
A Recursive Attribute Reduction Algorithm and Its Application in Predicting the Hot Metal Silicon Content in Blast Furnaces



Abstract
1. Introduction
- (1)
- We propose a novel heuristic reduction construction.
| Algorithm 1. Traditional heuristic attribute reduction algorithm. |
| Input: Information table and priority sequence Output: Reduct . Step 1: Construct the discernibility matrix, ; calculate the core attribute set, ; and the delete elements discerned by . Step 2: Delete the attributes belonging to from the priority sequence; then, the new priority sequence is }. Step 3: Addition: , k = 1. While is not a super reduct of , do End Step 4: Deletion: While , do If is a super reduct then End k = k − 1 End Step 5: Output |
- (2)
- We define a new optimal reduct.
- (3)
- We provide a recursive reduction algorithm and illustrate its validity based on UCI datasets and a real application on silicon content prediction.
2. Preliminary Knowledge on Pawlak Rough Set
- (1)
- ;
- (2)
- .
- (1)
- ;
- (2)
- .
3. Recursive Attribute Reduction Algorithm Based on Priority Sequence
3.1. Priority Sequence and Priority-Optimal Reduct
3.2. Calculation Method on POR
3.2.1. Calculation of the First Attribute of POR
- (1)
- ;
- (2)
- , if , then , ;
- (3)
- .
| Algorithm 2. Construct the free matrix. |
| Input: Discernibility matrix . Output: The related free matrix. Step 1: Sort all the non-empty elements by ; let be the number of non-empty elements. Step 2: Set While , do ; While , do If then delete from , Else . End End End Step 3: Output the free matrix. |
3.2.2. Calculation on Other Attributes of POR
- (1)
- ;
- (2)
- If then .
- (1)
- For each non-empty element , ;
- (2)
- For each attribute , .
- Simple Repeated Logic
- (1)
- If , then we accept , and we call this method with the updated parameter set.
- (2)
- If , then we reject , and we remove from the discernibility matrix.
- Additional Border Logic
- The Terminate Condition
3.2.3. The Complete Reduction Algorithm Based on Recursion
| Algorithm 3. Reduction algorithm based on recursion for calculating POR. |
| Input: Information table and attribute priority sequence . Output: The corresponding . Step 1: Construct the discernibility matrix , calculate the core attribute set , and delete the elements from that can be discerned by . Step 2: Construct the free matrix and delete attributes in the attribute priority sequence that do not appear in the free matrix ( and ). The new attribute priority sequence is , and the attribute with the highest priority in is , i.e., . Step 3: Use Algorithm 4 to test other attributes in with the input (), and output (). Step 4: Output . |
| Algorithm 4. Recursive function . |
| Input: Attribute set , priority sequence , discernibility matrix , . Output: Attribute set , . Step 1: If then Return with /Valid reduct found, recursion ends End Step 2: For each attribute in , calculate based on . Step 3: If then Call with input ()//Accept , recursive call Else Refuse and test if is a core set of If is a core set, then Return with //Core conflict detected, backtrack Else Delete from Call with input ()//Recursive call without End End Step 3: Process the result returned: If not be rejected not a core of Refuse and delete from Call with input () and return the result returned directly Else Return the result returned directly End |
4. Application in Blast Furnace Smelting
4.1. Data Description and Priority Sequence
- (1)
- The mechanisms of blast furnace smelting should be considered first. For example, since blast furnace smelting is a continuous process, the silicon content at the last time point strongly influences the current silicon content.
- (2)
- We also considered the staff’s experience, since they know which attributes carry the greatest importance during operation.
- (3)
- Correlation analysis between the condition attributes can serve as a reference for the attribute priority sequence.
4.2. Attribute Reduction
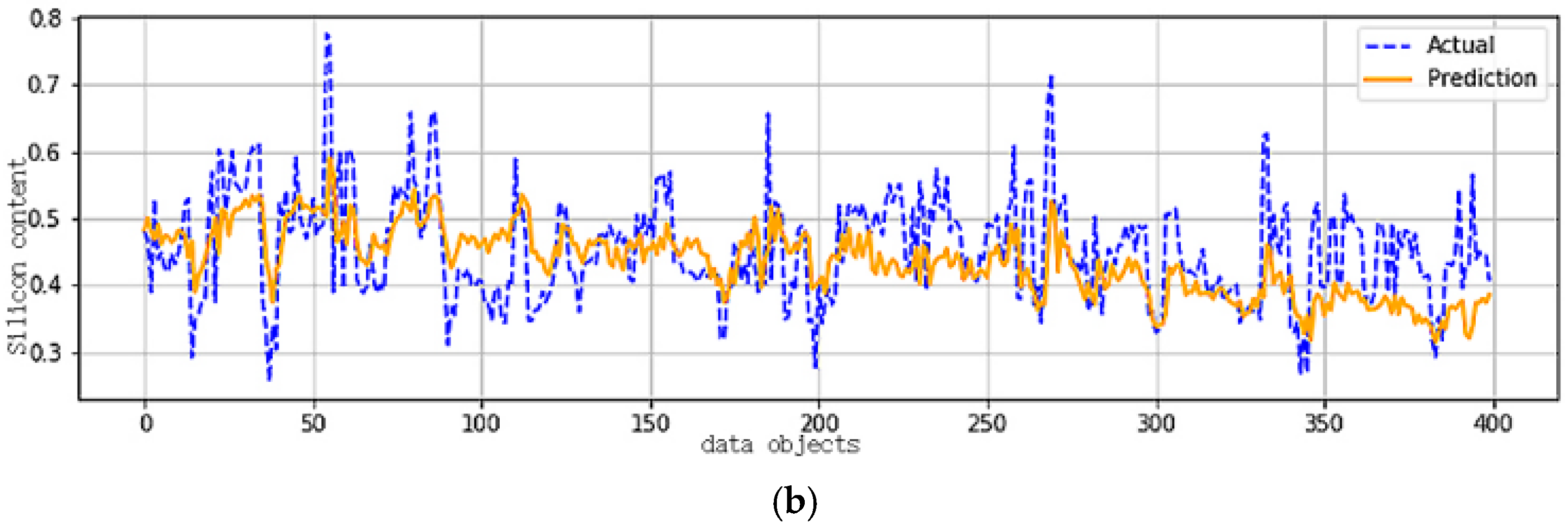
4.3. Prediction with LSTM-RNN
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Taher, D.I.; Abu-Gdairi, R.; El-Bably, M.K.; El-Gayar, M.A. Decision-making in diagnosing heart failure problems using basic rough sets. AIMS Math. 2024, 9, 21816–21847. [Google Scholar] [CrossRef]
- Zhang, Q.; Xie, Q.; Wang, G. A survey on rough set theory and its applications. CAAI Trans. Intell. Technol. 2016, 1, 323–333. [Google Scholar] [CrossRef]
- Yin, L.; Cao, K.; Jiang, Z.; Li, Z. RA-MRS: A high efficient attribute reduction algorithm in big data. J. King Saud Univ.-Comput. Inf. Sci. 2024, 36, 102064. [Google Scholar] [CrossRef]
- Qin, L.; Wang, X.; Yin, L.; Jiang, Z. A distributed evolutionary based instance selection algorithm for big data using Apache Spark. Appl. Soft Comput. 2024, 159, 111638. [Google Scholar] [CrossRef]
- Akram, M.; Ali, G.; Alcantud, J.C.R. Attributes reduction algorithms for m-polar fuzzy relation decision systems. Int. J. Approx. Reason. 2022, 140, 232–254. [Google Scholar] [CrossRef]
- Liu, G.; Feng, Y. Knowledge granularity reduction for decision tables. Int. J. Mach. Learn. Cyber. 2022, 13, 569–577. [Google Scholar] [CrossRef]
- Yin, L.; Qin, L.; Jiang, Z.; Xu, X. A fast parallel attribute reduction algorithm using Apache Spark. Knowl.-Based Syst. 2021, 212, 106582. [Google Scholar] [CrossRef]
- Xie, X.; Gu, X.; Li, Y.; Ji, Z. K-size partial reduct: Positive region optimization for attribute reduction. Knowl.-Based Syst. 2021, 228, 107253. [Google Scholar] [CrossRef]
- Turaga, V.K.H.; Chebrolu, S. Rapid and optimized parallel attribute reduction based on neighborhood rough sets and MapReduce. Expert Syst. Appl. 2025, 260, 125323. [Google Scholar] [CrossRef]
- Kumar, A.; Prasad, P.S.V.S.S. Enhancing the scalability of fuzzy rough set approximate reduct computation through fuzzy min–max neural network and crisp discernibility relation formulation. Eng. Appl. Artif. Intell. 2022, 110, 104697. [Google Scholar] [CrossRef]
- Sowkunta, P.; Prasad, P.S.V.S.S. MapReduce based parallel fuzzy-rough attribute reduction using discernibility matrix. Appl. Intell. 2022, 52, 154–173. [Google Scholar] [CrossRef]
- Xu, W.; Yuan, K.; Li, W.; Ding, W. An Emerging Fuzzy Feature Selection Method Using Composite Entropy-Based Uncertainty Measure and Data Distribution. IEEE Trans. Emerg. Top. Comput. Intell. 2023, 7, 76–88. [Google Scholar] [CrossRef]
- Sang, B.; Chen, H.; Yang, L.; Li, T.; Xu, W. Incremental Feature Selection Using a Conditional Entropy Based on Fuzzy Dominance Neighborhood Rough Sets. IEEE Trans. Fuzzy Syst. 2022, 30, 1683–1697. [Google Scholar] [CrossRef]
- Ji, X.; Li, J.; Yao, S.; Zhao, P. Attribute reduction based on fusion information entropy. Int. J. Approx. Reason. 2023, 160, 108949. [Google Scholar] [CrossRef]
- Fontes, D.O.L.; Vasconcelos, L.G.S.; Brito, R.P. Blast furnace hot metal temperature and silicon content prediction using soft sensor based on fuzzy C-means and exogenous nonlinear autoregressive models. Comput. Chem. Eng. 2020, 141, 107028. [Google Scholar] [CrossRef]
- Nistala, S.H.; Kumar, R.; Parihar, M.S.; Runkana, V. metafur: Digital Twin System of a Blast Furnace. Trans. Indian. Inst. Met. 2024, 77, 4383–4393. [Google Scholar] [CrossRef]
- Jiang, K.; Jiang, Z.; Xie, Y.; Pan, D.; Gui, W. Prediction of Multiple Molten Iron Quality Indices in the Blast Furnace Ironmaking Process Based on Attention-Wise Deep Transfer Network. IEEE Trans. Instrum. Meas. 2022, 71, 2512114. [Google Scholar] [CrossRef]
- Liu, C.; Tan, J.; Li, J.; Li, Y.; Wang, H. Temporal Hypergraph Attention Network for Silicon Content Prediction in Blast Furnace. IEEE Trans. Instrum. Meas. 2022, 71, 2521413. [Google Scholar] [CrossRef]
- Li, J.; Yang, C.; Li, Y.; Xie, S. A Context-Aware Enhanced GRU Network with Feature-Temporal Attention for Prediction of Silicon Content in Hot Metal. IEEE Trans. Ind. Inf. 2022, 18, 6631–6641. [Google Scholar] [CrossRef]
- Wang, W.; Huang, B.; Wang, T. Optimal scale selection based on multi-scale single-valued neutrosophic decision-theoretic rough set with cost-sensitivity. Int. J. Approx. Reason. 2023, 155, 132–144. [Google Scholar] [CrossRef]
- Shu, W.; Xia, Q.; Qian, W. Neighborhood multigranulation rough sets for cost-sensitive feature selection on hybrid data. Neurocomputing 2023, 565, 126990. [Google Scholar] [CrossRef]
- Yang, J.; Kuang, J.; Liu, Q.; Liu, Y. Cost-Sensitive Multigranulation Approximation in Decision-Making Applications. Electronics 2022, 11, 3801. [Google Scholar] [CrossRef]
- Su, H.; Chen, J.; Lin, Y. A four-stage branch local search algorithm for minimal test cost attribute reduction based on the set covering. Appl. Soft Comput. 2024, 153, 111303. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Classical Algorithm | The Proposed Algorithm | Reduction Algorithm in [7] | RA-MRS in [3] |
|---|---|---|---|---|
| Sonar_2 | 5,7,11,16,17,2022,24,26,27,30,33,35,37,53,54 | 1,5,8,13,16,17,19–22,26,27, 30–34,36, 37, 42,43, 53, 54 | 5,7,11,16,17,20,21,22,24,26,27,30–33, 35, 37,53,54 | 1–30 |
| Sonar_4 | 1,6–8,11,12,17, 18, 21, 23 | 1–6,23,25,31, 35, 41,43,47 | 1,6–8,11,12,17, 18,21, 23 | 1–23 |
| Sonar_8 | 1,2,7,9,10,14,18 | 1–7,44,50,58 | 1,2,7,9,10,14,18 | 1–12 |
| Sonar_16 | 1–5,9 | 1–5,7,53 | 1–5,9 | 1–8 |
| Iono_2 | 1,3,5–7,9,11–14, 16,19,23,25,29,30,33 | 1–3,5,7,9,11–17,19,23,25, 29, 32, 33 | 1,3,5–7,9,11–14, 16,19,23,25,29,30,33 | 1–32 |
| Iono_4 | 2–5,7,9,10,15, 23, 24 | 1–7,23,24,26, 33 | 2–5,7,9,10,15, 23,24 | 1–24 |
| Iono_8 | 1–4,6,7,9 | 1–5,13,16,29 | 1–4,6,7,9 | 1–10 |
| Iono_16 | 2,3,5,7,8 | 1–4,6,9,28 | 2,3,5,7,8 | 1–8 |
| Zoo | 3,4,6,8,13 | 1,3,6,7,10,12,13 | 3,4,6,8,13 | 1–12 |
| Wine_2 | 1–12 | 1–12 | 1–12 | 1–12 |
| Wine_4 | 1–7,9 | 1–7,9 | 1–7,9 | 1–12 |
| Wine_8 | 1–3,5,6 | 1–4,8 | 1–3,5,6 | 1–12 |
| Wine_16 | 1–4. | 1–4. | 1–4 | 1–7 |
| Fertility_4 | 1–3,5–7,9 | 1–3,5–7,9 | 1–3,5–7,9 | 1–8 |
| Fertility_8 | 1,2,4–7 | 1–3,7–9 | 1,2,4–7 | 1–7 |
| Fertility_16 | 1–4,6,7 | 1–4,6,7 | 1–4,6,7 | 1–7 |
| Algorithm | Reduct |
|---|---|
| Proposed algorithm | |
| Addition–deletion algorithm |
| Parameter | Setting |
|---|---|
| Activation | relu |
| Timesteps | 1 |
| input_dim | |reduct| |
| batch_size | 100 |
| Others | default |
| Reduct | Test Number | Train_MSE | Test_MSE | Hit (Train) | Hit (Test) |
|---|---|---|---|---|---|
| 1 | 0.0042 | 0.0051 | 88.75% | 85.25% | |
| 2 | 0.0042 | 0.0048 | 88.35% | 86.75% | |
| 3 (Figure 4) | 0.0043 | 0.0047 | 87.93% | 87.75% | |
| 4 | 0.0042 | 0.0053 | 88.49% | 84.25% | |
| 5 | 0.0046 | 0.0047 | 86.55% | 87.50% | |
| 1 | 0.0042 | 0.0055 | 88.06% | 83.25% | |
| 2 | 0.0040 | 0.0054 | 89.17% | 83.50% | |
| 3 (Figure 5) | 0.0042 | 0.0057 | 88.89% | 82.25% | |
| 4 | 0.0045 | 0.0057 | 86.67% | 81.50% | |
| 5 | 0.0048 | 0.0052 | 87.36% | 84.25% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Cheng, P.; Yin, L.; Guan, Y. A Recursive Attribute Reduction Algorithm and Its Application in Predicting the Hot Metal Silicon Content in Blast Furnaces. Big Data Cogn. Comput. 2025, 9, 6. https://doi.org/10.3390/bdcc9010006
Li Z, Cheng P, Yin L, Guan Y. A Recursive Attribute Reduction Algorithm and Its Application in Predicting the Hot Metal Silicon Content in Blast Furnaces. Big Data and Cognitive Computing. 2025; 9(1):6. https://doi.org/10.3390/bdcc9010006
Chicago/Turabian StyleLi, Zhanqi, Pan Cheng, Linzi Yin, and Yuyin Guan. 2025. "A Recursive Attribute Reduction Algorithm and Its Application in Predicting the Hot Metal Silicon Content in Blast Furnaces" Big Data and Cognitive Computing 9, no. 1: 6. https://doi.org/10.3390/bdcc9010006
APA StyleLi, Z., Cheng, P., Yin, L., & Guan, Y. (2025). A Recursive Attribute Reduction Algorithm and Its Application in Predicting the Hot Metal Silicon Content in Blast Furnaces. Big Data and Cognitive Computing, 9(1), 6. https://doi.org/10.3390/bdcc9010006