
A Multi-Modal Entity Alignment Method with Inter-Modal Enhancement


Abstract
:1. Introduction
- To address the problem of missing modalities, this paper proposes to add a unique numerical modality based on existing additional modalities, such as structure, relation, and attribute, to improve the information on additional modalities. We extracted numerical triplets from the original dataset and sent the numerical information to the radial basis function network. We then concatenated the resulting feature vectors with attribute embeddings and combined them with entity embeddings to form numerical embeddings. In order to ensure the accuracy of the numerical embeddings, we generated negative numerical triplets by swapping aligned entities in the given positive numerical triplets. We used contrastive learning to improve the credibility of the embeddings.
- To overcome the problem of insufficient cross-modal effects, this paper proposes a novel approach that utilizes pre-trained visual models to obtain visual features of entities and applies them to entity embeddings to enhance the representation of visual interaction relations. We also use visual feature vectors and apply attention mechanisms to allocate entity attribute weights, forming enhanced entity attribute features. Specifically, we first use existing visual models to extract the visual features of entities. These visual features are then concatenated with entity embeddings to form enhanced entity embeddings. Next, we use these enhanced entity embeddings to represent the visual interaction relations between entities, better utilizing visual information to infer relations between entities. Moreover, we also use visual feature vectors and apply attention mechanisms to allocate entity attribute weights. This way, we can adjust the attribute weights based on the visual features of entities, thereby better utilizing attribute information to infer relations between entities. By adopting this approach, we can more comprehensively and accurately describe the entity relation, enhancing knowledge graphs’ application value.
- To address the problem of the excessive influence of weak modalities, this paper proposes a method of dynamically allocating modal weights. Specifically, we dynamically calculate the importance of each modality in the current alignment task using attention mechanisms and neural networks, thus avoiding the over-influence of weak modalities. In modality calculation, we first represent each modality using embedding representations, then we use a multi-layer perception to calculate the importance score of each modality, and finally we use an attention mechanism to calculate the weighted sum of modalities to obtain the weighted modality embedding representation. Through this method, we can better utilize multi-modal information to improve the accuracy and efficiency of alignment while avoiding the over-influence of weak modalities.
2. Related Work
2.1. Multi-Modal Knowledge Graph
2.2. Entity Alignment
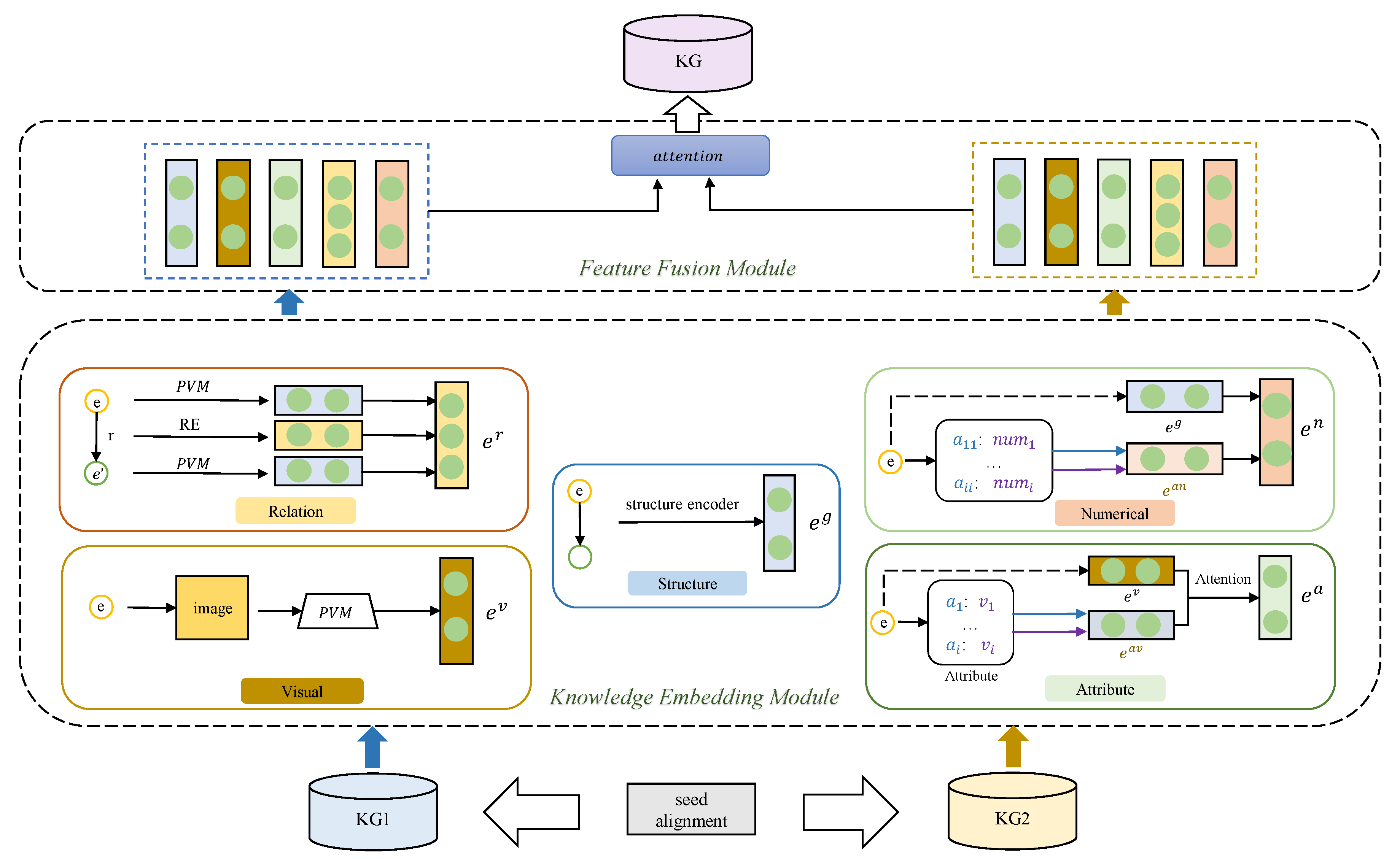
3. Methodology
3.1. Notation and Problem Definition
3.2. Framework Overview
3.3. Multi-Modal Knowledge Embedding
3.3.1. Structure Embedding
3.3.2. Visual Embedding
3.3.3. Attribute Embedding
3.3.4. Relation Embedding
3.3.5. Numerical Embedding
3.4. Feature Processing Fusion Module
4. Experiments
4.1. Experimental Settings
4.2. Existing Methods
- MTransE: Embeds different knowledge graphs into other embedding spaces to provide a transformation for aligning entities.
- GCN-Align: Performs entity alignment by combining structure and entity attribute information through graph convolutional neural networks.
- SEA [20]: Proposes a semi-supervised entity alignment method that aligns labeled entities and rich unlabeled entity information and improves knowledge graph embedding through adversarial training.
- MMEA: Generates entity representations of relation knowledge, visual knowledge, and numerical knowledge and then maps the multi-modal knowledge embeddings from their respective embedding spaces to a common area for entity alignment.
- EVA: Proposes the importance of visual knowledge and combines it with multi-modal information to form a joint embedding for entity alignment.
- MultiJAF [31]: Introduces a separate numerical processing module and predicts entity similarity based on the similarity matrix formed by the numerical module, combined with knowledge embedding fused with structural attributes and visual knowledge.
- MSNEA: Considers the importance of visual knowledge and uses it to influence the embeddings of other modalities and proposes a contrastive learning optimization model to improve the alignment effect.
- MCLEA: Introduces separate encoders for each modality to form knowledge embeddings and proposes a contrastive learning scheme to establish interactions within and between modalities to improve entity alignment.
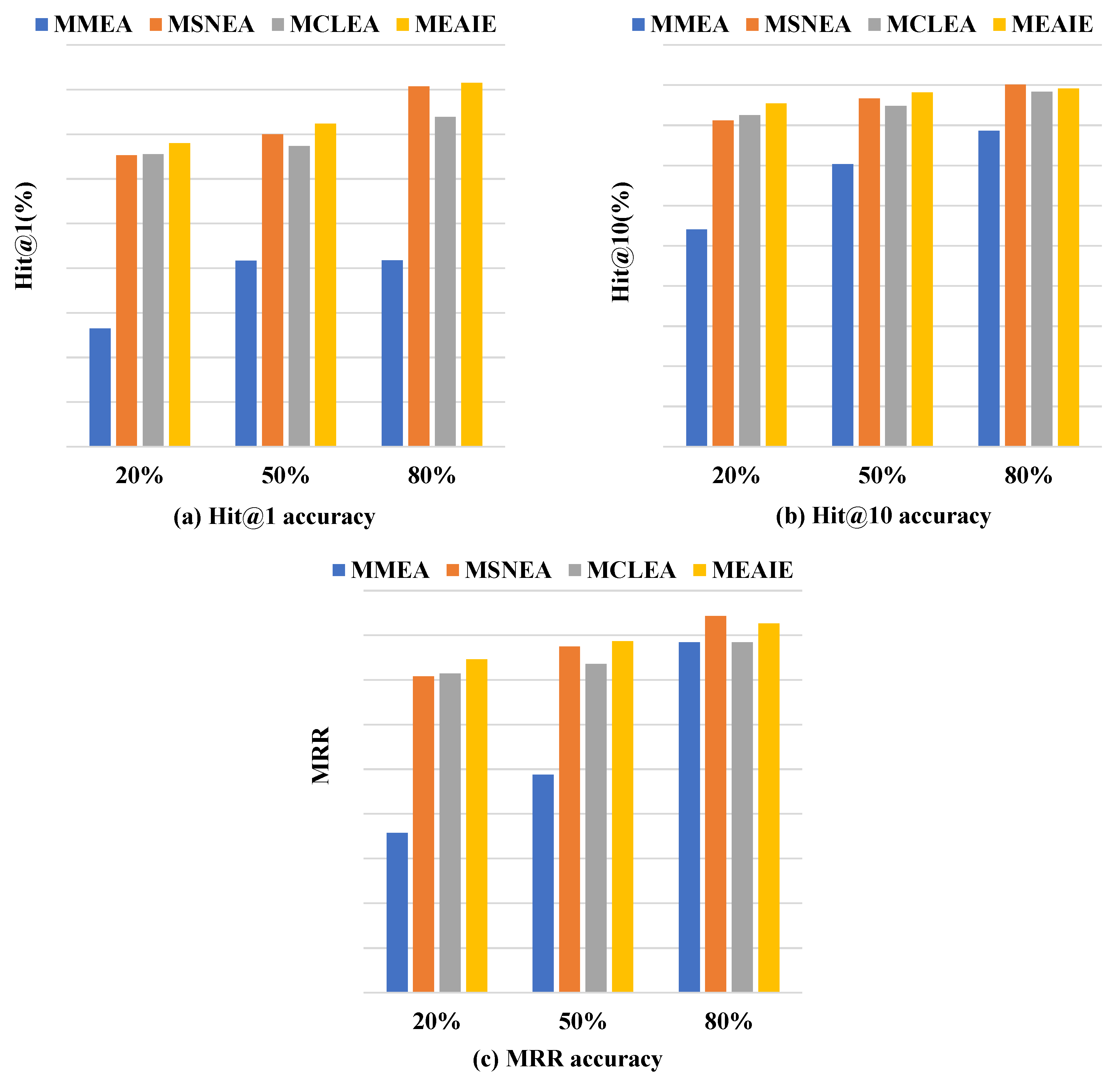
4.3. Results and Analysis
4.3.1. Overall Results
4.3.2. Ablation Study
4.3.3. Seed Sensitivity
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sun, R.; Cao, X.; Zhao, Y.; Wan, J.; Zhou, K.; Zhang, F.; Wang, Z.; Zheng, K. Multi-modal Knowledge Graphs for Recommender Systems. In Proceedings of the CIKM ’20: The 29th ACM International Conference on Information and Knowledge Management, Virtual Event, 19–23 October 2020; ACM: New York, NY, USA, 2020; pp. 1405–1414. [Google Scholar]
- Yang, S.; Zhang, R.; Erfani, S.M.; Lau, J.H. UniMF: A Unified Framework to Incorporate Multimodal Knowledge Bases intoEnd-to-End Task-Oriented Dialogue Systems. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI 2021, Virtual Event, 19–27 August 2021; Morgan Kaufmann: San Mateo, CA, USA, 2021; pp. 3978–3984. [Google Scholar]
- Lan, Y.; He, G.; Jiang, J.; Jiang, J.; Zhao, W.X.; Wen, J. A Survey on Complex Knowledge Base Question Answering: Methods, Challenges and Solutions. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI 2021, Virtual Event, 19–27 August 2021; Morgan Kaufmann: San Mateo, CA, USA, 2021; pp. 4483–4491. [Google Scholar]
- Yin, J.; Tang, M.; Cao, J.; You, M.; Wang, H.; Alazab, M. Knowledge-Driven Cybersecurity Intelligence: Software Vulnerability Coexploitation Behavior Discovery. IEEE Trans. Ind. Inform. 2023, 19, 5593–5601. [Google Scholar] [CrossRef]
- You, M.; Yin, J.; Wang, H.; Cao, J.; Wang, K.N.; Miao, Y.; Bertino, E. A knowledge graph empowered online learning framework for access control decision-making. World Wide Web (WWW) 2023, 26, 827–848. [Google Scholar] [CrossRef]
- Ge, C.; Liu, X.; Chen, L.; Zheng, B.; Gao, Y. Make It Easy: An Effective End-to-End Entity Alignment Framework. In Proceedings of the SIGIR ’21: The 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 11–15 July 2021; ACM: New York, NY, USA, 2021; pp. 777–786. [Google Scholar]
- Chen, M.; Tian, Y.; Yang, M.; Zaniolo, C. Multilingual Knowledge Graph Embeddings for Cross-lingual Knowledge Alignment. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI 2017, Melbourne, Australia, 19–25 August 2017; Morgan Kaufmann: San Mateo, CA, USA, 2017; pp. 1511–1517. [Google Scholar]
- Shen, L.; He, R.; Huang, S. Entity alignment with adaptive margin learning knowledge graph embedding. Data Knowl. Eng. 2022, 139, 101987. [Google Scholar] [CrossRef]
- Wang, Z.; Lv, Q.; Lan, X.; Zhang, Y. Cross-lingual Knowledge Graph Alignment via Graph Convolutional Networks. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 349–357. [Google Scholar]
- Xiang, Y.; Zhang, Z.; Chen, J.; Chen, X.; Lin, Z.; Zheng, Y. OntoEA: Ontology-guided Entity Alignment via Joint Knowledge Graph Embedding. In Proceedings of the Findings of the Association for Computational Linguistics: ACL/IJCNLP 2021, Online Event, 1–6 August 2021; Findings of ACL. Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; Volume ACL/IJCNLP 2021, pp. 1117–1128. [Google Scholar]
- Chen, L.; Li, Z.; Wang, Y.; Xu, T.; Wang, Z.; Chen, E. MMEA: Entity Alignment for Multi-modal Knowledge Graph. In Proceedings of the Knowledge Science, Engineering and Management—13th International Conference, KSEM 2020, Hangzhou, China, 28–30 August 2020; Proceedings, Part I. Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2020; Volume 12274, pp. 134–147. [Google Scholar]
- Liu, F.; Chen, M.; Roth, D.; Collier, N. Visual Pivoting for (Unsupervised) Entity Alignment. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in Artificial Intelligence, EAAI 2021, Virtual Event, 2–9 February 2021; AAAI Press: Palo Alto, CA, USA, 2021; pp. 4257–4266. [Google Scholar]
- Chen, L.; Li, Z.; Xu, T.; Wu, H.; Wang, Z.; Yuan, N.J.; Chen, E. Multi-modal Siamese Network for Entity Alignment. In Proceedings of the KDD ’22: The 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022; ACM: New York, NY, USA, 2022; pp. 118–126. [Google Scholar]
- Lin, Z.; Zhang, Z.; Wang, M.; Shi, Y.; Wu, X.; Zheng, Y. Multi-modal Contrastive Representation Learning for Entity Alignment. In Proceedings of the 29th International Conference on Computational Linguistics, COLING 2022, Gyeongju, Republic of Korea, 12–17 October 2022; pp. 2572–2584. [Google Scholar]
- Wang, Y.; Huang, W.; Sun, F.; Xu, T.; Rong, Y.; Huang, J. Deep Multimodal Fusion by Channel Exchanging. In Proceedings of the Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, Virtual, 6–12 December 2020; Volume 33, pp. 4835–4845. [Google Scholar]
- Liu, Y.; Li, H.; García-Durán, A.; Niepert, M.; Oñoro-Rubio, D.; Rosenblum, D.S. MMKG: Multi-modal Knowledge Graphs. In Proceedings of the The Semantic Web—16th International Conference, ESWC 2019, Portorož, Slovenia, 2–6 June 2019; Proceedings. Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2019; Volume 11503, pp. 459–474. [Google Scholar]
- Wang, M.; Wang, H.; Qi, G.; Zheng, Q. Richpedia: A Large-Scale, Comprehensive Multi-Modal Knowledge Graph. Big Data Res. 2020, 22, 100159. [Google Scholar] [CrossRef]
- Wang, X.; Huang, T.; Wang, D.; Yuan, Y.; Liu, Z.; He, X.; Chua, T. Learning Intents behind Interactions with Knowledge Graph for Recommendation. In Proceedings of the WWW ’21: The Web Conference 2021, Virtual Event, 19–23 April 2021; pp. 878–887. [Google Scholar]
- Zhu, H.; Xie, R.; Liu, Z.; Sun, M. Iterative Entity Alignment via Joint Knowledge Embeddings. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI 2017, Melbourne, Australia, 19–25 August 2017; Morgan Kaufmann: San Mateo, CA, USA, 2017; pp. 4258–4264. [Google Scholar]
- Pei, S.; Yu, L.; Hoehndorf, R.; Zhang, X. Semi-Supervised Entity Alignment via Knowledge Graph Embedding with Awareness of Degree Difference. In Proceedings of the The World Wide Web Conference, WWW 2019, San Francisco, CA, USA, 13–17 May 2019; ACM: New York, NY, USA, 2019; pp. 3130–3136. [Google Scholar]
- Sun, Z.; Wang, C.; Hu, W.; Chen, M.; Dai, J.; Zhang, W.; Qu, Y. Knowledge Graph Alignment Network with Gated Multi-Hop Neighborhood Aggregation. In Proceedings of the The Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, 7–12 February 2020; AAAI Press: Palo Alto, CA, USA, 2020; pp. 222–229. [Google Scholar]
- He, F.; Li, Z.; Yang, Q.; Liu, A.; Liu, G.; Zhao, P.; Zhao, L.; Zhang, M.; Chen, Z. Unsupervised Entity Alignment Using Attribute Triples and Relation Triples. In Proceedings of the Database Systems for Advanced Applications—24th International Conference, DASFAA 2019, Chiang Mai, Thailand, 22–25 April 2019; Proceedings, Part I. Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2019; Volume 11446, pp. 367–382. [Google Scholar]
- Zhang, Q.; Sun, Z.; Hu, W.; Chen, M.; Guo, L.; Qu, Y. Multi-view Knowledge Graph Embedding for Entity Alignment. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI 2019, Macao, China, 10–16 August 2019; Morgan Kaufmann: San Mateo, CA, USA, 2019; pp. 5429–5435. [Google Scholar]
- Shi, Y.; Wang, M.; Zhang, Z.; Lin, Z.; Zheng, Y. Probing the Impacts of Visual Context in Multimodal Entity Alignment. In Proceedings of the Web and Big Data—6th International Joint Conference, APWeb-WAIM 2022, Nanjing, China, 25–27 November 2022; Proceedings, Part II. Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2022; Volume 13422, pp. 255–270. [Google Scholar]
- Zhu, R.; Ma, M.; Wang, P. RAGA: Relation-Aware Graph Attention Networks for Global Entity Alignment. In Proceedings of the Advances in Knowledge Discovery and Data Mining—25th Pacific-Asia Conference, PAKDD 2021, Virtual Event, 11–14 May 2021; Proceedings, Part I. Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2021; Volume 12712, pp. 501–513. [Google Scholar]
- Shen, J.; Wang, C.; Gong, L.; Song, D. Joint Language Semantic and Structure Embedding for Knowledge Graph Completion. In Proceedings of the 29th International Conference on Computational Linguistics, COLING 2022, Gyeongju, Republic of Korea, 12–17 October 2022; pp. 1965–1978. [Google Scholar]
- Yang, J.; Wang, D.; Zhou, W.; Qian, W.; Wang, X.; Han, J.; Hu, S. Entity and Relation Matching Consensus for Entity Alignment. In Proceedings of the CIKM ’21: The 30th ACM International Conference on Information and Knowledge Management, Virtual Event, 1–5 November 2021; Demartini, G., Zuccon, G., Culpepper, J.S., Huang, Z., Tong, H., Eds.; ACM: New York, NY, USA, 2021; pp. 2331–2341. [Google Scholar]
- Mao, X.; Wang, W.; Wu, Y.; Lan, M. From Alignment to Assignment: Frustratingly Simple Unsupervised Entity Alignment. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event, 7–11 November 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 2843–2853. [Google Scholar]
- Qi, Z.; Zhang, Z.; Chen, J.; Chen, X.; Xiang, Y.; Zhang, N.; Zheng, Y. Unsupervised Knowledge Graph Alignment by Probabilistic Reasoning and Semantic Embedding. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI 2021, Virtual Event, 19–27 August 2021; Morgan Kaufmann: San Mateo, CA, USA, 2021; pp. 2019–2025. [Google Scholar]
- Guo, H.; Tang, J.; Zeng, W.; Zhao, X.; Liu, L. Multi-modal entity alignment in hyperbolic space. Neurocomputing 2021, 461, 598–607. [Google Scholar] [CrossRef]
- Cheng, B.; Zhu, J.; Guo, M. MultiJAF: Multi-modal joint entity alignment framework for multi-modal knowledge graph. Neurocomputing 2022, 500, 581–591. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Dataset | KG | Entity | Relation Triple | Attribute Triple | Image | Seed |
|---|---|---|---|---|---|---|
| FB15K-DB15K | FB15K | 14,951 | 592,213 | 29,395 | 13,444 | 12,846 |
| DB15K | 12,842 | 89,197 | 48,080 | 12,837 | ||
| FB15K-YG15K | FB15K | 14,951 | 592,213 | 29,395 | 13,444 | 11,199 |
| YG15K | 15,404 | 122,886 | 23,532 | 11,194 |
| Parameter | Default Value |
|---|---|
| training set rate | 0.5 |
| number of epochs to train | 1000 |
| check_point | 100 |
| hidden_units | 128,128,128 |
| lr | 0.005 |
| batch_size | 512 |
| img_dim | 100 |
| attr_dim | 100 |
| num_dim | 100 |
| Models | FB15K-DB15K | |||
|---|---|---|---|---|
| Hit@1(%) | Hit@5(%) | Hit@10(%) | MRR | |
| MtransE | 0.365 | 1.514 | 2.532 | 0.013 |
| GCN-Align | 4.312 | 10.956 | 15.548 | 0.078 |
| SEA | 16.945 | 33.465 | 42.512 | 0.256 |
| MMEA | 26.482 | 45.133 | 54.107 | 0.357 |
| EVA | 55.591 | 66.644 | 71.587 | 0.609 |
| MultiJAF | 54.241 | 64.654 | 68.741 | 0.687 |
| MSNEA | 65.268 | 76.847 | 81.214 | 0.708 |
| MCLEA | 65.512 | 75.831 | 82.534 | 0.714 |
| MEAIE | 67.014 | 78.414 | 85.425 | 0.746 |
| Models | FB15K-YG15K | |||
|---|---|---|---|---|
| Hit@1(%) | Hit@5(%) | Hit@10(%) | MRR | |
| MtransE | 0.312 | 0.977 | 1.832 | 0.012 |
| GCN-Align | 2.271 | 7.232 | 10.754 | 0.053 |
| SEA | 14.084 | 28.694 | 37.147 | 0.218 |
| MMEA | 23.391 | 39.764 | 47.999 | 0.317 |
| EVA | 10.257 | 21.667 | 27.791 | 0.164 |
| MultiJAF | 45.681 | 58.432 | 67.801 | 0.467 |
| MSNEA | 44.288 | 62.554 | 69.831 | 0.529 |
| MCLEA | 42.381 | 60.016 | 65.414 | 0.473 |
| MANEA | 46.014 | 63.744 | 69.817 | 0.534 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, S.; Lu, Z.; Li, Q.; Gu, J. A Multi-Modal Entity Alignment Method with Inter-Modal Enhancement. Big Data Cogn. Comput. 2023, 7, 77. https://doi.org/10.3390/bdcc7020077
Yuan S, Lu Z, Li Q, Gu J. A Multi-Modal Entity Alignment Method with Inter-Modal Enhancement. Big Data and Cognitive Computing. 2023; 7(2):77. https://doi.org/10.3390/bdcc7020077
Chicago/Turabian StyleYuan, Song, Zexin Lu, Qiyuan Li, and Jinguang Gu. 2023. "A Multi-Modal Entity Alignment Method with Inter-Modal Enhancement" Big Data and Cognitive Computing 7, no. 2: 77. https://doi.org/10.3390/bdcc7020077
APA StyleYuan, S., Lu, Z., Li, Q., & Gu, J. (2023). A Multi-Modal Entity Alignment Method with Inter-Modal Enhancement. Big Data and Cognitive Computing, 7(2), 77. https://doi.org/10.3390/bdcc7020077