1. Introduction
Adequate grassland management is required to ensure sustainable and rentable cattle production, especially taking into account the potentially high environmental impacts of this activity. The management of pasture areas is complex, in particular for intensive production systems with multiple mowing and/or grazing events over the growing season. For farmers, determining the quantity and quality of forage available in-situ is essential since it is the least expensive source of feed and optimizing the utilization of this resource is crucial to reduce production costs [
1]. In this sense, choosing the right time for harvesting or grazing a given field is important and involves a trade-off between yield and biomass nutritional value, since dry matter accumulation over time is generally followed by reduction in nutritional quality, in particular regarding digestibility [
2].
Exploring the full productive potential of pasture fields requires sound fertilization planning. Considering the high amount of biomass extracted and the relatively low nutrient use efficiency, depending on the management practices related to nitrogen for example [
3], it is important to have accurate estimates of yield and nutrient uptake to assist farmers in the decision-making process related to fertilizer and amendment application. Current approaches used to evaluate yield or sward height involve visual assessment, rising-plate meters or electronic probes since destructive samples are labour demanding and expensive, therefore inadequate for practical use. In addition, grass quality parameters are not often monitored since their assessment depends on laboratory analysis, which increases the costs and complexity of the evaluation methods conventionally used. As an alternative, remote sensing techniques have been proposed in the literature as viable tools to assess quantity and quality of grassland production.
In recent years, particular attention has been given to Unmanned Aerial Vehicles (UAVs) as affordable and flexible platforms for agricultural studies and applications. Different sensors can be carried as payload by UAVs, allowing a comprehensive characterization of the vegetation. However, optical sensors, from high resolution RGB to multispectral and hyperspectral cameras, are generally the most accessible and informative sensing solutions available for general crop assessment and growth monitoring [
4,
5]. The spectral response of the plant canopy in the visible and near-infrared (NIR) regions (i.e., wavelengths between 450 and 900 nm) is strongly correlated to several biophysical and biochemical characteristics such as biomass and chlorophyll or nitrogen content [
5,
6]. At the same time, UAV-based imaging systems provide spatially continuous information, which is potentially advantageous when compared to point-based measurements regarding the description of spatial patterns and subsequent adjustment of management operations.
The use of UAV-based optical imaging systems for the characterization of forage traits has increasingly been explored in the literature, specially concerning yield estimation [
7,
8,
9]. Retrieval of pasture quality parameters such as crude protein content have been less frequently studied, but research interest in this topic is also increasing due to its importance to the planning of animal feeding and fertilizer application [
10]. However, most of the studies investigating the use of UAVs for forage assessment and management focus on single harvests or growing seasons [
11], limiting their conclusions to specific cases or small datasets. As other plants, grasses are subject to intra- and inter-annual growth variability caused by different factors such as temperature, water availability or changes in management practices. In addition, pastures are perennial and monitoring systems need to cope with considerable variation in measuring conditions since frequent data acquisition is generally required for relatively extensive periods of time to allow informed decisions. Therefore, prediction models for grassland traits based on limited or small spectral datasets will be prone to errors and large uncertainties when applied to samples acquired on other years or under different measurement conditions than those already described by observations available for model training.
Approaches used to estimate vegetation traits based on canopy spectral measurements in the optical domain can be roughly divided in empirical and physically-based methods [
5,
12]. While the first case relies on a training dataset to fit prediction models the later requires, in general, adequate parametrization of a Radiative Transfer Model (RTM) to translate spectral information into vegetation characteristics. RTM-based frameworks have greater generalization potential but performance might eventually be suboptimal, in particular for complex systems composed of multiple cultivars and/or crop mixtures, which makes parametrization more difficult. In turn, empirical models adapt well to complex datasets however their application is restricted to observations sharing the characteristics of the training data. Considering that fast evaluation and deployment of monitoring solutions based on UAV optical imagery is desirable, empirical models can be an initial option, especially for complex systems not yet well characterized or fully described.
Extending pre-existing training datasets to better represent new observations can reduce costs associated to monitoring frameworks that rely on empirical models to assist in general crop management. The purposeful or active selection of additional calibration samples offers an alternative to take advantage of data already available while improving model performance for newly acquired measurements [
13]. Different criteria can be considered to choose samples from a pool of available unlabelled cases for model training, and some of the most relevant aspects for this selection are sample diversity (i.e., how much the selected samples in the target dataset scatters across the feature space) and prediction uncertainty (i.e., how unsure the current modelling framework is about predictions for individual samples in the target domain) [
14,
15,
16]. One way to broadly divide active learning approaches is to consider if they are supervised or unsupervised [
15,
17,
18,
19,
20]. While unsupervised algorithms do not rely on labelled examples to further select candidate datasets for annotation and model fitting, supervised methods need at least an initial set of reference samples and usually also require an initial predictive model. Unsupervised approaches are attractive due to their flexibility and relatively straightforward implementation, however they are not optimal. Conversely, supervised methods are at least weakly optimal, through a heuristic approximation, and generally lead to better performance [
20].
In this context, the objectives of this study are: (i) evaluate the use of UAV hyperspectral imagery for the quantification of forage yield (dry matter in dt ha
) and nitrogen nutrition status (nitrogen content in % of dry matter and nitrogen uptake in kg ha
); (ii) extend the research presented by Capolupo et al. [
10] to a multi-annual assessment of grassland traits retrieval, closer to real application scenarios; and (iii) implement and validate a supervised approach for model transfer, searching to add informative samples from the target date to a pre-existing source dataset, based on sample diversity and prediction uncertainty within an adapted Active Learning framework [
17]. The main focus is to demonstrate that even considerably simple approaches applied to small datasets can result in relatively accurate predictions of grassland traits, indicating their spatial patterns and providing initial site-specific information to assist farmers in pasture management.
2. Material and Methods
2.1. Study Site and Experimental Design
The data used in this study was acquired in an experimental site in Germany, located near the city of Kleve (51
47
12.5
N, 6
10
08.7
E; as also described by Capolupo et al. [
10]). In this site, 60 plots measuring 1.5 by 8.0 m were arranged in four blocks and cultivated with ryegrass (
Lolium perenne) from 2012 to 2019 (
Figure 1). In each block, 15 different nitrogen (N) treatments were randomly applied to the experimental plots with four repetitions (i.e., one treatment per plot and one repetition per block). The treatments comprised different rates of inorganic (five levels of Calcium Ammonium Nitrate—CAN: 0, 85, 115, 170, 230, and 340 kg of N ha
) and organic fertilizer (three levels of slurry: 170, 230 and 340 kg of N ha
). For the treatments involving organic fertilizer, one additional factor considered was the number of consecutive years (from one to three years) in which these treatments were applied. The experiment was designed to represent the most common scenarios of N management adopted by farmers in the study region (i.e., 170 kg of N ha
, maximum normally allowed by law) and deviations from that (e.g., 230 kg of N ha
, maximum allowed in ‘non-grazing’ regime; and 340 kg N ha
, estimate maximum possible uptake) allowing an evaluation of the grassland response to different N fertilization planning and sources.
2.2. Measurement of above Ground Biomass and Nitrogen Content
Grassland traits were periodically evaluated since the start of the experiment in 2012. At the plot level, dry above-ground biomass was measured by harvesting and drying fresh vegetative material (for 24 h at 105 C). Further analysis of the collected material at treatment level (i.e., composite sample representing all plots of a given treatment) for each harvest date was carried out by the Agriculture Research Institute North Rhine-Westphalia in Germany (Landwirtschaftliche Untersuchungs- und Forschungsanstalt Nordrhein-Westfalen—LUFA NRW) following methods of the German Association of Agricultural Research and Research Institutes (Verband der Landwirtschaftlichen Untersuchungs- und Forschungsanstalten—VDLUFA). For each sample, multiple properties were determined (i.e., crude ash, crude fiber, sodium and potassium contents) however we focus here on nitrogen (N) content, which was expressed in (i) percentage of dry matter; and (ii) in kg ha, after being multiplied by the average dry matter weight at the treatment level. The final traits evaluated comprised dry matter and N-related properties (N% in dry matter and N-uptake in kg ha), since these aspects are of particular interest for the management of nitrogen in intensive grassland systems.
2.3. UAV Hyperspectral and High Resolution Imagery: Acquisition and Pre-Processing
On 2014 and 2017, a total of five UAV flights were performed in the experimental site, always before biomass harvest (DOY 135 and 288 in 2014, and DOY 130, 242 and 299 in 2017). The image acquisition was realized using the WageningenUR Hyperspectral Mapping System (HYMSY), a pushbroom imaging sensor comprising a custom spectrometer (PhotonFocus SM2-D1312 camera—PhotonFocus AG, Lachen, SZ, Switzerland—with a Specim ImSpector V10 2/3 spectrograph—Specim, Spectral Imaging Ltd., Oulu, Finland) and a RGB high resolution photogrammetric camera (Panasonic GX1 16 MP—Panasonic Corp., Osaka, Japan—with 14 mm pancake lens). Further details about the sensor as well as the radiometric and geometric correction of the acquired data can be found in Suomalainen et al. [
21].
In general lines, the main steps involved in the hyperspectral data pre-processing were: (i) Digital Numbers (DNs) conversion to radiance units using dark current and flat field calibration; (ii) radiance conversion to reflectance factors based on measurements taken before each flight of a 25% reflectance Spectralon panel; (iii) geometric correction of the hyperspectral datacube through a direct georeferencing procedure, which required external Digital Surface Model (DSM) and Global Navigation Satellite System-Inertial Navigation System (GNSS-INS) data as auxiliary inputs [
22]. The DSM in this case was obtained from images taken with the RGB camera, using Structure-from-Motion (SfM) algorithm in the photogrammetric software PhotoScan Pro v1.0.0 (currently Metashape; Agisoft LLC, St. Petersburg, Russia). Adjusted camera orientations that matched the surface model were obtained at the same time the high resolution DSM was derived. These adjusted orientations were used to increase accuracy of the GNSS-INS data before geometric correction of the hyperspectral data. The resulting DSM and updated GNSS-INS data were feed together with the hyperspectral datacube to the PARGE algorithm (v3.2beta, ReSe Applications, Schläpfer and Richter [
22]) in order to implement the georeferencing of the hyperspectral images.
The final hyperspectral data used during analysis comprised 101 spectral bands (from 450 up to 950 nm) registered in a 5 nm interval. The Full Width at Half Maximum (FWHM) for the spectral response of each band was approximately 10 nm and the signal measured was smoothed out by resampling the spectra using the same sampling interval but adopting a larger FWHM (30 nm) and assuming a Gaussian spectral response.
An important aspect related to the obtention of the DSMs used in the geometric correction of the hyperspectral data is the parametrization of the dedicated photogrammetric software. For that, image alignment and dense point cloud estimation were implemented using RGB images with full resolution, by setting quality to ‘high’ and ‘ultra-high’ for these steps in the software processing chain, respectively. In addition, camera positioning optimization was performed based on 4 to 8 Ground Control Points (GCPs), depending on the acquisition date, which had their coordinates registered using a Real Time Kinematic (RTK)-GNSS receiver. Also, only focal length, principal point, three radial distortion parameters and two tangential distortion parameters were optimized during processing to avoid overfitting [
23]. Before the camera position optimization, sparse point clouds were filtered based on residuals and reconstruction uncertainty (10% of points were removed in each case), as recommended by [
24].
Finally, considering a flight height of approximately 30 m, GSD between 0.8 and 1.5 cm was obtained for RGB images while for the hyperspectral data GSD varied between 7.8 and 15.6 cm.
2.4. Prediction of Grassland Traits Based on Hyperspectral Imagery across Different Years
Grassland above ground dry matter (DM, dt ha) and nitrogen related traits (N% in DM and N-uptake in kg ha) were estimated based on reflectance factors extracted from the UAV hyperspectral imagery. For that, Partial Least Squares Regression (PLSR) was used to represent the relationship between each grassland trait and the canopy spectral response.
In order to match the support of the spectral data and ground truth observations (i.e., area represented by the measurements), the spectral information was averaged at plot level for DM prediction and at the treatment level (comprising generally four plots) for N-related traits. For all cases, analysis was made assuming three scenarios: first using data from each season separately, (i) 2014 or (ii) 2017; and finally (iii) considering both seasons together, which was used as benchmark to evaluate the generalization potential of the models obtained for each season.
The modelling framework adopted in this study was adapted from approaches described by Singh et al. [
25] and Wang et al. [
26], which include simultaneous estimation of prediction potential and model uncertainty. For that, the complete dataset (comprising 49 observations from each acquisition date for DM, after excluding plots in which the corresponding spectral information acquired was potentially obscured by a metal structure present in the field; or 15 observations from each acquisition date for N-related traits, summarizing information at the treatment level) was randomly split in two parts, 70% used for model calibration and 30% for validation. The calibration set was further divided in two, 2/3 used to fit the prediction models and 1/3 used to test their accuracy. This last sampling procedure was randomly repeated 100 times and the derived models were applied to the test and validation datasets. This procedure allowed not only to estimate the average trait value for each sample but also the associated prediction uncertainty, expressed as standard deviation of prediction.
2.5. Calibration Model Transfer through Active Sample Selection
A calibration set transfer approach was tested as an alternative to increase the portability of prediction models between years, instead of scenario (iii) described in
Section 2.4, which would require a relatively large number of samples from the target date (i.e., equal proportion of samples from source and target domains). Estimations made for a given year/season risk to be inaccurate if the model used was trained on a limited number of samples, or if these samples are acquired in a different year/season. This occurs because a small training samples set with limited variability may not adequately represent a new set of observations. Despite that, a pre-existing dataset can potentially contain useful information for estimating properties of new samples, even if source and target domains are not fully comparable. The approach adopted in this study consisted in adding samples from the target domain (i.e., the acquisition date of interest, from a different growing season/year than that of samples initially available for training) to the dataset used to fit the prediction models (i.e., source domain). With this objective, a framework based on Active Learning [
16,
27] was implemented and evaluated.
The active selection of samples from the target domain to be included in the training dataset was made based on sample diversity and prediction uncertainty. For that, a method well describe by Douak et al. [
17] was adapted, which relies on a pool of regressors (abbreviated PAL). These authors have sampled the training dataset in a given number
of subsets, down sampling the available observations by a given factor. Considering that the obtained subsets were independent, different models were derived using Kernel Ridge Regression. Therefore it was possible to obtain
predictions for each sample from the target domain, and estimate the associated prediction variance for them. Samples with the highest variance were selected for model fitting. It is clear that this approach is very similar to the modelling framework described in
Section 2.4, however in our research we have used PLSR and a more conventional bootstrap-based uncertainty estimation.
Therefore, our method relied first on prediction models already available, which were derived from the different source datasets; i.e., scenarios (i) and (ii) presented in
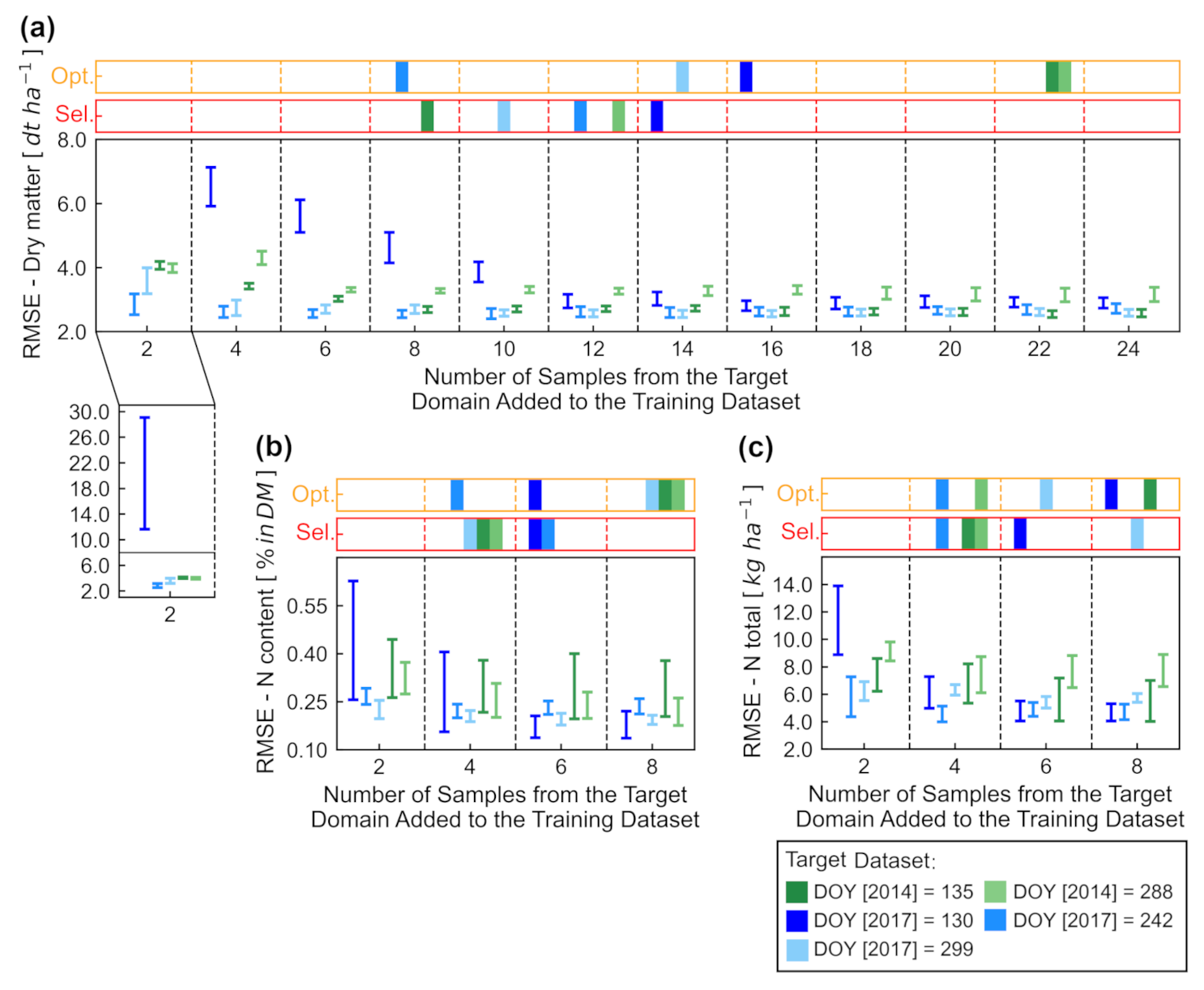
Section 2.4. With them it was possible to estimate vegetation traits and prediction uncertainty for the target samples, acquired on other years/seasons. In addition, K-means clustering was adopted to group each target dataset according to their spectral variability, using results of Principal Components Analyses (i.e., Principal Components with cumulative explained variance of at least 99.5% in each case) and searching to split the target samples into two clusters. After that, the observation with the largest prediction uncertainty (i.e., standard deviation of prediction) was selected for each cluster. These two samples were added to the training data and a new prediction model was derived. This process was repeated until half of the samples available for a given target date were included in the training dataset. The ‘optimal’ number of samples selected to transfer the prediction model to the target domain was chosen considering all cases in the range of the average uncertainty ±20% of the total uncertainty reduction (i.e., smallest uncertainty value subtracted from the largest one considering the multiple transfer datasets compared for each target date). If there were no cases included in the calculated interval, the number of samples resulting in the highest uncertainty was removed and the average calculated again for the remaining cases, until at least one value was selected. The case closest to the median number of included samples was retained (if multiple cases were in the interval). This criterium was chosen after an empirical evaluation (considering the number of samples used, overall uncertainty reduction achieved for the target data and prediction accuracy for out-of-the bag samples in the calibration dataset), which indicated that selecting samples based on an interval around the average uncertainty resulted in a good compromise between minimizing prediction uncertainty and limiting the number of samples required for model transfer.
For comparison, the same number of samples identified as ‘optimal’ in each case was selected considering only the spectral information (samples closest to the centroid of each K-means cluster), ignoring the estimated prediction uncertainty. This allowed to assess the added value of taking into account the prediction uncertainty during model transfer. It is also worth mentioning that ground truth reference was assumed to be always available after samples from the target dataset were selected. This is not possible in practice since all samples used during the ‘optimization’ of the training dataset would need to be processed and analysed in laboratory beforehand, therefore with no advantages over scenario (iii) described in
Section 2.4. This issue could potentially be circumvented by using predictions of the model available or RTM inversion for a first estimation of traits, for example, resulting in values that could be used to replace ground truth during sample selection. However, for brevity, this aspect was not evaluated in this study since the main objective was to assess whether selecting samples based on prediction uncertainty would be beneficial or not in this context.
2.6. Feature Selection for Grassland Traits Retrieval
The vegetation traits evaluated in this study (i.e., biomass and N-related traits) are linked to the canopy spectral response in ways that can be difficult to distinguish, depending on the spectral region and conditions of data acquisition. Therefore, it is relevant to inspect the importance of the multiple spectral bands or regions for the estimation of each specific grassland trait, so differences and similarities between models can be compared. This analysis can also be used to evaluate the performance of the model transfer approach, allowing one to compare the main variables contributing to the predictions when models are derived from distinct training datasets.
With this objective, Variable Importance in the Projection (
; [
28,
29]) was calculated for each model, obtained from the different calibration datasets, and spectral band
j, as described by Equations (
1) and (
2).
where
corresponds to the weight of variable
j and PLS component
f while
represents the sum of squares of explained variance for the component
f and
J number of variables (spectral bands). In addition,
F is the total number of factors,
T is the scores matrix and
b is the inner relation vector of coefficients.
Variables with
greater than one are generally selected as informative. However, considering the uncertainty associated to the prediction models the estimated
values are also uncertain. For this reason the approach described by Afanador et al. [
30] was adopted to derive confidence intervals for the
values. This relatively simple method could easily be combined with the model fitting and uncertainty estimation procedure described in
Section 2.5. In this sense, the overall
and corresponding standard deviation for each individual spectral band were estimated according to Equations (
3) and (
4), respectively.
With
B indicating the number of bootstrap repetitions. The final confidence interval for the
corresponding to each spectral band was determined following a straightforward approach (i.e., Student’s confidence interval), as described in Equation (
5).
where a 90% confidence interval was considered (
= 10%) and
t indicates the appropriate quantile from the
t-distribution with
degrees of freedom. In addition,
indicates the final
value for a given spectral band, which can be derived by fitting a prediction model to the complete training dataset (i.e., without bootstrap) or by adopting
as the final estimate (which was the case). Finally, all features associated to a lower boundary above one for the
confidence interval were retained as informative.
4. Discussion
Grassland traits could be accurately predicted based on UAV hyperspectral imagery, with
of 0.92, 0.58 and 0.91 and
of 3.25 dt ha
, 0.27% and 6.50 kg ha
for dry matter, N content in % of dry matter and N-uptake, respectively (
Figure 2 and
Figure 6). Results reported in the literature for predictions based on spectral data acquired by UAVs are generally comparable to those obtained in our study. For instance, Grüner et al. [
11] achieved relative
between 12.8 and 16.4% of the range of values observed for dry matter in their study. Since these values varied between 0.3 to 7.0 t ha
, in their experiment with legume-grass mixtures, the
obtained was between 0.86 and 1.10 t ha
or 8.6 and 11.0 dt ha
. Therefore, errors were higher than those reported here, however the authors studied a more complex system (i.e., grass-legumes) as well as used a multispectral sensor (Parrot Sequoia—spectral bands in the green, red, red-edge and NIR wavelengths) and RGB imagery instead of a hyperspectral dataset, which might have limited the predictive potential. Another factor that probably contributed to a lower accuracy in their case is the data acquisition in different seasons/years, continuing the work reported in Grüner et al. [
31]. In their previous study, more accurate predictions could be achieved, by focusing on a single season, with
of 0.52 t ha
or 5.2 dt ha
in the best case. Better results were also reported by Michez et al. [
32], using the same multispectral sensor (with 4 spectral bands) to predict grassland biomass and quality, based on spectral features (reflectance factors and Vegetation Indices—VIs) and height, derived using Structure from Motion (SfM) algorithm. In this case, the best predictions for dry matter resulted in
of 0.50 t ha
or 5.0 dt ha
. Other authors have used hyperspectral sensors instead of multispectral cameras and generally reported more accurate predictions, even closer to those obtained in our study. For instance, Viljanen et al. [
2] have estimated dry matter yield with
of 0.34 t ha
or 3.4 dt ha
using narrow spectral bands (approximately 20.0 nm of FWHM) and heigh information derived from images of a tunable hyperspectral camera employed on board of a UAV platform. More recently, Oliveira et al. [
33] have evaluated a comprehensive set of spectral and structural features derived using the same tunable hyperspectral sensor, together with high-resolution RGB imagery, to retrieve grassland yield and quality. In this case,
for predictions of dry matter varied between 0.39 and 0.56 t ha
or 3.9 and 5.6 dt ha
, also in a range close to the results reported here.
Regarding N-related traits, results are frequently communicated in the literature as crude protein content (CP in % of dry matter), considering the nutritional importance of this forage characteristic. CP and N content in the biomass are strongly correlated, with CP content being frequently estimated from N content by multiplying the latter by a factor of 6.25 [
32,
34]. This way,
obtained in our study for N% in terms of CP% can be assumed to be approximately 1.68%. Other authors have achieved
for CP in % of dry matter varying between 0.82% and 2.90% with multispectral datasets [
32,
35,
36]. Also, the number of studies in which hyperspectral sensors on board of UAVs are used to estimate N% or CP% have increased in the last years. In recent studies, the
for predictions of CP% based on hyperspectral images varied between 0.80% and 2.81% [
33,
34,
37,
38], in agreement with results obtained in our study. In general, approaches relying on hyperspectral datasets to retrieve N% or CP% are more accurate than those based on multispectral imagery, similarly to what is observed for dry matter. However, absolute
depends on the range of values in the dataset used to evaluate the model performance. This makes it difficult to compare the results of different studies and many authors also report relative
(i.e.,
normalized by a given measure of central tendency or dispersion). Despite that, the base used for normalization (e.g., average or range) is not always clear and/or the exact number used not informed, which again makes posterior comparison with other studies difficult. For N-uptake, research directly exploring the prediction of this trait based on UAV sensors is less frequent. However, Oliveira et al. [
33] have evaluated the use of hyperspectral imagery to estimate this trait and achieved
of 16.99 kg ha
during validation. These results are comparable to those obtained in our study and corroborate the idea that relatively accurate retrieval is possible not only for dry matter and N content but also directly for N-uptake using UAV-based optical imagery.
One of the main aspects investigated in the present study is the use of empirical models over time, with datasets that do not share exactly the same characteristics of the observations used for model training. This problem is well known by researchers in the machine learning and remote sensing communities and arises from the fact that it is not always possible to describe all variation present in new observations based on a limited number of training samples [
13,
39]. This is also of particular interest to the chemometrics community since it is important to be sure that a given model, developed with an initial laboratory dataset, will work with new data, acquired with different sensors or with the same sensor under varying conditions [
40]. The differences between source (training data) and target (new data) domains in the context of UAV-based vegetation monitoring can be attributed to different factors, for instance: changes in illumination and view geometry, different target properties over time and sensor drift. A robust method to ensure that a prediction model represents well the target domain is to add informative samples from the target domain itself to the training data [
13], the so called Active Learning (AL). This concept has been applied to the retrieval of vegetation traits via Radiative Transfer Model (RTM) inversion [
41]. In this case, the objective was to select combinations of crop traits (samples) in the forward model simulation that would lead to accurate predictions while reducing the training dataset used in a hybrid inversion framework (i.e., combination of RTM and machine learning). In our study, AL was used with a different objective, to reduce the number of samples that would need to be collected and posteriorly analysed in a laboratory.
As described in
Section 2.5, a general (supervised) AL approach was adapted from the methodology described by Douak et al. [
17], which was originally applied to wind speed prediction based on Kernel Ridge Regression. Besides considering prediction uncertainty, we accounted for sample diversity via K-means clustering while selecting candidate samples to add to the calibration dataset. Also, we adopted an empirical uncertainty threshold criterium (medium number of samples in the interval comprising the average uncertainty ±20% of the total uncertainty reduction possible, considering training datasets with different number of samples selected from the target date). While we expected that such straightforward methodology would result in lower uncertainty and increased accuracy, the solution optimality is not guaranteed. Despite that, results presented in
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7 and
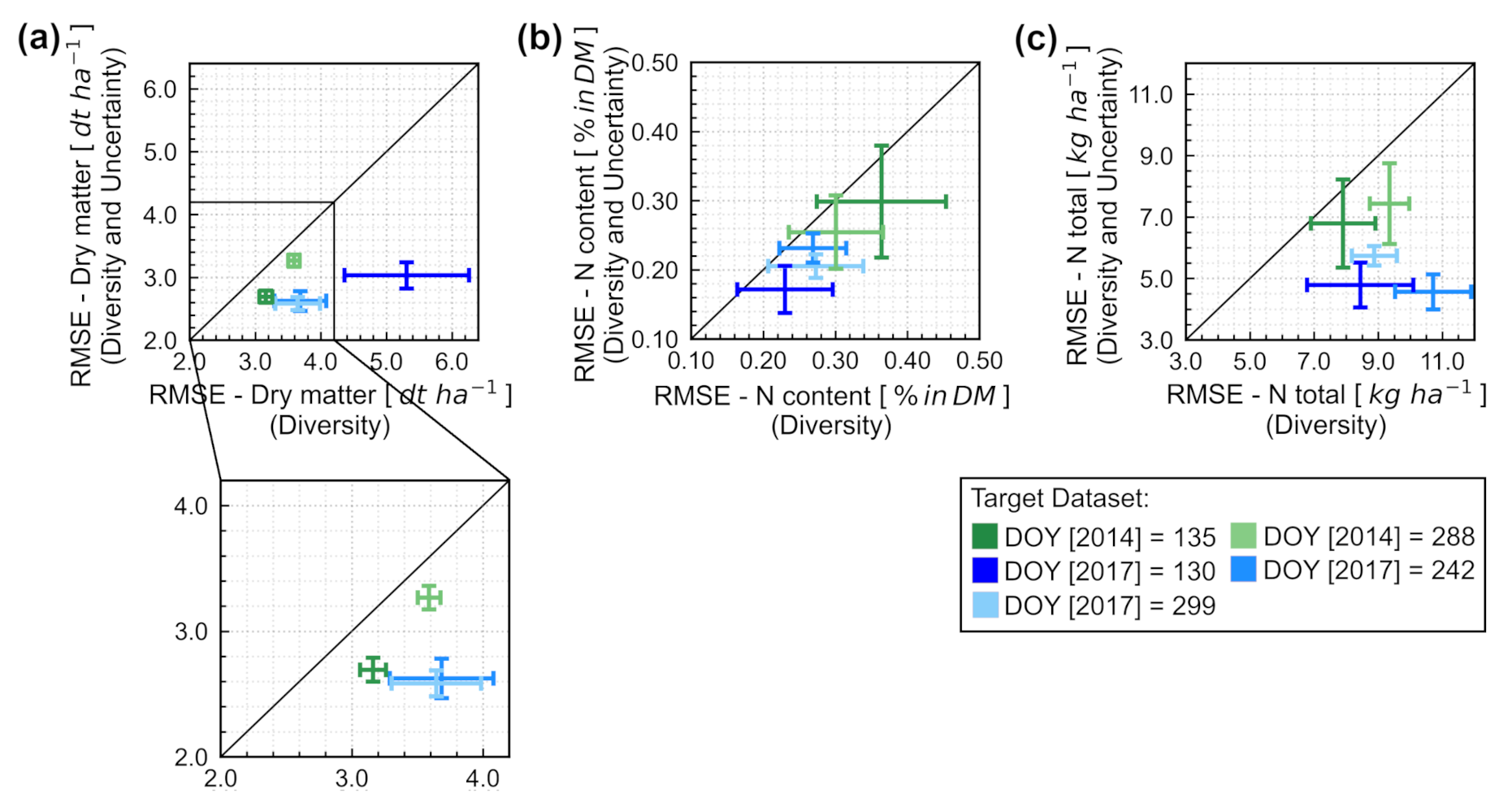
Figure 8 confirm that the calibration transfer was relatively successful, leading to empirical models with satisfactory accuracy while reducing the number of training samples required. In our case, it was possible to reduce the number of samples from the target domain included in the training dataset by up to 77% and 74% for dry matter and N-related traits, respectively (
Figure 4). In addition,
was lower only 20–30% for the true optimal number of samples for transfer (i.e., identified after validation and used as benchmark), in comparison to
obtained with the number of samples selected based on uncertainty reduction, indicating that accuracy loss was relatively small. In practice, this could lead to significant savings in terms of labour and time necessary to extend a pre-existing dataset in order to better describe new observations. A similar approach was used by Wan et al. [
42] to validate random forest models for rice yield prediction based on RGB and multispectral UAV imagery. However, in their case only the sample diversity was taken into account (i.e., Kennard-Stone algorithm was used for sample selection). Other examples of calibration transfer applied to UAV vegetation monitoring and more specifically to grassland traits estimation could not be found in the literature. However, by sharing these initial results and the dataset used in our study [
43], we hope to stimulate further research in this topic, notably with the development of more advanced approaches and/or comparison between methods already available.
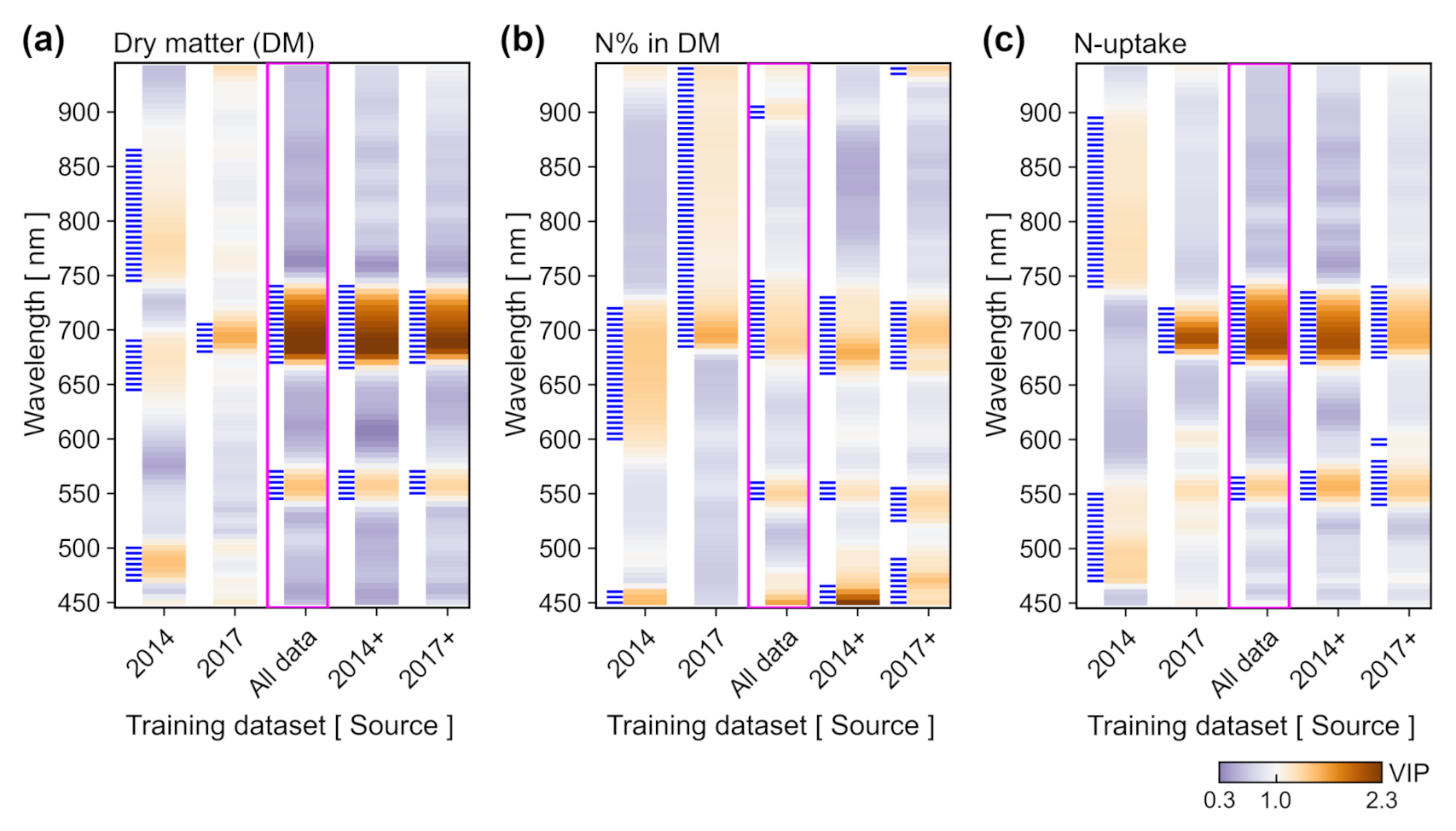
In addition to the estimation of grassland properties based on the complete hyperspectral dataset, the most important spectral features for prediction were identified and selected by calculating a confidence interval associated to
values. This analysis revealed that feature importance for each trait varied between the different source datasets (2014 or 2017), indicating that the obtained models expressed different relationship between spectral information and grassland properties (
Figure 7). This highlights the importance of calibration transfer approaches such as the one evaluated here, in particular for small datasets. Multivariate non-parametric models (such as PLSR) are mostly designed to minimize prediction errors for the training samples. This objective can lead to very good prediction accuracy for observations sharing the characteristics of the source domain. However, the portability of such models to other conditions is questionable [
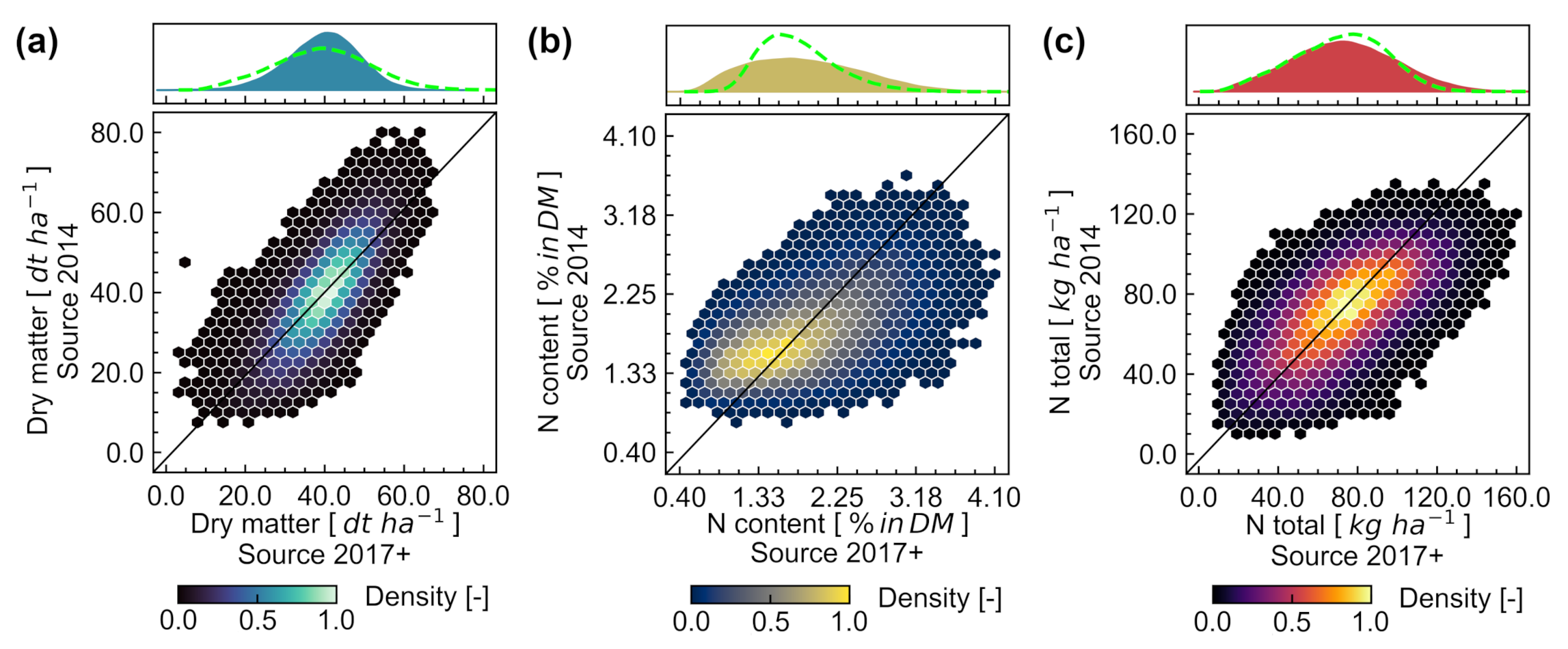
12]. Inspecting the features selected after calibration transfer (i.e., after adding selected samples from the target domain to the training data) it is clear that a similar relationship between spectral information and traits was obtained for the different training datasets. Besides that, the similarity between maps (
Figure 9 and
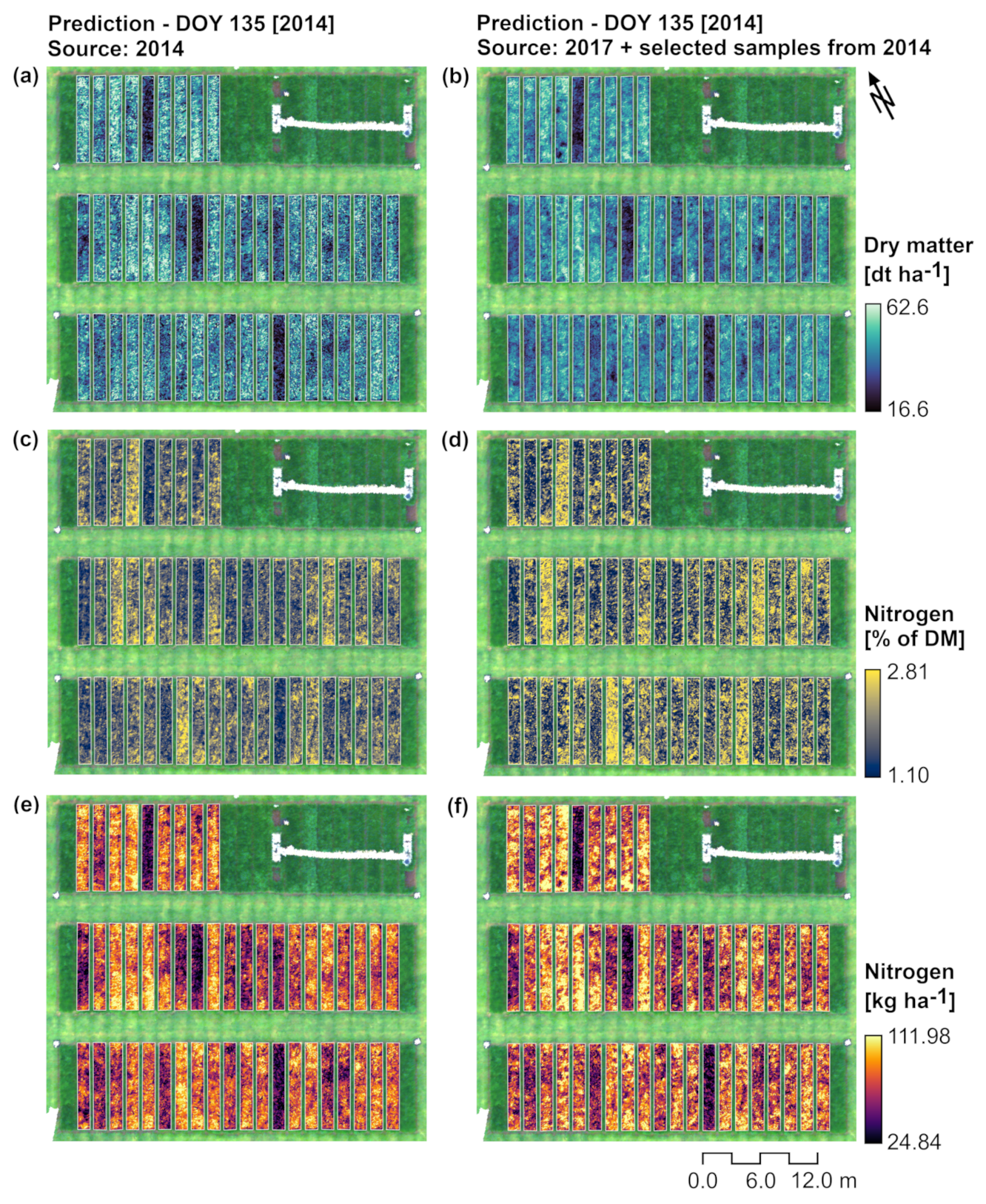
Figure 10) derived from training data acquired the same year of the target date or from data collected in another year after transfer, indicate that the transferred models performed well for an individual date (15 May 2014, used as example), despite being more general. This resulted in pixel-wise representation of similar spatial patterns and overlap of marginal probability densities for values predicted in both cases.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}