


BERTGuard: Two-Tiered Multi-Domain Fake News Detection with Class Imbalance Mitigation


Abstract
1. Introduction
- Contributions: The key contributions of this paper are as follows:
- Introduction of BERTGuard: We propose BERTGuard, a novel two-tier solution for multi-domain fake news detection utilizing BERT-based models, which addresses limitations in existing methods by improving the semantic understanding of textual data.
- State-of-the-art performance: We carry out an extensive evaluation of our proposed approach by comparing it against existing alternative solutions and demonstrate that BERTGuard outperforms existing methods by achieving a 27% improvement in accuracy and a 29% increase in F1-score across multiple benchmark datasets, establishing a new state-of-the-art in fake news detection.
- Class imbalance analysis: We analyze the impact of three methods for dealing with the class imbalance inherent to these domains, providing valuable insights for future research and practical applications in fake news detection.
- Organization: The structure of this paper is as follows. Section 2 provides the background and a review of the literature. In Section 3, we present our proposed multi-stage solution for fake news detection, BERTGuard. In Section 4, we outline the experimental methodology employed in our study, providing details on the datasets and the evaluation metrics utilized. Section 5 presents the experimental results and analyzes the findings. Lastly, Section 6 concludes our paper.
2. Background and Related Work
2.1. Fake News Detection
- RoBERTa: Robustly Optimized BERT Pretraining Approach (RoBERTa) is a variant of BERT designed to improve the training process. It was developed by extending the training duration, using larger datasets with longer sequences, and employing larger mini-batches. The researchers achieved significant performance enhancements by adjusting several hyperparameters of the original BERT model [37].
- DistilBERT: DistilBERT is a more compact, faster, and cost-effective version of BERT, which is derived from the original model with certain architectural features removed to enhance efficiency [38]. Similar to BERT, DistilBERT can be fine-tuned to achieve strong performance in various natural language processing tasks [39].
- BERT-large-uncased: This is a BERT model with 12 more transformer layers, 230 million more parameters, and a larger embedding dimension, allowing the model to encapsulate much more information than BERT-base-uncased [40].
- BERT-cased: This is a model trained with the same hyperparameters as first published by Google [39].
- ALBERT: ALBERT is short for ‘A Lite’ BERT and is a streamlined version of BERT designed to reduce memory usage and accelerate training. It employs two primary parameter-reduction techniques: dividing the embedding matrix into two smaller matrices and using shared layers grouped together [41]. ALBERT is recognized for its reduced number of parameters compared to BERT, which enhances its memory efficiency while still delivering strong performance. These variations highlight BERT’s adaptability across various domains and its potential for tailored customization to specific tasks.
2.2. Fake News Datasets
2.3. Dealing with Class Imbalance
3. BERTGuard: Two-Tiered Multi-Domain Fake News Detection with Class Imbalance Mitigation
- Tokenizer: BertTokenizer, classifier: BertForSequenceClassification, and model: BERT (base uncased);
- Tokenizer: BertTokenizer, classifier: BertForSequenceClassification, and model: BERT (base cased);
- Tokenizer: DistilBertTokenizer, classifier: DistilBertForSequenceClassification, and model: DistilBERT (base uncased, finetuned SST-2 English);
- Tokenizer: DistilBertTokenizer, classifier: DistilBertForSequenceClassification, and model: DistilBERT (base uncased);
- Tokenizer: RobertaTokenizer, classifier: RobertaForSequenceClassification, and model: RoBERTa (base);
- Tokenizer: AlbertTokenizer, classifier: AlbertForSequenceClassification, and model: ALBERT (base v2).
4. Materials and Methods
- Crime: distilbert-base-uncased-finetuned-sst-2-english;
- Health: distilbert-base-uncased;
- Politics: bert-base-uncased;
- Science: roberta-base;
- Social media: distilbert-base-uncased.
4.1. Data Collection
- Label standardization: The label values were standardized to ensure uniformity. The datasets that we utilized in this study were already labeled by their sources. In this project, ‘1’ was assigned to indicate ‘fake’ news, and ‘0’ indicates ‘not fake’ news. Some datasets originally had multiple classes representing varying degrees of ‘fakeness’. These were binarized to a fake/not fake format based on criteria that balanced the dataset as effectively as possible.
- Text processing:
- Cleaning: raw data were cleaned to remove irrelevant content such as HTML tags, scripts, special characters, and advertisements.
- Standardization: standardized formats were applied, such as converting dates to a consistent format and removing duplicates.
- Normalization: text normalization included converting text to lowercase, removing punctuation, and expanding contractions.
- Tokenization: the text was tokenized to break it down into individual words or tokens.
- Stop word removal: common stop words were removed to focus on the most meaningful words.
- Lemmatization: words were reduced to their base or root forms through lemmatization, aiding in the normalization of text data.
- Handling missing data: entries with missing titles, bodies, or descriptions were removed to ensure the integrity of the dataset.
- Multi-language data: for datasets containing multi-language data, articles were filtered to include only those written in English, ensuring uniformity in text processing and model training.
- Metadata management: all other features not directly used in the primary analysis were stored in a JSON dictionary as supplementary metadata. This approach allows these features to be easily utilized if needed for further refinement of the results.
4.2. Evaluation Metrics
5. Results and Discussion
5.1. Model Selection
- Crime: The distilbert-base-uncased-finetuned-sst-2-english model performed the best, with an average accuracy of 68.8%. This suggests that the finetuned version of DistilBERT is better at capturing the nuances in the crime domain.
- Health: The distilbert-base-uncased model achieved the highest accuracy of 88.3%, making it the most suitable for health-related news detection.
- Politics: The bert-base-uncased model had the highest accuracy at 87.8%, indicating its effectiveness in detecting political news.
- Science: The roberta-base model excelled in the science domain, with an accuracy of 80.2%, suggesting it handles the specific language and context of science-related news more effectively.
- Social: The distilbert-base-uncased model stood out, with a remarkable accuracy of 95.6%, making it the best choice for the social domain.
5.2. Single-Stage Fake News Detection Results
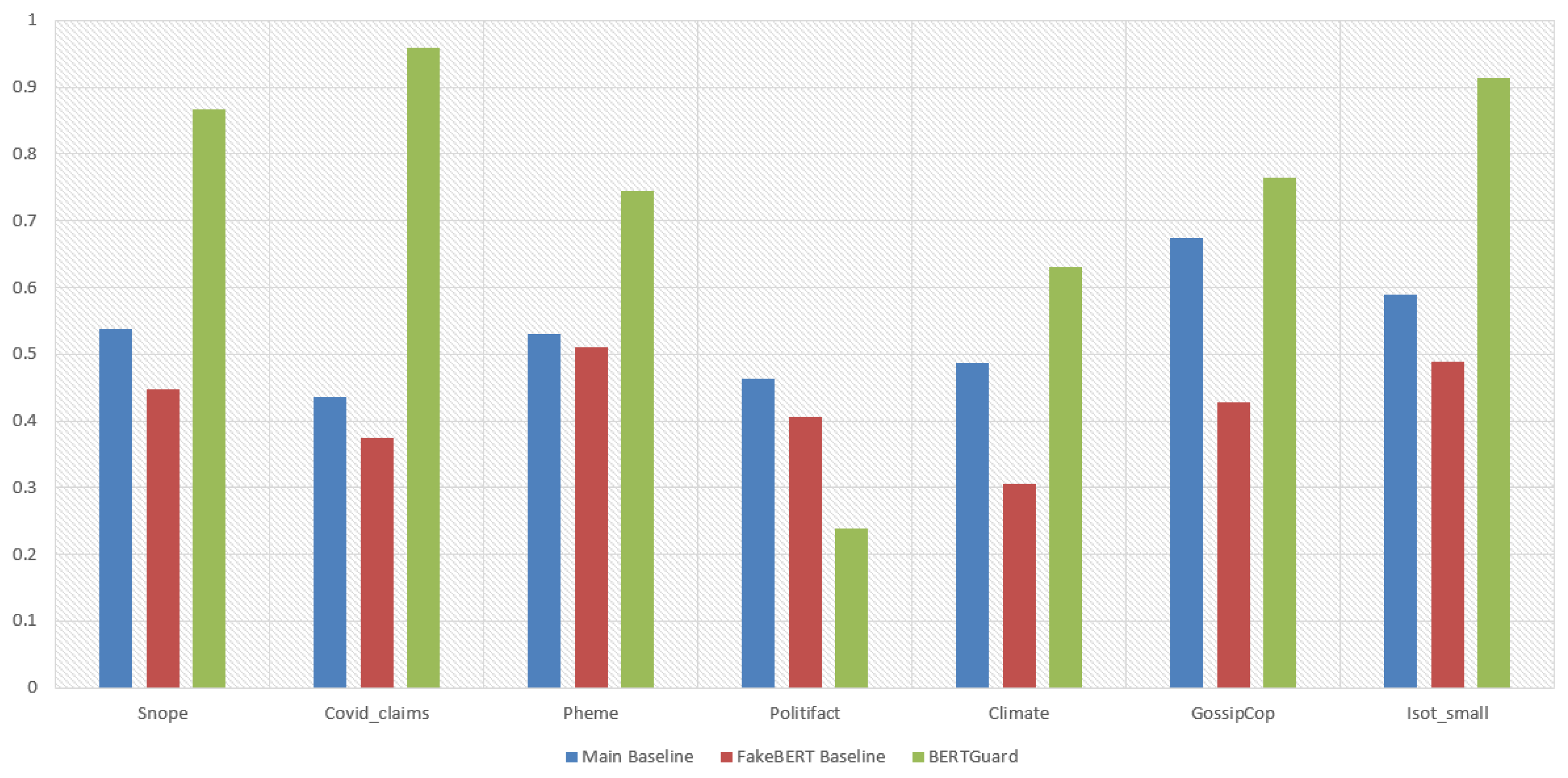
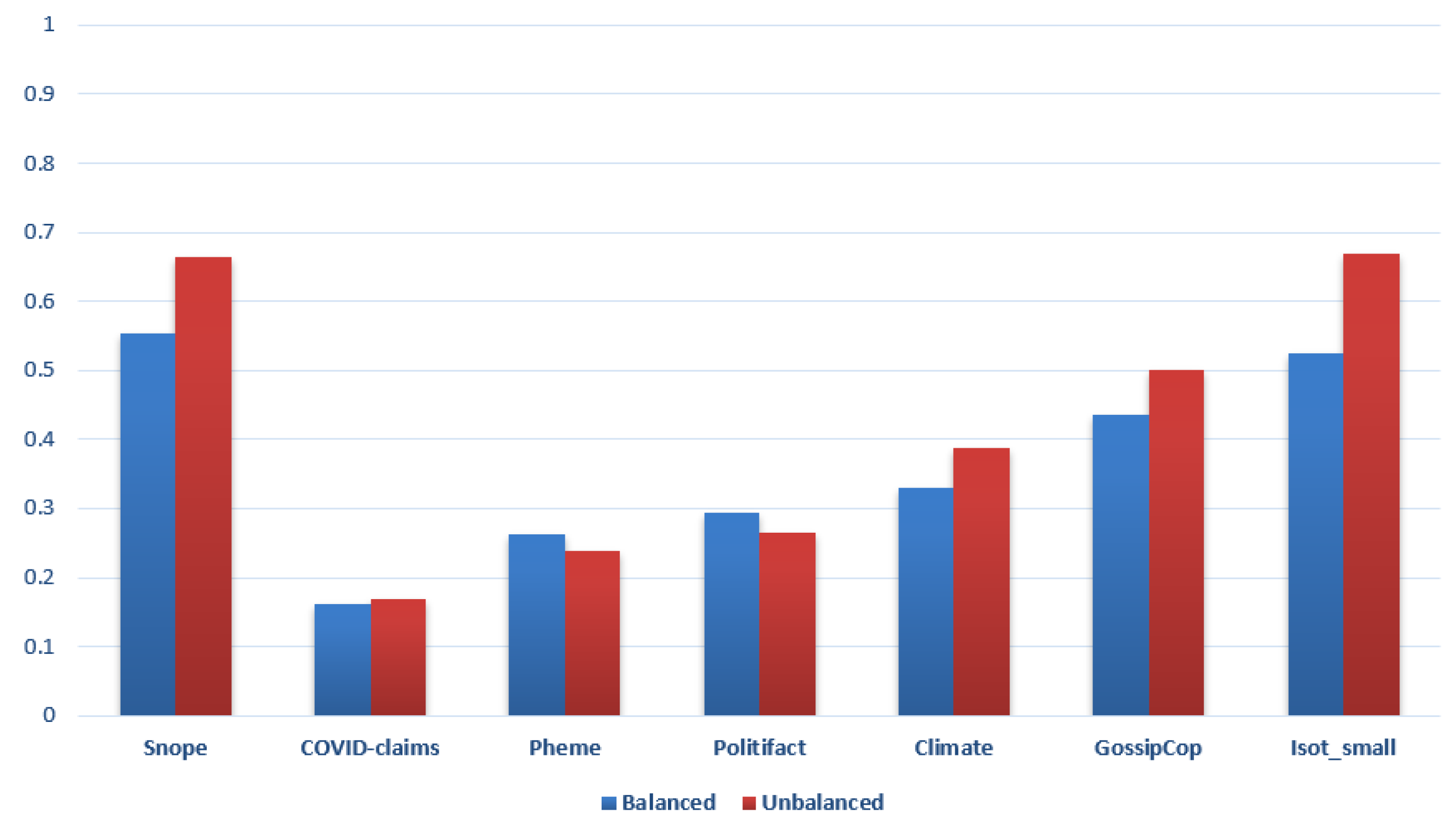
5.3. Multi-Domain Fake News Approach
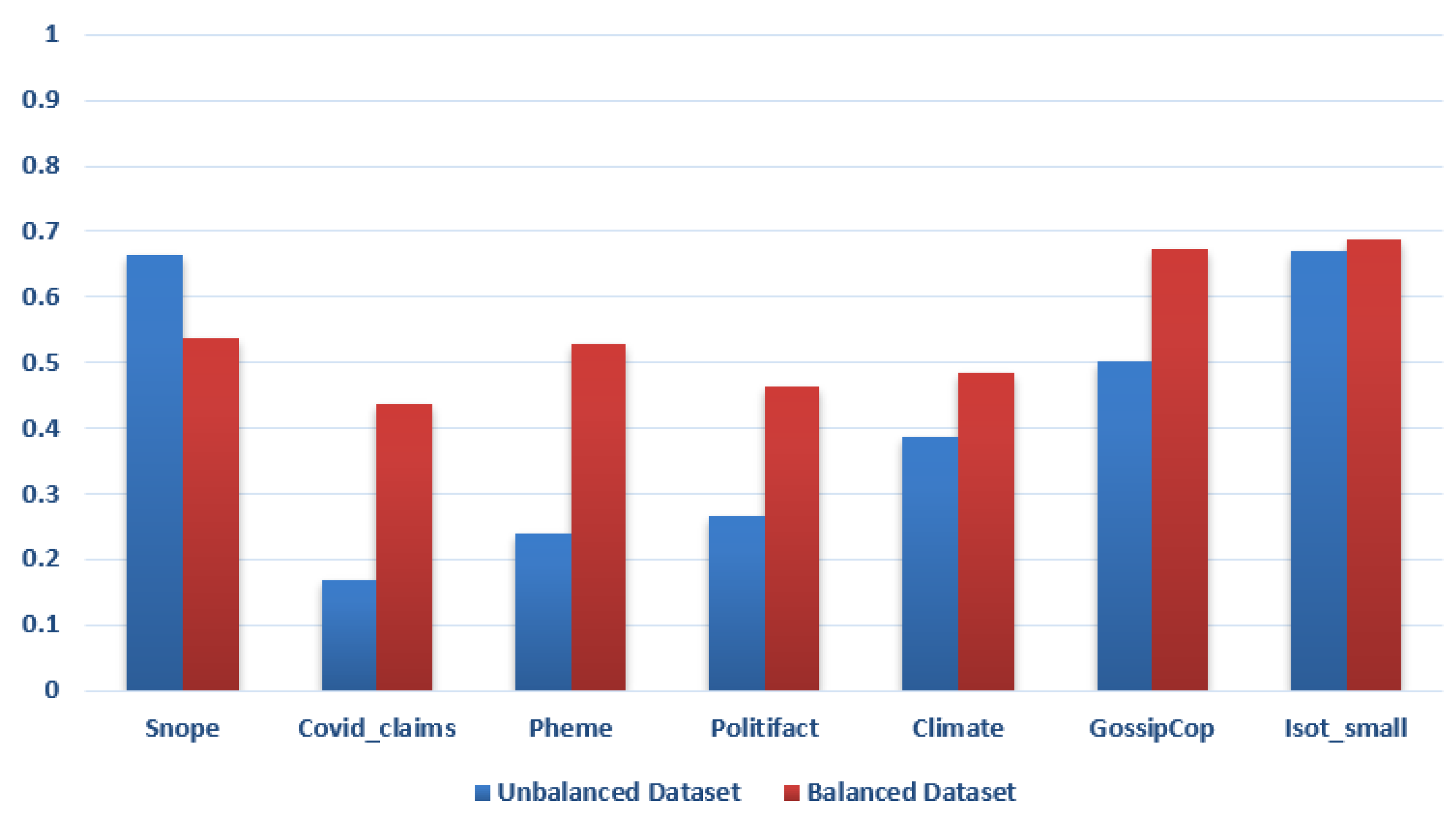
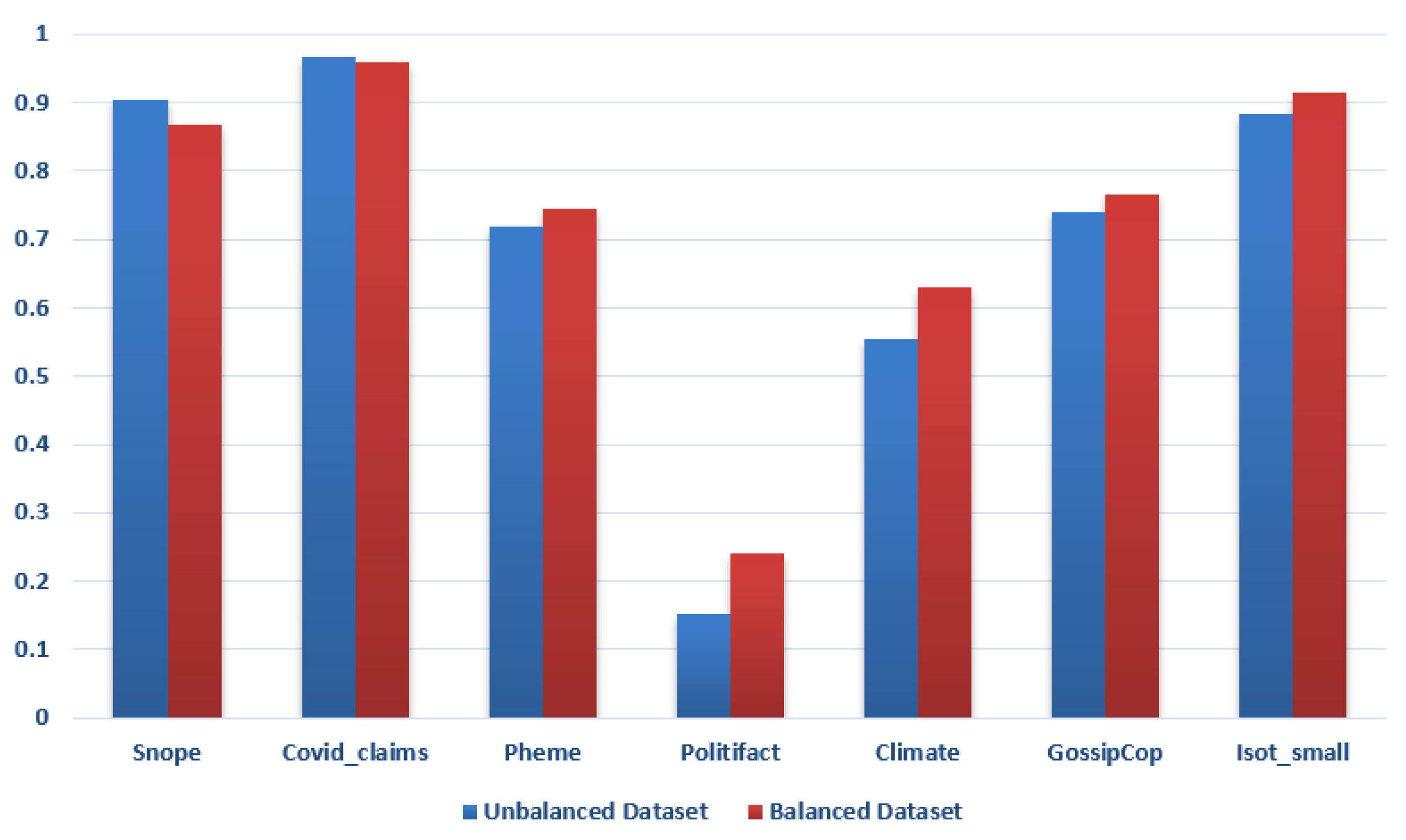
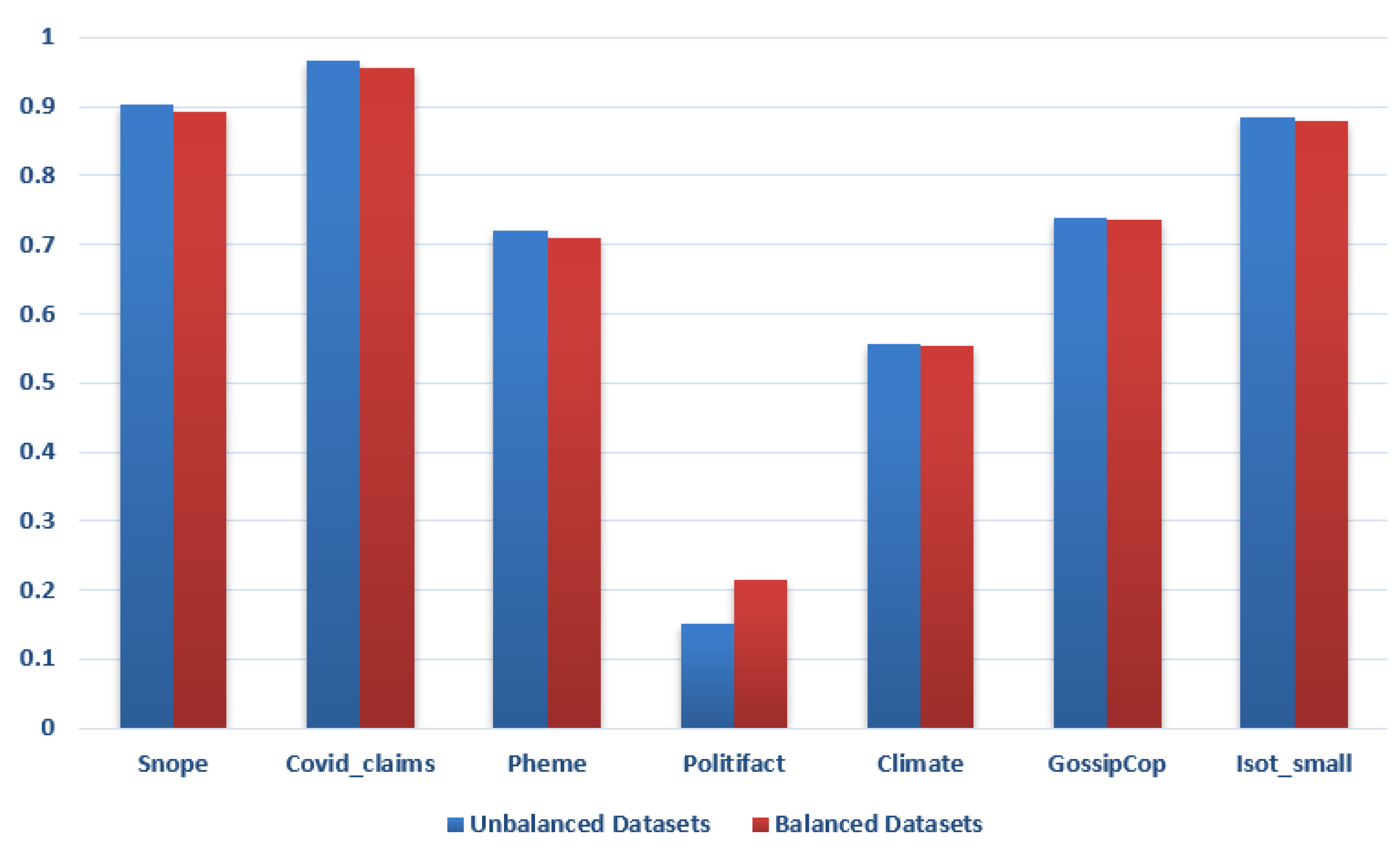
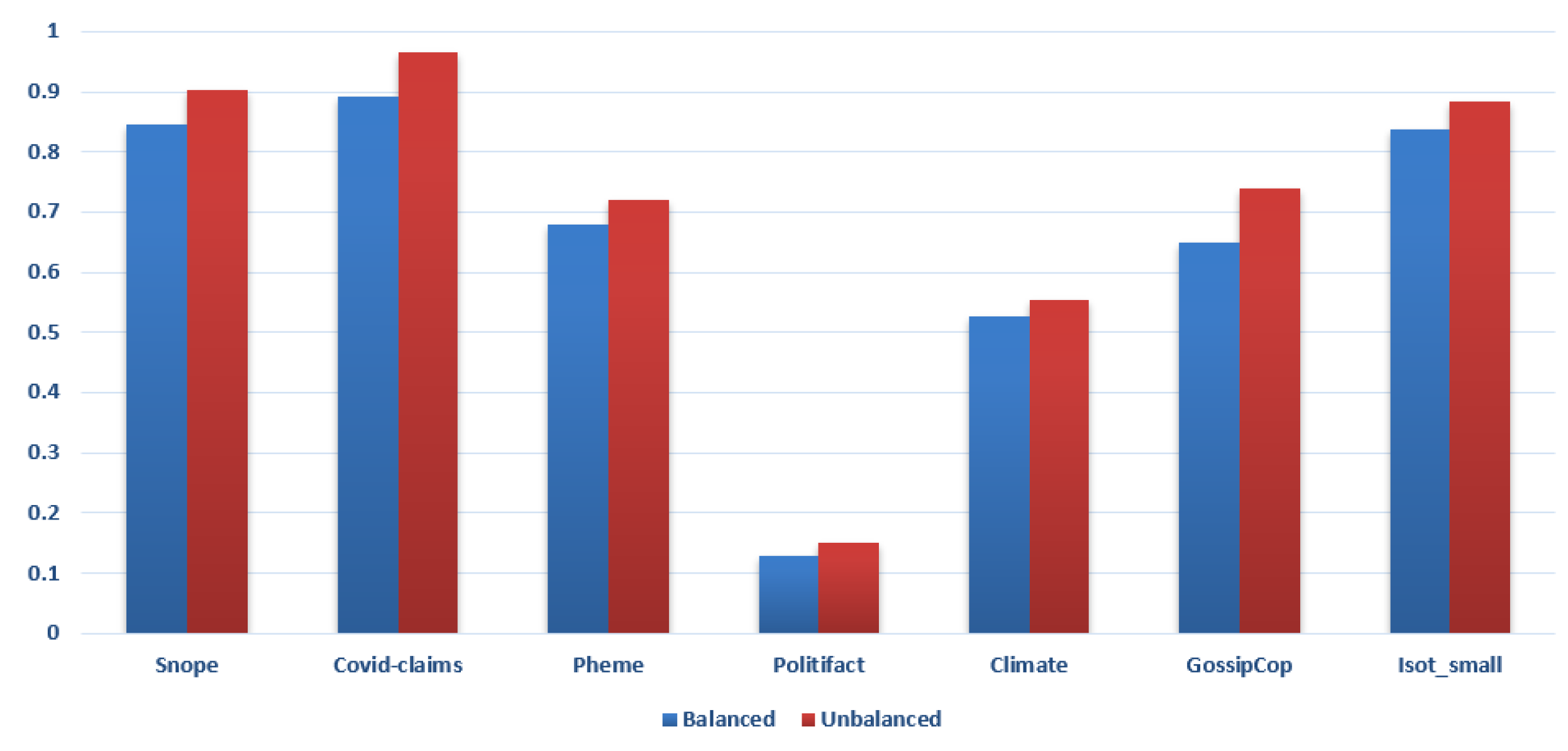
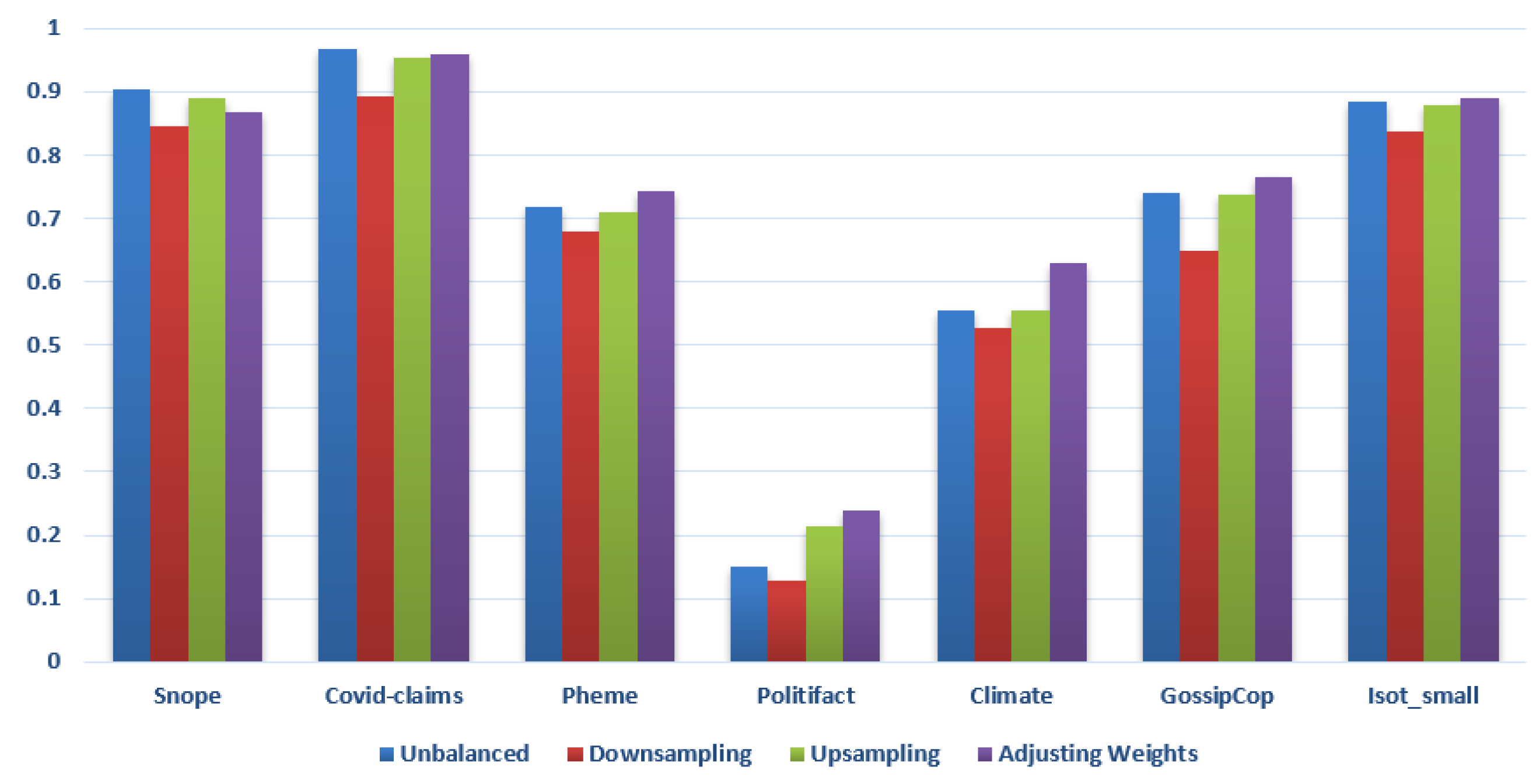
5.4. Overall Impact of Class Imbalance Handling Strategies
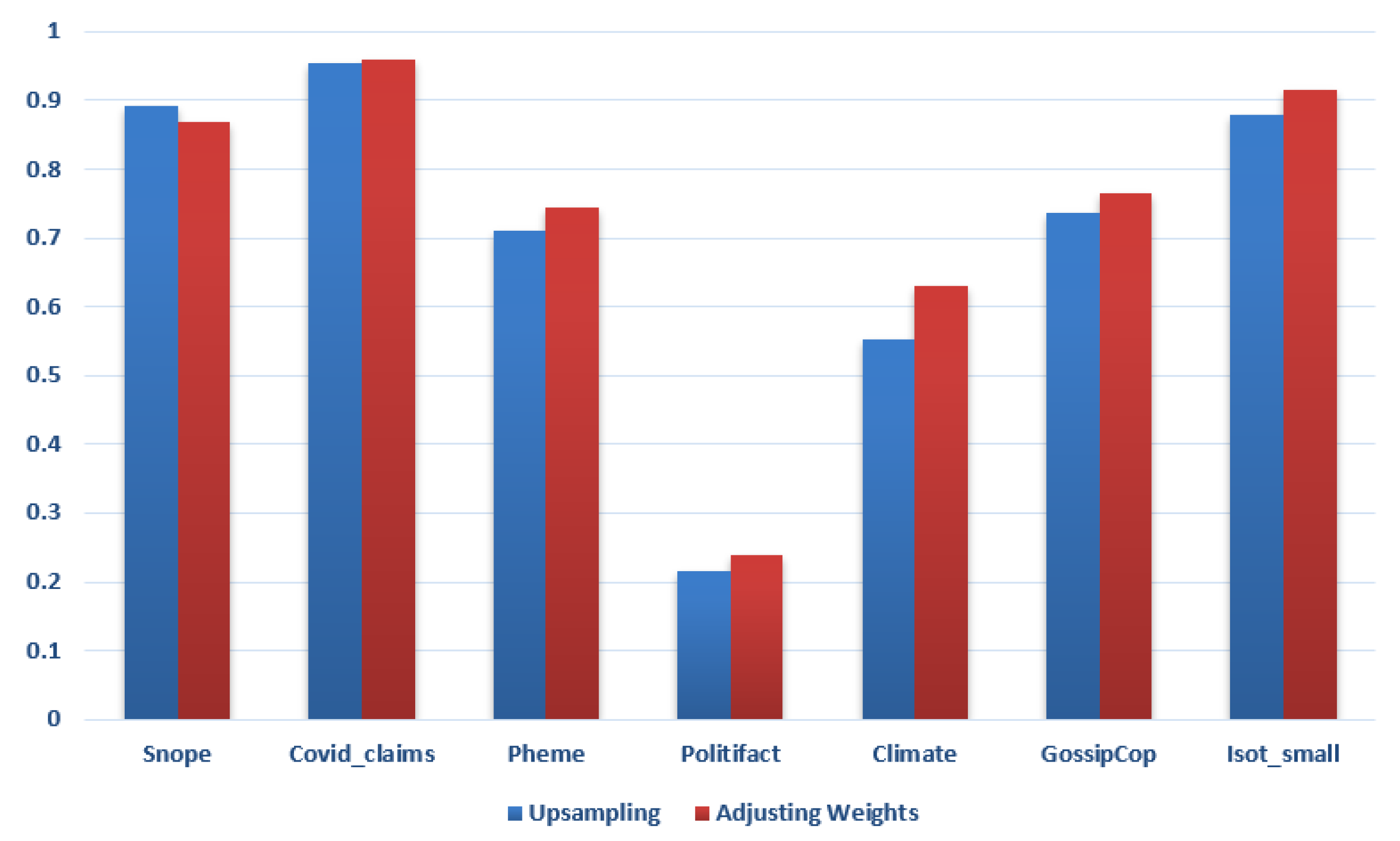
5.5. Impact of Balancing Datasets by Adjusting Weights
5.6. Impact of Balancing Datasets by Upsampling
5.7. Impact of Balancing Datasets by Downsampling
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Silva, A.; Luo, L.; Karunasekera, S.; Leckie, C. Embracing domain differences in fake news: Cross-domain fake news detection using multi-modal data. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 557–565. [Google Scholar]
- Chen, Q. Coronavirus Rumors Trigger Irrational Behaviors among Chinese Netizens. 2020. Available online: https://www.globaltimes.cn/content/1178157.shtml (accessed on 12 May 2024).
- Sharma, K.; Qian, F.; Jiang, H.; Ruchansky, N.; Zhang, M.; Liu, Y. Combating fake news: A survey on identification and mitigation techniques. Acm Trans. Intell. Syst. Technol. (TIST) 2019, 10, 1–42. [Google Scholar] [CrossRef]
- Schuster, T.; Schuster, R.; Shah, D.J.; Barzilay, R. The limitations of stylometry for detecting machine-generated fake news. Comput. Linguist. 2020, 46, 499–510. [Google Scholar] [CrossRef]
- Shabani, S.; Sokhn, M. Hybrid machine-crowd approach for fake news detection. In Proceedings of the 2018 IEEE 4th International Conference on Collaboration and Internet Computing (CIC), Philadelphia, PA, USA, 18–20 October 2018; pp. 299–306. [Google Scholar]
- Nan, Q.; Wang, D.; Zhu, Y.; Sheng, Q.; Shi, Y.; Cao, J.; Li, J. Improving Fake News Detection of Influential Domain via Domain- and Instance-Level Transfer. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; pp. 2834–2848. [Google Scholar]
- Nan, Q.; Cao, J.; Zhu, Y.; Wang, Y.; Li, J. MDFEND: Multi-domain fake news detection. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Virtual Event, QLD, Australia, 1–5 November 2021; pp. 3343–3347. [Google Scholar]
- Allcott, H.; Gentzkow, M. Social media and fake news in the 2016 election. J. Econ. Perspect. 2017, 31, 211–236. [Google Scholar] [CrossRef]
- Vosoughi, S.; Roy, D.; Aral, S. The spread of true and false news online. Science 2018, 359, 1146–1151. [Google Scholar] [CrossRef] [PubMed]
- Bursztyn, L.; Rao, A.; Roth, C.P.; Yanagizawa-Drott, D.H. Misinformation during a Pandemic; Technical Report; National Bureau of Economic Research: Cambridge, MA, USA, 2020. [Google Scholar]
- Alnabhan, M.Q.; Branco, P. Evaluating Deep Learning for Cross-Domains Fake News Detection. In Proceedings of the International Symposium on Foundations and Practice of Security, Bordeaux, France, 11–13 December 2023; Springer: Cham, Switzerland, 2024; pp. 40–51. [Google Scholar]
- Kaliyar, R.K.; Goswami, A.; Narang, P. FakeBERT: Fake news detection in social media with a BERT-based deep learning approach. Multimed. Tools Appl. 2021, 80, 11765–11788. [Google Scholar] [CrossRef] [PubMed]
- Tang, H.; Liu, J.; Zhao, M.; Gong, X. Progressive layered extraction (ple): A novel multi-task learning (mtl) model for personalized recommendations. In Proceedings of the 14th ACM Conference on Recommender Systems, Rio de Janeiro, Brazil, 22–26 September 2020; pp. 269–278. [Google Scholar]
- Seiffert, C.; Khoshgoftaar, T.M.; Van Hulse, J.; Napolitano, A. A comparative study of data sampling and cost sensitive learning. In Proceedings of the 2008 IEEE International Conference on Data Mining Workshops, Pisa, Italy, 15–19 December 2008; pp. 46–52. [Google Scholar]
- Alnabhan, M.Q.; Branco, P. Fake News Detection Using Deep Learning: A Systematic Literature Review. IEEE Access 2024, 12, 1. [Google Scholar] [CrossRef]
- Longadge, R.; Dongre, S. Class imbalance problem in data mining review. arXiv 2013, arXiv:1305.1707. [Google Scholar]
- Alenezi, M.N.; Alqenaei, Z.M. Machine learning in detecting COVID-19 misinformation on twitter. Future Internet 2021, 13, 244. [Google Scholar] [CrossRef]
- Moravec, P.; Kim, A.; Dennis, A. Flagging fake news: System 1 vs. System 2. In Proceedings of the 39th International Conference on Information Systems, San Francisco, CA, USA, 13–16 December 2018. [Google Scholar]
- Khweiled, R.; Jazzar, M.; Eleyan, D. Cybercrimes during COVID-19 pandemic. Int. J. Inf. Eng. Electron. Bus. 2021, 13, 1–10. [Google Scholar] [CrossRef]
- Shin, D.; Koerber, A.; Lim, J.S. Impact of misinformation from generative AI on user information processing: How people understand misinformation from generative AI. New Media Soc. 2024, 14614448241234040. [Google Scholar] [CrossRef]
- Qawasmeh, E.; Tawalbeh, M.; Abdullah, M. Automatic identification of fake news using deep learning. In Proceedings of the 2019 Sixth International Conference on Social Networks Analysis, Management and Security (SNAMS), Granada, Spain, 22–25 October 2019; pp. 383–388. [Google Scholar]
- Kozik, R.; Kula, S.; Choraś, M.; Woźniak, M. Technical solution to counter potential crime: Text analysis to detect fake news and disinformation. J. Comput. Sci. 2022, 60, 101576. [Google Scholar] [CrossRef]
- Deepak, S.; Chitturi, B. Deep neural approach to Fake-News identification. Procedia Comput. Sci. 2020, 167, 2236–2243. [Google Scholar]
- Sharma, S.; Saraswat, M.; Dubey, A.K. Fake News Detection Using Deep Learning. In Proceedings of the Knowledge Graphs and Semantic Web: Third Iberoamerican Conference and Second Indo-American Conference, KGSWC 2021, Kingsville, TX, USA, 22–24 November 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 249–259. [Google Scholar]
- Pilkevych, I.; Fedorchuk, D.; Naumchak, O.; Romanchuk, M. Fake news detection in the framework of decision-making system through graph neural network. In Proceedings of the 2021 IEEE 4th International Conference on Advanced Information and Communication Technologies (AICT), Lviv, Ukraine, 21–25 September 2021; pp. 153–157. [Google Scholar]
- Manene, S. Mitigating misinformation about the COVID-19 infodemic on social media: A conceptual framework. Jàmbá J. Disaster Risk Stud. 2023, 15, 1416. [Google Scholar] [CrossRef]
- Akhter, M.; Hossain, S.M.M.; Nigar, R.S.; Paul, S.; Kamal, K.M.A.; Sen, A.; Sarker, I.H. COVID-19 Fake News Detection using Deep Learning Model. Ann. Data Sci. 2024, 1–32. [Google Scholar] [CrossRef]
- Nasir, J.A.; Khan, O.S.; Varlamis, I. Fake news detection: A hybrid CNN-RNN based deep learning approach. Int. J. Inf. Manag. Data Insights 2021, 1, 100007. [Google Scholar] [CrossRef]
- Kaliyar, R.K.; Goswami, A.; Narang, P.; Sinha, S. FNDNet—A deep convolutional neural network for fake news detection. Cogn. Syst. Res. 2020, 61, 32–44. [Google Scholar] [CrossRef]
- Saleh, H.; Alharbi, A.; Alsamhi, S.H. OPCNN-FAKE: Optimized convolutional neural network for fake news detection. IEEE Access 2021, 9, 129471–129489. [Google Scholar] [CrossRef]
- Yang, Y.; Zheng, L.; Zhang, J.; Cui, Q.; Li, Z.; Yu, P.S. TI-CNN: Convolutional neural networks for fake news detection. arXiv 2018, arXiv:1806.00749. [Google Scholar]
- Raj, C.; Meel, P. ConvNet frameworks for multi-modal fake news detection. Appl. Intell. 2021, 51, 8132–8148. [Google Scholar] [CrossRef]
- Hashmi, E.; Yayilgan, S.Y.; Yamin, M.M.; Ali, S.; Abomhara, M. Advancing fake news detection: Hybrid deep learning with fasttext and explainable AI. IEEE Access 2024, 12, 44462–44480. [Google Scholar] [CrossRef]
- Mosallanezhad, A.; Karami, M.; Shu, K.; Mancenido, M.V.; Liu, H. Domain adaptive fake news detection via reinforcement learning. In Proceedings of the ACM Web Conference 2022, Lyon, France, 25–29 April 2022; pp. 3632–3640. [Google Scholar]
- Li, X.; Fu, X.; Xu, G.; Yang, Y.; Wang, J.; Jin, L.; Liu, Q.; Xiang, T. Enhancing BERT representation with context-aware embedding for aspect-based sentiment analysis. IEEE Access 2020, 8, 46868–46876. [Google Scholar] [CrossRef]
- Xu, H.; Liu, B.; Shu, L.; Yu, P.S. BERT Post-Training for Review Reading Comprehension and Aspect-based Sentiment Analysis. arXiv 2019, arXiv:1904.02232. [Google Scholar]
- Kumar, B. BERT Variants and Their Differences; Technical report; 360DigiTMG: Hyderabad, India, 2023. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2020, arXiv:1910.01108. [Google Scholar]
- Lutkevich, B. BERT Language Model; Technical report; TechTarget: Newton, MA, USA, 2020. [Google Scholar]
- Tida, V.S.; Hsu, D.S.; Hei, D.X. Unified Fake News Detection using Transfer Learning of BERT Model. IEEE 2020. Available online: https://d1wqtxts1xzle7.cloudfront.net/86079521/2202.01907v1-libre.pdf?1652817185=&response-content-disposition=inline%3B+filename%3DUnified_Fake_News_Detection_using_Transf.pdf&Expires=1723717032&Signature=SlJqui-38VOu3m7EAFYMcfZkoxq23tXKTFkq-wlwLHawKo0ibgs47MWTsCwm~7pRxvt4tl7LYN90t0QkZ7TNA8u30OuhD1JPpvNYhXoF4rYemFei0xLNEpYr4NkaPcsRshcrXcEuN0u1DTA5aR8TD1eZhJcU6x1~AZbl745yKnoIrztd032Gb2EVFS5VW~Gy3xxYIiAWD~HJ3zu5SFhTzdOcHChdGXexeXZ8Dls7N-UU-KGdGMWq4XnwnWXv9A20jpMYks6Dqcho9rutx~f3t3A0UyuCYilNghvcU-o0uGj4J4zGnEN1rhhCvtCUEAl1DMabCr-aCCW73t7Q9URcRg__&Key-Pair-Id=APKAJLOHF5GGSLRBV4ZA (accessed on 12 May 2024).
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Luo, Y.; Shi, Y.; Li, S. Social media fake news detection algorithm based on multiple feature groups. In Proceedings of the 2023 IEEE 3rd International Conference on Information Technology, Big Data and Artificial Intelligence (ICIBA), Chongqing, China, 26–28 May 2023; Volume 3, pp. 91–95. [Google Scholar]
- Bounaama, R.; Abderrahim, M.E.A. Classifying COVID-19 Related Tweets for Fake News Detection and Sentiment Analysis with BERT-based Models. arXiv 2023, arXiv:2304.00636. [Google Scholar]
- Essa, E.; Omar, K.; Alqahtani, A. Fake news detection based on a hybrid BERT and LightGBM models. Complex Intell. Syst. 2023, 9, 6581–6592. [Google Scholar] [CrossRef] [PubMed]
- Shushkevich, E.; Cardiff, J.; Boldyreva, A. Detection of Truthful, Semi-Truthful, False and Other News with Arbitrary Topics Using BERT-Based Models. In Proceedings of the 2023 33rd Conference of Open Innovations Association (FRUCT), Zilina, Slovakia, 24–26 May 2023; pp. 250–256. [Google Scholar]
- Sultana, R.; Nishino, T. Fake News Detection System: An implementation of BERT and Boosting Algorithm. In Proceedings of the 38th International Conference on Computers and Their Applications, Virtual, 20–22 March 2023; Volume 91, pp. 124–137. [Google Scholar]
- Alghamdi, J.; Lin, Y.; Luo, S. Towards COVID-19 fake news detection using transformer-based models. Knowl.-Based Syst. 2023, 274, 110642. [Google Scholar] [CrossRef] [PubMed]
- SATHVIK, M.; Mishra, M.K.; Padhy, S. Fake News Detection by Fine Tuning of Bidirectional Encoder Representations from Transformers. IEEE Trans. Comput. Soc. Syst. 2023, 20, 20. [Google Scholar]
- Kitanovski, A.; Toshevska, M.; Mirceva, G. DistilBERT and RoBERTa Models for Identification of Fake News. In Proceedings of the 2023 46th MIPRO ICT and Electronics Convention (MIPRO), Opatija, Croatia, 22–26 May 2023; pp. 1102–1106. [Google Scholar]
- Saini, K.; Jain, R. A Hybrid LSTM-BERT and Glove-based Deep Learning Approach for the Detection of Fake News. In Proceedings of the 2023 3rd International Conference on Smart Data Intelligence (ICSMDI), Trichy, India, 30–31 March 2023; pp. 400–406. [Google Scholar]
- Fauzy, A.R.I.; Setiawan, E.B. Detecting Fake News on Social Media Combined with the CNN Methods. J. Resti (Rekayasa Sist. Dan Teknol. Informasi) 2023, 7, 271–277. [Google Scholar] [CrossRef]
- Nassif, A.B.; Elnagar, A.; Elgendy, O.; Afadar, Y. Arabic fake news detection based on deep contextualized embedding models. Neural Comput. Appl. 2022, 34, 16019–16032. [Google Scholar] [CrossRef]
- Ranjan, V.; Agrawal, P. Fake News Detection: GA-Transformer And IG-Transformer Based Approach. In Proceedings of the 2022 12th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Virtual Conference, 27–28 January 2022; pp. 487–493. [Google Scholar]
- Raza, S.; Ding, C. Fake news detection based on news content and social contexts: A transformer-based approach. Int. J. Data Sci. Anal. 2022, 13, 335–362. [Google Scholar] [CrossRef] [PubMed]
- Truică, C.O.; Apostol, E.S. MisRoBÆRTa: Transformers versus misinformation. Mathematics 2022, 10, 569. [Google Scholar] [CrossRef]
- Schütz, M.; Schindler, A.; Siegel, M.; Nazemi, K. Automatic fake news detection with pre-trained transformer models. In Proceedings of the Pattern Recognition. ICPR International Workshops and Challenges, Virtual Event, 10–15 January 2021; Springer: Berlin/Heidelberg, Germany, 2021. Part VII. pp. 627–641. [Google Scholar]
- Huang, Y.; Gao, M.; Wang, J.; Shu, K. Dafd: Domain adaptation framework for fake news detection. In Proceedings of the Neural Information Processing: 28th International Conference, ICONIP 2021, Sanur, Bali, Indonesia, 8–12 December 2021; Springer: Berlin/Heidelberg, Germany, 2021. Part I 28. pp. 305–316. [Google Scholar]
- Qazi, M.; Khan, M.U.; Ali, M. Detection of fake news using transformer model. In Proceedings of the 2020 3rd International Conference on Computing, Mathematics and Engineering Technologies (iCoMET), Sukkur, Pakistan, 29–30 January 2020; pp. 1–6. [Google Scholar]
- Nirav Shah, M.; Ganatra, A. A systematic literature review and existing challenges toward fake news detection models. Soc. Netw. Anal. Min. 2022, 12, 168. [Google Scholar] [CrossRef]
- Kato, S.; Yang, L.; Ikeda, D. Domain Bias in Fake News Datasets Consisting of Fake and Real News Pairs. In Proceedings of the 2022 12th International Congress on Advanced Applied Informatics (IIAI-AAI), Kanazawa, Japan, 2–8 July 2022; pp. 101–106. [Google Scholar]
- Hamed, S.K.; Ab Aziz, M.J.; Yaakub, M.R. A review of fake news detection approaches: A critical analysis of relevant studies and highlighting key challenges associated with the dataset, feature representation, and data fusion. Heliyon 2023, 9, e20382. [Google Scholar] [CrossRef]
- Ghosh, K.; Bellinger, C.; Corizzo, R.; Branco, P.; Krawczyk, B.; Japkowicz, N. The class imbalance problem in deep learning. Mach. Learn. 2024, 113, 4845–4901. [Google Scholar] [CrossRef]
- Rastogi, S.; Bansal, D. A review on fake news detection 3T’s: Typology, time of detection, taxonomies. Int. J. Inf. Secur. 2023, 22, 177–212. [Google Scholar] [CrossRef] [PubMed]
- Zhou, P.; Han, X.; Morariu, V.I.; Davis, L.S. Two-stream neural networks for tampered face detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 19–27. [Google Scholar]
- Cardoso, E.F.; Silva, R.M.; Almeida, T.A. Towards automatic filtering of fake reviews. Neurocomputing 2018, 309, 106–116. [Google Scholar] [CrossRef]
- Castelo, S.; Almeida, T.; Elghafari, A.; Santos, A.; Pham, K.; Nakamura, E.; Freire, J. A topic-agnostic approach for identifying fake news pages. In Proceedings of the Companion Proceedings of the 2019 World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 975–980. [Google Scholar]
- Shu, K.; Mahudeswaran, D.; Wang, S.; Lee, D.; Liu, H. Fakenewsnet: A data repository with news content, social context, and spatiotemporal information for studying fake news on social media. Big Data 2020, 8, 171–188. [Google Scholar] [CrossRef]
- Ahmad, I.; Yousaf, M.; Yousaf, S.; Ahmad, M.O. Fake news detection using machine learning ensemble methods. Complexity 2020, 2020, 1–11. [Google Scholar] [CrossRef]
- Zubiaga, A.; Liakata, M.; Procter, R. Learning reporting dynamics during breaking news for rumour detection in social media. arXiv 2016, arXiv:1610.07363. [Google Scholar]
- Wang, W.Y. “Liar, liar pants on fire”: A new benchmark dataset for fake news detection. arXiv 2017, arXiv:1705.00648. [Google Scholar]
- Diggelmann, T.; Boyd-Graber, J.; Bulian, J.; Ciaramita, M.; Leippold, M. CLIMATE-FEVER: A Dataset for Verification of Real-World Climate Claims. arXiv 2020, arXiv:2012.00614. [Google Scholar]
- Branco, P.; Torgo, L.; Ribeiro, R.P. A survey of predictive modeling on imbalanced domains. ACM Comput. Surv. (CSUR) 2016, 49, 1–50. [Google Scholar] [CrossRef]
- Agarwal, I.Y.; Rana, D.P. Fake News and Imbalanced Data Perspective. In Data Preprocessing, Active Learning, and Cost Perceptive Approaches for Resolving Data Imbalance; IGI Global: Hershey, PA, USA, 2021; pp. 195–210. [Google Scholar]
- Salah, I.; Jouini, K.; Korbaa, O. On the use of text augmentation for stance and fake news detection. J. Inf. Telecommun. 2023, 7, 359–375. [Google Scholar] [CrossRef]
- Keya, A.J.; Wadud, M.A.H.; Mridha, M.; Alatiyyah, M.; Hamid, M.A. AugFake-BERT: Handling imbalance through augmentation of fake news using BERT to enhance the performance of fake news classification. Appl. Sci. 2022, 12, 8398. [Google Scholar] [CrossRef]
- Sastrawan, I.K.; Bayupati, I.; Arsa, D.M.S. Detection of fake news using deep learning CNN–RNN based methods. ICT Express 2022, 8, 396–408. [Google Scholar] [CrossRef]
- Mouratidis, D.; Nikiforos, M.N.; Kermanidis, K.L. Deep learning for fake news detection in a pairwise textual input schema. Computation 2021, 9, 20. [Google Scholar] [CrossRef]
- Al Obaid, A.; Khotanlou, H.; Mansoorizadeh, M.; Zabihzadeh, D. Multimodal fake-news recognition using ensemble of deep learners. Entropy 2022, 24, 1242. [Google Scholar] [CrossRef]
- Isa, S.M.; Nico, G.; Permana, M. Indobert for Indonesian fake news detection. ICIC Express Lett. 2022, 16, 289–297. [Google Scholar]
- Szczepański, M.; Pawlicki, M.; Kozik, R.; Choraś, M. New explainability method for BERT-based model in fake news detection. Sci. Rep. 2021, 11, 23705. [Google Scholar] [CrossRef] [PubMed]
- Palani, B.; Elango, S.; Viswanathan K, V. CB-Fake: A multimodal deep learning framework for automatic fake news detection using capsule neural network and BERT. Multimed. Tools Appl. 2022, 81, 5587–5620. [Google Scholar] [CrossRef] [PubMed]
- Rai, N.; Kumar, D.; Kaushik, N.; Raj, C.; Ali, A. Fake News Classification using transformer based enhanced LSTM and BERT. Int. J. Cogn. Comput. Eng. 2022, 3, 98–105. [Google Scholar] [CrossRef]
- Gaudreault, J.G.; Branco, P.; Gama, J. An analysis of performance metrics for imbalanced classification. In Proceedings of the International Conference on Discovery Science, Virtual, 11–13 October 2021; pp. 67–77. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Year | Model | Covered Multi-Domain? |
|---|---|---|---|
| [11] | 2023 | BiLSTM, Hybrid CNN+RNN, CNN, C-LSTM, and BERT | No |
| [42] | 2023 | BERT+LSTM model for text content analysis GAT for modeling social network features | No |
| [43] | 2023 | BERT | No |
| [44] | 2023 | BERT + LightGBM | No |
| [45] | 2023 | SBERT, RoBERTa, and mBERT | No |
| [46] | 2023 | Hybrid ensemble learning model: BERT for text classification tasks Ensemble learning models, including Voting Regressor and Boosting Ensemble | No |
| [47] | 2023 | CT-BERT with BiGRU | No |
| [48] | 2023 | BERT, LSTM, BiLSTM, and CNN-BiLSTM | No |
| [49] | 2023 | DistilBERT and RoBERTa | No |
| [50] | 2023 | hybrid model combining LSTM and BERT with GloVe embeddings | No |
| [51] | 2023 | TF-IDF N-gram, BERT, GloVe, and CNN | No |
| [52] | 2022 | Arabic-BERT, ARBERT, and QaribBert | No |
| [53] | 2022 | BERT, XLNet, RoBERTa, and Longformer | No |
| [34] | 2022 | BERT with Reinforcement Learning | Yes Gossip (Social) and Political |
| [54] | 2022 | BERT | No |
| [55] | 2022 | BART and RoBERTa | No |
| [12] | 2021 | FakeBERT: Combination of BERT and 1d-CNN | Yes Social and Political |
| [56] | 2021 | ALBERT, BERT, RoBERTa, XLNet, and DistilBERT | No |
| [57] | 2021 | BERT | Yes Political, Social, and Health |
| Dataset | Domain | True | Fake |
|---|---|---|---|
| FA-KES | Crime | 426 | 378 |
| Snopes | Crime | 195 | 120 |
| COVID-FNIR | Health | 3795 | 3793 |
| COVID-Claims | Health | 1591 | 1230 |
| COVID-FN | Health | 2061 | 1058 |
| Pheme | Politics | 5089 | 1335 |
| Liar | Politics | 7176 | 5669 |
| ISOT | Politics | 23,481 | 21,417 |
| Politifact | Politics | 11,760 | 9392 |
| FakeNews | Politics | 10,413 | 10,387 |
| Climate | Science | 654 | 253 |
| ISOT-small (Science) | Science | 1000 | 1000 |
| GossipCop | Social | 16,817 | 5323 |
| ISOT-small (Social) | Social | 1000 | 1000 |
| Metric | Formula | Evaluation Focus |
|---|---|---|
| Accuracy | The proportion of correctly predicted positive and negative instances out of the total instances. | |
| Precision | Measures the positive patterns that are correctly predicted from the total predicted patterns in a positive class. | |
| Recall | The proportion of actual positive instances that were correctly predicted by the model. | |
| F1-Score | The harmonic mean of precision and recall, balancing both metrics. | |
| Geometric-mean (G-Mean) | The geometric mean of recall for each class, focusing on the balance between classification performance across classes. |
| Model | Average Accuracy | Training Time |
|---|---|---|
| albert-base-v2 | 95.8% | 724.1373889 |
| bert-base-uncased | 92.9% | 1933.898181 |
| distilbert-base-uncased | 96.8% | 96.21049619 |
| distilbert-base-uncased-finetuned-sst-2-english | 91.8% | 220.6201028 |
| roberta-base | 98.6% | 1545.978703 |
| Model | Crime | Health | Politics | Science | Social |
|---|---|---|---|---|---|
| albert-base-v2 | 61.7% | 84.8% | 67.8% | 75.3% | 84.2% |
| bert-base-uncased | 61.3% | 87.5% | 87.8% | 74.7% | 84.7% |
| distilbert-base-uncased | 60.1% | 88.3% | 68.5% | 77.7% | 95.6% |
| distilbert-base-uncased-finetuned-sst-2-english | 68.8% | 86.2% | 61.3% | 71.6% | 84.5% |
| roberta-base | 56.9% | 87.6% | 71.8% | 80.2% | 88.7% |
| bert-base-cased | 61.9% | 87.1% | 69.6% | 76.4% | 84.7% |
| Testing Dataset | Precision | Recall | F1-Score | Accuracy | G-Mean |
|---|---|---|---|---|---|
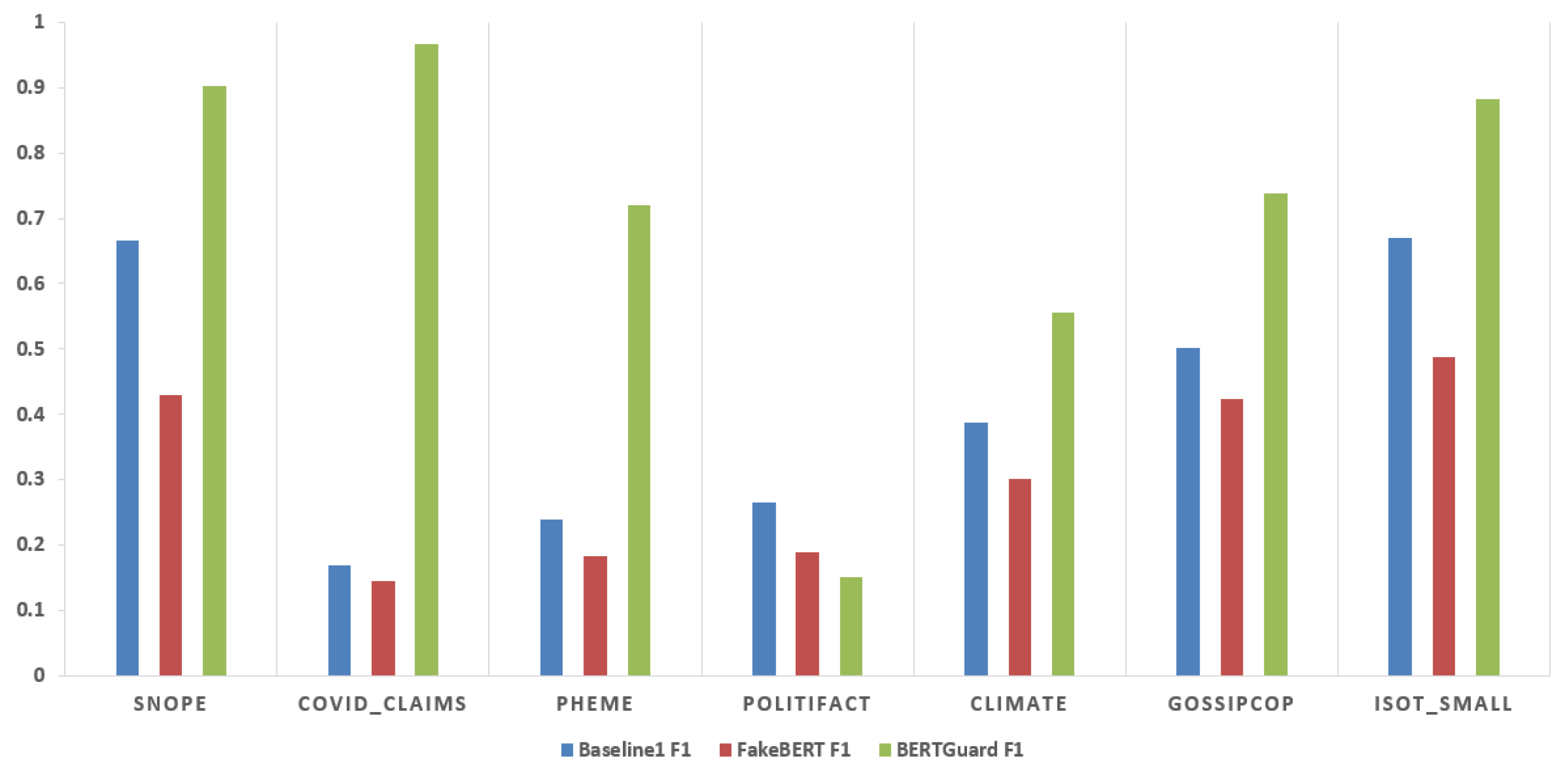
| Snope | 0.583011583 | 0.774358974 | 0.665198238 | 0.517460317 | 0.671907919 |
| COVID-Claims | 0.224425887 | 0.135135135 | 0.168693605 | 0.246979389 | 0.174148852 |
| Pheme | 0.313032887 | 0.192509363 | 0.238404453 | 0.744396015 | 0.245482712 |
| Politifact | 0.486368313 | 0.18228263 | 0.265180199 | 0.49520736 | 0.297752406 |
| Climate | 0.349206349 | 0.434782609 | 0.387323944 | 0.61631753 | 0.389652213 |
| GossipCop | 0.378611058 | 0.743565658 | 0.501743044 | 0.644941283 | 0.530586638 |
| ISOT-small | 0.581487556 | 0.789125069 | 0.669578551 | 0.556974212 | 0.677396788 |
| Architecture | Precision | Recall | F1-Score | Accuracy |
|---|---|---|---|---|
| BERTGuard (Domain-Aware) | 82% | 68% | 70% | 82% |
| Baseline 1 (No Domains) | 42% | 46% | 41% | 55% |
| Baseline 2 (FakeBERT) | 32% | 34% | 31% | 38% |
| Testing Dataset | Precision | Recall | F1-Score | Accuracy | G-Mean |
|---|---|---|---|---|---|
| Snopes | 0.837719298 | 0.979487179 | 0.903073286 | 0.86984127 | 0.905834043 |
| COVID-Claims | 0.956869994 | 0.976115651 | 0.966397013 | 0.961620469 | 0.966444916 |
| Pheme | 0.847560976 | 0.624719101 | 0.71927555 | 0.89866127 | 0.727658939 |
| Politifact | 0.800490597 | 0.083248299 | 0.150812601 | 0.478772693 | 0.258146239 |
| Climate | 0.534798535 | 0.577075099 | 0.55513308 | 0.742006615 | 0.555534803 |
| GossipCop | 0.835781991 | 0.66259628 | 0.739180551 | 0.887579042 | 0.744168017 |
| ISOT-small | 0.898968008 | 0.868 | 0.883240223 | 0.8835 | 0.883362106 |
| Strategy | Precision | Recall | F1-Score | Accuracy |
|---|---|---|---|---|
| BERTGuard | ||||
| No balancing | 82% | 68% | 70% | 82% |
| Random oversampling | 81% | 69% | 71% | 82% |
| Random undersampling | 79% | 61% | 65% | 68% |
| Adjusting class weights | 87% | 68% | 73% | 78% |
| Baseline 1 | ||||
| No balancing | 42% | 46% | 41% | 55% |
| Random oversampling | 46% | 48% | 45% | 52% |
| Random undersampling | 36% | 41% | 37% | 46% |
| Adjusting class weights | 62% | 51% | 55% | 56% |
| FakeBERT (Baseline 2) | ||||
| No balancing | 32% | 34% | 31% | 38% |
| Random oversampling | 46% | 48% | 45% | 52% |
| Random undersampling | 36% | 41% | 37% | 46% |
| Adjusting class weights | 62% | 51% | 55% | 56% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alnabhan, M.Q.; Branco, P. BERTGuard: Two-Tiered Multi-Domain Fake News Detection with Class Imbalance Mitigation. Big Data Cogn. Comput. 2024, 8, 93. https://doi.org/10.3390/bdcc8080093
Alnabhan MQ, Branco P. BERTGuard: Two-Tiered Multi-Domain Fake News Detection with Class Imbalance Mitigation. Big Data and Cognitive Computing. 2024; 8(8):93. https://doi.org/10.3390/bdcc8080093
Chicago/Turabian StyleAlnabhan, Mohammad Q., and Paula Branco. 2024. "BERTGuard: Two-Tiered Multi-Domain Fake News Detection with Class Imbalance Mitigation" Big Data and Cognitive Computing 8, no. 8: 93. https://doi.org/10.3390/bdcc8080093
APA StyleAlnabhan, M. Q., & Branco, P. (2024). BERTGuard: Two-Tiered Multi-Domain Fake News Detection with Class Imbalance Mitigation. Big Data and Cognitive Computing, 8(8), 93. https://doi.org/10.3390/bdcc8080093