
Semi-Open Set Object Detection Algorithm Leveraged by Multi-Modal Large Language Models

 ,
,
Abstract
1. Introduction
2. Related Work
2.1. Traditional Object Detection Algorithms
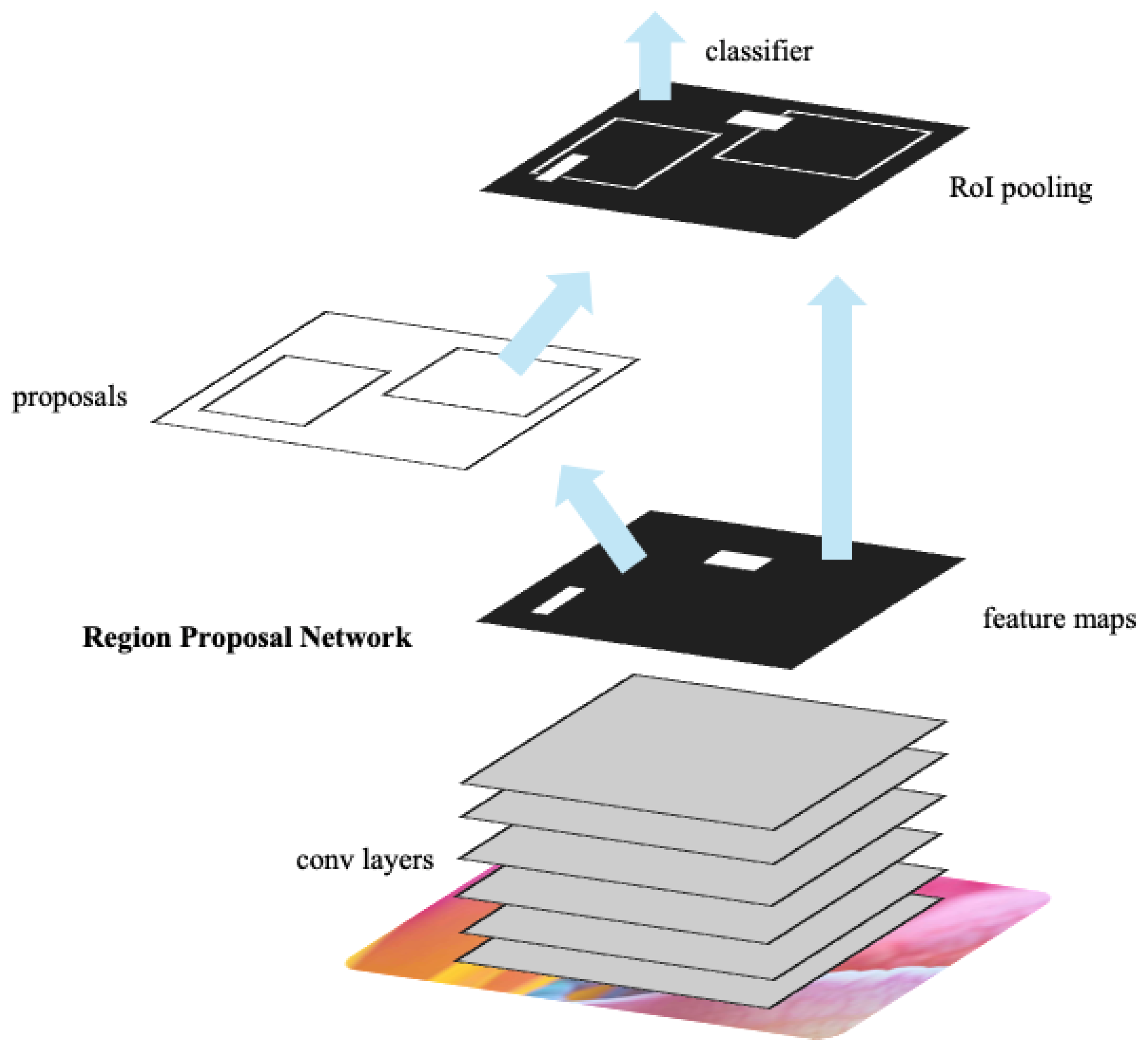
2.2. Deep Learning Object Detection Algorithms
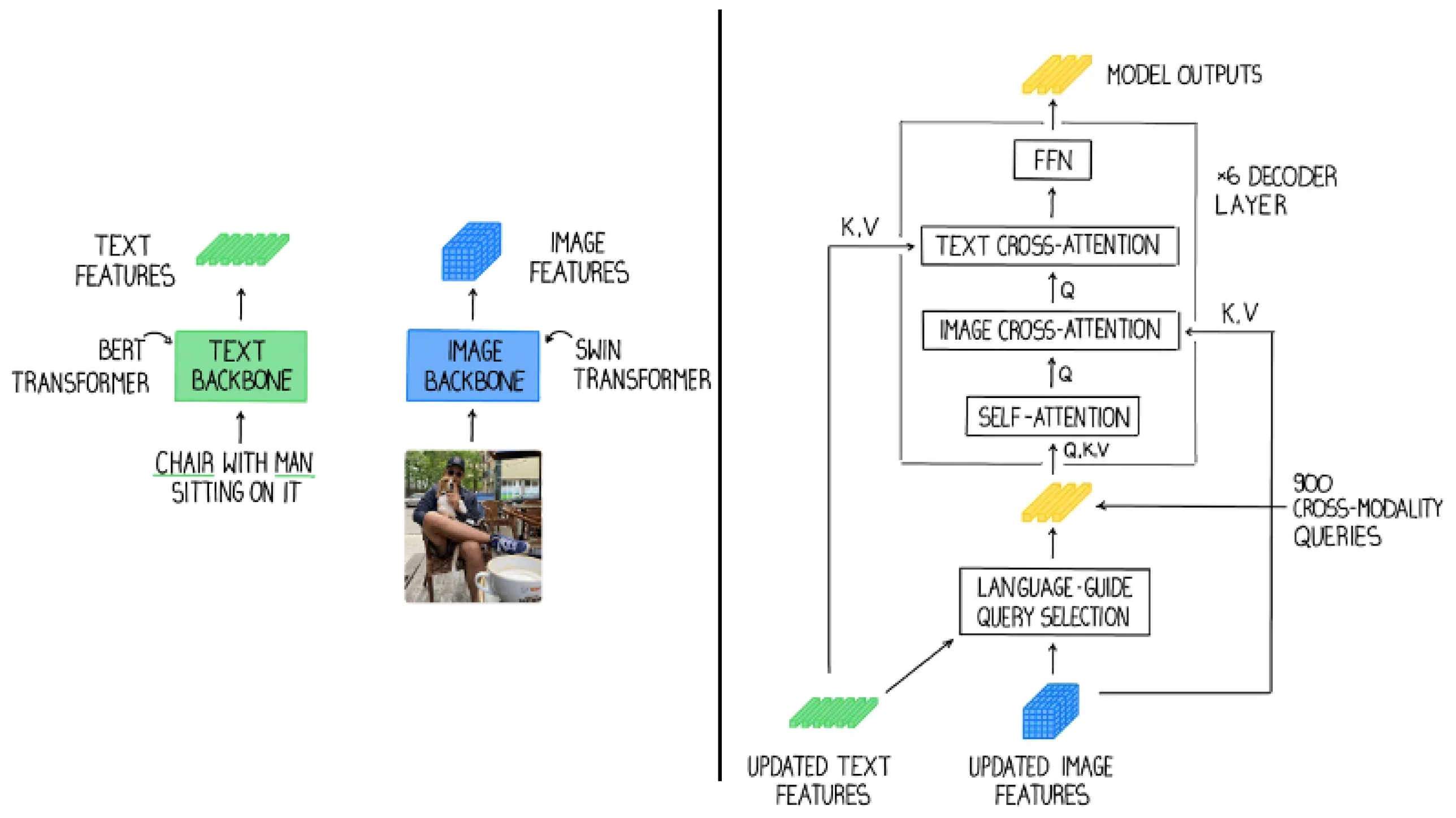
2.3. Open-Set Objection Detection Algorithms
3. Method
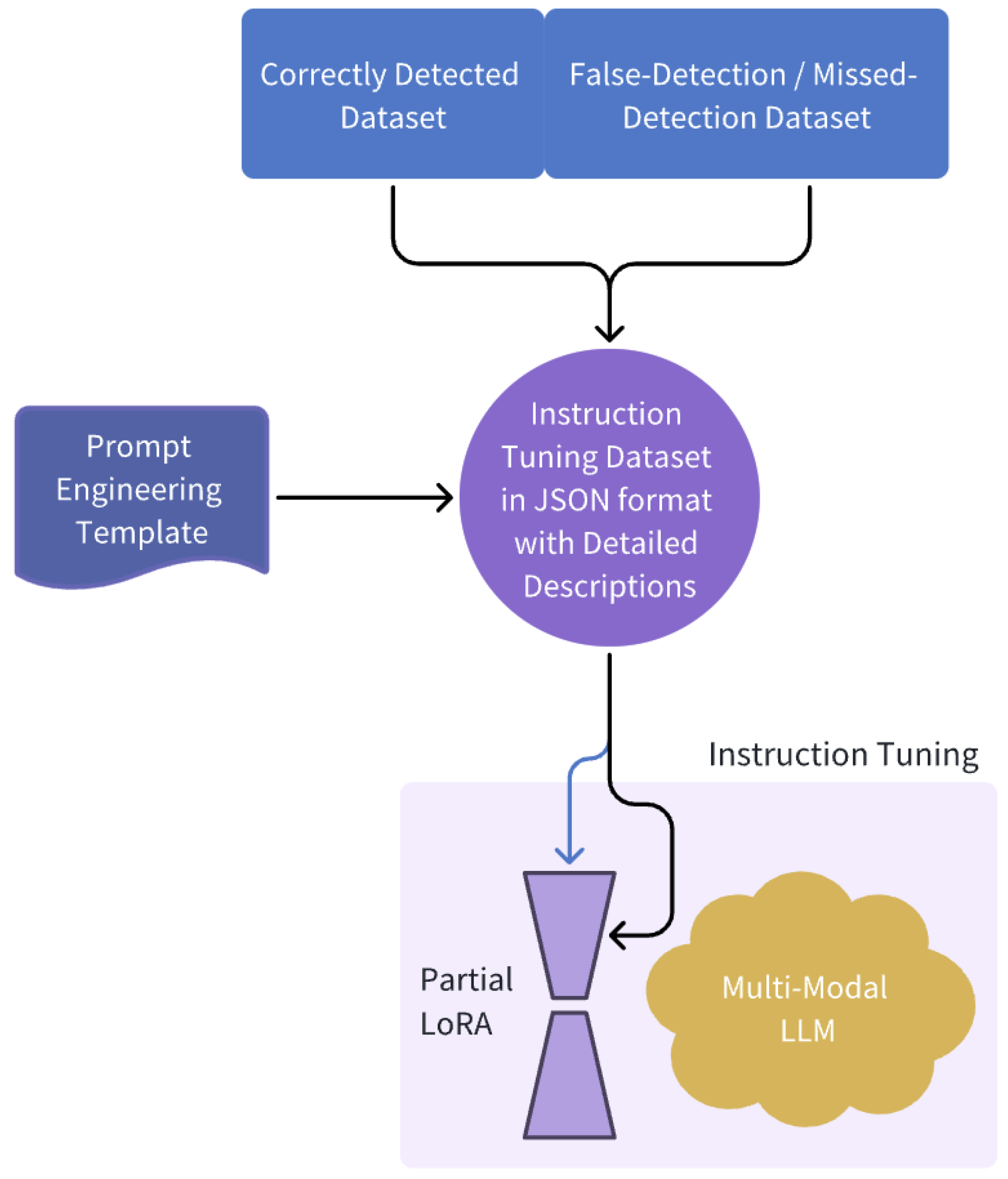
3.1. Multi-Modal LLM Training Based on Instruction Tuning
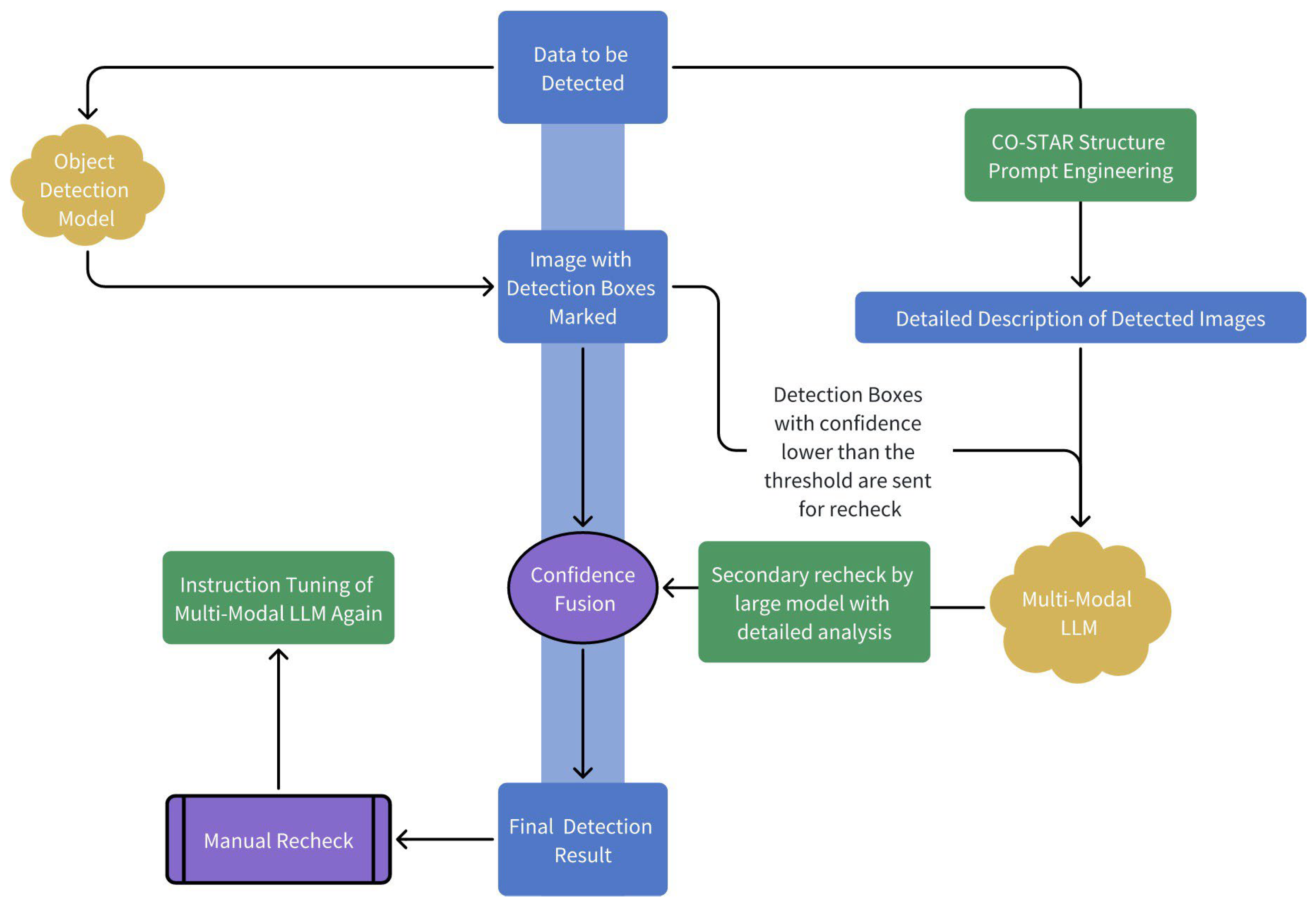
3.2. Enhanced Object Detection Framework Incorporating Multi-Modal LLM
4. Experiment
5. Conclusions
- Exploring the application of the model in more diverse and complex scenarios to improve its generalization ability;
- Investigating the integration of additional modalities or features to obtain more comprehensive and accurate detection results;
- Studying the interpretability and explainability of the model to better understand its decision-making process and increase its reliability.
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep learning for generic object detection: A survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed]
- Dhamija, A.; Gunther, M.; Ventura, J.; Boult, T. The overlooked elephant of object detection: Open set. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, The Westin Snowmass Resort, CO, USA, 2–5 March 2020; pp. 1021–1030. [Google Scholar]
- Dhillon, A.; Verma, G.K. Convolutional neural network: A review of models, methodologies and applications to object detection. Prog. Artif. Intell. 2020, 9, 85–112. [Google Scholar] [CrossRef]
- Navneet, D. Histograms of oriented gradients for human detection. Int. Conf. Comput. Vis. Pattern Recognit. 2005, 2, 886–893. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Uijlings, J.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Liu, S.; Zeng, Z.; Ren, T.; Li, F.; Zhang, H.; Yang, J.; Li, C.; Yang, J.; Su, H.; Zhu, J.; et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. arXiv 2023, arXiv:2303.05499. [Google Scholar]
- Zhang, Y.; Huang, X.; Ma, J.; Li, Z.; Luo, Z.; Xie, Y.; Qin, Y.; Luo, T.; Li, Y.; Liu, S.; et al. Recognize anything: A strong image tagging model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–18 June 2024; pp. 1724–1732. [Google Scholar]
- Yin, S.; Fu, C.; Zhao, S.; Li, K.; Sun, X.; Xu, T.; Chen, E. A survey on multimodal large language models. arXiv 2023, arXiv:2306.13549. [Google Scholar] [CrossRef]
- Ding, W.; Wang, X.; Zhao, Z. CO-STAR: A collaborative prediction service for short-term trends on continuous spatio-temporal data. Future Gener. Comput. Syst. 2020, 102, 481–493. [Google Scholar] [CrossRef]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. Lora: Low-rank adaptation of large language models. arXiv 2021, arXiv:2106.09685. [Google Scholar]
- Pfeiffer, J.; Rücklé, A.; Poth, C.; Kamath, A.; Vulić, I.; Ruder, S.; Cho, K.; Gurevych, I. Adapterhub: A framework for adapting transformers. arXiv 2020, arXiv:2007.07779. [Google Scholar]
- Zhang, Q.; Chen, M.; Bukharin, A.; Karampatziakis, N.; He, P.; Cheng, Y.; Chen, W.; Zhao, T. AdaLoRA: Adaptive budget allocation for parameter-efficient fine-tuning. arXiv 2023, arXiv:2303.10512. [Google Scholar]
- Sohan, M.; Sai Ram, T.; Reddy, R.; Venkata, C. A review on yolov8 and its advancements. In Proceedings of the International Conference on Data Intelligence and Cognitive Informatics; Springer: Berlin/Heidelberg, Germany, 2024; pp. 529–545. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | mAP50-95 | mAP50 |
|---|---|---|
| YOLOv8 | 0.716 ± 0.015 | 0.917 ± 0.012 |
| YOLOv8 + ours | 0.751 ± 0.018 | 0.944 ± 0.014 |
| Faster RCNN | 0.689 ± 0.013 | 0.898 ± 0.011 |
| Faster R-CNN + ours | 0.724 ± 0.016 | 0.922 ± 0.013 |
| PEFT Method | Correction Rate | |||
|---|---|---|---|---|
| 5-Shot | 10-Shot | 20-Shot | 50-Shot | |
| Partial LoRA | 88% | 92% | 96% | 98% |
| LoRA | 86% | 90% | 94% | 95% |
| AdaLORA | 86% | 90% | 94% | 95% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, K.; Wang, Y.; He, X.; Yan, J.; Guo, Y.; Jiang, Z.; Zhang, X.; Wang, W.; Xiong, Y.; Men, A.; et al. Semi-Open Set Object Detection Algorithm Leveraged by Multi-Modal Large Language Models. Big Data Cogn. Comput. 2024, 8, 175. https://doi.org/10.3390/bdcc8120175
Wu K, Wang Y, He X, Yan J, Guo Y, Jiang Z, Zhang X, Wang W, Xiong Y, Men A, et al. Semi-Open Set Object Detection Algorithm Leveraged by Multi-Modal Large Language Models. Big Data and Cognitive Computing. 2024; 8(12):175. https://doi.org/10.3390/bdcc8120175
Chicago/Turabian StyleWu, Kewei, Yiran Wang, Xiaogang He, Jinyu Yan, Yang Guo, Zhuqing Jiang, Xing Zhang, Wei Wang, Yongping Xiong, Aidong Men, and et al. 2024. "Semi-Open Set Object Detection Algorithm Leveraged by Multi-Modal Large Language Models" Big Data and Cognitive Computing 8, no. 12: 175. https://doi.org/10.3390/bdcc8120175
APA StyleWu, K., Wang, Y., He, X., Yan, J., Guo, Y., Jiang, Z., Zhang, X., Wang, W., Xiong, Y., Men, A., & Xiao, L. (2024). Semi-Open Set Object Detection Algorithm Leveraged by Multi-Modal Large Language Models. Big Data and Cognitive Computing, 8(12), 175. https://doi.org/10.3390/bdcc8120175