
An Enhanced Genetic Algorithm for Optimized Educational Assessment Test Generation Through Population Variation


Abstract
1. Introduction
2. Literature Review
2.1. Qualitative Literature Analysis
- encoding techniques (e.g., binary-coded, real-coded);
- genetic operators approach, for the crossover (e.g., single-point crossover, two-point crossover), mutation (e.g., swap mutation) or selection (e.g., sort, roulette wheel, tournament selection) operators, with variate configurations for each operator;
- fitness function type, either being single or multiobjective type.
- difficulty in large or complex dimensions of data;
- the determination of the optimal genetic algorithm parameters;
- search space challenges, where the solution space is massive and the searching process of the best chromosome is difficult.
- Hybrid diversity approaches, combining operator adaptability with inter-individual distance measures [52].
2.2. Quantitative Literature Analysis
- Step 1:
- Keyword search: performed in Dimensions.ai using “genetic algorithm population variation”;
- Step 2:
- Data export: via platform options;
- Step 3:
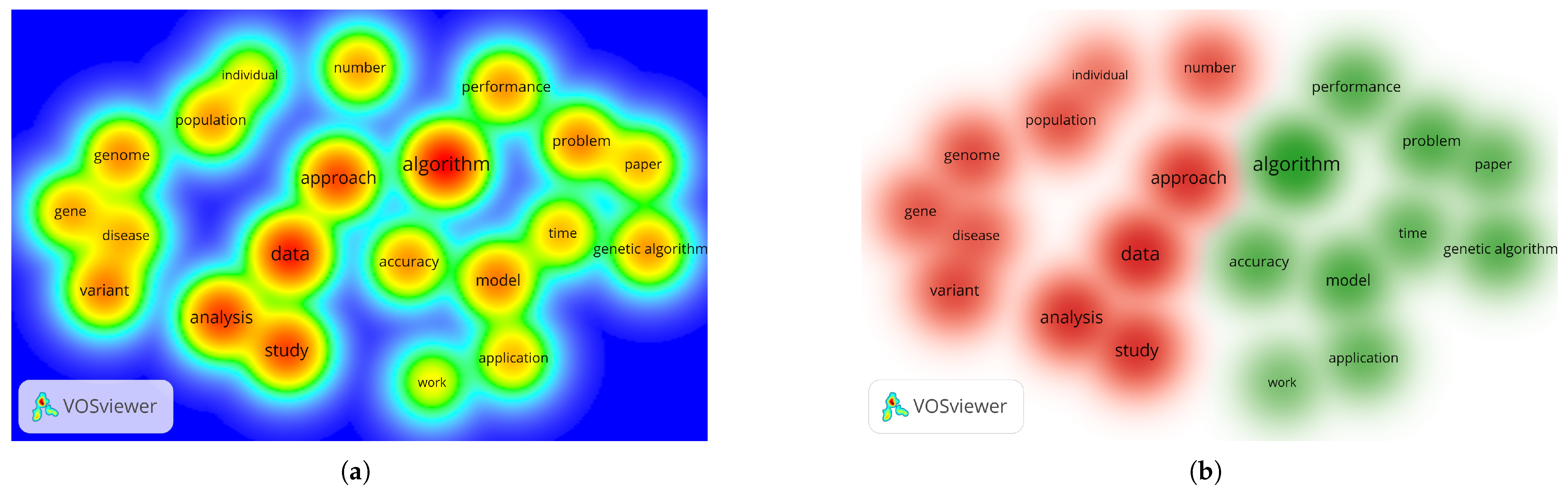
- Term mapping: using VOSViewer 1.6.20 [54], with a minimum threshold of 50 occurrences, resulting in 21 terms.
3. Model Description
3.1. Purpose
3.2. Mathematical Formulation
- is the average difficulty of the items in the test ;
- is the user-defined target difficulty.
- Generate k independent sub-populations:
- From each , select the top F chromosomes according to fitness:
- Merge all selected sets:
- Sort in descending order of using merge sort:
- Select the top chromosome.
3.3. Elements
3.3.1. Assessment Test Structures
- q: the item, a tuple , generated and stored in a database, where the elements of the tuple are:
- –
- id, : the unique identification particle of the item;
- –
- nkw, : the number of keywords that define an item;
- –
- kw, : the set of keywords that define an item. A keyword is a word or expression that describes the topic of the item. The set of keywords can be obtained manually by a human operator or automatically using Machine Learning (ML) based NLP (Natural Language Processing) techniques;
- –
- d, : the degree of difficulty of the item, calculated using specific metrics (usually statistical, as the ratio between the correct number of responses to the item and the total number of answers to the item);
- –
- type, : the item type, where m has the meaning of multiple-choice item, e essay item and s short-answer item.
- SI: the sequence of items, a tuple which codifies an educational assessment test generated based on requirements using genetic algorithms. The elements of the tuple are:
- –
- id, is the unique identification particle of the test;
- –
- is the test size (number of questions);
- –
- is the set of items that form the test;
- –
- : the reunion of the sets of keywords of all the items q within the sequence;
- –
- is the degree of difficulty of the item, calculated as an average of the degrees of difficulty of all the items that form a test, as follows:
- C: the set of courses, , where is a course taught in a series of courses over a period of time. The item formation is made from the content of these courses, either manually or using automated methods. The number of courses in the assessment can be represented equally (the number of items associated with a course equal with ) or weights given to courses can be considered related to m.
- R: the set of requirements {}, where is a requirement for the test generation and k the total number of requirements. A requirement is a rule set by the user for the final result of the assessment test (e.g., the degree of difficulty of the test). For this paper, and the requirements are as follows:
- –
- is the requirement related to the topic of the items needed in the sequence. This requirement is related to the set of keywords desired by the user, where is the list of user-defined keywords and their number;
- –
- is the requirement related to the degree of difficulty. is related to the desired degree of difficulty. ;
- –
- is the requirement related to the predominant item type, which can take values from the set, thus .
3.3.2. Genetic Structures
Genetic Structures and Fitness Function
- : a gene representing an individual test item , where ;
- : a chromosome encoding a sequence of items ;
- : a quadruple representing the genetic algorithm parameters:
- –
- —initial population size,
- –
- —number of generations,
- –
- —mutation rate,
- –
- —crossover rate.
- : the fitness function, computed as an average of weighted sigmoid functions:with user-defined weights , satisfying , and .
- : number of overlapping keywords between the user-defined set and the test keywords .
- : average frequency of user-defined keywords in the sequence . If any , then .
- : measures the uniformity of keyword usage; is the average frequency.
- : inverse of the absolute difference between the desired difficulty and actual test difficulty D.
- : proportion of user-preferred item type in the sequence of m items.The total area under the fitness curve over the interval can be expressed as:ensuring normalization and boundedness of the fitness function.
3.3.3. Genetic Operators
- mutation operator Mut, defined as the replacement of a randomly-selected gene within a randomly-selected chromosome with a randomly-selected gene;
- crossover operator Csv, where two parent chromosomes combine related to a randomly-selected position in a manner that two new child chromosomes are obtained;
- selection operator Sel, which selects the chromosomes with the best fitness function values.
3.4. Usual and Improved GA Algorithm
- the initial (usual) algorithm, that was used to generate assessment test in previous papers;
- the improved algorithm, developed based on the methodology currently presented in this paper.
3.4.1. Usual GA Algorithm
- Step 1:
- The input data (Q set, , , and ) is read.
- Step 2:
- The genetic algorithm is applied, as follows:
- (a)
- the generation of the initial population of items is made;
- (b)
- the mutation operation is applied;
- (c)
- the crossover operation is applied;
- (d)
- the resulted chromosomes are selected;
- (e)
- after generations, the best chromosome is selected.
- Step 3:
- The best chromosome is input.
| Algorithm 1 Usual GA algorithm |
|
3.4.2. Improved GA Algorithm
- Step 1:
- The input data (Q set, , , , , and F) is read. is the number of runs of genetic algorithm and F is the number of chromosomes taken into account at each run.
- Step 2:
- The genetic algorithm is applied, as follows:
- (a)
- the generation of the initial population of items is made;
- (b)
- the mutation operation is applied;
- (c)
- the crossover operation is applied;
- (d)
- the resulted chromosomes are selected;
- (e)
- after generations, the best F chromosomes are selected and added to the set, where retains the best F chromosomes from each GA run.
- Step 3:
- After runs, the set is established.
- Step 4:
- Merge sort is applied in set depending on the fitness values.
- Step 5:
- The best chromosome is input.
| Algorithm 2 Improved GA algorithm |
|
4. Research Methodology
- Step RM1.
- Purpose: the main purpose of the methodology was to validate the hypotheses A and B referred as improvements for the usual GA algorithm.
- Step RM2.
- Design: the design step included the research type used in the study, the used variables (the fitness value and the population diversity) and the study group of individuals, delimited by the chosen GA algorithm. These elements are described as follows:
- research type: the research was made using the observational study method. This method was chosen as the results related to diversity and performance can be compared directly;
- variables: new operations were applied to the usual GA algorithm that were presented in previous sections. The two variables computed for the hypotheses were:
- –
- , the fitness value of the best chromosome;
- –
- , the population diversity, calculated as the average value of all the Euclidean distances between the chromosomes in the final population:where
- study groups: two main comparison groups were determined:
- –
- , the control group, consisting in the best chromosome and its calculated fitness value, as well as the representative population, for the usual GA algorithm;
- –
- , the experimental group, consisting in the best chromosome and its calculated fitness value, as well as the representative population, for the improved GA algorithm.
The main purpose of this step was to establish a research context which would include performance analysis (by fitness values and variation) and comparative observations between the two described approaches (initial and improved GA). - Step RM3.
- Hypotheses formulation: Two main hypotheses were formulated:
- hypothesis A: The population diversity for the group is higher than the population diversity for the group.
- hypothesis B: The fitness value for the group is higher than the fitness value for the group.
These hypotheses were determined in order to establish the scientific approach related to the improvements brought by the novel GA in connection to population diversity and performance. - Step RM4.
- Data collection: item data was randomly generated using implementation-based techniques. The usage of randomly-generated data created an unbiased context related to human influence on the selection of initial items. Also, the experimental nature of the approach is a preliminary step for the implementation of the described method using real-time context data.
- Step RM5.
- Data analysis: the direct comparison method was used. The comparison was made between the mean values of the fitness and variation variables for rounds of runs (each round was a mean of five runs). This approach ensured that extreme values or exceptional cases were not used to determine the performance. After the computation of the values, these were directly compared in order to establish the differences in performance.
- Step RM6.
- Limitations: obviously, the approach has several in-built limitations, referring to the next facts:
- Euclidean distance may not always reflect semantic or functional differences between individuals in the population.
- Using the fitness function value of the best chromosome to measure diversity may not be representative of the entire population.
- The calculation methods of Euclidean distance and fitness function value are influenced by specific parameters of the genetic algorithm, such as coding, selection method, crossover and mutation rates, etc. Changing these parameters can affect the diversity measures and lead to different interpretations of the results.
- A single measure (Euclidean distance) may not be sufficient to fully understand population diversity. Other approaches, such as entropy, may be used.
5. Results and Discussions
- the number of items in the database (N) was 1000;
- the number of courses was set to 5 (n = 5)
- the number of desired items in the sequence (m) was 10;
- three keywords were chosen (;
- a degree of difficulty of 0.4 was chosen (;
- the desired type of question was chosen as multiple-choice (;
- the mutation rate was established at 0.8 (;
- the crossover rate was established at 0.5 (;
- the population size was established at 50 (;
- the number of generations was established at 50 (;
- the proportion of best chromosomes for each population was established at 10 (;
- the number of obtained generation was set to 50 (.
- the number of items in the database (N) was 400;
- the number of desired items in the sequence (m) was 10;
- three keywords were chosen (;
- a degree of difficulty of 0.4 was chosen (;
- the desired type of question was chosen as multiple-choice (;
- the mutation rate was established at 0.1 (;
- the crossover rate was established at 0.5 (;
- the population size was established at 50 (;
- the number of generations was established at 50 (;
- the proportion of best chromosomes for each population was established at 10 (;
- the number of obtained generation was set to 100 (.
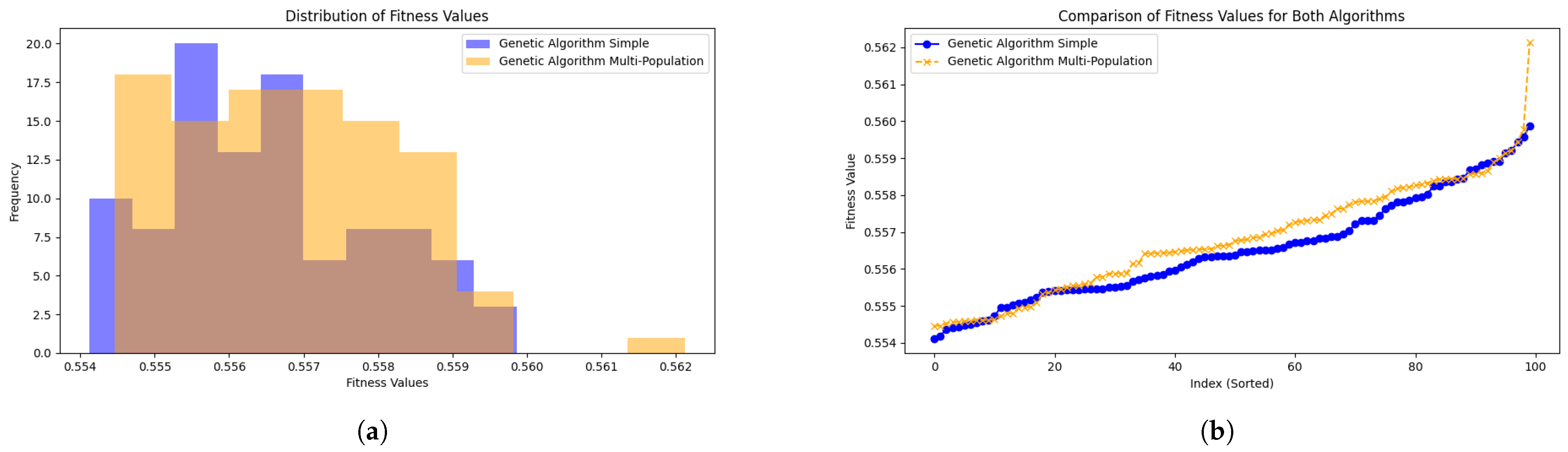
- the initial population size and the database size influences greatly the diversity of the final population;
- higher mutation and crossover rates lead to finer and more accurate results, with moderately higher values of fitness function as the rates increase, but with a mild increase in runtime;
- the number of generations influences greatly the accuracy of the results, increasing the fitness values with higher rates, but also having an great impact on the runtime.
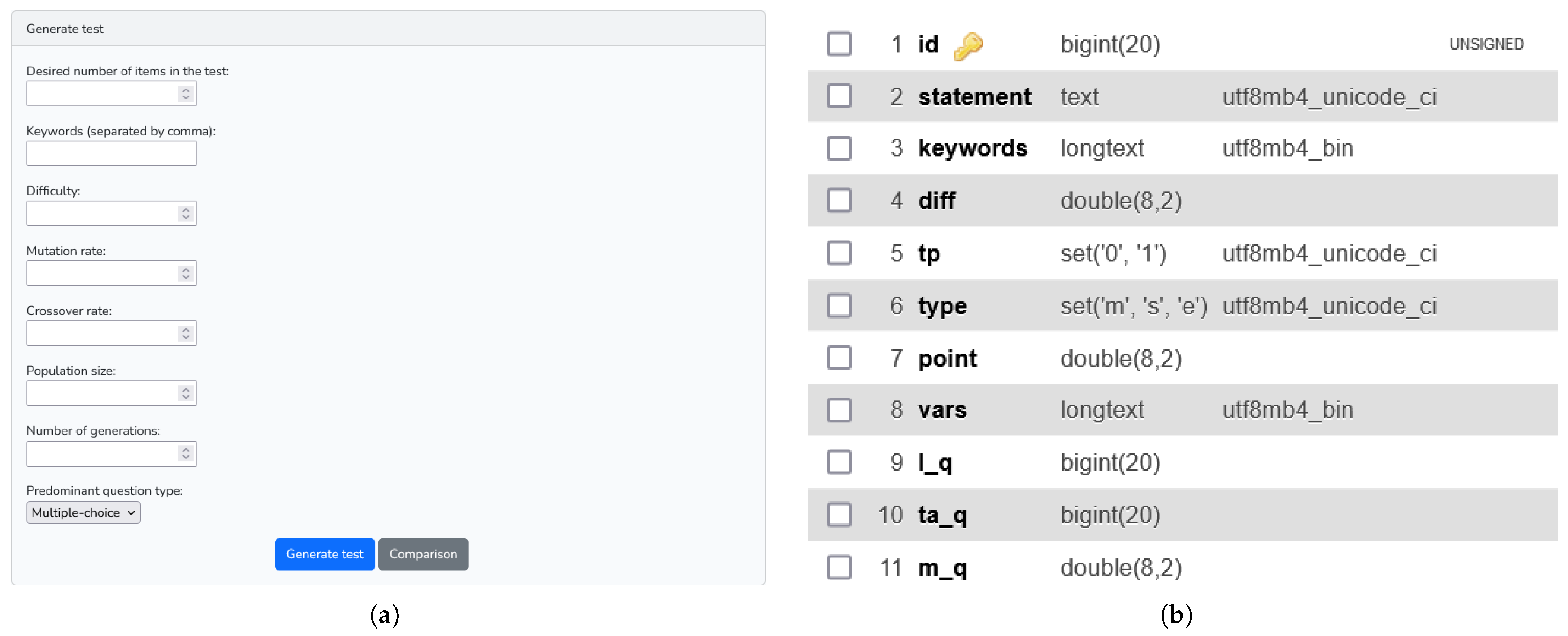
- the item identification number (id);
- the statement (statement);
- the set of keywords defining the item (keywords);
- the degree of difficulty (diff);
- the type (multiple choice, short or essay) (type);
- the choices statement (whether the case) (vars);
- the theoretical or practical nature of the item (tp);
- the score of the item (point).
- the average score of the item (m_q);
- the number of correct answers to the item (l_q);
- the number of students that answered the item (ma_q).
6. Conclusions
- Population diversity: using multiple nested sorted populations resulted in greater diversity in the total population;
- Exploration of the solution space: multiple populations allow for a wider exploration of the solution space;
- Convergence to higher-quality solutions: the combination of population diversity and exploration of the solution space can contribute to convergence to higher-quality solutions;
- Need to adjust parameters: to get the best results, it may be necessary to adjust the parameters of the genetic algorithm.
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| GA | Genetic Algorithm |
| LP | Linear Programming |
| PSO | Particle Swarm Optimisation |
| MOEA | Evolutionary Algorithms for Multi-Criterion Optimization |
| ACO | Ant Colony Optimisation |
| ML | Machine-Learning |
| NLP | Natural Language Processing |
References
- Bertsimas, D.; Tsitsiklis, J.N. Introduction to Linear Optimization; Athena Scientific: Belmon, MA, USA, 1997; pp. 479–530. [Google Scholar]
- Nemhauser, G.L.; Wolsey, L.A. Integer and Combinatorial Optimization; Wiley-Interscience: New York, NY, USA, 1999. [Google Scholar]
- Jackson, P. Introduction to Expert Systems, 3rd ed.; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 1998. [Google Scholar]
- Giarratano, J.C.; Riley, G.D. Expert Systems: Principles and Programming; Brooks/Cole Publishing Co.: Pacific Grove, CA, USA, 2005. [Google Scholar]
- Ricci, F.; Rokach, L.; Shapira, B. (Eds.) Recommender Systems Handbook, 3rd ed.; Springer: New York, NY, USA, 2022. [Google Scholar]
- Adomavicius, G.; Tuzhilin, A. Toward the Next Generation of Recommender Systems: A Survey of the State-of-the-Art and Future Directions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Mitchell, T.M. Machine Learning; McGraw-Hill: New York, NY, USA, 1997. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle Swarm Optimization. In Proceedings of the IEEE International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995; pp. 1942–1948. [Google Scholar]
- Clerc, M.; Kennedy, J. The Particle Swarm—Explosion, Stability, and Convergence in a Multidimensional Complex Space. IEEE Trans. Evol. Comput. 2002, 6, 58–73. [Google Scholar] [CrossRef]
- Aarts, E.H.L.; Lenstra, J.K. Local Search in Combinatorial Optimization; John Wiley & Sons: Hoboken, NJ, USA, 1997. [Google Scholar]
- Kirkpatrick, S.; Gelatt, C.D.; Vecchi, M.P. Optimization by Simulated Annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef]
- Deb, K.; Agrawal, R.B. Simulated binary crossover for continuous search space. Complex Syst. 1995, 9, 115–148. [Google Scholar]
- Zitzler, E.; Thiele, L. Multiobjective Evolutionary Algorithms: A Comparative Case Study and the Strength Pareto Approach. IEEE Trans. Evol. Comput. 1999, 3, 257–271. [Google Scholar] [CrossRef]
- Holland, J.H. Adaptation in Natural and Artificial Systems; University of Michigan Press: Ann Arbor, MI, USA, 1975. [Google Scholar]
- Goldberg, D.E. Genetic Algorithms in Search, Optimization, and Machine Learning; Addison-Wesley: New York, NY, USA, 1989. [Google Scholar]
- Dorigo, M.; Stützle, T. Ant Colony Optimization; MIT Press: Cambridge, MA, USA, 2004. [Google Scholar]
- Blumer, A.; Karp, R.M. Ant Algorithms for Network Routing. In Proceedings of the International Conference on Networking and Services, Las Vegas, NV, USA, 23–26 June 2003. [Google Scholar]
- Popescu, D.A.; Stanciu, G.C.; Nijloveanu, D. Evaluation Test Generator Using a List of Keywords. In Proceedings of the Intelligent Tutoring Systems: 17th International Conference, ITS 2021, Virtual Event, 7–11 June 2021; Proceedings 17. Springer: Berlin/Heidelberg, Germany, 2021; pp. 481–489. [Google Scholar]
- Victor, T.; Daniel, N.; Popescu, D.A.; Bold, N. Study on the efficiency of the design of the drip irrigation management system using plastics. J. Intell. Fuzzy Syst. 2022, 43, 1697–1705. [Google Scholar] [CrossRef]
- Nijloveanu, D.; Tita, V. Elaboration of some models to reduce the hydric erosion in Olt county. Econ. Eng. Agric. Rural Dev. 2012, 12, 169–282. [Google Scholar]
- Thakkar, A.; Chaudhari, K. Applicability of genetic algorithms for stock market prediction: A systematic survey of the last decade. Comput. Sci. Rev. 2024, 53, 100652. [Google Scholar] [CrossRef]
- Smedescu, D.; Tudor, V.; Micu, M.M.; Mărcuță, L.; Mărcuță, A.; Smedescu, C. Comparative insights into labour productivity trends in the european union’s agri-food sector. Sci. Pap. Ser. Manag. Econ. Eng. Agric. Rural Dev. 2024, 24, 899–908. [Google Scholar]
- Chahar, V.; Katoch, S.; Chauhan, S. A Review on Genetic Algorithm: Past, Present, and Future. Multimed. Tools Appl. 2021, 80, 8091–8126. [Google Scholar]
- Angelova, M.; Pencheva, T. Tuning Genetic Algorithm Parameters to Improve Convergence Time. Int. J. Chem. Eng. 2011, 2011, 646917. [Google Scholar] [CrossRef]
- Pandey, H.M.; Chaudhary, A.; Mehrotra, D. A comparative review of approaches to prevent premature convergence in GA. Appl. Soft Comput. 2014, 24, 1047–1077. [Google Scholar] [CrossRef]
- Ibrahim Kucukkoc, A.D.K.; Yaman, R. Using response surface design to determine the optimal parameters of genetic algorithm and a case study. Int. J. Prod. Res. 2013, 51, 5039–5054. [Google Scholar] [CrossRef]
- Deep, K.; Thakur, M. A new mutation operator for real coded genetic algorithms. Appl. Math. Comput. 2007, 193, 211–230. [Google Scholar] [CrossRef]
- Ono, I. A real-coded genetic algorithms for function optimization using unimodal normal distribution crossover. In Proceedings of the Seventh International Conference on Genetic Algorithms: Michigan State University, East Lansing, MI, USA, 19–23 July 1997; pp. 246–253. [Google Scholar]
- Tan, K.; Li, Y.; Murray-Smith, D.; Sharman, K. System Identification And Linearisation Using Genetic Algorithms With Simulated Annealing. In Proceedings of the First International Conference on Genetic Algorithms in Engineering Systems: Innovations and Applications, Sheffield, UK, 12–14 September 1995. [Google Scholar]
- Hedar, A.R.; Fukushima, M. Simplex Coding Genetic Algorithm for the Global Optimization of Nonlinear Functions; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Da Ronco, C.C.; Benini, E. A simplex crossover based evolutionary algorithm including the genetic diversity as objective. Appl. Soft Comput. 2013, 13, 2104–2123. [Google Scholar] [CrossRef]
- Richter, J.N.; Peak, D. Fuzzy evolutionary cellular automata. In Proceedings of the International Conference on Artificial Neural Networks In Engineering, Honolulu, HI, USA, 12–17 May 2002; Volume 24, p. 185. [Google Scholar]
- Harik, G.R.; Lobo, F.G. A parameter-less genetic algorithm. In Proceedings of the GECCO, Orlando, FL, USA, 13–17 July 1999; Volume 99, pp. 258–267. [Google Scholar]
- Feng, L.; Ong, Y.S.; Gupta, A. Genetic algorithm and its advances in embracing memetics. In Evolutionary and Swarm Intelligence Algorithms; Springer: Berlin/Heidelberg, Germany, 2019; pp. 61–84. [Google Scholar]
- Wan, W.; Birch, J.B. An improved hybrid genetic algorithm with a new local search procedure. J. Appl. Math. 2013, 2013, 103591. [Google Scholar] [CrossRef]
- Yusoff, M.; Roslan, N. Evaluation of genetic algorithm and hybrid genetic algorithm-hill climbing with elitist for lecturer university timetabling problem. In Proceedings of the Advances in Swarm Intelligence: 10th International Conference, ICSI 2019, Chiang Mai, Thailand, 26–30 July 2019; Proceedings, Part I 10. Springer: Berlin/Heidelberg, Germany, 2019; pp. 363–373. [Google Scholar]
- D’Angelo, G.; Palmieri, F. GGA: A modified genetic algorithm with gradient-based local search for solving constrained optimization problems. Inf. Sci. 2021, 547, 136–162. [Google Scholar] [CrossRef]
- Ross, B.J. A Lamarckian evolution strategy for genetic algorithms. In Practical Handbook of Genetic Algorithms; CRC Press: Boca Raton, FL, USA, 2019; pp. 1–16. [Google Scholar]
- Akopov, A.S.; Beklaryan, L.A. Traffic Improvement in Manhattan Road Networks With the Use of Parallel Hybrid Biobjective Genetic Algorithm. IEEE Access 2024, 12, 19532–19552. [Google Scholar] [CrossRef]
- Whitley, D.; Starkweather, T. Genitor II: A distributed genetic algorithm. J. Exp. Theor. Artif. Intell. 1990, 2, 189–214. [Google Scholar] [CrossRef]
- Bhandari, D.; Murthy, C.A.; Pal, S.K. Genetic algorithm with elitist model and its convergence. Int. J. Pattern Recognit. Artif. Intell. 1996, 10, 731–747. [Google Scholar] [CrossRef]
- Ahn, C.W.; Ramakrishna, R.S. Elitism-based compact genetic algorithms. IEEE Trans. Evol. Comput. 2003, 7, 367–385. [Google Scholar]
- Du, H.; Wang, Z.; Zhan, W.; Guo, J. Elitism and distance strategy for selection of evolutionary algorithms. IEEE Access 2018, 6, 44531–44541. [Google Scholar] [CrossRef]
- Kouchakpour, P.; Zaknich, A.; Bräunl, T. Population variation in genetic programming. Inf. Sci. 2007, 177, 3438–3452. [Google Scholar] [CrossRef]
- Gibbs, M.S.; Maier, H.R.; Dandy, G.C. Using characteristics of the optimisation problem to determine the genetic algorithm population size when the number of evaluations is limited. Environ. Model. Softw. 2015, 69, 226–239. [Google Scholar] [CrossRef]
- Kouchakpour, P.; Zaknich, A.; Bräunl, T. Dynamic population variation in genetic programming. Inf. Sci. 2009, 179, 1078–1091. [Google Scholar] [CrossRef]
- Shapiro, B.A.; Wu, J.C.; Bengali, D.; Potts, M.J. The massively parallel genetic algorithm for RNA folding: MIMD implementation and population variation. Bioinformatics 2001, 17, 137–148. [Google Scholar] [CrossRef]
- Razali, N.M.; Geraghty, J. Genetic algorithm performance with different selection strategies in solving TSP. In Proceedings of the World Congress on Engineering, London, UK, 6–8 July 2011; International Association of Engineers: Hong Kong, China, 2011; Volume 2, pp. 1–6. [Google Scholar]
- Kreinovich, V.; Quintana, C.; Fuentes, O. Genetic algorithms: What fitness scaling is optimal? Cybern. Syst. 1993, 24, 9–26. [Google Scholar] [CrossRef]
- Chehouri, A.; Younes, R.; Khoder, J.; Perron, J.; Ilinca, A. A selection process for genetic algorithm using clustering analysis. Algorithms 2017, 10, 123. [Google Scholar] [CrossRef]
- Xinping, L.; Ying, L. Adaptive Genetic Algorithm Based on Population Diversity. In Proceedings of the 2009 International Forum on Information Technology and Applications, Chengdu, China, 15–17 May 2009; Volume 2. [Google Scholar]
- Hook, D.W.; Porter, S.J.; Herzog, C. Dimensions: Building Context for Search and Evaluation. Front. Res. Metrics Anal. 2018, 3, 23. [Google Scholar] [CrossRef]
- Wong, D. VOSviewer. Tech. Serv. Q. 2018, 35, 219–220. [Google Scholar] [CrossRef]
- Popescu, D.A.; Ileana, M.; Bold, N. Analyzing the Performance of Distributed Web Systems Within an Educational Assessment Framework. In Breaking Barriers with Generative Intelligence; Using GI to Improve Human Education and Well-Being; Basiouni, A., Frasson, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2024; pp. 102–115. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| Method | Complexity | Compute Cost | Accuracy | Scalability | Main Disadvantage |
|---|---|---|---|---|---|
| LP | Moderate | High | High | Moderate | Diversity of item types |
| Expert systems | Low | Low | Moderate | Low | Adaptability |
| Recommender systems | Moderate | Moderate | Moderate | Moderate | Partial optimisation |
| Supervised learning | High | Variable | High | High | Big Data for training |
| PSO | Moderate | Moderate | High | High | Premature convergence |
| Simulated Annealing | Moderate | Moderate | Moderate | Moderate | Global exploration |
| MOEA | High | High | High | High | - |
| GA | High | Moderate | High | High | - |
| ACO | Moderate | Moderate | High | High | - |
| No. | Term | Relevance Score | Occurrences |
|---|---|---|---|
| 14 | paper | 24.477 | 98 |
| 20 | variant | 19.765 | 139 |
| 17 | problem | 18.002 | 131 |
| 7 | disease | 16.697 | 97 |
| 10 | genome | 16.482 | 128 |
| 19 | time | 12.332 | 96 |
| 9 | genetic algorithm | 2.651 | 117 |
| 8 | gene | 2.082 | 106 |
| 15 | performance | 0.7211 | 121 |
| 3 | analysis | 0.6668 | 202 |
| 16 | population | 0.6054 | 116 |
| No. | Challenge | Strategies |
|---|---|---|
| 1 | Algorithm convergence | Lamarckian genetic algorithms Parallel and distributed GAs |
| 2 | Large dimensions of data | Genetic-local search methods |
| 3 | GA parameter | Fuzzy logic Parameter-less Variation in genetic operators Genetic operator replacement Hybrid algorithms |
| 4 | Search space | Response surface-dependent parameter Elitism strategies |
| Metric | Usual GA | Improved GA |
|---|---|---|
| Max Fitness | 0.559866 | 0.562122 |
| Min Fitness | 0.554124 | 0.554461 |
| Avg Fitness | 0.556522 | 0.556801 |
| No. | Run | Fitness G1 | Fitness G2 | var G1 | var G2 |
|---|---|---|---|---|---|
| 1 | Run 1 | 0.573 | 0.576 | 274.155 | 283.806 |
| 2 | Run 2 | 0.568 | 0.579 | 250.249 | 279.087 |
| 3 | Run 3 | 0.557 | 0.576 | 214.318 | 283.185 |
| 4 | Run 4 | 0.570 | 0.579 | 292.030 | 285.178 |
| 5 | Run 5 | 0.567 | 0.579 | 223.110 | 281.297 |
| 6 | Run 6 | 0.562 | 0.579 | 238.708 | 281.993 |
| 7 | Run 7 | 0.564 | 0.579 | 288.253 | 281.107 |
| 8 | Run 8 | 0.568 | 0.580 | 275.557 | 283.338 |
| 9 | Run 9 | 0.567 | 0.580 | 232.573 | 286.446 |
| 10 | Run 10 | 0.562 | 0.576 | 235.989 | 281.244 |
| Average | 0.566 | 0.578 | 252.494 | 282.668 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Popescu, D.-A. An Enhanced Genetic Algorithm for Optimized Educational Assessment Test Generation Through Population Variation. Big Data Cogn. Comput. 2025, 9, 98. https://doi.org/10.3390/bdcc9040098
Popescu D-A. An Enhanced Genetic Algorithm for Optimized Educational Assessment Test Generation Through Population Variation. Big Data and Cognitive Computing. 2025; 9(4):98. https://doi.org/10.3390/bdcc9040098
Chicago/Turabian StylePopescu, Doru-Anastasiu. 2025. "An Enhanced Genetic Algorithm for Optimized Educational Assessment Test Generation Through Population Variation" Big Data and Cognitive Computing 9, no. 4: 98. https://doi.org/10.3390/bdcc9040098
APA StylePopescu, D.-A. (2025). An Enhanced Genetic Algorithm for Optimized Educational Assessment Test Generation Through Population Variation. Big Data and Cognitive Computing, 9(4), 98. https://doi.org/10.3390/bdcc9040098