
Large Language Models as Kuwaiti Annotators


Abstract
1. Introduction
- This study represents the first attempt to investigate the efficiency of stance detection for the Kuwaiti Dialect using zero- and few-shot prompts on closed-source generative LLMs, in comparison with other available open-source generative LLMs.
- The study results demonstrate that using few-shot prompts with open-source LLMs for stance detection can achieve a performance comparable to that of paid closed-source models when applied to the Kuwaiti dialect vaccine stance dataset, offering significant cost savings and data privacy benefits.
- This study compares model performance, focusing on consistency and reliability. Using statistical methods such as one-way ANOVA and Tukey’s HSD, we identified significant differences and determined which models are most stable and reliable.
- The study results are valuable for expanding training datasets, enhancing automated labeling systems, and filling the gaps in NLP research across various domains—particularly with respect to the Kuwaiti dialect—underscoring the broad impact of the research.
2. Background
2.1. Large Language Models (LLMs)
2.2. Arabic Stance Detection with LLMs
2.3. Kuwaiti Dialect NLP Research
2.4. LLMs as Data Annotators
3. Methodology
3.1. Dataset
3.2. Pre-Processing
3.2.1. Selection of Large Language Models (LLMs)
3.2.2. Design of Prompt Templates
3.3. LLMs as Kuwaiti Annotator Experiments
- Dataset Preparation:
- From the Q8Stance test dataset, retrieve text from each tweet.
- For the few-shot prompts, also retrieve six example tweets covering pro- and anti-vaccine stances.
- Prompt Template Generation:
- Generate zero-shot prompts by applying the zero-shot prompt templates on each row from the Q8Stance test dataset. These prompts serve as the input for LLM inference, guiding it to complete the given annotation task.
- Generate few-shot prompts using example tweets through applying the few-shot prompt templates combined with the few-shot examples on each row from the Q8Stance test dataset.
- For each generated prompt, call the LLM API to execute the instructions in the prompt.
- Store the completion results from the LLM.
- Post-processing Steps: After receiving the completion results from the LLM, we apply post-processing steps to enable comparison with the human-labeled test dataset. This involves filtering keywords from the results and mapping them to related labels. This step is necessary as the LLMs sometimes do not follow the exact instructions. Instead of returning only the label, they produce results that are not directly comparable to the human-annotated labels. For example, they may return labels while adding extra text or return variations in Arabic labels.
- Store the final LLM results.
- To evaluate the performance of the LLMs, we compared the final results of the LLM with human-annotated labels from the Q8VaxStance test dataset. For the evaluation metrics, we utilized the Macro F1 formula. Additionally, we conducted a one-way ANOVA and Tukey’s HSD post hoc tests in order to determine whether the experimental results were statistically significant. We chose one-way ANOVA as it is a robust statistical method for comparing the means of multiple groups, allowing us to determine whether there are statistically significant differences among them. In this study, the groups represent the performances of different models (or conditions), while the dependent variable is the performance metric, specifically the Macro F1 score. One-way ANOVA enabled us to test the null hypothesis that all model performances were equal, thereby revealing any significant differences among the groups. After identifying significant differences using ANOVA, we applied Tukey’s HSD (Honestly Significant Difference) test as a post hoc analysis to determine which specific groups (models) differ from each other. To further analyze the consistency of the responses generated by the LLMs, we assessed the variability in their performance across different prompts and settings. A model that produces consistent results will exhibit low variance in its Macro F1 scores across various scenarios, while a model with high variance would be considered less reliable. We calculated the variance [71] in Macro F1 scores across different prompts for each LLM model using the variance formula variance Formula (1):where
- is the variance;
- N is the total number of Macro F1 scores (or observations);
- represents each individual Macro F1 score;
- is the mean of the Macro F1 scores.
4. Results
- Prompt Type: zero- versus few-shot setting;
- Prompt Language: Arabic (MSA) prompts versus English prompts;
- LLM source: closed- versus open-source LLMs.
4.1. Performance Comparison Across LLMs
4.2. Open vs. Closed LLMs
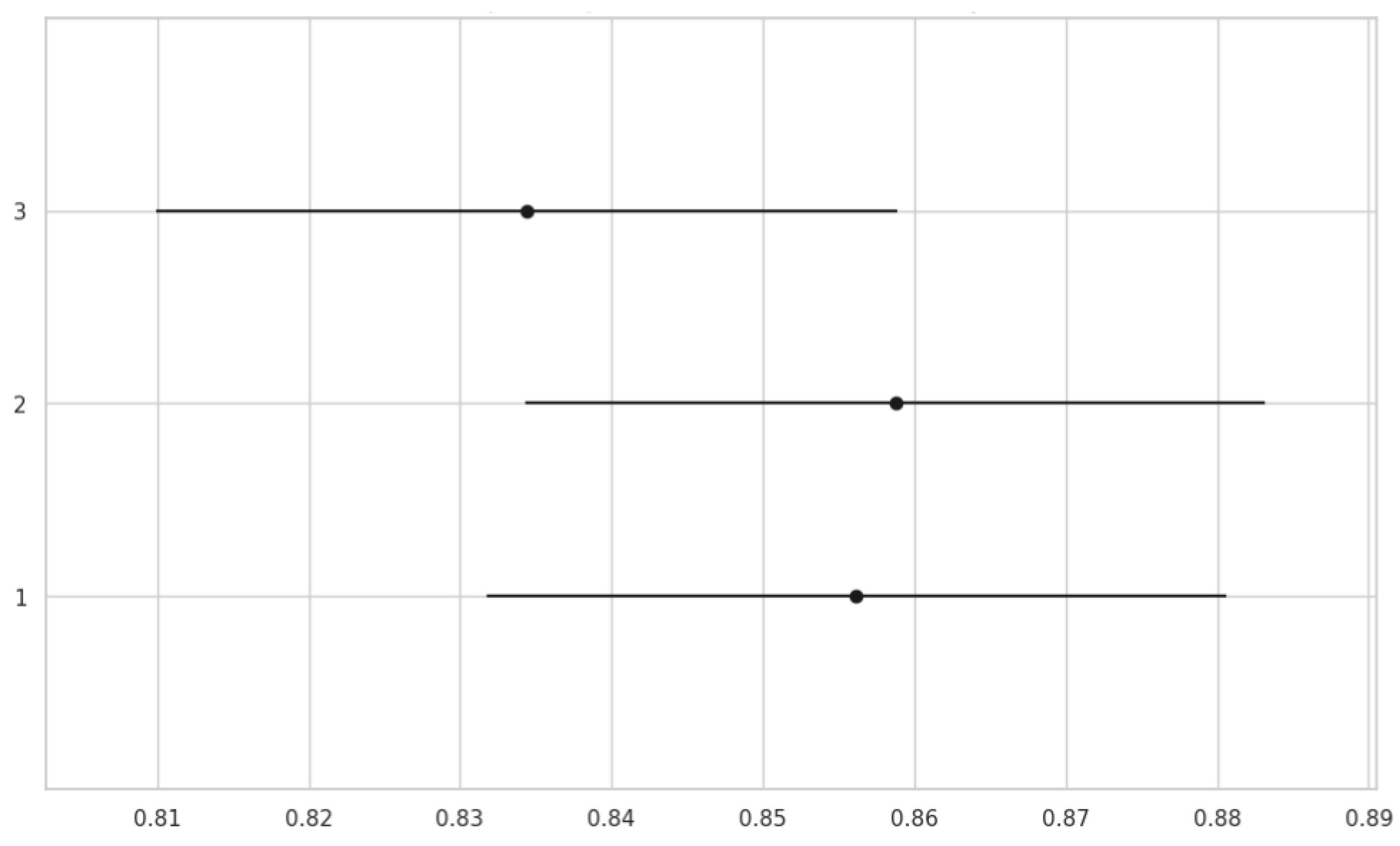
4.3. Statistical Significance Tests
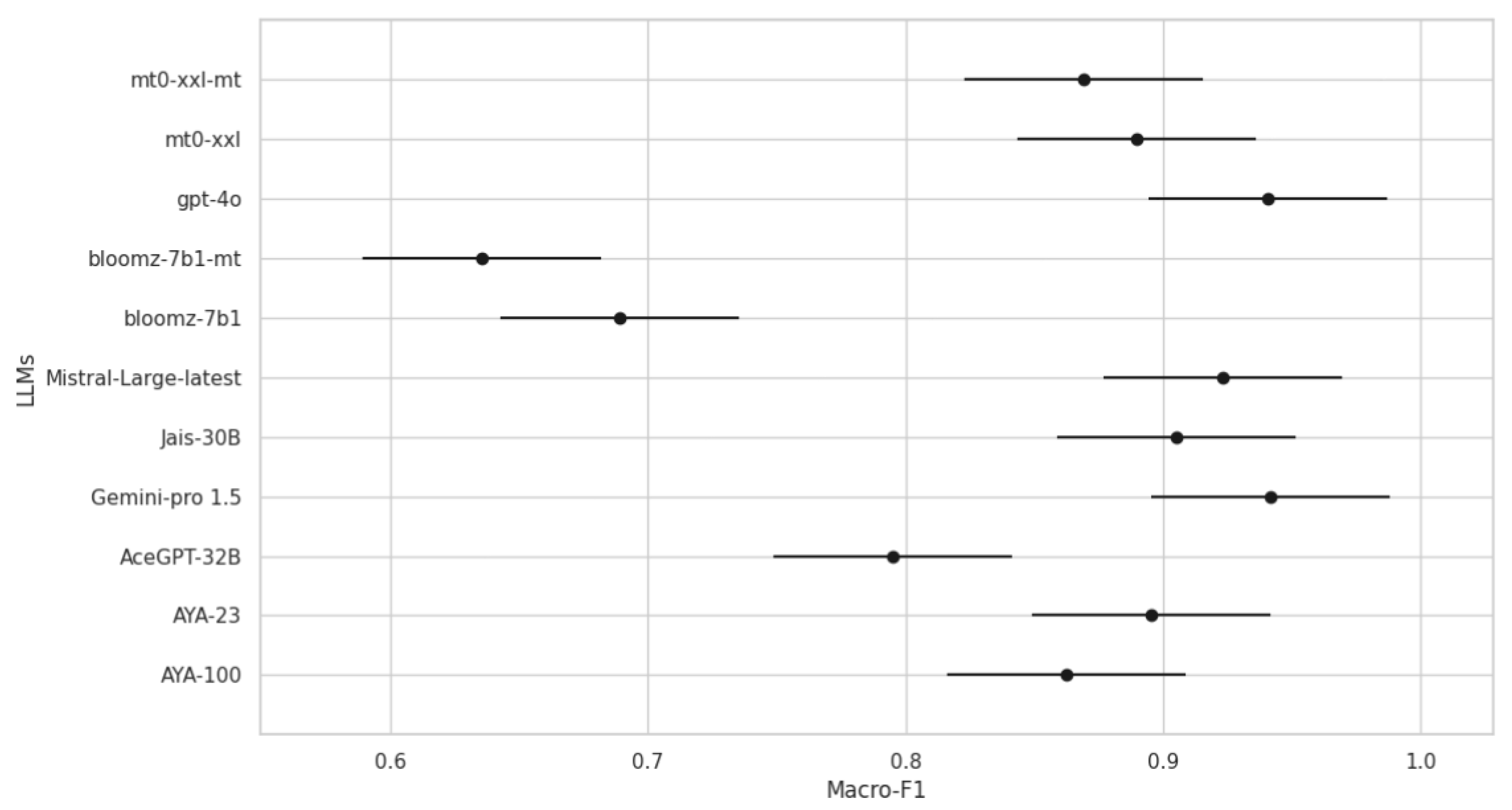
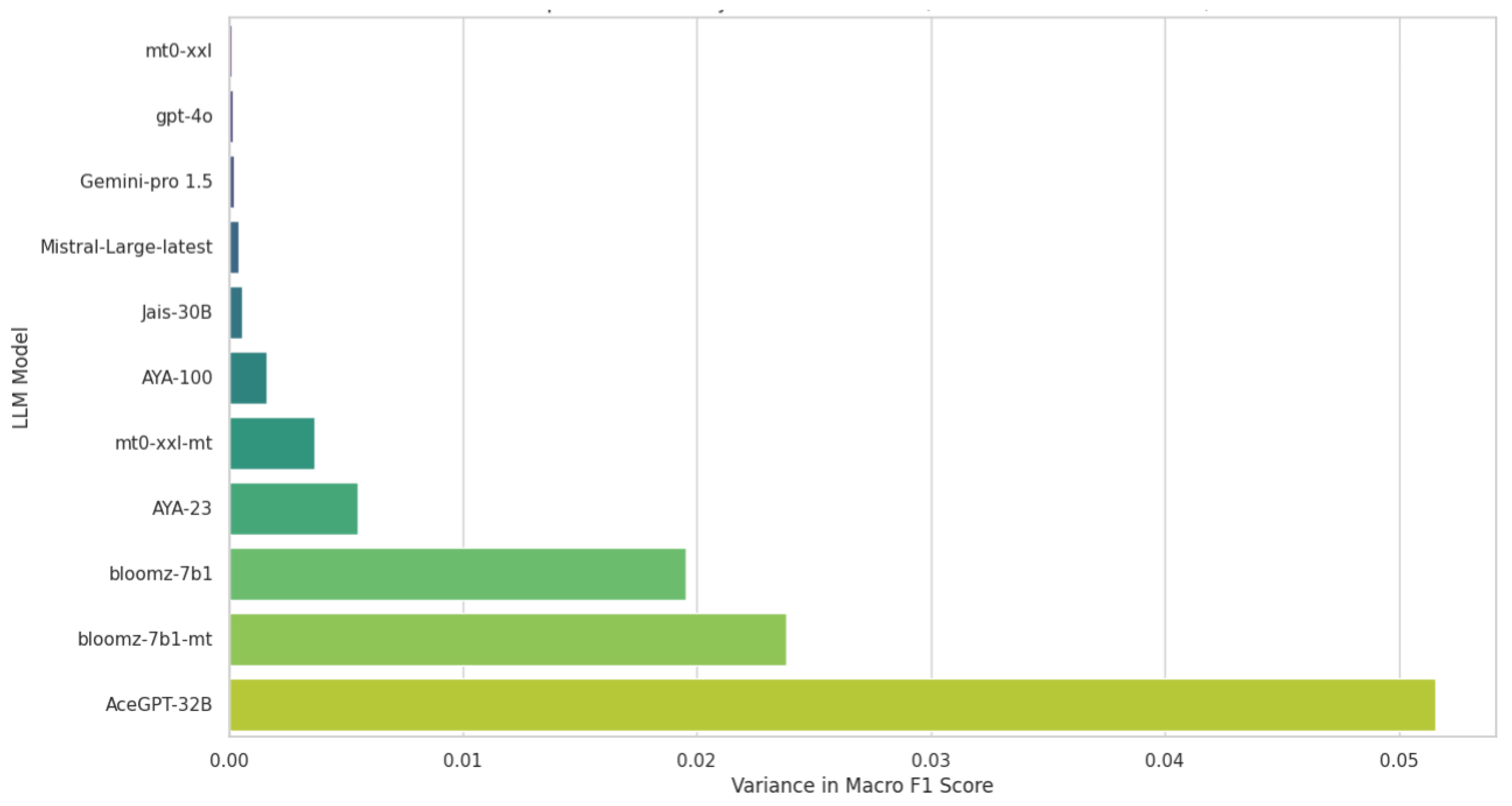
4.4. Response Consistency of LLMs
4.5. Error Analysis
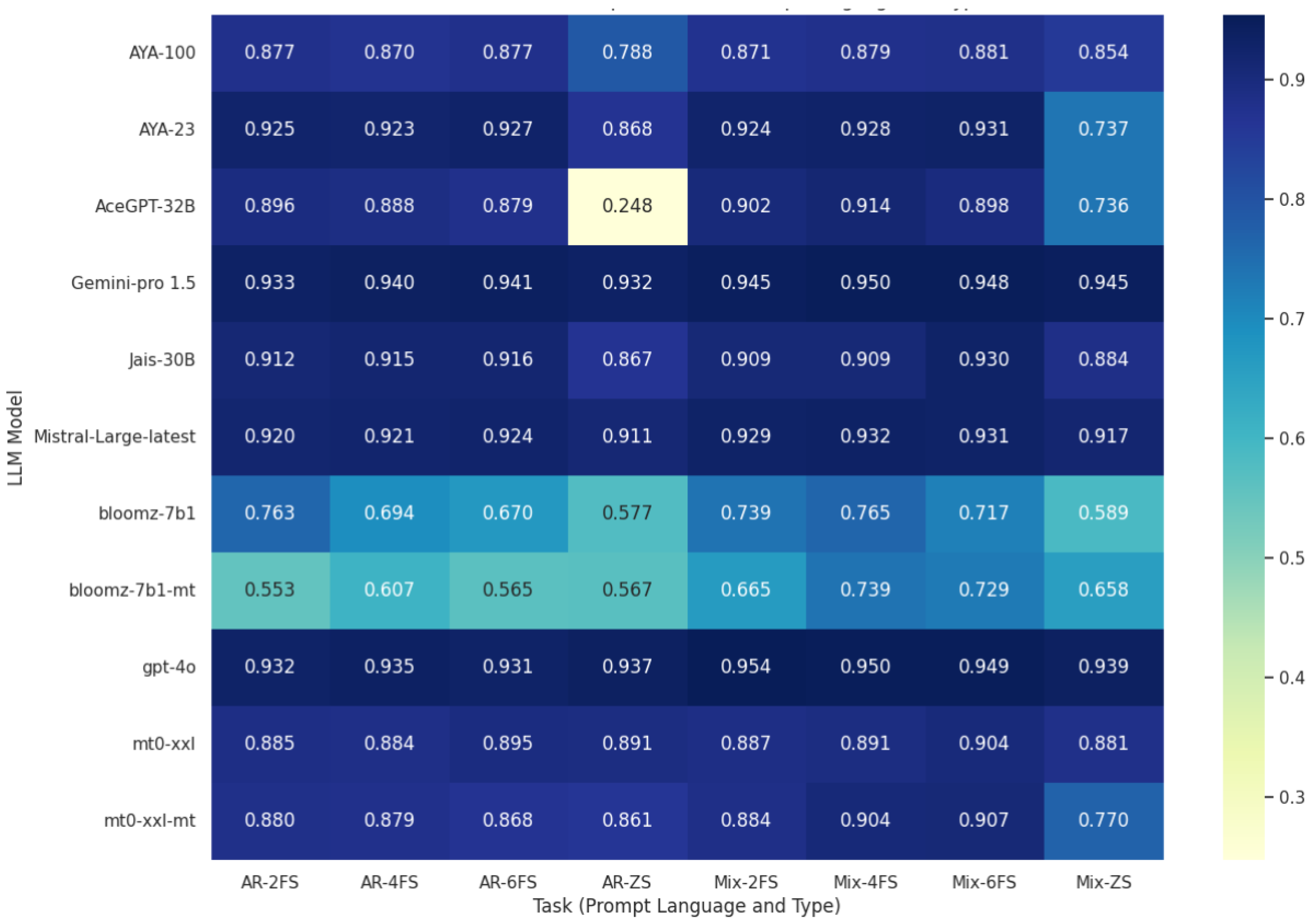
4.5.1. Effect of Prompt Language and Few-Shot Examples
4.5.2. Impact of Prompt Selection on Performance
4.5.3. Hallucinations and Unrelated Outputs
- Arabic Zero-shot Prompt 2: A tweet simply stating that “ATV channel supported vaccination” was processed incorrectly, and the model returned an irrelevant classification instruction (“Categorize the posts now”) instead of the correct stance label.
- Mixed Zero-shot Prompt 3: A tweet about COVID-19 spreading in Kuwait and calling for more vaccinations was misinterpreted, with the model inserting an unrelated username (“## Prepared by: @Mohamed Al-Masry”), which was not part of the original tweet.
- Arabic Zero-shot Prompt 2: A pro-vaccine tweet discussing a decrease in COVID-19-related deaths due to vaccination was mistakenly transformed into a statement about training (“In this part, we will train”), indicating failure in stance detection.
4.5.4. Misclassifications
- Arabic Zero-shot Prompt 1 Misclassification: A tweet expressing skepticism about vaccine mandates (“Is it possible that we are in a country with a constitution and democracy, yet its people are forced to be vaccinated? No to compulsory vaccination”.) was incorrectly classified as pro-vaccine.
- Mixed Zero-shot Prompt 3 Misclassification: A tweet that blamed authorities for vaccination failures (“Do not blame the citizens for your miserable failure, no to compulsory vaccination”.) was mistakenly labeled as pro-vaccine instead of anti-vaccine.
- Mixed Zero-shot Prompt 3 Misclassification: A tweet thanking the Ministry of Health for vaccinations (“I have been vaccinated. I thank the Ministry of Health and everyone who works in it and for it for the health of Kuwait, a very sophisticated organization”) was wrongly labeled as anti-vaccine, demonstrating the model’s struggle with positive statements about vaccination policies.
- Mixed Zero-shot Prompt 3 had the highest misclassification rate (166 pro-vaccine, 29 anti-vaccine), indicating that pro-vaccine tweets were more frequently misclassified in the English prompt setting.
- Arabic Zero-shot Prompt 3 had the highest misclassification rate (51 total), with more errors in anti-vaccine tweets (30 anti-vaccine misclassified vs. 21 pro-vaccine misclassified).
- Arabic Zero-shot Prompt 1 also showed more misclassification in anti-vaccine tweets (30 anti-vaccine vs. 8 pro-vaccine).
- Arabic Zero-shot Prompt 2 had the lowest misclassification rate (23 total) but misclassified more pro-vaccine tweets (17 pro-vaccine vs. 6 anti-vaccine).
5. Conclusions
6. Limitations
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| NLP | Natural Language Processing |
| LLMs | Large Language Models |
| GPT | Generative Pre-trained Transformer |
| BLOOM | BigScience Language Open-science Open-access Multilingual |
| MSA | Modern Standard Arabic |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LLM | Language Support | Source Type | Model Architecture | Model Size |
|---|---|---|---|---|
| GPT-4o | Multi-lingual | Closed | Decoder | Not officially declared |
| Gemini-pro 1.5 | Multi-lingual | Closed | Decoder | Not officially declared |
| Mistral-Large-latest | Multi-lingual | Closed | Decoder | 123 Billion |
| AYA-23 | Multi-lingual | Open | Decoder | 35 Billion |
| AceGPT-32B | Bilingual | Open | Decoder | 32 Billion |
| Jais-30B | Bilingual | Open | Decoder | 30 Billion |
| AYA-100 | Multi-lingual | Open | Decoder | 13 Billion |
| mt0-xxl | Multi-lingual | Open | Encoder–Decoder | 13 Billion |
| mt0-xxl-mt | Multi-lingual | Open | Encoder–Decoder | 13 Billion |
| bloomz-7b1 | Multi-lingual | Open | Decoder | 7 Billion |
| bloomz-7b1-mt | Multi-lingual | Open | Decoder | 7 Billion |
| Group 1 | Group 2 | p-adj | Reject |
|---|---|---|---|
| 2FS | 4FS | 0.9938 | False |
| 2FS | 6FS | 0.9999 | False |
| 2FS | ZS | 0.0047 | True |
| 4FS | 6FS | 0.9973 | False |
| 4FS | ZS | 0.0019 | True |
| 6FS | ZS | 0.0038 | True |
| Group 1 | Group 2 | p-adj | Reject |
|---|---|---|---|
| 1 | 2 | 0.9915 | False |
| 1 | 3 | 0.5464 | False |
| 2 | 3 | 0.4697 | False |
| Group 1 | Group 2 | p-adj | Reject |
|---|---|---|---|
| AR | Mixed | 0.0968 | False |
| Group 1 | Group 2 | p-adj | Reject | Group 1 | Group 2 | p-adj | Reject |
|---|---|---|---|---|---|---|---|
| AceGPT-32B | GPT-4o | 0.0000 | True | AceGPT-32B | Gemini-pro | 0.0000 | True |
| AceGPT-32B | Jais-30B | 0.0065 | True | AceGPT-32B | bloomz-7b1 | 0.0112 | True |
| AceGPT-32B | bloomz-7b1-mt | 0.0000 | True | AceGPT-32B | mT0-xxl | 0.0399 | True |
| AceGPT-32B | mT0-xxl-mt | 0.2534 | False | AceGPT-32B | AYA-100 | 0.3995 | False |
| AceGPT-32B | AYA-23 | 0.0213 | True | AceGPT-32B | Mistral-Large | 0.0005 | True |
| GPT-4o | Gemini-pro | 1.0000 | False | GPT-4o | Jais-30B | 0.9769 | False |
| GPT-4o | bloomz-7b1 | 0.0000 | True | GPT-4o | bloomz-7b1-mt | 0.0000 | True |
| GPT-4o | mT0-xxl | 0.7875 | False | GPT-4o | mT0-xxl-mt | 0.3050 | False |
| GPT-4o | AYA-100 | 0.1825 | False | GPT-4o | AYA-23 | 0.8866 | False |
| GPT-4o | Mistral-Large | 0.9999 | False | Gemini-pro | Jais-30B | 0.9723 | False |
| Gemini-pro | bloomz-7b1 | 0.0000 | True | Gemini-pro | bloomz-7b1-mt | 0.0000 | True |
| Gemini-pro | mT0-xxl | 0.7686 | False | Gemini-pro | mT0-xxl-mt | 0.2869 | False |
| Gemini-pro | AYA-100 | 0.1697 | False | Gemini-pro | AYA-23 | 0.8730 | False |
| Gemini-pro | Mistral-Large | 0.9999 | False | Jais-30B | bloomz-7b1 | 0.0000 | True |
| Jais-30B | bloomz-7b1-mt | 0.0000 | True | Jais-30B | mT0-xxl | 1.0000 | False |
| Jais-30B | mT0-xxl-mt | 0.9737 | False | Jais-30B | AYA-100 | 0.9149 | False |
| Jais-30B | AYA-23 | 1.0000 | False | Jais-30B | Mistral-Large | 0.9999 | False |
| bloomz-7b1 | bloomz-7b1-mt | 0.7258 | False | bloomz-7b1 | mT0-xxl | 0.0000 | True |
| bloomz-7b1 | mT0-xxl-mt | 0.0000 | True | bloomz-7b1 | AYA-100 | 0.0000 | True |
| bloomz-7b1 | AYA-23 | 0.0000 | True | bloomz-7b1 | Mistral-Large | 0.0000 | True |
| bloomz-7b1-mt | mT0-xxl | 0.0000 | True | bloomz-7b1-mt | mT0-xxl-mt | 0.0000 | True |
| bloomz-7b1-mt | AYA-100 | 0.0000 | True | bloomz-7b1-mt | AYA-23 | 0.0000 | True |
| bloomz-7b1-mt | Mistral-Large | 0.0000 | True | mT0-xxl | mT0-xxl-mt | 0.9997 | False |
| mT0-xxl | AYA-100 | 0.9967 | False | mT0-xxl | AYA-23 | 1.0000 | False |
| mT0-xxl | Mistral-Large | 0.9849 | False | mT0-xxl-mt | AYA-100 | 1.0000 | False |
| mT0-xxl-mt | AYA-23 | 0.9978 | False | mT0-xxl-mt | Mistral-Large | 0.7204 | False |
| AYA-100 | AYA-23 | 0.9854 | False | AYA-100 | Mistral-Large | 0.5494 | False |
| AYA-23 | Mistral-Large | 0.9965 | False |
References
- Küçük, D.; Can, F. Stance Detection: A Survey. ACM Comput. Surv. 2020, 53, 1–37. [Google Scholar] [CrossRef]
- Shyu, M.L.; Yan, Y.; Chen, J. Efficient Large-Scale Stance Detection in Tweets. Int. J. Multimed. Data Eng. Manag. 2018, 9, 1–16. [Google Scholar] [CrossRef]
- Burnham, M. Stance detection: A practical guide to classifying political beliefs in text. Political Sci. Res. Methods 2024, 1–18. [Google Scholar] [CrossRef]
- Kuo, K.H.; Wang, M.H.; Kao, H.Y.; Dai, Y.C. Advancing Stance Detection of Political Fan Pages: A Multimodal Approach. In Proceedings of the Companion Proceedings of the ACM Web Conference 2024, WWW ’24, New York, NY, USA, 13–17 May 2024; pp. 702–705. [Google Scholar] [CrossRef]
- Mets, M.; Karjus, A.; Ibrus, I.; Schich, M. Automated stance detection in complex topics and small languages: The challenging case of immigration in polarizing news media. PLoS ONE 2024, 19, e0302380. [Google Scholar] [CrossRef]
- Lee, Y.; Ozer, M.; Corman, S.R.; Davulcu, H. Identifying Behavioral Factors Leading to Differential Polarization Effects of Adversarial Botnets. SIGAPP Appl. Comput. Rev. 2023, 23, 44–56. [Google Scholar] [CrossRef]
- Lee, Y.; Alostad, H.; Davulcu, H. Quantifying Variations in Controversial Discussions within Kuwaiti Social Networks. Big Data Cogn. Comput. 2024, 8, 60. [Google Scholar] [CrossRef]
- Hua, Y.; Jiang, H.; Lin, S.; Yang, J.; Plasek, J.M.; Bates, D.W.; Zhou, L. Using Twitter Data to Understand Public Perceptions of Approved Versus Off-Label Use for COVID-19-related Medications. J. Am. Med. Inform. Assoc. 2022, 29, 1668–1678. [Google Scholar] [CrossRef] [PubMed]
- Cascini, F.; Pantović, A.; Al-Ajlouni, Y.A.; Failla, G.; Puleo, V.; Melnyk, A.; Lontano, A.; Ricciardi, W. Social Media and Attitudes Towards a COVID-19 Vaccination: A Systematic Review of the Literature. Eclinicalmedicine 2022, 48, 101454. [Google Scholar] [CrossRef]
- List of Countries and Territories Where Arabic Is an Official Language. Available online: https://en.wikipedia.org/wiki/List_of_countries_and_territories_where_Arabic_is_an_official_language (accessed on 16 December 2024).
- Alostad, H.; Dawiek, S.; Davulcu, H. Q8VaxStance: Dataset Labeling System for Stance Detection towards Vaccines in Kuwaiti Dialect. Big Data Cogn. Comput. 2023, 7, 151. [Google Scholar] [CrossRef]
- Alhindi, T.; Alabdulkarim, A.; Alshehri, A.; Abdul-Mageed, M.; Nakov, P. AraStance: A Multi-Country and Multi-Domain Dataset of Arabic Stance Detection for Fact Checking. In Proceedings of the Fourth Workshop on NLP for Internet Freedom: Censorship, Disinformation, and Propaganda; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 57–65. [Google Scholar] [CrossRef]
- Alturayeif, N.S.; Luqman, H.A.; Ahmed, M.A.K. MAWQIF: A Multi-label Arabic Dataset for Target-specific Stance Detection. In Proceedings of the Seventh Arabic Natural Language Processing Workshop (WANLP); Association for Computational Linguistics: Abu Dhabi, United Arab Emirates, 2022; pp. 174–184. [Google Scholar]
- Haouari, F.; Elsayed, T. Detecting stance of authorities towards rumors in Arabic tweets: A preliminary study. In Proceedings of the 45th European Conference on Information Retrieval; Springer: Dublin, Ireland, 2023; pp. 430–438. [Google Scholar]
- Hamad, O.; Hamdi, A.; Hamdi, S.; Shaban, K. StEduCov: An Explored and Benchmarked Dataset on Stance Detection in Tweets towards Online Education during COVID-19 Pandemic. Big Data Cogn. Comput. 2022, 6, 88. [Google Scholar] [CrossRef]
- Hardalov, M.; Arora, A.; Nakov, P.; Augenstein, I. Few-Shot Cross-Lingual Stance Detection With Sentiment-Based Pre-Training. Proc. AAAI Conf. Artif. Intell. 2022, 36, 10729–10737. [Google Scholar] [CrossRef]
- Kim, H.; Mitra, K.; Li Chen, R.; Rahman, S.; Zhang, D. MEGAnno+: A Human-LLM Collaborative Annotation System. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations, St. Julian’s, Malta, 17–22 March 2024; Aletras, N., De Clercq, O., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 168–176. [Google Scholar]
- He, X.; Lin, Z.; Gong, Y.; Jin, A.L.; Zhang, H.; Lin, C.; Jiao, J.; Yiu, S.M.; Duan, N.; Chen, W. AnnoLLM: Making Large Language Models to Be Better Crowdsourced Annotators. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 6: Industry Track), Mexico City, Mexico, 16–21 June 2024; Yang, Y., Davani, A., Sil, A., Kumar, A., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 165–190. [Google Scholar] [CrossRef]
- Zhang, R.; Li, Y.; Ma, Y.; Zhou, M.; Zou, L. LLMaAA: Making Large Language Models as Active Annotators. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, 6–10 December 2023; Bouamor, H., Pino, J., Bali, K., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 13088–13103. [Google Scholar] [CrossRef]
- Liu, R.; Lin, Z.; Tan, Y.; Wang, W. Enhancing zero-shot and few-shot stance detection with commonsense knowledge graph. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 3152–3157. [Google Scholar]
- Liang, B.; Zhu, Q.; Li, X.; Yang, M.; Gui, L.; He, Y.; Xu, R. Jointcl: A joint contrastive learning framework for zero-shot stance detection. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; Volume 1, pp. 81–91. [Google Scholar]
- Liew, X.Y.; Hameed, N.; Clos, J.; Fischer, J.E. Predicting Stance to Detect Misinformation in Few-shot Learning. In Proceedings of the First International Symposium on Trustworthy Autonomous Systems, TAS ’23, New York, NY, USA, 11–12 July 2023. [Google Scholar] [CrossRef]
- Hasanain, M.; Ahmad, F.; Alam, F. Can GPT-4 Identify Propaganda? Annotation and Detection of Propaganda Spans in News Articles. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), Torino, Italy, 20–25 May 2024; Calzolari, N., Kan, M.Y., Hoste, V., Lenci, A., Sakti, S., Xue, N., Eds.; ELRA and ICCL: Torino, Italy, 2024; pp. 2724–2744. [Google Scholar]
- Abdelali, A.; Mubarak, H.; Chowdhury, S.; Hasanain, M.; Mousi, B.; Boughorbel, S.; Abdaljalil, S.; El Kheir, Y.; Izham, D.; Dalvi, F.; et al. LAraBench: Benchmarking Arabic AI with Large Language Models. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), St. Julian’s, Malta, 17–22 March 2024; Graham, Y., Purver, M., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 487–520. [Google Scholar]
- Husain, F.; Alostad, H.; Omar, H. Bridging the Kuwaiti Dialect Gap in Natural Language Processing. IEEE Access 2024, 12, 27709–27722. [Google Scholar] [CrossRef]
- OpenAI. GPT-4o System Card. Available online: https://openai.com/index/gpt-4o-system-card/ (accessed on 22 September 2024).
- AI Models. Premier Models. Available online: https://mistral.ai/technology/#models (accessed on 16 December 2024).
- Team, G.; Anil, R.; Borgeaud, S.; Wu, Y.; Alayrac, J.B.; Yu, J.; Soricut, R.; Schalkwyk, J.; Dai, A.M.; Hauth, A.; et al. Gemini: A family of highly capable multimodal models. arXiv 2023, arXiv:2312.11805. [Google Scholar]
- Sengupta, N.; Sahu, S.K.; Jia, B.; Katipomu, S.; Li, H.; Koto, F.; Marshall, W.; Gosal, G.; Liu, C.; Chen, Z.; et al. Jais and Jais-chat: Arabic-Centric Foundation and Instruction-Tuned Open Generative Large Language Models. arXiv 2023, arXiv:2308.16149. [Google Scholar]
- Muennighoff, N.; Wang, T.; Sutawika, L.; Roberts, A.; Biderman, S.; Scao, T.L.; Bari, M.S.; Shen, S.; Yong, Z.X.; Schoelkopf, H.; et al. Crosslingual Generalization through Multitask Finetuning. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Toronto, ON, Canada, 9–14 July 2023; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 15991–16111. [Google Scholar]
- Aryabumi, V.; Dang, J.; Talupuru, D.; Dash, S.; Cairuz, D.; Lin, H.; Venkitesh, B.; Smith, M.; Campos, J.A.; Tan, Y.C.; et al. Aya 23: Open Weight Releases to Further Multilingual Progress. arXiv 2024, arXiv:2405.15032. [Google Scholar]
- Üstün, A.; Aryabumi, V.; Yong, Z.X.; Ko, W.Y.; D’souza, D.; Onilude, G.; Bhandari, N.; Singh, S.; Ooi, H.L.; Kayid, A.; et al. Aya model: An instruction finetuned open-access multilingual language model. arXiv 2024, arXiv:2402.07827. [Google Scholar]
- Huang, H.; Yu, F.; Zhu, J.; Sun, X.; Cheng, H.; Song, D.; Chen, Z.; Alharthi, A.; An, B.; He, J.; et al. AceGPT, Localizing Large Language Models in Arabic. arXiv 2024, arXiv:2309.12053. [Google Scholar]
- Singh, S.K.; Mahmood, A. The NLP Cookbook: Modern Recipes for Transformer Based Deep Learning Architectures. IEEE Access 2021, 9, 68675–68702. [Google Scholar] [CrossRef]
- Li, K.; Liu, Z.; He, T.; Huang, H.; Peng, F.; Povey, D.; Khudanpur, S. An Empirical Study of Transformer-Based Neural Language Model Adaptation. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 7934–7938. [Google Scholar] [CrossRef]
- Xie, H.; Qin, Z.; Tao, X.; Letaief, K.B. Task-oriented multi-user semantic communications. IEEE J. Sel. Areas Commun. 2022, 40, 2584–2597. [Google Scholar] [CrossRef]
- Choi, H.; Kim, J.; Joe, S.; Gwon, Y. Evaluation of BERT and ALBERT Sentence Embedding Performance on Downstream NLP Tasks. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 5482–5487. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Beheitt, M.E.G.; Ben Haj Hmida, M. Automatic Arabic Poem Generation with GPT-2. In Proceedings of the 14th International Conference on Agents and Artificial Intelligence, Online, 3–5 February 2022; Science and Technology Publications: Setúbal, Portugal, 2022; pp. 366–374. [Google Scholar] [CrossRef]
- Steele, J.L. To GPT or not GPT? Empowering our students to learn with AI. Comput. Educ. Artif. Intell. 2023, 5, 100160. [Google Scholar] [CrossRef]
- Google AI. Gemini Models. Available online: https://ai.google.dev/gemini-api/docs/models/gemini (accessed on 16 December 2024).
- Google AI. Pricing Models. Available online: https://ai.google.dev/pricing (accessed on 16 December 2024).
- Google AI. Billing. Available online: https://ai.google.dev/gemini-api/docs/billing (accessed on 16 December 2024).
- Core42. Core42’s Bilingual AI for Arabic Speakers. Available online: https://www.core42.ai/jais.html (accessed on 16 December 2024).
- Abdul-Mageed, M.; Elmadany, A.; Nagoudi, E.M.B. ARBERT & MARBERT: Deep Bidirectional Transformers for Arabic. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; Zong, C., Xia, F., Li, W., Navigli, R., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 7088–7105. [Google Scholar] [CrossRef]
- Kmainasi, M.; Shahroor, A.; Hasanain, M.; Laskar, S.; Hassan, N.; Alam, F. LlamaLens: Specialized Multilingual LLM for Analyzing News and Social Media Content. arXiv 2024, arXiv:2410.15308. [Google Scholar]
- Alturayeif, N.; Luqman, H.; Alyafeai, Z.; Yamani, A. StanceEval 2024: The First Arabic Stance Detection Shared Task. In Proceedings of the Second Arabic Natural Language Processing Conference, Bangkok, Thailand, 16 August 2024; pp. 774–782. [Google Scholar]
- Badran, M.; Hamdy, M.; Torki, M.; El-Makky, N. AlexUNLP-BH at StanceEval2024: Multiple Contrastive Losses Ensemble Strategy with Multi-Task Learning For Stance Detection in Arabic. In Proceedings of the Second Arabic Natural Language Processing Conference, Bangkok, Thailand, 16 August 2024; Habash, N., Bouamor, H., Eskander, R., Tomeh, N., Abu Farha, I., Abdelali, A., Touileb, S., Hamed, I., Onaizan, Y., Alhafni, B., et al., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 823–827. [Google Scholar] [CrossRef]
- Alghaslan, M.; Almutairy, K. MGKM at StanceEval2024 Fine-Tuning Large Language Models for Arabic Stance Detection. In Proceedings of the Second Arabic Natural Language Processing Conference, Bangkok, Thailand, 16 August 2024; Habash, N., Bouamor, H., Eskander, R., Tomeh, N., Abu Farha, I., Abdelali, A., Touileb, S., Hamed, I., Onaizan, Y., Alhafni, B., et al., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 816–822. [Google Scholar] [CrossRef]
- Hasanaath, A.; Alansari, A. StanceCrafters at StanceEval2024: Multi-task Stance Detection using BERT Ensemble with Attention Based Aggregation. In Proceedings of the Second Arabic Natural Language Processing Conference, Bangkok, Thailand, 16 August 2024; Habash, N., Bouamor, H., Eskander, R., Tomeh, N., Abu Farha, I., Abdelali, A., Touileb, S., Hamed, I., Onaizan, Y., Alhafni, B., et al., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 811–815. [Google Scholar] [CrossRef]
- Salamah, J.B.; Elkhlifi, A. Microblogging opinion mining approach for kuwaiti dialect. In Proceedings of the the International Conference on Computing Technology and Information Management (ICCTIM), Dubai, United Arab Emirates, 9 April 2014; Society of Digital Information and Wireless Communication (SDIWC). p. 388. [Google Scholar]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1993. [Google Scholar]
- Freund, Y.; Mason, L. The Alternating Decision Tree Learning Algorithm. In Proceedings of the Sixteenth International Conference on Machine Learning, ICML ’99, San Francisco, CA, USA, 27–30 June 1999; pp. 124–133. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar]
- Antoun, W.; Baly, F.; Hajj, H. AraBERT: Transformer-based Model for Arabic Language Understanding. In Proceedings of the 4th Workshop on Open-Source Arabic Corpora and Processing Tools, with a Shared Task on Offensive Language Detection, Marseille, France, 11–16 May 2020; Al-Khalifa, H., Magdy, W., Darwish, K., Elsayed, T., Mubarak, H., Eds.; European Language Resource Association: Paris, France, 2020; pp. 9–15. [Google Scholar]
- Wang, W.; Wei, F.; Dong, L.; Bao, H.; Yang, N.; Zhou, M. MINILM: Deep self-attention distillation for task-agnostic compression of pre-trained transformers. In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS ’20, Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- Inoue, G.; Alhafni, B.; Baimukan, N.; Bouamor, H.; Habash, N. The Interplay of Variant, Size, and Task Type in Arabic Pre-trained Language Models. In Proceedings of the Sixth Arabic Natural Language Processing Workshop, Kyiv, Ukraine (Virtual), 19 April 2021; Habash, N., Bouamor, H., Hajj, H., Magdy, W., Zaghouani, W., Bougares, F., Tomeh, N., Abu Farha, I., Touileb, S., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 92–104. [Google Scholar]
- Tan, Z.; Li, D.; Wang, S.; Beigi, A.; Jiang, B.; Bhattacharjee, A.; Karami, M.; Li, J.; Cheng, L.; Liu, H. Large Language Models for Data Annotation and Synthesis: A Survey. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Miami, FL, USA, 12–16 November 2024; Al-Onaizan, Y., Bansal, M., Chen, Y.N., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 930–957. [Google Scholar] [CrossRef]
- Kojima, T.; Gu, S.S.; Reid, M.; Matsuo, Y.; Iwasawa, Y. Large language models are zero-shot reasoners. In Proceedings of the 36th International Conference on Neural Information Processing Systems, NIPS ’22, Red Hook, NY, USA, 28 November–9 December 2022. [Google Scholar]
- Li, Y.; Zhang, J. Semi-supervised Meta-learning for Cross-domain Few-shot Intent Classification. In Proceedings of the 1st Workshop on Meta Learning and Its Applications to Natural Language Processing, Online, 5 August 2021; Lee, H.Y., Mohtarami, M., Li, S.W., Jin, D., Korpusik, M., Dong, S., Vu, N.T., Hakkani-Tur, D., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 67–75. [Google Scholar] [CrossRef]
- Wei, J.; Bosma, M.; Zhao, V.Y.; Guu, K.; Yu, A.W.; Lester, B.; Du, N.; Dai, A.M.; Le, Q.V. Finetuned Language Models are Zero-Shot Learners. In Proceedings of the the Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, 25–29 April 2022. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Proceedings of the 34th International Conference on Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2020; pp. 1877–1901. [Google Scholar]
- Gao, T.; Fisch, A.; Chen, D. Making Pre-trained Language Models Better Few-shot Learners. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 5 August 2021; Zong, C., Xia, F., Li, W., Navigli, R., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 3816–3830. [Google Scholar] [CrossRef]
- Goel, A.; Gueta, A.; Gilon, O.; Liu, C.; Erell, S.; Nguyen, L.H.; Hao, X.; Jaber, B.; Reddy, S.; Kartha, R.; et al. Llms accelerate annotation for medical information extraction. In Proceedings of the Machine Learning for Health (ML4H), PMLR, New Orleans, LA, USA, 10 December 2023; ML Research Press: Cambridge, MA, USA, 2023; Volume 225, pp. 82–100. [Google Scholar]
- Aguda, T.D.; Siddagangappa, S.; Kochkina, E.; Kaur, S.; Wang, D.; Smiley, C. Large Language Models as Financial Data Annotators: A Study on Effectiveness and Efficiency. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), Torino, Italy, 20–25 May 2024; Calzolari, N., Kan, M.Y., Hoste, V., Lenci, A., Sakti, S., Xue, N., Eds.; ELRA and ICCL: Torino, Italy, 2024; pp. 10124–10145. [Google Scholar]
- Trad, F.S.; Chehab, A. Prompt Engineering or Fine-Tuning? A Case Study on Phishing Detection with Large Language Models. Mach. Learn. Knowl. Extr. 2024, 6, 367–384. [Google Scholar] [CrossRef]
- Kholodna, N.; Julka, S.; Khodadadi, M.; Gumus, M.N.; Granitzer, M. LLMs in the loop: Leveraging large language model annotations for active learning in low-resource languages. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Vilnius, Lithuania, 9–13 September 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 397–412. [Google Scholar]
- FreedomIntelligence. FreedomIntelligence/AceGPT-v2-32B. Available online: https://huggingface.co/FreedomIntelligence/AceGPT-v2-32B (accessed on 16 December 2024).
- Wikipedia. Variance. Available online: https://en.wikipedia.org/wiki/Variance (accessed on 16 December 2024).
- RunPod. RunPod—The Cloud Built for AI. Available online: https://www.runpod.io/ (accessed on 16 December 2024).
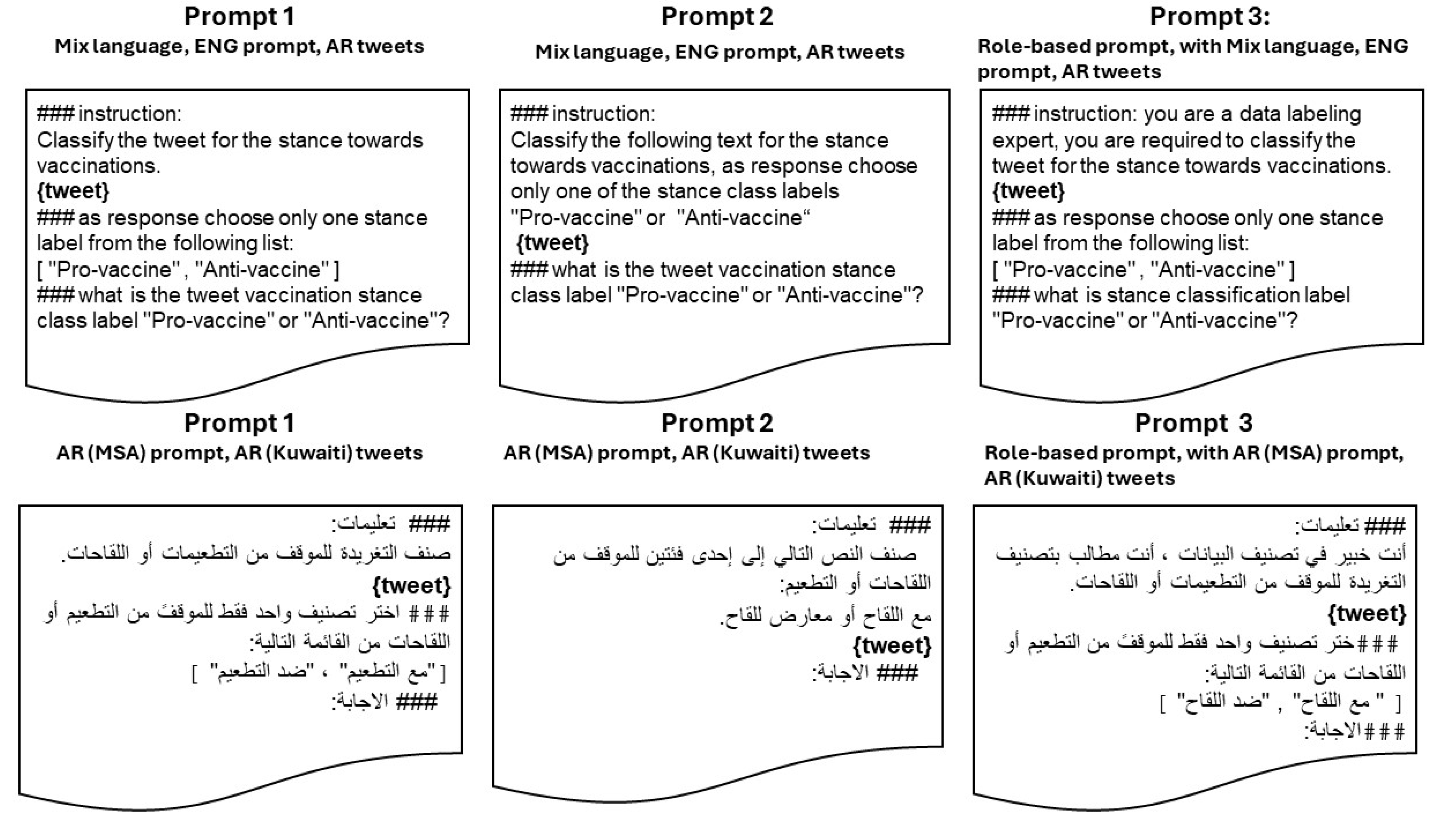



| Tweet in Kuwiati Dialect | Tweet in English | Label |
|---|---|---|
 | They are not supposed to confuse those who are vaccinated with those who are not vaccinated. They must separate them and distinguish between the two vaccinated people. As for the decisions, I do not consider them naive. Most deaths occurred within a month due to vaccination. Yes to vaccination. Yes to vaccination. | Pro-vaccine |
 | I have been vaccinated. I thank the Ministry of Health and everyone who works there and for it for the health of Kuwait, a very sophisticated organization | Pro-vaccine |
 | The solution to achieving community immunity through which we can regain the right to our normal lives is vaccination. If you have not yet registered for vaccination, register, and if you have a question or fear, you can ask the specialists and everyone is ready to answer you yes to vaccination | Pro-vaccine |
 | Do not blame the citizens for your miserable failure, no to compulsory vaccination | Anti-vaccine |
 | Is it possible that we are in a country that has a constitution, parliament, and democracy? Furthermore, it is known to be a country of humanity and its people are forced to be vaccinated! So, no to compulsory vaccination. | Anti-vaccine |
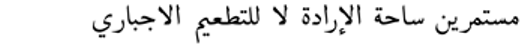 | Continuing the arena of will, no to compulsory vaccination | Anti-vaccine |
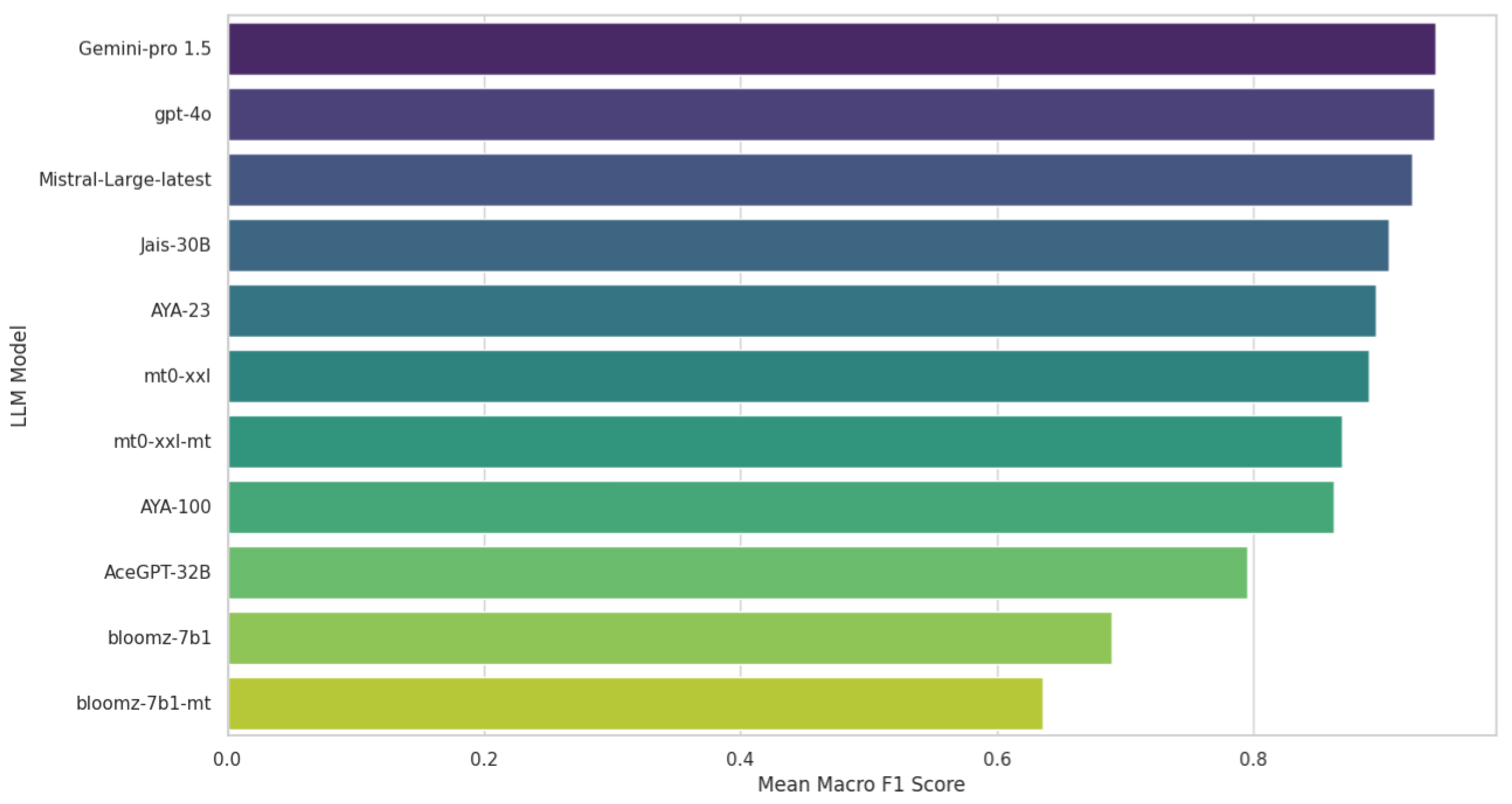
| LLM | Mean Macro F1 Score |
|---|---|
| Gemini-pro 1.5 * | 0.94 * |
| GPT-4o * | 0.94 * |
| Mistral-Large-latest | 0.92 |
| Jais-30B | 0.90 |
| AYA-23 | 0.89 |
| mt0-xxl | 0.88 |
| mt0-xxl-mt | 0.87 |
| AYA-100 | 0.86 |
| AceGPT-32B | 0.79 |
| bloomz-7b1 | 0.69 |
| bloomz-7b1-mt | 0.63 |
| LLM | Macro F1 |
|---|---|
| mT0-xxl | 0.00014 |
| GPT-4o | 0.00016 |
| Gemini-pro 1.5 | 0.00023 |
| Mistral-Large-latest | 0.00044 |
| Jais-30B | 0.00057 |
| AYA-100 | 0.00160 |
| mT0-xxl-mt | 0.00368 |
| AYA-23 | 0.00551 |
| bloomz-7b1 | 0.01955 |
| bloomz-7b1-mt | 0.02384 |
| AceGPT-32B | 0.05155 |
| Method | Macro F1 Arabic Templates | Macro F1 English Templates |
|---|---|---|
| ZS | 0.248 | 0.736 |
| 2FS | 0.896 | 0.902 |
| 4FS | 0.888 | 0.914 |
| 6FS | 0.879 | 0.898 |
| Prompt Template Language | Prompt Template Number | Macro F1 Score |
|---|---|---|
| AR | 1 | 0.354 |
| AR | 2 | 0.095 |
| AR | 3 | 0.294 |
| Mix | 1 | 0.854 |
| Mix | 2 | 0.801 |
| Mix | 3 | 0.552 |
| Prompt Template | Tweet Text | Predicted Label | Human Label | Error Type |
|---|---|---|---|---|
| Arabic 2 |  |  | Pro-vaccine | Hallucination |
| English Translation: ATV channel raises the slogan “Yes to vaccination”. |
English Translation: Categorize the posts now | |||
| Mixed 3 |  |  | Pro-vaccine | Hallucination |
| English Translation: On this day, the Corona virus began to spread locally in Kuwait. The solution is to vaccinate more than % of the people. Yes to vaccination. May God help us. | English Translation: ## Prepared by: @Mohamed Al-Masry - Mohamed Elmas | |||
| Arabic 2 |  | 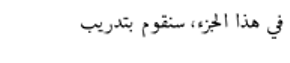 | Pro-vaccine | Hallucination |
| English Translation: They are not supposed to confuse those who are vaccinated with those who are not vaccinated. They must separate them and distinguish between the two vaccinated people. As for the decisions, I do not consider them naive. Most deaths occurred within a month due to vaccination. Yes to vaccination. Yes to vaccination. | English Translation: In this part, we will train | |||
| Arabic 1 |  |  | Anti-vaccine | Misclassification |
| English Translation: Is it possible that we are in a country that has a constitution, parliament, and democracy? Furthermore, it is known to be a country of humanity and its people are forced to be vaccinated! So, no to compulsory vaccination. | English Translation: Pro-vaccine | |||
| Mixed 3 | 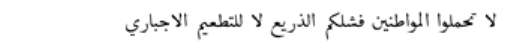 | Pro-vaccine | Anti-vaccine | Misclassification |
| English Translation: Do not blame the citizens for your miserable failure, no to compulsory vaccination | ||||
| Mixed 3 | 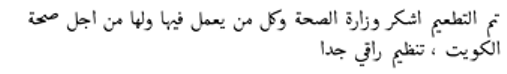 | Anti-vaccine | Pro-vaccine | Misclassification |
| English Translation: I have been vaccinated. I thank the Ministry of Health and everyone who works in it and for it for the health of Kuwait, a very sophisticated organization |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alostad, H. Large Language Models as Kuwaiti Annotators. Big Data Cogn. Comput. 2025, 9, 33. https://doi.org/10.3390/bdcc9020033
Alostad H. Large Language Models as Kuwaiti Annotators. Big Data and Cognitive Computing. 2025; 9(2):33. https://doi.org/10.3390/bdcc9020033
Chicago/Turabian StyleAlostad, Hana. 2025. "Large Language Models as Kuwaiti Annotators" Big Data and Cognitive Computing 9, no. 2: 33. https://doi.org/10.3390/bdcc9020033
APA StyleAlostad, H. (2025). Large Language Models as Kuwaiti Annotators. Big Data and Cognitive Computing, 9(2), 33. https://doi.org/10.3390/bdcc9020033