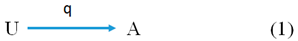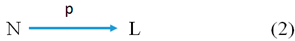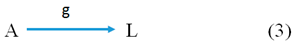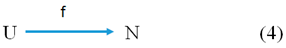2. Knowledge Processing
It is possible to understand knowledge processing in three different ways:
Transformation of data into knowledge
Changing the form of knowledge representation
Deriving new knowledge from a given knowledge
However, whatever understanding we take, it is evident that knowledge processing involves manipulation with knowledge structures. Thus, to be able to efficiently process knowledge using computers and networks, it is essential to know and properly use knowledge structures. The most basic knowledge structures are described in the
synthetic theory of knowledge presented in [
2]. This theory shows that there are several levels or types of data, which by an enrichment (enhancement) process become knowledge.
The first type is raw or un-interpreted data. Their first-order structure is represented by Picture (1).
![Proceedings 01 00212 i001]()
In this Picture, U consists of some objects, q is a relation between U and A, while A denotes: (a) attributes of these objects in the case of descriptive data, (b) representations of these objects in the case of representational data, and (c) operations, action and processes related to these objects in the case of operational data. For instance, all three types of data are used in the object-oriented programming for object description. Namely, object-oriented programming (OOP) is a programming paradigm based on the concept of abstract objects represented by data structures that include attributes in the form of descriptive data, characteristics in the form of representational data and methods in the form of operational data.
Raw data correspond to the substantial component of knowledge [
2]. The difference is that in contrast to the substantial component of knowledge, raw data are not related to any definite property.
Having raw data, a person or a computer system can transform them into knowledge by means of additional knowledge that this person or computer system already has.
The second type of data is formally interpreted data. They are related to the abstract property P, forming a named subset of the information component of a knowledge unit represented by Picture (1), and the first-order structure of this component is represented by Picture (2).
![Proceedings 01 00212 i002]()
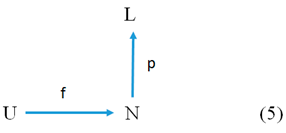
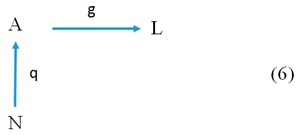
Here N consists of the names of objects and L is the set of values (the scale) of the property P = (N, p, L) on the names of objects that tentatively have these properties, while p is the relation that connects names of considered objects with values of the ascribed properties of these objects, i.e., p is the functional component (evaluation function) of the property P.
Formally interpreted data correspond to the symbolic component of knowledge [
2]. The difference is that formally interpreted data are not necessarily included in a knowledge system.
The third type is attributed data. They are related not to the abstract property P but to the values of an intrinsic property, i.e., to the attribute A. The first-order structure of attributed data is represented by Picture (3).
![Proceedings 01 00212 i003]()
The fourth type of data is naming data, the first-order structure of which is represented by Picture (4).
![Proceedings 01 00212 i004]()
There are two more types of data, which are more enhanced and are closer to knowledge.
The fourth type is object interpreted data. Their first-order structure is represented by Picture (5).
![Proceedings 01 00212 i005]()
The fifth type of data is object attributed data. Their first-order structure is represented by Picture (6).
![Proceedings 01 00212 i006]()
It is interesting to remark that the statement about the correspondence between linguistic constructions representing knowledge and things in the external world as a necessary component of knowledge, which makes it different from data, was discovered in [
3] and then reiterated by Davis [
4] and Burgin [
5,
6].
It is possible to treat all types of data as incomplete knowledge.
Formally, naming data are names of considered objects and correspond to the naming component of knowledge [
2]. The difference is that naming data are not necessarily included in a knowledge system.
It is important to understand that data and knowledge can themselves be objects, which have names, as well as intrinsic and ascribed properties. In particular, when the domain
U consists of (some kind of) data, then in this case, we come to
named data, which play an important role in the recent ideas for the development of the Internet [
7,
8]. To understand what named data are and why they are so popular, we consider the schema of the data transfer on the Internet.
The contemporary Internet is based on the TCP/IP communication protocol. In it, the TCP (Transmission Control Protocol) part is performs separation of the file/message into packets on the source computer and reassembling the received packets at the destination, e.g., at the recipient computer. The IP (Internet Protocol) part handles the address of the destination computer so that each packet is routed (sent) to its proper destination.
In Named Data Networking (NDN) architecture for the future Internet, the transmitted packets of data carry data names rather than source or destination addresses. The developers of this architecture believe that this conceptually simple shift will have far-reaching implications for how people design, develop, deploy, and use networks and applications. The Named Data principle implies that a communication network should allow a user to focus on the data identified by their names he or she needs, rather than having to reference a specific, physical location where that data would be retrieved.
Actually, Internet packets of data are already named by destination addresses and the new approach suggests changing these names to the original data names (identifiers). It is assumed that such a renaming brings potential for a wide range of benefits such as simpler configuration of network devices, building security into the network at the data level and content caching to reduce congestion and improve delivery speed. In addition, sustained growth in e-commerce, digital media, social networking, and smartphone applications has led to prevailing use of the Internet in the role of a distribution network. Utilization of a point-to-point communication protocol in distribution networks is complex and error-prone, while Named Data Networking better suits distribution environment.
In this context, named sets give a natural mathematical model for named data, which form the naming component of the knowledge quanta with data as their object or domain [
9]. Consequently, named set theory provides powerful means for network algorithms and procedures in the form of various operations and correspondences [
10].
Another example of naming data is named graphs, which are a key structure of the Semantic Web architecture [
11]. In it, a set of Resource Description Framework (RDF) statements (a graph) are identified using a URI (Universal Resource Identifier), allowing derivation of descriptions of context, provenance information or other metadata. This shows that named graphs form an extension of the RDF data model giving additional evidence for importance of naming data in contemporary information technology.
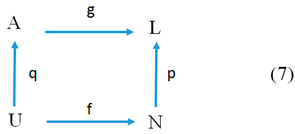
Combining all previous Pictures together, we get the quantum knowledge structure or structure of a knowledge quantum.
![Proceedings 01 00212 i007]()
In Picture (7), U is the knowledge domain (knowledge object), A is an aspect of the domain (object) U, the symbol N, which denotes the name of U or a class of names of the objects from U (a name of the object U), and L is the set of values (the scale) of the property P = (N, p, L) on the names of objects.
There is a tendency to treat knowledge as data with ontology. This approach is represented by Picture (8).
![Proceedings 01 00212 i008]()
In Picture (8), D denotes raw data, Ont is an ontology or interpretation of the data D, the symbol N denotes the names of the elements from the raw data D, and DescOnt is a description of the ontology Ont, which provides understanding of the ontology Ont.
Thus, we see that efficient organization of knowledge processing has to be based on structure transformations of data represented in a symbolic form.