Gaussian Processes for Data Fulfilling Linear Differential Equations †


{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. GP Regression for Data from Linear PDEs
2.1. Construction of Kernels for PDEs
2.2. Linear Modeling of Sources
3. Application Cases
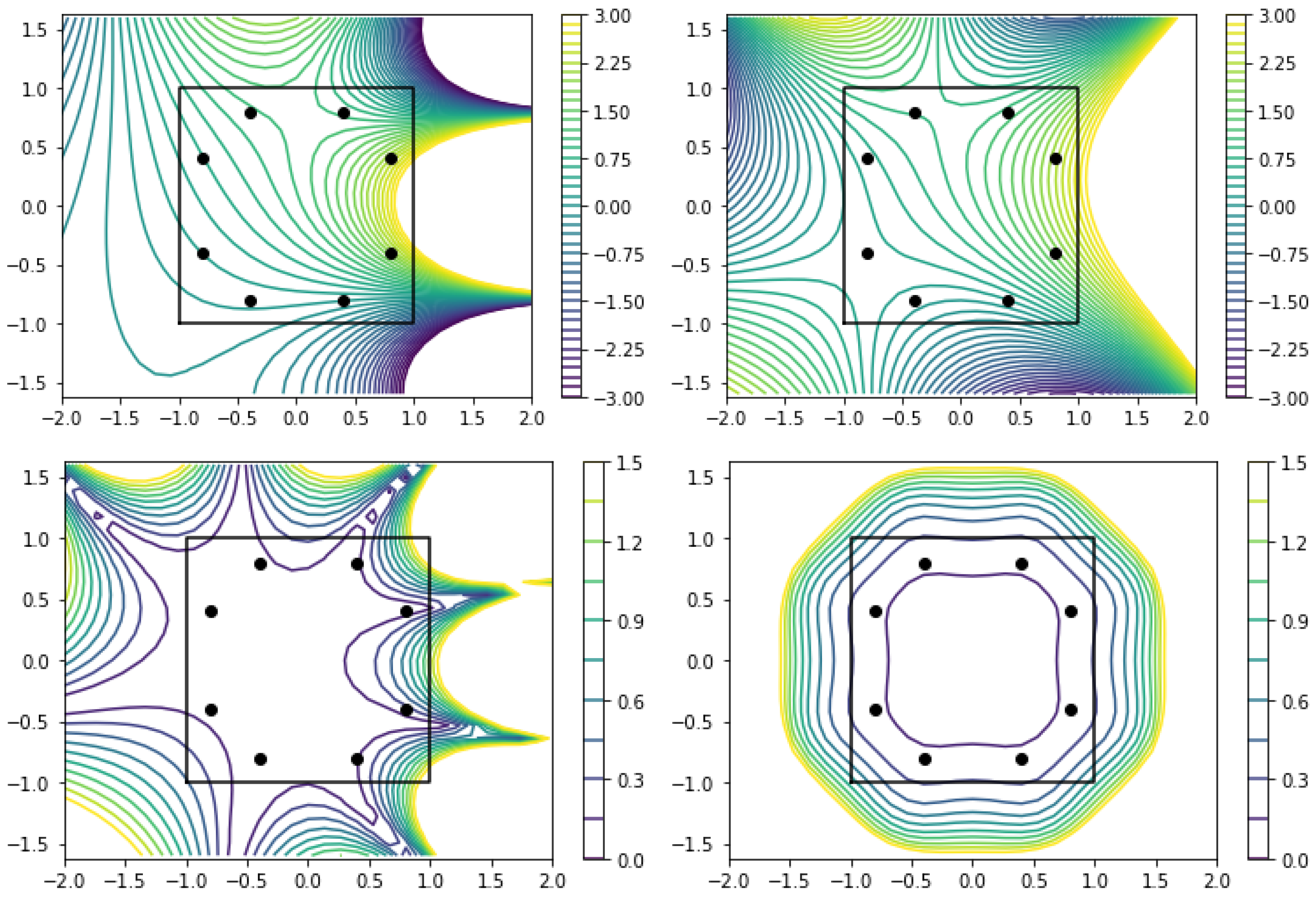
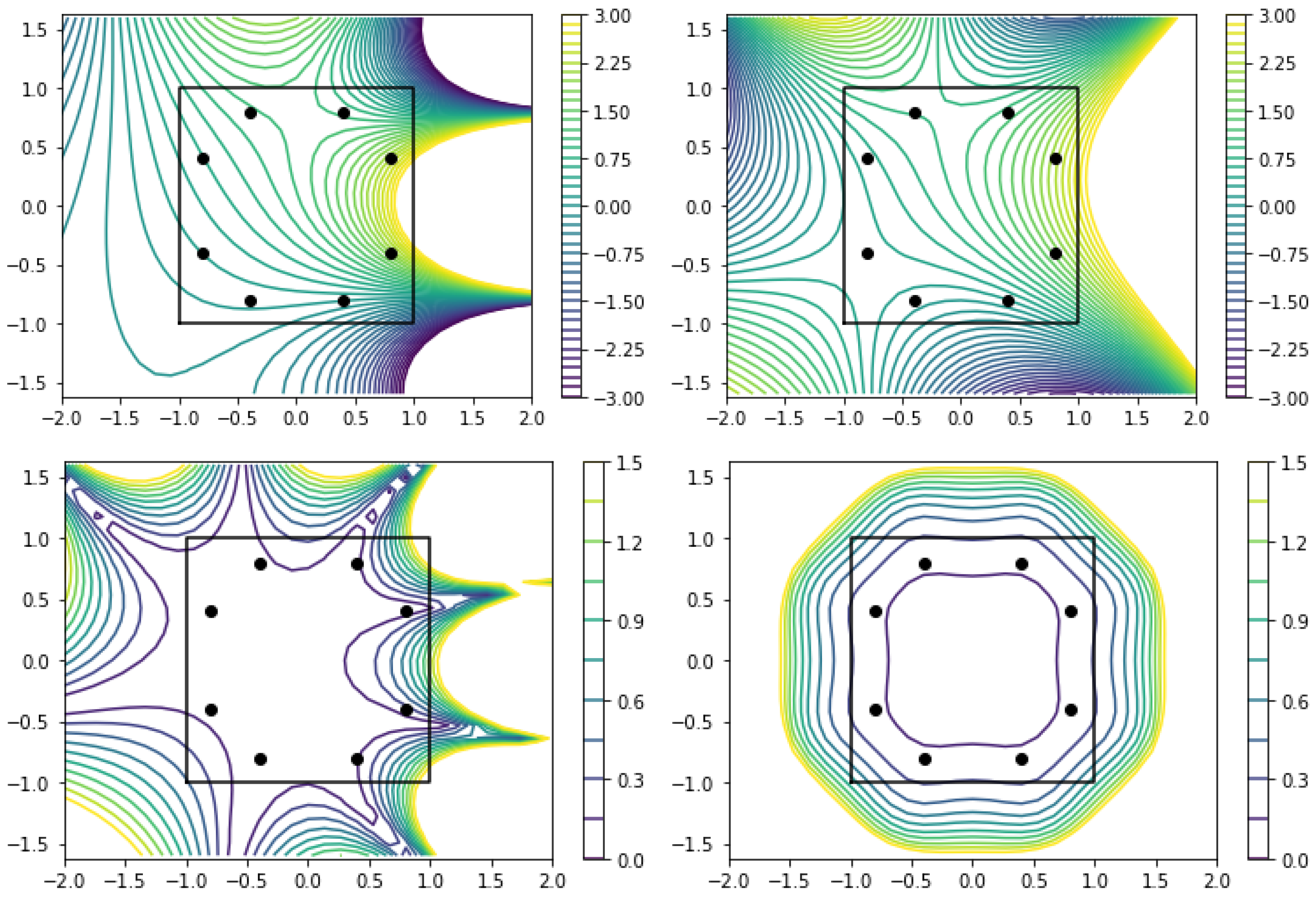
3.1. Laplace’s Equation in Two Dimensions
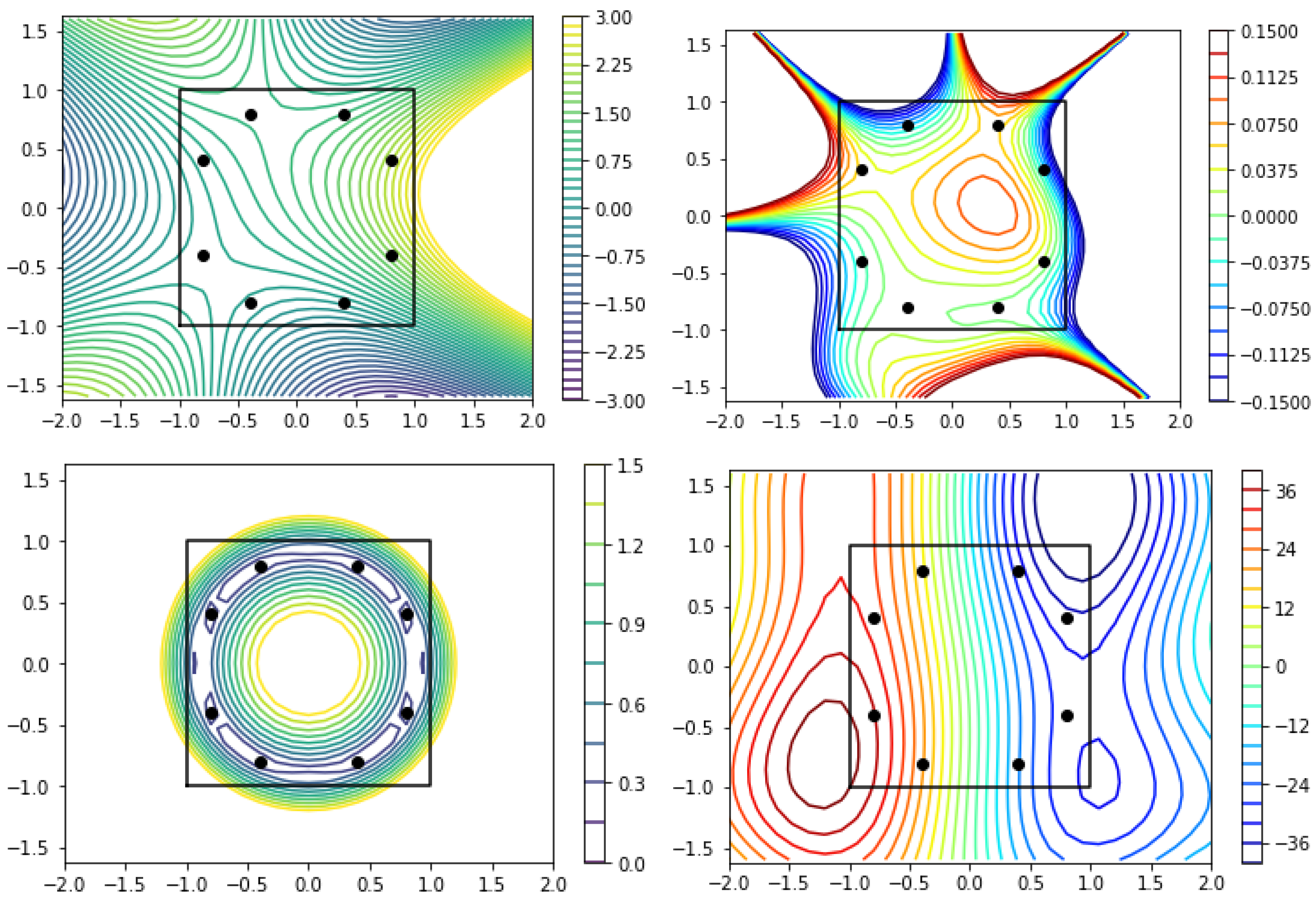
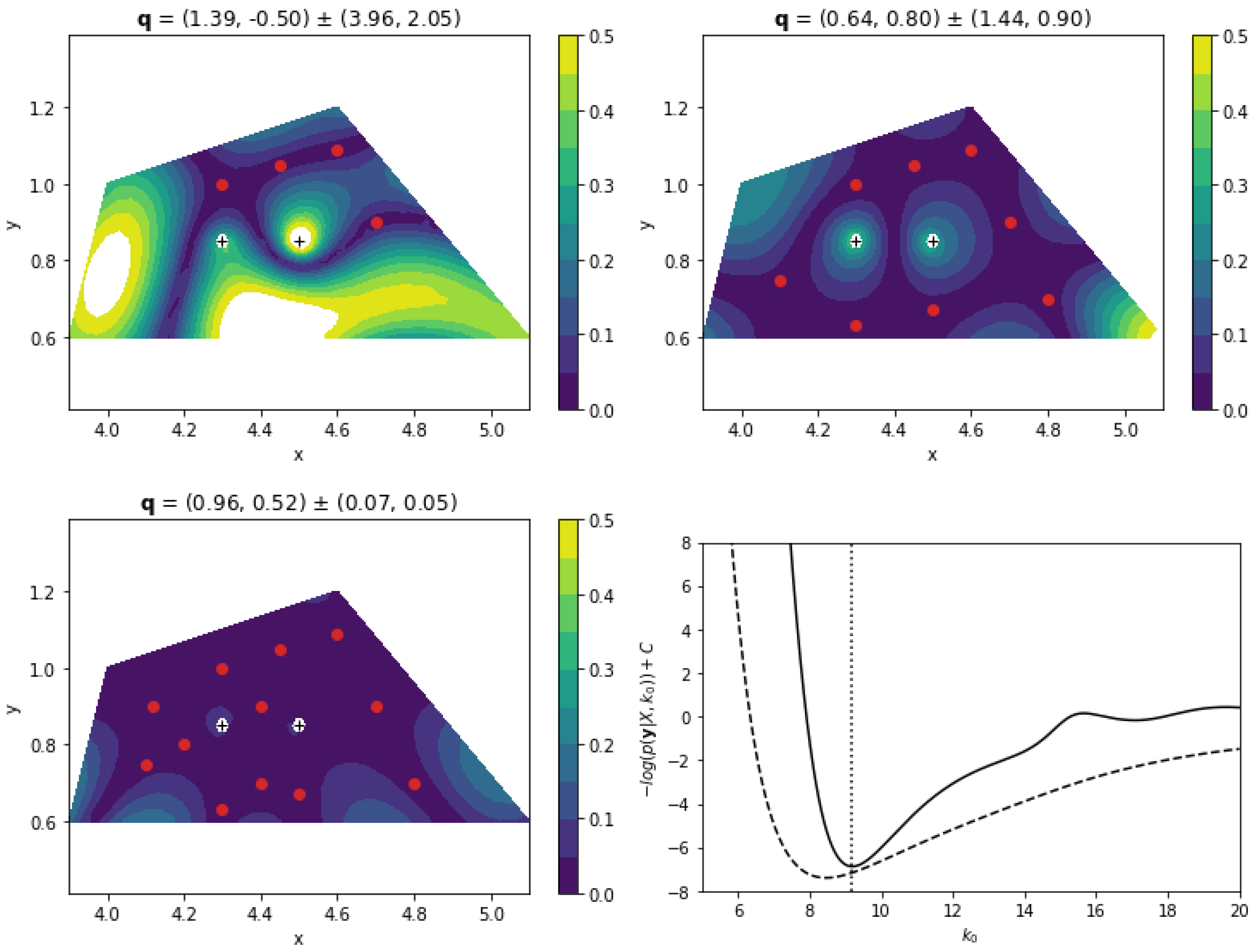
3.2. Helmholtz Equation: Source and Wavenumber Reconstruction
3.3. Heat Equation
4. Summary and Outlook
Acknowledgments
References
- Dong, A. Kriging Variables that Satisfy the Partial Differential Equation ΔZ = Y. Geostatistics 1989, 237–248. [Google Scholar] [CrossRef]
- van den Boogaart, K.G. Kriging for processes solving partial differential equations. In Proceedings of the IAMG2001, Cancun, Mexico, 6–12 September 2001; pp. 1–21. [Google Scholar]
- Graepel, T. Solving noisy linear operator equations by Gaussian processes: Application to ordinary and partial differential equations. In Proceedings of the International Conference on Machine Learning, Washington, DC, USA, 21–24 August 2003; 2003; Fawcett, T., Mishra, N., Eds.; pp. 234–241. [Google Scholar]
- Särkkä, S. Linear Operators and Stochastic Partial Differential Equations in Gaussian Process Regression. In Artificial Neural Networks and Machine Learning; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6792, pp. 151–158. [Google Scholar] [CrossRef]
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Inferring solutions of differential equations using noisy multi-fidelity data. J. Comput. Phys. 2017, 335, 736–746. [Google Scholar] [CrossRef]
- Lackner, K. Computation of ideal MHD equilibria. Comput. Phys. Commun. 1976, 12, 33–44. [Google Scholar] [CrossRef]
- Golberg, M.A. The method of fundamental solutions for Poisson’s equation. Eng. Anal. Bound. Elem. 1995, 16, 205–213. [Google Scholar] [CrossRef]
- Schaback, R.; Wendland, H. Kernel techniques: From machine learning to meshless methods. Acta Numer. 2006, 15, 543–639. [Google Scholar] [CrossRef]
- Mendes, F.M.; da Costa Junior, E.A. Bayesian inference in the numerical solution of Laplace’s equation. AIP Conf. Proc. 2012, 1443, 72–79. [Google Scholar] [CrossRef]
- Cockayne, J.; Oates, C.; Sullivan, T.; Girolami, M. Probabilistic Numerical Methods for Partial Differential Equations and Bayesian Inverse Problems. arXiv 2016, arXiv:1605.07811. [Google Scholar]
- Albert, C. Physics-informed transfer path analysis with parameter estimation using Gaussian processes. In Proceedings of the 23rd International Congress on Acoustics, Aachen, Germany, 9–13 September 2019. [Google Scholar]
- O’Hagan, A. Curve Fitting and Optimal Design for Prediction. J. R. Stat. Soc. Ser. B 1978, 40, 1–24. [Google Scholar] [CrossRef]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006. [Google Scholar] [CrossRef]
- Narcowich, F.J.; Ward, J.D. Generalized Hermite Interpolation via Matrix-Valued Conditionally Positive Definite Functions. Math. Comput. 1994, 63, 661. [Google Scholar] [CrossRef]
- Macêdo, I.; Castro, R. Learning divergence-free and curl-free vector fields with matrix-valued kernels. Available online: http://preprint.impa.br/FullText/Macedo__Thu_Oct_21_16_38_10_BRDT_2010/macedo-MVRBFs.pdf (accessed on 30 June 2019).
- Cobb, A.D.; Everett, R.; Markham, A.; Roberts, S.J. Identifying Sources and Sinks in the Presence of Multiple Agents with Gaussian Process Vector Calculus. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1254–1262. [Google Scholar] [CrossRef]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Albert, C.G. Gaussian Processes for Data Fulfilling Linear Differential Equations . Proceedings 2019, 33, 5. https://doi.org/10.3390/proceedings2019033005
Albert CG. Gaussian Processes for Data Fulfilling Linear Differential Equations . Proceedings. 2019; 33(1):5. https://doi.org/10.3390/proceedings2019033005
Chicago/Turabian StyleAlbert, Christopher G. 2019. "Gaussian Processes for Data Fulfilling Linear Differential Equations " Proceedings 33, no. 1: 5. https://doi.org/10.3390/proceedings2019033005
APA StyleAlbert, C. G. (2019). Gaussian Processes for Data Fulfilling Linear Differential Equations . Proceedings, 33(1), 5. https://doi.org/10.3390/proceedings2019033005