
An Empirical Study on Core Data Asset Identification in Data Governance


Abstract
:1. Introduction
2. Related Works
2.1. Related Literature on Data Governance
2.2. Related Literature on Data Classification
2.3. Related Literature on Graph Perception
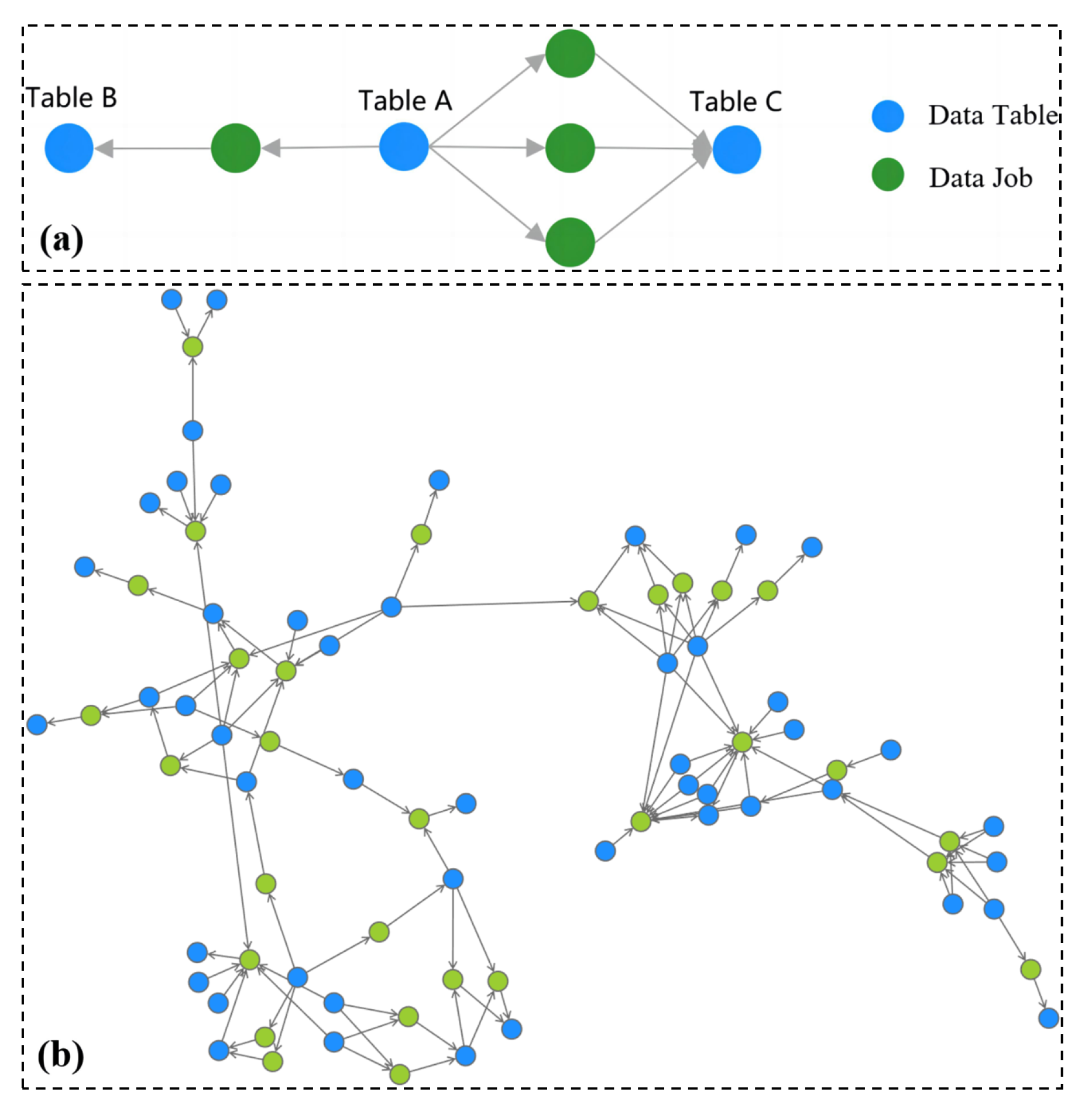
3. Experimental Design
3.1. Experiment on Scenario Perspective
- (1)
- Experimental Objective
- (2)
- Experimental Method
- (3)
- Experimental Result
3.2. Experiment on Abstraction Perspective
- (1)
- Experimental Objective
- (2)
- Experimental Method
- (3)
- Experimental Result
3.3. Expert Seminar
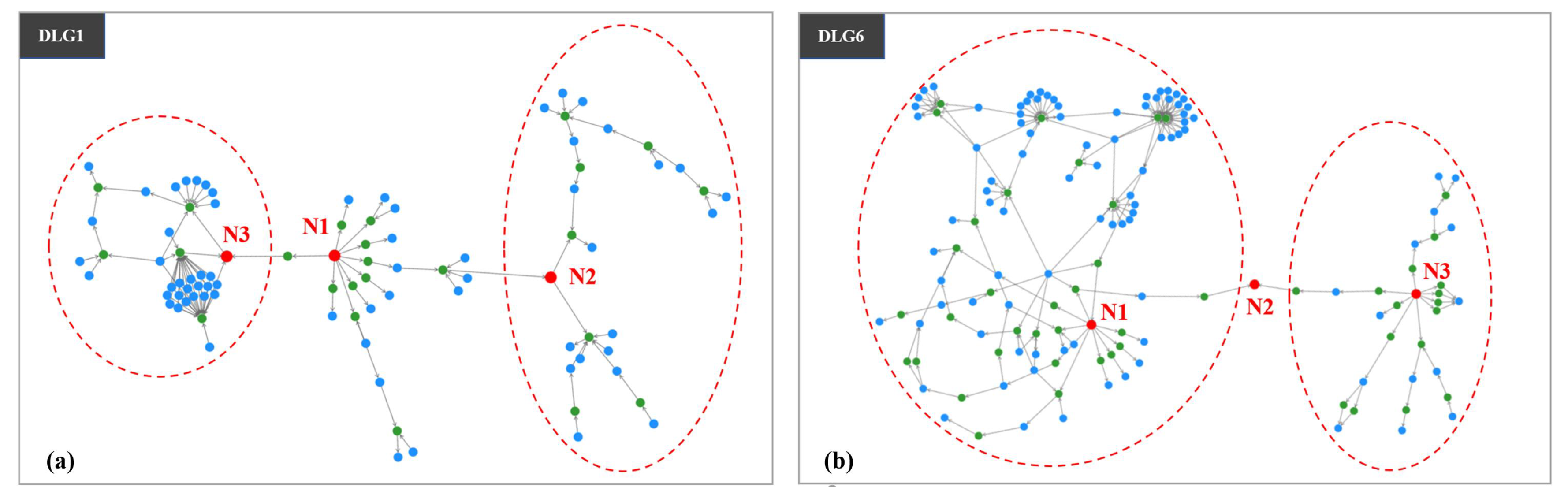
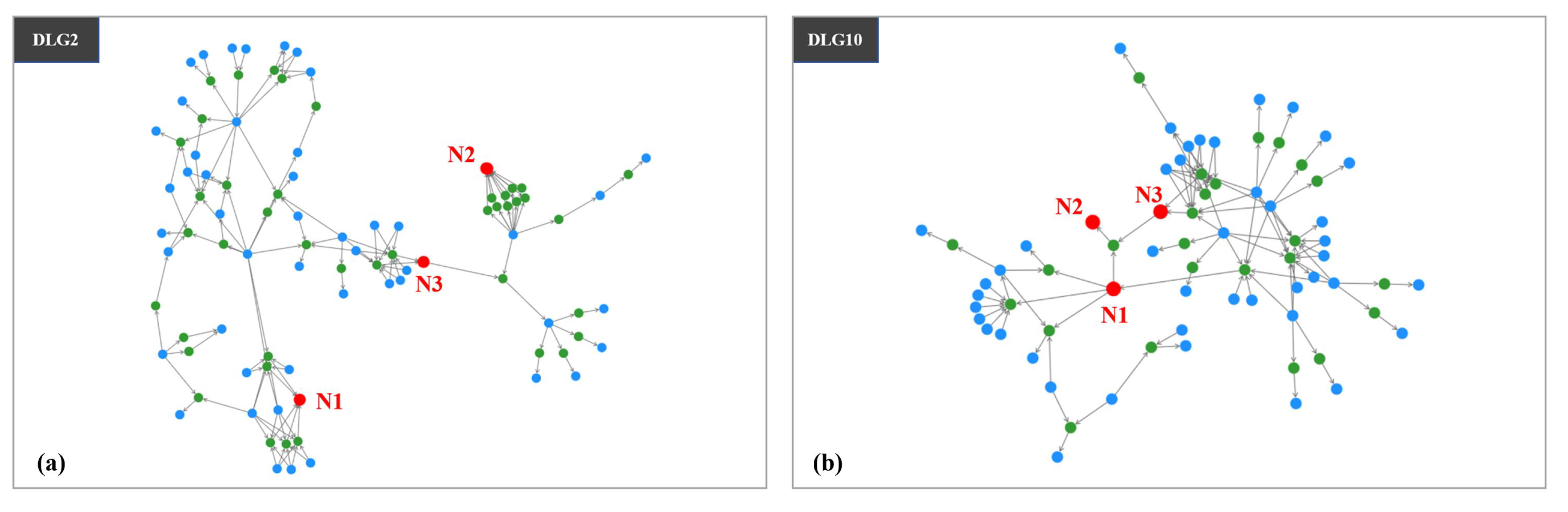
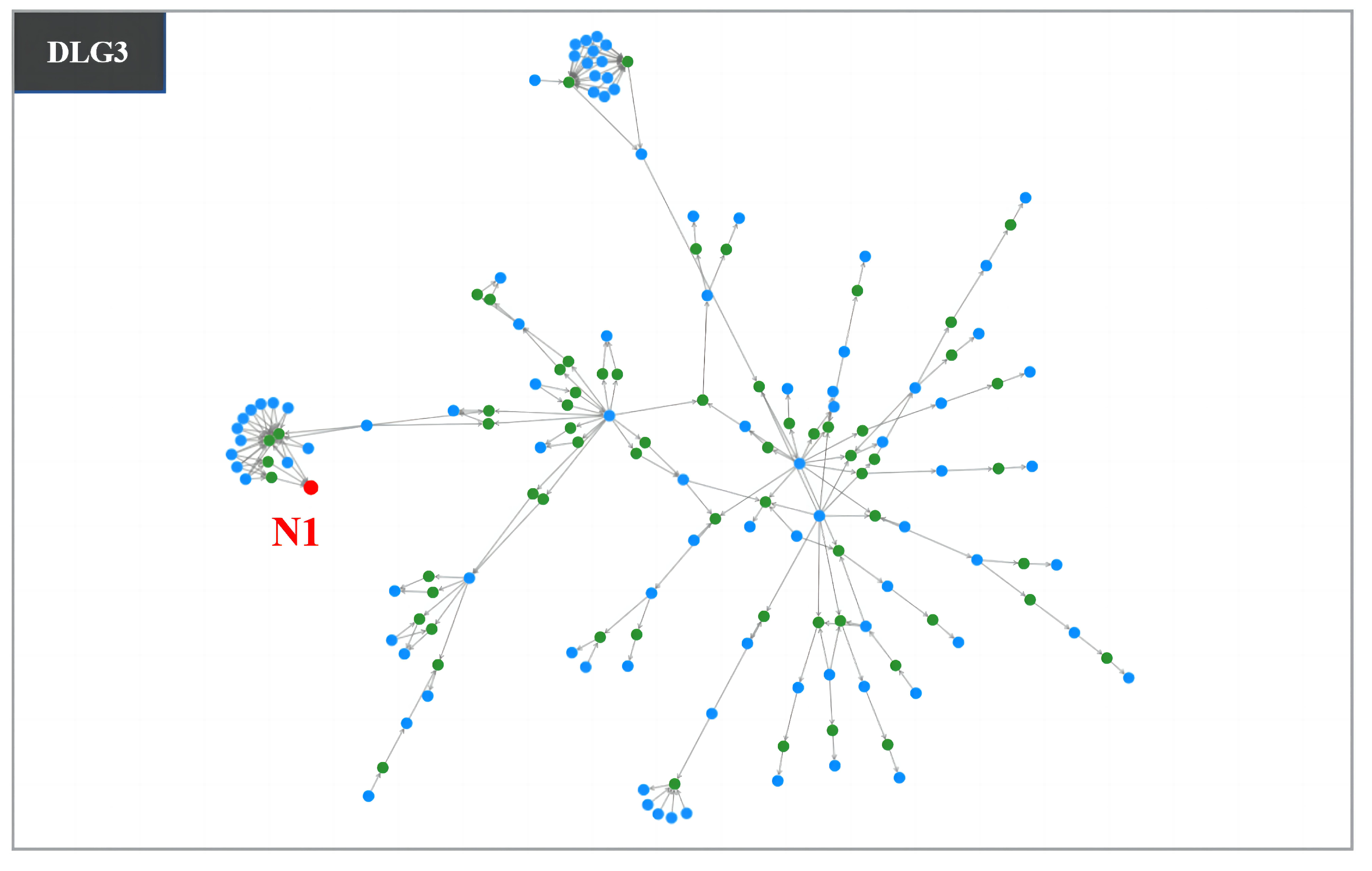
4. Evaluation
4.1. User Study
4.2. Field Study
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hannila, H.; Silvola, R.; Harkonen, J.; Haapasalo, H. Data-driven Begins with DATA; Potential of Data Assets. J. Comput. Inf. Syst. 2022, 62, 29–38. [Google Scholar] [CrossRef]
- Janssen, M.; Brous, P.; Estevez, E.; Barbosa, L.S.; Janowski, T. Data Governance: Organizing Data for Trustworthy Artificial Intelligence. Gov. Inf. Q. 2020, 37, 101493. [Google Scholar] [CrossRef]
- Abraham, R.; Schneider, J.; Brocke, J.V. Data Governance: A Conceptual Framework, Structured Review, and Research Agenda. Int. J. Inf. Manag. 2019, 49, 424–438. [Google Scholar]
- Bergström, E.; Karlsson, F.; Åhlfeldt, R. Developing an Information Classification Method. Inf. Comput. Secur. 2021, 29, 209–239. [Google Scholar] [CrossRef]
- Park, Y.; Teiken, W.; Rao, J.R.; Chari, S.N. Data Classification and Sensitivity Estimation for Critical Asset Discovery. IBM J. Res. Dev. 2016, 60, 2:1–2:12. [Google Scholar] [CrossRef]
- Gibson, H.; Faith, J.; Vickers, P. A Survey of Two-dimensional Graph Layout Techniques for Information Visualisation. Inf. Vis. 2013, 12, 324–357. [Google Scholar] [CrossRef]
- Li, J.; Liu, Y.; Wang, C. Evaluation of Graph Layout Methods Based on Visual Perception. In Proceedings of the 10th Indian Conference on Computer Vision, Graphics, and Image Processing, New York, NY, USA, 18–22 December 2016; pp. 1–7. [Google Scholar]
- Wu, Y.; Cao, N.; Archambault, D. Evaluation of Graph Sampling: A Visualization Perspective. IEEE Trans. Vis. Comput. Graph. 2017, 23, 401–410. [Google Scholar] [CrossRef]
- Ladley, J. Data Governance: How to Design, Deploy, and Sustain an Effective Data Governance Program; Elsevier Science: Amsterdam, The Netherlands, 2019; pp. 16–18. [Google Scholar]
- Veroniki, S.K.; Christos, I.; Richard, O.; Christos, G.; Demosthenes, S. Insider Threats in Corporate Environments: A Case Study for Data Leakage Prevention. In Proceedings of the Fifth Balkan Conference in Informatics, Novi Sad, Serbia, 16 September 2012; pp. 271–274. [Google Scholar]
- Schlackl, F.; Link, N.; Hoehle, H. Antecedents and Consequences of Data Breaches: A Systematic Review. Inf. Manag. 2021, 59, 103638. [Google Scholar]
- Dhillon, G.; Smith, K.; Dissanayaka, I. Information Systems Security Research Agenda: Exploring the Gap Between Research and Practice. J. Strateg. Inf. Syst. 2021, 30, 101693. [Google Scholar] [CrossRef]
- Liginlal, D.; Sim, I.; Khansa, L. How significant is human error as a cause of privacy breaches? An empirical study and a framework for error management. Comput. Secur. 2009, 28, 215–228. [Google Scholar] [CrossRef]
- Kamoun, F.; Nicho, M. Human and Organizational Factors of Healthcare Data Breaches: The Swiss Cheese Model of Data Breach Causation and Prevention. Int. J. Healthc. Inf. Syst. Inform. 2014, 9, 42–60. [Google Scholar] [CrossRef]
- Ayyagari, R. An Exploratory Analysis of Data Breaches from 2005–2011: Trends and Insights. J. Inf. Priv. Secur. 2012, 8, 33–56. [Google Scholar] [CrossRef]
- Liu, C.; Huang, P.; Lucas, H. Centralized IT Decision Making and Cybersecurity Breaches: Evidence from U.S. Higher Education Institutions. J. Manag. Inf. Syst. 2020, 37, 758–787. [Google Scholar] [CrossRef]
- Higgs, J.L.; Pinsker, R.E.; Smith, T.J.; Young, G.R. The Relationship between Board-Level Technology Committees and Reported Security Breaches. J. Manag. Inf. Syst. 2016, 30, 79–98. [Google Scholar] [CrossRef]
- Sung, W.; Kang, S. An Empirical Study on the Effect of Information Security Activities: Focusing on Technology, Institution, and Awareness. In Proceedings of the 18th Annual International Conference on Digital Government Research, New York, NY, USA, 7 June 2017; pp. 84–93. [Google Scholar]
- Kim, S.H.; Kwon, J. How Do EHRs and a Meaningful Use Initiative Affect Breaches of Patient Information? Inf. Syst. Res. 2019, 30, 1107–1452. [Google Scholar] [CrossRef]
- Kwon, J.; Im, G. Data Breaches in Multihospital Systems: Antecedents and Mitigation Mechanisms. In Proceedings of the 40th International Conference on Information Systems, New Delhi, India, 13 December 2020; pp. 84–93. [Google Scholar]
- McLeod, A.; Dolezel, D. Cyber-analytics: Modeling Factors Associated with Healthcare Data Breaches. Decis. Support Syst. 2018, 3, 57–68. [Google Scholar] [CrossRef]
- Ransbotham, S.; Mitra, S. Choice and Chance: A Conceptual Model of Paths to Information Security Compromise. Inf. Syst. Res. 2009, 20, 1–157. [Google Scholar] [CrossRef]
- Kweon, E.; Lee, H.; Chai, S.; Yoo, K. The Utility of Information Security Training and Education on Cybersecurity Incidents: An Empirical Evidence. Inf. Syst. Front. 2021, 2, 361–373. [Google Scholar] [CrossRef]
- Cavusoglu, H.; Mishra, B.; Raghunathan, S. The Value of Intrusion Detection Systems in Information Technology Security Architecture. Inf. Syst. Res. 2005, 16, 28–46. [Google Scholar] [CrossRef]
- Kwon, J.; Johnson, M.E. Health-Care Security Strategies for Data Protection and Regulatory Compliance. J. Manag. Inf. Syst. 2013, 30, 41–66. [Google Scholar] [CrossRef]
- Miller, A.R.; Tucker, C.E. Encryption and The Loss of Patient Data. J. Policy Anal. Manag. 2011, 30, 534–556. [Google Scholar] [CrossRef] [PubMed]
- Mitra, S.; Ransbotham, S. Information Disclosure and the Diffusion of Information Security Attacks. Inf. Syst. Res. 2005, 16, 473–636. [Google Scholar] [CrossRef]
- Hausken, K. Information Sharing Among Firms and Cyber Attacks. J. Account. Public Policy 2005, 26, 639–688. [Google Scholar] [CrossRef]
- Gao, X.; Zhong, W.; Shue, M. Security Investment and Information Sharing under an Alternative Security Breach Probability Function. Inf. Syst. Front. 2015, 17, 423–438. [Google Scholar] [CrossRef]
- Beaver, J.M.; Patton, R.M.; Potok, T.E. An Approach to the Automated Determination of Host Information Value. In Proceedings of the 23th IEEE Symposium on Computational Intelligence in Cyber Security, Paris, France, 11 April 2011; pp. 92–99. [Google Scholar]
- Youngja, P.; Stephen, G.; Wilfried, T.; Suresh, C. System for Automatic Estimation of Data Sensitivity with Applications to Access Control and Other Applications. In Proceedings of the 16th ACM Symposium on Access Control Models and Technologies, Innsbruck, Austria, 15 June 2011; pp. 145–146. [Google Scholar]
- Beaudoin, L.; Eng, P. Asset Valuation Technique for Network Management and Security. In Proceedings of the 6th IEEE International Conference on Data Mining-Workshops, Innsbruck, Austria, 18 December 2006; pp. 718–721. [Google Scholar]
- Sawilla, R.E.; Ou, X. Identifying Critical Attack Assets in Dependency Attack Graphs. In Proceedings of the 13th European Symposium on Research in Computer Security, Málaga, Spain, 6 October 2008; pp. 18–34. [Google Scholar]
- Huang, W.; Eades, P.; Hong, S.-H.; Been-Lirn Duh, H. Effects of Curves on Graph Perception. In Proceedings of the 2016 IEEE Pacific Visualization Symposium, Taipei, Taiwan, 5 May 2016; pp. 199–203. [Google Scholar]
- Marriott, K.; Purchase, H.; Wybrow, M.; Goncu, C. Memorability of Visual Features in Network Diagrams. IEEE Trans. Vis. Comput. Graph. 2012, 18, 2477–2485. [Google Scholar] [CrossRef]
- McGrath, C.; Blythe, J.; Krackhardt, D. The Effect of Spatial Arrangement on Judgments and Errors in Interpreting Graphs. Soc. Netw. 1997, 19, 223–242. [Google Scholar] [CrossRef]
- Chen, M.; Ouyang, J.; Jian, A.; Liu, J.; Li, P.; Hao, Y.; Gong, Y.; Hu, J.; Zhou, J.; Wang, R.; et al. Imperceptible, Designable, and Scalable Braided Electronic Cord. Nat. Commun. 2022, 13, 7097. [Google Scholar] [CrossRef]
- Kypridemou, E.; Zito, M.; Bertamini, M. The Effect of Graph Layout on the Perception of Graph Properties. In Proceedings of the 22th Eurographics Conference on Visualization, Norrköping, Sweden, 25 May 2020; pp. 15–20. [Google Scholar]
- Hao, Y.; Hu, L.; Chen, M. Joint Sensing Adaptation and Model Placement in 6G Fabric Computing. IEEE J. Sel. Areas Commun. 2023, 41, 2013–2024. [Google Scholar] [CrossRef]
- Ham, F.V.; Rogowitz, B. Perceptual Organization in User-generated Graph Layouts. IEEE Trans. Vis. Comput. Graph. 2008, 14, 1333–1339. [Google Scholar]
- Rahman, R.A.; Sommer, W. Seeing What We Know and Understand: How Knowledge Shapes Perception. Psychon. Bull. Rev. 2008, 15, 1055–1063. [Google Scholar] [CrossRef]
- Lupyan, G. Objective Effects of Knowledge on Visual Perception. J. Exp. Psychol. Hum. Percept. Perform. 2017, 43, 794–806. [Google Scholar] [CrossRef] [PubMed]
- Saxena, A.; Iyengar, S. Centrality Measures in Complex Networks: A Survey. arXiv 2020. [Google Scholar] [CrossRef]
- Zhao, Y.; Yang, K.; Chen, S.; Zhang, Z.; Huang, X.; Li, Q.; Ma, Q.; Luan, X.; Fan, X. A Benchmark for Visual Analysis of Insider Threat Detection. Sci. China Inf. Sci. 2022, 65, 199102. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, X.; Chen, S.; Zhang, Z.; Huang, X. An Indoor Crowd Movement Trajectory Benchmark Dataset. IEEE Trans. Reliab. 2021, 70, 1368–1380. [Google Scholar] [CrossRef]
- Zhao, Y.; Shi, J.; Liu, J.; Zhao, J.; Zhou, F.; Zhang, W.; Chen, W. Evaluating Effects of Background Stories on Graph Perception. IEEE Trans. Vis. Comput. Graph. 2022, 28, 4839–4854. [Google Scholar] [CrossRef] [PubMed]
- Burch, M.; Brinke, K.B.t.; Castella, A.; Peters, G.K.S.; Shteriyanov, V.; Vlasvinkel, R. Dynamic Graph Exploration By Interactively Linked Node-Link Diagrams and Matrix Visualizations. Vis. Comput. Ind. Biomed. Art 2021, 4, 23. [Google Scholar] [CrossRef]
- Cauteruccio, F.; Terracina, G. Extended High-Utility Pattern Mining: An Answer Set Programming-Based Framework and Applications. Theory Pract. Log. Program. 2023, 1, 1–31. [Google Scholar] [CrossRef]
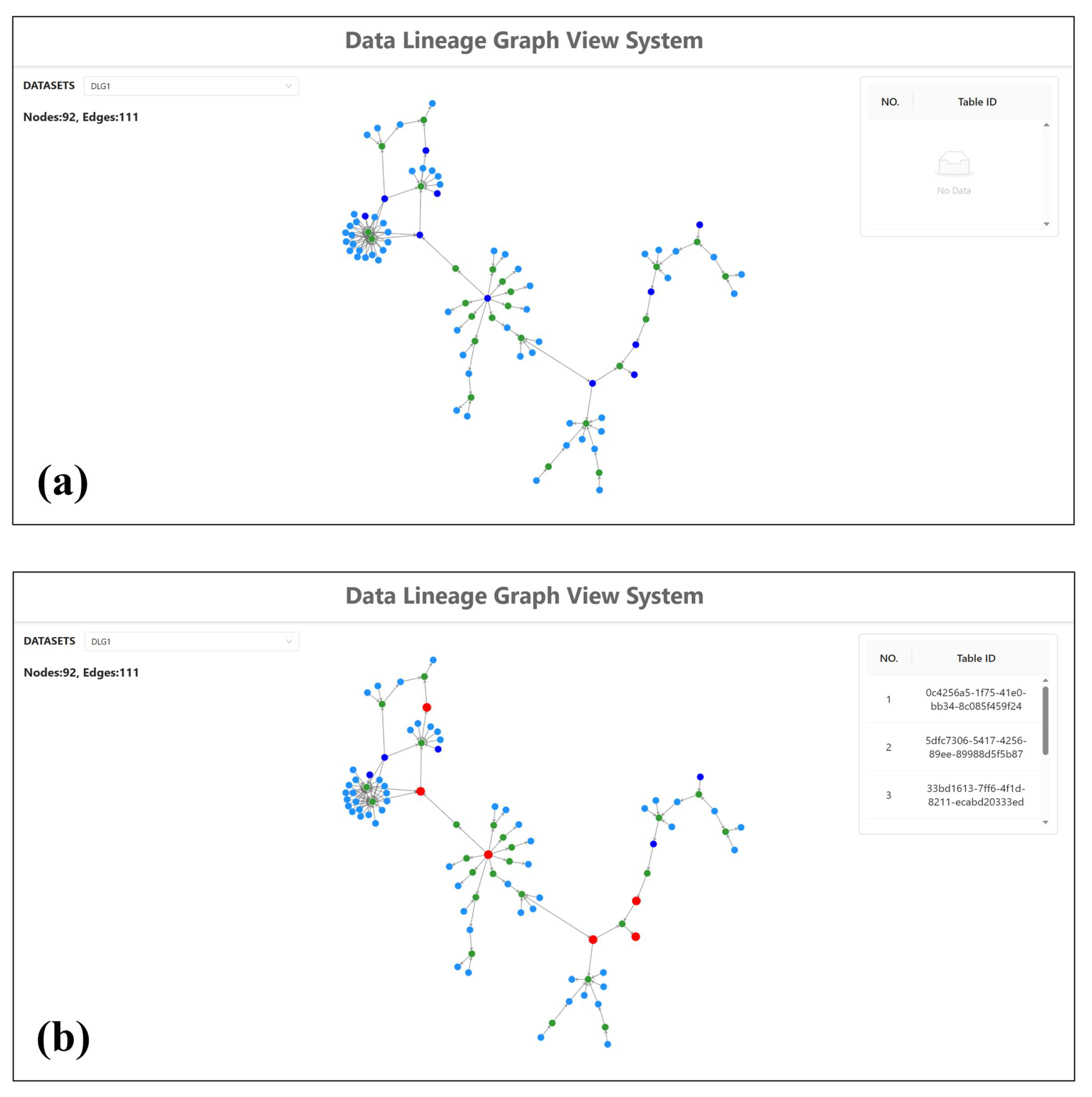

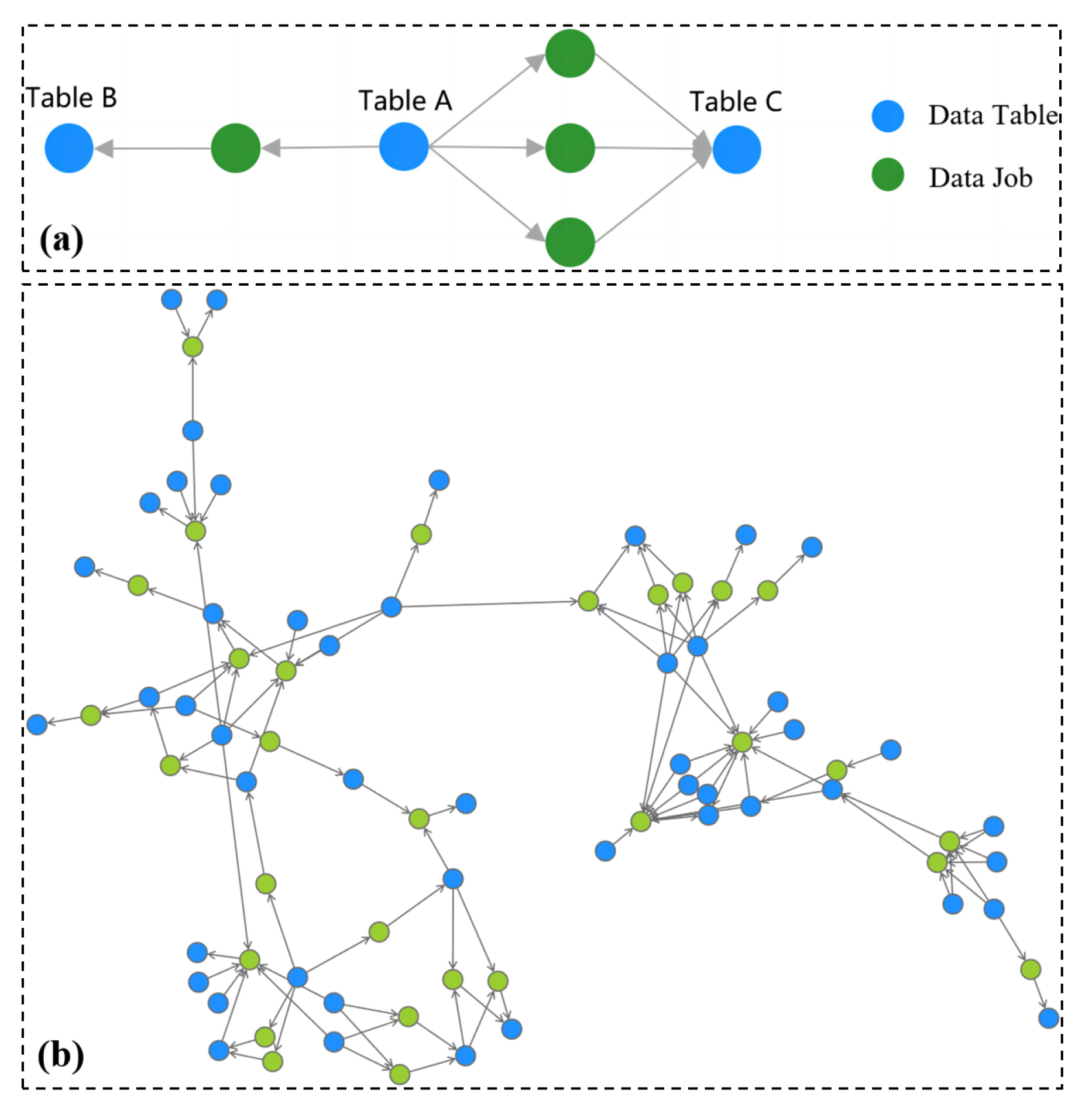{kind=link}
{kind=link}
{kind=link}
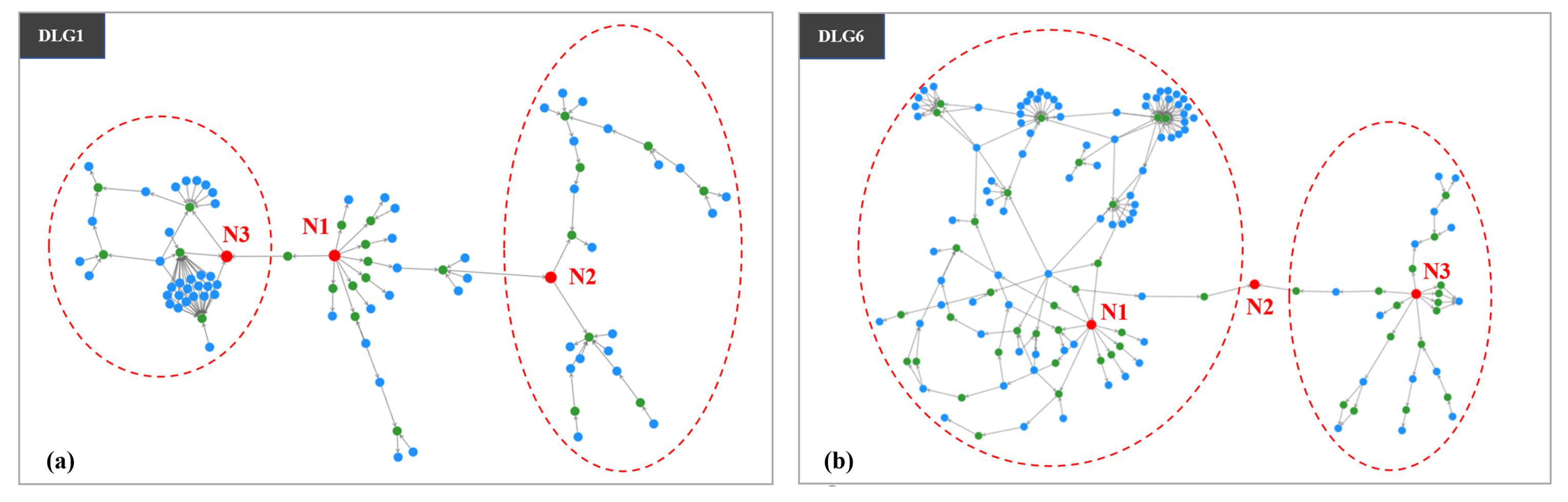
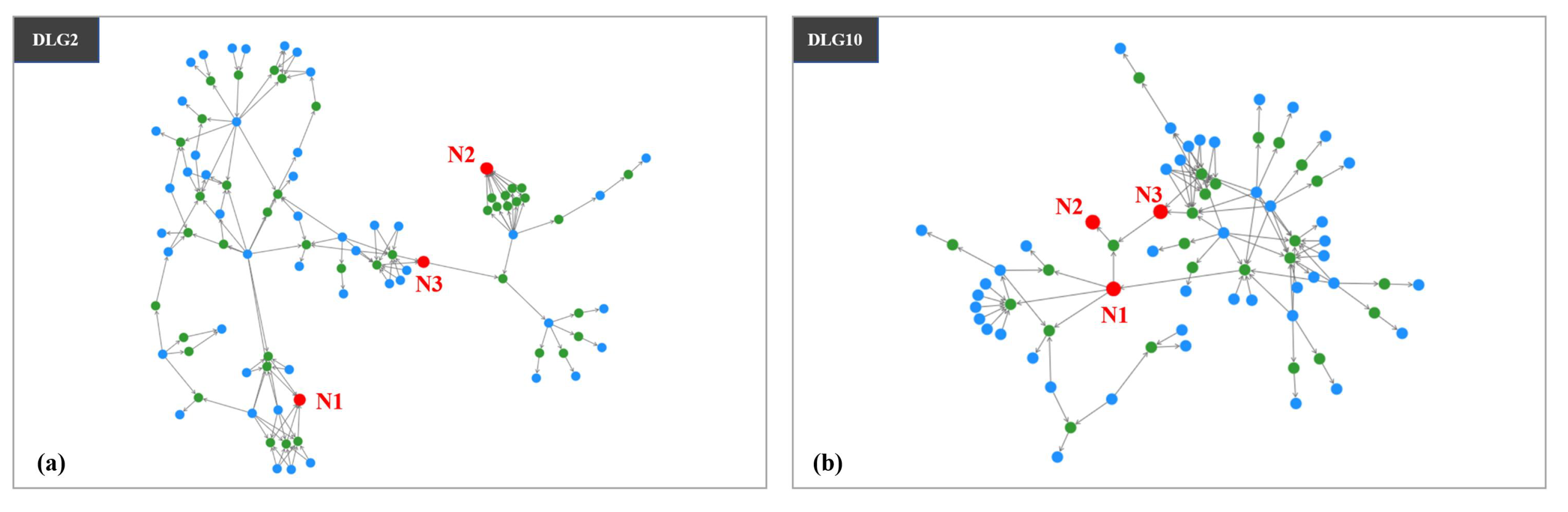
{kind=link}
{kind=link}
| Scenario | ID | Nodes | Edges | Core Data Asset |
|---|---|---|---|---|
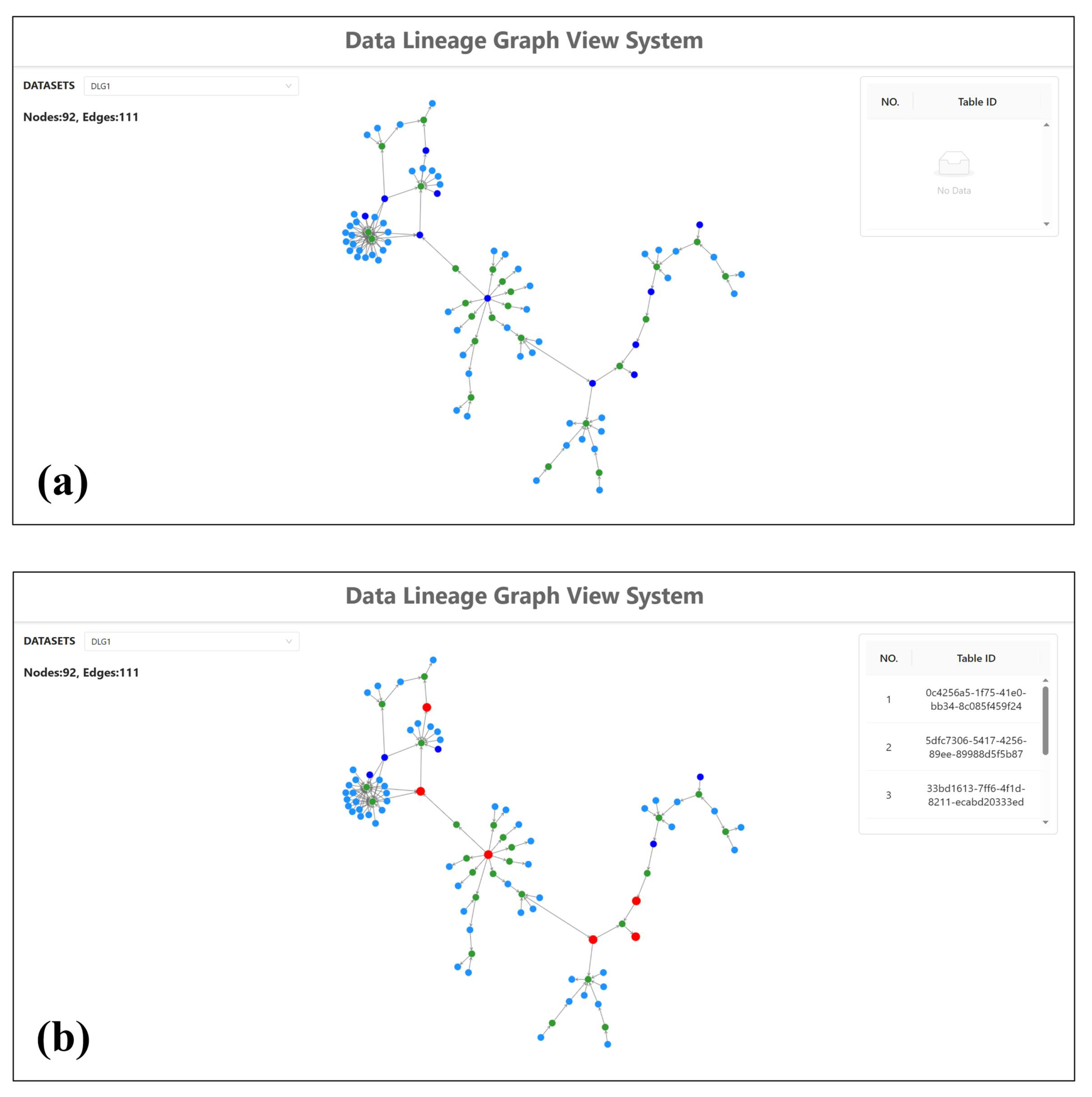
| Cloud Infrastructure | DLG1 | 92 | 111 | 6 |
| DLG2 | 94 | 141 | 6 | |
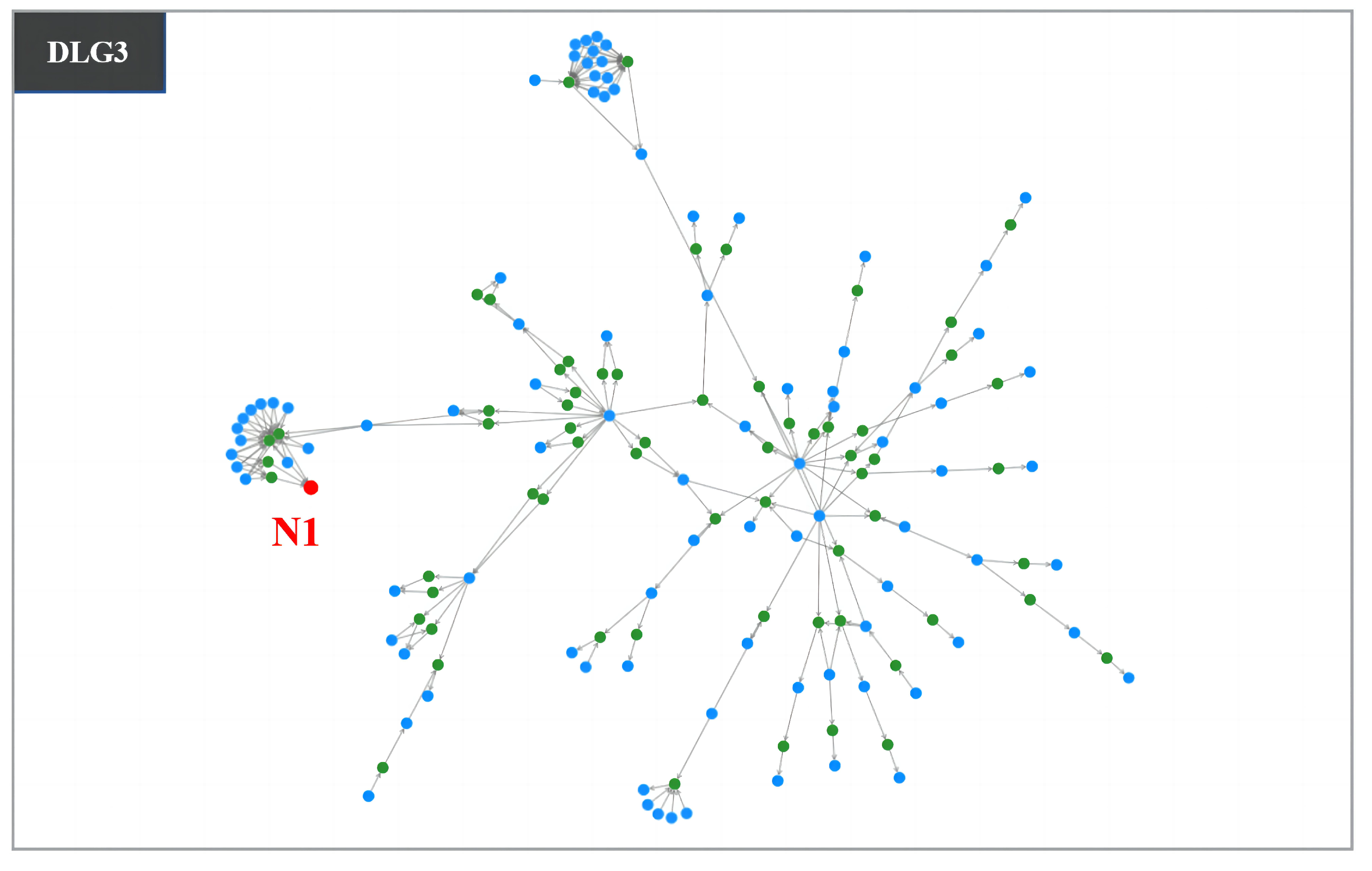
| DLG3 | 157 | 211 | 8 | |
| DLG4 | 305 | 526 | 19 | |
| Customer Service | DLG5 | 100 | 149 | 7 |
| DLG6 | 144 | 185 | 10 | |
| DLG7 | 380 | 572 | 24 | |
| DLG8 | 90 | 122 | 6 | |
| Operation Analysis | DLG9 | 91 | 185 | 7 |
| DLG10 | 74 | 99 | 6 |
| Node Centrality Metric | Precision | Recall |
|---|---|---|
| * Degree Centrality | 41% | 40% |
| Semi-Local Centrality | 26% | 25% |
| * LocalRank Centrality | 41% | 40% |
| ClusterRank Centrality | 19% | 18% |
| K-shell Decomposition Centrality | 26% | 24% |
| Closeness Centrality | 26% | 25% |
| Eccentricity | 18% | 17% |
| * Flow Betweenness Centrality | 45% | 44% |
| Shortest Path Betweenness Centrality | 28% | 27% |
| Random Walk Betweenness Centrality | 30% | 29% |
| * Information Centrality | 43% | 42% |
| Katz Centrality | 13% | 12% |
| Routing Betweenness Centrality | 14% | 13% |
| Communicability Centrality | 15% | 14% |
| Harmonic Centrality | 20% | 19% |
| Local Research Centrality | 20% | 19% |
| Subgraph Centrality | 16% | 14% |
| Traffic Load Centrality | 14% | 13% |
| Percolation Centrality | 23% | 22% |
| Shortest Path of Node Deletion | 22% | 22% |
| Spanning Tree of Node Deletion | 20% | 19% |
| Node Contraction | 26% | 25% |
| Residual Closeness Centrality | 0% | 0% |
| * PageRank | 28% | 27% |
| * Eigenvector Centrality | 40% | 39% |
| H-index | 18% | 17% |
| HITs | 14% | 13% |
| Automatic Resource Compilation | 23% | 22% |
| Cumulative Nomination | 25% | 24% |
| * LeaderRank | 28% | 27% |
| SALSA | 12% | 11% |
| Questions | Rating Results | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Reference Method | Our Method | ||||||||
| Manager | Expert A | Expert B | Expert C | Manager | Expert A | Expert B | Expert C | ||
| Usability | 1. Can you quickly learn the method? | 2 | 2 | 3 | 2 | 4 | 4 | 4 | 5 |
| 2. Can you master the method without specific knowledge? | 2 | 2 | 2 | 2 | 5 | 5 | 5 | 5 | |
| 3. Do you think the method is easy to use? | 4 | 3 | 3 | 4 | 4 | 4 | 4 | 4 | |
| Effectiveness | 4. Can you use the method to identify enough core data assets? | 3 | 3 | 3 | 3 | 4 | 4 | 4 | 4 |
| 5. Can you use the method to quickly identify core data assets? | 2 | 3 | 3 | 3 | 5 | 4 | 4 | 4 | |
| 6. Can you identify core assets in various scenarios? | 1 | 3 | 2 | 2 | 4 | 4 | 4 | 5 | |
| Satisfaction | 7. How satisfied are you with this method overall? | 3 | 3 | 3 | 4 | 3 | 4 | 3 | 3 |
| 8. Does this method support your daily work? | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | |
| 9. Are you satisfied with the way the data are presented? | 3 | 3 | 4 | 4 | 4 | 4 | 4 | 4 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Zhao, Y.; Xie, W.; Zhai, Y.; Zhao, X.; Zhang, J.; Long, J.; Zhou, F. An Empirical Study on Core Data Asset Identification in Data Governance. Big Data Cogn. Comput. 2023, 7, 161. https://doi.org/10.3390/bdcc7040161
Chen Y, Zhao Y, Xie W, Zhai Y, Zhao X, Zhang J, Long J, Zhou F. An Empirical Study on Core Data Asset Identification in Data Governance. Big Data and Cognitive Computing. 2023; 7(4):161. https://doi.org/10.3390/bdcc7040161
Chicago/Turabian StyleChen, Yunpeng, Ying Zhao, Wenxuan Xie, Yanbo Zhai, Xin Zhao, Jiang Zhang, Jiang Long, and Fangfang Zhou. 2023. "An Empirical Study on Core Data Asset Identification in Data Governance" Big Data and Cognitive Computing 7, no. 4: 161. https://doi.org/10.3390/bdcc7040161
APA StyleChen, Y., Zhao, Y., Xie, W., Zhai, Y., Zhao, X., Zhang, J., Long, J., & Zhou, F. (2023). An Empirical Study on Core Data Asset Identification in Data Governance. Big Data and Cognitive Computing, 7(4), 161. https://doi.org/10.3390/bdcc7040161