Improved Testing of AI-Based Anomaly Detection Systems Using Synthetic Surveillance Data †

 , ,
, , {kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
- A lack of a defined pattern in which an anomaly occurs;
- Noise within the input data;
- As the length of the time series data increases, the computational complexity also increases.
3. ADS-B Data Architecture
3.1. Data Gathering
3.2. Preprocessing
3.3. ML Architecture
4. Automatic Identification System (AIS) Data Architecture
4.1. Data Collection
4.2. Preprocessing
5. Synthetic Anomalous Data Generation Framework
5.1. Background: FDI-T—An FDIA Testing Framework
- ①
- Data acquisition. This component collects legitimate surveillance messages (in Beast or SBS (site base station) formats for ADS-B, and in the NMEA 0183 format for AIS). obtained either from the Internet or a Mode S receiver. Data take the form of a recording—i.e., a sequence of surveillance messages—ordered by reception time.
- ②
- FDIA scenario design. The domain expert defines FDIA scenarios to be applied on a recording obtained via the data acquisition component. FDIA scenarios have various parameters, such as a time window, a list of targeted aircraft, triggering conditions, etc. Once designed, FDIA scenarios are translated into a set of alteration directives, which is the output of the component (an alteration directive is a small modification of the initial recording, usually doable by hand). The scenario design is specified via a domain-specific language (DSL), which is further specified depending on the targeted domain (ATC or VTS). For example, a trajectory modification scenario can be defined as below:
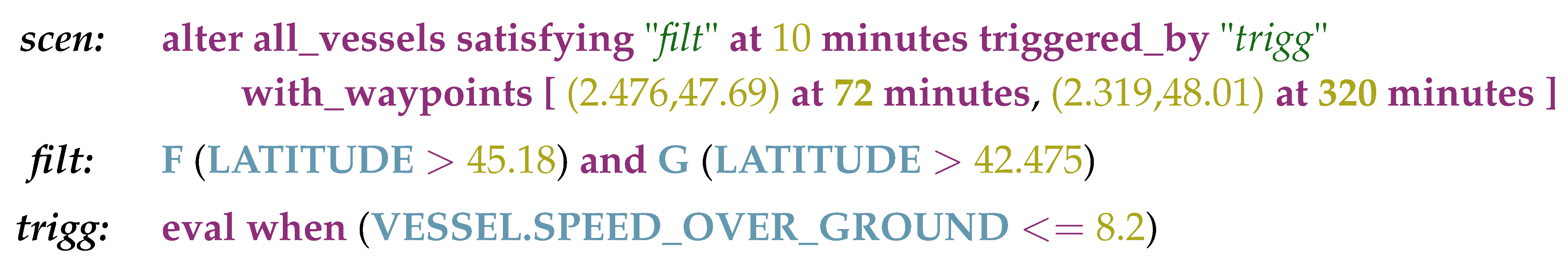
- ③
- Alteration engine. This component takes as its input a set of original sub-recordings, a set of alteration directives and a correspondence matrix that defines which alteration scenario should be applied on which given sub-recording. It then produces altered sub-recordings in the system input format (regarding the ATC domain, this component is thoroughly described in [16]).
- ④
- Execution engine. The obtained altered ATC sub-recordings are fed to the surveillance system as if it were receiving live surveillance messages.
5.2. FDI-T for the Training and Testing of Anomaly Detection Models

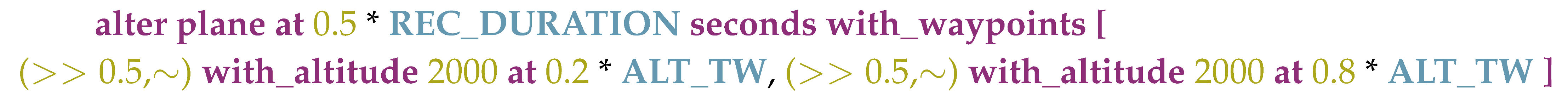
6. Work in Progress and Use-Cases
6.1. ADS-B Datasets and Use-Cases
6.2. AIS Datasets and Associated Learning Objectives
- With self-supervised techniques:AIS intentional shutdown detection: The shutdown of AIS allows a fisher to hide illegal fishing quite easily. The dataset is composed of a model that predicts if a new message should be received soon, or if the connection will be lost for diverse reasons.Rendez-vous prediction: A dataset containing instances of two vessels that eventually approach and stay close for a certain period of time—a so-called rendez-vous situation. The model predicts, given a path of two vessels, if they will meet in the future.Vessel type identification:A very broad dataset, as the model is trained to determine the type of a vessel given its path.
- With FDI-T:Trajectory modification: A dataset that contains random trajectory modifications, speed modifications and/or vessel type modifications. The objective is to detect which parts of the messages have been modified.Rendez-vous hiding with trajectory modification: A dataset created using FDI-T’s trajectory modification feature to mimic real-life scenarios in which two vessels hide a rendez-vous by modifying their trajectory. Indeed, two vessels staying close to each other in the middle of the sea is an easily detectable behavior.Spoofing: A dataset in which each sample contains multiple vessels’ histories; the objective of the model is to spot fake vessels among genuine ones.
7. Conclusions
Acknowledgments
References
- Smith, A.; Cassell, R.; Breen, T.; Hulstrom, R.; Evers, C. Methods to provide system-wide ADS-B back-up, validation and security. In Proceedings of the 25th Digital Avionics Systems Conference, Portland, OR, USA, 15–19 October 2006; pp. 1–7. [Google Scholar]
- IALA Guideline 1082; International Association of Marine Aids to Navigation and Lighthouse: Saint-Germain-en-Laye, France, 2016.
- Balduzzi, M.; Pasta, A.; Wilhoit, K. A Security Evaluation of AIS Automated Identification System; Association for Computing Machinery: New York, NY, USA, 2014. [Google Scholar]
- Strohmeier, M.; Martinovic, I.; Lenders, V. Securing the Air–Ground Link in Aviation. In The Security of Critical Infrastructures: Risk, Resilience and Defense; Keupp, M.M., Ed.; Springer International Publishing: Heidelberg, Germany, 2020. [Google Scholar]
- Habler, E.; Shabtai, A. Using LSTM encoder-decoder algorithm for detecting anomalous ADS-B messages. Comput. Secur. 2018, 78, 155–173. [Google Scholar] [CrossRef]
- Chalapathy, R.; Chawla, S. Deep Learning for Anomaly Detection: A Survey. arXiv 2019, arXiv:1901.03407. [Google Scholar]
- Almalawi, A.; Yu, X.; Tari, Z.; Fahad, A.; Khalil, I. An unsupervised anomaly-based detection approach for integrity attacks on SCADA systems. Comput. Secur. 2014, 46, 94–110. [Google Scholar] [CrossRef]
- Kiran, B.R.; Thomas, D.M.; Parakkal, R. An overview of deep learning based methods for unsupervised and semi-supervised anomaly detection in videos. J. Imaging 2018, 4, 36. [Google Scholar] [CrossRef]
- Almgren, M.; Jonsson, E. Using active learning in intrusion detection. In Proceedings of the 17th IEEE Computer Security Foundations Workshop, Pacific Grove, CA, USA, 30 June 2004; pp. 88–98. [Google Scholar]
- Gornitz, N.; Kloft, M.; Rieck, K.; Brefeld, U. Toward supervised anomaly detection. J. Artif. Intell. Res. 2013, 46, 235–262. [Google Scholar] [CrossRef]
- Basora, L.; Olive, X.; Dubot, T. Recent Advances in Anomaly Detection Methods Applied to Aviation. Aerospace 2019, 6, 117. [Google Scholar] [CrossRef]
- Filipiak, D.; Stróz, M. Anomaly Detection in the Maritime Domain: Comparison of Traditional and Big Data Approach; Technical Report STO-MP-IST-160; NATO Science and Technology Organization: Brussels, Belgium, 2018. [Google Scholar]
- Auslander, B.; Gupta, K.M.; Aha, D.W. Maritime Threat Detection Using Probabilistic Graphical Models; Naval Research Lab: Washington, DC, USA, 2012. [Google Scholar]
- Kim, K.I.; Lee, K.M. Deep Learning-Based Caution Area Traffic Prediction with Automatic Identification System Sensor Data. Sensors 2018, 18, 3172. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, D.; Vadaine, R.; Hajduch, G.; Garello, R.; Fablet, R. GeoTrackNet-A Maritime Anomaly Detector Using Probabilistic Neural Network Representation of AIS Tracks and A Contrario Detection. arXiv 2019, arXiv:1912.00682. [Google Scholar]
- Cretin, A.; Vernotte, A.; Chevrot, A.; Peureux, F.; Legeard, B. Test Data Generation for False Data Injection Attack Testing in Air Traffic Surveillance. In Proceedings of the 2020 IEEE International Conference on Software Testing, Verification and Validation Workshops (ICSTW), Porto, Portugal, 24–28 October 2020. [Google Scholar]
- Schäfer, M.; Strohmeier, M.; Lenders, V.; Martinovic, I.; Wilhelm, M. Bringing Up OpenSky: A Large-scale ADS-B Sensor Network for Research. In Proceedings of the IPSN-14 Proceedings of the 13th International Symposium on Information Processing in Sensor Networks, Berlin, Germany, 15–17 April 2014; pp. 83–94. [Google Scholar]
- Olive, X. Traffic, a toolbox for processing and analysing air traffic data. J. Open Source Softw. 2019, 4, 1518. [Google Scholar] [CrossRef]
- Sun, J.; Ellerbroek, J.; Hoekstra, J. Flight Extraction and Phase Identification for Large Automatic Dependent Surveillance–Broadcast Datasets. J. Aerosp. Inf. Syst. 2017, 14, 566–572. [Google Scholar] [CrossRef]
- Strohmeier, M.; Lenders, V.; Martinovic, I. On the Security of the Automatic Dependent Surveillance- Broadcast Protocol. IEEE Commun. Surv. Tutor. 2015, 17, 1066–1087. [Google Scholar] [CrossRef]
- Cretin, A.; Legeard, B.; Peureux, F.; Vernotte, A. Increasing the Resilience of ATC systems against False Data Injection Attacks using DSL-based Testing. In Proceedings of the ICRAT’18, Barcelona, Spain, 26–29 June 2018; pp. 1–4. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2014, arXiv:1312.6114. [Google Scholar]
- An, J.; Cho, S. Variational autoencoder based anomaly detection using reconstruction probability. Spec. Lect. IE 2015, 2, 1–18. [Google Scholar]
- Olive, X.; Basora, L. Detection and identification of significant events in historical aircraft trajectory data. Transp. Res. Part C Emerg. Technol. 2020, 119, 102737. [Google Scholar] [CrossRef]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chevrot, A.; Vernotte, A.; Bernabe, P.; Cretin, A.; Peureux, F.; Legeard, B. Improved Testing of AI-Based Anomaly Detection Systems Using Synthetic Surveillance Data. Proceedings 2020, 59, 9. https://doi.org/10.3390/proceedings2020059009
Chevrot A, Vernotte A, Bernabe P, Cretin A, Peureux F, Legeard B. Improved Testing of AI-Based Anomaly Detection Systems Using Synthetic Surveillance Data. Proceedings. 2020; 59(1):9. https://doi.org/10.3390/proceedings2020059009
Chicago/Turabian StyleChevrot, Antoine, Alexandre Vernotte, Pierre Bernabe, Aymeric Cretin, Fabien Peureux, and Bruno Legeard. 2020. "Improved Testing of AI-Based Anomaly Detection Systems Using Synthetic Surveillance Data" Proceedings 59, no. 1: 9. https://doi.org/10.3390/proceedings2020059009
APA StyleChevrot, A., Vernotte, A., Bernabe, P., Cretin, A., Peureux, F., & Legeard, B. (2020). Improved Testing of AI-Based Anomaly Detection Systems Using Synthetic Surveillance Data. Proceedings, 59(1), 9. https://doi.org/10.3390/proceedings2020059009