1. Introduction
Deep underground engineering is becoming more common in mine production, tunnel construction, and the construction of various subsurface structures. This trend has led to more frequent encounters with highly stressed geological conditions [
1]. As a result, the seismically triggering environment has led to numerous geological hazards, such as rockbursts. A rockburst is a progressive failure process wherein a rock mass ruptures due to the sudden release of a large quantity of stored elastic energy in highly stressed rocks. Casualties and the failure of engineering structures then result from the sudden ejection of surrounding rocks [
2]. Rockbursts are becoming more prevalent worldwide as mines delve deeper; as a result, accidents are becoming more common [
3]. In central Europe, 42 seismically active mines reported approximately 190 rockbursts that caused 122 casualties over the last two decades [
4]. Deep gold fields in western Australia and the Beaconsfield mine in Tasmania have also experienced fatalities [
3]. The Taiping head-race tunnels in China have experienced over 400 rockburst incidents, resulting in several casualties and the destruction of mechanical equipment [
5]. Numerous countries have faced rockburst problems in mines, tunnels, shafts, and caverns [
6,
7]. To ensure the safety of personnel, various approaches have been implemented for the real-time monitoring of short-term rockburst risk.
Microgravity, electromagnetic radiation, acoustic emissions, and microseismic monitoring (MS) methods are commonly employed to generate early warnings of short-term rockburst risk [
8,
9]. Among these techniques, the MS technique has been extensively used in deep engineering excavation to warn of short-term rockburst risks by studying the results of various multi-parameter MS methods using experimental, probabilistic, and fractal-theory approaches [
10,
11,
12]. For instance, Feng et al. examined the fractal behaviour of the energy distribution of microseismic events during the development of immediate rockbursts. The results indicated that, as the rockburst approached, the daily energy fractal dimension for MS events increased [
11]. Additionally, Yu et al. investigated the fractal behaviour of the time distribution of MS events for different intensities of rockbursts. The result indicated that time-fractal characteristics could be used to estimate rockburst intensity and that a smaller time-fractal dimension means a lower intensity [
13].
Further, using the MS technique, Chen et al. collated 133 rockburst cases and established a relationship between radiated energy and burst intensity. Based on their criteria, rockburst grades were divided into five types: none, slight, moderate, intense, and highly intense [
14]. Feng et al. utilised six MS parameters from real-time monitoring and established an early warning method. The proposed method was able to successfully identify the strain and strain-structure slip burst of the Jinping II hydropower project [
10]. Additionally, Alcott et al. established performance criteria for MS source parameters and thresholds for daily decision-making on the ground control. Those criteria were used to help identify seismically affected areas [
15]. Lastly, Liu et al. observed that, before more significant events, MS apparent volume and spatial correlation length increased, while the energy index, fractal dimension, and b value decreased [
6].
All the aforementioned approaches achieved significant results for the early recognition of rockbursts and could be used in early-warning systems. However, the identification of a globally accepted threshold value for rockburst risk that could apply to different site conditions and the choice of MS parameters indicating the various risk levels without the aid of computer models both remain challenging. As a result, some researchers have used a machine learning (ML) approach to predict rockburst risk. The value of ML methods is that they do not require knowledge of input and output, so they can predict outcomes by studying underlying data patterns without human involvement.
Feng et al. proposed an optimised probabilistic neural network (PNN) method to predict rockburst intensity using real-time MS information. The model integrated two other algorithms to improve performance, which increased the model’s accuracy in predicting test samples by 20% compared to the standard PNN model [
16]. Additionally, Liang et al. developed boosting and stacking ensemble methods using real engineering datasets. Those researchers achieved significantly higher accuracy in predicting short-term rockbursts [
17,
18]. Further, Liu et al. presented an artificial neural network (ANN) for the dynamic updating of short-term rockburst predictions. The model was further optimised by embedding a genetic algorithm (GA), which was employed to predict 31 actual cases. The results showed that the model could correctly estimate 83.9% of rockburst cases [
19]. Further, Zhao et al. built a decision tree (DT) model to predict the exact rank of the rockburst using MS information. The relationship between the MS features and rockbursts was investigated using the DT classifier, and the results showed that the model could accurately predict risk and provide insights regarding rockbursts using MS data [
20]. Toksanbayev and Adoko collected 254 samples from seismically active mines and established a damage-scale classification model based on multinational logistic regression (LR). The proposed work used regression equations to create probabilistic models for the assessment of seismic hazards in mines [
21]. Lastly, Ullah et al. integrated K-means clustering with extreme gradient boosting (XGBoost) [
22]. The original data were relabelled through a clustering method, and XGBoost was trained and tested to validate the model.
All the above-mentioned models have contributed significantly to improving the accuracy of prediction. Neural networks have an advantage in dealing with complex nonlinear problems; however, some neural-network models are susceptible to problems caused by irrelevancies in the data and prone to suboptimal local minima. Although the integration of multiple hybrid and complex ensemble models improves prediction accuracy, the resultant models are often difficult to understand and execute. LR and DT are simple and easy to use but have less accuracy in highly complex, nonlinear rockburst problems. Most applied methods have focused on achieving higher accuracy in predicting risk, and the microseismic dataset is comparatively small. The proportions of different intensity levels in datasets are often unequal. However, accurately classifying each risk level is crucial when classes are imbalanced. One previous study [
23] shows that the boosting method (CGB) is more efficient for analysing multi-class imbalanced data in small and large datasets than are other boosting algorithms. However, the feasibility of employing CGB in short-term rockburst prediction has never been studied before, and it is necessary to develop a simple and easy-to-use classification model with promise for predicting each class level effectively.
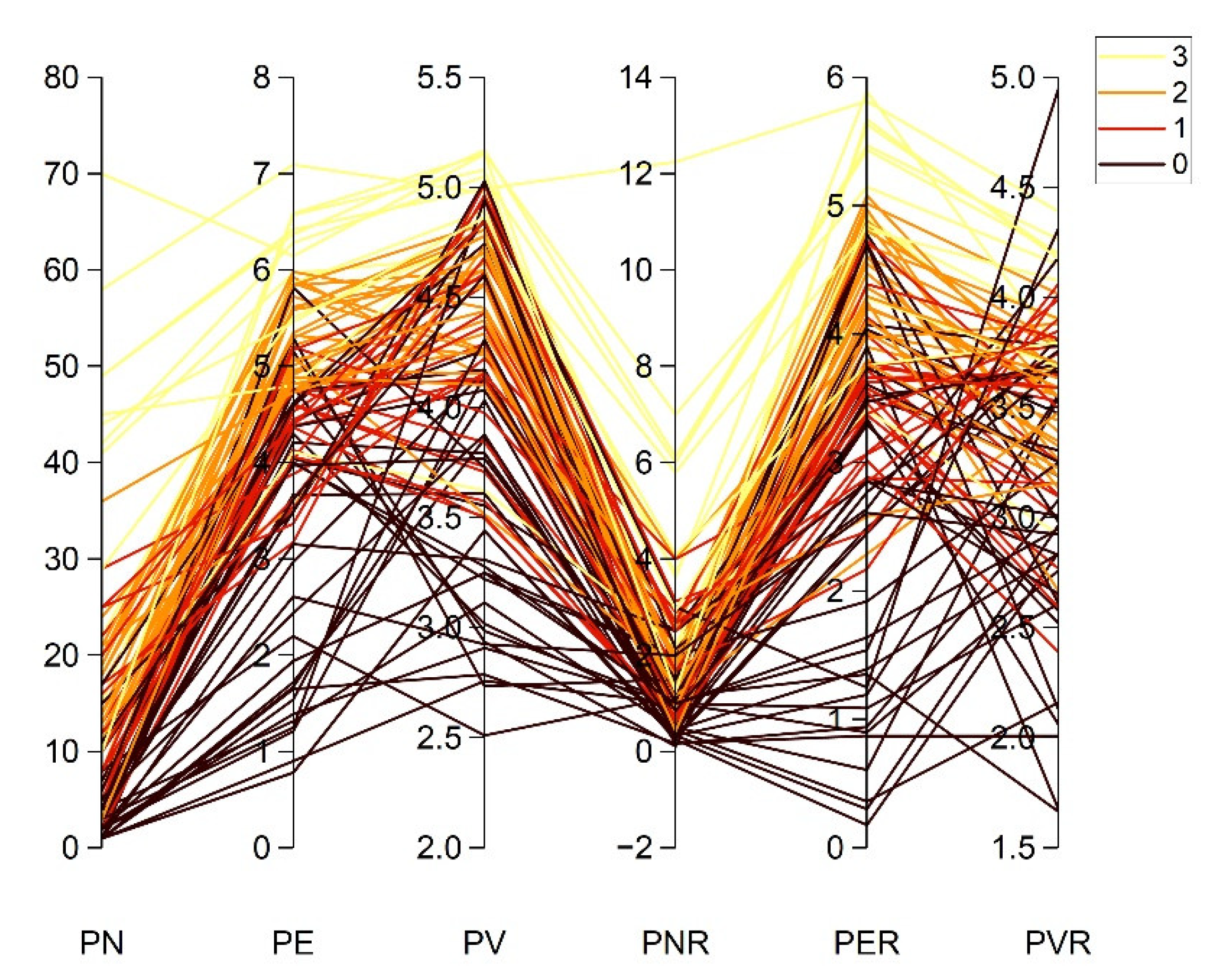
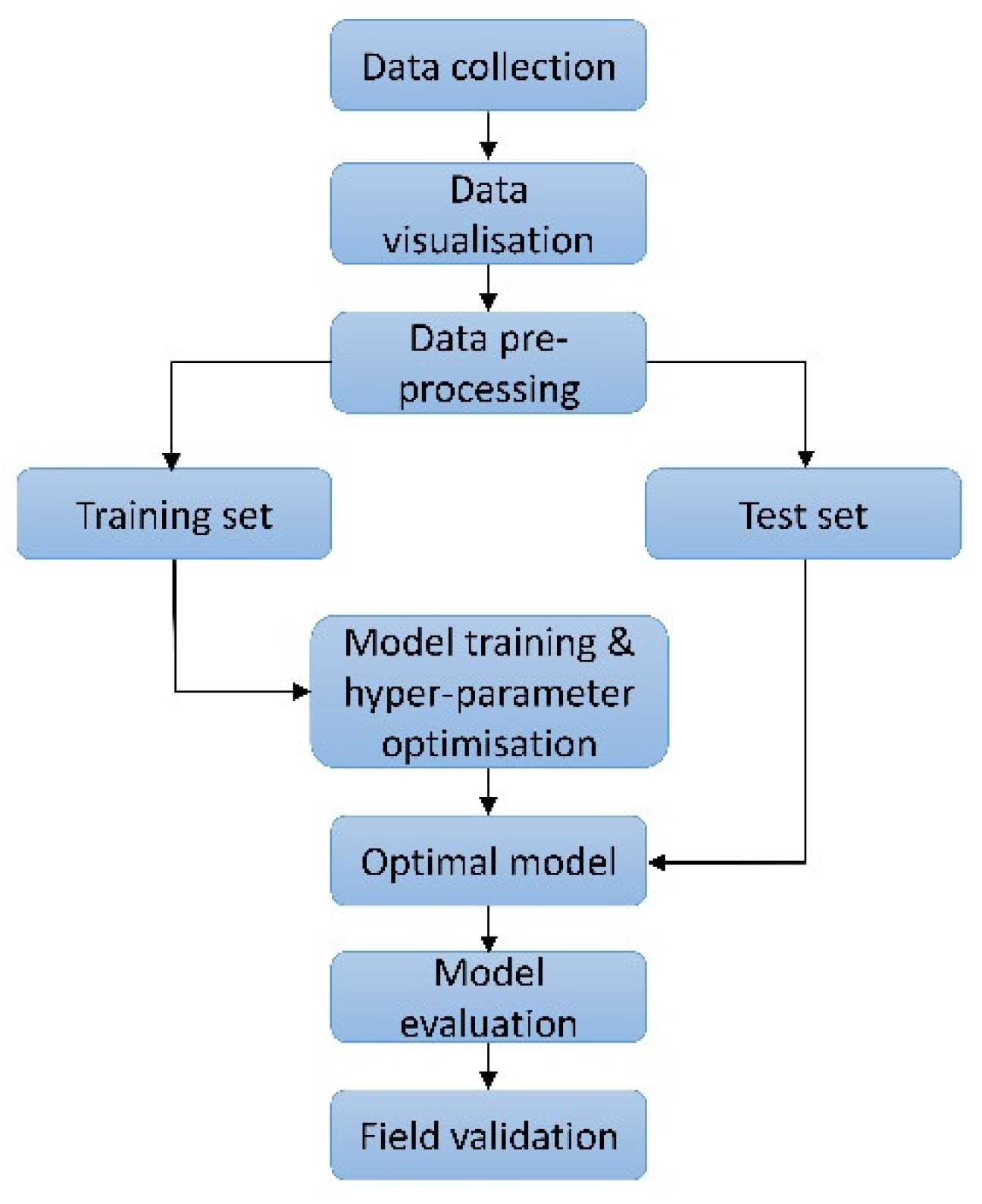
Therefore, this work proposes a PCA-CGB classification model to create a simple and reliable approach to predicting the intensity of rockbursts. The advantage of this proposed work over the previous approach is that more data have been gathered for the study; additionally, variable redundancies are managed through unsupervised learning. Also, to precisely classify each majority or minority class, a simple model is built and performance is comprehensively evaluated using various metrics.
4. Performance Comparison
To check the feasibility of using the PCA-CGB, its performance was compared with those of three conventional boosting classifiers on the same dataset. These other classifiers have often been utilised in rockburst prediction [
17,
36], and the comparison checked for improvements. The three boosting classifiers were the gradient boosting classifier (GBC) [
37], adaptive boosting (AdaBoost) [
38], and light gradient boosting machine (LGBM) [
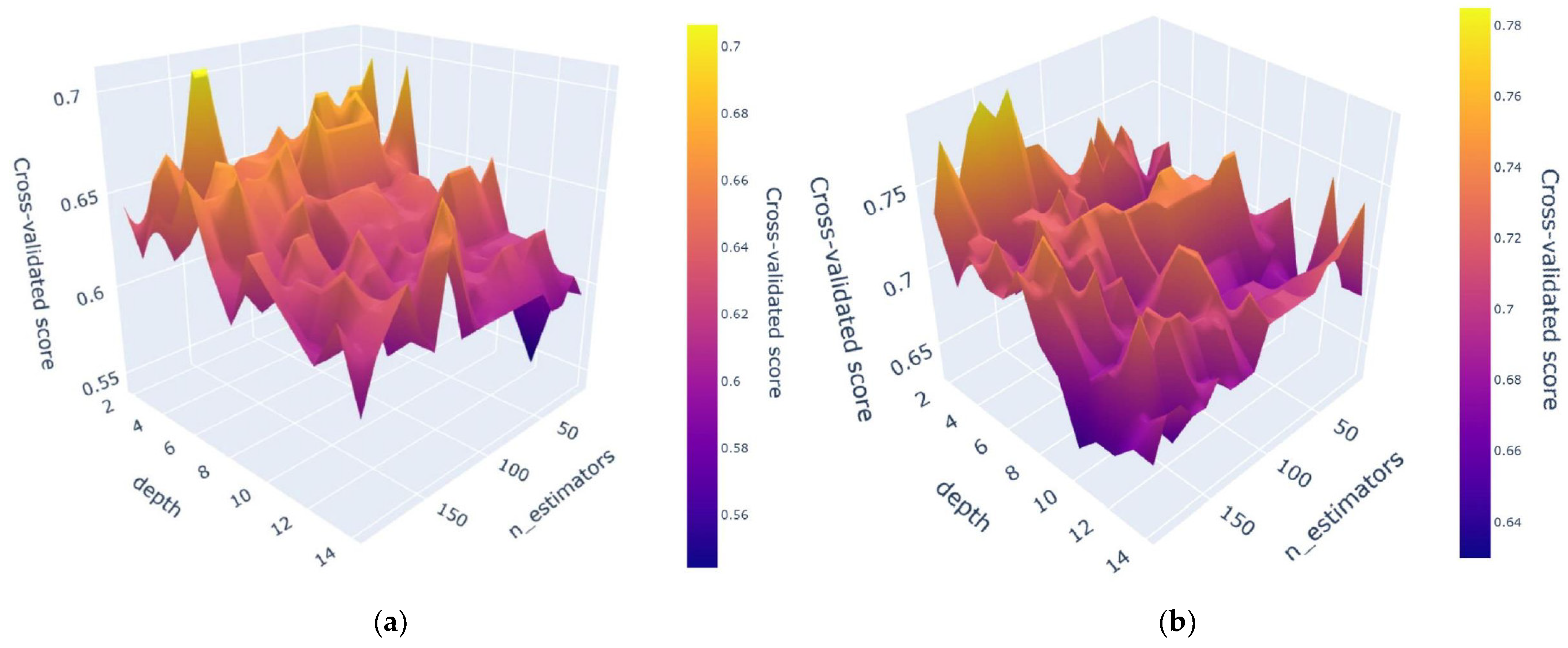
39]. All three models were trained on the same data after PCA, and their hyper-parameters were also optimised using the GS-CV method with the same process used for PCA-CGB. For GBC and LGBM, two crucial parameters, max_depth and n_estimators, were adopted with the same tuning range as that used for PCA-CGB. However, the parameters used for AdaBoost were slightly different; therefore, n_estimators and learning_rate were selected. The selected hyper-parameter range and obtained values are shown in
Table 7.
Once the optimal hyper-parameters were tuned, classifiers with optimal hyper-parameters were employed to predict the previously unseen test samples.
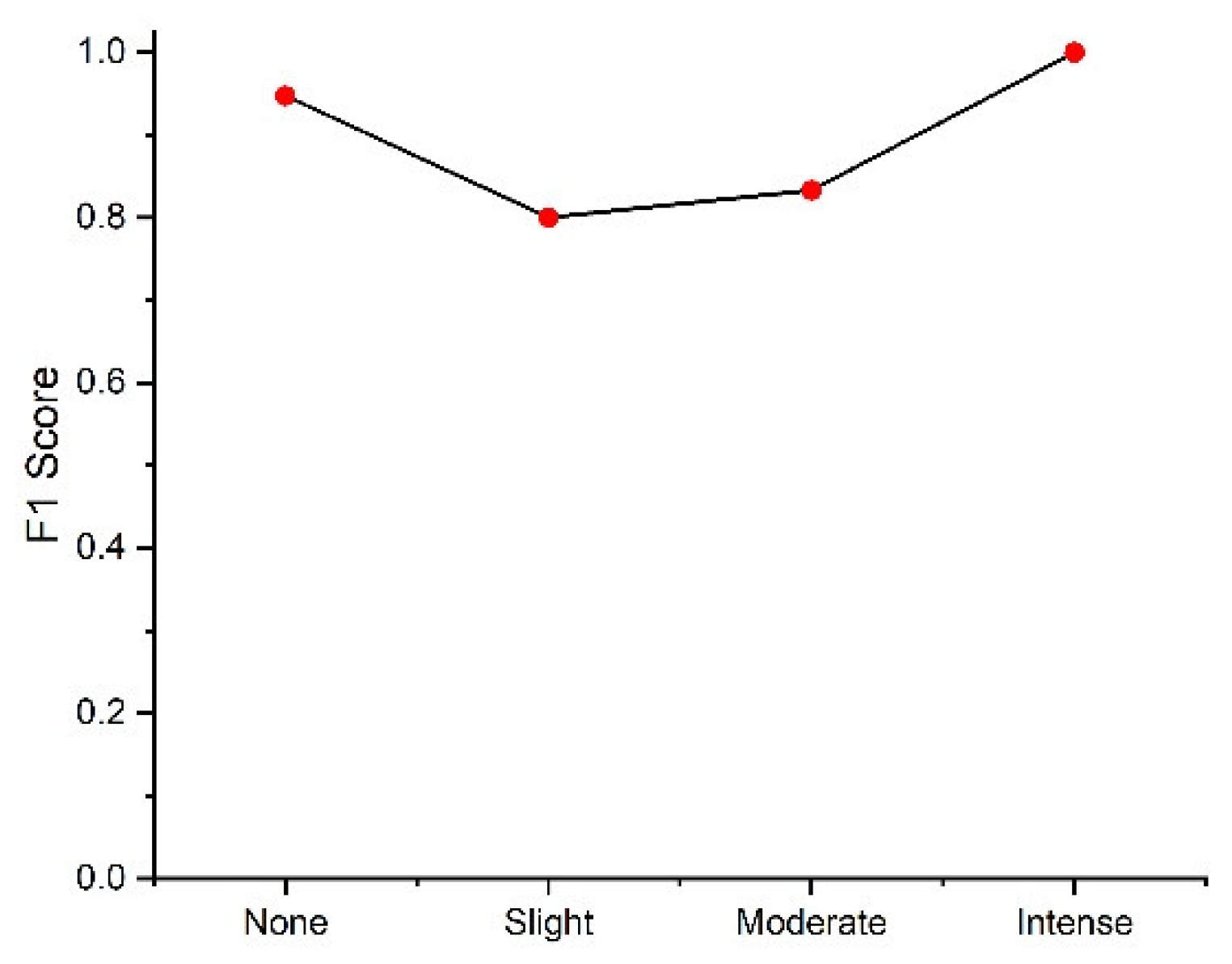
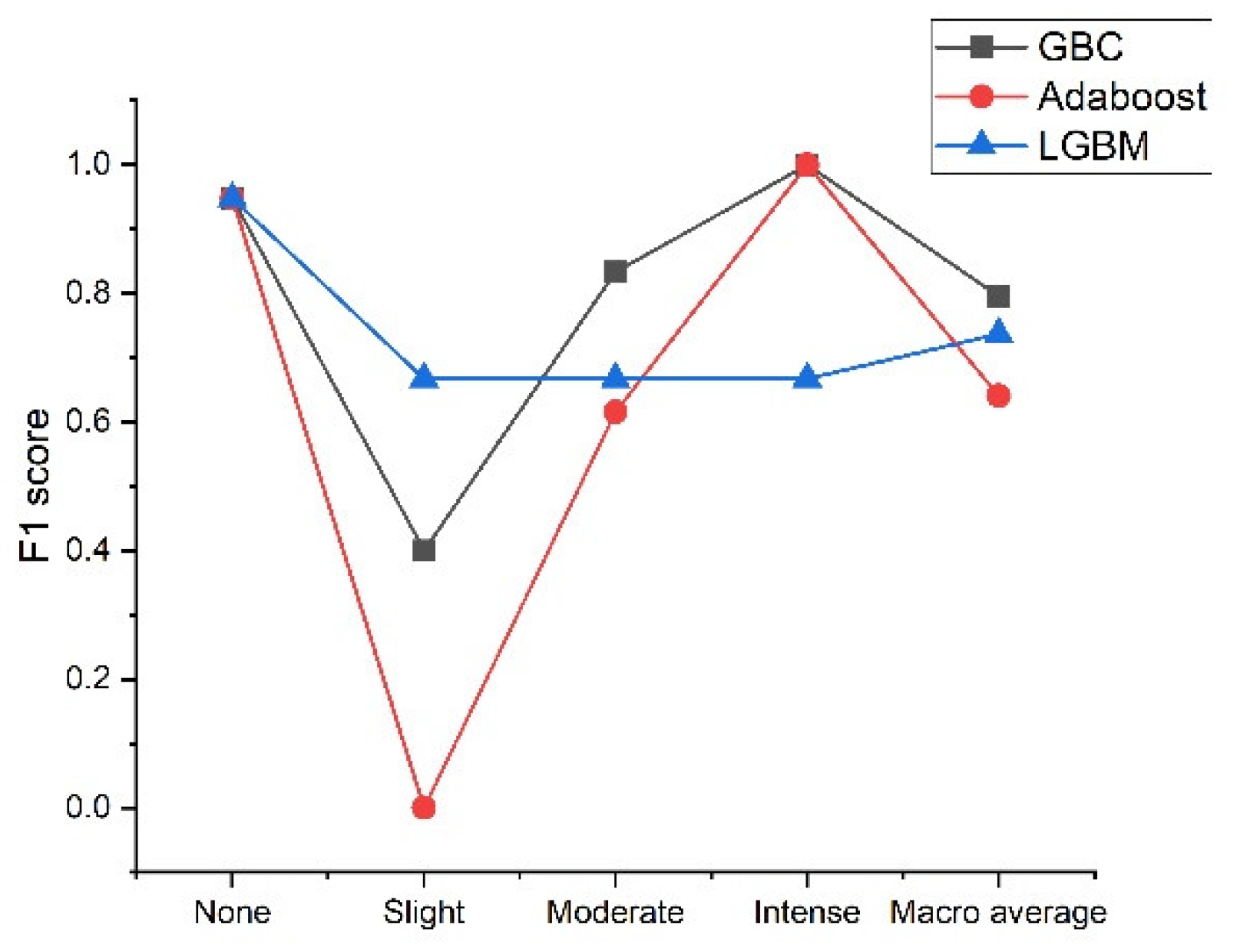
Table 8 shows the confusion matrices for GBC, AdaBoost, and LGBM. Among the three classifiers, GBC and LGBM show better results than AdaBoost. GBC misclassified one none as slight risk and two slight risks as moderate risk, whereas LGBM and AdaBoost incorrectly classified some other intensity classes as moderate risk. The F1 scores of the three classifiers are shown in
Figure 11. The figure indicates that all classifiers yield better results for none/no risk and intense risk; however, all have very low scores for slight and moderate risk. GBC, AdaBoost, and LGBM generated F1 scores of 0.7952, 0.6407, and 0.7368, respectively.
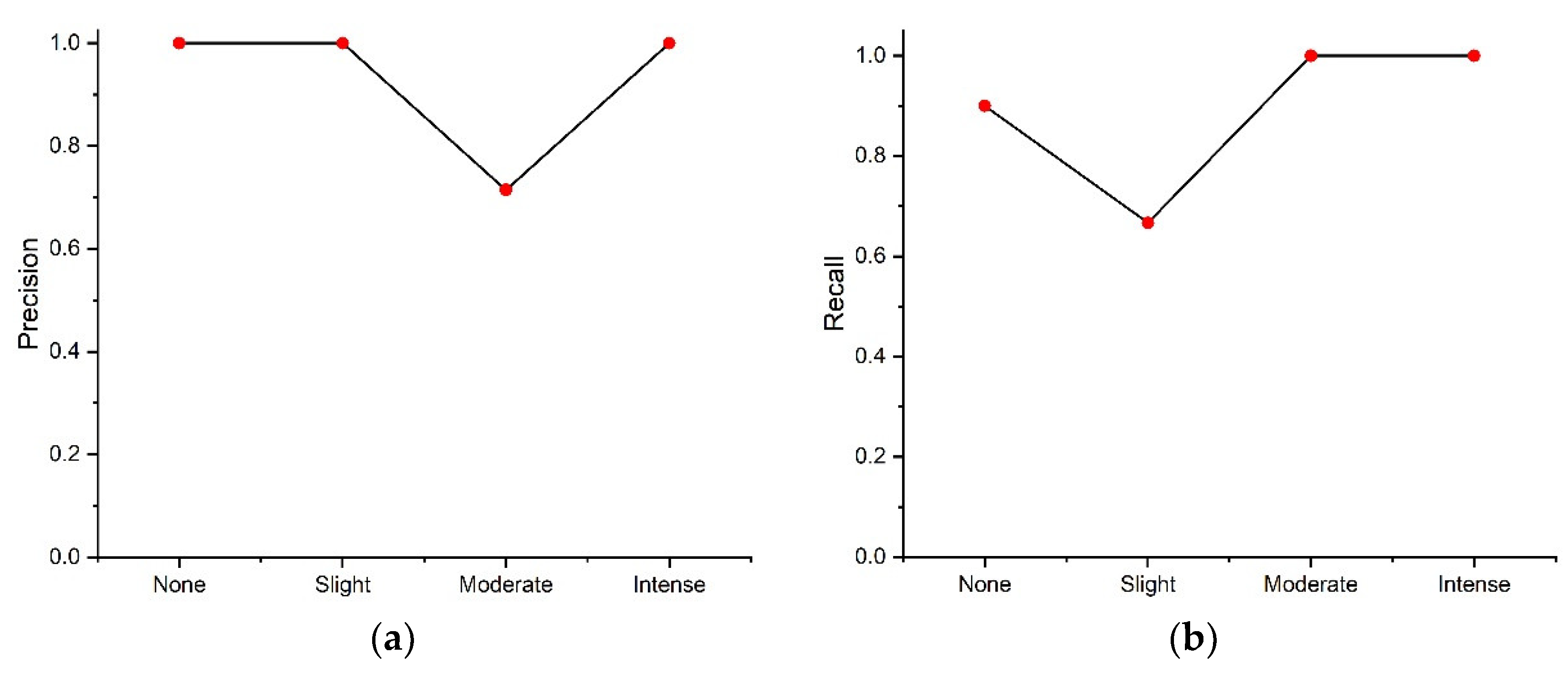
Finally, the results of PCA-CGB were compared with those of these three classifiers. In various ways, the predictive performance of the proposed work is better than those of other traditional boosting classifiers when used for imbalanced rockburst data. Although GBC, AdaBoost, and LGBM seem reasonably accurate, their F1 scores are relatively low, meaning they are less robust to the above problem of class imbalance. However, the overall performance of PCA-CGB is superior concerning precision, recall, and F1 score measure, indicating that it is more reliable and possesses greater predictive power than the other boosting classifiers.
Further, in terms of F1 scores, we can discuss the performance in relation to previous work on the subject, including [
18,
22,
40], which acquired F1 scores of 0.66, 0.8779, and 0.8631, respectively. However, the results are not directly comparable due to differences in the dataset sizes because samples for training and variables that appear in the different studies vary marginally. However, to make class distribution more diverse in this study, more cases were gathered to expand the dataset size, and a larger dataset was used compared to those in other studies. When the data are more complex, feeding a lower quantity of data for training may cause an underfitting problem, and the model loses generalisation. Therefore, more samples were used during training to ensure the model obtained enough records to learn the pattern between inputs and output. Overall, the final result for the previously unseen test set reveals that in unequally distributed data, the F1 score of the proposed approach still yields better results for all types of risk severity compared to other works, which have a low error rate even for the datasets that are mostly complex and consist of relatively few data points for particular class.
6. Discussion and Limitations
Prediction of rockbursts in underground engineering using intelligent models should focus on correctly classifying each class equally. Generally, classical ML methods assume that all classes are equally distributed. However, when a dataset has a problem of class imbalance, relying on a single accuracy measure could be misleading because the model may correctly classify members of the majority class but fail to identify members of the minority class. In this scenario, relying on a single measure of accuracy may not be entirely reliable. For the purposes of controlling economic losses and promoting safety, the prediction of each intensity class is equally important.
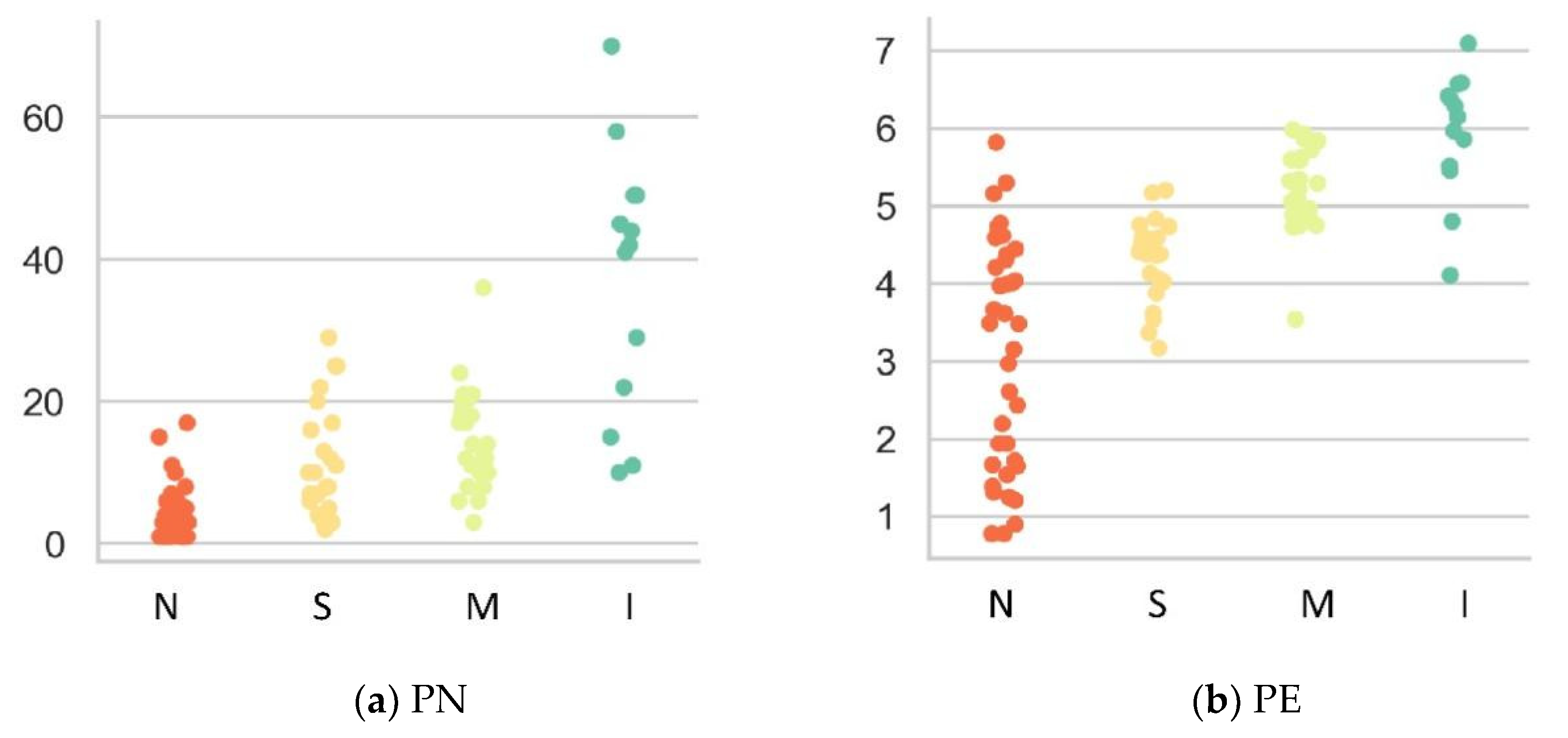
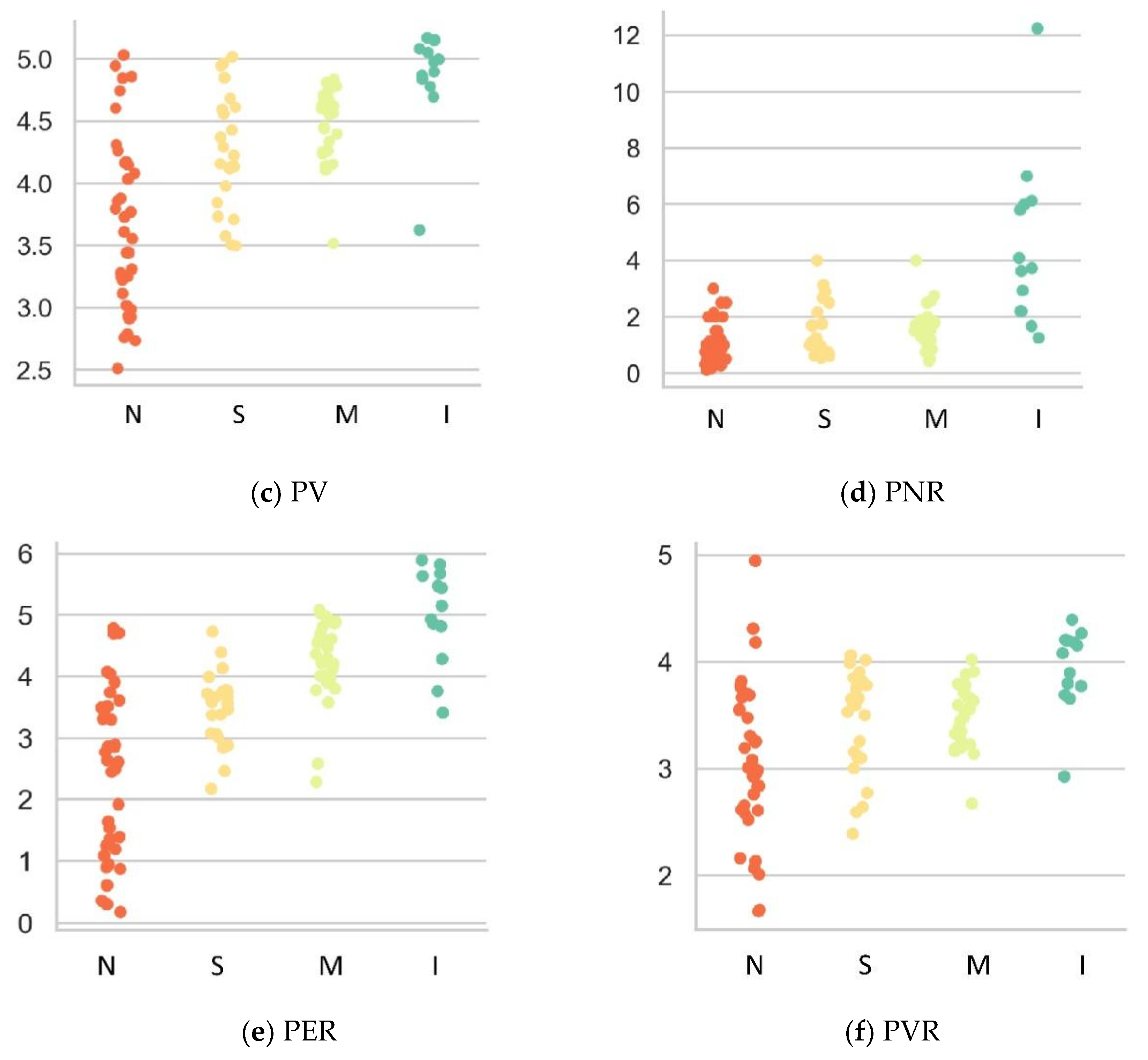
Section 3.3 shows that the model is highly accurate for the majority class (none/no risk) and minority class (intense risk). However, there are some inaccurate outcomes for two other minority classes, slight risk and moderate risk. If we rely on accuracy alone, the model may seem highly accurate. However, the model may fail to classify other minority classes equally, and the misclassification of these types of low-risk events as high-risk rockburst events could have serious implications. Most previous approaches that used classical ML methods relied on a single accuracy measure to evaluate the classifier’s performance. Rather than depending on a single metric, this study used precision, recall, and F1 scores because they indicate how robust the classifier is when applied to imbalanced classes. If the model’s performance is compared using the F1 score, it is reasonable and acceptable to suggest that it is not susceptible to performance problems associated with imbalanced cases and has greater power to distinguish among classes. The model’s performance can also be confirmed when it is applied to rockburst classes that constitute a less extreme minority, as it can accurately identify events in such classes. Nevertheless, the model yields a slightly lower F1 score for slight and moderate rockbursts, the primary reason for which might be uncertainties and overlap between the two cases, which in turn might have led to misclassifications. Despite this issue, PCA-CGB is still more powerful than traditional boosting classifiers because while they seem accurate, they have lower scores in other metrics, indicating that their performance in predicting rockburst data is weak.
Although the proposed method yielded satisfactory results, the dataset size is still relatively small compared to those seen in common ML tasks. In common practice, ML methods rely heavily on huge datasets for better generalisation. Very small datasets can significantly lower performance by underfitting or overfitting the model. Thus, future research should focus on enhancing the model’s robustness by developing a model from larger datasets.
7. Conclusions
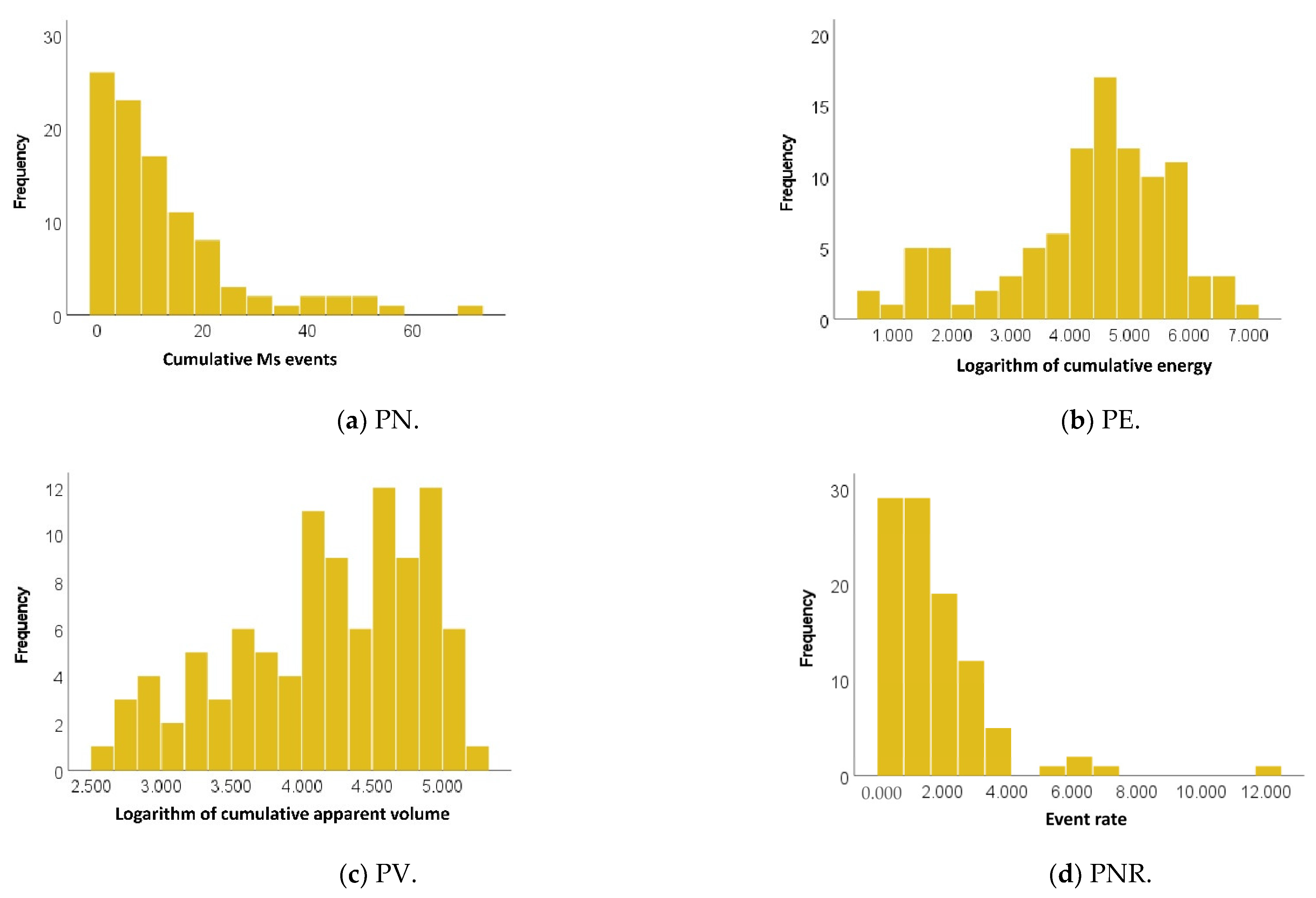
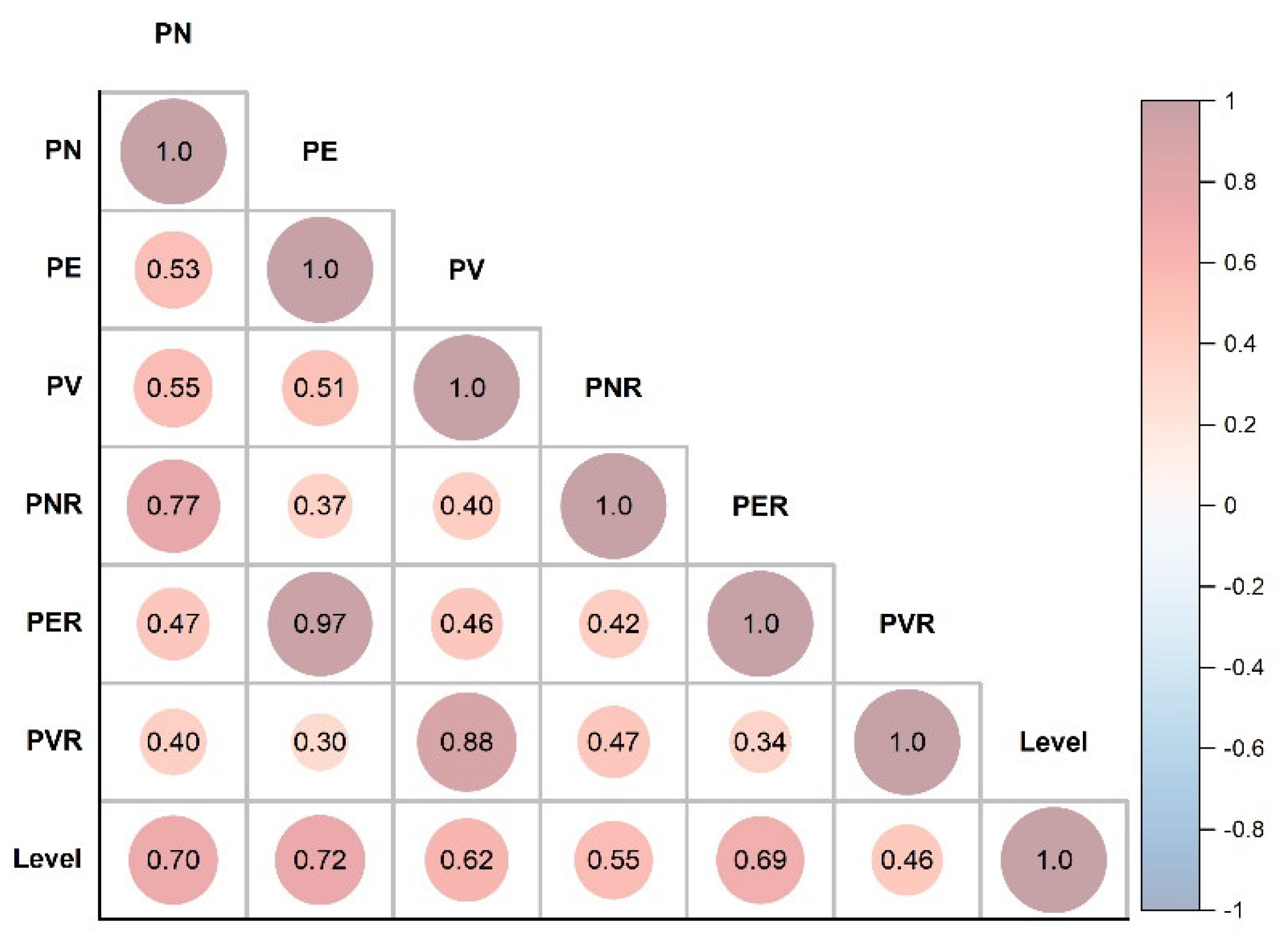
Predicting short-term rockburst risk accurately has always been important, as it directly threatens the safety of personnel, equipment, and subsurface structures. Equally, classifying risk severity is essential to allowing the adoption of efficient control measures to avoid economic loss and ensure personnel safety. However, reliably distinguishing among risk levels is often challenging due to class-imbalance issues. Most existing work relies on models with high accuracy, but some of them cannot perform well with imbalanced data. Hence, this work proposes a simple, intelligent predictive method combining unsupervised learning, principal component analysis (PCA), and supervised categorical gradient-boosting (CGB) approaches to intelligently predict rockburst risk levels. The value of this method is that it can generate predictions on unequally distributed classes more efficiently than classical ML models can. The real engineering data based on microseismic information were as assembled into a supportive database comprising six features. The variables have high correlation; therefore, PCA reduces redundancy among variables. After reducing the original dimension into three components, the CGB is adopted to create a PCA-CGB model to predict rockburst risk. To ensure that the optimal model is produced, hyper-parameters are tuned to obtain the best output. The model’s predictive performance was evaluated using precision, recall, and F1 score and further compared with three traditional boosting techniques to check for feasibility. The results showed that, regarding multiple performance measures, CGB with PCA data surpassed all conventional techniques and achieved precision, recall, and F1 scores of 0.9286, 0.8917, and 0.8952, respectively. In particular, when dataset have higher degree of correlation and classes are unevenly distributed, the output of PCA-CGB is more stable and effectively identifies majority and minority classes at higher rates than do the conventional methods. The final model also predicts new cases collected from the underground engineering project, accurately matching the corresponding actual events. The proposed work supports the management of rockburst risk because it can categorise and classify various risk levels with a degree of accuracy.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}