
Exploration of Generative Neural Networks for Police Facial Sketches



Abstract
1. Introduction
- Direct or Artistic Method: An artist’s drawing, created based on witness descriptions using traditional drawing techniques. This method is labor-intensive and time-consuming (Figure 1).
- Composition Method: This approach is more straightforward and includes two types that have evolved sequentially:
- −
- Identi-Kit: A semi-manual method involving paper-based drawings of different facial features that are inserted into a specially designed frame to assemble a complete face.
- −
- Photo-Fit: Developed by SIRCHIE Laboratories, this method is similar to Identi-Kit but uses photographs of different facial segments instead of drawings.
- Mixed Method: This method combines the direct/artistic approach (using artistic drawing techniques) with semi-mechanized techniques, such as the composition method. This approach is computerized, allowing the exchange of facial segments represented by drawings or photographs in a digital environment.
1.1. Artificial Intelligence (AI)
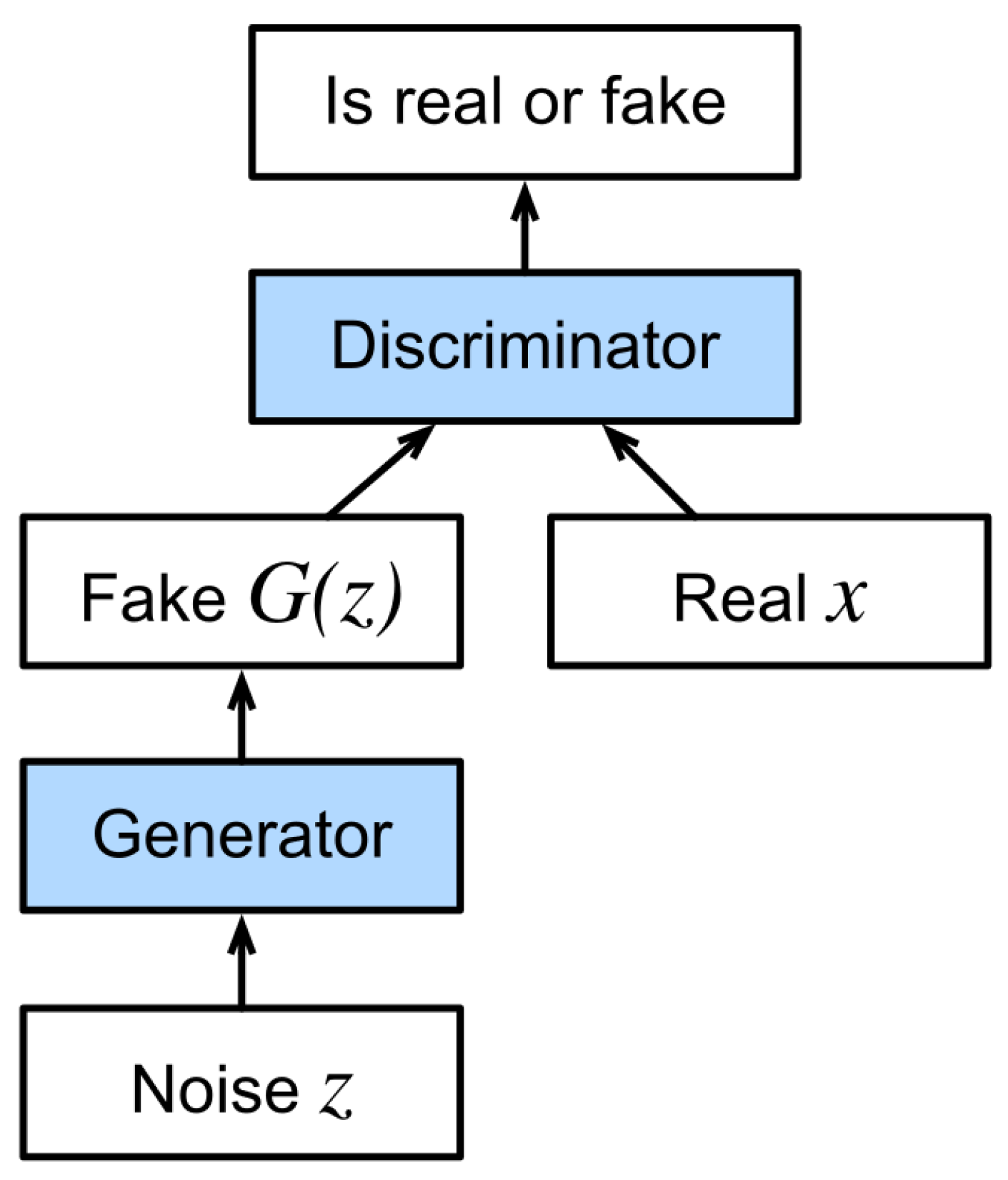
1.1.1. Generative Adversarial Networks (GANs)
- Generative Model: Captures a data distribution and produces new output images.
- Discriminative Model: Estimates the probability that a given sample originates from the training data rather than being created by the generator.
1.1.2. Variational Autoencoders (VAEs)
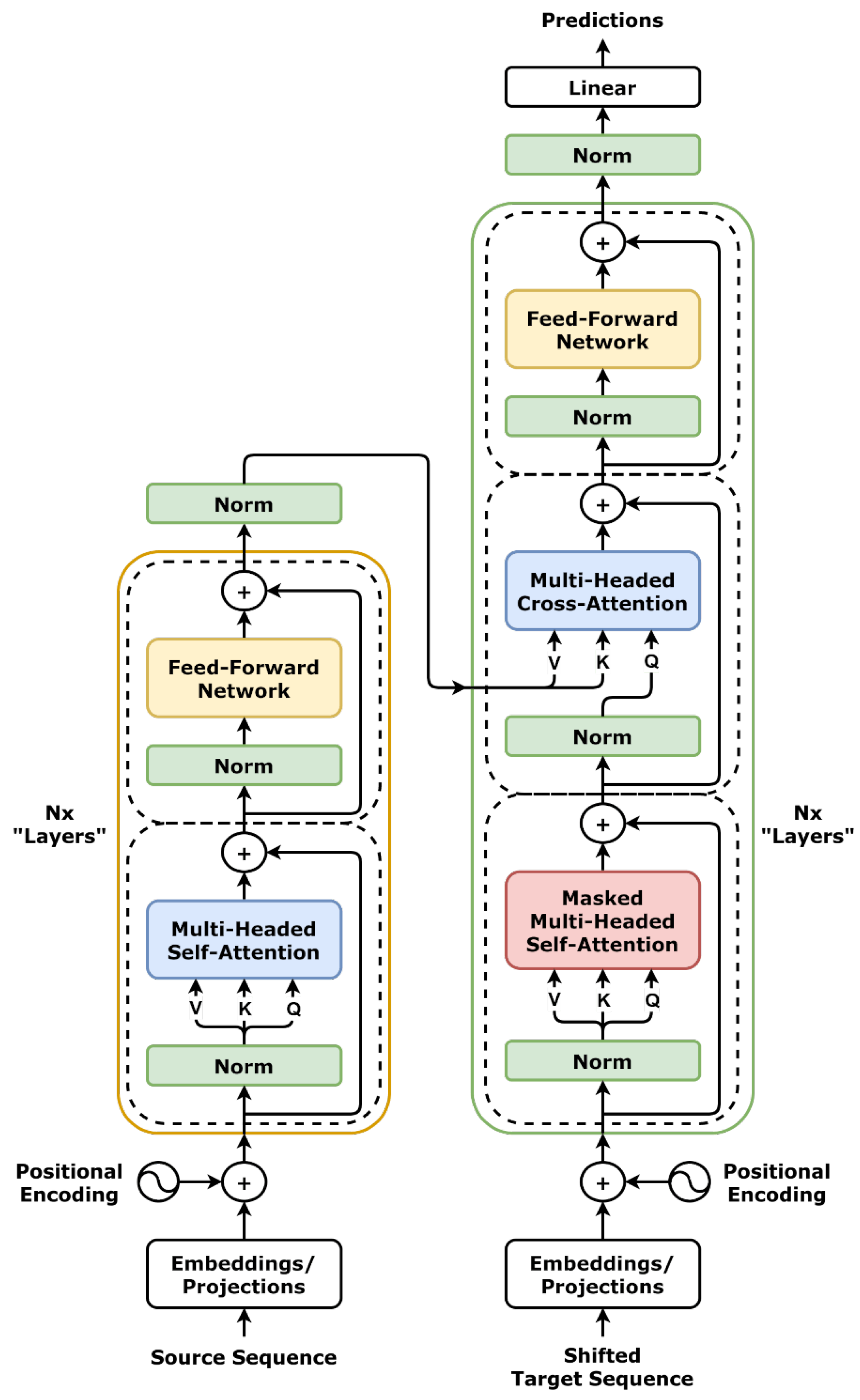
1.1.3. Transformers
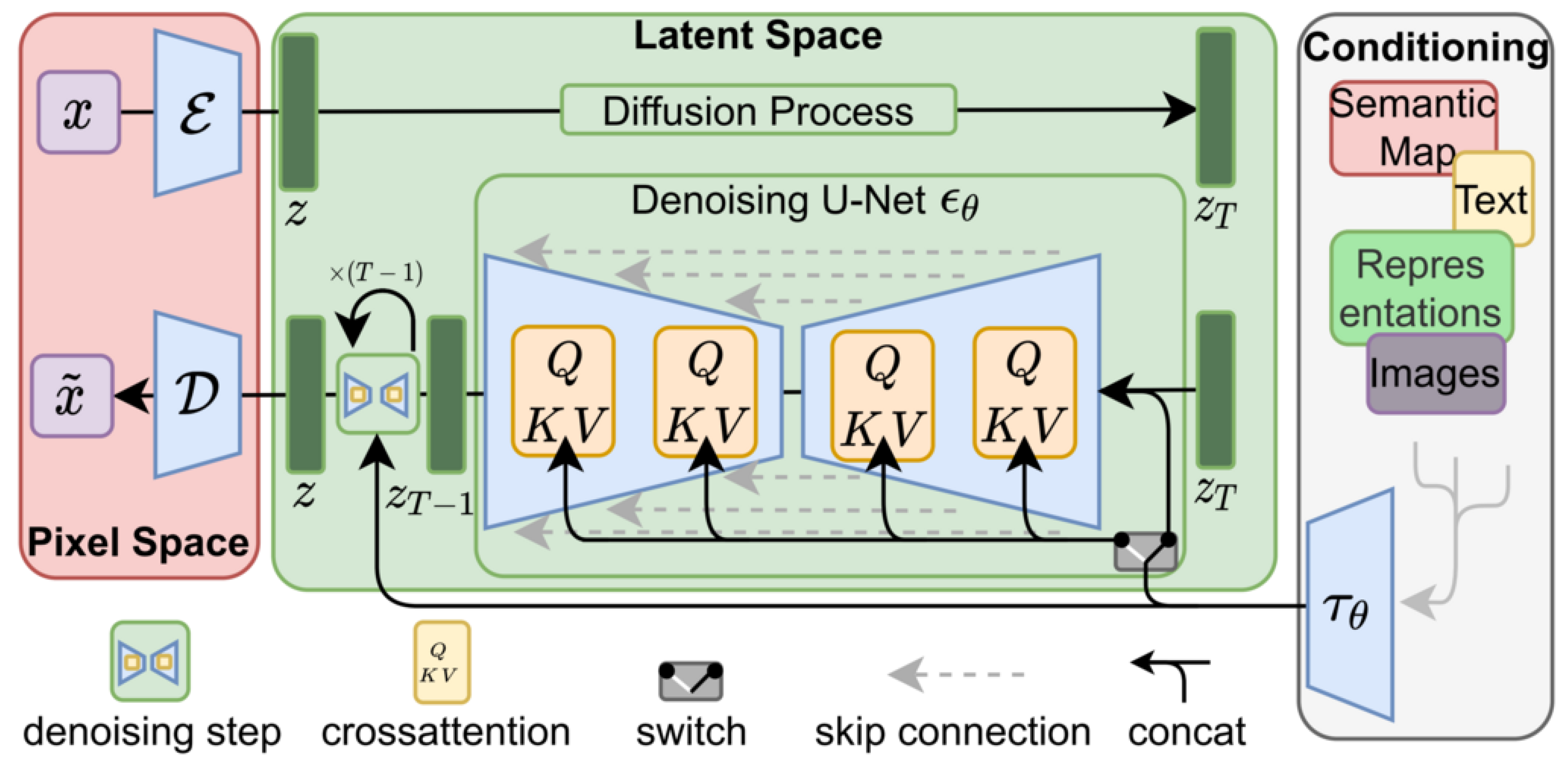
1.1.4. Diffusion Models
2. Materials and Methods
2.1. Image Generation Tools
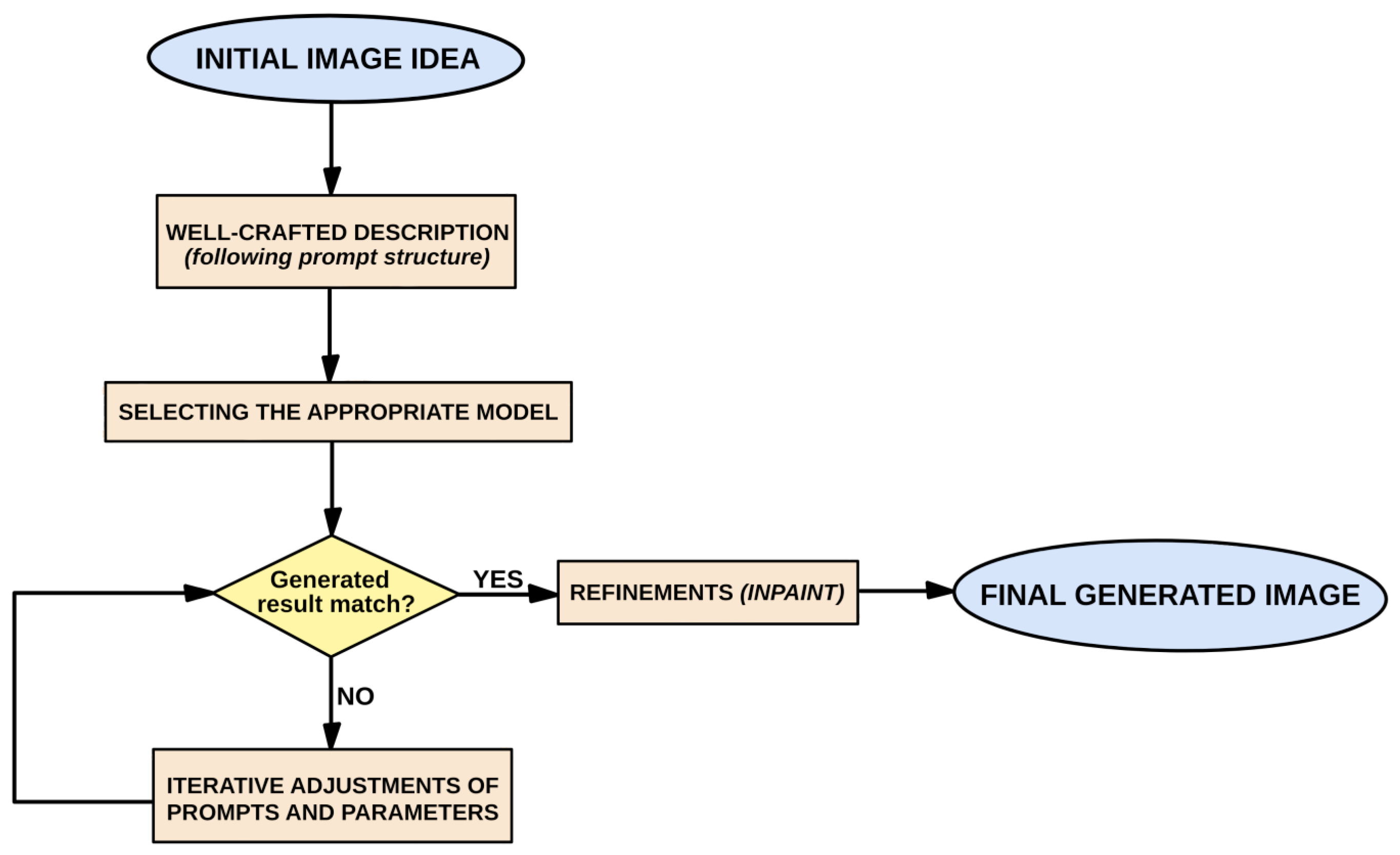
2.2. Methodology
2.2.1. Comparison and Selection of Image Generation Tools
Prompt: “Realistic portrait face of a 25-year-old woman with tanned skin, prominent brown eyes, a straight nose, thin lips, wavy brown hair, and a serious expression. The lighting in the image must be natural. It is crucial that the lips are thin and the eyes are large and brown.”
- Midjouney—Figure 7b: “/imagine: [prompt: realistic portrait female 25 years old, tanned skin, straight nose, serious face, open brown eyes::2 long brown wavy hair::1.5 very thin lips::2 –no malformed, draw, anime, deformed, bad quality, make-up –style raw]”
- Stable Diffusion—Figure 7c: realistic portrait photo of a woman 25 years old, tanned skin, straight nose, serious face, (very thin lips:1.4), natural light //BREAK// big brown eyes //BREAK// dark brown wavy hair //BREAK// very thin lips:1.7, highly detailed. And negative prompt: lowres, drawing, sketch, malformed, bad quality.
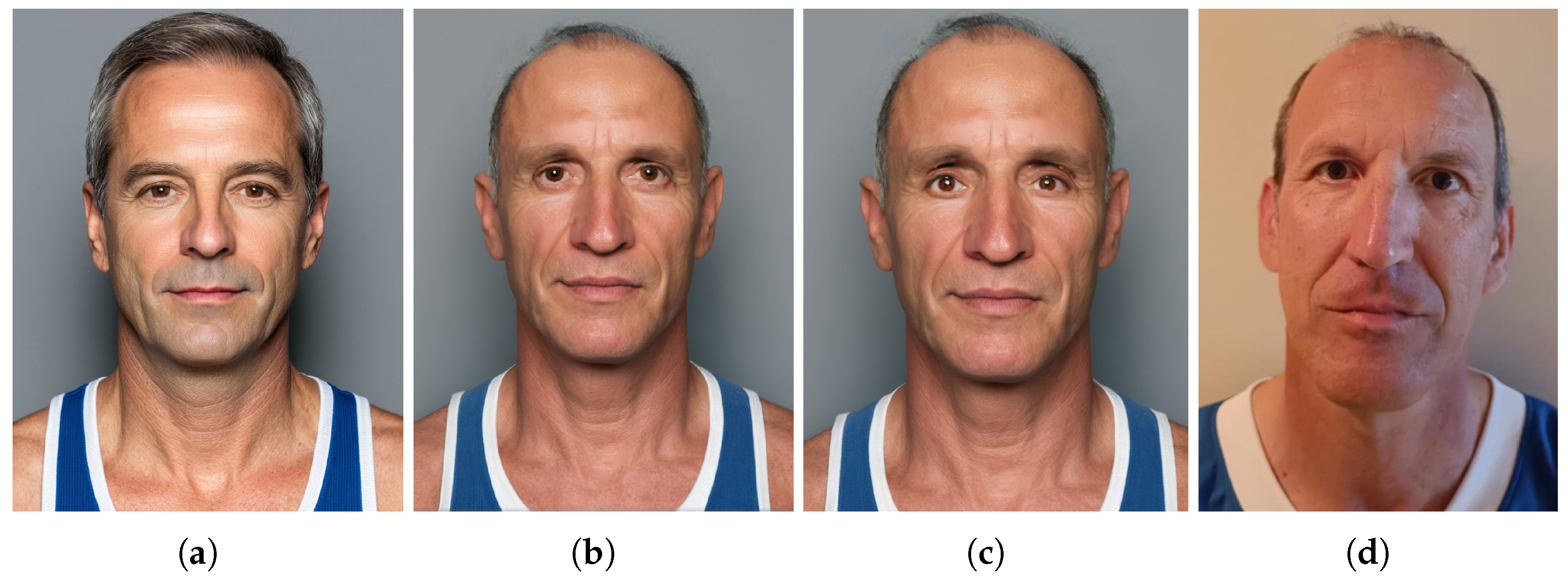
- DALL-E—Figure 8a: generate an image of a portrait photo face man 70 years old short white hair, small eyes, big nose, fat, smile
- Midjouney—Figure 8b: “/imagine: [prompt: portrait photo face man 70 years old short white hair, small eyes, big nose, fat, smile –no malformed, draw, anime, deformed, bad quality –stylize 75 –style raw]”
- Stable Diffusion—Figure 8c: portrait photo face man 70 years old short white hair, small eyes, big nose, fat, smile. And negative prompt: lowres, drawing, sketch, malformed, bad quality.
- FLUX—Figure 8d: portrait photo face man 70 years old short white hair, small eyes, big nose, fat, smile
- DALL-E—Figure 8b: turns my drawing into a photo-realistic style.
- Midjouney—Figure 8c: “/image [prompt: https://s.mj.run/38me-KNonTY (Accessed on 12 December 2024) hyperrealistic portrait picture of an 18 year old male following the composition and borders of the attached image, brown eyes, dark brown hair, photographic style–style raw].”
- Stable Diffusion—Figure 8d: “(((brown eyes))) //BREAK// (((brown hair))) //BREAK// realistic portrait photo of a boy 20 years old, friendly expression.” And negative prompt: draw, painting, sketch, noisy, blurred //BREAK// lowres, low quality, render, anime, bad photography.
2.2.2. Procedure Development Methodology
Prompt: “portrait photo of a 24-year-old Caucasian woman with a round face, fair skin, wide forehead, long brown straight hair, small ears, small silver hoop earrings and a tiny silver pendant necklace with a circular design, realistic low saturation blue grey eyes, small curved thin eyebrows, small pointed nose, marked philtrum. She is looking at the camera, smiling slightly with thin closed lips with a friendly expression. Natural makeup that includes winged eyeliner. Neutral background and midday natural light indoors. She is wearing a simple black tank top.”
Negative prompt: “open mouth, skinny complexion, deformed, low resolution.”
Prompt: “portrait picture 24-years-old fat:0.3 Caucasian boy, large oval face, broad build, rounded //BREAK// black wavy hair that is longer on top and shaved:1.8 on the sides //BREAK// eyes centered and small, brown eyes, slight bags //BREAK// wide nose, left nostril wider //BREAK// big closed mouth, smile, lips thin and fading slightly at the corners //BREAK// beige striped button-up shirt.”
Negative prompt: “bread:1.8, open mouth.”
A highly detailed portrait photo of a 24-year-old Caucasian woman with a round face, fat girl, wide forehead, very fair skin //BREAK// large, expressive brown eyes, small curved thin eyebrows, natural makeup with winged eyeliner //BREAK// loose long straight black hair parted in the middle //BREAK// small pointed nose with the right nostril smaller //BREAK// small silver hoop earrings and a delicate silver pendant necklace with a circular design. Black, thin-strapped top, and her friendly expression is directed towards the camera. The high-resolution image highlights the texture of her skin //BREAK// thin lips:1.3, slight smile.
- Checkpoint Models: Comprehensive Stable Diffusion models containing all components required for image generation without additional files. They are large, typically ranging from 2 to 7 GB.
- Textual Inversions (Embeddings): Small files (10–100 KB) that define new keywords to generate specific objects or styles. They must be used alongside a Checkpoint model.
- LoRA Models (Low-Rank Adaptation): Compact patch files (10–200 MB) designed to modify styles without full model retraining. Also dependent on a Checkpoint model.
- Hypernetworks: Additional network modules (5–300 MB) that enhance flexibility and style adaptation of Checkpoint models.
3. Results and Discussion
- Figure 14a: A close-up portrait of a 24-year-old Caucasian woman with round face, very fair skin, long straight black hair, and large brown eyes. The woman is wearing silver hoop earrings and a tiny silver pendant necklace with a circular design and a thin-strapped top, her expression is friendly as she looks directly at the camera. Neutral background, natural midday light, realistic photographic style, high resolution //BREAK// round face, elongated face, thick complexion:1.8, fair skin, wide forehead //BREAK// thin lips:1.3, slight smile //BREAK// Very big eyes
- Figure 14b: same prompt as image (a) but adding “fat”.
- Figure 14c: the hyperrealism style was added; Prompt “A highly detailed, close-up portrait of a 24-year-old Caucasian woman with a round face, wide forehead, very fair skin, and large, expressive brown eyes. Small pointed nose with the right nostril smaller, loose long straight black hair parted in the middle, and is wearing small silver hoop earrings and a delicate silver pendant necklace with a circular design. Natural makeup that includes winged eyeliner. Thin-strapped top, friendly expression, slightly blurred neutral background with soft natural midday light. Realistic photographic style, high-resolution, lifelike representation //BREAK// thick complexion:1.8, fat:1.8, small curved thin eyebrows //BREAK// thin lips:1.3, slight smile ”; Negative prompt “hair up”.
- Figure 14d: A highly detailed portrait photo of a 24-year-old Caucasian woman with a round face, fat girl, wide forehead, very fair skin //BREAK// large, expressive brown eyes, small curved thin eyebrows, natural makeup with winged eyeliner //BREAK// loose long straight black hair parted in the middle //BREAK// small pointed nose with the right nostril smaller //BREAK// small silver hoop earrings and a delicate silver pendant necklace with a circular design. Black, thin-strapped top, and her friendly expression is directed towards the camera. The high-resolution image highlights the texture of her skin //BREAK// thin lips:1.3, slight smile.
- Prompt example: “small nosed thin:1.7 lips//smiley expression//thin lips//occluded lip at the end//Negative prompt: thick lips, teeth”
- Prompt example: “black thin eyeliner//pointed eyebrows//huge realistic eyes//greenish:0.0001 brown:1.7 eyes//huge upper eyelid”
- Prompt example: “few freckles:0.00001//white complexion//skin detail//fat girl fair complexion//smooth”
Prompt: “realistic portrait photo of a 24-year-old Caucasian girl, rounded face, fair skin, broad forehead //BREAK// straight black hair, long hair, ears close to the head, silver hoop earrings //BREAK// small thin curved eyebrows, very large eyes, light brown eyes, pointed nose //BREAK// small mouth and thin lips, closed mouth, wearing black tank top”
- The calculated distance between Figure 16a,b is 0.38, which, despite exceeding the threshold, indicates a high degree of similarity.
- The calculated distance between Figure 17a,b is 0.62, which denotes a less accurate outcome with a lower degree of similarity.
- The calculated distance between Figure 17c,d is 0.39, indicating a high degree of similarity.
’Caucasian man 50 years old, oval elongated face, narrow bone structure //BREAK// few shaved dark gray hair, pronounced receding messy hairline //BREAK// curved eyebrows, sparse eyebrows, huge and pronounced nose, raised nostrils //BREAK// dark brown eyes, almond eyes //BREAK// very thin lips, closed smile, big mouth, very marked nasofacial lines //BREAK// Blue tank top with white borders’; and negative prompt: ’anime, draw, malformed, disformed, teeth, bread’.
- “small:1.6 ear backward rounded, [[[[upper part of the ear back]]]] //BREAK// 55 man skin detail, straight huge nose //BREAK// very wide nose, huge nose, straight prominent nose”, “55 years old man, skin detail, elongated face //BREAK// soft features //BREAK// three vertical age line; with the negative prompt: “bread:1.9, malformed, bread, mustache, hair, wrinkles”
- “serious expression, friendly expression, 50 years man //BREAK// very thin lips, closed smile, big mouth //BREAK// very thin lower lip, occluded lips; with the negative prompt: “teeth:1.7, thick lips, open mouth, teeth”
4. Conclusions and Future Lines
- DALL-E 3 offers intuitive natural language processing for detailed prompts, enabling users to describe desired images interactively. Its intuitive interface simplifies usage; however, it is limited in integrating external visual references and often produces artifacts or inaccurate details.
- Midjourney provides high realism through concise, structured prompts but has a less user-friendly interface compared to DALL-E.
- FLUX demonstrates the capability to generate high-resolution images with a strong interpretation of prompts, delivering detailed outputs. However, FLUX exhibits a notable limitation in the variability of facial features. Furthermore, it tends to favor an idealized aesthetic, prioritizing symmetry and perfection over realism. As a result, the generated images, while visually appealing, lack the nuanced imperfections and diversity of features that are characteristic of realistic human faces. This limitation poses challenges for applications requiring natural visual representations.
- In terms of close-up portraits, Stable Diffusion stands out for its ability to generate greater variability, refined skin textures, and a higher degree of realism. The model’s flexibility in adjusting details allows for more lifelike and diverse facial representations, making it particularly effective for tasks requiring high accuracy in facial feature generation. Stable Diffusion is open-source and highly customizable. Despite its steeper learning curve compared to other tools, because it requires more technical familiarity for optimal use, it shines in sketch-guided generation and allows users to select models tailored to detail and realism.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jain, A.K.; Bolle, R.; Pankanti, S. Biometrics: Personal Identification in Networked Society; Springer: Berlin/Heidelberg, Germany, 2006; Volume 479. [Google Scholar]
- Facial Identification Scientific Working Group. Facial Image Comparison Feature List for Morphological Analysis, Version 2.0. 2018. Available online: https://fiswg.org/FISWG_Morph_Analysis_Feature_List_v2.0_20180911.pdf (accessed on 20 May 2024).
- Richmond, S.; Howe, L.J.; Lewis, S.; Stergiakouli, E.; Zhurov, A. Facial genetics: A brief overview. Front. Genet. 2018, 9, 462. [Google Scholar] [CrossRef] [PubMed]
- Ouyang, S.; Hospedales, T.M.; Song, Y.Z.; Li, X. ForgetMeNot: Memory-Aware Forensic Facial Sketch Matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Frowd, C.D.; Carson, D.; Ness, H.; McQuiston-Surrett, D.; Richardson, J.; Baldwin, H.; Hancock, P. Contemporary composite techniques: The impact of a forensically-relevant target delay. Leg. Criminol. Psychol. 2005, 10, 63–81. [Google Scholar] [CrossRef]
- Faces Software. Facial Composite Software. Available online: https://facialcomposites.com/ (accessed on 10 June 2024).
- FACETTE Face Design System—Phantombild-Programm—Facial Composites. Available online: http://www.facette.com/index.php?id=1&L=1 (accessed on 10 June 2024).
- Singular Inversions. 2024. FaceGen 3D. Available online: https://facegen.com/3dprint.htm (accessed on 10 June 2024).
- Lugmayr, A.; Danelljan, M.; Romero, A.; Yu, F.; Timofte, R.; Van Gool, L. Repaint: Inpainting using denoising diffusion probabilistic models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11461–11471. [Google Scholar]
- Cheng, Y.C.; Lin, C.H.; Lee, H.Y.; Ren, J.; Tulyakov, S.; Yang, M.H. Inout: Diverse image outpainting via GAN inversion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11431–11440. [Google Scholar]
- Betker, J.; Goh, G.; Jing, L.; Brooks, T.; Wang, J.; Li, L.; Ouyang, L.; Zhuang, J.; Lee, J.; Guo, Y.; et al. Improving image generation with better captions. Comput. Sci. 2023, 2, 8. [Google Scholar]
- Midjourney. Midjourney. Available online: http://www.midjourney.com (accessed on 20 November 2024).
- Stable Diffusion AI. Stable Diffusion. Available online: https://stablediffusionweb.com/es (accessed on 25 October 2024).
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, J.; Peng, L.; Wu, Y.; Xu, Y.; Zhang, Z. Auto-Encoding Variational Bayes. Camb. Explor. Arts Sci. 2024, 2. [Google Scholar] [CrossRef]
- Rocca, J.; Rocca, B. Understanding Variational Autoencoders (VAEs). Towards Data Sci. 2019, 23. Available online: https://medium.com/towards-data-science/understanding-variational-autoencoders-vaes-f70510919f73 (accessed on 15 April 2024).
- Van Den Oord, A.; Vinyals, O. Neural discrete representation learning. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6309–6318. [Google Scholar]
- Esser, P.; Rombach, R.; Ommer, B. Taming transformers for high-resolution image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12873–12883. [Google Scholar]
- Khan, S.H.; Hayat, M.; Barnes, N. Adversarial training of variational auto-encoders for high fidelity image generation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; IEEE: New York, NY, USA, 2018; pp. 1312–1320. [Google Scholar]
- Williams, K. Transformers in Generative AI. 2024. Available online: https://www.pluralsight.com/resources/blog/ai-and-data/what-are-transformers-generative-ai (accessed on 6 November 2024).
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2017; Volume 30. [Google Scholar]
- Hudson, D.A.; Zitnick, L. Generative adversarial transformers. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 4487–4499. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Yang, L.; Zhang, Z.; Song, Y.; Hong, S.; Xu, R.; Zhao, Y.; Zhang, W.; Cui, B.; Yang, M.H. Diffusion Models: A Comprehensive Survey of Methods and Applications. ACM Comput. Surv. 2023, 56, 1–39. [Google Scholar] [CrossRef]
- Sohl-Dickstein, J.; Weiss, E.; Maheswaranathan, N.; Ganguli, S. Deep unsupervised learning using nonequilibrium thermodynamics. In Proceedings of the International Conference on Machine Learning, PMLR, Lile, France, 6–11 July 2015; pp. 2256–2265. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. In Proceedings of the NIPS ’20: 34th International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 6–12 December 2020. [Google Scholar]
- Nichol, A.Q.; Dhariwal, P. Improved denoising diffusion probabilistic models. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 8162–8171. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis with Latent Diffusion Models. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Los Alamitos, CA, USA, 21–23 June 2022; pp. 10674–10685. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Zhang, L.; Rao, A.; Agrawala, M. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 3836–3847. [Google Scholar]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 6, 679–698. [Google Scholar] [CrossRef]
- Lack Forest Labs. FluxBF. Black Forest Labs Web. Available online: https://blackforestlabs.ai/ (accessed on 25 November 2024).
- Lipman, Y.; Chen, R.T.Q.; Ben-Hamu, H.; Nickel, M.; Le, M. Flow Matching for Generative Modeling. arXiv 2023, arXiv:2210.02747. [Google Scholar]
- Su, J.; Ahmed, M.; Lu, Y.; Pan, S.; Bo, W.; Liu, Y. RoFormer: Enhanced transformer with Rotary Position Embedding. Neurocomputing 2024, 568, 127063. [Google Scholar] [CrossRef]
- Dehghani, M.; Djolonga, J.; Mustafa, B.; Padlewski, P.; Heek, J.; Gilmer, J.; Steiner, A.P.; Caron, M.; Geirhos, R.; Alabdulmohsin, I.; et al. Scaling vision transformers to 22 billion parameters. In Proceedings of the International Conference on Machine Learning, PMLR, Honolulu, HI, USA, 23–29 July 2023; pp. 7480–7512. [Google Scholar]
- Research Graph via Medium. The Ultimate FLUX.1 Hands-On Guide. 2024. Available online: https://medium.com/@researchgraph/the-ultimate-flux-1-hands-on-guide-067fc053fedd (accessed on 20 November 2024).
- Emanuele via Medium. Flux: An Advanced (and Open Source) Text-to-Image Model Comparable to Midjourney. 2024. Available online: https://medium.com/diffusion-images/flux-an-advanced-and-open-source-text-to-image-model-comparable-to-midjourney-1b01cf5a7148 (accessed on 20 November 2024).
- Andrew via Sagio Development LLC. How to Use Stable Diffusion. 2024. Available online: https://stable-diffusion-art.com/beginners-guide/ (accessed on 21 November 2024).
- Beaumont, R. LAION-5B: A New Era of Open Large-Scale Multi-Modal Datasets. 2022. Available online: https://laion.ai/blog/laion-5b/ (accessed on 21 November 2024).
- Serengil, S.I.; Ozpinar, A. LightFace: A Hybrid Deep Face Recognition Framework. In Proceedings of the 2020 Innovations in Intelligent Systems and Applications Conference (ASYU), Istanbul, Turkey, 15–17 October 2020; IEEE: New York, NY, USA, 2020; pp. 23–27. [Google Scholar] [CrossRef]
- Serengil, S.; Ozpinar, A. A Benchmark of Facial Recognition Pipelines and Co-Usability Performances of Modules. J. Inf. Technol. 2024, 17, 95–107. [Google Scholar] [CrossRef]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A unified embedding for face recognition and clustering. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar] [CrossRef]
- Deng, J.; Guo, J.; Ververas, E.; Kotsia, I.; Zafeiriou, S. RetinaFace: Single-Shot Multi-Level Face Localisation in the Wild. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 5202–5211. [Google Scholar] [CrossRef]
- Phillips, P.; Wechsler, H.; Huang, J.; Rauss, P.J. The FERET database and evaluation procedure for face-recognition algorithms. Image Vis. Comput. 1998, 16, 295–306. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, X.; Tang, X. Coupled information-theoretic encoding for face photo-sketch recognition. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; IEEE: New York, NY, USA, 2011; pp. 513–520. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Strengths | Weaknesses |
|---|---|---|
| DALL-E 3 |
|
|
| Midjourney |
|
|
| FLUX |
|
|
| Stable Diffusion |
|
|
| Model/Checkpoint | Prompt Structure | Results | Strengths | Weaknesses |
|---|---|---|---|---|
| Juggernaut XL | Structured prompts incorporating “BREAK” and detailed facial descriptions. | Realistic images with clear textures and strong coherence. | High fidelity in facial details. | Overly sensitive to excessively detailed prompts. |
| fullyREALXL | Similar structured prompts with reduced emphasis on fine details. | Smooth images with less intricate textures compared to Juggernaut XL. | Balanced detail and generation time. | Reduced fidelity in intricate details. |
| Textual Inversions | Embeddings added for specific stylistic elements (e.g., “hyperrealistic style”). | Enhanced stylistic accuracy while maintaining overall realism. | Improved stylistic personalization. | Requires a compatible checkpoint model. |
| LoRA Models | Style and object adjustments integrated into prompts using LoRA files. | Fine-tuned results with enhanced stylistic or artistic control. | High flexibility for customization. | Depends on a base checkpoint model for operation. |
| Negative Prompting | Exclusion of undesirable elements (e.g., “low resolution”, “distorted”). | Reduced artifacts and improved result coherence. | Effectively filters undesirable elements. | Overuse may remove excessive details. |
| Sampling Methods | DPM++ 2M SDE: Produces smoother outputs. Euler a: Generates more dynamic and textured results. | Variations in sharpness and texture based on the sampling method. | Versatile methods tailored for specific needs. | Results vary depending on the applied method. |
| Inpainting Refinement | Iterative editing focusing on morphological adjustments while preserving the rest of the image. | Precise adjustments in specific features such as eyes, nose, and mouth. | High precision and control over outcomes. | Slower process compared to initial generation. |
| Image 1 | Image 2 | Image 3 | Image 4 | Image 5 | |
|---|---|---|---|---|---|
| Original Image |  |  |  |  |  |
| Professional Sketch |  |  |  |  |  |
| Original-Sketch Comparison | 0.65 | 0.46 | 0.45 | 0.42 | 0.26 |
| Stable Diffusion Image Generated |  |  |  |  |  |
| Original-SD Comparison | 0.49 | 0.34 | 0.48 | 0.40 | 0.34 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sádaba-Campo, N.; Gómez-Moreno, H. Exploration of Generative Neural Networks for Police Facial Sketches. Big Data Cogn. Comput. 2025, 9, 42. https://doi.org/10.3390/bdcc9020042
Sádaba-Campo N, Gómez-Moreno H. Exploration of Generative Neural Networks for Police Facial Sketches. Big Data and Cognitive Computing. 2025; 9(2):42. https://doi.org/10.3390/bdcc9020042
Chicago/Turabian StyleSádaba-Campo, Nerea, and Hilario Gómez-Moreno. 2025. "Exploration of Generative Neural Networks for Police Facial Sketches" Big Data and Cognitive Computing 9, no. 2: 42. https://doi.org/10.3390/bdcc9020042
APA StyleSádaba-Campo, N., & Gómez-Moreno, H. (2025). Exploration of Generative Neural Networks for Police Facial Sketches. Big Data and Cognitive Computing, 9(2), 42. https://doi.org/10.3390/bdcc9020042