Low-Power Pedestrian Detection System on FPGA †


Abstract
:1. Introduction
2. Related Works
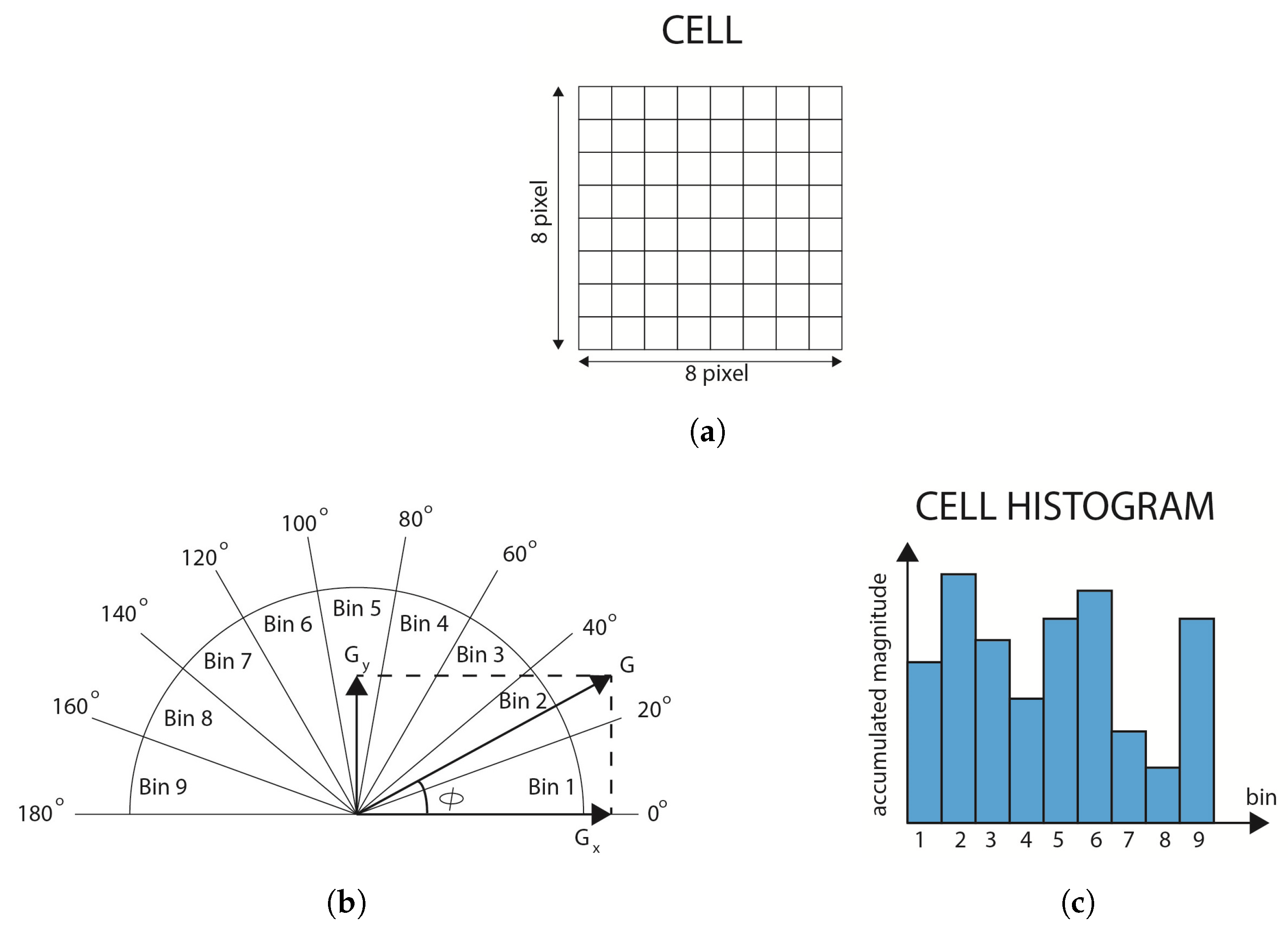
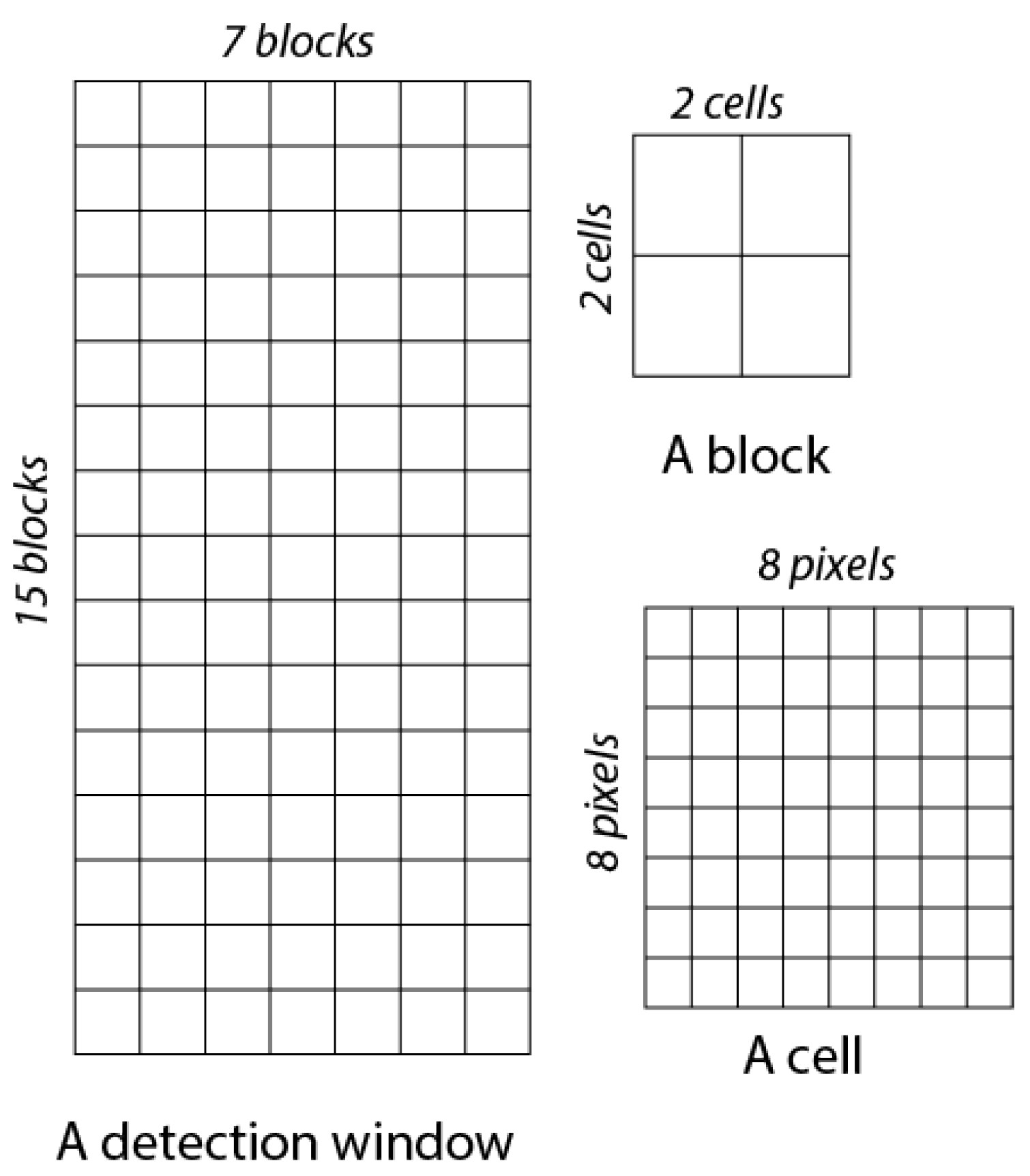
3. HOG Overview
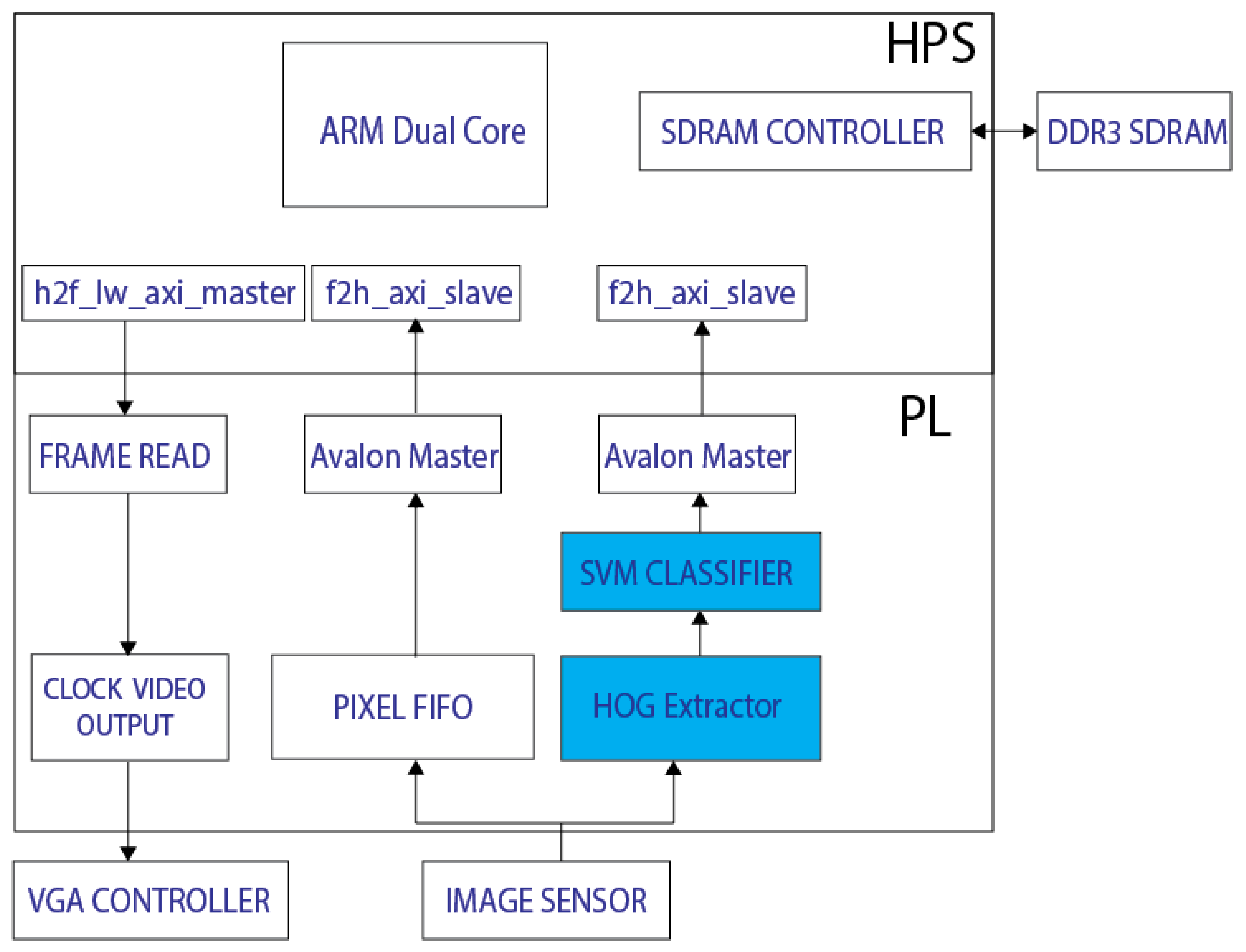
4. Implementation
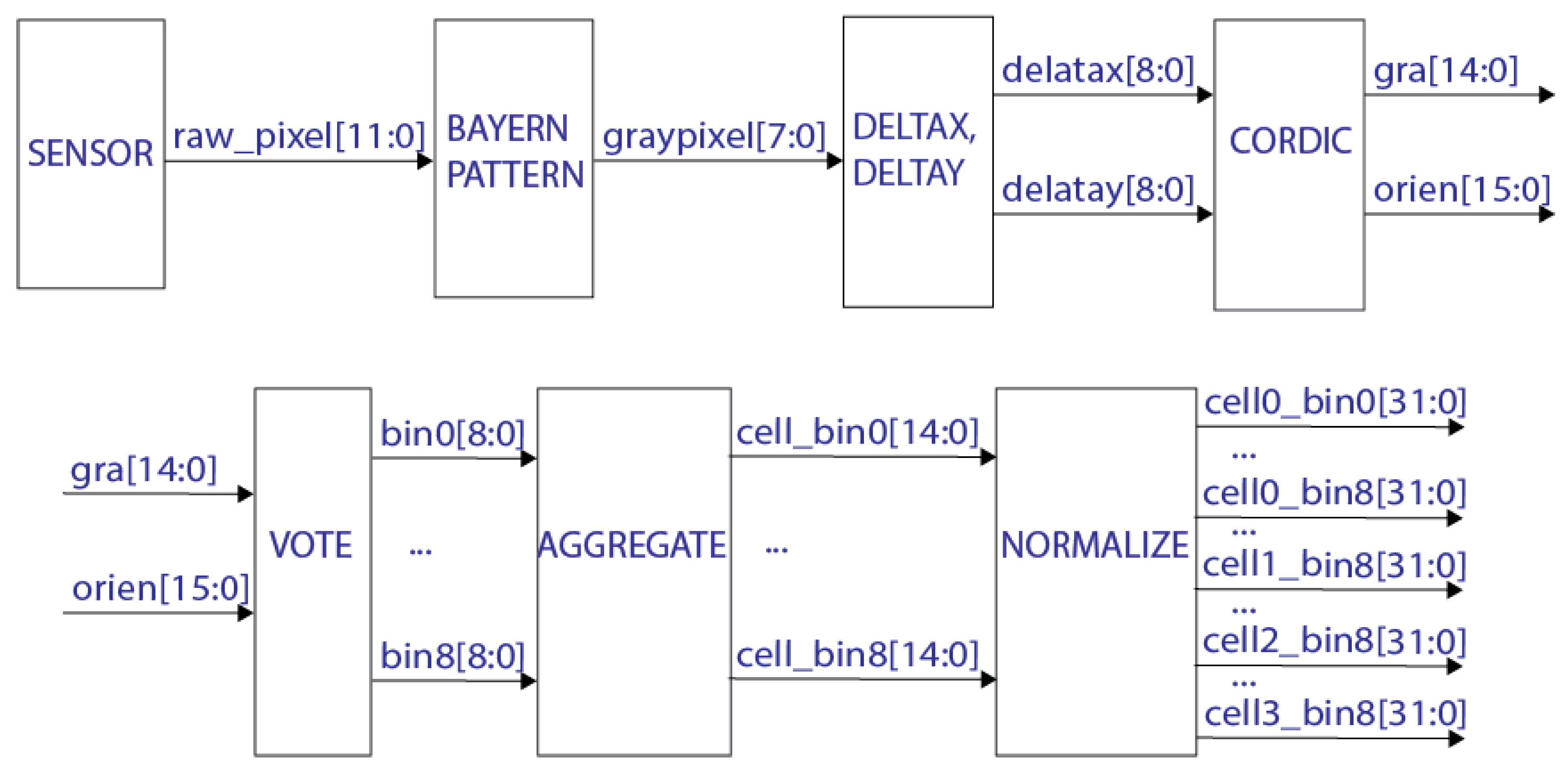
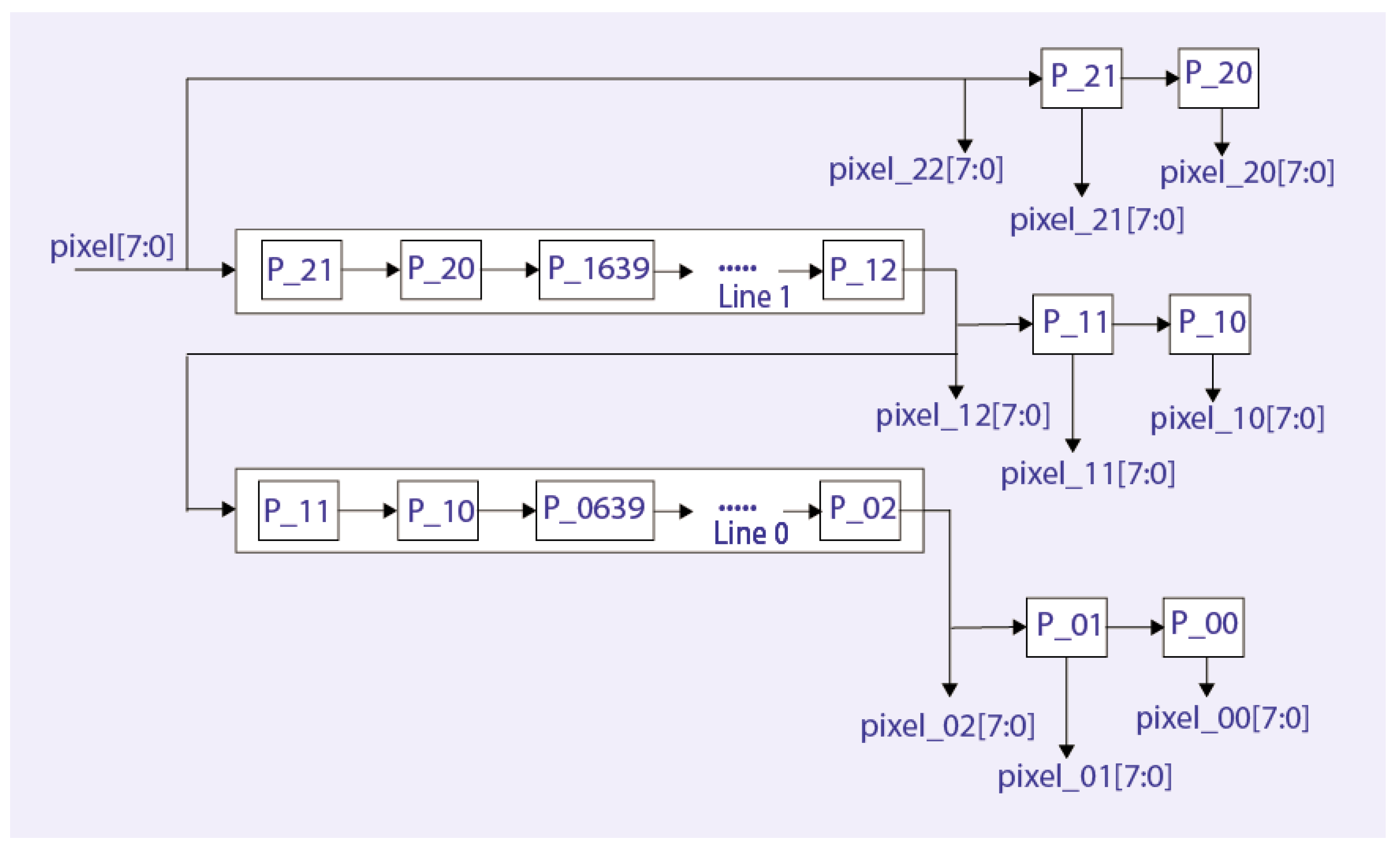
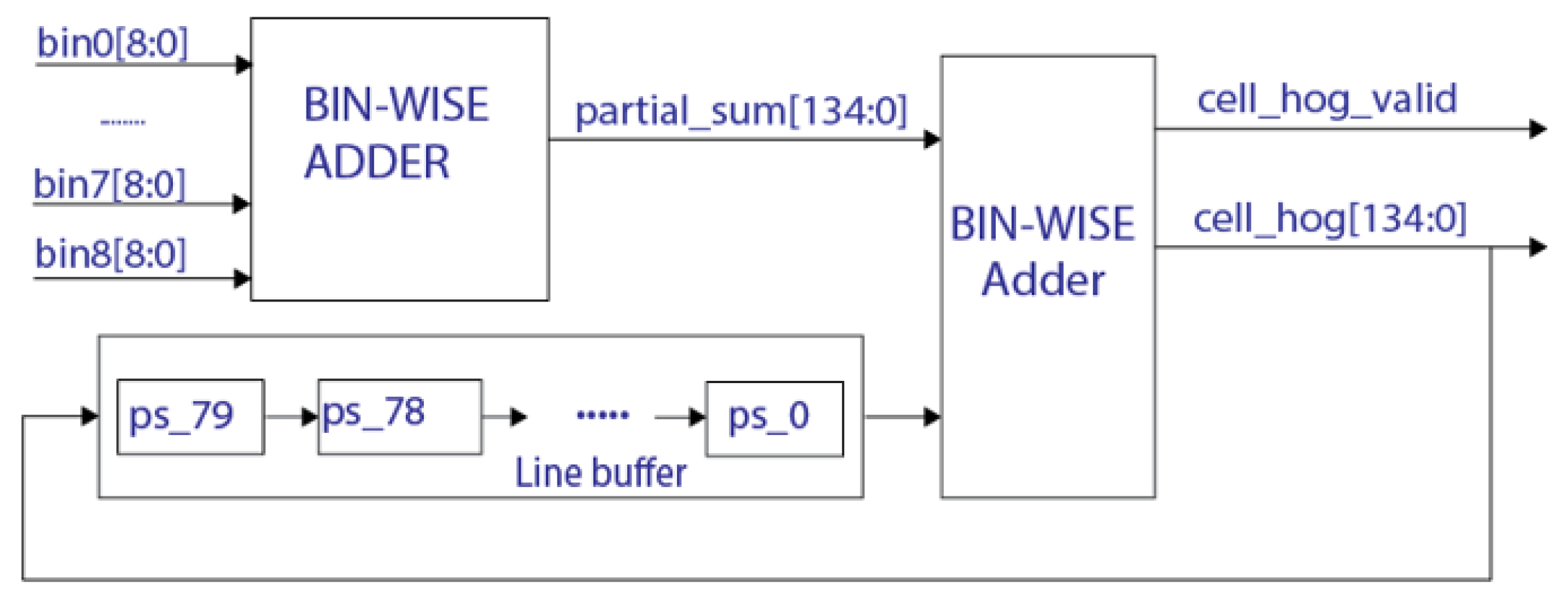
4.1. HOG Extractor
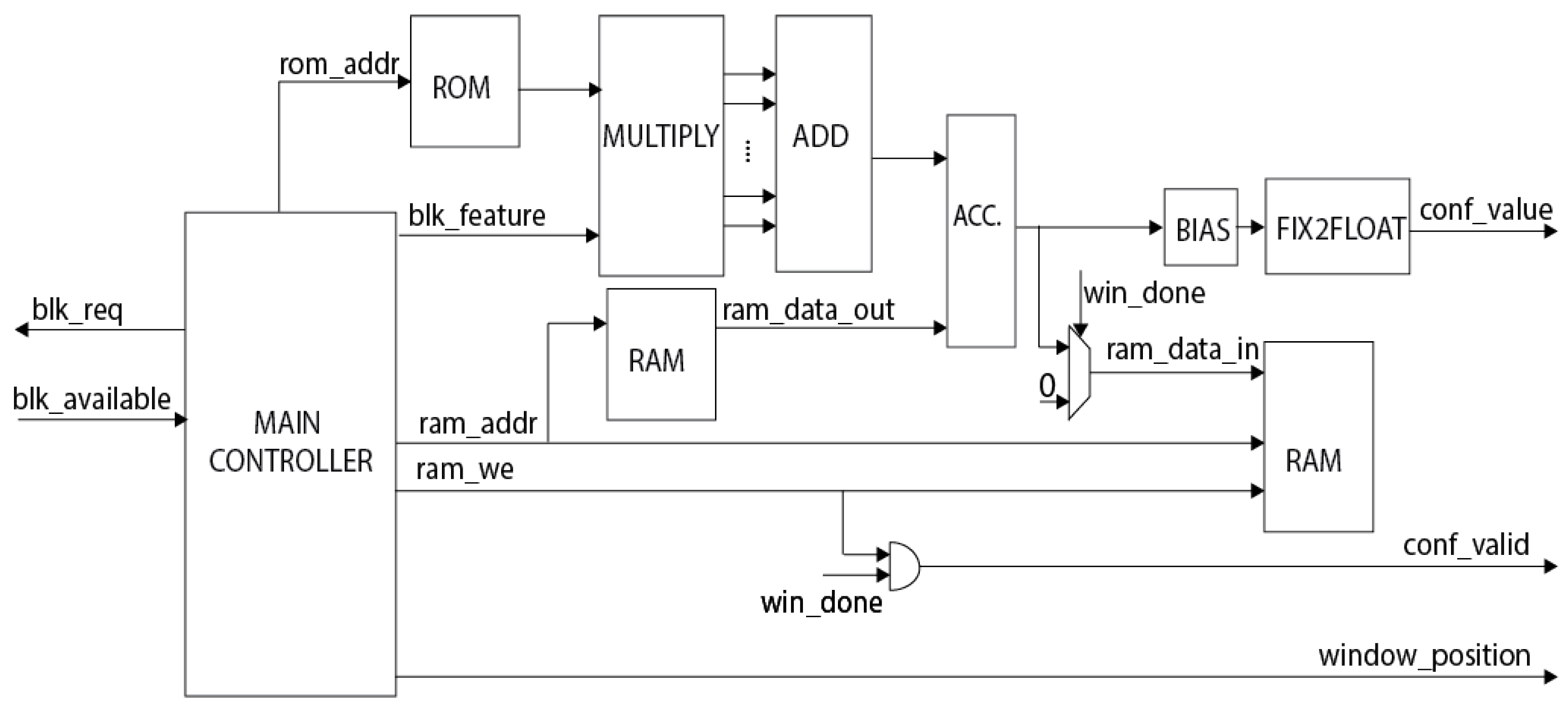
4.2. SVM Classifier
- MAIN CONTROLLER: Finite state machine (FSM) that controls the whole design. Once a block is processed, it will check if a new block is available before fetching it to the pipeline. Knowing the block position, the FSM can infer at what detection windows belong that block. Besides, the FSM generates appropriate addresses to access ROM and RAM memory.
- ROM: this memory stores all the elements of the weight vector. If the pre-trained model is changed, that ROM must be reloaded with the new weight vector set. The size of this ROM is bits. It means that each element of the weight vector is represented by a 10-bit fixed-point, in which 8 bits are fractional bits. To generate the weight vector, we trained and tested several models with different configurations using the INRIA Person Dataset [1] to achieve maximum yield in terms of accuracy. We tested our model with INRIA test dataset and with images coming from a camera sensor to have a more generalized model.
- RAM: there are two RAM instances in Figure 8 to distinguish between the reading and the writing process. Physically, there is one unique RAM module in the design. The memory, which has a size of bits, stores temporary sums for final confidence values. Each word is 19-bit width including a 12-bit partial sum and a 7-bit counter. Each resulting confidence value of a detection window is a sum of 105 partial sums. Therefore, the counter is used to signify that the detection window’s confidence value is valid. The signal is active when 105 partial sums of a detection window are fully accumulated. Furthermore, to optimize the on-chip memory usage, the memory location storing that window’s value will be reused for other detection windows. Therefore, the design uses only RAM locations to store the temporary sums of the detection windows.
- MULTIPLY: this module takes a hog block and multiplies it with appropriate elements of the weight vector stored in the ROM memory. One-cycle multiplication will generate 36 products because a block contains 36 elements. Depends on the position of the block, it might belong to multiple detection windows. It would take 105 cycles to finish processing a specific block if that block belongs to 105 detection windows.
- ADD: This module simply sums up 36 products from the MULTIPLY module.
- ACC.: Since a detection window’s confidence value is the sum of 105 partial values. This module accumulates the temporary value stored in the RAM memory with the new partial sum.
- BIAS: This module adds the bias value to generate the final confidence value in fixed-point representation.
- FIX2FLOAT: Fixed-point confidence values are converted to 32-bit floating-point numbers by this block. From the right side of Figure 8, we can see that each confidence value is accompanied by a valid signal and an address indicating the position of that detection window in the image. This coordination is used by the HPS software to draw the rectangular if the confidence value is higher than the threshold or, in other words, a pedestrian is detected.
4.3. Number Representation
5. Results
6. Conclusions
Acknowledgments
References
- Dalal, N.; Triggs, W. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition CVPR05, San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar] [CrossRef]
- Ma, X.; Najjar, W.A.; Roy-Chowdhury, A.K. Evaluation and acceleration of high-throughput fixed-point object detection on FPGAS. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 1051–1062. [Google Scholar] [CrossRef]
- Ngo, V.; Casadevall, A.; Codina, M.; Castells-Rufas, D.; Carrabina, J. A pipeline hog feature extraction for real-time pedestrian detection on FPGA. In Proceedings of the 2017 IEEE East-West Design Test Symposium (EWDTS), Novi Sad, Serbia, 29 September–2 October 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Ngo, V.; Casadevall, A.; Codina, M.; Castells-Rufas, D.; Carrabina, J. A low-cost SVM classifier on FPGA for pedestrian detection. In Proceedings of the Jornadas de Computación Empotrada y Reconfigurable (JCER2018), Teruel, Spain, 10–14 September 2018. [Google Scholar]
- Bauer, S.; Brunsmann, U.; Schlotterbeck-Macht, S. FPGA Implementation of a HOG-Based Pedestrian Recognition System; MPC-Workshop: Karlsruhem, Germany, 2009. [Google Scholar]
- Kadota, R.; Sugano, H.; Hiromoto, M.; Ochi, H.; Miyamoto, R.; Nakamura, Y. Hardware architecture for HOG feature extraction. In Proceedings of the IIH-MSP 2009—2009 5th International Conference on Intelligent Information Hiding and Multimedia Signal Processing, Kyoto, Japan, 12–14 September 2009; pp. 1330–1333. [Google Scholar] [CrossRef]
- Hahnle, M.; Saxen, F.; Hisung, M.; Brunsmann, U.; Doll, K. FPGA-Based real-time pedestrian detection on high-resolution images. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 629–635. [Google Scholar] [CrossRef]
- Khan, A.; Khan, M.U.K.; Bilal, M.; Kyung, C.M. Hardware architecture and optimization of sliding window based pedestrian detection on FPGA for high resolution images by varying local features. In Proceedings of the IEEE/IFIP International Conference on VLSI and System-on-Chip, VLSI-SoC, Daejeon, Korea, 5–7 October 2015; pp. 142–148. [Google Scholar] [CrossRef]
- Rettkowski, J.; Boutros, A.; Göhringer, D. Real-time pedestrian detection on a xilinx zynq using the HOG algorithm. In Proceedings of the 2015 International Conference on ReConFigurable Computing and FPGAs (ReConFig), Mexico City, Mexico, 7–9 December 2015; pp. 1–8. [Google Scholar] [CrossRef]
- Blair, C.; Robertson, N.M.; Hume, D. Characterising a Heterogeneous System for Person Detection in Video using Histograms of Oriented Gradients: Power vs. Speed vs. Accuracy. IEEE J. Emerg. Sel. Top. Circuits Syst. 2013, 3, 236–247. [Google Scholar] [CrossRef]
- Bilal, M.; Khan, A.; Karim Khan, M.U.; Kyung, C. A Low-Complexity Pedestrian Detection Framework for Smart Video Surveillance Systems. IEEE Trans. Circuits Syst. Video Technol. 2017, 27, 2260–2273. [Google Scholar] [CrossRef]
- Luo, J.H.; Lin, C.H. Pure FPGA Implementation of an HOG Based Real-Time Pedestrian Detection System. Sensors 2018, 18. [Google Scholar] [CrossRef] [PubMed]
- Castells i Rufas, D. Scalable Parallel Architectures on Reconfigurable Platforms. Ph.D. Thesis, Autonomous University of Barcelona, Bellaterra, Spain, 2016. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Implementation | [10] | [7] | [2] | [9] | [8] | [12] | Ours |
|---|---|---|---|---|---|---|---|
| Year | 2013 | 2013 | 2015 | 2015 | 2015 | 2018 | 2019 |
| Hardware | Virtex 6 | Virtex 5 | Virtex 6 | XC7Z020 | Virtex 7 | Cyclone IV | Cyclone V |
| Technology node | 40 nm | 65 nm | 40 nm | 28 nm | 28 nm | 60 nm | 28 nm |
| Freq. (MHz) | NA | 266 | 150 | 82.2 | 266 | 150 | 50 |
| Frame size | 1024 × 768 | 1920 × 1080 | 640 × 480 | 1920 × 1080 | 1920 × 1080 | 800 × 600 | 640 × 480 |
| Latency | 4.88 ms | <150 s | 44 ms | 25.2 ms | NA | NA | 13.3 ms |
| Power (W) | 182 | NA | 37 | NA | 19 | NA | 9 |
| Energy (J/frame) | 14 | NA | 0.54 | NA | 0.45 | NA | 0.12 |
| FPS | 13 | 64 | 68.2 | 40 | 42.7 | 162 | 75 |
| Memory (Kb) | 3.744 | 1.188 | 13.738 | 0 | 4.079 | 344 | 317 |
| LUTs | 108.518 | 5.188 | 184.953 | 21.297 | 30.360 | 16.060 | 13.464 |
| DSPs | 138 | 49 | 190 | 4 | 364 | 69 | 38 |
| FFs | 120.576 | 5.176 | 208.666 | NA | 48.576 | 7.220 | 17.117 |
| Pixels per clock | NA | 0.0005 | 0.0003 | 0.0009 | 0.0003 | 0.0009 | 0.0010 |
| Energy per pixel | 18 | NA | 1.8 | NA | 0.22 | NA | 0.39 |
| (J/pixel) | |||||||
| FPS per watt | 0.07 | NA | 1.84 | NA | 2.25 | NA | 8.35 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ngo, V.; Castells-Rufas, D.; Casadevall, A.; Codina, M.; Carrabina, J. Low-Power Pedestrian Detection System on FPGA. Proceedings 2019, 31, 35. https://doi.org/10.3390/proceedings2019031035
Ngo V, Castells-Rufas D, Casadevall A, Codina M, Carrabina J. Low-Power Pedestrian Detection System on FPGA. Proceedings. 2019; 31(1):35. https://doi.org/10.3390/proceedings2019031035
Chicago/Turabian StyleNgo, Vinh, David Castells-Rufas, Arnau Casadevall, Marc Codina, and Jordi Carrabina. 2019. "Low-Power Pedestrian Detection System on FPGA" Proceedings 31, no. 1: 35. https://doi.org/10.3390/proceedings2019031035
APA StyleNgo, V., Castells-Rufas, D., Casadevall, A., Codina, M., & Carrabina, J. (2019). Low-Power Pedestrian Detection System on FPGA. Proceedings, 31(1), 35. https://doi.org/10.3390/proceedings2019031035