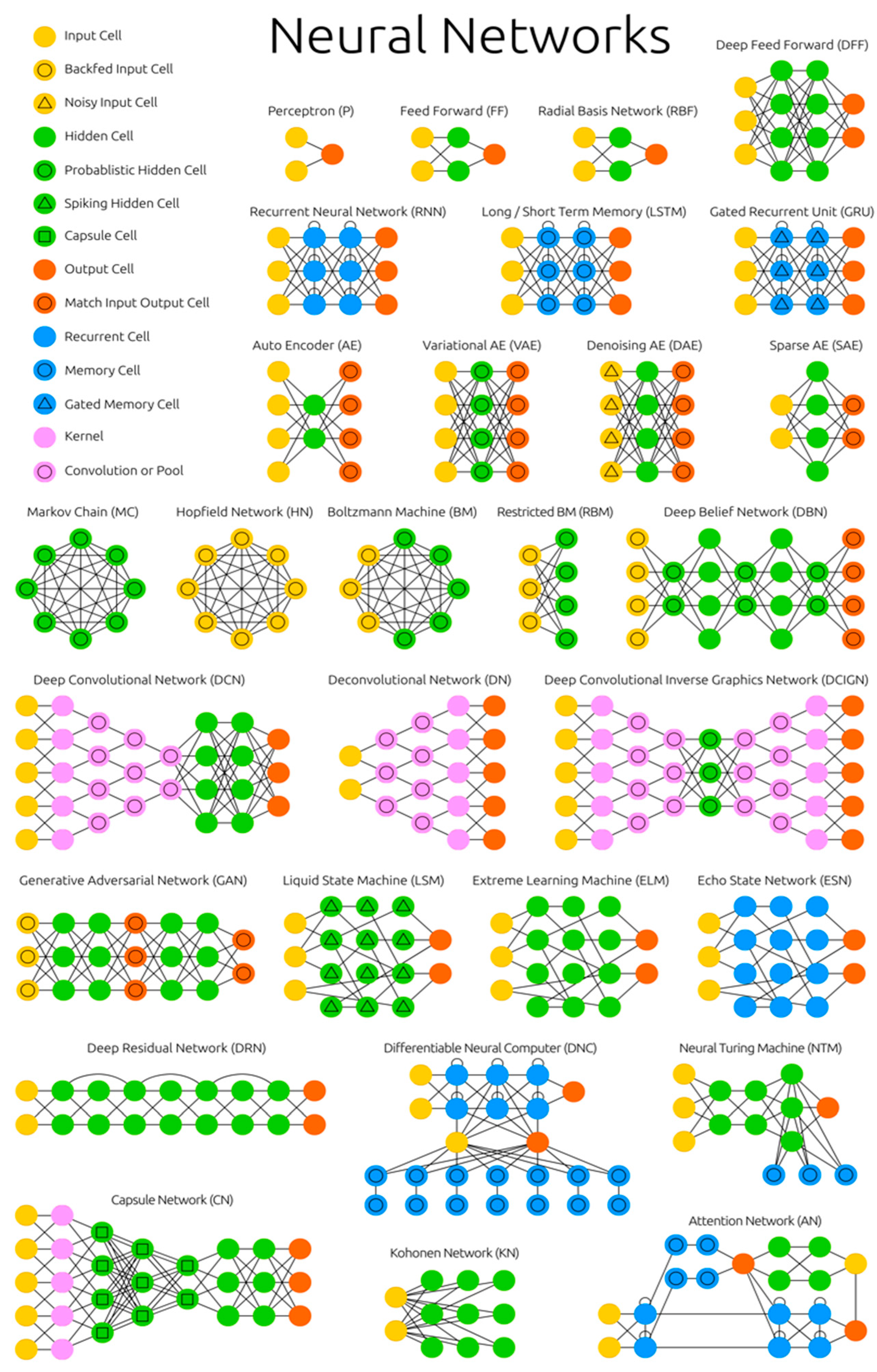
The Neural Network Zoo †

{kind=link}
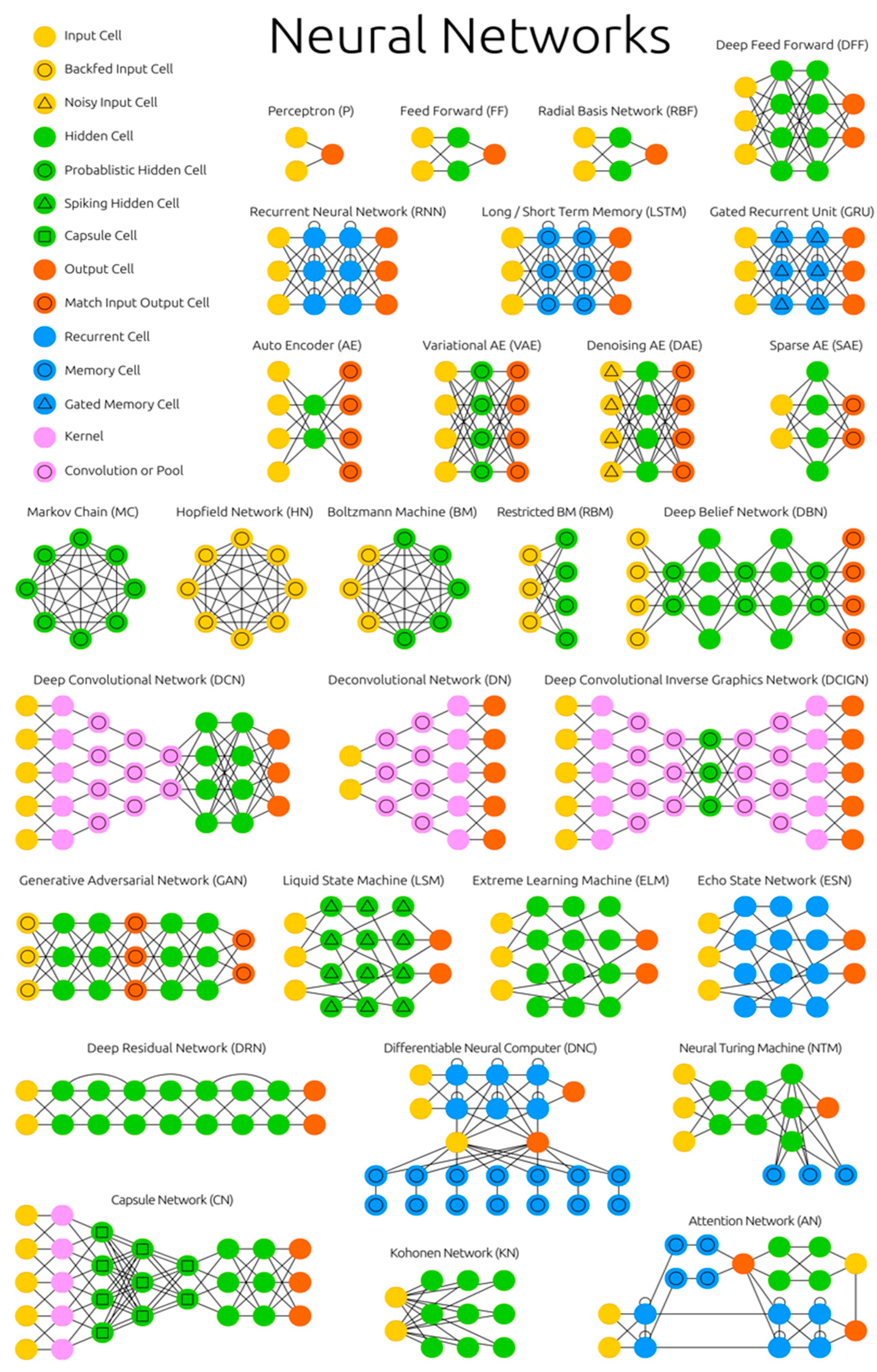{kind=link}
Abstract
:1. Introduction
2. Neural Network Architectures
2.1. Feed Forward Neural Networks
2.2. Recurrent Neural Networks
2.3. Long Short-Term Memory
2.4. Autoencoders
2.5. Hopfield Networks and Boltzmann Machines
2.6. Convolutional Networks
2.7. Generative Adversarial Networks
2.8. Liquid State Machines and Echo State Machines
2.9. Deep Residual Networks
2.10. Neural Turing Machines and Differentiable Neural Computers
2.11. Attention Networks
2.12. Kohonen Networks
2.13. Capsule Networks
3. Conclusions
References
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386. [Google Scholar] [CrossRef] [PubMed]
- Broomhead, D.S.; Lowe, D. Radial Basis Functions, Multi-Variable Functional Interpolation and Adaptive Networks; RSE-MEMO-4148; Royal Signals and Radar Establishment Malvern: Farnborough, UK, 1988. [Google Scholar]
- The Neural Network Zoo. Available online: http://www.asimovinstitute.org/neural-network-zoo (accessed on 10 April 2020).
- Elman, J.L. Finding structure in time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Bourlard, H.; Kamp, Y. Auto-association by multilayer perceptrons and singular value decomposition. Biol. Cybern. 1988, 59, 291–294. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.A. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th International Conference of Machine Learning, Helsinki, Finland, 5–9 July 2008. [Google Scholar]
- Ranzato, M.A.; Poultney, C.; Chopra, S.; Cun, Y.L. Efficient learning of sparse representations with an energy-based model. In Proceedings of the NIPS, Vancouver, BC, Canada, 3–6 December 2007. [Google Scholar]
- Hopfield, J.J. Neural Networks and physical systems with emergent collective computational abilities. Proc. Natl. Acad. Sci. USA 1982, 79, 2554–2558. [Google Scholar] [CrossRef]
- Hinton, G.E.; Sejnowski, T.J. Learning and relearning in Boltzmann machines. Parallel Distrib. Process. Explor. Microstruct. Cogn. 1986, 1, 282–317. [Google Scholar]
- Smolensky, P. Information Processing in Dynamical Systems: Foundations of Harmony Theory; No. CU-CS-321-86; Colorado Univ at Boulder Dept of Computer Science: Boulder, CO, USA, 1986. [Google Scholar]
- Bengio, Y.; Lamblin, P.; Popovici, D.; Larochelle, H. Greedy layer-wise training of deep networks. Adv. Neural Inf. Process. Syst. 2007, 19, 153. [Google Scholar]
- Hayes, B. First links in the Markov chain. Am. Sci. 2013, 101, 252. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Krishnan, D.; Taylor, G.W.; Fergus, R. Deconvolutional networks. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–15 June 2010. [Google Scholar]
- Kulkarni, T.D.; Whitney, W.F.; Kohli, P.; Tenenbaum, J. Deep convolutional inverse graphics network. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2014. [Google Scholar]
- Maas, W.; Natschläger, T.; Markram, H. Real-time computing without stable states: A new framework for neural computation based on pertubations. Neural Comput. 2002, 14, 2531–2560. [Google Scholar] [CrossRef] [PubMed]
- Jaeger, H.; Haas, H. Harnessing nonlinearity: Predicting chaotic systems and saving energy in wireless communication. Science 2004, 304, 78–80. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Graves, A.; Wayne, G.; Danihelke, I. Neuralturing machines. arXiv 2014, arXiv:1410.5401. [Google Scholar]
- Graves, A.; Wayne, G.; Reynolds, M.; Harley, T.; Danihelka, I.; Grabska-Barwińska, A.; Colmenarejo, S.G.; Grefenstette, E.; Ramalho, T.; Agapiou, J. Hybrid computing using a neural network with dynamic external memory. Nature 2016, 538, 471–476. [Google Scholar] [CrossRef]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. SpatialTransformer Network. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 2017–2025. [Google Scholar]
- Kohonen, T. Self-organized formation of topologically correct feature maps. Biol. Cybern. 1982, 43, 59–69. [Google Scholar] [CrossRef]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic Routing Between Capsules. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 3856–3866. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Leijnen, S.; Veen, F.v. The Neural Network Zoo. Proceedings 2020, 47, 9. https://doi.org/10.3390/proceedings2020047009
Leijnen S, Veen Fv. The Neural Network Zoo. Proceedings. 2020; 47(1):9. https://doi.org/10.3390/proceedings2020047009
Chicago/Turabian StyleLeijnen, Stefan, and Fjodor van Veen. 2020. "The Neural Network Zoo" Proceedings 47, no. 1: 9. https://doi.org/10.3390/proceedings2020047009
APA StyleLeijnen, S., & Veen, F. v. (2020). The Neural Network Zoo. Proceedings, 47(1), 9. https://doi.org/10.3390/proceedings2020047009