Fast Tuning of Topic Models: An Application of Rényi Entropy and Renormalization Theory †


Abstract
:1. Introduction
Basics of Topic Modeling
2. Methods
2.1. Entropic Approach for Determining the Optimal Number of Topics
2.2. General Formulation of the Renormalization Approach in Topic Modeling
2.3. Renormalization of Topic Models with Variational Inference
- We choose a pair of topics for merging according to one of the three possible criteria described in Section 2.2. Let us denote the chosen topics by and .
- We merge the chosen topics. The word distribution of a ‘new’ topic resulted from merging of and is stored in column of matrix :where is a digamma function. Then, we normalize the obtained column so that . We also recalculate , which corresponds to the hyper-parameter of the ‘new’ topic. Then, we delete column from matrix and element from vector . Let us note that this step leads to a decrease in the number of topics by one, i.e., we have topics at the end of this step. Further, vector is normalized so that .
- We calculate the overall value of the global Rényi entropy. Since a new topic solution (matrix ) is formed in the previous step, we recalculate the global Rényi entropy for this solution. We refer to entropy calculated according to Equation (2) as global Rényi entropy since it accounts for distributions of all topics.
3. Results
3.1. Description of Datasets and Experiments
- Dataset in Russian (Lenta.ru). This dataset contains news articles in the Russian language where each news item was manually assigned to one of ten topic classes by the dataset provider [10]. However, as some of these topics could be considered folded or correlated (i.e., topic ‘soccer’ is a part of topic ‘sports’), this dataset could be represented by 7–10 topics. We considered a class-balanced subset of this dataset, which consisted of 8624 news texts (containing 23,297 unique words).
- Dataset in English (20 Newsgroups dataset [11]). This well-known dataset contains articles assigned by users to one of 20 newsgroups. Since some of these topics can be unified, this document collection can be represented by 14–20 topics [12]. The dataset is composed of 15,404 documents with 50,948 unique words.
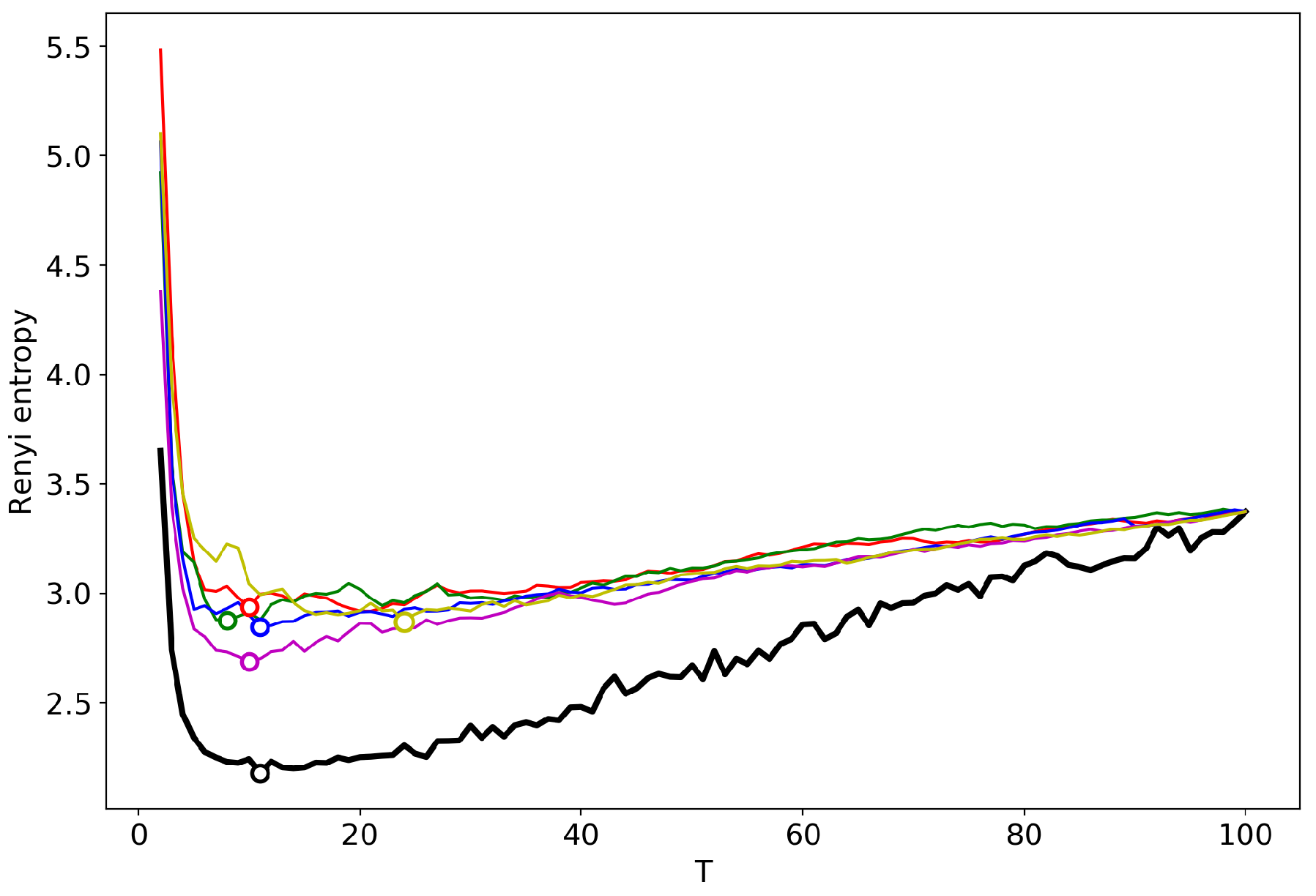
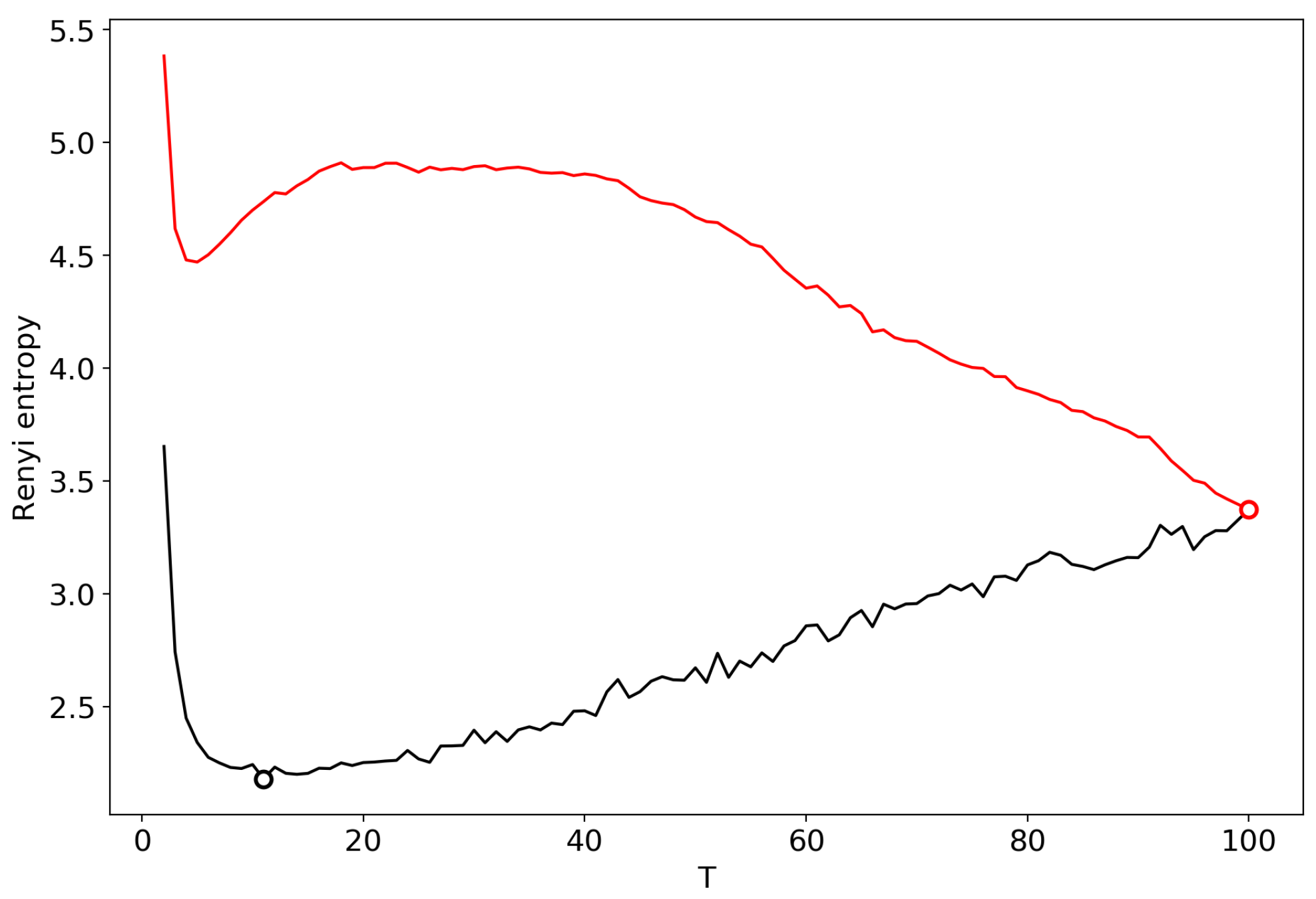
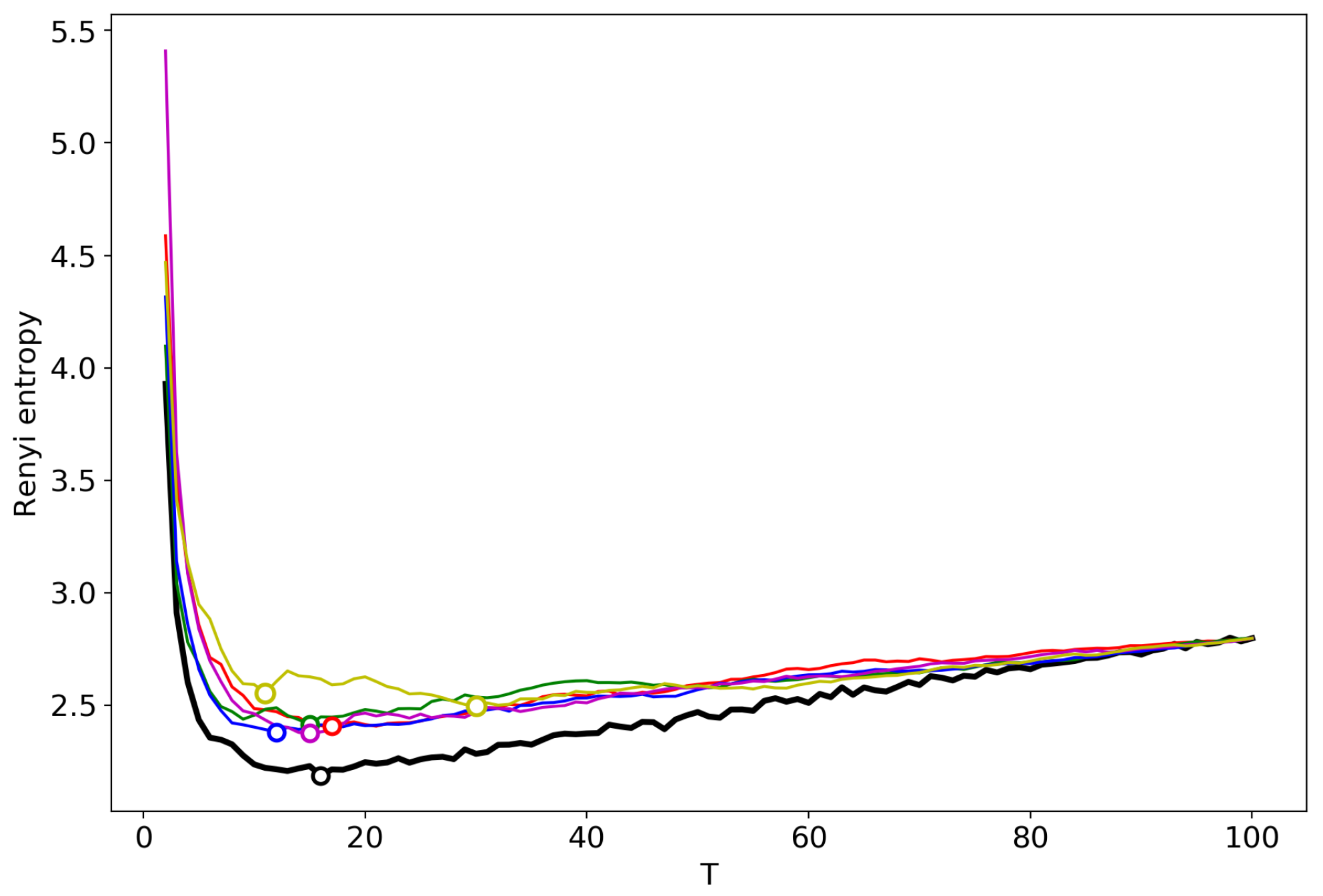
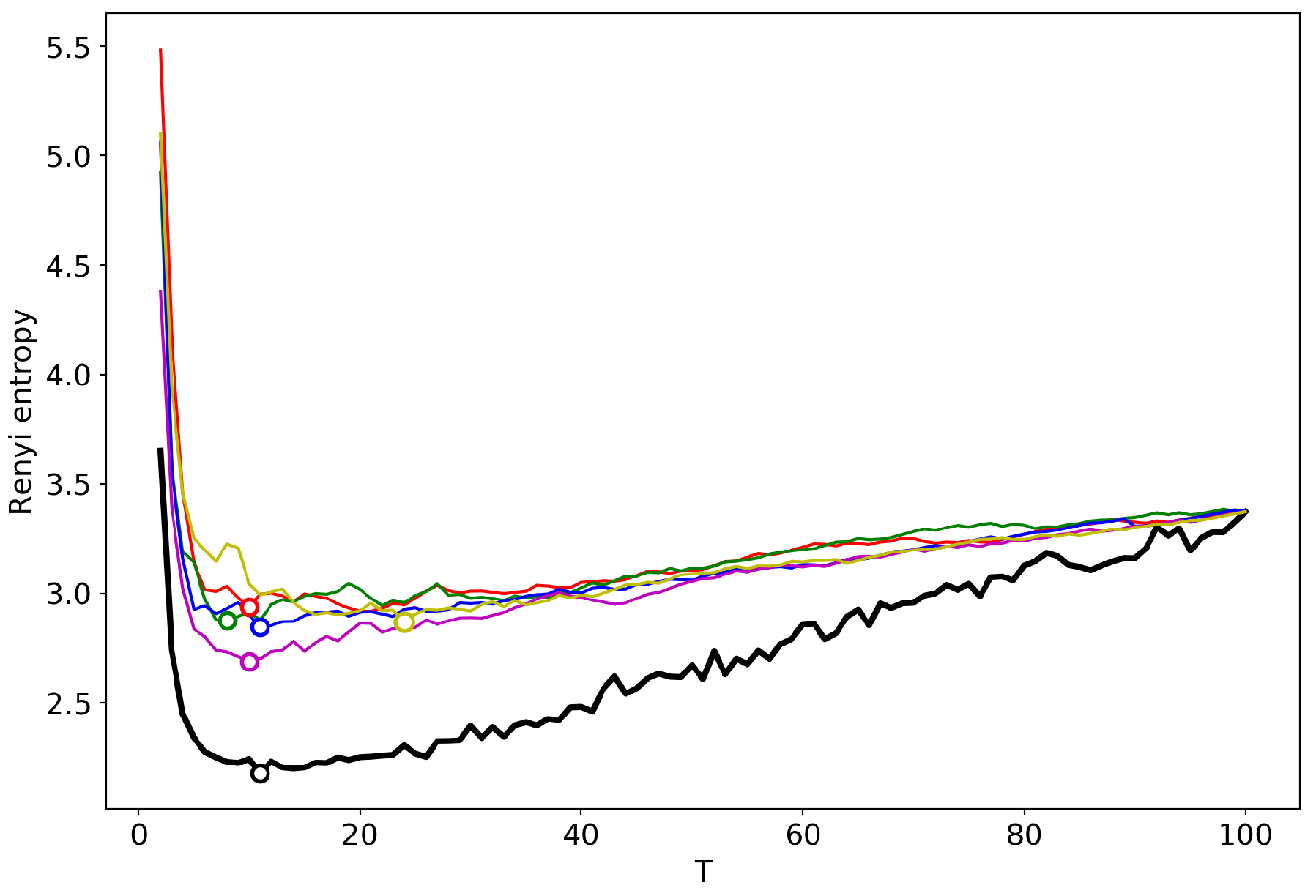
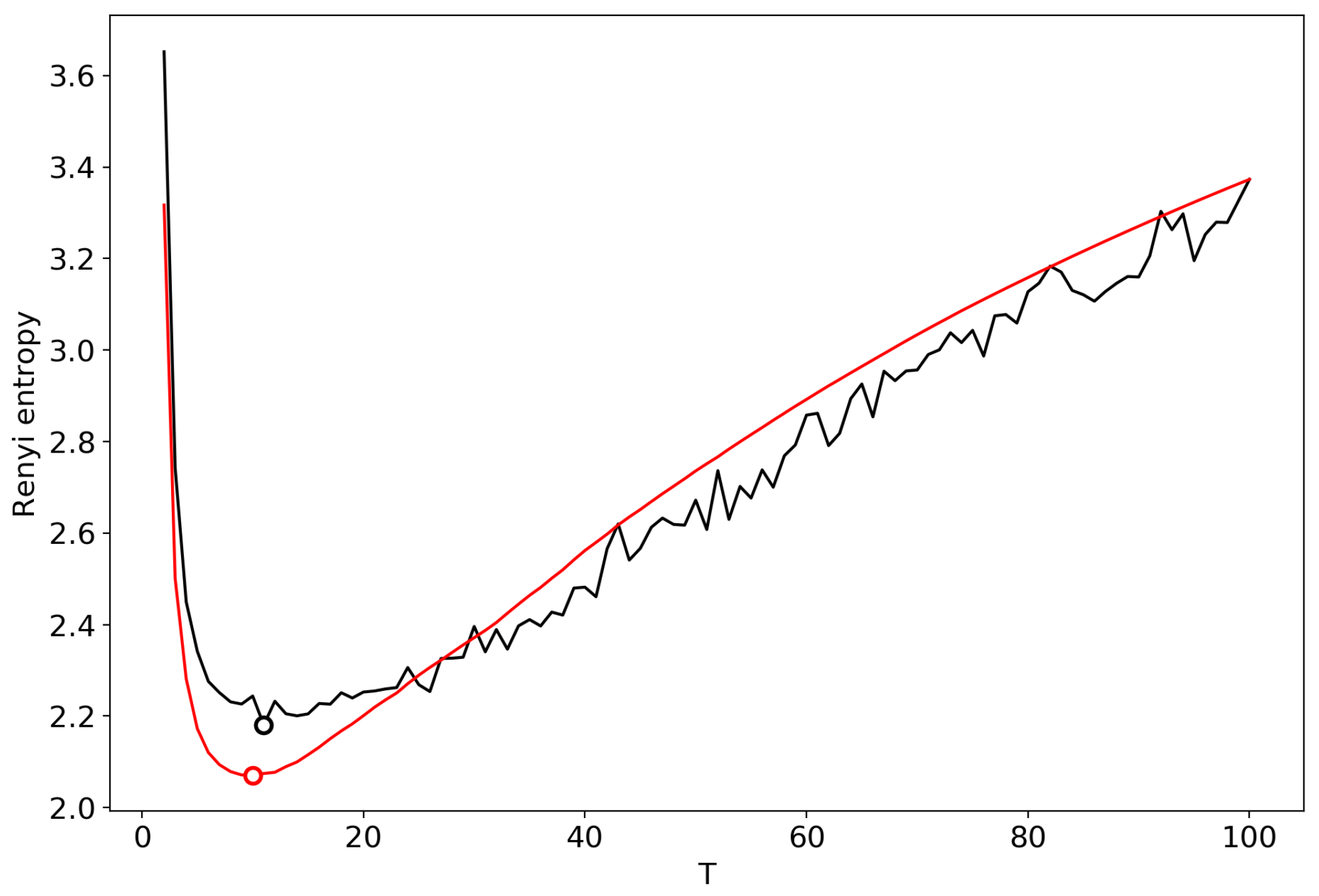
3.2. Results for the Dataset in Russian
3.3. Results for the Dataset in English
3.4. Computational Speed
4. Discussion
Funding
Conflicts of Interest
References
- Roberts, M.E.; Stewart, B.M.; Airoldi, E.M. A Model of Text for Experimentation in the Social Sciences. J. Am. Stat. Assoc. 2016, 111, 988–1003. [Google Scholar] [CrossRef]
- Arun, R.; Suresh, V.; Veni Madhavan, C.E.; Narasimha Murthy, M.N. On Finding the Natural Number of Topics with Latent Dirichlet Allocation: Some Observations. In Advances in Knowledge Discovery and Data Mining; Zaki, M.J., Yu, J.X., Ravindran, B., Pudi, V., Eds.; Springer: Heidelberg, Germany, 2010; pp. 391–402. [Google Scholar]
- Cao, J.; Xia, T.; Li, J.; Zhang, Y.; Tang, S. A Density-based Method for Adaptive LDA Model Selection. Neurocomputing 2009, 72, 1775–1781. [Google Scholar] [CrossRef]
- Koltcov, S. Application of Rényi and Tsallis entropies to topic modeling optimization. Phys. A Stat. Mech. Appl. 2018, 512, 1192–1204. [Google Scholar] [CrossRef]
- Jizba, P.; Arimitsu, T. The world according to Rényi: Thermodynamics of multifractal systems. Ann. Phys. 2004, 312, 17–59. [Google Scholar] [CrossRef]
- Hofmann, T. Probabilistic Latent Semantic Indexing. In Proceedings of the 22Nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval; ACM: New York, NY, USA, 1999; pp. 50–57. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Koltsov, S.; Ignatenko, V.; Koltsova, O. Estimating Topic Modeling Performance with Sharma–Mittal Entropy. Entropy 2019, 21, 660. [Google Scholar] [CrossRef] [PubMed]
- Ignatenko, V.; Koltcov, S.; Staab, S.; Boukhers, Z. Fractal approach for determining the optimal number of topics in the field of topic modeling. J. Phys. Conf. Ser. 2019, 1163, 012025. [Google Scholar] [CrossRef]
- News Dataset from Lenta.Ru. Available online: https://www.kaggle.com/yutkin/corpus-of-russian-news-articles-from-lenta (accessed on 31 October 2019).
- News Dataset from Usenet. Available online: http://qwone.com/~jason/20Newsgroups/ (accessed on 31 October 2019).
- Basu, S.; Davidson, I.; Wagstaff, K. (Eds.) Constrained Clustering: Advances in Algorithms, Theory, and Applications; Taylor & Francis Group: Boca Raton, FL, USA, 2008. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Successive TM Simulations | Renormalization (Random) | Renormalization (Minimum Rényi Entropy) | Renormalization (Minimum KL Divergence) |
|---|---|---|---|---|
| Russian dataset | 780 min | 1 min | 1 min | 4 min |
| English dataset | 1320 min | 3 min | 3 min | 10 min |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koltcov, S.; Ignatenko, V.; Pashakhin, S. Fast Tuning of Topic Models: An Application of Rényi Entropy and Renormalization Theory. Proceedings 2020, 46, 5. https://doi.org/10.3390/ecea-5-06674
Koltcov S, Ignatenko V, Pashakhin S. Fast Tuning of Topic Models: An Application of Rényi Entropy and Renormalization Theory. Proceedings. 2020; 46(1):5. https://doi.org/10.3390/ecea-5-06674
Chicago/Turabian StyleKoltcov, Sergei, Vera Ignatenko, and Sergei Pashakhin. 2020. "Fast Tuning of Topic Models: An Application of Rényi Entropy and Renormalization Theory" Proceedings 46, no. 1: 5. https://doi.org/10.3390/ecea-5-06674
APA StyleKoltcov, S., Ignatenko, V., & Pashakhin, S. (2020). Fast Tuning of Topic Models: An Application of Rényi Entropy and Renormalization Theory. Proceedings, 46(1), 5. https://doi.org/10.3390/ecea-5-06674