1. Introduction
Image semantic segmentation is an important part of computer vision, which recognizes an image pixel by pixel and labels the object class to which each pixel belongs. Image semantic segmentation is of great significance in several practical application areas, such as automatic driving, robot perception, virtual reality, augmented reality, etc. Deep learning-based image semantic segmentation technology has made great progress with the development of convolutional neural network technology [
1,
2,
3,
4]. New methods and models continue to emerge. Fully Convolutional Networks [
5] is the earliest model to introduce deep learning into the field of image semantic segmentation and achieves excellent segmentation results. DeepLabV3 [
6] extends the receptive field of the convolution kernel through null convolution, which is able to capture a larger range of information and uses depth-separable convolution to significantly reduce the computational effort and improve the model. The Atrous Spatial Pyramid Pooling (ASPP) module is used to significantly reduce the amount of computation and improve the efficiency of the model, and the accuracy of semantic segmentation is improved by extracting information at different scales through multi-scale cavity convolution. DeepLabV3+ [
7] is based on DeepLabV3 with a decoder module, which improves the accuracy of the model for semantic segmentation by adding a decoding layer; this improves the model’s handling of detail boundaries, especially in the segmentation of edges and small objects in the image. The decoder helps the model to recover the spatial information more accurately, which improves segmentation accuracy.
While DeepLabV3+ has established itself as a robust solution for various semantic segmentation tasks, several inherent limitations persist that hinder its broader applicability. The architecture’s computational complexity, stemming from its extensive parameter count and heavy reliance on atrous convolution operations coupled with deep backbone networks, poses significant challenges for deployment on resource-constrained edge devices. Furthermore, despite incorporating ASPP modules to enhance feature extraction, the model still struggles to capture sufficiently diverse feature representations, particularly when processing complex textures and fine object boundaries. This limitation is compounded by the progressive loss of spatial details during successive downsampling operations, which adversely affects segmentation precision for smaller or thinner objects. Additionally, the model’s predominant focus on local receptive fields through conventional convolution operations results in inadequate modeling of long-range contextual relationships, a critical capability for accurately parsing large-scale or structurally complex scenes. These architectural constraints collectively impact the model’s performance across various real-world segmentation scenarios, motivating the need for targeted improvements to address these fundamental limitations while preserving the framework’s core strengths.
Improved versions based on the DeepLabV3+ model have been developed to improve the performance of semantic segmentation [
8,
9,
10,
11,
12]. To mitigate these issues, various improvements have been proposed. Gu et al. [
8] introduced the AFFP module to enhance the multi-scale feature extraction ability of the network and then used PSCAN to refine the network’s attention to the channel and spatial information, enabling the network to pay more sensitive attention to salient features in the image data. Hou [
9] replaced the ASPP pool of the original ASPP module with the strip pool method, which can be applied to more complex images. The EPSA attention mechanism was introduced to effectively establish the long-term dependency between multi-scale channel attention and realize the cross-dimensional channel attention interaction of important features. Ding et al. [
10] used MobileNetV2Lite-SE to improve the efficiency of feature extraction and introduced an ACsc–ASPP module based on the ASPP structure to solve the problem of local information loss. Baban et al. [
11] proposed a new image segmentation model mid-DeepLabv3+, which extracts backbone features after using the SimAM attention mechanism and adding a new intermediate layer in the decoder path using a streamlined version of ResNet50 as the backbone. However, these methods still suffer from insufficient generalization ability, perform well only on specific datasets, have a large number of parameters with high computational resource requirements, perform poorly in semantic segmentation of small objects in large-scale scenarios, and operate on local receptive domains, which may not be able to effectively capture the global context. In conclusion, the performance of the above algorithms still needs to be improved, and balancing accuracy and real-time performance is an urgent problem when they are deployed on mobile devices. Therefore, balancing segmentation accuracy, efficiency, and generalization remains an open and pressing issue, particularly in practical applications involving mobile or embedded platforms.
To address the semantic segmentation of Signet Ring Cells (SRCs), a recent study proposed RGGC-UNet [
13], a deep learning model that achieves high segmentation accuracy with improved computational efficiency. Built upon the UNet architecture, the model incorporates a residual Ghost block combined with coordinate attention to design a lightweight and expressive encoder, significantly reducing redundant computation. TranSiam [
14] is a dual-path segmentation framework tailored for multi-modal medical image analysis, leveraging the complementary nature of different imaging modalities. The architecture employs two parallel convolutional branches to extract modality-specific low-level features, while a Transformer module captures high-level global context. MiM–UNet [
15] is a novel remote sensing segmentation model that addresses the challenges of accurately interpreting complex building structures. By incorporating Mamba-in-Mamba blocks based on state—space model principles, the architecture enhances the traditional encoder-decoder framework, improving both multi-scale feature extraction and computational efficiency.
Aiming at the above problems, to improve the performance of image semantic segmentation, this study optimizes and improves the DeepLabV3+ image semantic segmentation algorithm based on its optimization and improvement to reduce the model parameters, improve the model running speed, retain more detailed information, and improve the model’s ability to perceive complex scenes. The innovation of this study is reflected in the following three aspects:
Considering the real-time nature of semantic segmentation and maintaining high classification accuracy, this study chose MobileNetV2, a lightweight network, as the backbone network of DeepLabv3+, to replace the original Xception network.
Introducing multiple shallow features of different scales in MobileNetV2 into the FEM attention mechanism and then fusing these shallow features to improve the utilization of edge information by the model encoder, which is able to retain more detailed information and enhance the feature representation capability of the network for complex scenes.
The ASPP module, as a core module in DeepLabV3+, is primarily responsible for obtaining multi-level contextual information from different scales. However, the output feature maps of ASPP often lack sufficient attention to the details after merging. To solve this problem, an attention mechanism was introduced on the feature maps processed by the ASPP module to help the network focus more on important regions.
2. Proposed Method
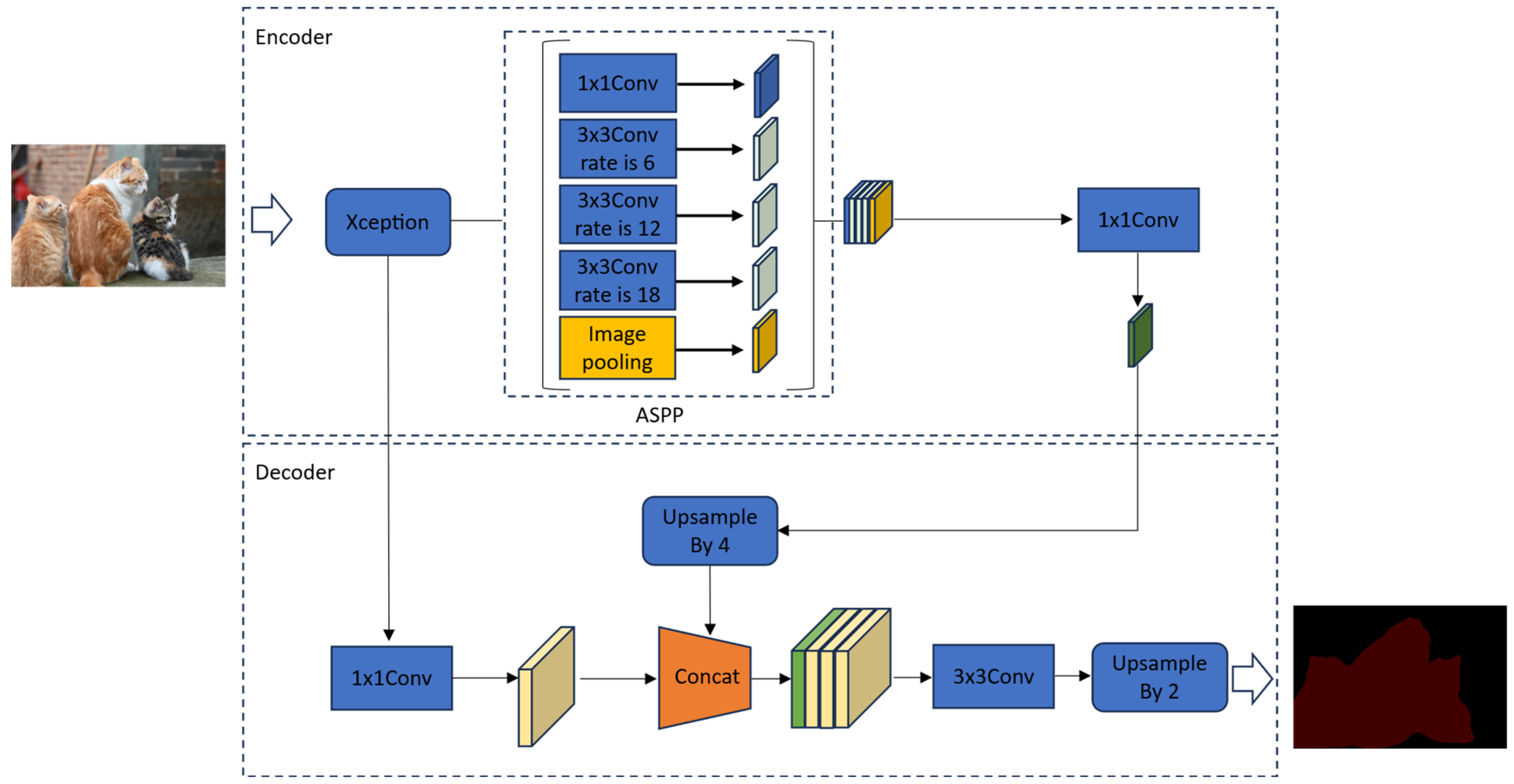
DeepLabV3+ uses an encoder-decoder architecture, as shown in
Figure 1, with Xception as the backbone network, applies depth-separable convolution to the ASPP module and decoder module, and arbitrarily controls the encoder’s feature extraction capability through null convolution in order to trade off accuracy against runtime [
7].
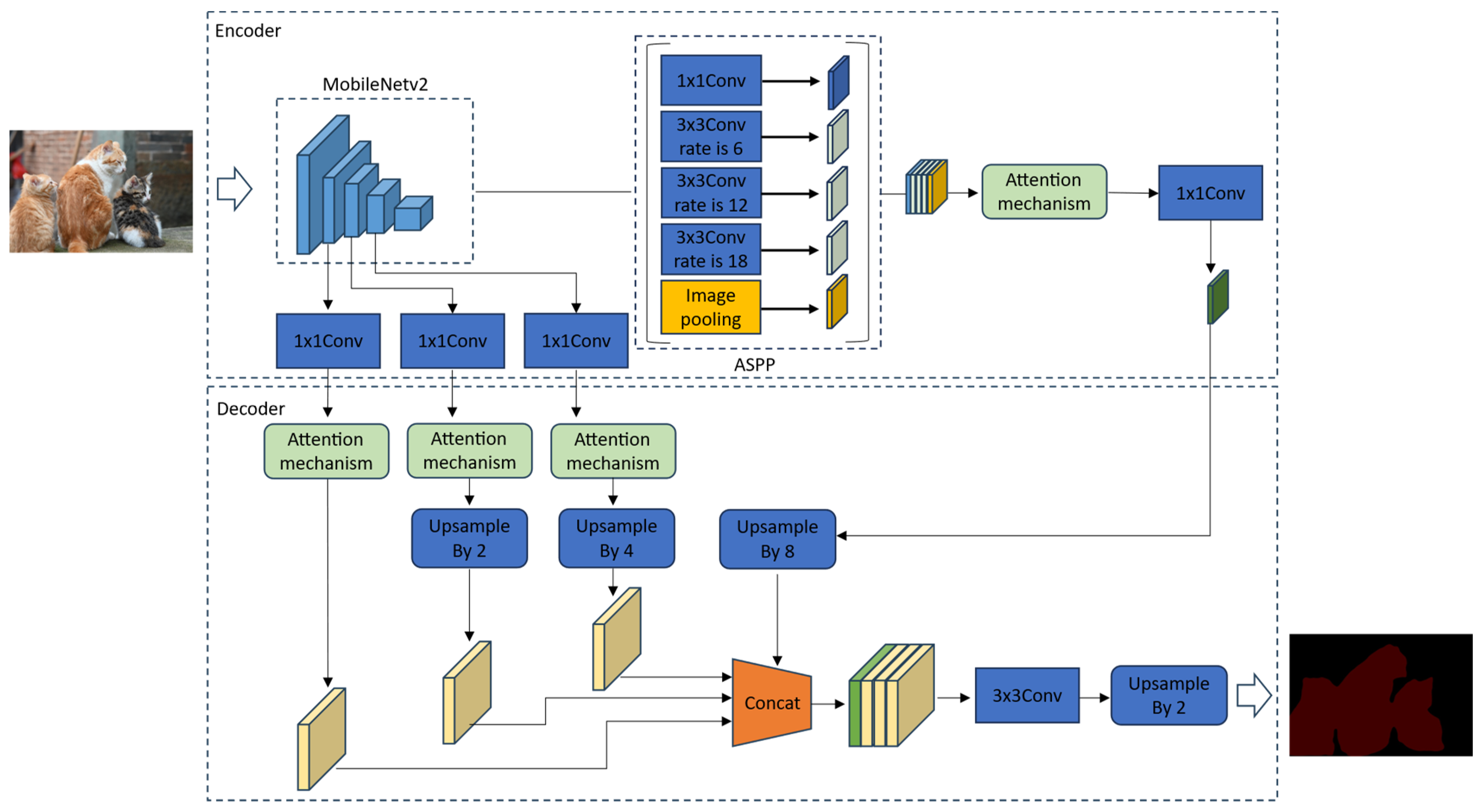
The improved DeepLabV3+ network is a multi-scale feature fusion network that attaches an attention mechanism to the backbone network. As shown in
Figure 2, the image features are initially extracted using the lightweight backbone network MobileNetV2, and to improve the image segmentation performance without destroying the structure of the backbone network, in the encoder part, we extract the shallow features after the first three downsamplings of the MobileNetV2 backbone network, and the number of channels is adjusted for the three shallow features by first using the one-dimensional convolution. To make the number of channels consistent, the attention mechanism is introduced to improve the feature representation capability, and finally, the size of the shallow features is adjusted by upsampling. Then the attention mechanism is introduced to improve the feature representation ability respectively, and finally the shallow feature size is adjusted by upsampling to make the three shallow features of the same size. The final output feature layer of the backbone network MobileNetV2 is used as the input of ASPP, which consists of one convolutional layer, three atrous convolutions with different dilation rates, and a global average pooling layer, which is able to capture information of multiple scales and effectively improve the model’s ability in recognizing targets of different sizes.
ASPP outputs five feature layers and performs fusion. The fused feature layer is processed using the attention mechanism and, after adjusting the number of channels and size, the feature layer is fused with the three shallow feature layers mentioned earlier in the decoder section. Then, the fused result is used for feature extraction using the 3 × 3 convolution, and the size of the feature map is restored to be consistent with the input through upsampling, and then the semantic segmentation result is output.
2.1. Backbone Network Selection
In semantic segmentation models, the backbone network is mainly responsible for extracting high-level features of an image. Commonly used backbone networks, such as ResNet [
16] and Xception [
17], are usually used for this task but, owing to the high com-putational overhead of these networks, an increasing number of lightweight networks, such as MobileNetV2, are becoming the optimized choice.
MobileNetV2 is a lightweight and efficient neural network that is designed for mobile devices. Its main innovation lies in the use of depthwise separable convolution and the inverse residual module, which greatly reduces the computational overhead and the number of parameters and improves the computational efficiency of the network while maintaining high accuracy [
18]. MobileNetV2 is significantly faster in computing than traditional backbone networks, such as ResNet-50 and Xception. Although ResNet-50 and Xception have higher accuracy, they have higher computational overhead and are not suitable for embedded and mobile devices. MobileNetV2, on the other hand, significantly reduces computational resource consumption while maintaining performance, and is suitable for real-time and resource-constrained conditions.
2.2. Attention Mechanism
The attention mechanism is a robot learning technique that simulates the human attention pattern [
19]. To improve the semantic segmentation model’s ability to extract the edge detail information, this paper introduces the same attention mechanism to the three shallow features of the extracted MobileNetV2 backbone network and the feature layer fused with the ASPP module, as shown in
Figure 2. In this study, the widely used coordinate attention (CA), squeeze-and-excitation (SE) attention modules, latest Feature Enhancement Module (FEM), multi-scale spatial pyramid attention (MSPA) attention modules, and comparative experiments are conducted, and the attention module with the best performance for the improved model in this study is identified.
2.2.1. CA Attention Mechanism
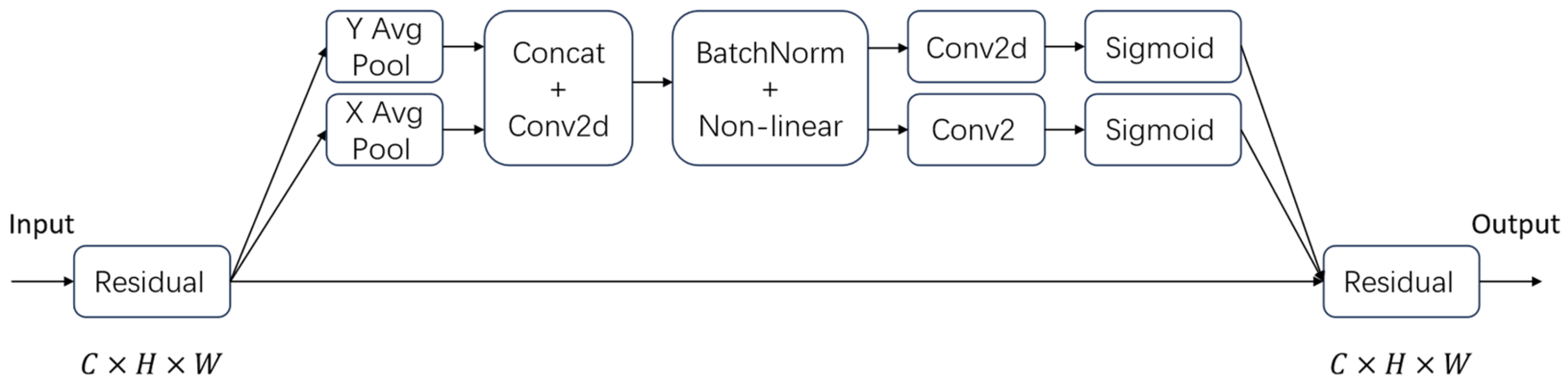
Conventional attention approaches predominantly emphasize inter-channel relationships while neglecting spatial correlations. In contrast, the Coordinate Attention (CA) mechanism [
20] incorporates spatial coordinate encoding, allowing simultaneous modeling of both channel significance and spatial dependencies, thereby significantly improving the network’s feature representation capacity. As illustrated in
Figure 3, the CA architecture comprises two key components: a coordinate encoding module and a coordinate transformation module.
In the coordinate generation module, the input feature map
,
and
are the height, width, and number of channels, respectively) is processed to generate the horizontal and vertical coordinate information. For the
c-th channel at height
h, the output is
For the
c-th channel at width
, the output is
The generated feature maps are then subjected to a fusion operation using the following fusion formula:
Subsequently, the fused feature map
undergoes a split operation, dividing it into
and
. These are then upscaled through convolution. Finally, a sigmoid activation function is applied to obtain the attention vectors:
2.2.2. SE Attention Mechanism
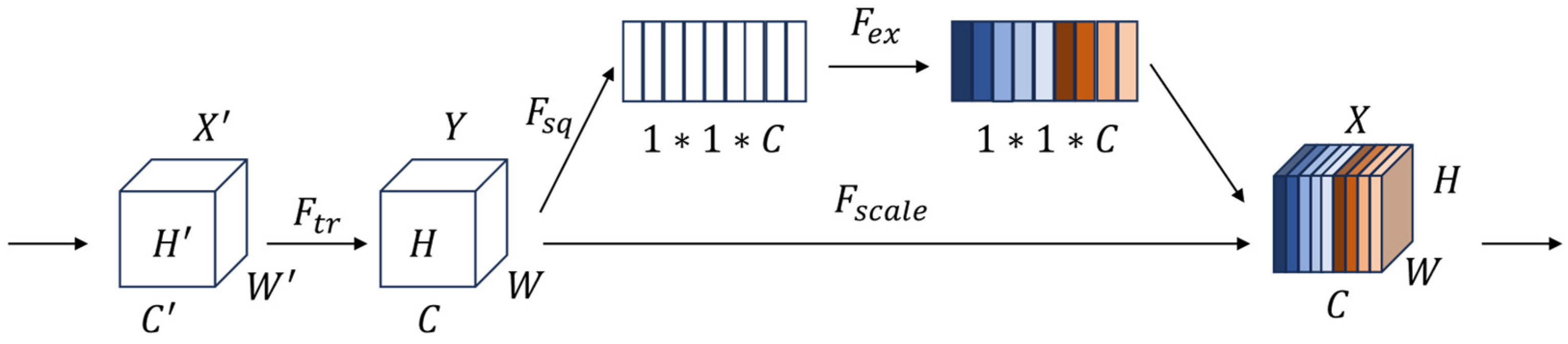
The squeeze-and-excitation (SE) module [
21] employs an adaptive channel-wise feature recalibration strategy to amplify informative feature channels while suppressing less useful ones. This mechanism operates by first squeezing global spatial information into channel descriptors, then exciting specific channels through learned weight allocations [
22]. Notably, SE achieves substantial performance improvements in deep networks with negligible computational overhead, as it enables dynamic feature refinement across channels. In our framework, we leverage SE’s weighting capability in the encoder to selectively emphasize discriminative features and attenuate irrelevant ones, thereby enhancing prediction accuracy. The detailed architecture of SE is illustrated in
Figure 4.
The SE mechanism begins by applying global average pooling to the input feature map
, thereby obtaining global information for each channel. Assuming that input image has dimensions
and
channels, let
represent the value of the input feature map at positions
in the
c-th channel. The global average pooling operation computes the channel descriptor
as follows:
The weights
for each channel are generated through fully connected layers, with the aim of determining which channels should be emphasized via learning. Here,
and
represent the ReLU and Sigmoid activation functions, respectively, whereas
and
denote the weight matrices of the first and second fully connected layers, respectively.
Finally, the learned channel weights
are used to calibrate each channel of the input feature map. Specifically, weights
are multiplied by each channel of the input feature map, thereby adjusting the contribution of each channel. where,
represents the weighted feature map.
2.2.3. FEM Attention Mechanism
In small object detection tasks, the constrained feature extraction capacity of backbone networks frequently leads to inadequate feature information acquisition and restricted perceptual fields, posing significant challenges for capturing discriminative small object features. This limitation becomes especially evident in complex environments, like remote sensing imagery, where small targets often merge with cluttered backgrounds or share similar characteristics with their surroundings. To address this issue, the lightweight Feature Enhancement Module (FEM) [
23] employs a dual-branch architecture to reinforce small object features from complementary aspects, thereby improving feature representation capabilities.
The Feature Enhancement Module (FEM) adopts a parallel multi-scale convolutional architecture to simultaneously extract heterogeneous semantic representations, significantly enriching feature diversity. This innovative design effectively addresses the common limitation of conventional single-path networks in preserving minute yet critical small object characteristics. Through hierarchical feature extraction across varying scales and receptive fields, the module demonstrates remarkable capability in retaining and highlighting subtle visual cues that are typically overlooked. Notably, FEM incorporates dilated convolutions to systematically enlarge the perceptual scope, facilitating more robust local context modeling. Such architectural consideration proves vital for small object recognition, where expanded field-of-view enables more accurate spatial relationship analysis between targets and their environment, consequently mitigating false detection risks induced by background interference or feature ambiguities.
The architectural design of FEM, depicted in
Figure 5, achieves an optimal balance between computational efficiency and detection performance. This lightweight framework synergistically combines multi-scale convolutional pathways with strategically placed dilated convolutions, delivering enhanced feature characterization while maintaining minimal computational demands. Such computationally efficient design renders the module particularly advantageous for deployment in resource-constrained environments. Through its simultaneous optimization of both feature discriminability and contextual awareness, FEM demonstrates substantial improvements in small target identification accuracy. These capabilities position the module as particularly effective for specialized applications including—but not limited to—aerial image analysis, security monitoring systems, and diagnostic medical imaging, where precise detection of minute targets is paramount.
Its expression is as follows:
Here, represents the standard convolution operation with a kernel size of , denotes a dilated convolution with a dilation rate of 5, Cat() signifies the concatenation operation, stands for the feature-wise addition operation, W1, W2 and W3 represent the output feature layers of the first three branches after convolution, and and denote the input and output feature layers of the FEM, respectively.
2.2.4. MSPA Attention Mechanism
The structure of multi-scale spatial pyramid attention (MSPA) [
24] is illustrated in
Figure 6. This module primarily consists of three core components: SPR, HPC, and Softmax modules. The SPR module effectively integrates structural regularization and structural information to explore the relationships between the channels. The HPC module, by constructing hierarchical residual-like connections, expands the receptive field of the feature layers, thereby enhancing feature representation and strengthening the extraction of multi-scale spatial information. The Softmax operation efficiently establishes long-range dependencies among channels.
3. Experiments and Results Analysis
In this section, extensive experiments are conducted to demonstrate the superiority of the improved semantic segmentation model based on DeepLabV3+ proposed herein. The experiments utilize the augmented PASCAL VOC2012 dataset and are implemented and trained on hardware platforms, such as Ubuntu 20.04 LTS (Canonical Ltd., London, UK) and NVIDIA GeForce 4070Ti GPU (NVIDIA Corporation, Santa Clara, CA, USA), as well as software platforms, including CUDA 11.3 and Pytorch 1.10.0.
3.1. Dataset
3.1.1. PASCAL VOC2012 Augmented Dataset
The PASCAL VOC2012 Augmented dataset represents a widely adopted benchmark in computer vision research, formed by combining the original VOC2012 dataset with the SBD dataset. This enhanced version overcomes several constraints of the base dataset, particularly regarding small object recognition and intricate scene understanding, through comprehensive data augmentation and refinement strategies. The dataset comprises 21 distinct semantic categories (20 foreground classes plus background), covering diverse visual scenarios. For experimental evaluation, it offers 10,582 training images along with 1449 validation and 1456 test samples.
3.1.2. ADE20K Dataset
The ADE20K dataset has become a benchmark resource for scene understanding research, particularly in pixel-level annotation tasks. With its comprehensive coverage of 150 object and scene categories across diverse environments—including natural landscapes, urban settings, and indoor spaces—the dataset provides rich annotations for both semantic and instance segmentation tasks. The dataset partition includes 20,210 training samples and 2000 validation images, each containing detailed per-pixel category labels and instance-level annotations.
3.2. Evaluation Indicators
To validate the performance of the improved model proposed in this study and compare it with other models, the evaluation metrics used in this study primarily include the mean intersection over union (
mIoU), mean pixel accuracy (
mPA), and Frames Per Second (
FPS). The formulas for calculating these evaluation metrics are as follows:
In the formula, represents the number of pixels that are actually of class but are predicted as class ; represents the number of pixels that are actually of class but are predicted as class ; represents the number of pixels that are actually of class and are also predicted as class ; denotes the total number of categories, including the background; represents the total number of images processed, and denotes the time consumed by the network to process the j-th image.
The mIoU is used to measure the overlap between each category predicted by the model and the real category, and mPA reacts to the model’s ability to correctly categorize the pixels of each category. These two evaluation indexes only react to the accuracy of the model’s prediction results, which cannot reflect the real-time performance. Therefore, in this study, we again use the frame rate FPS as a measure of the speed of the model, which refers to the number of images processed or the number of video frames per second.
3.3. Ablation Experiment
The improved model employs MobileNetV2, a lightweight backbone network, for initial image feature extraction, reducing computational complexity and improving inference speed, making it ideal for practical applications. MobileNetV2’s efficient depthwise separable convolution ensures high-quality feature extraction while minimizing parameters and computations, enhancing overall efficiency and scalability. The model extracts shallow features from MobileNetV2’s first three downsampling layers, which contain rich detail and spatial structure information, crucial for accurate segmentation. By adding an attention mechanism for multi-scale feature fusion, it retains more details and enhances multi-scale feature representation, significantly boosting segmentation accuracy in complex and dynamic scenes. Additionally, MobileNetV2’s final output features are fed into the Atrous Spatial Pyramid Pooling (ASPP) module, which captures multi-scale contextual information through atrous convolutions, further improving segmentation performance and adaptability. An attention mechanism on ASPP’s output helps the model focus on key regions, reducing background interference and enhancing accuracy, robustness, and reliability. This multi-level feature extraction and optimization strategy ensures higher segmentation accuracy with efficient computation, offering a reliable, scalable, and adaptable solution for real-world applications across diverse domains.
To validate the effectiveness of the proposed improvements, we conducted backbone network comparison and ablation experiments on the PASCAL VOC2012 augmented dataset. The performance of different backbone networks on DeepLabv3+ is shown in
Table 1. The results of the ablation experiments are shown in
Table 2, where Multi-scale Feature Fusion with Additional Attention Mechanisms (MSFA) refers to multi-scale feature fusion incorporating additional attention mechanisms, and ASPP-A denotes the addition of an attention mechanism after ASPP. As can be seen from
Table 1, when the backbone network of Deeplabv3+ is switched from the original Xception to MobileNetV2, the mIoU and mPA decreased by 3.98% and 4.47%, respectively, but the FPS increased by 25.11, resulting in better real-time performance of the network. From
Table 2, it is evident that the unmodified network using MobileNetV2 achieved an mIoU of 72.56%, an mPA of 83.01%, and an FPS of 37.67. With the addition of multi-scale feature fusion with additional attention mechanisms, the mIoU and mPA increased by 1.81% and 1.74%, respectively, while the FPS decreased by 9.13. When an attention mechanism was added after the ASPP, the mIoU and mPA increased by 1.17% and 1.25%, respectively, and the FPS decreased by 7.46. When both improvements were applied simultaneously, mIoU and mPA increased by 3.89% and 3.27%, respectively, while FPS decreased by 8.49. It is clear that, at the cost of a slight reduction in real-time performance, these two improvements can enhance the accuracy of the network to varying degrees, with a more significant improvement when both are applied together.
In this study, the same attention mechanism was added to the three shallow features extracted from the MobileNetV2 backbone network and the feature layer fused with the ASPP module. Four attention modules—CA, SE, FEM, and MSPA—were selected and introduced into the improved model. The experimental results are listed in
Table 3. Among them, the FEM attention module demonstrates more significant improvement effects than the other attention modules, with mIoU and mPA increasing to 76.45% and 86.28%, respectively. In addition, it achieves a better balance between accuracy and real-time performance. Therefore, the FEM attention module was selected as the final selection for the improved model. Based on these observations and thorough experimental validation, we concluded that this attention module represents the optimal choice for our improved model architecture. Its consistent performance across various test conditions and ability to enhance both accuracy and robustness made it the clear selection for our final implementation.
3.4. Performance Evaluation
Figure 7 and
Figure 8 present the semantic segmentation results of the Deeplabv3+ network and the improved Deeplabv3+ network proposed in this paper. Specifically,
Figure 7 and
Figure 8 display the segmentation results under the training weights of the PASCAL VOC2012 augmented dataset and ADE20K dataset, respectively. To more intuitively demonstrate the improvements of the proposed algorithm over the Deeplabv3+ algorithm, this study simultaneously showcases the semantic segmentation results before and after the algorithm improvements. In the figures, column (a) represents the input images, column (b) shows the ground truth labels, column (c) displays the semantic segmentation results of the original Deeplabv3+, and column (d) presents the semantic segmentation results of the improved network.
From the experimental results, it is evident that the improved DeepLabv3+ network proposed in this study is capable of performing efficient and precise semantic segmentation of various objects and urban road scenes with different complexity levels. In simple road environments and complex urban landscapes, the network demonstrates exceptional segmentation capabilities. Compared with the pre-improvement network, the enhanced version exhibits significant advantages in multiple aspects. First, its prediction accuracy is substantially improved, enabling more accurate identification and classification of various objects in the images, particularly when handling multi-category and multi-scale targets. Second, the prediction results generated by the improved network feature clearer and smoother contours, significantly reducing edge blurring and noise interference, making the segmentation results more aligned with real-world scenes, thereby enhancing visual quality and practicality. Additionally, segmentation precision is notably improved, especially when processing scenes rich in details or with complex backgrounds. The improved network can capture subtle features better, thereby boosting the overall segmentation performance.
Finally, the enhanced network exhibited stronger robustness and maintained a stable performance under varying lighting conditions, weather changes, and complex backgrounds. Whether in strong light, low light, shadows, or rain and snow, the network consistently achieves a high segmentation accuracy and consistency. This further validates its reliability and adaptability in practical applications, particularly in fields such as autonomous driving and intelligent traffic monitoring, in which real-time performance and robustness are critical. The improved network demonstrates significant potential for these applications. Overall, the proposed improvement method not only significantly enhances the network’s performance but also lays a solid foundation for its widespread application in real-world scenarios.
On the PASCAL VOC2012 augmented dataset and the ADE20K dataset, this study conducted a comprehensive performance comparison between the improved network and various state-of-the-art semantic segmentation networks, with the specific results shown in
Table 4 and
Table 5. From the data in the tables, it can be observed that the improved network proposed in this paper excels in segmentation accuracy, approaching the performance levels of high-precision network models, such as CCNet (which uses criss-cross attention for long-range context but suffers from high computation), ISANet (excels in multi-scale fusion via self-attention yet is resource-intensive), and PSANet (leverages spatial attention for context aggregation but requires heavy memory), while significantly outperforming OCRNet (relies on object-contextual representations but lacks real-time efficiency) and Deeplabv3+ based on MobileNetV2. Particularly when handling complex scenes and detail-rich images, the proposed network can capture the boundaries and detailed information of target objects more accurately, thereby enhancing the overall segmentation effect.
Additionally, in terms of real-time performance, the proposed network demonstrates a clear advantage, with inference speeds significantly faster than those of computationally intensive models, such as CCNet, ISANet, and PSANet. Overall, the improved network not only achieves leading-edge segmentation accuracy but also strikes a good balance between accuracy and real-time performance, better meeting the practical demands for efficient and precise semantic segmentation. These results indicate that the proposed improvement method not only enhances network performance but also considers computational efficiency, providing strong support for the engineering applications of semantic segmentation tasks.
On the Cityscapes dataset, we conducted comparative analysis with several representative state-of-the-art (SOTA) semantic segmentation models as baselines, including DDRNet, known for its excellent real-time performance, and Mask2Former, recognized for its leading accuracy. The performance comparison with other advanced networks on the Cityscapes dataset is shown in
Table 6. Experimental results demonstrate that, while our improved model shows enhanced performance compared to its previous version, it achieves a better balance between accuracy and real-time efficiency when benchmarked against higher-accuracy SOTA models.
4. Conclusions
To meet the urgent demand for real-time performance in practical applications of semantic segmentation algorithms, this study focused on optimizing and improving the DeepLabv3+ network. First, in the selection of the backbone network, lightweight MobileNetV2 was adopted to reduce the computational complexity and enhance the inference speed. To further optimize the feature extraction process, multi-scale feature fusion was performed on the shallow features obtained from the first three downsampling layers of MobileNetV2, and the FEM attention mechanism was introduced during the fusion process. This design not only preserves more detailed information, avoiding feature loss caused by downsampling, but also significantly enhances the network’s ability to represent multi-scale features, thereby improving the model’s segmentation performance in complex scenes.
Additionally, to further increase the network’s focus on critical information, the FEM attention mechanism is introduced on the feature maps processed by the Atrous Spatial Pyramid Pooling (ASPP) module. Through this improvement, the network can adaptively focus on important regions in the image, reducing interference from irrelevant background information, and thus further enhancing segmentation accuracy. Experimental results show that, compared to the original DeepLabv3+ network and other mainstream semantic segmentation models, the improved network proposed in this paper maintains high semantic segmentation accuracy while significantly improving computational efficiency, achieving a better balance between accuracy and speed. This improvement makes the network more suitable for practical application scenarios, such as autonomous driving and intelligent surveillance, which require high real-time performance and provide strong support for the engineering implementation of semantic segmentation technology.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}