
A Pruning Method Based on Feature Map Similarity Score

Abstract
:1. Introduction
2. Related Works
2.1. Unstructured Pruning
2.2. Structured Pruning
3. Method
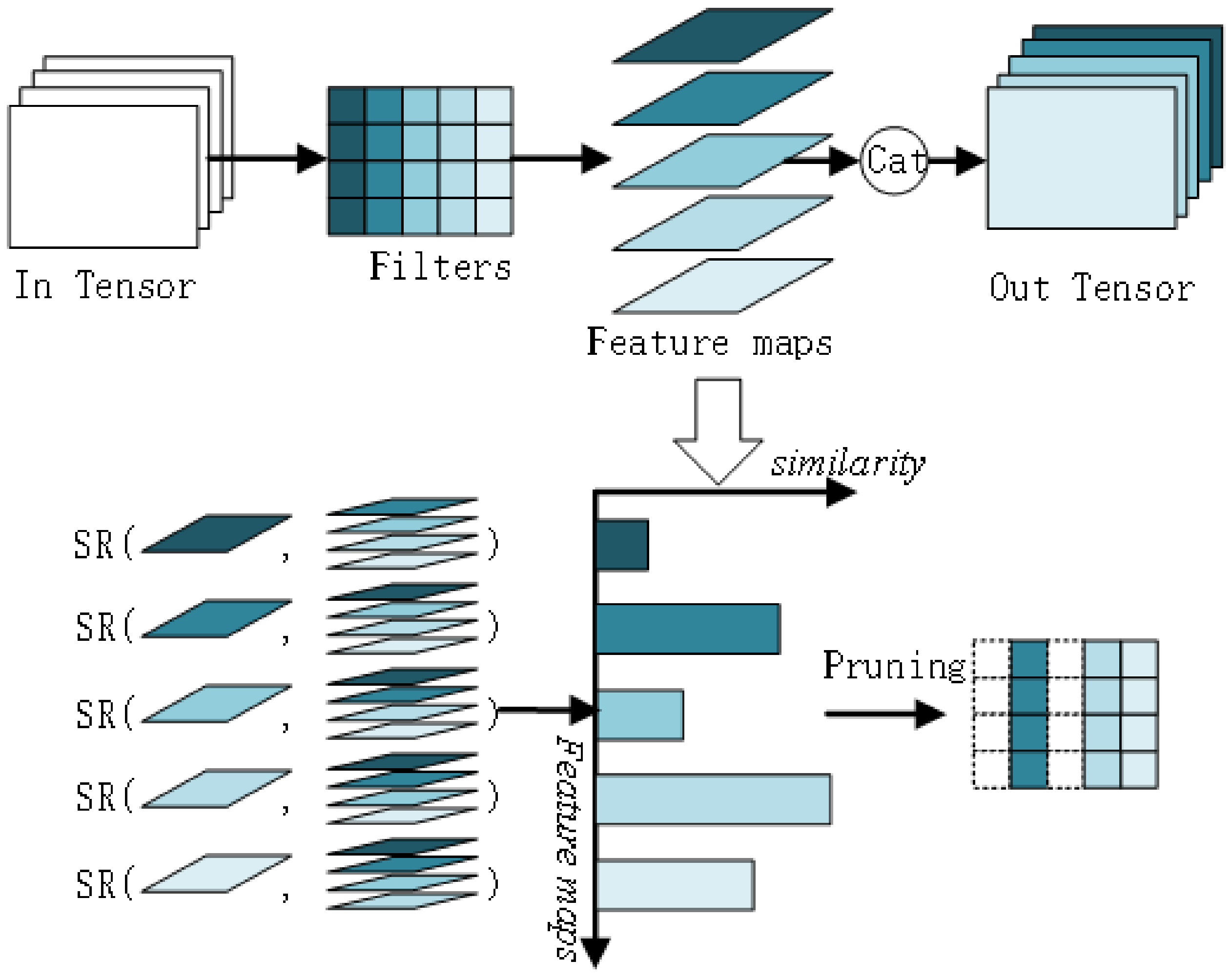
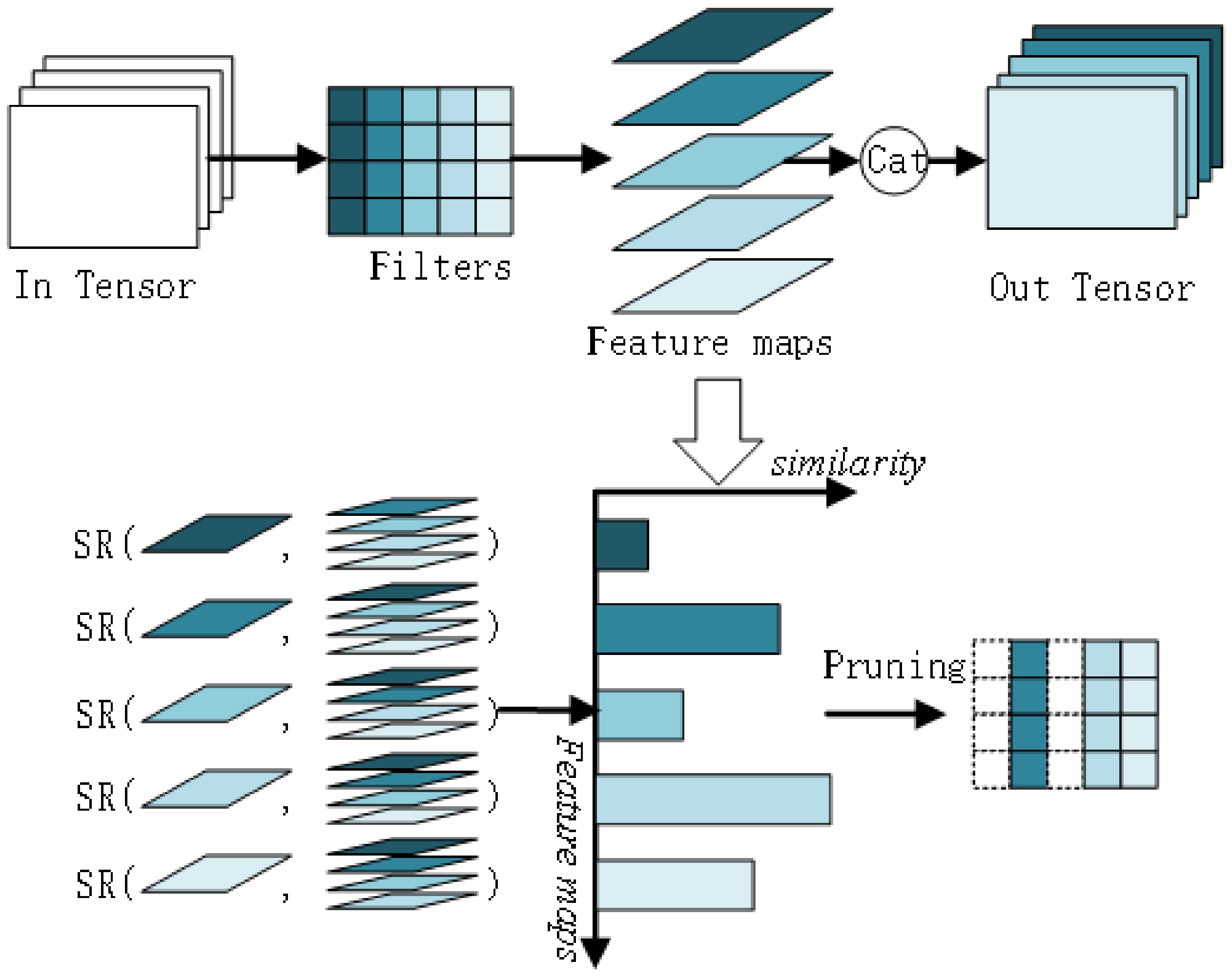
3.1. Algorithmic Thinking
3.2. Algorithmic Framework
- (1)
- Similarity calculation: For a convolutional layer, calculate the similarity between the feature map output of each filter and the feature map output of other filters.
- (2)
- Similarity score calculation: calculate the similarity score for each feature map.
- (3)
- Distance sorting: The similarity score calculated for each feature map is sorted.
- (4)
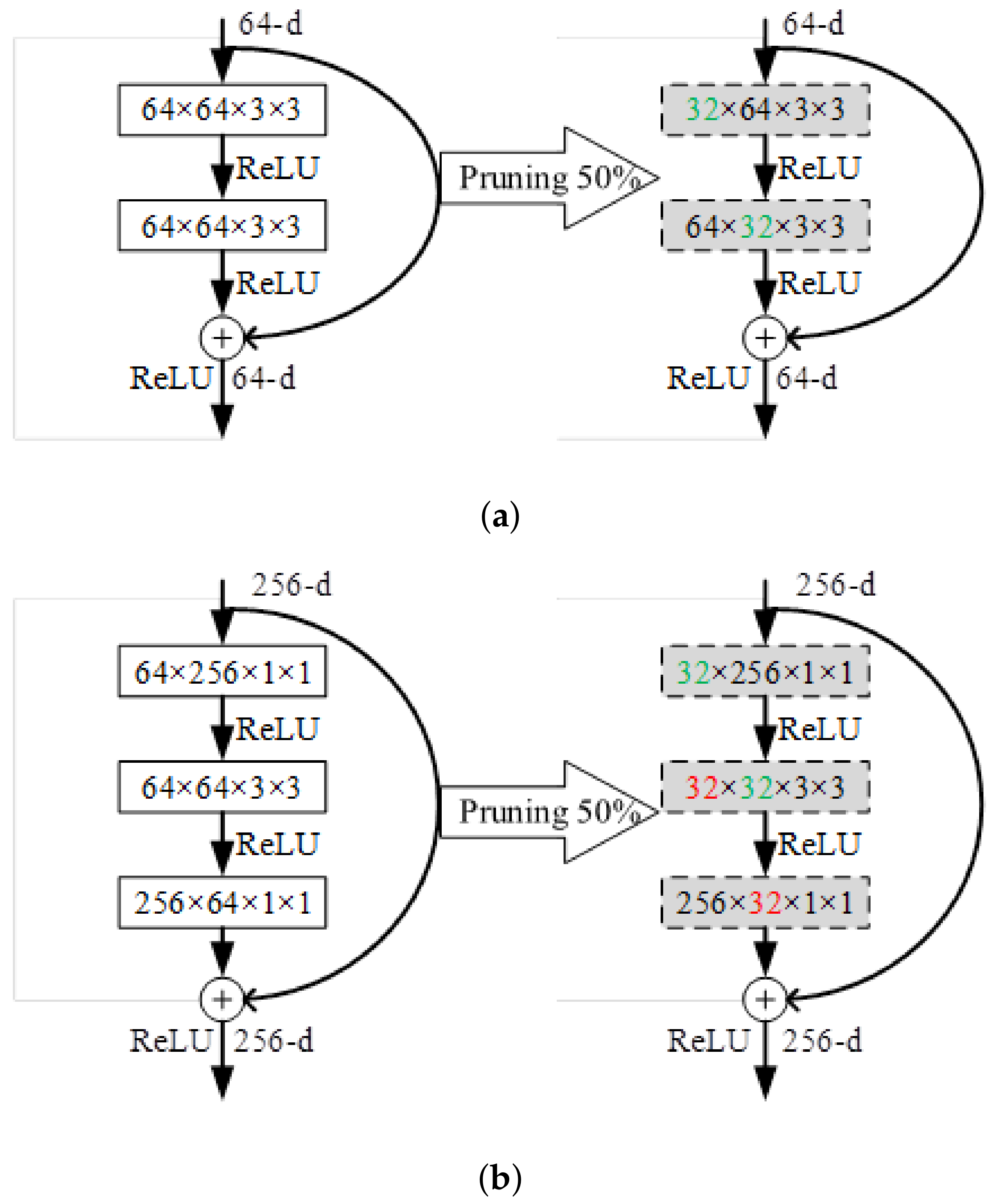
- Filter and channel pruning: According to the set pruning rate, the feature map with low redundancy is retained to map the corresponding convolution kernels, and the unimportant convolution kernels are removed. Also remove the channel corresponding to the next layer.
- (5)
- Prune the next convolutional layer: Repeat steps 1–4 to prune the next convolutional layer, until all convolutional layers have been pruned.
| Algorithm 1: Pruning method based on feature map similarity score. |
|
3.3. Similarity Calculation
- (1)
- Euclidean distance
- (2)
- Difference hash
- (3)
- Structural similarity
3.4. Similarity Score
3.5. Sorting and Pruning
4. Experiments
4.1. Experimental Environment and Dataset
4.2. Evaluation Indicators
- (1)
- Accuracy: Accuracy is calculated according to the formula (9). It is used to evaluate the recognition performance of the model. During the pruning process, we are concerned about the change that pruning brings to the accuracy of the model. Use the formula (10) to calculate the change in accuracy of the model after pruning and compression .where is the number of samples that were correctly identified; is the total number of samples.where is benchmark model accuracy; is model accuracy after pruning.
- (2)
- Parameters: The number of parameters refers to the number of parameters that the model can train, and it can also be expressed by the size of the storage space occupied by the actual model. Filter pruning is the filter that removes the convolutional layer, and also removes the trainable parameters of the corresponding convolutional layer. The amount of parameters of the ith convolutional layer is calculated according to the formula (11).where represents the number of filters, K represents the size of the filter, and represents the number of the channel.
- (3)
- Floating-point operations (FLOPs): Floating-point operations are the number of floating-point operations required in the model, and the calculation method is a formula (12), which can reflect the complexity of the model. Floating-point operations in the model are mainly addition and multiplication operations. It directly affects the speed of the model and reflects the proportion of model speedup.where H and W represent the height and the width of the outputting feature, respectively.
4.3. Similarity Experiment
4.4. Comparative Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, M. NDNC-BAN: Supporting rich media healthcare services via named data networking in cloud-assisted wireless body area networks. Inf. Sci. 2014, 284, 142–156. [Google Scholar] [CrossRef]
- Chen, M.; Ouyang, J.; Jian, A.; Hao, Y. Imperceptible, designable, and scalable braided electronic cord. Nat. Commun. 2022, 13, 7097. [Google Scholar] [CrossRef] [PubMed]
- Hao, Y.; Hu, L.; Chen, M. Joint Sensing Adaptation and Model Placement in 6G Fabric Computing. IEEE J. Sel. Areas Commun. 2023, 41, 2013–2024. [Google Scholar] [CrossRef]
- Chen, M.; Hao, Y.; Gharavi, H.; Leung, V.C.M. Cognitive information measurements: A new perspective. Inf. Sci. 2019, 505, 487–497. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.; Stich, S.U.; Flores, L.F.B.; Dmitriev, D.; Jaggi, M. Dynamic Model Pruning with Feedback. The ICLR-International Conference on Learning Representations. arXiv 2020. [Google Scholar] [CrossRef]
- Kalms, L.; Rad, P.A.; Ali, M.; Iskander, A.; Gohringer, D. A parametrizable high-level synthesis library for accelerating neural networks on fpgas. J. Signal Process. Syst. 2021, 93, 513–529. [Google Scholar] [CrossRef]
- Denil, M.; Shakibi, B.; Dinh, L.; Ranzato, M.; de Freitas, M. Predicting parameters in deep learning. Adv. Neural Inf. Process. Syst. 2013, 26, 543. [Google Scholar] [CrossRef]
- Han, S.; Pool, J.; Tran, J.; Dally, W. Learning both weights and connections for efficient neural network. Adv. Neural Inf. Process. Syst. (NeurIPS) 2015, 1135–1143. [Google Scholar] [CrossRef]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv 2015, arXiv:151000149. [Google Scholar]
- Guo, Y.; Yao, A.; Chen, Y. Dynamic network surgery for efficient dnns. arXiv 2016. [Google Scholar] [CrossRef]
- Lee, N.; Ajanthan, T.; Torr, P.H. SNIP: Single-shot network pruning based on connection sensitivity. arXiv 2019. [Google Scholar] [CrossRef]
- Alizadeh, M.; Tailor, S.A.; Zintgraf, L.M.; Farquhar, S.; Lane, N.D.; Gal, Y. Prospect Pruning: Finding Trainable Weights at Initialization using Meta-Gradients. International Conference on Learning Representations. arXiv 2022. [Google Scholar] [CrossRef]
- Wen, W.; Wu, C.; Wang, Y.; Lee, B. Learning structured sparsity in deep neural networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 5–10 December 2016; pp. 2082–2090. [Google Scholar]
- Li, H.; Kadav, A.; Durdanovic, I.; Graf, H.P. Pruning Filters for Efficient ConvNets. arXiv 2017. [Google Scholar] [CrossRef]
- He, Y.; Zhang, X.; Sun, J. Channel pruning for accelerating very deep neural networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV2017), Venice, Italy, 22–29 October 2017; pp. 1389–1397. [Google Scholar]
- Liu, Z.; Li, J.; Shen, Z.; Zhang, C. Learning efficient convolutional networks through network slimming. In Proceedings of the IEEE International Conference on Computer Vision (ICCV2017), Venice, Italy, 22–29 October 2017; pp. 2736–2744. [Google Scholar]
- Luo, J.-H.; Wu, J.; Lin, W. Thinet: A filter level pruning method for deep neural network compression. In Proceedings of the IEEE International Conference on Computer Vision (ICCV2017), Venice, Italy, 22–29 October 2017; pp. 5058–5066. [Google Scholar]
- He, Y.; Liu, P.; Wang, Z.; Zhang, L. Filter pruning via geometric median for deep convolutional neural networks acceleration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR2019), Seattle, WA, USA, 13–19 June 2019; pp. 4340–4349. [Google Scholar]
- Lin, M.; Ji, R.; Wang, Y.; Zhang, Y.; Zhang, B.; Tian, Y.; Shao, L. Hrank: Filter pruning using high-rank feature map. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR2019), Seattle, WA, USA, 13–19 June 2020; pp. 1529–1538. [Google Scholar]
- Sui, Y.; Yin, M.; Xie, Y.; Yuan, B. Chip: Channel independence-based pruning for compact neural networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS2021), Beijing, China, 12–20 October 2021; pp. 24604–24616. [Google Scholar]
- Zhuo, H.; Qian, X.; Fu, Y.; Xue, X. SCSP: Spectral Clustering Filter Pruning with Soft Self-adaption Manners. arXiv 2018. [Google Scholar] [CrossRef]
- Wang, D.; Zhou, L.; Zhang, X.; Zhou, J. Exploring linear relationship in feature map subspace for convnets compression. arXiv 2018. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.H.; Tian, Q.; Xu, P. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Lin, S.; Ji, R.; Yan, C.; Xie, Y. Towards optimal structured cnn pruning via generative adversarial learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–19 June 2019; pp. 2790–2799. [Google Scholar]
- Shang, H.; Wu, J.-L.; Hong, W.; Qian, C. Neural network pruning by cooperative coevolution. arXiv 2022. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| Article | Structure | Criterion | Method |
|---|---|---|---|
| [8,9] | weights | weights magnitude | train, prune and fine-tune |
| [10] | weights | weights magnitude | mask learning |
| [11] | weights | weights magnitude | prune and train |
| [12] | weights | weights magnitude | prune and train |
| [14] | filters | L1 norm | train, prune and fine-tune |
| [15] | filters | filters magnitude | group-LASSO regularization |
| [16] | filters | magnitude of batchnorm parameters | train, prune and fine-tune |
| [17] | filters | output of the next layer | train, prune and fine-tune |
| [18] | filters | geometric median of common information in filters | train, prune and fine-tune |
| [19] | filters | average rank of feature map | train, prune and fine-tune |
| [20] | filters | channel independence | train, prune and fine-tune |
| [21,22] | filters | norm | train, prune, and fine-tune |
| Model | Method | Base Acc (%) | Pruned Acc (%) | Acc ↓ (%) | FLOPs ↓ (%) | Param ↓ (%) |
|---|---|---|---|---|---|---|
| ResNet-56 | Odist-Acc | 93.26 | 93.68 | −0.42 | 47.4 | 42.8 |
| dHash-Acc | 93.26 | 94.20 | −0.94 | 47.4 | 42.8 | |
| SSIM-Acc | 93.26 | 93.86 | −0.60 | 47.4 | 42.8 | |
| Odist-Flops | 93.26 | 92.58 | +0.68 | 72.3 | 71.8 | |
| dHash-Flops | 93.26 | 92.67 | +0.59 | 72.3 | 71.8 | |
| SSIM-Flops | 93.26 | 92.66 | −0.60 | 72.3 | 71.8 | |
| ResNet-110 | Odist-Acc | 93.50 | 94.58 | −1.08 | 52.1 | 48.3 |
| dHash-Acc | 93.50 | 94.53 | −1.03 | 52.1 | 48.3 | |
| SSIM-Acc | 93.50 | 94.35 | −0.85 | 52.1 | 48.3 | |
| Odist-Flops | 93.50 | 93.29 | +0.21 | 71.6 | 68.3 | |
| dHash-Flops | 93.50 | 93.53 | −0.03 | 71.6 | 68.3 | |
| SSIM-Flops | 93.50 | 93.37 | +0.13 | 71.6 | 68.3 |
| Model | Method | Base Acc (%) | Pruned Acc (%) | Acc ↓ (%) | FLOPs ↓ (%) | Param↓ (%) |
|---|---|---|---|---|---|---|
| ResNet-56 | L1 [14] | 93.04 | 93.06 | −0.02 | 27.6 | 13.7 |
| HRank [19] | 93.26 | 93.52 | −0.26 | 29.3 | 16.8 | |
| GAL-0.6 [24] | 93.26 | 93.38 | −0.12 | 37.6 | 11.8 | |
| CHIP [20] | 93.26 | 94.16 | −0.90 | 47.4 | 42.8 | |
| dHash-Acc(Ours) | 93.26 | 94.20 | −0.94 | 47.4 | 42.8 | |
| GAL-0.8 [24] | 93.26 | 91.58 | +1.68 | 60.20 | 65.9 | |
| CHIP [20] | 93.26 | 92.05 | +1.21 | 72.3 | 71.8 | |
| CCEP [25] | 93.48 | 93.72 | −0.24 | 63.42 | - | |
| dHash-Flops(Ours) | 93.26 | 92.67 | +0.59 | 72.3 | 71.8 | |
| ResNet-110 | GAL-0.5 [24] | 93.50 | 92.74 | 0.76 | 48.5 | 44.8 |
| CHIP [20] | 93.50 | 94.44 | −0.94 | 52.1 | 48.3 | |
| dHash-Acc(Ours) | 93.50 | 94.53 | −1.03 | 52.1 | 48.3 | |
| CHIP [20] | 93.50 | 93.63 | −0.13 | 71.6 | 68.3 | |
| CCEP [25] | 93.68 | 93.90 | −0.22 | 67.09 | - | |
| dHash-Flops(Ours) | 93.50 | 93.53 | −0.03 | 71.6 | 68.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, J.; Wang, Z.; Yang, Z.; Guan, X. A Pruning Method Based on Feature Map Similarity Score. Big Data Cogn. Comput. 2023, 7, 159. https://doi.org/10.3390/bdcc7040159
Cui J, Wang Z, Yang Z, Guan X. A Pruning Method Based on Feature Map Similarity Score. Big Data and Cognitive Computing. 2023; 7(4):159. https://doi.org/10.3390/bdcc7040159
Chicago/Turabian StyleCui, Jihua, Zhenbang Wang, Ziheng Yang, and Xin Guan. 2023. "A Pruning Method Based on Feature Map Similarity Score" Big Data and Cognitive Computing 7, no. 4: 159. https://doi.org/10.3390/bdcc7040159
APA StyleCui, J., Wang, Z., Yang, Z., & Guan, X. (2023). A Pruning Method Based on Feature Map Similarity Score. Big Data and Cognitive Computing, 7(4), 159. https://doi.org/10.3390/bdcc7040159