Data-Driven Representation of Soft Deformable Objects Based on Force-Torque Data and 3D Vision Measurements †

Abstract
:1. Introduction
2. Proposed Framework for Soft Object Deformation Representation
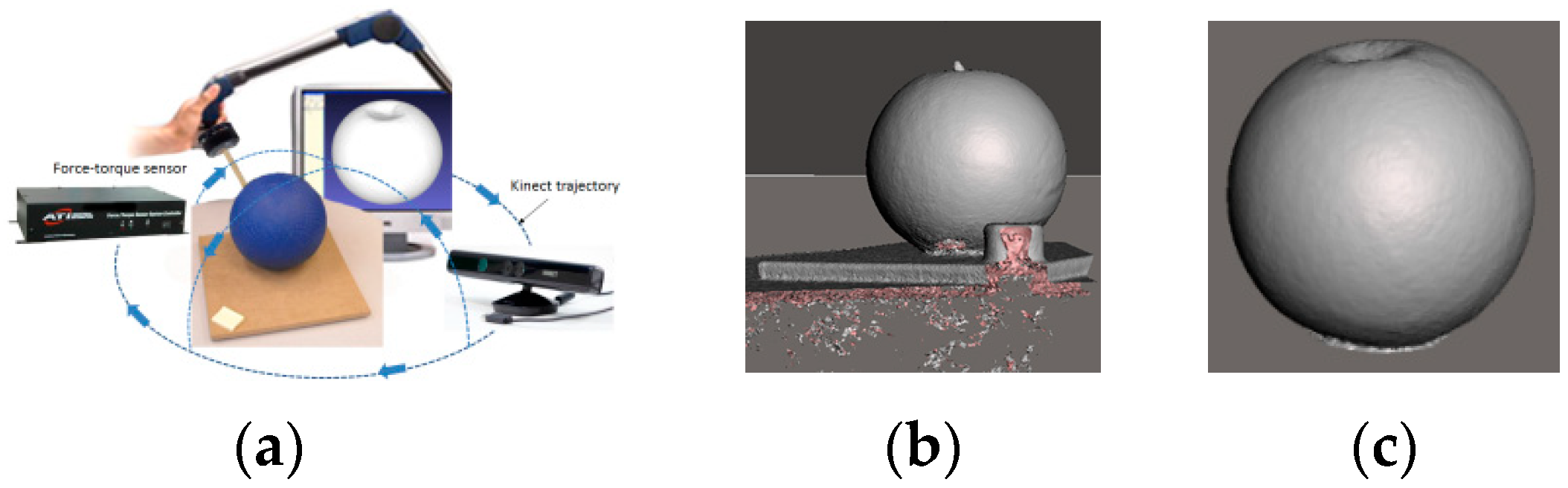
2.1. Data Acquisition
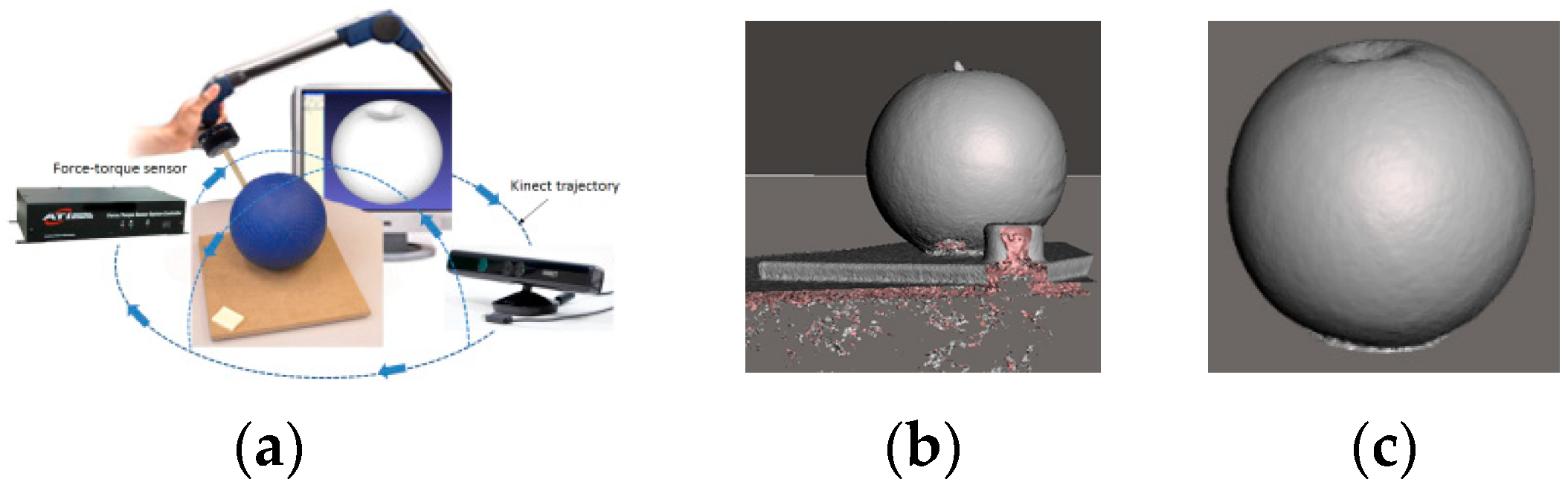
2.2. Data Preparation
2.3. Deformation Characterization
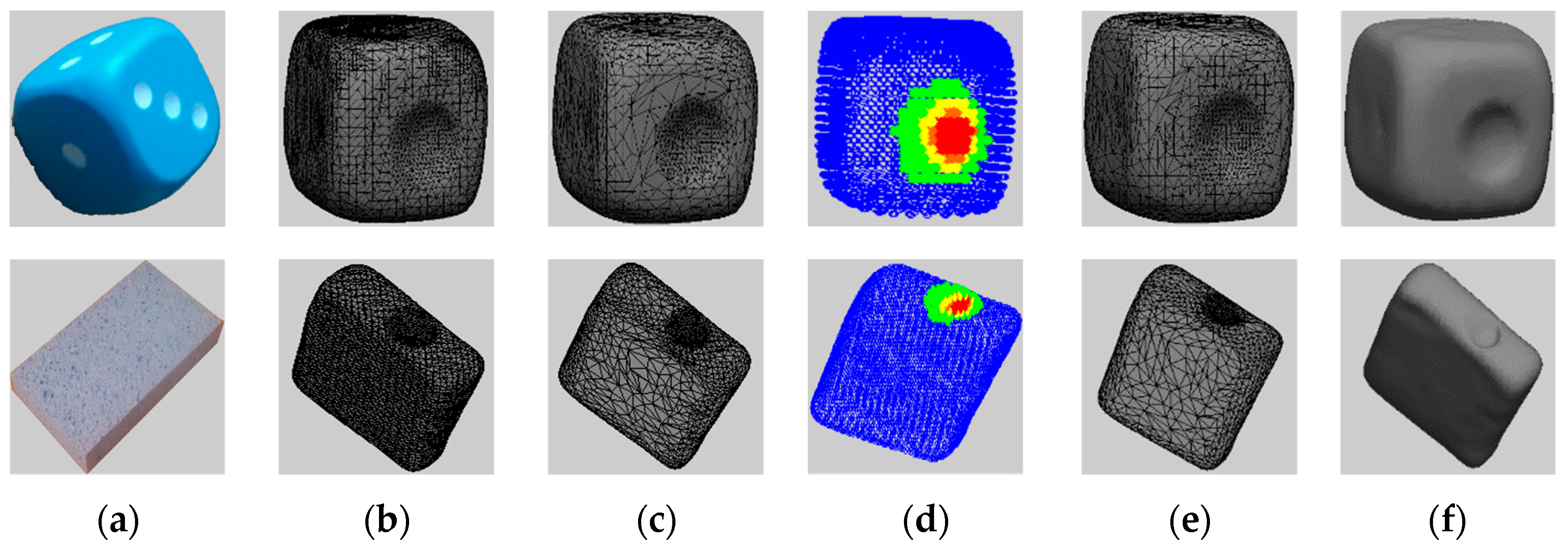
2.4. Quality Evaluation
3. Experimental Results
4. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Krainin, M.; Henry, P.; Ren, X.; Fox, D. Manipulator and object tracking for in-hand 3D object modeling. Int. J. Robot. Res. 2011, 30, 1311–1327. [Google Scholar] [CrossRef]
- Zollhofer, M.; Nießner, M.; Izadi, S.; Rhemann, C.; Zach, C.; Fisher, M.; Wu, C.; Fitzgibbon, A.; Loop, C.; Theobalt, C.; et al. Real-time non-rigid reconstruction using an RGB-D camera. ACM Trans. Graph. 2014, 33, 1–12. [Google Scholar] [CrossRef]
- Dou, M.; Taylor, J.; Fuchs, H.; Fitzgibbon, A.; Izadi, S. 3D Scanning deformable objects with a single RGBD sensor. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 493–501. [Google Scholar]
- Microsoft Kinect Fusion. Available online: https://msdn.microsoft.com/en-us/library/dn188670.aspx (accessed on 1 August 2016).
- Skanect. Available online: http://skanect.occipital.com/ (accessed on 1 August 2016).
- Zaidi, L.; Bouzgarrou, B.; Sabourin, L.; Menzouar, Y. Interaction modeling in the grasping and manipulation of 3D deformable objects. In Proceedings of the IEEE International Conference on Advanced Robotics, Istanbul, Turkey, 27–31 July 2015. [Google Scholar]
- Lang, J.; Pai, D.K.; Woodham, R.J. Acquisition of elastic models for interactive simulation. Int. J. Robot. Res. 2002, 21, 713–733. [Google Scholar] [CrossRef]
- Jordt, A.; Koch, R. Fast tracking of deformable objects in depth and colour video. In Proceedings of the British Machine Vision Conference, Dundee, Scotland, UK, 30 August–1 September 2011; pp. 1–11. [Google Scholar]
- Burion, S.; Conti, F.; Petrovskaya, A.; Baur, C.; Khatib, O. Identifying physical properties of deformable objects by using particle filters. In Proceedings of the IEEE International Conference Robotics and Automation, Pasadena, CA, USA, 19–23 May 2008; pp. 1112–1117. [Google Scholar]
- Bianchi, G.; Solenthaler, B.; Szekely, G.; Harders, M. Simultaneous topology and stiffness identification for mass-spring models based on FEM reference deformations. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention (MICCAI) 2004, LNCS 3217, Saint-Malo, France, 26–29 September 2004; pp. 293–301. [Google Scholar]
- Frank, B.; Schmedding, R.; Stachniss, C.; Teschner, M.; Burgard, W. Learning the Elasticity Parameters of Deformable Objects with a Manipulation Robot. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 1877–1883. [Google Scholar]
- Meshmixer. Available online: http://www.meshmixer.com/ (accessed on 1 August 2016).
- Monette-Thériault, H.; Cretu, A.-M.; Payeur, P. 3D Object modeling with neural gas based selective densification of surface meshes. In Proceedings of the IEEE Conference Systems, Man and Cybernetics, San Diego, CA, USA, 5–8 October 2014; pp. 1373–1378. [Google Scholar]
- Garland, M.; Heckbert, P.S. Surface simplification using quadric error meshes. In Proceedings of the T Association for Computing Machinery (ACM) Siggraph, New York, NY, USA, 3–8 August 1997; pp. 209–216. [Google Scholar]
- Martinetz, M.; Berkovich, S.G.; Schulten, K.J. Neural-gas network for vector quantization and its application to time-series prediction. IEEE Trans. Neural Netw. 1993, 4, 558–568. [Google Scholar] [CrossRef] [PubMed]
- Cretu, A.-M.; Payeur, P.; Petriu, E.M. Selective range data acquisition driven by neural gas networks. IEEE Trans. Instrum. Meas. 2009, 58, 2634–2642. [Google Scholar] [CrossRef]
- Cignoni, P.; Rocchini, C.; Scopigno, R. Metro: Measuring error on simplified surfaces. Comp. Graph. Forum 1998, 17, 167–174. [Google Scholar] [CrossRef]
- Laparra, V.; Balle, J.; Berardino, A.; Simoncelli, E.P. Perceptual image quality assessment using a normalized Laplacian pyramid. In Proceedings of the Human Vision and Electronic Imaging, Fargo, ND, USA, 15–18 February 2016; Volume 16. [Google Scholar]
- CloudCompare—3D Point Cloud and Mesh Processing Software. Available online: http://www.danielgm.net/cc/ (accessed on 1 August 2016).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metro Overall Error (e−3) Max/Mean/rms | Perceptual Overall Error (Similarity%) | Metro Error in Deformed Area (e−5) Max/Mean/rms | Perceptual Error (Similarity%) in Deformed Area | Computing Time/Object | |
|---|---|---|---|---|---|
| Ball | 16.7/5.58/7.4 | 0.205 (79.5%) | 24.3/3.05/4.69 | 0.082 (91.8%) | 0.72 s |
| Cube | 46.2/11.8/17.2 | 0.286 (71.4%) | 25.7/3.47/5.07 | 0.127 (87.3%) | 0.35 s |
| Sponge | 21.6/5.09/7.55 | 0.281 (71.9%) | 22.4/2.29/3.51 | 0.070 (93.0%) | 0.23 s |
| Average | 28.16/7.49/10.7 | 0.257 (74.3%) | 24.13/2.93/4.42 | 0.093 (90.7%) | 0.43 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2016 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tawbe, B.; Cretu, A.-M. Data-Driven Representation of Soft Deformable Objects Based on Force-Torque Data and 3D Vision Measurements. Proceedings 2017, 1, 22. https://doi.org/10.3390/ecsa-3-E006
Tawbe B, Cretu A-M. Data-Driven Representation of Soft Deformable Objects Based on Force-Torque Data and 3D Vision Measurements. Proceedings. 2017; 1(2):22. https://doi.org/10.3390/ecsa-3-E006
Chicago/Turabian StyleTawbe, Bilal, and Ana-Maria Cretu. 2017. "Data-Driven Representation of Soft Deformable Objects Based on Force-Torque Data and 3D Vision Measurements" Proceedings 1, no. 2: 22. https://doi.org/10.3390/ecsa-3-E006
APA StyleTawbe, B., & Cretu, A.-M. (2017). Data-Driven Representation of Soft Deformable Objects Based on Force-Torque Data and 3D Vision Measurements. Proceedings, 1(2), 22. https://doi.org/10.3390/ecsa-3-E006