
Comparative Study of Filtering Methods for Scientific Research Article Recommendations

 ,
, 
 , , and
, , and
Abstract
1. Introduction
- Classical Classification [9]: This widely known classification divides recommendation systems into three main methods (which will be discussed in detail throughout this article):
- –
- –
- –
- Hybrid filtering: This method combines both CF and CB techniques to capitalize on the strengths of each, resulting in more precise recommendations.
- Rao and Talwar’s Classification [15]: This method expands on classical classification by introducing additional categories and categorizing systems based on the source of information used. In addition to the collaborative filtering, content-based filtering and hybrid filtering, we find:
- –
- Demographic Filtering [16]: This method uses demographic information about users to make recommendations.
- –
- Knowledge-Based Filtering [17]: This method uses specific domain knowledge and user requirements to recommend items.
- –
- Community Filtering: Also called social RSs [18], this method enhances personalized recommendations by incorporating social relationships. However, the impact of social relationships on recommendation accuracy in niche domains is not well understood, and methods often ignore implicit social influences and their evolution over time. Key research areas include the influence of community interactions, best practices for integrating community data, balancing explicit and implicit social influences, and maintaining scalability while preserving social relationship information.
2. Related Works
2.1. Collaborative Filtering (CF)
2.1.1. Memory-Based
2.1.2. Model-Based
- Bayesian Networks [68]:These probabilistic models represent dependencies among variables (users and items) and use these relationships to make predictions.
- Clustering [69]: Users or items are grouped into clusters based on their similarities, and recommendations are made based on the preferences of the cluster members.
- Markov Decision Processe [70]: These models consider the sequences of user interactions and make recommendations by predicting the next item in a user’s sequence.
- Machine Learning Techniques [71]: Algorithms such as neural networks, decision trees, and support vector machines can be trained on user-item interaction data to predict user preferences.
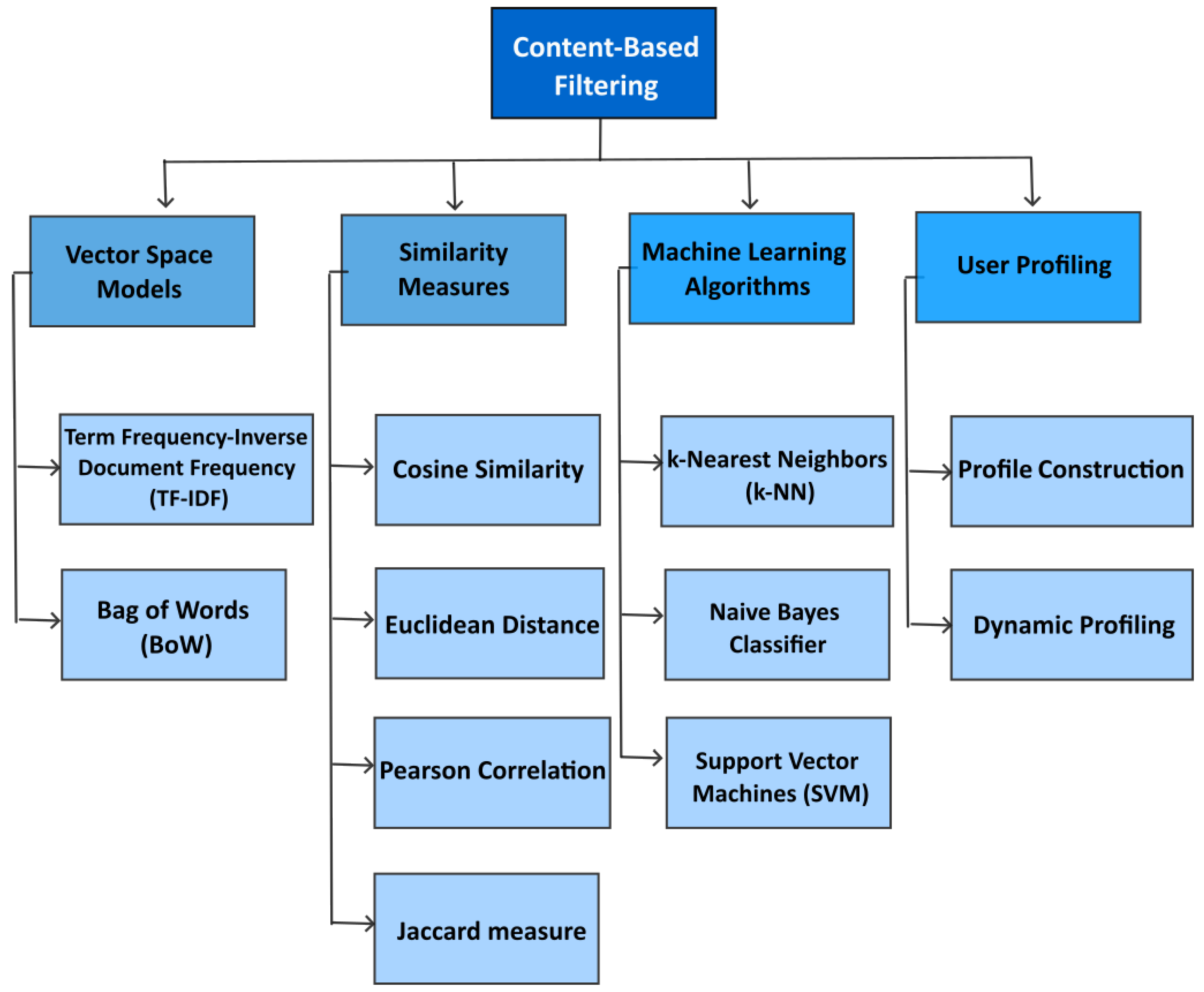
2.2. Content-Based Filtering (CB)
2.3. Hybrid Recommendation Systems
- Weighted: Assigns weights to each of the methods, combining their scores into a single recommendation score based on the weighted sum.
- Switching: Alternates between different recommendation methods depending on specific criteria like user type, item characteristics, or the recommendation context.
- Mixed: Independently generates recommendations using various methods and then merges the results into a unified list presented to the user.
- Cascade: Uses one recommendation method to produce an initial list and refines it with another method. For example, CF can create a broad list, which is then fine-tuned by content-based filtering.
- Feature augmentation: Enhances one recommendation method by incorporating additional features derived from another. For example, user similarity scores from CF can improve content-based filtering.
- Meta-level: Utilizes the model output from one recommendation technique as input features for another. For example, the results of a content-based model can serve as features in a CF model.
3. Proposed Methods
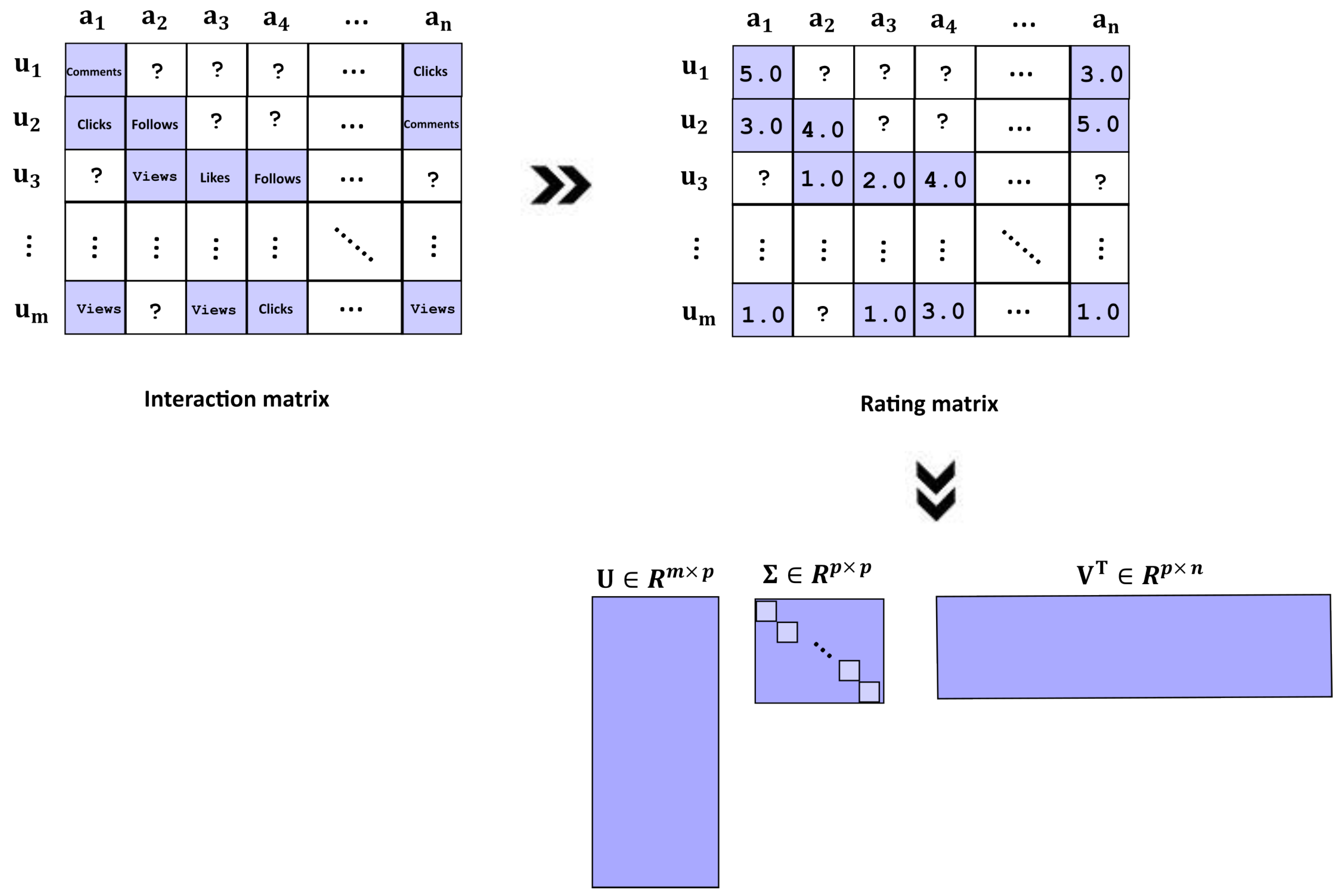
- Collaborative Filtering: For this method, we employed a model-based approach, specifically using the singular value decomposition (SVD) algorithm [73], as it is a robust and reliable choice for building high-quality CF recommendation systems. The SVD algorithm (see Figure 2) decomposes the user-item interaction Y matrix into three matrices , , and that capture the latent factors representing users and items.where U and V are the orthogonal matrices and is the singular orthogonal matrix with non-negative elements and contains all the singular values of Y. This decomposition allows the model to make predictions by approximating the original interaction matrix using these latent factors, thereby improving the accuracy and scalability of the recommendations.
- Content-Based Filtering: Since the task involves recommending scientific articles, we decided to use common techniques from the fields of information retrieval and text mining. Specifically, we used Term Frequency–Inverse Document Frequency (TF-IDF) [74] to convert text data into numerical vectors and extract features, where each word is represented by a position in the vector, and the value indicates the relevance of that word to a particular article. We calculate the similarity between the articles because all the elements will be represented in the same vector space model. The weight of term t in document d is given by:where is the number of occurrences of t in document d, is the number of articles containing the term t, and N is the total number of articles in the corpus. We used cosine similarity to measure the similarity between the vectors generated by TF-IDF.
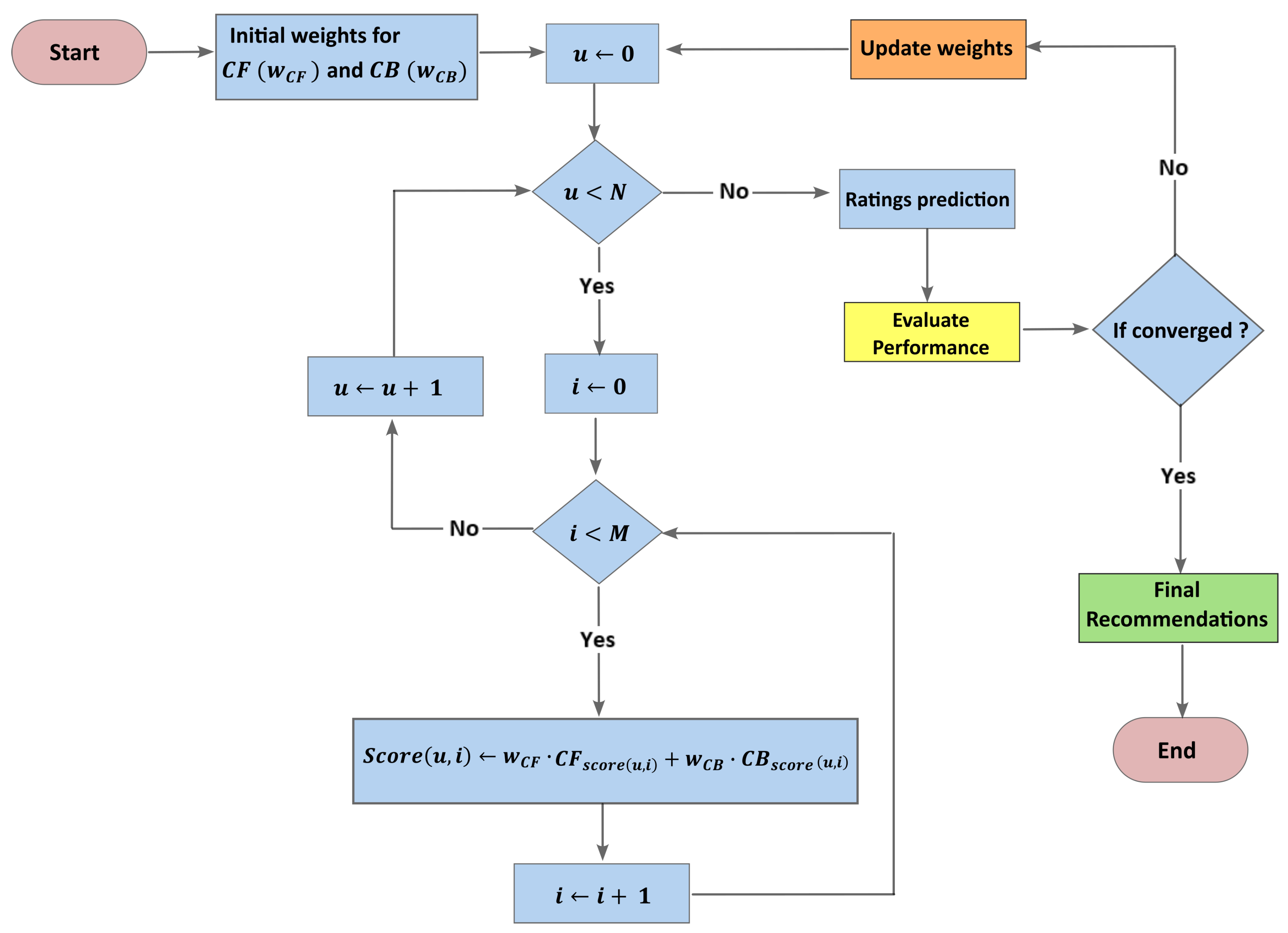
- Hybrid Filtering: Concerning this approach, we used the dynamic weighted hybridization method (see the algorithm flowchart in Figure 3). This technique combines the recommendations from both CF and CB by assigning different weights ( and ), we can adjust them based on performance evaluation until convergence, resulting in final recommendations. This flexibility is particularly useful when dealing with diverse datasets, as it enables us to tailor the hybrid model to better suit the specific characteristics of the data. We update weights using the gradient of the loss function as follows:where is the actual rating of user u to item i, and is the combined score for user u and item i generated by the hybrid RS.
4. Experimental Section
4.1. Experimental Settings and Datasets
4.2. Metrics of Evaluation
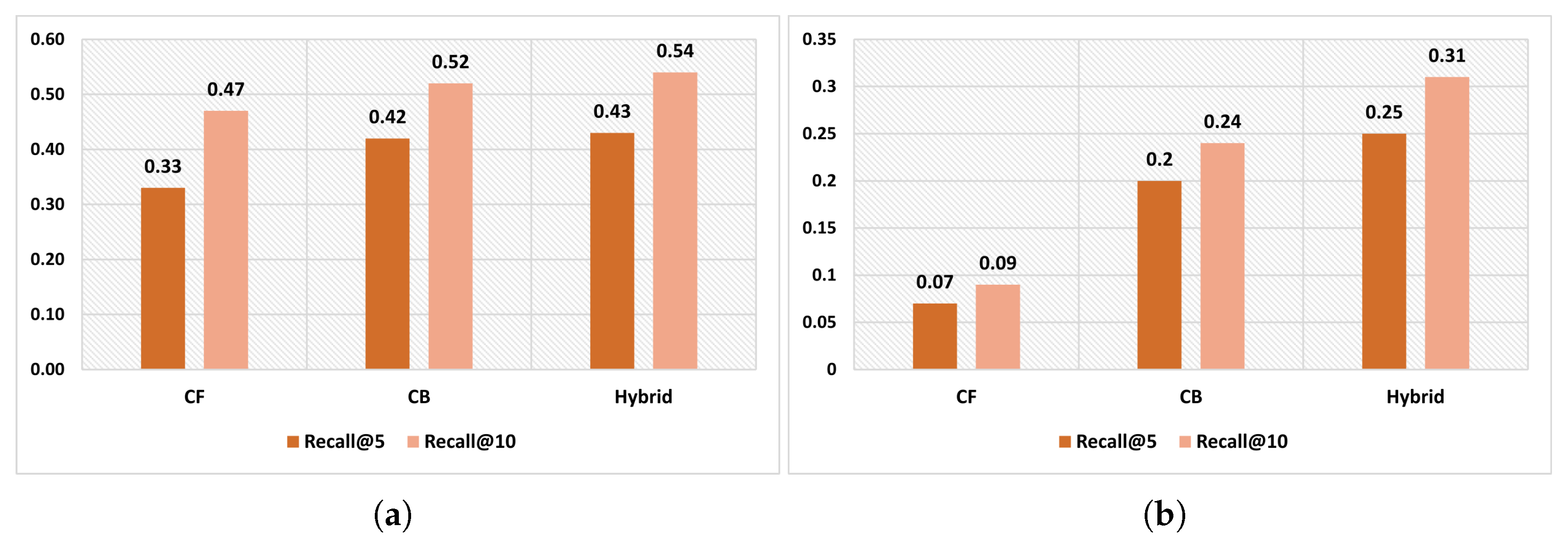
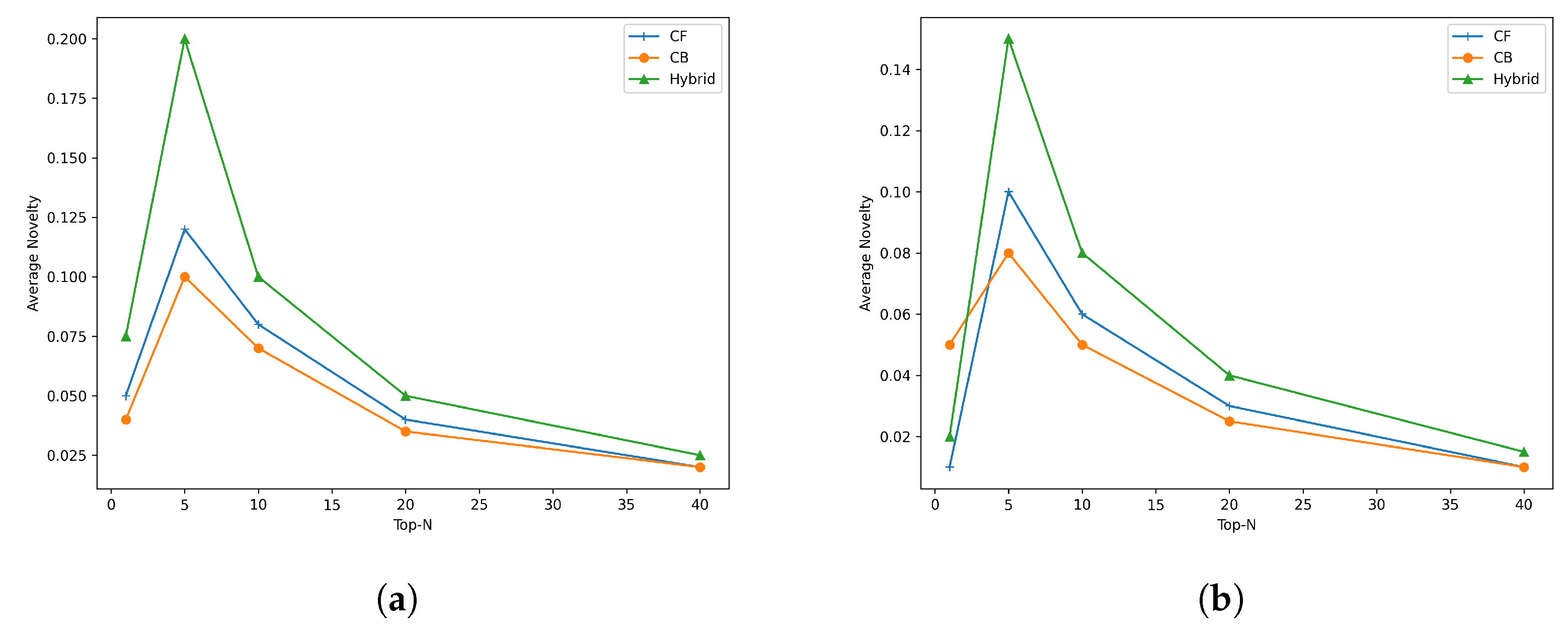
4.3. Results
4.4. Discussion
- Switching and Cascade techniques: NDCG@5 values range from 0.180 to 0.293, showing varying performance across systems.
- Traditional Weighted technique: NDCG@5 values range from 0.183 to 0.305, indicating performance variability.
- Dynamic Weighted technique: Highest NDCG@5 values ranging from 0.200 to 0.312, suggesting superior effectiveness.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- National Science Foundation. Science and Engineering Indicators 2020; Technical Report NSB-2020-6; National Science Board: Alexandria, VA, USA, 2020. [Google Scholar]
- Elsevier Scopus. Scopus Database Statistics; Scopus Database; Elsevier: Amsterdam, The Netherlands, 2022. [Google Scholar]
- Lee, J.; Lee, K.; Kim, J.G. Personalized academic research paper recommendation system. arXiv 2013, arXiv:1304.5457. [Google Scholar]
- Bai, X.; Wang, M.; Lee, I.; Yang, Z.; Kong, X.; Xia, F. Scientific paper recommendation: A survey. IEEE Access 2019, 7, 9324–9339. [Google Scholar] [CrossRef]
- Beel, J.; Langer, S. A comparison of offline evaluations, online evaluations, and user studies in the context of research-paper recommender systems. In Proceedings of the Research and Advanced Technology for Digital Libraries: 19th International Conference on Theory and Practice of Digital Libraries, TPDL 2015, Poznań, Poland, 14–18 September 2015; Springer: Cham, Switzerland, 2015; pp. 153–168. [Google Scholar]
- Sakib, N.; Ahmad, R.B.; Ahsan, M.; Based, M.A.; Haruna, K.; Haider, J.; Gurusamy, S. A hybrid personalized scientific paper recommendation approach integrating public contextual metadata. IEEE Access 2021, 9, 83080–83091. [Google Scholar] [CrossRef]
- Guo, G.; Chen, B.; Zhang, X.; Liu, Z.; Dong, Z.; He, X. Leveraging title-abstract attentive semantics for paper recommendation. In Proceedings of the AAAI conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 67–74. [Google Scholar]
- Alzoghbi, A.; Arrascue Ayala, V.A.; Fischer, P.M.; Lausen, G. Pubrec: Recommending publications based on publicly available meta-data. In Proceedings of the LWLA 2015 Workshops: KDML, FGWM, IR, and FGDB, Trier, Germany, 7–9 October 2015. [Google Scholar]
- Adomavicius, G.; Tuzhilin, A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Najmani, K.; Benlahmar, E.H.; Sael, N.; Zellou, A. Collaborative filtering approach: A review of recent research. In Proceedings of the International Conference on Advanced Intelligent Systems for Sustainable Development, Tangier, Morocco, 21–26 December 2020; Springer: Cham, Switzerland, 2020; pp. 151–163. [Google Scholar]
- Schafer, J.B.; Frankowski, D.; Herlocker, J.; Sen, S. Collaborative filtering recommender systems. In The Adaptive Web: Methods and Strategies of Web Personalization; Springer: Berlin/Heidelberg, Germany, 2007; pp. 291–324. [Google Scholar]
- Lops, P.; Jannach, D.; Musto, C.; Bogers, T.; Koolen, M. Trends in content-based recommendation: Preface to the special issue on Recommender systems based on rich item descriptions. User Model. User-Adapt. Interact. 2019, 29, 239–249. [Google Scholar] [CrossRef]
- Lops, P.; De Gemmis, M.; Semeraro, G. Content-based recommender systems: State of the art and trends. Recommender Systems Handbook; Springer: Boston, MA, USA, 2011; pp. 73–105. [Google Scholar]
- Pazzani, M.J.; Billsus, D. Content-based recommendation systems. In The Adaptive Web: Methods and Strategies of Web Personalization; Springer: Berlin/Heidelberg, Germany, 2007; pp. 325–341. [Google Scholar]
- Rao, K.N. Application domain and functional classification of recommender systems—A survey. DESIDOC J. Libr. Inf. Technol. 2008, 28, 17. [Google Scholar]
- Lahoud, C.; Moussa, S.; Obeid, C.; Khoury, H.E.; Champin, P.A. A comparative analysis of different recommender systems for university major and career domain guidance. Educ. Inf. Technol. 2023, 28, 8733–8759. [Google Scholar] [CrossRef]
- Uta, M.; Felfernig, A.; Le, V.M.; Tran, T.N.T.; Garber, D.; Lubos, S.; Burgstaller, T. Knowledge-based recommender systems: Overview and research directions. Front. Big Data 2024, 7, 1304439. [Google Scholar] [CrossRef]
- Shokeen, J.; Rana, C. A study on features of social recommender systems. Artif. Intell. Rev. 2020, 53, 965–988. [Google Scholar] [CrossRef]
- Sparck Jones, K. A statistical interpretation of term specificity and its application in retrieval. J. Doc. 1972, 28, 11–21. [Google Scholar] [CrossRef]
- Salton, G.; Fox, E.A.; Wu, H. Extended boolean information retrieval. Commun. ACM 1983, 26, 1022–1036. [Google Scholar] [CrossRef]
- Belkin, N.J.; Croft, W.B. Information filtering and information retrieval: Two sides of the same coin? Commun. ACM 1992, 35, 29–38. [Google Scholar] [CrossRef]
- Goldberg, D.; Nichols, D.; Oki, B.M.; Terry, D. Using collaborative filtering to weave an information tapestry. Commun. ACM 1992, 35, 61–70. [Google Scholar] [CrossRef]
- Resnick, P.; Iacovou, N.; Suchak, M.; Bergstrom, P.; Riedl, J. Grouplens: An open architecture for collaborative filtering of netnews. In Proceedings of the 1994 ACM Conference on Computer Supported Cooperative Work, New York, NY, USA, 22–26 October 1994; pp. 175–186. [Google Scholar]
- Shardanand, U.; Maes, P. Social information filtering: Algorithms for automating “word of mouth”. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 7–11 May 1995; pp. 210–217. [Google Scholar]
- Hill, W.; Stead, L.; Rosenstein, M.; Furnas, G. Recommending and evaluating choices in a virtual community of use. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 7–11 May 1995; pp. 194–201. [Google Scholar]
- Konstan, J.A.; Riedl, J. Recommender systems: From algorithms to user experience. User Model. User-Adapt. Interact. 2012, 22, 101–123. [Google Scholar] [CrossRef]
- Schafer, J.B.; Konstan, J.; Riedl, J. Recommender systems in e-commerce. In Proceedings of the 1st ACM Conference on Electronic Commerce, Denver, CO, USA, 3–5 November 1999; pp. 158–166. [Google Scholar]
- Harper, F.M.; Konstan, J.A. The movielens datasets: History and context. Acm Trans. Interact. Intell. Syst. (Tiis) 2015, 5, 1–19. [Google Scholar] [CrossRef]
- Breese, J.S.; Heckerman, D.; Kadie, C. Empirical analysis of predictive algorithms for collaborative filtering. arXiv 2013, arXiv:1301.7363. [Google Scholar]
- Herlocker, J.L.; Konstan, J.A.; Borchers, A.; Riedl, J. An algorithmic framework for performing collaborative filtering. In Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Berkeley, CA, USA, 15–19 August 1999; pp. 230–237. [Google Scholar]
- Linden, G.; Smith, B.; York, J. Amazon. com recommendations: Item-to-item collaborative filtering. IEEE Internet Comput. 2003, 7, 76–80. [Google Scholar] [CrossRef]
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. Item-based collaborative filtering recommendation algorithms. In Proceedings of the 10th International Conference on World Wide Web, Hong Kong, China, 1–5 May 2001; pp. 285–295. [Google Scholar]
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J.T. Application of Dimensionality Reduction in Recommender System—A Case Study; Technical Report No. 00-043; University of Minnesota: Minneapolis, MN, USA, 2000. [Google Scholar]
- Koren, Y. Factorization meets the neighborhood: A multifaceted collaborative filtering model. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 426–434. [Google Scholar]
- Koren, Y. Collaborative filtering with temporal dynamics. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 447–456. [Google Scholar]
- McNee, S.M.; Riedl, J.; Konstan, J.A. Being accurate is not enough: How accuracy metrics have hurt recommender systems. In Proceedings of the CHI’06 Extended Abstracts on Human Factors in Computing Systems, Montreal, QC, Canada, 22–27 April 2006; pp. 1097–1101. [Google Scholar]
- Massa, P.; Avesani, P. Trust-aware recommender systems. In Proceedings of the 2007 ACM Conference on Recommender Systems, Minneapolis, MN, USA, 19–20 October 2007; pp. 17–24. [Google Scholar]
- Richardson, M.; Dominowska, E.; Ragno, R. Predicting clicks: Estimating the click-through rate for new ads. In Proceedings of the 16th International Conference on World Wide Web, Banff, Canada, 8–12 May 2007; pp. 521–530. [Google Scholar]
- Rendle, S. Factorization machines. In Proceedings of the 2010 IEEE International Conference on Data Mining, Sydney, Australia, 13–17 December 2010; IEEE: New York, NY, USA, 2010; pp. 995–1000. [Google Scholar]
- Juan, Y.; Zhuang, Y.; Chin, W.S.; Lin, C.J. Field-aware factorization machines for CTR prediction. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 43–50. [Google Scholar]
- Pu, P.; Chen, L.; Hu, R. A user-centric evaluation framework for recommender systems. In Proceedings of the Fifth ACM Conference on Recommender Systems, Chicago, IL, USA, 23–27 October 2011; pp. 157–164. [Google Scholar]
- Pu, P.; Chen, L.; Hu, R. Evaluating recommender systems from the user’s perspective: Survey of the state of the art. User Model. User-Adapt. Interact. 2012, 22, 317–355. [Google Scholar] [CrossRef]
- Cheng, H.T.; Koc, L.; Harmsen, J.; Shaked, T.; Chandra, T.; Aradhye, H.; Anderson, G.; Corrado, G.; Chai, W.; Ispir, M.; et al. Wide & deep learning for recommender systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016; pp. 7–10. [Google Scholar]
- Guo, H.; Tang, R.; Ye, Y.; Li, Z.; He, X.; Dong, Z. Deepfm: An end-to-end wide & deep learning framework for CTR prediction. arXiv 2018, arXiv:1804.04950. [Google Scholar]
- Covington, P.; Adams, J.; Sargin, E. Deep neural networks for youtube recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 191–198. [Google Scholar]
- Zhu, J.; Liu, J.; Yang, S.; Zhang, Q.; He, X. Fuxictr: An open benchmark for click-through rate prediction. arXiv 2020, arXiv:2009.05794. [Google Scholar]
- Ferrari Dacrema, M.; Cremonesi, P.; Jannach, D. Are we really making much progress? A worrying analysis of recent neural recommendation approaches. In Proceedings of the 13th ACM Conference on Recommender Systems, Copenhagen, Denmark, 16–20 September 2019; pp. 101–109. [Google Scholar]
- Lin, J. The neural hype and comparisons against weak baselines. In ACM SIGIR Forum; ACM: New York, NY, USA, 2019; Volume 52, pp. 40–51. [Google Scholar]
- Dong, Z.; Zhu, H.; Cheng, P.; Feng, X.; Cai, G.; He, X.; Xu, J.; Wen, J. Counterfactual learning for recommender system. In Proceedings of the 14th ACM Conference on Recommender Systems, Virtual, 22–26 September 2020; pp. 568–569. [Google Scholar]
- Yuan, B.; Hsia, J.Y.; Yang, M.Y.; Zhu, H.; Chang, C.Y.; Dong, Z.; Lin, C.J. Improving ad click prediction by considering non-displayed events. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 329–338. [Google Scholar]
- Verma, S.; Dickerson, J.; Hines, K. Counterfactual explanations for machine learning: A review. arXiv 2020, arXiv:2010.10596. [Google Scholar]
- Collins, A.; Beel, J. Document embeddings vs. keyphrases vs. terms for recommender systems: A large-scale online evaluation. In In Proceedings of the 2019 ACM/IEEE Joint Conference on Digital Libraries (JCDL), Urbana-Champaign, IL, USA, 2–6 June 2019; IEEE: New York, NY, USA, 2019; pp. 130–133. [Google Scholar]
- Chen, J.; Ban, Z. Academic paper recommendation based on clustering and pattern matching. In Proceedings of the Artificial Intelligence: Second CCF International Conference, ICAI 2019, Xuzhou, China, 22–23 August 2019; Springer: Singapore, 2019; pp. 171–182. [Google Scholar]
- Ali, Z.; Qi, G.; Muhammad, K.; Ali, B.; Abro, W.A. Paper recommendation based on heterogeneous network embedding. Knowl.-Based Syst. 2020, 210, 106438. [Google Scholar] [CrossRef]
- Du, N.; Guo, J.; Wu, C.Q.; Hou, A.; Zhao, Z.; Gan, D. Recommendation of academic papers based on heterogeneous information networks. In Proceedings of the 2020 IEEE/ACS 17th International Conference on Computer Systems and Applications (AICCSA), Antalya, Turkey, 2–5 November 2020; IEEE: New York, NY, USA, 2020; pp. 1–6. [Google Scholar]
- Nishioka, C.; Hauke, J.; Scherp, A. Influence of tweets and diversification on serendipitous research paper recommender systems. Peerj Comput. Sci. 2020, 6, e273. [Google Scholar] [CrossRef] [PubMed]
- Rahdari, B.; Brusilovsky, P.; Thaker, K.; Barria-Pineda, J. Knowledge-driven wikipedia article recommendation for electronic textbooks. In Proceedings of the European Conference on Technology Enhanced Learning, Heidelberg, Germany, 14–18 September 2020; Springer: Cham, Switzerland, 2020; pp. 363–368. [Google Scholar]
- Wang, X.; Xu, H.; Tan, W.; Wang, Z.; Xu, X. Scholarly paper recommendation via related path analysis in knowledge graph. In Proceedings of the 2020 International Conference on Service Science (ICSS), Xining, China, 24–26 August 2020; IEEE: New York, NY, USA, 2020; pp. 36–43. [Google Scholar]
- Márk, B. Graph Neural Networks for Article Recommendation Based on Implicit User Feedback and Content. Master’s Thesis, KTH Royal Institute of Technology, Stockholm, Sweden, 2021. [Google Scholar]
- Chaudhuri, A.; Sinhababu, N.; Sarma, M.; Samanta, D. Hidden features identification for designing an efficient research article recommendation system. Int. J. Digit. Libr. 2021, 22, 233–249. [Google Scholar] [CrossRef]
- Kreutz, C.K.; Schenkel, R. Scientific paper recommendation systems: A literature review of recent publications. Int. J. Digit. Libr. 2022, 23, 335–369. [Google Scholar] [CrossRef]
- Aymen, A.T.M.; Imène, S. Scientific Paper Recommender Systems: A Review. In Artificial Intelligence and Heuristics for Smart Energy Efficiency in Smart Cities: Case Study: Tipasa, Algeria; Springer: Cham, Switzerland, 2022; pp. 896–906. [Google Scholar]
- Zhang, Z.; Patra, B.G.; Yaseen, A.; Zhu, J.; Sabharwal, R.; Roberts, K.; Cao, T.; Wu, H. Scholarly recommendation systems: A literature survey. Knowl. Inf. Syst. 2023, 65, 4433–4478. [Google Scholar] [CrossRef]
- Papadakis, H.; Papagrigoriou, A.; Panagiotakis, C.; Kosmas, E.; Fragopoulou, P. Collaborative filtering recommender systems taxonomy. Knowl. Inf. Syst. 2022, 64, 35–74. [Google Scholar] [CrossRef]
- Seridi, K.; El Rharras, A. A Comparative Analysis of Memory-Based and Model-Based Collaborative Filtering on Recommender System Implementation. In Proceedings of the International Conference on Smart City Applications, Paris, France, 4–6 October 2023; Springer: Cham, Switzerland, 2023; pp. 75–86. [Google Scholar]
- Zhang, Y. An Introduction to Matrix factorization and Factorization Machines in Recommendation System, and Beyond. arXiv 2022, arXiv:2203.11026. [Google Scholar]
- El Alaoui, D.; Riffi, J.; Aghoutane, B.; Sabri, A.; Yahyaouy, A.; Tairi, H. Collaborative Filtering: Comparative Study Between Matrix Factorization and Neural Network Method. In Proceedings of the Networked Systems: 8th International Conference, NETYS 2020, Marrakech, Morocco, 3–5 June 2020; Springer: Cham, Switzerland, 2021; pp. 361–367. [Google Scholar]
- Shi, K.; Zhang, J.; Fang, L.; Wang, W.; Jing, B. Enhanced Bayesian Personalized Ranking for Robust Hard Negative Sampling in Recommender Systems. arXiv 2024, arXiv:2403.19276. [Google Scholar]
- Beregovskaya, I.; Koroteev, M. Review of Clustering-Based Recommender Systems. arXiv 2021, arXiv:2109.12839. [Google Scholar]
- Gupta, G.; Katarya, R. A study of recommender systems using Markov decision process. In Proceedings of the Second International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 14–15 June 2018; IEEE: New York, NY, USA, 2018; pp. 1279–1283. [Google Scholar]
- Portugal, I.; Alencar, P.; Cowan, D. The use of machine learning algorithms in recommender systems: A systematic review. Expert Syst. Appl. 2018, 97, 205–227. [Google Scholar] [CrossRef]
- Burke, R. Hybrid web recommender systems. In The Adaptive Web: Methods and Strategies of Web Personalization; Springer: Berlin/Heidelberg, Germany, 2007; pp. 377–408. [Google Scholar]
- Lange, K.; Lange, K. Singular value decomposition. In Numerical Analysis for Statisticians; Springer: New York, NY, USA, 2010; pp. 129–142. [Google Scholar]
- Bafna, P.; Pramod, D.; Vaidya, A. Document clustering: TF-IDF approach. In Proceedings of the International Conference on Electrical, Electronics, and Optimization Techniques (ICEEOT), Chennai, India, 3–5 March 2016; IEEE: New York, NY, USA, 2016; pp. 61–66. [Google Scholar]
- Jannach, D.; Lerche, L.; Zanker, M. Recommending based on implicit feedback. In Social Information Access: Systems and Technologies; Springer: Cham, Switzerland, 2018; pp. 510–569. [Google Scholar]
- Van Meteren, R.; Van Someren, M. Using content-based filtering for recommendation. In Proceedings of the Machine Learning in the New Information Age: MLnet/ECML2000 Workshop, Barcelona, Spain, 31 May–2 June 2000; Volume 30, pp. 47–56. [Google Scholar]
- Singh, M. Scalability and sparsity issues in recommender datasets: A survey. Knowl. Inf. Syst. 2020, 62, 1–43. [Google Scholar] [CrossRef]
- Yuan, H.; Hernandez, A.A. User Cold Start Problem in Recommendation Systems: A Systematic Review. IEEE Access 2023, 11, 136958–136977. [Google Scholar] [CrossRef]
- Fayyaz, Z.; Ebrahimian, M.; Nawara, D.; Ibrahim, A.; Kashef, R. Recommendation systems: Algorithms, challenges, metrics, and business opportunities. Appl. Sci. 2020, 10, 7748. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Author(s) | Purpose | Sample and Methods | Key Findings |
|---|---|---|---|---|
| 2019 | Collins and Beel [52] | To evaluate different document embedding methods for paper recommendations | Used Doc2Vec and TF-IDF in Mr. DLib recommender-as-service | Demonstrated the effectiveness of different document embedding approaches for paper recommendations |
| 2019 | Chen and Ban [53] | To develop a user interest clustering model | Applied LDA and pattern equivalence class mining in CPM model | Successfully clustered user interests using topic modeling and pattern mining techniques |
| 2020 | Ali et al. [54] | To create a personalized probabilistic recommendation model | Developed PR-HNE using citations, co-authorships, and topical relevance with SBERT and LDA | Effectively integrated multiple graph information sources with semantic embeddings |
| 2020 | Du et al. [55] | To develop a heterogeneous network-based recommendation system | Created HNPR using random walks on citation and co-author networks | Demonstrated the effectiveness of using heterogeneous network structures for recommendations |
| 2020 | Nishioka et al. [56] | To incorporate users’ recent interests for serendipitous recommendations | Integrated user tweets to capture current interests | Successfully enhanced recommendation serendipity through social media integration |
| 2020 | Rahdari & Brusilovsky [57] | To develop a customizable recommendation system for conference participants | Created a system allowing users to control feature impacts | Showed the benefits of user-controlled feature weighting in recommendations |
| 2020 | Wang et al. [58] | To develop a knowledge-aware recommendation system | Implemented LSTM-based path recurrent network with TF-IDF representations | Successfully mined knowledge graph paths for enhanced recommendations |
| 2021 | Bereczki [59] | To model user–paper interactions in a bipartite graph | Used Word2Vec/BERT embeddings with graph convolution | Demonstrated effective integration of text embeddings with graph-based approaches |
| 2021 | Chaudhuri et al. [60] | To incorporate indirect features for recommendations | Developed Hybrid Topic Model combining LDA and Word2Vec | Successfully utilized keyword diversification and citation analysis for improved recommendations |
| 2022 | Kreutz et al. [61] | To review contemporary paper recommendation systems | Surveyed studies from January 2019 to October 2021 | Provided comprehensive overview of methods, datasets, and challenges |
| 2022 | Aymen et al. [62] | To review academic works on paper recommendations | Analyzed content-based, CF, and hybrid methods | Compared methodologies and identified open issues in the field |
| 2023 | Zhang et al. [63] | To survey scholarly recommendation systems | Reviewed challenges and approaches in scholarly recommendations | Provided insights into broader scholarly recommendation systems |
| Approach | Strengths | Weaknesses |
|---|---|---|
| Collaborative Filtering (CF) |
|
|
| Content-Based (CB) |
|
|
| CI&T Deskdrop | Citeulike-t | |
|---|---|---|
| # of Users | 1895 | 7947 |
| # of Articles | 3122 | 25,975 |
| # of Interactions | 72,312 | 134,860 |
| Sparsity | 7.99% | 99.93% |
| CI&T Deskdrop | Citeulike-t | |||||||
|---|---|---|---|---|---|---|---|---|
| Hybridizing Technique | NDCG@5 | NDCG@10 | Novelty@5 | Novelty@10 | NDCG@5 | NDCG@10 | Novelty@5 | Novelty@10 |
| Switching | 0.293 | 0.287 | 0.180 | 0.090 | 0.225 | 0.215 | 0.125 | 0.065 |
| Cascade | 0.295 | 0.290 | 0.175 | 0.088 | 0.230 | 0.210 | 0.120 | 0.063 |
| Traditional Weighted | 0.305 | 0.300 | 0.183 | 0.094 | 0.240 | 0.230 | 0.138 | 0.074 |
| Dynamic Weighted | 0.312 | 0.308 | 0.200 | 0.100 | 0.250 | 0.240 | 0.150 | 0.080 |
| CI&T Deskdrop | Citeulike-t | |||
|---|---|---|---|---|
| NDCG@5 | NDCG@10 | NDCG@5 | NDCG@10 | |
| Collaborative-filtering(CF) | 0.259 | 0.257 | 0.200 | 0.190 |
| Content based (CB) | 0.289 | 0.290 | 0.230 | 0.220 |
| Hybrid | 0.312 | 0.308 | 0.250 | 0.240 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
El Alaoui, D.; Riffi, J.; Sabri, A.; Aghoutane, B.; Yahyaouy, A.; Tairi, H. Comparative Study of Filtering Methods for Scientific Research Article Recommendations. Big Data Cogn. Comput. 2024, 8, 190. https://doi.org/10.3390/bdcc8120190
El Alaoui D, Riffi J, Sabri A, Aghoutane B, Yahyaouy A, Tairi H. Comparative Study of Filtering Methods for Scientific Research Article Recommendations. Big Data and Cognitive Computing. 2024; 8(12):190. https://doi.org/10.3390/bdcc8120190
Chicago/Turabian StyleEl Alaoui, Driss, Jamal Riffi, Abdelouahed Sabri, Badraddine Aghoutane, Ali Yahyaouy, and Hamid Tairi. 2024. "Comparative Study of Filtering Methods for Scientific Research Article Recommendations" Big Data and Cognitive Computing 8, no. 12: 190. https://doi.org/10.3390/bdcc8120190
APA StyleEl Alaoui, D., Riffi, J., Sabri, A., Aghoutane, B., Yahyaouy, A., & Tairi, H. (2024). Comparative Study of Filtering Methods for Scientific Research Article Recommendations. Big Data and Cognitive Computing, 8(12), 190. https://doi.org/10.3390/bdcc8120190