ResNet-101) [10] | 1000 × 600 | 67.21 | 55.71 | 61.46 | 53.26 | 10.24 |
| RetinaNet [33] | 800 × 800 | 71.77 | 57.29 | 64.53 | 54.43 | 17.5 |
| SSD300 [11] | 300 × 300 | 65.03 | 50.94 | 57.99 | 52.67 | 30.36 |
| SSD512 [11] | 512 × 512 | 68.90 | 54.81 | 61.86 | 53.80 | 19.32 |
| YOLOv2 [34] | 416 × 416 | 53.46 | 39.18 | 46.32 | 42.93 | 69.27 |
| YOLOv3 [12] | 416 × 416 | 59.54 | 44.15 | 51.85 | 50.45 | 61.3 |
| YOLOv4 [13] | 416 × 416 | 74.34 | 60.45 | 67.40 | 55.48 | 44.5 |
| After SM | 416 × 416 | 75.14 | 61.11 | 68.13 | 56.08 | 33.2 |
| Ours | 416 × 416 | 77.53 | 64.28 | 70.91 | 57.73 | 30.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, X.; Zhang, Y.; Zhang, W.; Zhou, H.; Yu, H. SDWBF Algorithm: A Novel Pedestrian Detection Algorithm in the Aerial Scene. Drones 2022, 6, 76. https://doi.org/10.3390/drones6030076
Ma X, Zhang Y, Zhang W, Zhou H, Yu H. SDWBF Algorithm: A Novel Pedestrian Detection Algorithm in the Aerial Scene. Drones. 2022; 6(3):76. https://doi.org/10.3390/drones6030076
Chicago/Turabian StyleMa, Xin, Yuzhao Zhang, Weiwei Zhang, Hongbo Zhou, and Haoran Yu. 2022. "SDWBF Algorithm: A Novel Pedestrian Detection Algorithm in the Aerial Scene" Drones 6, no. 3: 76. https://doi.org/10.3390/drones6030076
APA StyleMa, X., Zhang, Y., Zhang, W., Zhou, H., & Yu, H. (2022). SDWBF Algorithm: A Novel Pedestrian Detection Algorithm in the Aerial Scene. Drones, 6(3), 76. https://doi.org/10.3390/drones6030076