A Sequential Marginal Likelihood Approximation Using Stochastic Gradients †


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Sequential Marginal Likelihood Estimation
3. Stochastic Gradient Hamiltonian Monte Carlo
4. Experiments
4.1. Linear Regression
4.2. Logistic Regression
4.3. Gaussian Mixture Model
5. Results and Discussion
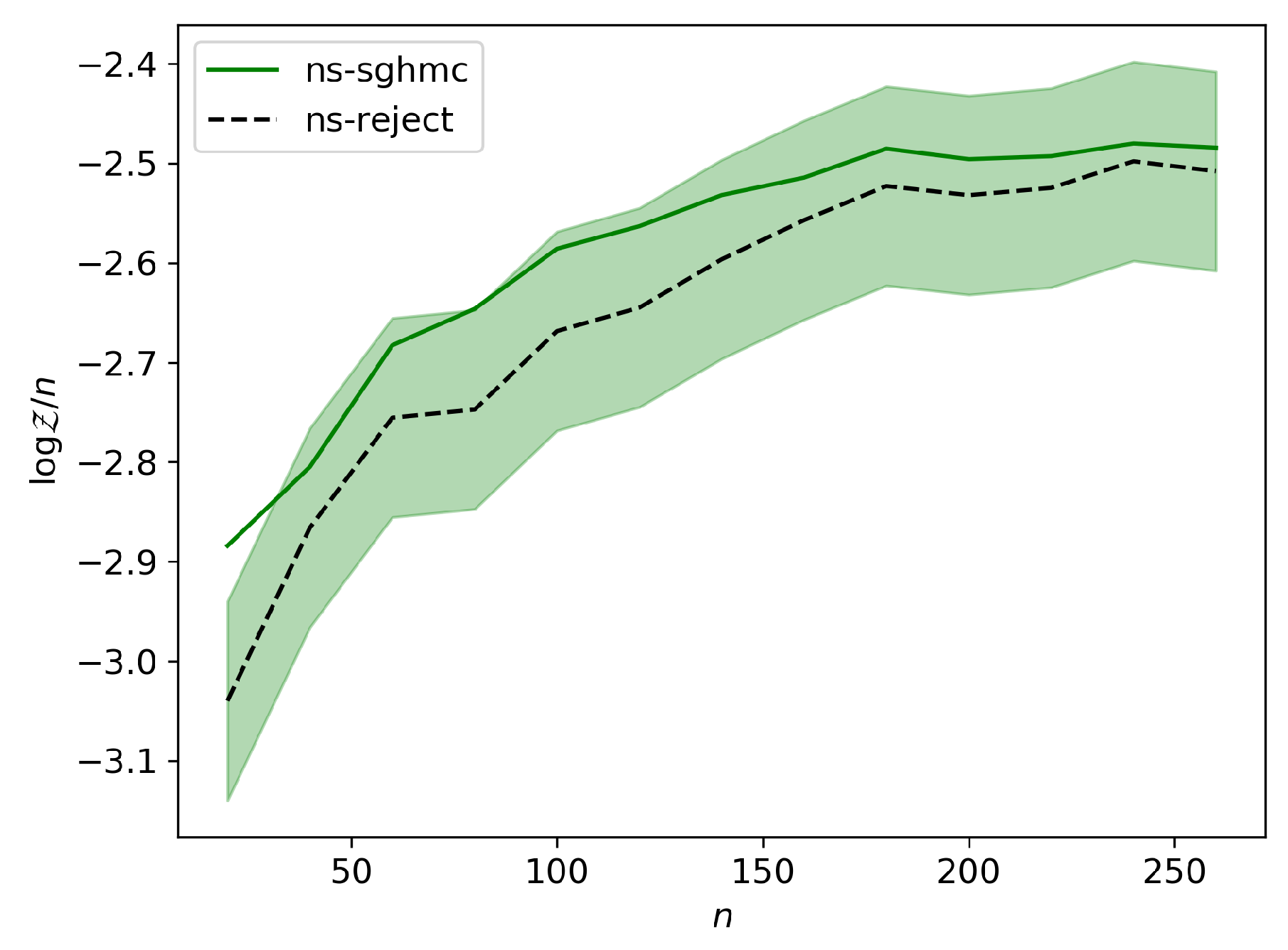
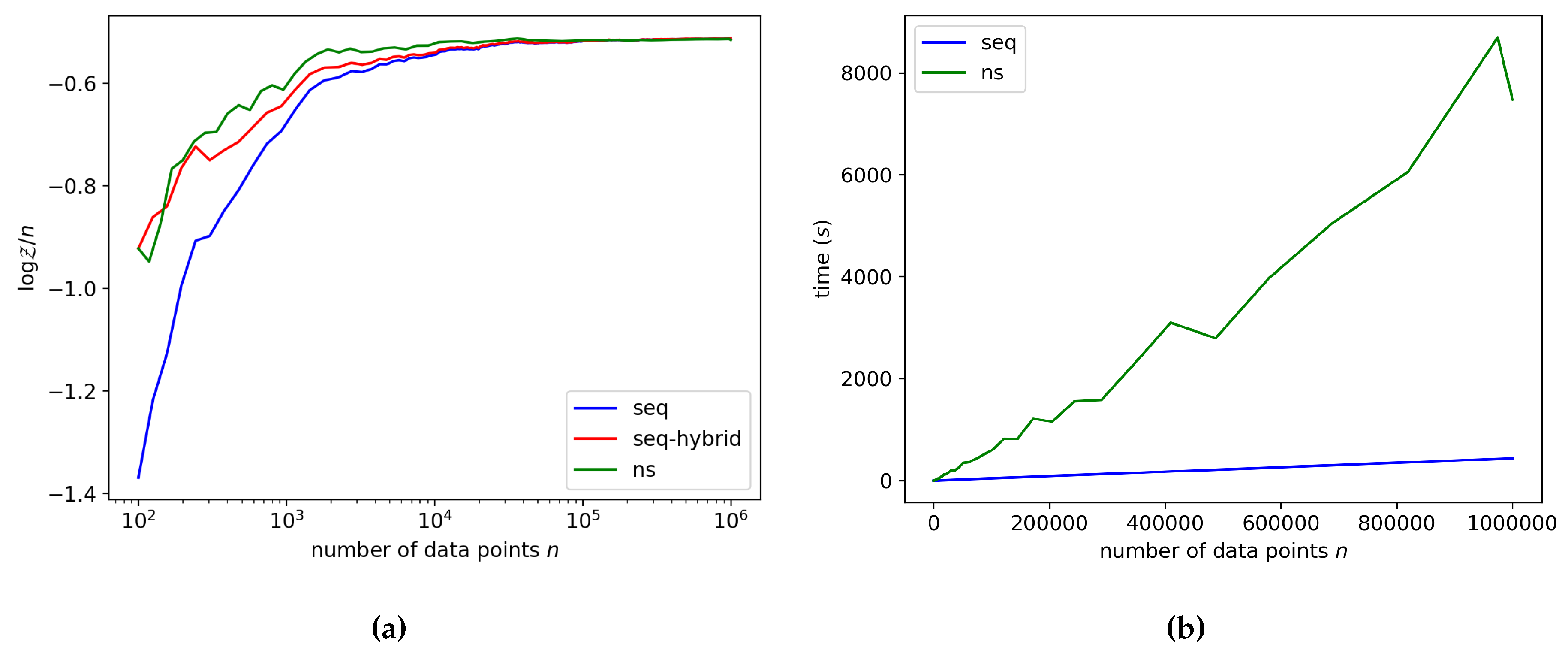
5.1. Linear Regression
5.2. Logistic Regression
5.3. Gaussian Mixture Model
6. Materials and Methods
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| AIS | Annealed importance sampling |
| MCMC | Markov chain Monte Carlo |
| ML | Marginal likelihood |
| NS | Nested sampling |
| SGHMC | Stochastic gradient Hamiltonian Monte Carlo |
Appendix A
References
- Barber, D. Bayesian Reasoning and Machine Learning; Cambridge University Press: New York, NY, USA, 2012. [Google Scholar]
- Skilling, J. Nested sampling for general Bayesian computation. Bayesian Anal. 2006, 1, 833–859, doi:10.1214/06-BA127. [Google Scholar] [CrossRef]
- Neal, R.M. Annealed Importance Sampling. arXiv 1998, arXiv:physics/9803008. [Google Scholar]
- Welling, M.; Teh, Y.W. Bayesian Learning via Stochastic Gradient Langevin Dynamics. In Proceedings of the 28th International Conference on Machine Learning, ICML 2011, Bellevue, WA, USA, 28 June–2 July 2011; Getoor, L., Scheffer, T., Eds.; Omnipress: Madison, WI, USA, 2011; pp. 681–688. [Google Scholar]
- Naesseth, C.A.; Lindsten, F.; Schön, T.B. Elements of Sequential Monte Carlo. arXiv 2019, arXiv:1903.04797. [Google Scholar]
- Gordon, N.J.; Salmond, D.J.; Smith, A.F.M. Novel approach to nonlinear/non-Gaussian Bayesian state estimation. IEE Proc. F Radar Signal Process. 1993, 140, 107–113, doi:10.1049/ip-f-2.1993.0015. [Google Scholar] [CrossRef]
- Wallach, H.M.; Murray, I.; Salakhutdinov, R.; Mimno, D. Evaluation Methods for Topic Models. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; ACM: New York, NY, USA, 2009; pp. 1105–1112, doi:10.1145/1553374.1553515. [Google Scholar] [CrossRef]
- Grosse, R.B.; Ghahramani, Z.; Adams, R.P. Sandwiching the marginal likelihood using bidirectional Monte Carlo. arXiv 2015, arXiv:1511.02543. [Google Scholar]
- Chen, T.; Fox, E.; Guestrin, C. Stochastic Gradient Hamiltonian Monte Carlo. In Proceedings of the 31st International Conference on Machine Learning, Beijing, China, 21–26 June 2014; Volume 5. [Google Scholar]
- Durrett, R. Stochastic Calculus: A Practical Introduction; Probability and Stochastics Series; CRC Press: Boca Raton, FL, USA, 1996; pp. 177–207. [Google Scholar]
- Gardiner, C.W. Handbook of Stochastic Methods for Physics, Chemistry and the Natural Sciences, 3rd ed.; Volume 13, Springer Series in Synergetics; Springer: Berlin, Germany, 2004; p. xviii+415. [Google Scholar]
- Zhang, R.; Li, C.; Zhang, J.; Chen, C.; Wilson, A.G. Cyclical Stochastic Gradient MCMC for Bayesian Deep Learning. arXiv 2019, arXiv:1902.03932. [Google Scholar]
- Ma, Y.A.; Chen, T.; Fox, E.B. A Complete Recipe for Stochastic Gradient MCMC. arXiv 2015, arXiv:1506.04696. [Google Scholar]
- Springenberg, J.T.; Klein, A.; Falkner, S.; Hutter, F. Bayesian Optimization with Robust Bayesian Neural Networks. In Advances in Neural Information Processing Systems 29; Lee, D.D., Sugiyama, M., Luxburg, U.V., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: Barcelona, Spain, 2016; pp. 4134–4142. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in PyTorch. Available online: https://openreview.net/pdJsrmfCZ (accessed on 24 June 2019).
- Skilling, J. Bayesian Computation in Big Spaces-Nested Sampling and Galilean Monte Carlo. AIP Conf. Proc. 2012, 1443, 145–156, doi:10.1063/1.3703630. [Google Scholar] [CrossRef]


© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cameron, S.A.; Eggers, H.C.; Kroon, S. A Sequential Marginal Likelihood Approximation Using Stochastic Gradients. Proceedings 2019, 33, 18. https://doi.org/10.3390/proceedings2019033018
Cameron SA, Eggers HC, Kroon S. A Sequential Marginal Likelihood Approximation Using Stochastic Gradients. Proceedings. 2019; 33(1):18. https://doi.org/10.3390/proceedings2019033018
Chicago/Turabian StyleCameron, Scott A., Hans C. Eggers, and Steve Kroon. 2019. "A Sequential Marginal Likelihood Approximation Using Stochastic Gradients" Proceedings 33, no. 1: 18. https://doi.org/10.3390/proceedings2019033018
APA StyleCameron, S. A., Eggers, H. C., & Kroon, S. (2019). A Sequential Marginal Likelihood Approximation Using Stochastic Gradients. Proceedings, 33(1), 18. https://doi.org/10.3390/proceedings2019033018