Selecting service compositions using QoS is a major topic in service-oriented computing (SOC). We mainly distinguish two categories: service selection with a certain (deterministic) QoS and service selection with an uncertain (nondeterministic) QoS. In what follows, we will review the two parts.
2.1. Service Selection with a Certain QoS
In this category, we assumed that the QoS attributes are static and do not change over time; therefore, the evaluation function of the compositions is also deterministic. Many works and reviews have been proposed to address this kind of issue [
1,
10,
11,
12]. In what follows, we will discuss the most-important ones.
The review presented in [
13] specified two main categories for handling the QoS-aware service-selection problem: the exact algorithms and the approximate algorithms (heuristic/metaheuristic). In each category, the authors reviewed many tips and strategies to simplify the problem resolution, including the cost function linearization, the local QoS optimization, and the simple additive weighting. In [
14], the authors proposed a framework that first takes the skyline services of each task; then, a set of service clusters (within each task) are hierarchically created using K-means to lower the size of the search space. At the end, the solutions are explored using the combinations of cluster-heads. The work by [
15] decomposes global QoS constraints into local constraints using the culture genetic algorithm, then the top items are selected to aggregate the final compositions.
In [
10], the service selection issue was viewed as an optimization problem that takes into account both functional (the function signature) and nonfunctional attributes (QoS, global constraints) to select the Top-K service compositions. The objective function involves several parts, including a similarity function for the input/output matching, a utility function for assessing the aggregated QoS, and a penalty function for evaluating the satisfaction of global constraints. The authors leveraged the harmony search to derive the compositions that best meet the complex requirements. In [
16], a multi-criteria decision method termed Topsis was proposed to handle the QoS-aware service selection. The overall idea consists of computing a distance between each candidate service and a couple of synthetic services termed the ideal positive item and the ideal negative item; the greater the distance is, the better the rank of the candidate element. The approach was tested on a small collection of six services, as well as three QoS attributes (cost, security, reliability). Despite the effectiveness of the results, the proposition needs scalable benchmarks to confirm its adequacy.
In [
17], both local and global searches were leveraged for tackling the selection of cloud services. The proposed approach involves three steps: First, the REMBRANDT technique (which is a multi-criteria decision-making method) is applied to each task to select a subset of n services that have the best scores. Second, a pass of compatibility check is performed to further reduce the search space. Finally, a Dijkstra-based algorithm is applied to derive the optimal compositions in terms of the aggregated QoS and the number of cloud service providers.
The work by [
18] tackled both the reliability assessment and the optimal selection of web service compositions. To estimate the reliability of complex web services, the authors adopted an extended version of PetriNet models and a mathematical model that leverages different factors including the network availability, the hermit device availability, the binding reliability, and the discovery reliability. To handle the second issue, a two-stage method was proposed: first the local skylines of each task of the workflow were extracted, then the global skylines were searched using R-tree structures and a multi-attribute decision-making method.
In [
12], the authors viewed the web service-selection problem as an optimization of deterministic QoS attributes. More specifically, they designed an objective function that involves both an assessment of the aggregated QoS of service workflows and a penalty function for measuring the satisfaction degree of global constraints. In addition, a discretization of the continuous harmony search metaheuristic was proposed for performing the exploration of near-optimal compositions.
In [
11], the authors used an optimized artificial bee colony (OABC) method for service composition. Mainly, the authors introduced three ideas into the initial bee algorithm: the first one is the diversification of the initial population; the second one is the dynamic adjustment of the neighborhood size of the local search; the third one is the addition of a global movement operator that aims to get closer to the global solution. The work by [
19] leveraged fuzzy dominated scores to derive the Top-K services that have a more balanced QoS (and which can be better than some skyline services with undesirable QoS values) in a self-contained task. In [
20], the authors considered the self-organizing migrating algorithm (SOMA) and the fuzzy dominance relationship to aggregate service workflows. The fuzzy dominance function was used in the SOMA metaheuristic to compute the QoS-aware distances between services. A bio-inspired method termed enhanced flying ant colony optimization (EFACO) was proposed in [
21]. This approach constrains the flying activity and handles the execution time problem by a modified local selection. Since this phase may degrade the selection quality, a multi-pheromone approach was adopted to enhance the exploration through the pheromone assignment to each QoS criterion.
In [
22], the authors clustered the cloud services using a trust-oriented k-means, then they created the composition of cloud services using honey bee mating. It is worth noting that the proposed framework is not scalable for large datasets. The work by [
23] tackled the service-selection problem by handling multiple users’ requirements. The approach is comprised of two steps: firstly, an approximate Pareto-optimal set is computed using approximate dominance; secondly, the near-optimal compositions are selected using the artificial bee colony algorithm.
In [
24], the authors proposed a hybrid recommendation method for predicting the missing QoS. The main idea consists of using both matrix factorization methods and the context of users and services to estimate the target QoS. The designed cost function involves a part from the latent factor model and a collaborative prediction model that uses the context-based neighbors. The results showed that the user context is more accurate than the service context, but the weighted average of both sub-models (the service context and the user context) is largely superior to the individual models.
In [
25], the authors predicted the QoS of a web service (which can be involved in a composition) using linear regression and correlation checking. More specifically, the proposed approach uses two different QoS datasets: the first one contains nine quality levels (such as response time, availability, and reliability), and the second one comprises a set of source code metrics that cover the quantity metrics, complexity metrics, and quality metrics (a total of fifteen metrics). This collection of metrics is also known as Sneed’s catalog. The objective of the study was to learn a multivariate linear model that predicts the level of a quality attribute from the variables of Sneed’s catalog.
The work by [
26] proposed a multi-stage composition method based on local and global optimization in addition to the handling of QoS flexibility. The proposition takes into account several types of workflows (including sequential, parallel, iterative, and conditional structures). The method first decomposes the global constraints into local constraints using well-defined heuristics; second, it relaxes the obtained bounds by adding/subtracting/multiplying flexibility terms and filters out the nonrelevant services. Third, the set of local Pareto-optimal services is extracted from each set of relevant services; finally, the Pareto-optimal compositions are computed using a progressive search. In [
27], an automated planning algorithm called Graphplan was proposed to address the composition of land cover services. The key idea of the proposed framework consists of creating an ontology for describing the tasks, the input/output data, and the atomic services, then a planning graph is created using the forward search of the planning algorithm. This graph contains two types of layers, one for modeling the services and the second one for modeling the input/output data (also termed facts). The building of the service composition is performed during the backward search, which is guided with mutual exclusion constraints over both facts and services.
2.2. Service Selection with Uncertain QoS
The framework of [
28] was one of the earliest works that addressed the service selection with uncertain QoS. The authors proposed an excellent heuristic, termed P-dominant skyline, to derive the best QoS-aware services in a self-contained task. The P-dominant skyline is considered to be resilient to QoS inconsistencies and noise. Moreover, this heuristic is accelerated using R-trees. A set of probability distributions was proposed in [
29] to model the QoS uncertainty of service workflows. To select the best compositions, the authors used both integer programming and global constraint penalty cost functions.
A majority interval-based heuristic was introduced in [
9] in order to derive the pertinent services of a set of tasks. The main idea consists of computing the median interval of each nondeterministic QoS attribute and comparing them using rectified linear unit (ReLU) functions [
30]. After that, an exhaustive search is applied to obtain the final compositions. In [
31], the authors proposed a set of heuristics for ranking the services of the workflow tasks. These propositions included probabilistic dominance relationships and fuzzy dominance alternatives. Once the Top-K elements are retained from each task, a constraint programming approach is applied to retain the Top-K optimal compositions of the services. In [
32], the authors addressed the service composition issue by handling the QoS uncertainty and the location awareness. They proposed a sophisticated approach that combines the Firefly metaheuristic with a fuzzy-logic-based web service aggregation.
The framework proposed in [
33] sorted the services of each task using both the entropy and the variance of the QoS attributes. The services that have larger values in terms of entropy and variance are discarded since they are considered as noisy or inconsistent services. Then, the items that have the lowest entropy/variance scores were retained to compose the final solutions.
The framework proposed in [
6] was one of the first works that handled the QoS uncertainty and composition at the same time. Based on ideas defined in [
34], the strategy adopted by the authors consisted of decomposing the end-to-end constraints into local constraints; the local edges (entrances) are calculated by dividing the end-to-end constraint bounds in proportion to the aggregated median QoS of each class of the workflow. After that, an initial service composition is built using a predefined utility function. If this latter one is not optimal, the method searches for alternative solutions using simulated annealing. In the same line of thought, the authors in [
35] introduced a proposition for web service selection with the presence of outliers. Contrary to the work of [
6], this method leverages a different heuristic to divide the end-to-end constraints into local constraints. The proposed idea ensures a high resilience against outliers (services with a noisy or unusual QoS). The work by [
36] leveraged the stochastic dominance relationship to sort the services of each task of the user’s workflow; after that, a backtracking search is applied to the filtered tasks to derive optimal service compositions. In [
37], the authors proposed an interval-based multi-objective bee colony method to address the uncertain QoS-aware service-composition problem. The authors proposed an interval-oriented dominance relationship for comparing the services using intervals that represent the variation range of the QoS attributes. In addition, an interval-valued utility function was introduced to assess the quality of a composition with QoS uncertainty. Finally, an improved version of NSGA-II was used to derive the non-dominated service compositions. The framework proposed in [
38] involved two steps: the first one retains the pertinent services of the local tasks using majority grades, and the second step performs a constraint programming search to keep the optimal compositions. In the same line of thought, the work by [
39] proposed a heuristic for filtering the desirable services of each local task using hesitant fuzzy sets and cross-entropy, then a metaheuristic termed grey wolf optimization was applied to retain the Top-K near-optimal service compositions. In [
40], the authors proposed a framework based on intuitionistic fuzzy logic to model the uncertainty of service compositions. It is worth noting that intuitionistic fuzzy logic is an extension of fuzzy logic in which the imprecise sets are modeled using three quantities: the membership degree, the non-membership degree, and the uncertainty degree. The authors targeted both single service devices and a type of device composition (with a parallel structure). Regarding device compositions, the authors proposed two mathematical models for estimating the uncertainty of data traffic quality. The first one uses the intuitionistic fuzzy information and internal parameters of the service components, while the second one uses only the intuitionistic fuzzy values of the component devices.
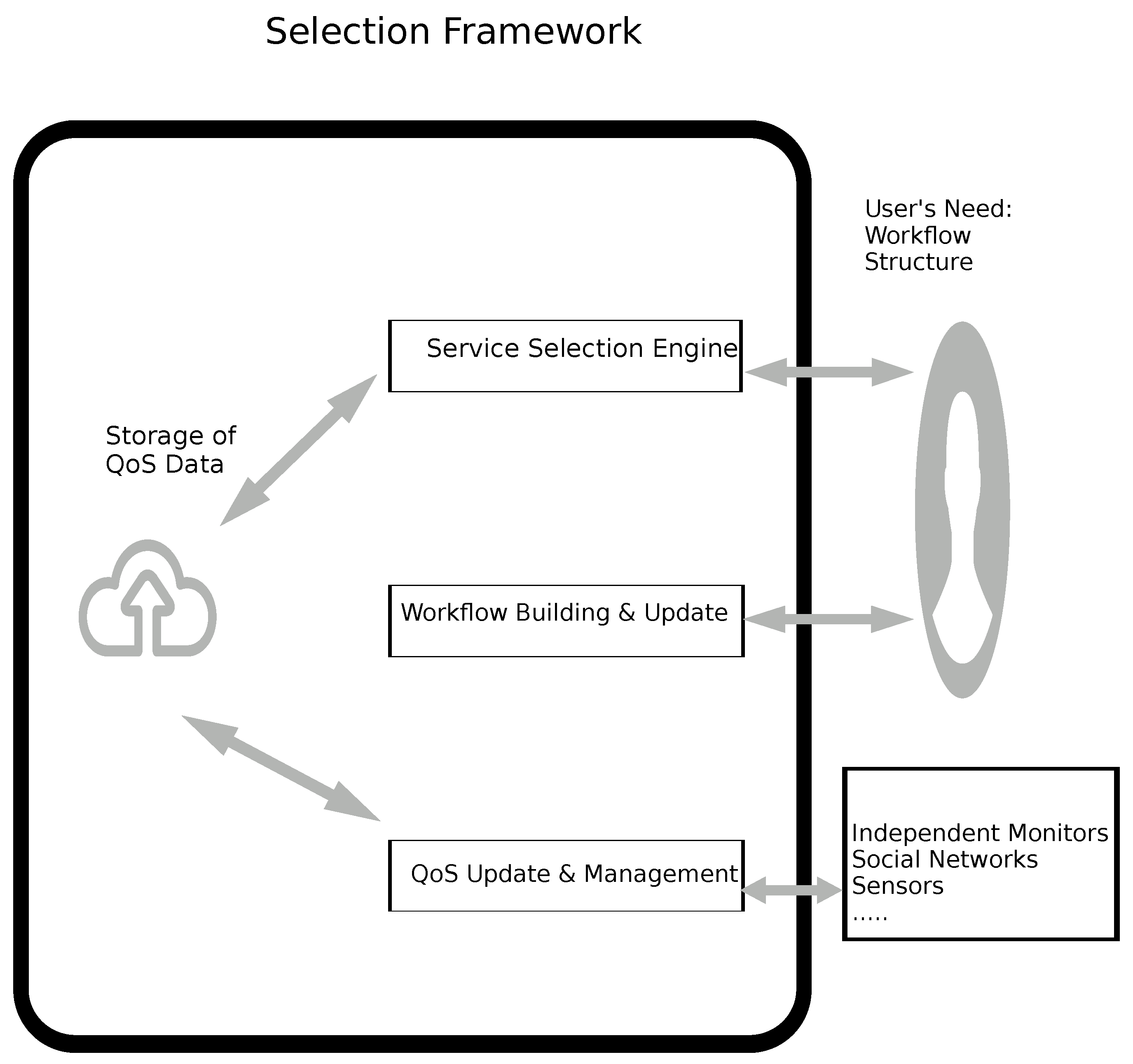
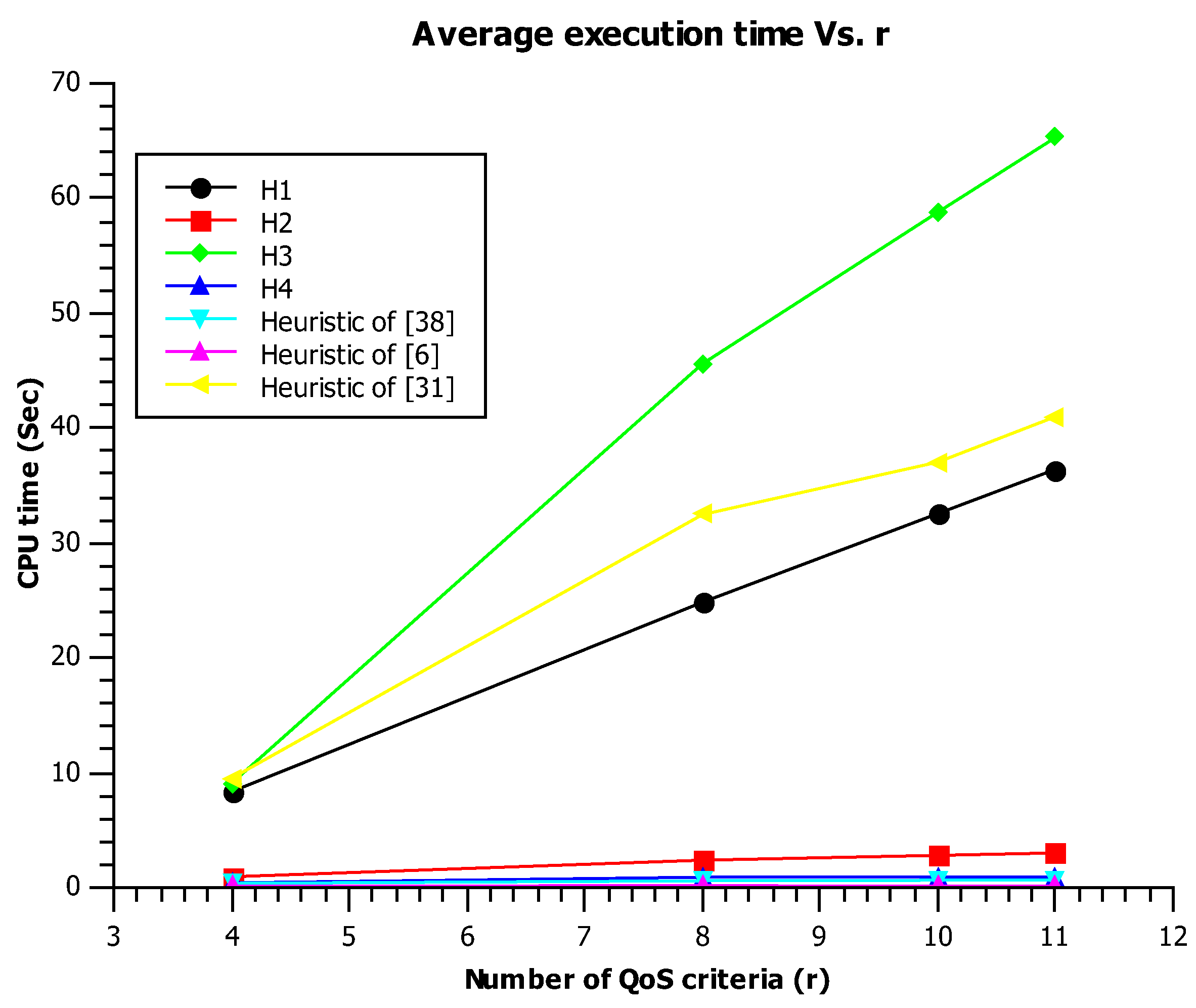
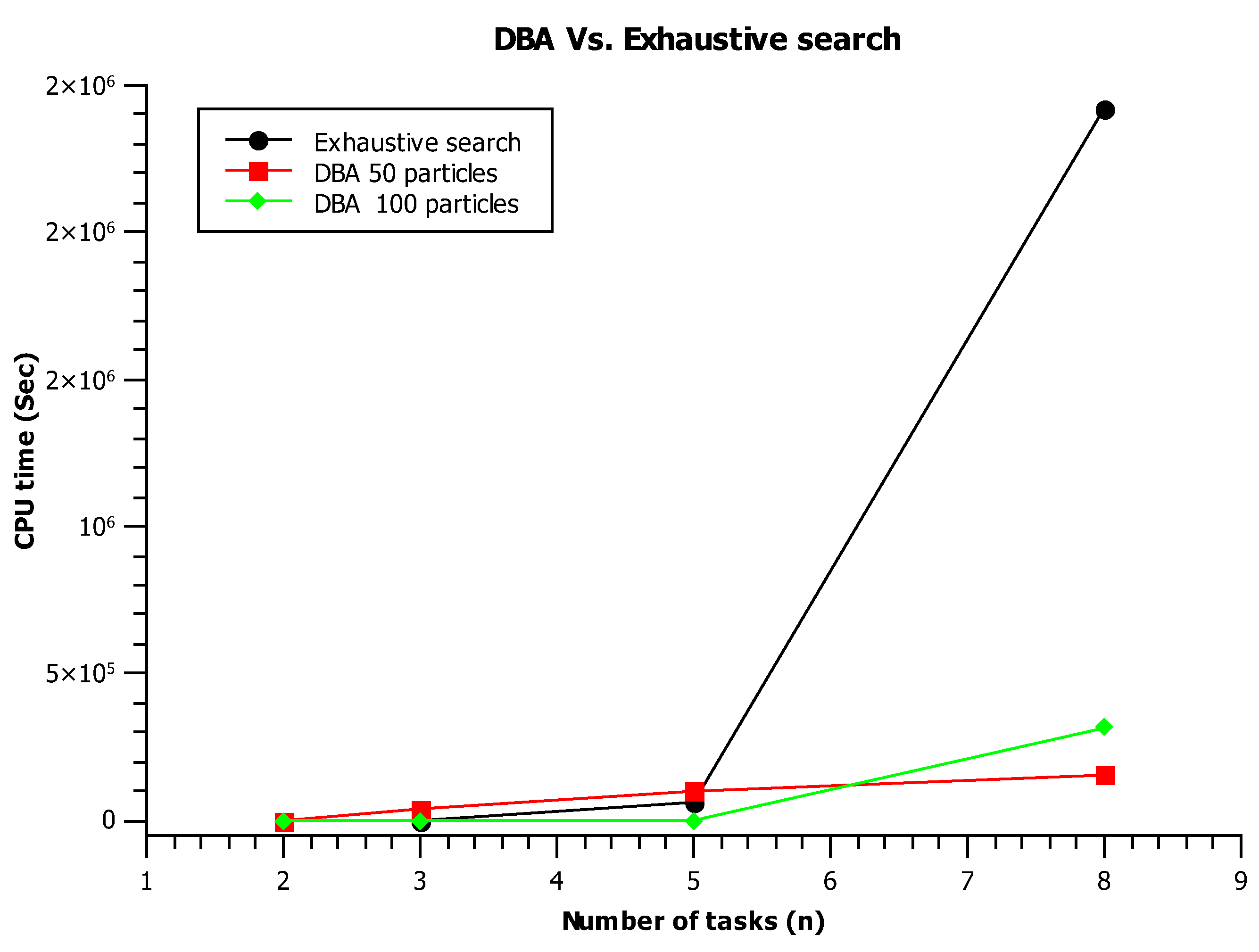
In what follows,
Table 2 summarizes the most-important properties of some prominent approaches; in addition, the abbreviation “nop” means near-optimal.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}