Building High-Quality Datasets for Information Retrieval Evaluation at a Reduced Cost †


{kind=link}
Abstract
:1. Introduction
2. Experiments
2.1. Systems and Query Variants
2.2. Pooling Algorithms
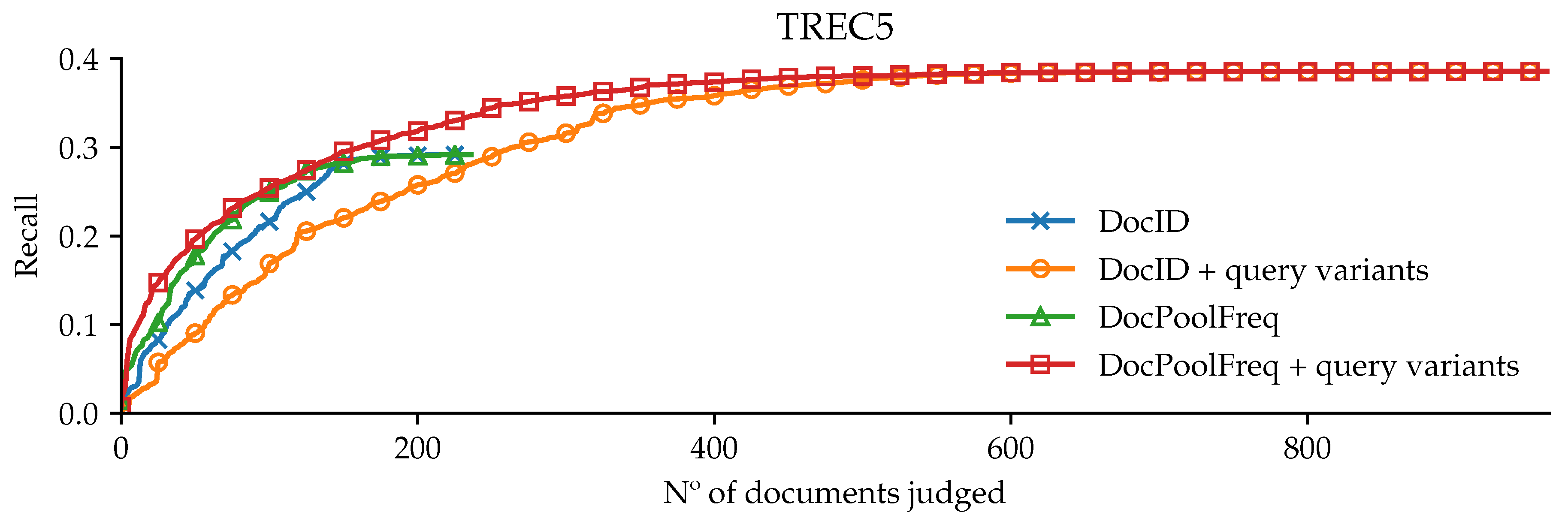
3. Results
4. Discussion
Funding
Conflicts of Interest
References
- Sanderson, M. Test Collection Based Evaluation of Information Retrieval Systems. Found. Trends® Inf. Retr. 2010, 4, 247–375. [Google Scholar] [CrossRef]
- Voorhees, E.M.; Harman, D.K. TREC: Experiment and Evaluation in Information Retrieval (Digital Libraries and Electronic Publishing); The MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Kanoulas, E. Building Reliable Test and Training Collections in Information Retrieval. Ph.D. Thesis, Northeastern University, Boston, MA, USA, 2009. [Google Scholar]
- Losada, D.E.; Parapar, J.; Barreiro, A. Cost-effective Construction of Information Retrieval Test Collections. In Proceedings of the 5th Spanish Conference on Information Retrieval, Zaragoza, Spain, 26–27 June 2018; ACM: New York, NY, USA, 2018; pp. 12:1–12:2. [Google Scholar]
- Losada, D.E.; Crestani, F. A Test Collection for Research on Depression and Language Use. In Experimental IR Meets Multilinguality, Multimodality, and Interaction: 7th International Conference of the CLEF Association, CLEF 2016, Évora, Portugal, 5–8 September 2016; Springer: Berlin, Germany, 2016; pp. 28–39. [Google Scholar]
- Kuriyama, K.; Kando, N.; Nozue, T.; Eguchi, K. Pooling for a Large-Scale Test Collection: An Analysis of the Search Results from the First NTCIR Workshop. Inf. Retr. 2002, 5, 41–59. [Google Scholar] [CrossRef]
- Losada, D.E.; Parapar, J.; Barreiro, Á. Feeling Lucky?: Multi-armed Bandits for Ordering Judgements in Pooling-based Evaluation. In Proceedings of the 31st Annual ACM Symposium on Applied Computing, Pisa, Italy, 4–8 April 2016; ACM: New York, NY, USA, 2016; pp. 1027–1034. [Google Scholar]
- Losada, D.E.; Parapar, J.; Barreiro, A. Multi-armed bandits for adjudicating documents in pooling-based evaluation of information retrieval systems. Inf. Process. Manag. 2017, 53, 1005–1025. [Google Scholar] [CrossRef]
- Allan, J.; Harman, D.; Kanoulas, E.; Li, D.; Gysel, C.V.; Voorhees, E.M. TREC 2017 Common Core Track Overview. In Proceedings of the Twenty-Sixth Text REtrieval Conference, TREC 2017, Gaithersburg, MD, USA, 15–17 November 2017. [Google Scholar]
- Losada, D.E.; Crestani, F.; Parapar, J. eRISK 2017: CLEF Lab on Early Risk Prediction on the Internet: Experimental Foundations. Proceedings of 18th Conference and Labs of the Evaluation Forum. Springer: Dublin, Ireland, 2017; CLEF’17; pp. 346–360. [Google Scholar]
- Losada, D.E.; Crestani, F.; Parapar, J. Overview of eRisk: Early Risk Prediction on the Internet. Proceedings of 19th Conference and Labs of the Evaluation Forum. Springer: Avignon, France, 2018; CLEF’18; pp. 343–361. [Google Scholar]
- Losada, D.E.; Crestani, F.; Parapar, J. Early Detection of Risks on the Internet: An Exploratory Campaign. In Proceedings of the 41st European Conference on Information Retrieval, Cologne, Germany, 14–18 April 2019; pp. 259–266. [Google Scholar]
- Losada, D.E.; Parapar, J.; Barreiro, A. A rank fusion approach based on score distributions for prioritizing relevance assessments in information retrieval evaluation. Inf. Fusion 2018, 39, 56–71. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Otero, D.; Valcarce, D.; Parapar, J.; Barreiro, Á. Building High-Quality Datasets for Information Retrieval Evaluation at a Reduced Cost. Proceedings 2019, 21, 33. https://doi.org/10.3390/proceedings2019021033
Otero D, Valcarce D, Parapar J, Barreiro Á. Building High-Quality Datasets for Information Retrieval Evaluation at a Reduced Cost. Proceedings. 2019; 21(1):33. https://doi.org/10.3390/proceedings2019021033
Chicago/Turabian StyleOtero, David, Daniel Valcarce, Javier Parapar, and Álvaro Barreiro. 2019. "Building High-Quality Datasets for Information Retrieval Evaluation at a Reduced Cost" Proceedings 21, no. 1: 33. https://doi.org/10.3390/proceedings2019021033
APA StyleOtero, D., Valcarce, D., Parapar, J., & Barreiro, Á. (2019). Building High-Quality Datasets for Information Retrieval Evaluation at a Reduced Cost. Proceedings, 21(1), 33. https://doi.org/10.3390/proceedings2019021033