

Health Use Cases of AI Chatbots: Identification and Analysis of ChatGPT Prompts in Social Media Discourses

 ,
, 
Abstract
1. Introduction
2. Materials and Methods
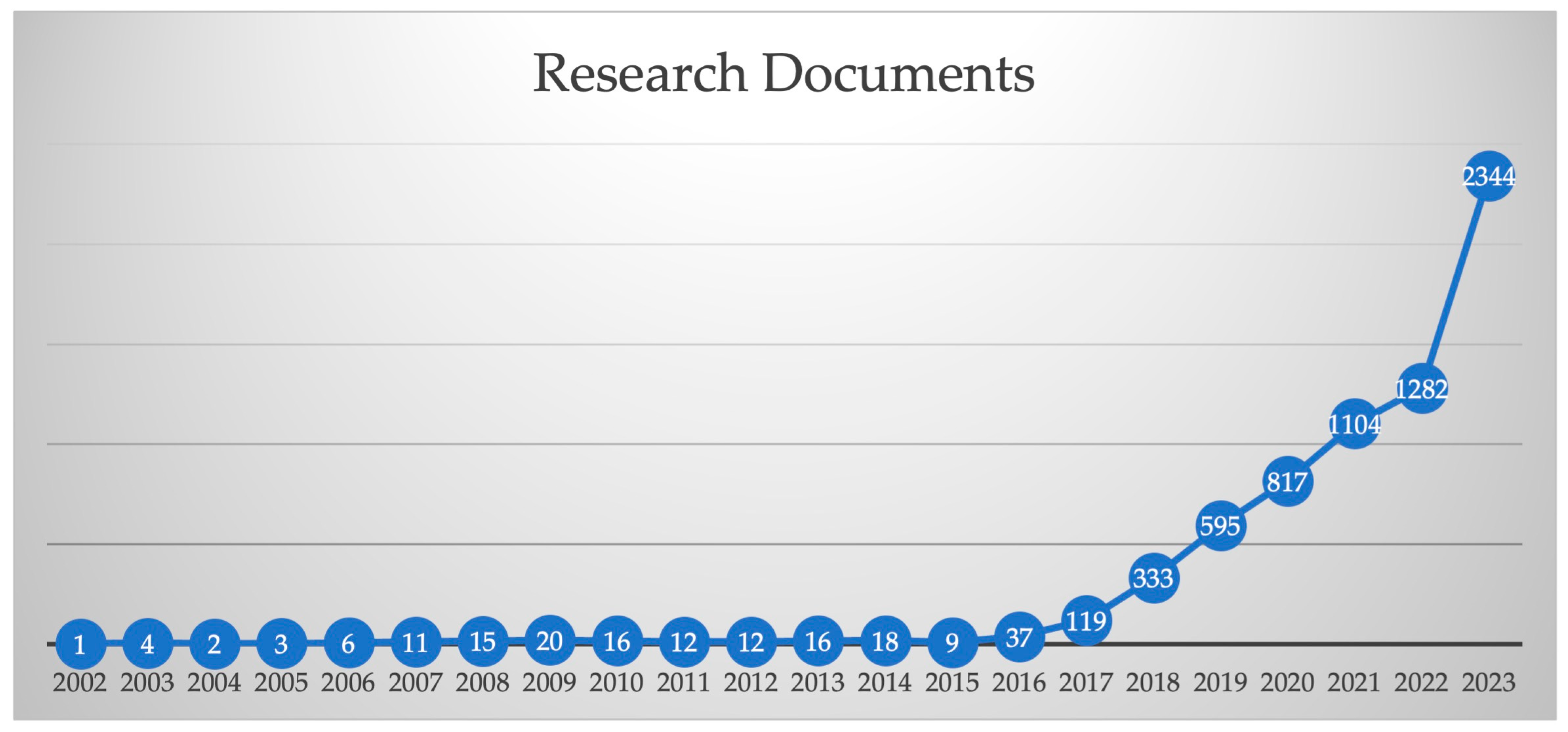
2.1. Data Collection and Processing
2.2. Initial Coding
2.3. Focused Coding
2.4. Theoretical Coding
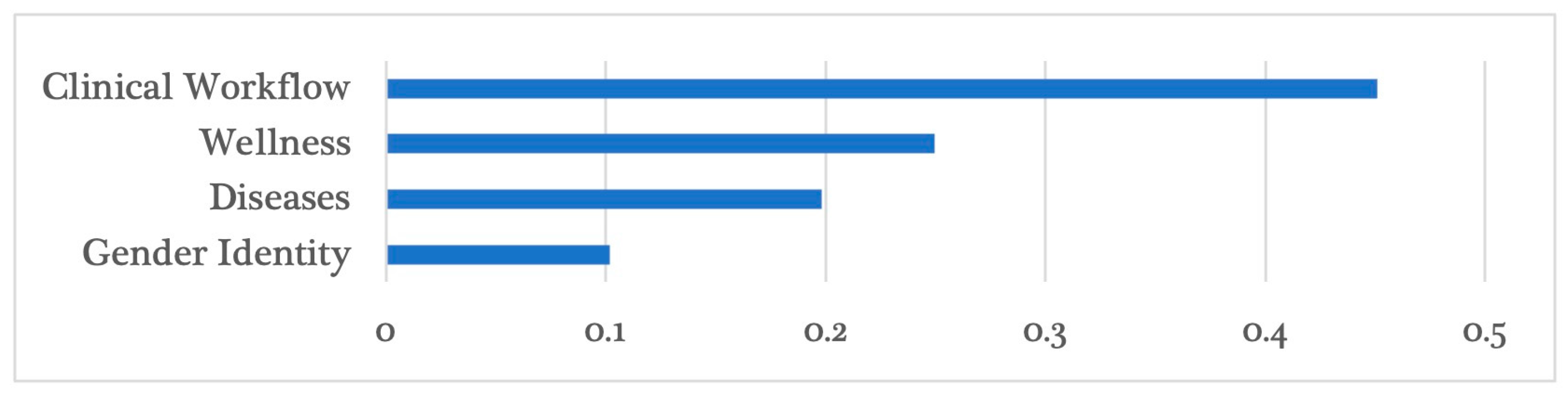
3. Results
3.1. Clinical Workflow
3.2. Wellness
3.3. Diseases
3.4. Gender Identity
4. Discussion
4.1. Theoretical Contributions
4.2. Implications for Practice
4.3. Limitations and Future Work
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Siriborvornratanakul, T. Advanced Artificial Intelligence Methods for Medical Applications. In Digital Human Modeling and Applications in Health, Safety, Ergonomics and Risk Management; Duffy, V.G., Ed.; Springer Nature: Cham, Switzerland, 2023; pp. 329–340. [Google Scholar] [CrossRef]
- Adamopoulou, E.; Moussiades, L. Chatbots: History, technology, and applications. Mach. Learn. Appl. 2020, 2, 100006. [Google Scholar] [CrossRef]
- Weizenbaum, J. ELIZA—A computer program for the study of natural language communication between man and machine. Commun. ACM 1966, 9, 36–45. [Google Scholar] [CrossRef]
- Shawar, B.A.; Atwell, E. Chatbots: Are they really useful? J. Lang. Technol. Comput. Linguist. 2007, 22, 29–49. [Google Scholar] [CrossRef]
- Brandtzaeg, P.B.; Følstad, A. Why People Use Chatbots. In Internet Science; Springer International Publishing: Cham, Germany, 2017; pp. 377–392. [Google Scholar] [CrossRef]
- Xu, A.; Liu, Z.; Guo, Y.; Sinha, V.; Akkiraju, R. A New Chatbot for Customer Service on Social Media. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017; ACM: New York, NY, USA, 2017; pp. 3506–3510. [Google Scholar] [CrossRef]
- Lin, C.-C.; Huang, A.Y.Q.; Yang, S.J.H. A review of AI-driven conversational chatbots implementation methodologies and challenges (1999–2022). Sustainability 2023, 15, 4012. [Google Scholar] [CrossRef]
- Biswas, S.S. Role of Chat GPT in Public Health. Ann. Biomed. Eng. 2023, 51, 868–869. [Google Scholar] [CrossRef]
- Xu, L.; Sanders, L.; Li, K.; Chow, J.C.L. Chatbot for health care and oncology applications using artificial intelligence and machine learning: Systematic review. JMIR Cancer 2021, 7, e27850. [Google Scholar] [CrossRef] [PubMed]
- Mesko, B. The Top 10 Healthcare Chatbots. In The Medical Futurist [Internet]. 1 August 2023. Available online: https://medicalfuturist.com/top-10-health-chatbots/ (accessed on 12 March 2024).
- OpenAI. Introducing ChatGPT. In Introducing ChatGPT [Internet]. 2022. Available online: https://openai.com/blog/chatgpt (accessed on 12 March 2024).
- Nath, S.; Marie, A.; Ellershaw, S.; Korot, E.; Keane, P.A. New meaning for NLP: The trials and tribulations of natural language processing with GPT-3 in ophthalmology. Br. J. Ophthalmol. 2022, 106, 889–892. [Google Scholar] [CrossRef]
- Retkowsky, J.; Hafermalz, E.; Huysman, M. Managing a ChatGPT-Empowered Workforce: Understanding Its Affordances and Side Effects. Business Horizons. 2024. Available online: https://www.sciencedirect.com/science/article/pii/S0007681324000545?casa_token=49wXQXd-2E4AAAAA:uGtVXwk42i-ED6_9q9a074b6x7_Ri2gIChZRgFjPVI_YkZeS7VXcfSK9Q18d0JlIgbuOGl9nfro (accessed on 23 April 2024).
- Palanica, A.; Flaschner, P.; Thommandram, A.; Li, M.; Fossat, Y. Physicians’ perceptions of chatbots in health care: Cross-sectional web-based survey. J. Med. Internet Res. 2019, 21, e12887. [Google Scholar] [CrossRef]
- McLaughlin, M.L.; Hou, J.; Meng, J.; Hu, C.-W.; An, Z.; Park, M.; Nam, Y. Propagation of Information About Preexposure Prophylaxis (PrEP) for HIV Prevention Through Twitter. Health Commun. 2016, 31, 998–1007. [Google Scholar] [CrossRef]
- Kepios. Global Social Media Statistics. In DataReportal—Global Digital Insights [Internet]. 2024. Available online: https://datareportal.com/social-media-users (accessed on 13 March 2024).
- Shaw, G., Jr.; Zimmerman, M.; Vasquez-Huot, L.; Karami, A. Deciphering Latent Health Information in Social Media Using a Mixed-Methods Design. Healthcare 2022, 10, 2320. [Google Scholar] [CrossRef]
- Karami, A.; Clark, S.B.; Mackenzie, A.; Lee, D.; Zhu, M.; Boyajieff, H.R.; Goldschmidt, B. 2020 U.S. presidential election in swing states: Gender differences in Twitter conversations. Int. J. Inf. Manag. Data Insights 2022, 2, 100097. [Google Scholar] [CrossRef]
- Messaoudi, C.; Guessoum, Z.; Ben Romdhane, L. Opinion mining in online social media: A survey. Soc. Netw. Anal. Min. 2022, 12, 25. [Google Scholar] [CrossRef]
- Duggan SF and M. Health Online 2013. In Pew Research Center [Internet]. 2013. Available online: https://www.pewresearch.org/internet/2013/01/15/health-online-2013/ (accessed on 23 April 2024).
- Moorhead, S.A.; Hazlett, D.E.; Harrison, L.; Carroll, J.K.; Irwin, A.; Hoving, C. A new dimension of health care: Systematic review of the uses, benefits, and limitations of social media for health communication. J. Med. Internet Res. 2013, 15, e85. [Google Scholar] [CrossRef] [PubMed]
- Attai, D.J.; Cowher, M.S.; Al-Hamadani, M.; Schoger, J.M.; Staley, A.C.; Landercasper, J. Twitter social media is an effective tool for breast cancer patient education and support: Patient-reported outcomes by survey. J. Med. Internet Res. 2015, 17, e188. [Google Scholar] [CrossRef] [PubMed]
- Kind, T.; Patel, P.D.; Lie, D.; Chretien, K.C. Twelve tips for using social media as a medical educator. Med. Teach. 2014, 36, 284–290. [Google Scholar] [CrossRef] [PubMed]
- Salathé, M.; Khandelwal, S. Assessing vaccination sentiments with online social media: Implications for Infectious disease dynamics and control. PLoS Comput. Biol. 2011, 7, e1002199. [Google Scholar] [CrossRef]
- Hu, K. ChatGPT Sets Record for Fastest-Growing User Base—Analyst Note. Reuters. 2 February 2023. Available online: https://www.reuters.com/technology/chatgpt-sets-record-fastest-growing-user-base-analyst-note-2023-02-01/ (accessed on 12 March 2024).
- Carr, D.F. ChatGPT’s First Birthday Is November 30: A Year in Review. In Similarweb [Internet]. 2023. Available online: https://www.similarweb.com/blog/insights/ai-news/chatgpt-birthday/ (accessed on 12 March 2024).
- Kelly, S.M. This AI chatbot Is Dominating Social Media with Its Frighteningly Good Essays|CNN Business. In CNN [Internet]. 5 December 2022. Available online: https://www.cnn.com/2022/12/05/tech/chatgpt-trnd/index.html (accessed on 12 March 2024).
- White, J.; Hays, S.; Fu, Q.; Spencer-Smith, J.; Schmidt, D.C. ChatGPT Prompt Patterns for Improving Code Quality, Refactoring, Requirements Elicitation, and Software Design. In Generative AI for Effective Software Development; Nguyen-Duc, A., Abrahamsson, P., Khomh, F., Eds.; Springer Nature Switzerland: Cham, Switzerland, 2024; pp. 71–108. [Google Scholar] [CrossRef]
- Li, J.; Dada, A.; Puladi, B.; Kleesiek, J.; Egger, J. ChatGPT in healthcare: A taxonomy and systematic review. Comput. Methods Programs Biomed. 2024, 245, 108013. [Google Scholar] [CrossRef]
- Taecharungroj, V. “What can ChatGPT do?” Analyzing early reactions to the innovative AI chatbot on Twitter. Big Data Cogn. Comput. 2023, 7, 35. [Google Scholar] [CrossRef]
- Javaid, M.; Haleem, A.; Singh, R.P. ChatGPT for healthcare services: An emerging stage for an innovative perspective. BenchCouncil Trans. Benchmarks Stand. Eval. 2023, 3, 100105. [Google Scholar] [CrossRef]
- Huh, S. Are ChatGPT’s Knowledge and Interpretation Ability Comparable to Those of Medical Students in Korea for Taking a Parasitology Examination?: A Descriptive Study. J. Educ. Eval. Health Prof. 2023, 20, 1. Available online: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9905868/ (accessed on 1 August 2024).
- Kung, T.H.; Cheatham, M.; Medenilla, A.; Sillos, C.; De Leon, L.; Elepaño, C.; Madriaga, M.; Aggabao, R.; Diaz-Candido, G.; Maningo, J.; et al. Performance of ChatGPT on USMLE: Potential for AI-assisted medical education using large language models. PLoS Digit. Health 2023, 2, e0000198. [Google Scholar] [CrossRef] [PubMed]
- Johnson, S.B.; King, A.J.; Warner, E.L.; Aneja, S.; Kann, B.H.; Bylund, C.L. Using ChatGPT to evaluate cancer myths and misconceptions: Artificial intelligence and cancer information. JNCI Cancer Spectr. 2023, 7, pkad015. [Google Scholar] [CrossRef]
- Potapenko, I.; Boberg-Ans, L.C.; Hansen, M.S.; Klefter, O.N.; van Dijk, E.H.C.; Subhi, Y. Artificial intelligence-based chatbot patient information on common retinal diseases using ChatGPT. Acta Ophthalmol. 2023, 101, 829–831. [Google Scholar] [CrossRef] [PubMed]
- Duong, D.; Solomon, B.D. Analysis of large-language model versus human performance for genetics questions. Eur. J. Hum. Genet. 2024, 32, 466–468. [Google Scholar] [CrossRef]
- Lahat, A.; Shachar, E.; Avidan, B.; Shatz, Z.; Glicksberg, B.S.; Klang, E. Evaluating the use of large language model in identifying top research questions in gastroenterology. Sci. Rep. 2023, 13, 4164. [Google Scholar] [CrossRef] [PubMed]
- Sinha, R.K.; Roy, A.D.; Kumar, N.; Mondal, H. Applicability of ChatGPT in Assisting to Solve Higher Order Problems in Pathology. Cureus 2023, 15, e35237. Available online: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10033699/ (accessed on 1 August 2024). [CrossRef]
- Ali, S.R.; Dobbs, T.D.; Hutchings, H.A.; Whitaker, I.S. Using ChatGPT to write patient clinic letters. Lancet Digit. Health 2023, 5, e179–e181. [Google Scholar] [CrossRef]
- Lim, S.; Schmälzle, R. Artificial intelligence for health message generation: An empirical study using a large language model (LLM) and prompt engineering. Front. Commun. 2023, 8, 1129082. [Google Scholar] [CrossRef]
- Ulusoy, I.; Yılmaz, M.; Kıvrak, A. How Efficient Is ChatGPT in Accessing Accurate and Quality Health-Related Information? Cureus 2023, 15, e46662. Available online: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10628365/ (accessed on 1 August 2024). [CrossRef]
- Cabrera, J.; Loyola, M.S.; Magaña, I.; Rojas, R. Ethical Dilemmas, Mental Health, Artificial Intelligence, and LLM-Based Chatbots. In Bioinformatics and Biomedical Engineering; Rojas, I., Valenzuela, O., Rojas Ruiz, F., Herrera, L.J., Ortuño, F., Eds.; Springer Nature Switzerland: Cham, Switzerland, 2023; pp. 313–326. [Google Scholar] [CrossRef]
- Fadhil, A.; Gabrielli, S. Addressing challenges in promoting healthy lifestyles: The al-chatbot approach. In Proceedings of the 11th EAI International Conference on Pervasive Computing Technologies for Healthcare, Barcelona, Spain, 23–26 May 2017; ACM: New York, NY, USA, 2017; pp. 261–265. [Google Scholar] [CrossRef]
- Sallam, M.; Salim, N.; Barakat, M.; Al-Tammemi, A. ChatGPT applications in medical, dental, pharmacy, and public health education: A descriptive study highlighting the advantages and limitations. Narra J. 2023, 3, e103. Available online: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10914078/ (accessed on 1 August 2024). [CrossRef]
- Yu, H.; McGuinness, S. An experimental study of integrating fine-tuned LLMs and prompts for enhancing mental health support chatbot system. J. Med. Artif. Intell. 2024, 7, 1–16. [Google Scholar] [CrossRef]
- Softić, A.; Husić, J.B.; Softić, A.; Baraković, S. Health chatbot: Design, implementation, acceptance and usage motivation. In Proceedings of the 2021 20th International Symposium Infoteh-Jahorina (INFOTEH), East Sarajevo, Bosnia and Herzegovina, 17–19 March 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. Available online: https://ieeexplore.ieee.org/abstract/document/9400693/ (accessed on 1 August 2024).
- Aggarwal, A.; Tam, C.C.; Wu, D.; Li, X.; Qiao, S. Artificial intelligence–based chatbots for promoting health behavioral changes: Systematic review. J. Med. Internet Res. 2023, 25, e40789. [Google Scholar] [CrossRef] [PubMed]
- Lian, Y.; Tang, H.; Xiang, M.; Dong, X. Public attitudes and sentiments toward ChatGPT in China: A text mining analysis based on social media. Technol. Soc. 2024, 76, 102442. [Google Scholar] [CrossRef]
- Zhou, W.; Zhang, C.; Wu, L.; Shashidhar, M. ChatGPT and marketing: Analyzing public discourse in early Twitter posts. J. Mark. Anal. 2023, 11, 693–706. [Google Scholar] [CrossRef]
- Strauss, A.; Corbin, J. Basics of Grounded Theory Methods; Sage: Beverly Hills, CA, USA, 1990. [Google Scholar]
- Glaser, B.G. Basic of Grounded Theory Analysis; Sociology Press: Mills, CA, USA, 1992; Available online: https://www.sidalc.net/search/Record/UnerFceco:4647/Description (accessed on 1 August 2024).
- Charmaz, K. Constructing Grounded Theory: A Practical Guide through Qualitative Analysis; Sage: Beverly Hills, CA, USA, 2006; Available online: https://books.google.com/books?hl=en&lr=&id=2ThdBAAAQBAJ&oi=fnd&pg=PP1&ots=f-i_aOoExV&sig=EbtcJbDMiY4X4oTxlVyyKLyXs04 (accessed on 1 August 2024).
- Odacioglu, E.C.; Zhang, L.; Allmendinger, R.; Shahgholian, A. Big textual data research for operations management: Topic modelling with grounded theory. Int. J. Oper. Prod. Manag. 2023, 44, 1420–1445. [Google Scholar] [CrossRef]
- Miller, F.; Davis, K.; Partridge, H. Everyday life information experiences in Twitter: A grounded theory. Inf. Res. Int. Electron. J. 2019, 24, 1–23. Available online: https://research.usq.edu.au/item/q7636/everyday-life-information-experiences-in-twitter-a-grounded-theory (accessed on 1 August 2024).
- Tie, Y.C.; Birks, M.; Francis, K. Grounded theory research: A design framework for novice researchers. SAGE Open Med. 2019, 7, 205031211882292. [Google Scholar] [CrossRef]
- Nelson, L.K. Computational Grounded Theory: A Methodological Framework. Sociol. Methods Res. 2020, 49, 3–42. [Google Scholar] [CrossRef]
- Finfgeld-Connett, D. Twitter and Health Science Research. West. J. Nurs. Res. 2015, 37, 1269–1283. [Google Scholar] [CrossRef]
- Edo-Osagie, O.; De La Iglesia, B.; Lake, I.; Edeghere, O. A scoping review of the use of Twitter for public health research. Comput. Biol. Med. 2020, 122, 103770. [Google Scholar] [CrossRef]
- Gotfredsen, S.G. Q&A: What Happened to Academic Research on Twitter? In Columbia Journalism Review [Internet]. Available online: https://www.cjr.org/tow_center/qa-what-happened-to-academic-research-on-twitter.php (accessed on 8 August 2024).
- Shewale, R. 17 Google Gemini Statistics (2024 Users & Traffic). In DemandSage [Internet]. 16 February 2024. Available online: https://www.demandsage.com/google-gemini-statistics/ (accessed on 3 June 2024).
- Duarte, F. Number of ChatGPT Users (May 2024). In Exploding Topics [Internet]. 30 March 2023. Available online: https://explodingtopics.com/blog/chatgpt-users (accessed on 3 June 2024).
- Google Trend. Google Trends of ChatGPT, Bard, Llama, and Copilot. 2023. Available online: https://trends.google.com/trends/explore?date=2023-01-01%202023-12-31&geo=US&q=chatgpt,%2Fg%2F11tsqm45vd,bard,Llama&hl=en (accessed on 3 June 2024).
- Kemp, S. Twitter Statistics and Trends. In DataReportal—Global Digital Insights [Internet]. 2023. Available online: https://datareportal.com/essential-twitter-stats (accessed on 15 March 2023).
- Shewale, R. Twitter Statistics in 2023. 2023. Available online: https://www.demandsage.com/twitter-statistics/#:~:text=Let%20us%20take%20a%20closer,528.3%20million%20monthly%20active%20users (accessed on 1 August 2024).
- Lim, M.S.C.; Molenaar, A.; Brennan, L.; Reid, M.; McCaffrey, T. Young adults’ use of different social media platforms for health information: Insights from web-based conversations. J. Med. Internet Res. 2022, 24, e23656. [Google Scholar] [CrossRef] [PubMed]
- Takats, C.; Kwan, A.; Wormer, R.; Goldman, D.; Jones, H.E.; Romero, D. Ethical and methodological considerations of twitter data for public health research: Systematic review. J. Med. Internet Res. 2022, 24, e40380. [Google Scholar] [CrossRef] [PubMed]
- Mejova, Y.; Weber, I.; Macy, M.W. Twitter: A Digital Socioscope; Cambridge University Press: Cambridge, UK, 2015. [Google Scholar]
- Antonakaki, D.; Fragopoulou, P.; Ioannidis, S. A survey of Twitter research: Data model, graph structure, sentiment analysis and attacks. Expert Syst. Appl. 2021, 164, 114006. [Google Scholar] [CrossRef]
- Karami, A.; Dahl, A.A.; Shaw, G.; Valappil, S.P.; Turner-McGrievy, G.; Kharrazi, H.; Bozorgi, P. Analysis of Social Media Discussions on (#)Diet by Blue, Red, and Swing States in the U.S. Healthcare 2021, 9, 518. [Google Scholar] [CrossRef]
- Son, J.; Negahban, A. Examining the Impact of Emojis on Disaster Communication: A Perspective from the Uncertainty Reduction Theory. AIS Trans. Hum.-Comput. Interact. 2023, 15, 377–413. [Google Scholar] [CrossRef]
- Van Vliet, L.; Törnberg, P.; Uitermark, J. The Twitter parliamentarian database: Analyzing Twitter politics across 26 countries. PLoS ONE 2020, 15, e0237073. [Google Scholar] [CrossRef]
- Kolagani, S.H.D.; Negahban, A.; Witt, C. Identifying trending sentiments in the 2016 us presidential election: A case study of twitter analytics. Issues Inf. Syst. 2017, 18, 80–86. [Google Scholar]
- Nzali, M.D.T.; Bringay, S.; Lavergne, C.; Mollevi, C.; Opitz, T. What patients can tell us: Topic analysis for social media on breast cancer. JMIR Public Health Surveill. 2017, 5, e23. [Google Scholar]
- Karami, A.; Zhu, M.; Goldschmidt, B.; Boyajieff, H.R.; Najafabadi, M.M. COVID-19 Vaccine and Social Media in the U.S.: Exploring Emotions and Discussions on Twitter. Vaccines 2021, 9, 1059. [Google Scholar] [CrossRef]
- Malik, A.; Antonino, A.; Khan, M.L.; Nieminen, M. Characterizing HIV discussions and engagement on Twitter. Health Technol. 2021, 11, 1237–1245. [Google Scholar] [CrossRef]
- Pennebaker, J.W.; Boyd, R.L.; Jordan, K.; Blackburn, K. The Development and Psychometric Properties of LIWC2015; Pennebaker Conglomerates: Austin, TX, USA, 2015; Available online: www.LIWC.net (accessed on 1 August 2024).
- Zipf, G.K. Human Behavior and the Principle of Least Effort: An Introduction to Human Ecology; Addison-Wesley Press, Inc.: Cambridge, MA, USA, 1949. [Google Scholar]
- Karami, A. Fuzzy Topic Modeling for Medical Corpora. Ph.D. Thesis, University of Maryland, Baltimore County, MD, USA, 2015. [Google Scholar]
- DiMaggio, P. Adapting computational text analysis to social science (and vice versa). Big Data Soc. 2015, 2, 205395171560290. [Google Scholar] [CrossRef]
- Baumer, E.P.S.; Mimno, D.; Guha, S.; Quan, E.; Gay, G.K. Comparing grounded theory and topic modeling: Extreme divergence or unlikely convergence? J. Assoc. Inf. Sci. Technol. 2017, 68, 1397–1410. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Egger, R.; Yu, J. A topic modeling comparison between lda, nmf, top2vec, and bertopic to demystify twitter posts. Front. Sociol. 2022, 7, 886498. [Google Scholar] [CrossRef] [PubMed]
- Zhang, D.; Luo, T.; Wang, D. Learning from LDA Using Deep Neural Networks. In Natural Language Understanding and Intelligent Applications; Lin, C.-Y., Xue, N., Zhao, D., Huang, X., Feng, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 657–664. [Google Scholar] [CrossRef]
- Mohammadi, M.; Al-Fuqaha, A.; Sorour, S.; Guizani, M. Deep learning for IoT big data and streaming analytics: A survey. IEEE Commun. Surv. Tutor. 2018, 20, 2923–2960. [Google Scholar] [CrossRef]
- Erhan, D.; Courville, A.; Bengio, Y.; Vincent, P. Why does unsupervised pre-training help deep learning? In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; JMLR Workshop and Conference Proceedings. pp. 201–208. Available online: http://proceedings.mlr.press/v9/erhan10a.html (accessed on 1 August 2024).
- Hong, L.; Davison, B.D. Empirical study of topic modeling in Twitter. In Proceedings of the First Workshop on Social Media Analytics; ACM: Washington, DC, USA, 2010; pp. 80–88. [Google Scholar] [CrossRef]
- Lu, Y.; Mei, Q.; Zhai, C. Investigating task performance of probabilistic topic models: An empirical study of PLSA and LDA. Inf. Retr. 2011, 14, 178–203. [Google Scholar] [CrossRef]
- Blei, D.M. Probabilistic Topic Models. Commun. ACM 2012, 55, 77–84. [Google Scholar] [CrossRef]
- Cao, J.; Xia, T.; Li, J.; Zhang, Y.; Tang, S. A density-based method for adaptive LDA model selection. Neurocomputing 2009, 72, 1775–1781. [Google Scholar] [CrossRef]
- Syed, S.; Spruit, M. Full-text or abstract? examining topic coherence scores using latent dirichlet allocation. In Proceedings of the 2017 IEEE International conference on data science and advanced analytics (DSAA), Tokyo, Japan, 19–21 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 165–174. Available online: https://ieeexplore.ieee.org/abstract/document/8259775/?casa_token=i0ifBOi_wfIAAAAA:UVPjwXEKAVWcHGS5BDHBh-SqPc-x8kOQCPZlGy2sNduuJN--QqiYT7df4bPsxoY2KvhXxZT_sw (accessed on 1 August 2024).
- Karami, A.; Swan, S.C.; White, C.N.; Ford, K. Hidden in plain sight for too long: Using text mining techniques to shine a light on workplace sexism and sexual harassment. Psychol. Violence 2019, 14, 1–13. [Google Scholar] [CrossRef]
- Karami, A.; Lundy, M.; Webb, F.; Dwivedi, Y.K. Twitter and research: A systematic literature review through text mining. IEEE Access 2020, 8, 67698–67717. [Google Scholar] [CrossRef]
- Karami, A.; Spinel, M.Y.; White, C.N.; Ford, K.; Swan, S. A systematic literature review of sexual harassment studies with text mining. Sustainability 2021, 13, 6589. [Google Scholar] [CrossRef]
- Zhou, X.; Xu, Y.; Li, Y.; Josang, A.; Cox, C. The state-of-the-art in personalized recommender systems for social networking. Artif. Intell. Rev. 2012, 37, 119–132. [Google Scholar] [CrossRef]
- Minssen, T.; Vayena, E.; Cohen, I.G. The Challenges for Regulating Medical Use of ChatGPT and Other Large Language Models. JAMA 2023, 330, 315–316. Available online: https://jamanetwork.com/journals/jama/article-abstract/2807167?casa_token=K4KeF9AGmRoAAAAA:36WVm5COT3vbRUafym6LeEM9S2QWgoOx8moN4gz4TADzxIAbVYc28ON36LB_2QskGuovyZqiQyg (accessed on 5 June 2024). [CrossRef] [PubMed]
- Wang, C.; Liu, S.; Yang, H.; Guo, J.; Wu, Y.; Liu, J. Ethical considerations of using ChatGPT in health care. J. Med. Internet Res. 2023, 25, e48009. [Google Scholar] [CrossRef]
- Hughes, A.; Wojcik, S. 10 Facts about Americans and Twitter; Pew Research Center: Washington, DC, USA, 2019. [Google Scholar]
- Singh, S. ChatGPT Statistics (AUG 2024)—Users Growth Data. In DemandSage [Internet]. 10 August 2024. Available online: https://www.demandsage.com/chatgpt-statistics/ (accessed on 12 August 2024).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Initial Coding | Focused Coding | Theoretical Coding |
|---|---|---|
| advice, give, therapist, specific, job, personal, therapy, prompt, ways, professional | Seeking Advice | Clinical Workflow |
| interesting, work, find, writing, clinical, change, thinking, made, essay, info | Clinical Documentation | |
| doctor, medical, patients, diagnose, found, provide, information, accurate, medicine, symptoms | Medical Diagnosis | |
| bad, high, heart, pain, low, hard, years, disease, treatment, chronic | Medical Treatment | |
| plan, workout, diet, create, meal, week, make, day, fitness, exercise, based, give | Diet and Workout Plans | Wellness |
| health, mental, people, data, based, generate, public, care, physical, improve | General Health | |
| cancer, cure, ill, similar, current, alcohol, important, risk, science, thinks | Cancer | Diseases |
| COVID, response, vaccine, immunity, disease, virus, symptoms, infection, prevent, pandemic | COVID-19 | |
| physical, human, men, woman, body, women, gender, abortion, pregnant, man | Anatomical Differences | Gender Identity |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karami, A.; Qiao, Z.; Zhang, X.; Kharrazi, H.; Bozorgi, P.; Bozorgi, A. Health Use Cases of AI Chatbots: Identification and Analysis of ChatGPT Prompts in Social Media Discourses. Big Data Cogn. Comput. 2024, 8, 130. https://doi.org/10.3390/bdcc8100130
Karami A, Qiao Z, Zhang X, Kharrazi H, Bozorgi P, Bozorgi A. Health Use Cases of AI Chatbots: Identification and Analysis of ChatGPT Prompts in Social Media Discourses. Big Data and Cognitive Computing. 2024; 8(10):130. https://doi.org/10.3390/bdcc8100130
Chicago/Turabian StyleKarami, Amir, Zhilei Qiao, Xiaoni Zhang, Hadi Kharrazi, Parisa Bozorgi, and Ali Bozorgi. 2024. "Health Use Cases of AI Chatbots: Identification and Analysis of ChatGPT Prompts in Social Media Discourses" Big Data and Cognitive Computing 8, no. 10: 130. https://doi.org/10.3390/bdcc8100130
APA StyleKarami, A., Qiao, Z., Zhang, X., Kharrazi, H., Bozorgi, P., & Bozorgi, A. (2024). Health Use Cases of AI Chatbots: Identification and Analysis of ChatGPT Prompts in Social Media Discourses. Big Data and Cognitive Computing, 8(10), 130. https://doi.org/10.3390/bdcc8100130