
Exploring Machine Learning Models for Soil Nutrient Properties Prediction: A Systematic Review

 , ,
, ,
Abstract
1. Introduction
- Examining the smart agriculture and digital soil management landscape in developing countries.
- Existing research literature on soil attributes, classifications, and key components in soil databases for soil fertility prediction.
- Identify and review the state-of-the-art smart soil system based on artificial intelligence models (machine learning and deep learning models).
- Overview of the current issues in development and deployment of soil information systems.
- Establishing a roadmap for future research to improve agricultural productivity with DSM and other digital innovation technologies through the development of a smart soil information system.
2. Soil Components and Properties
2.1. Soil Dataset
2.2. Soil Map
- S = soil classes or attributes
- f = function
- s = soil, other or previously measured properties of the soil at a point
- c = climate, climatic properties of the environment at a point
- o = organisms, including land cover and natural vegetation or fauna or human activity
- r = relief, topography, landscape attributes
- p = parent material, lithology
- a = age, the time factor
- n = spatial or geographic position.
2.3. Research Justification
3. Materials and Methods
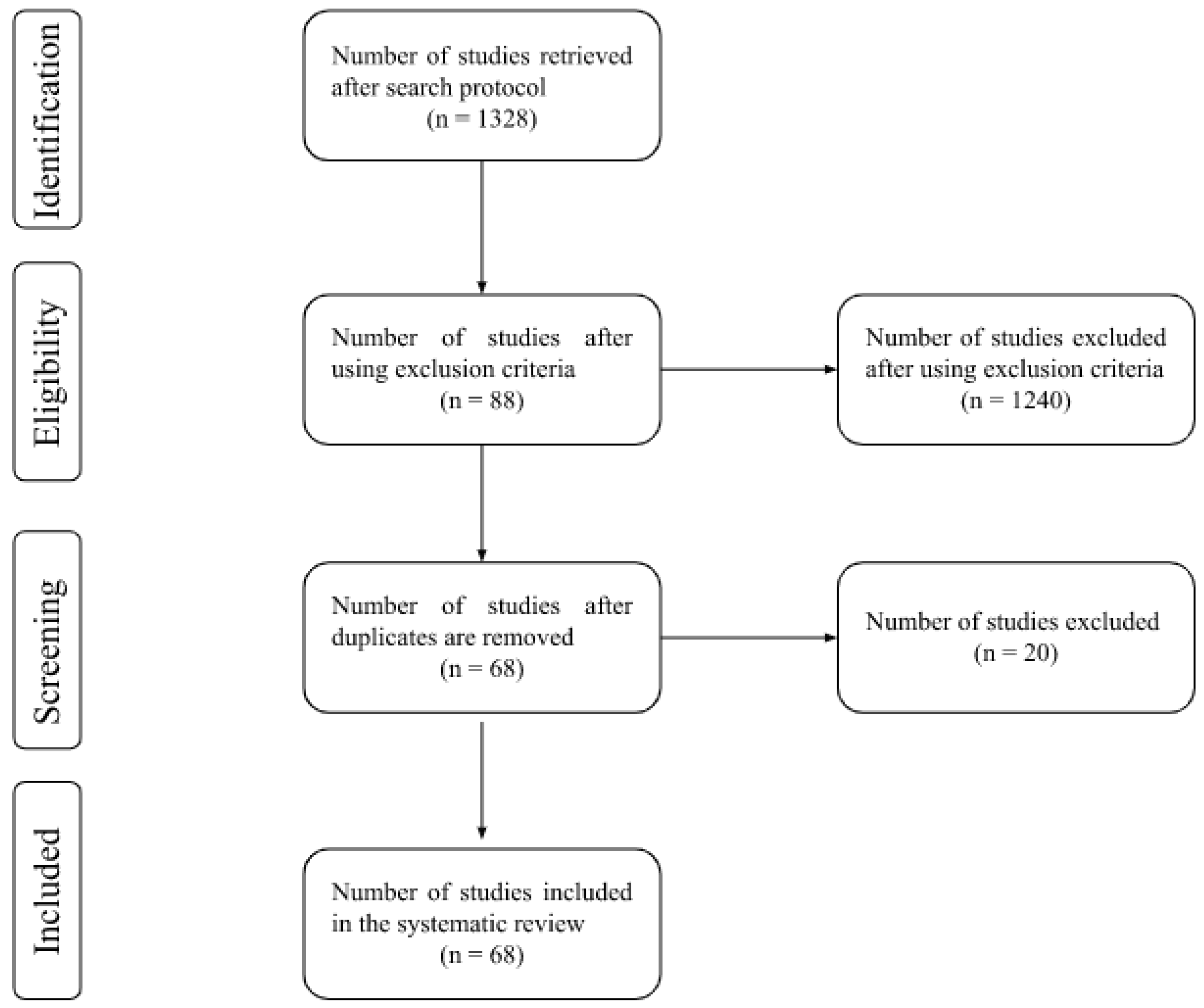
3.1. Database Search Strategy and Eligibility Criteria
3.2. Review Strategy
- Results for (a): DSM, SPP, ML, deep learning, soil properties, soil nutrients, soil map, soil datasets and crop growth.
- Results of (b): smart soil, soil information system and soil fertility.
- Results for (c): smart farming, plant disease, crop disease, articles in different languages other than English.
- Result (d): a, b, c combined using AND OR.
3.3. Characteristics of Studies
3.4. Quality Assessment
3.5. Data Sources and Search Strategy
3.6. Inclusion and Exclusion Criteria
3.7. Data Extraction and Quality Assessments
4. The Impact of Soil Nutrients and Fertility on Crop Growth
4.1. Research on Soil Nutrients and Crop Yield in Developing Countries
4.2. DSM/ML Soil Prediction in Developing Countries: Challenges
- (a)
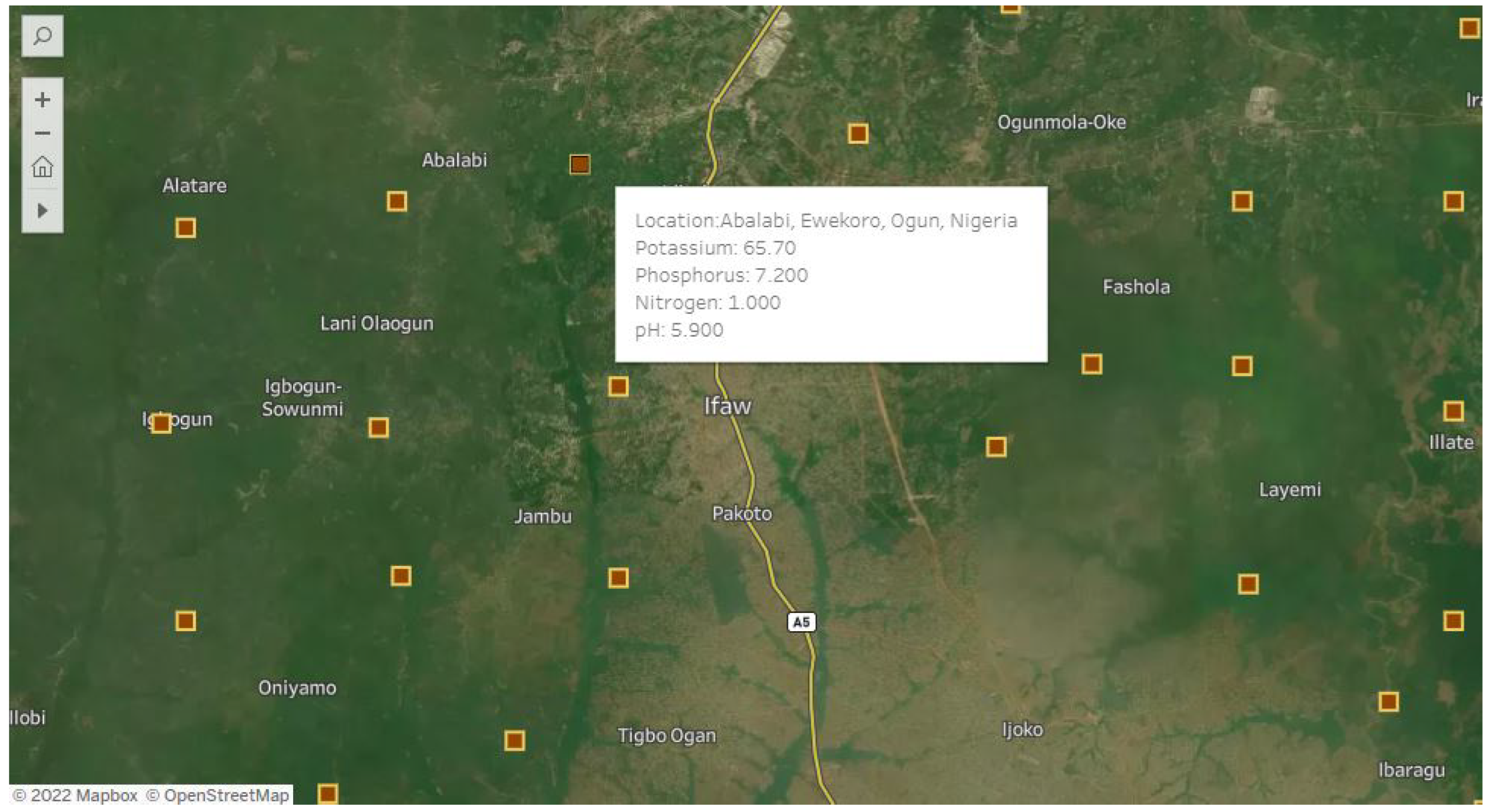
- Data scarcity: In many underdeveloped nations, soil data is scarce or nonexistent, making accurate digital soil maps and training machine learning models problematic. This occurs frequently owing to a scarcity of resources and funds for soil surveys and studies.
- (b)
- Low technical expertise: Poor countries may lack professionals with the technical abilities needed to produce and evaluate digital soil maps as well as developing machine learning models. This can make it challenging to effectively implement these technologies.
- (c)
- Restricted access to technology: Many underdeveloped countries may lack the requisite infrastructure or resources to facilitate the usage of digital soil maps and machine learning. This can involve a lack of internet connectivity, computer equipment, and access to software and data.
- (d)
- Inadequate governmental capacity: Poor countries may lack the institutional ability necessary to properly employ digital soil mapping and machine learning technology. These can include ineffective governance systems, insufficient financing for research and development, and a lack of coordination among various government agencies and stakeholders.
5. Soil Information System
6. Artificial Intelligence Models for Soil Properties Prediction
6.1. Data Quality and ML Model Considerations
- (a)
- Data gathering and preprocessing: This entails making sure that the soil types, geographic areas, and environmental conditions represented in the model training data are accurate. In order to understand soil nutrients, data must also be gathered through soil samples, lab testing, remote sensing, and historical records. The final step is data cleaning, which includes handling missing numbers, fixing errors, and removing outliers [117].
- (b)
- Feature engineering: In order to enhance the accuracy of soil nutrient level estimation, it is imperative to identify and extract relevant features from the collected data. The influence of environmental factors, including climate, rainfall, and cultivation of land, as well as the chemical, biological, and physical characteristics of soil, is potentially significant [118].
- (c)
- Integrate domain knowledge: In order to gain further insight into the determinants that impact the levels of nutrients present in the soil, it is recommended to consult with experts in the domain [119], including agricultural scientists or researchers specializing in soil science. Applying this data when constructing the models and determining which attributes to incorporate is essential.
- (d)
- Innovative modelling methods: Conducting research on state-of-the-art machine learning techniques [120] and advanced deep learning architectures is of great significance [121]. Furthermore, it is imperative to consider ensemble methodologies that employ an assemblage of models to enhance the accuracy of predictions.
- (e)
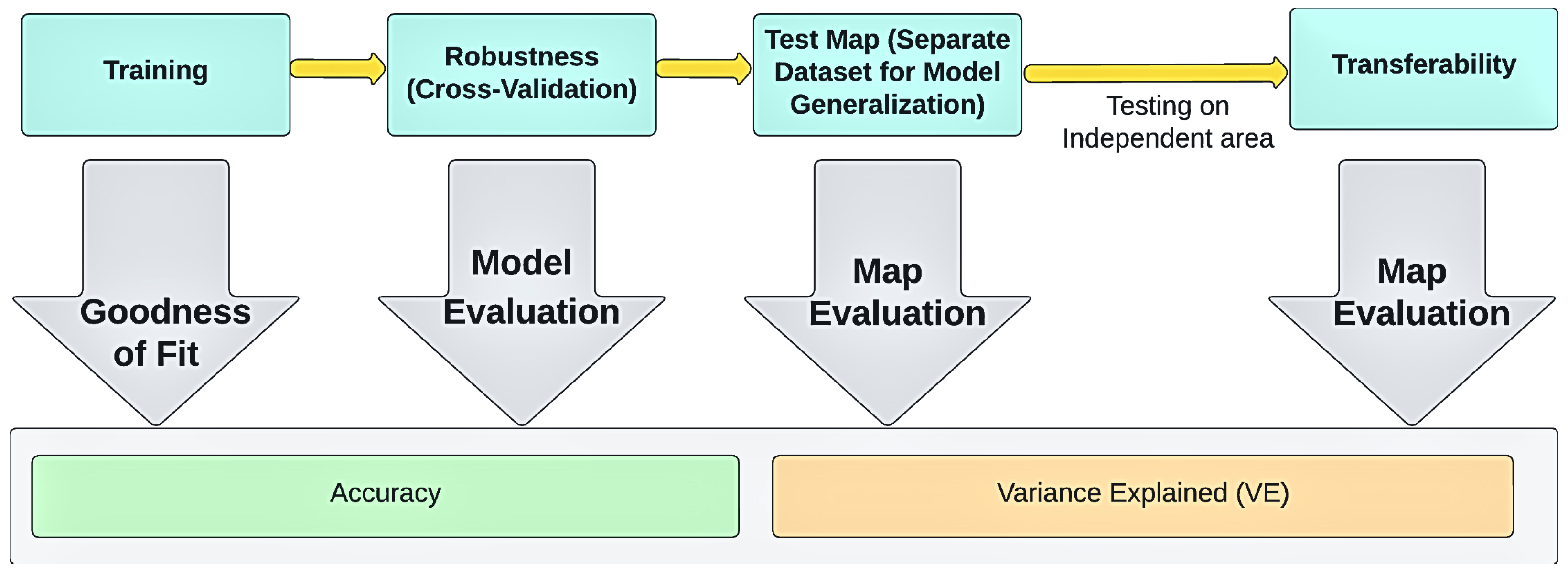
- Model testing and verification: It is imperative to assess the model capacity to extrapolate to new datasets through the application of rigorous evaluation methodologies. Furthermore, assessment criteria are examined and monitored to measure the precision of the models [122].
6.2. Considerations for Choice of ML Technique for Soil Nutrient Properties Prediction
7. Findings and Discussion
- (a)
- Resiliency to distortion: When compared to other algorithms, RF is less susceptible to noise and outliers, which might help it deliver precise forecasts even when working with unclear or missing soil data.
- (b)
- Managing massive data: Because RF can accommodate large datasets with many input features, it is well suited for forecasting soil qualities with several factors impacting their values, such as pH, moisture content, organic matter, and nutrient levels.
- (c)
- Features selection: RF automatically chooses the most significant features for making predictions, which can aid in identifying the main soil qualities and nutrients that are most important in determining soil fertility.
- (d)
- Overfitting minimization: Random forest employs numerous decision trees and aggregates their outputs, which can aid in the reduction of overfitting, a typical problem in machine learning in which models perform well on training data but fail to generalize to new data.
- (e)
- Random forest’s ensembling feature, in which it integrates many decision trees, aids in bias reduction and prediction accuracy by using the collective wisdom of multiple trees.
8. Conclusions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sundari, V.; Anusree, M.; Swetha, U. Crop recommendation and yield prediction using machine learning algorithms. World J. Adv. Res. Rev. 2022, 14, 452–459. [Google Scholar] [CrossRef]
- Muthoni, F.; Thierfelder, C.; Mudereri, B.; Manda, J.; Bekunda, M.; Hoeschle-Zeledon, I. Machine learning model accurately predict maize grain yields in conservation agriculture systems in Southern Africa. In Proceedings of the 2021 9th International Conference on Agro-Geoinformatics (Agro-Geoinformatics), Shenzhen, China, 26–29 July 2021; pp. 1–5. [Google Scholar]
- Rao, T.V.N.; Reddy, G.R. Prediction Of Soil Quality Using Machine Learning Techniques. Int. J. Sci. Technol. Res. 2019, 8, 1309–1313. [Google Scholar]
- Phasinam, K.; Kassanuk, T.; Shabaz, M. Applicability of internet of things in smart farming. J. Food Qual. 2022, 2022, 7692922. [Google Scholar] [CrossRef]
- Ma, Y.; Minasny, B.; Malone, B.P.; Mcbratney, A.B. Pedology and digital soil mapping (DSM). Eur. J. Soil Sci. 2019, 70, 216–235. [Google Scholar] [CrossRef]
- Shaikh, F.K.; Memon, M.A.; Mahoto, N.A.; Zeadally, S.; Nebhen, J. Artificial intelligence best practices in smart agriculture. IEEE Micro 2021, 42, 17–24. [Google Scholar] [CrossRef]
- Chen, Q.; Li, L.; Chong, C.; Wang, X. AI-enhanced soil management and smart farming. Soil Use Manag. 2022, 38, 7–13. [Google Scholar] [CrossRef]
- Dobos, E. Digital Soil Mapping: As a Support to Production of Functional Maps; Office for Official Publication of the European Communities: Luxembourg, 2006.
- Wadoux, A.M.C.; Minasny, B.; McBratney, A.B. Machine learning for digital soil mapping: Applications, challenges and suggested solutions. Earth-Sci. Rev. 2020, 210, 103359. [Google Scholar] [CrossRef]
- Lagacherie, P.; Buis, S.; Constantin, J.; Dharumarajan, S.; Ruiz, L.; Sekhar, M. Evaluating the impact of using digital soil mapping products as input for spatializing a crop model: The case of drainage and maize yield simulated by STICS in the Berambadi catchment (India). Geoderma 2022, 406, 115503. [Google Scholar] [CrossRef]
- Dong, W.; Wu, T.; Sun, Y.; Luo, J. Digital mapping of soil available phosphorus supported by AI technology for precision agriculture. In Proceedings of the 2018 7th International Conference on Agro-geoinformatics (Agro-geoinformatics), Hangzhou, China, 6–9 August 2018; pp. 1–5. [Google Scholar]
- Khaledian, Y.; Miller, B.A. Selecting appropriate machine learning methods for digital soil mapping. Appl. Math. Model. 2020, 81, 401–418. [Google Scholar] [CrossRef]
- Shahare, Y.; Gautam, V. Soil Nutrient Assessment and Crop Estimation with Machine Learning Method: A Survey. In Cyber Intelligence and Information Retrieval; Springer: Berlin/Heidelberg, Germany, 2022; pp. 253–266. [Google Scholar]
- Pallathadka, H.; Mustafa, M.; Sanchez, D.T.; Sajja, G.S.; Gour, S.; Naved, M. Impact of machine learning on management, healthcare and agriculture. Mater. Today Proc. 2021, 80, 2803–2806. [Google Scholar] [CrossRef]
- Murmu, K.; Swain, D.K.; Ghosh, B.C. Comparative assessment of conventional and organic nutrient management on crop growth and yield and soil fertility in tomato-sweet corn production system. Aust. J. Crop. Sci. 2013, 7, 1617–1626. [Google Scholar]
- Shukla, M.; Lal, R.; Ebinger, M. Determining soil quality indicators by factor analysis. Soil Tillage Res. 2006, 87, 194–204. [Google Scholar] [CrossRef]
- Rezaei, S.A.; Gilkes, R.J.; Andrews, S.S. A minimum data set for assessing soil quality in rangelands. Geoderma 2006, 136, 229–234. [Google Scholar] [CrossRef]
- Li, Y.; Li, Z.; Cui, S.; Zhang, Q. Trade-off between soil pH, bulk density and other soil physical properties under global no-tillage agriculture. Geoderma 2020, 361, 114099. [Google Scholar] [CrossRef]
- Fernández, F.G.; Hoeft, R.G. Managing soil pH and crop nutrients. Ill. Agron. Handb. 2009, 24, 91–112. [Google Scholar]
- Marschner, P.; Rengel, Z. Nutrient availability in soils. In Marschners Mineral Nutrition of Higher Plants; Elsevier: Amsterdam, The Netherlands, 2012; pp. 315–330. [Google Scholar]
- Kovačević, M.; Bajat, B.; Gajić, B. Soil type classification and estimation of soil properties using support vector machines. Geoderma 2010, 154, 340–347. [Google Scholar] [CrossRef]
- Baskar, S.; Arockiam, L.; Charles, S. Applying data mining techniques on soil fertility prediction. Int. J. Comput. Appl. Technol. Res. 2013, 2, 660–662. [Google Scholar] [CrossRef]
- Tziachris, P.; Aschonitis, V.; Chatzistathis, T.; Papadopoulou, M.; Doukas, I.J.D. Comparing machine learning models and hybrid geostatistical methods using environmental and soil covariates for soil pH prediction. ISPRS Int. J. Geo-Inf. 2020, 9, 276. [Google Scholar] [CrossRef]
- Zeraatpisheh, M.; Garosi, Y.; Owliaie, H.R.; Ayoubi, S.; Taghizadeh-Mehrjardi, R.; Scholten, T.; Xu, M. Improving the spatial prediction of soil organic carbon using environmental covariates selection: A comparison of a group of environmental covariates. Catena 2022, 208, 105723. [Google Scholar] [CrossRef]
- Legros, J.P. Mapping of the Soil; Science Publishers: Singapore, 2006. [Google Scholar]
- Ryan, P.; McKenzie, N.; O’Connell, D.; Loughhead, A.; Leppert, P.; Jacquier, D.; Ashton, L. Integrating forest soils information across scales: Spatial prediction of soil properties under Australian forests. For. Ecol. Manag. 2000, 138, 139–157. [Google Scholar] [CrossRef]
- Hudson, B.D. The Soil Survey as Paradigm-based Science. Soil Sci. Soc. Am. J. 1992, 56, 836–841. [Google Scholar] [CrossRef]
- Lagacherie, P.; McBratney, A. Chapter 1 Spatial Soil Information Systems and Spatial Soil Inference Systems: Perspectives for Digital Soil Mapping. In Digital Soil Mapping; Lagacherie, P., McBratney, A., Voltz, M., Eds.; Developments in Soil Science; Elsevier: Amsterdam, The Netherlands, 2006; Volume 31, pp. 3–22. [Google Scholar] [CrossRef]
- Franklin, J. Predictive vegetation mapping: Geographic modelling of biospatial patterns in relation to environmental gradients. Prog. Phys. Geogr. Earth Environ. 1995, 19, 474–499. [Google Scholar] [CrossRef]
- McKenzie, N.J.; Ryan, P.J. Spatial prediction of soil properties using environmental correlation. Geoderma 1999, 89, 67–94. [Google Scholar] [CrossRef]
- Scull, P.; Franklin, J.; Chadwick, O.; McArthur, D. Predictive soil mapping: A review. Prog. Phys. Geogr. 2003, 27, 171–197. [Google Scholar] [CrossRef]
- Kempen, B.; Heuvelink, G.B.M.; Brus, D.J.; Stoorvogel, J.J. Pedometric mapping of soil organic matter using a soil map with quantified uncertainty. Eur. J. Soil Sci. 2010, 61, 333–347. [Google Scholar] [CrossRef]
- Tomlinson, R. Design Considerations for Digital Soil Map Systems. In Proceedings of the 11th Congress of Soil Science, ISSS, Edmonton, AB, Canada, 19–27 June 1978. [Google Scholar]
- McBratney, A.; Mendonça Santos, M.; Minasny, B. On digital soil mapping. Geoderma 2003, 117, 3–52. [Google Scholar] [CrossRef]
- Florinsky, I. The Dokuchaev hypothesis as a basis for predictive digital soil mapping (on the 125th anniversary of its publication). Eurasian Soil Sci. 2012, 45, 445–451. [Google Scholar] [CrossRef]
- Bou Kheir, R.; Greve, M.H.; Bøcher, P.K.; Greve, M.B.; Larsen, R.; McCloy, K. Predictive mapping of soil organic carbon in wet cultivated lands using classification-tree based models: The case study of Denmark. J. Environ. Manag. 2010, 91, 1150–1160. [Google Scholar] [CrossRef]
- Brungard, C.W.; Boettinger, J.L.; Duniway, M.C.; Wills, S.A.; Edwards, T.C. Machine learning for predicting soil classes in three semi-arid landscapes. Geoderma 2015, 239–240, 68–83. [Google Scholar] [CrossRef]
- Subburayalu, S.K.; Slater, B.K. Soil Series Mapping By Knowledge Discovery from an Ohio County Soil Map. Soil Sci. Soc. Am. J. 2013, 77, 1254–1268. [Google Scholar] [CrossRef]
- Odgers, N.P.; Sun, W.; McBratney, A.B.; Minasny, B.; Clifford, D. Disaggregating and harmonising soil map units through resampled classification trees. Geoderma 2014, 214–215, 91–100. [Google Scholar] [CrossRef]
- Moran, C.J.; Bui, E.N. Spatial data mining for enhanced soil map modelling. Int. J. Geogr. Inf. Sci. 2002, 16, 533–549. [Google Scholar] [CrossRef]
- Martinelli, G.; Gasser, M.O. Machine learning models for predicting soil particle size fractions from routine soil analyses in Quebec. Soil Sci. Soc. Am. J. 2022, 86, 1509–1522. [Google Scholar] [CrossRef]
- Payen, F.T.; Sykes, A.; Aitkenhead, M.; Alexander, P.; Moran, D.; MacLeod, M. Predicting the abatement rates of soil organic carbon sequestration management in Western European vineyards using random forest regression. Clean. Environ. Syst. 2021, 2, 100024. [Google Scholar] [CrossRef]
- Liu, D.; Liu, C.; Tang, Y.; Gong, C. A GA-BP neural network regression model for predicting soil moisture in slope ecological protection. Sustainability 2022, 14, 1386. [Google Scholar] [CrossRef]
- Han, J.; Zhang, Z.; Cao, J.; Luo, Y.; Zhang, L.; Li, Z.; Zhang, J. Prediction of winter wheat yield based on multi-source data and machine learning in China. Remote Sens. 2020, 12, 236. [Google Scholar] [CrossRef]
- Kuwata, K.; Shibasaki, R. Estimating crop yields with deep learning and remotely sensed data. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 858–861. [Google Scholar]
- Maimaitijiang, M.; Sagan, V.; Sidike, P.; Hartling, S.; Esposito, F.; Fritschi, F.B. Soybean yield prediction from UAV using multimodal data fusion and deep learning. Remote Sens. Environ. 2020, 237, 111599. [Google Scholar] [CrossRef]
- Keerthan Kumar, T.; Shubha, C.; Sushma, S. Random forest algorithm for soil fertility prediction and grading using machine learning. Int. J. Innov. Technol. Explor. Eng. 2019, 9, 1301–1304. [Google Scholar]
- Benedet, L.; Acuña-Guzman, S.F.; Faria, W.M.; Silva, S.H.G.; Mancini, M.; dos Santos Teixeira, A.F.; Pierangeli, L.M.P.; Júnior, F.W.A.; Gomide, L.R.; Júnior, A.L.P.; et al. Rapid soil fertility prediction using X-ray fluorescence data and machine learning algorithms. Catena 2021, 197, 105003. [Google Scholar] [CrossRef]
- Muruganantham, P.; Wibowo, S.; Grandhi, S.; Samrat, N.H.; Islam, N. A systematic literature review on crop yield prediction with deep learning and remote sensing. Remote Sens. 2022, 14, 1990. [Google Scholar] [CrossRef]
- Du Plessis, C.; Van Zijl, G.; Van Tol, J.; Manyevere, A. Machine learning digital soil mapping to inform gully erosion mitigation measures in the Eastern Cape, South Africa. Geoderma 2020, 368, 114287. [Google Scholar] [CrossRef]
- Hounkpatin, K.O.; Bossa, A.Y.; Yira, Y.; Igue, M.A.; Sinsin, B.A. Assessment of the soil fertility status in Benin (West Africa)—Digital soil mapping using machine learning. Geoderma Reg. 2022, 28, e00444. [Google Scholar] [CrossRef]
- Taghizadeh-Mehrjardi, R.; Hamzehpour, N.; Hassanzadeh, M.; Heung, B.; Goydaragh, M.G.; Schmidt, K.; Scholten, T. Enhancing the accuracy of machine learning models using the super learner technique in digital soil mapping. Geoderma 2021, 399, 115108. [Google Scholar] [CrossRef]
- Taghizadeh-Mehrjardi, R.; Schmidt, K.; Eftekhari, K.; Behrens, T.; Jamshidi, M.; Davatgar, N.; Toomanian, N.; Scholten, T. Synthetic resampling strategies and machine learning for digital soil mapping in Iran. Eur. J. Soil Sci. 2020, 71, 352–368. [Google Scholar] [CrossRef]
- Dharumarajan, S.; Vasundhara, R.; Suputhra, A.; Lalitha, M.; Hegde, R. Prediction of soil depth in Karnataka using digital soil mapping approach. J. Indian Soc. Remote. Sens. 2020, 48, 1593–1600. [Google Scholar] [CrossRef]
- Baltensweiler, A.; Walthert, L.; Hanewinkel, M.; Zimmermann, S.; Nussbaum, M. Machine learning based soil maps for a wide range of soil properties for the forested area of Switzerland. Geoderma Reg. 2021, 27, e00437. [Google Scholar] [CrossRef]
- Lamichhane, S.; Kumar, L.; Wilson, B. Digital soil mapping algorithms and covariates for soil organic carbon mapping and their implications: A review. Geoderma 2019, 352, 395–413. [Google Scholar] [CrossRef]
- Zeraatpisheh, M.; Ayoubi, S.; Mirbagheri, Z.; Mosaddeghi, M.R.; Xu, M. Spatial prediction of soil aggregate stability and soil organic carbon in aggregate fractions using machine learning algorithms and environmental variables. Geoderma Reg. 2021, 27, e00440. [Google Scholar] [CrossRef]
- Zhou, T.; Geng, Y.; Chen, J.; Pan, J.; Haase, D.; Lausch, A. High-resolution digital mapping of soil organic carbon and soil total nitrogen using DEM derivatives, Sentinel-1 and Sentinel-2 data based on machine learning algorithms. Sci. Total. Environ. 2020, 729, 138244. [Google Scholar] [CrossRef] [PubMed]
- Zhou, T.; Geng, Y.; Ji, C.; Xu, X.; Wang, H.; Pan, J.; Bumberger, J.; Haase, D.; Lausch, A. Prediction of soil organic carbon and the C: N ratio on a national scale using machine learning and satellite data: A comparison between Sentinel-2, Sentinel-3 and Landsat-8 images. Sci. Total. Environ. 2021, 755, 142661. [Google Scholar] [CrossRef] [PubMed]
- Zhou, T.; Geng, Y.; Chen, J.; Liu, M.; Haase, D.; Lausch, A. Mapping soil organic carbon content using multi-source remote sensing variables in the Heihe River Basin in China. Ecol. Indic. 2020, 114, 106288. [Google Scholar] [CrossRef]
- Emadi, M.; Taghizadeh-Mehrjardi, R.; Cherati, A.; Danesh, M.; Mosavi, A.; Scholten, T. Predicting and mapping of soil organic carbon using machine learning algorithms in Northern Iran. Remote. Sens. 2020, 12, 2234. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Ngo, H.H.; Guo, W.; Chang, S.W.; Nguyen, D.D.; Nguyen, C.T.; Zhang, J.; Liang, S.; Bui, X.T.; Hoang, N.B. A low-cost approach for soil moisture prediction using multi-sensor data and machine learning algorithm. Sci. Total. Environ. 2022, 833, 155066. [Google Scholar] [CrossRef]
- Riese, F.M.; Keller, S.; Hinz, S. Supervised and semi-supervised self-organizing maps for regression and classification focusing on hyperspectral data. Remote. Sens. 2019, 12, 7. [Google Scholar] [CrossRef]
- Du, F.; Zhu, A.X.; Liu, J.; Yang, L. Predictive mapping with small field sample data using semi-supervised machine learning. Trans. Gis 2020, 24, 315–331. [Google Scholar] [CrossRef]
- Mosavi, A.; Sajedi-Hosseini, F.; Choubin, B.; Taromideh, F.; Rahi, G.; Dineva, A.A. Susceptibility mapping of soil water erosion using machine learning models. Water 2020, 12, 1995. [Google Scholar] [CrossRef]
- Keskin, H.; Grunwald, S.; Harris, W.G. Digital mapping of soil carbon fractions with machine learning. Geoderma 2019, 339, 40–58. [Google Scholar] [CrossRef]
- Behrens, T.; Schmidt, K.; MacMillan, R.A.; Viscarra Rossel, R.A. Multi-scale digital soil mapping with deep learning. Sci. Rep. 2018, 8, 15244. [Google Scholar] [CrossRef]
- Ou, D.; Tan, K.; Lai, J.; Jia, X.; Wang, X.; Chen, Y.; Li, J. Semi-supervised DNN regression on airborne hyperspectral imagery for improved spatial soil properties prediction. Geoderma 2021, 385, 114875. [Google Scholar] [CrossRef]
- Yao, J.; Qin, S.; Qiao, S.; Che, W.; Chen, Y.; Su, G.; Miao, Q. Assessment of landslide susceptibility combining deep learning with semi-supervised learning in Jiaohe County, Jilin Province, China. Appl. Sci. 2020, 10, 5640. [Google Scholar] [CrossRef]
- Kaluba, P.; Mwamba, S.; Moualeu-Ngangue, D.P.; Chiona, M.; Munyinda, K.; Winter, E.; Stutzel, H.; Chishala, B.H. Cropping Practices and Effects on Soil Nutrient Adequacy Levels and Cassava Yield of Smallholder Farmers in Northern Zambia. Int. J. Agron. 2021, 2021, 1325964. [Google Scholar] [CrossRef]
- Mwamba, S.; Kaluba, P.; Moualeu-Ngangue, D.; Winter, E.; Chiona, M.; Chishala, B.H.; Munyinda, K.; Stutzel, H. Physiological and morphological responses of cassava genotypes to fertilization regimes in chromi-haplic acrisols soils. Agronomy 2021, 11, 1757. [Google Scholar] [CrossRef]
- Agbede, T.; Adekiya, A.; Ogeh, J. Effects of Chromolaena and Tithonia mulches on soil properties, leaf nutrient composition, growth and yam yield. West Afr. J. Appl. Ecol. 2013, 21, 15–30. [Google Scholar]
- Sanchez, D.; Luna, L.; ESPITIA, A.; Cadena, J. Yield response of yam (Dioscorea rotundata Poir.) to inoculation with Azotobacter and nitrogen chemical fertilization in the Caribbean region of Colombia. RIA Rev. Investig. Agropecu. 2021, 47, 61–70. [Google Scholar]
- Byju, G.; Suja, G. Mineral nutrition of cassava. Adv. Agron. 2020, 159, 169–235. [Google Scholar]
- Laekemariam, F. Soil nutrient status of smallholder cassava farms in southern Ethiopia. J. Biol. Agric. Healthc. 2016, 6, 12–18. [Google Scholar]
- Otieno, H.M. Growth and yield response of maize (Zea mays L.) to a wide range of nutrients on ferralsols of western Kenya. World Sci. News 2019, 129, 96–106. [Google Scholar]
- Endris, S.; Dawid, J. Yield response of maize to integrated soil fertility management on acidic nitosol of Southwestern Ethiopia. J. Agron. 2015, 14, 152–157. [Google Scholar] [CrossRef]
- Aziz, T.; Ullah, S.; Sattar, A.; Nasim, M.; Farooq, M.; Khan, M.M. Nutrient availability and maize (Zea mays) growth in soil amended with organic manures. Int. J. Agric. Biol. 2010, 12, 621–624. [Google Scholar]
- Salami, B.; Sangoyomi, T. Soil fertility status of cassava fields in South Western Nigeria. Am. J. Exp. Agric. 2013, 3, 152. [Google Scholar] [CrossRef][Green Version]
- Akom, M.; Oti-Boateng, C.; Otoo, E.; Dawoe, E. Effect of biochar and inorganic fertilizer in yam (Dioscorea rotundata Poir) production in a forest agroecological zone. J. Agric. Sci. 2015, 7, 211–222. [Google Scholar] [CrossRef]
- Mainoo, A.; Banful, B.K. Yam plant growth and tuber yield response to ex-situ mulches of moringa oleifera, chromolaena odorata and panicum maximum under three natural fallow aged systems. Ann. Ecol. Environ. Sci. 2018, 2, 7–14. [Google Scholar]
- McCauley, A.; Jones, C.; Jacobsen, J. Basic soil properties. Soil Water Manag. Modul. 2005, 1, 1–12. [Google Scholar]
- Padarian, J.; Minasny, B.; McBratney, A.B. Machine learning and soil sciences: A review aided by machine learning tools. Soil 2020, 6, 35–52. [Google Scholar] [CrossRef]
- Dai, Y.; Shangguan, W.; Wei, N.; Xin, Q.; Yuan, H.; Zhang, S.; Liu, S.; Lu, X.; Wang, D.; Yan, F. A review of the global soil property maps for Earth system models. Soil 2019, 5, 137–158. [Google Scholar] [CrossRef]
- Van Loenen, B.; Kok, B. Spatial Data Infrastructure and Policy Development in Europe and the United States; DUP Science: Delft, The Netherlands, 2004. [Google Scholar]
- Masser, I. All shapes and sizes: The first generation of national spatial data infrastructures. Int. J. Geogr. Inf. Sci. 1999, 13, 67–84. [Google Scholar] [CrossRef]
- Dwivedi, R.S. Remote Sensing of Soils; Springer: Berlin/Heidelberg, Germany, 2017; Volume 497. [Google Scholar]
- Eckelmann, W. Soil information for Germany: The 2004 position. Soil Resour. Eur. 2005, 9, 147. [Google Scholar]
- Lilburne, L.; Hewitt, A.; Webb, T. Soil and informatics science combine to develop S-map: A new generation soil information system for New Zealand. Geoderma 2012, 170, 232–238. [Google Scholar] [CrossRef]
- Nshimiyimana, N. Machine Learning based Soil Fertility Prediction. Int. J. Innov. Sci. Eng. Technol. 2021, 8, 141–146. [Google Scholar]
- Akpa, S.I.; Odeh, I.O.; Bishop, T.F.; Hartemink, A.E. Digital mapping of soil particle-size fractions for Nigeria. Soil Sci. Soc. Am. J. 2014, 78, 1953–1966. [Google Scholar] [CrossRef]
- Pásztor, L.; Szabó, J.; Bakacsi, Z.; Matus, J.; Laborczi, A. Compilation of 1: 50,000 scale digital soil maps for Hungary based on the digital Kreybig soil information system. J. Maps 2012, 8, 215–219. [Google Scholar] [CrossRef]
- Hengl, T.; Mendes de Jesus, J.; Heuvelink, G.B.; Ruiperez Gonzalez, M.; Kilibarda, M.; Blagotić, A.; Shangguan, W.; Wright, M.N.; Geng, X.; Bauer-Marschallinger, B.; et al. SoilGrids250m: Global gridded soil information based on machine learning. PLoS ONE 2017, 12, e0169748. [Google Scholar] [CrossRef]
- Kumar, T.R.; Aiswarya, B.; Suresh, A.; Jain, D.; Balaji, N. Smart management of crop cultivation using IOT and machine learning. Int. Res. J. Eng. Technol. (IRJET) 2018, 5, 845–850. [Google Scholar]
- Patil, P.; Panpatil, V.; Kokate, S. Crop prediction system using machine learning algorithms. Int. Res. J. Eng. Technol. (IRJET) 2020, 7, 748–753. [Google Scholar]
- Nachtergaele, F.; Van Ranst, E. Qualitative and quantitative aspects of soil databases in tropical countries. Evolution of Tropical Soil Science: Past and Future; Koninklijke Academie voor Overzeese Wetenschappen: Brussels, Belgium, 2003; pp. 107–126. [Google Scholar]
- Eyo, E.; Abbey, S.; Lawrence, T.; Tetteh, F. Improved prediction of clay soil expansion using machine learning algorithms and meta-heuristic dichotomous ensemble classifiers. Geosci. Front. 2022, 13, 101296. [Google Scholar] [CrossRef]
- Sudha, M.K.; Manorama, M.; Aditi, T. Smart Agricultural Decision Support Systems for Predicting Soil Nutrition Value Using IoT and Ridge Regression. Agris Line Pap. Econ. Inform. 2022, 14, 95–106. [Google Scholar] [CrossRef]
- Adjuik, T.A.; Davis, S.C. Machine Learning Approach to Simulate Soil CO2 Fluxes under Cropping Systems. Agronomy 2022, 12, 197. [Google Scholar] [CrossRef]
- Akinola, I.; Dowd, T. Predicting Africa Soil Properties Using Machine Learning Techniques. Electr. Eng. Stanf. Univ. Stanford CA 2016, 94305, 50–62. [Google Scholar]
- Blesslin Sheeba, T.; Anand, L.; Manohar, G.; Selvan, S.; Wilfred, C.B.; Muthukumar, K.; Padmavathy, S.; Ramesh Kumar, P.; Asfaw, B.T. Machine Learning Algorithm for Soil Analysis and Classification of Micronutrients in IoT-Enabled Automated Farms. J. Nanomater. 2022, 2022, 5343965. [Google Scholar] [CrossRef]
- Hajjar, C.S.; Hajjar, C.; Esta, M.; Chamoun, Y.G. Machine learning methods for soil moisture prediction in vineyards using digital images. In E3S Web of Conferences; EDP Sciences: Les Ulis, France, 2020; Volume 167, p. 02004. [Google Scholar]
- Zhu, L.; Liao, Q.; Wang, Z.; Chen, J.; Chen, Z.; Bian, Q.; Zhang, Q. Prediction of Soil Shear Strength Parameters Using Combined Data and Different Machine Learning Models. Appl. Sci. 2022, 12, 5100. [Google Scholar] [CrossRef]
- Motia, S.; Reddy, S. Exploration of machine learning methods for prediction and assessment of soil properties for agricultural soil management: A quantitative evaluation. J. Phys. Conf. Ser. 2021, 1950, 012037. [Google Scholar] [CrossRef]
- Cedric, L.S.; Adoni, W.Y.H.; Aworka, R.; Zoueu, J.T.; Mutombo, F.K.; Krichen, M.; Kimpolo, C.L.M. Crops Yield Prediction Based on Machine Learning Models: Case of West African Countries. Smart Agric. Technol. 2022, 2, 100049. [Google Scholar] [CrossRef]
- SQAPP. iSQAPER. 2015. Available online: https://www.isqaper-is.eu/sqapp-the-soil-quality-app (accessed on 15 September 2022).
- SoilWeb. SOILTEC GmbH. 1999. Available online: https://www.soiltecgeo.com/soilweb-r (accessed on 15 September 2022).
- AgriApp. AgriApp: Smart Farming App—Apps on Google Play. 2014. Available online: https://play.google.com/store/apps/details (accessed on 18 September 2022).
- LandPKS. LandPKS. 2020. Available online: https://landpotential.org (accessed on 20 September 2022).
- CABI. Crop App Index. 2017. Available online: https://cropappindex.org (accessed on 20 September 2022).
- MySoil. MySoil Test Kit. 2022. Available online: https://www.mysoiltesting.com (accessed on 22 September 2022).
- SIFSS. Soil Indicators for Scottish Soils (SIFSS) App Update. 2017. Available online: https://soils.environment.gov.scot/news/soil-indicators-for-scottish-soils-sifss-app-update (accessed on 10 October 2022).
- SoilTestPro. SoilTestPro. 2019. Available online: https://soiltestpro.com (accessed on 7 October 2022).
- Soil, C.; Institute, A. Soilscapes. Available online: https://www.landis.org.uk/soilscapes (accessed on 10 October 2022).
- ISRIC. SoilInfo App—Global Soil Data on Your Palm. 2017. Available online: https://www.isric.org/explore/soilinfo (accessed on 17 October 2022).
- AgroCares. SoilCares-Smart Farming: Nutrient Testing. 2021. Available online: https://www.agrocares.com/soilcares (accessed on 17 October 2022).
- Rodríguez-Pérez, J.R.; Marcelo, V.; Pereira-Obaya, D.; García-Fernández, M.; Sanz-Ablanedo, E. Estimating soil properties and nutrients by visible and infrared diffuse reflectance spectroscopy to characterize vineyards. Agronomy 2021, 11, 1895. [Google Scholar] [CrossRef]
- Bocca, F.F.; Rodrigues, L.H.A. The effect of tuning, feature engineering, and feature selection in data mining applied to rainfed sugarcane yield modelling. Comput. Electron. Agric. 2016, 128, 67–76. [Google Scholar] [CrossRef]
- Kansou, K.; Laurier, W.; Charalambides, M.N.; Della-Valle, G.; Djekic, I.; Feyissa, A.H.; Marra, F.; Thomopoulos, R.; Bredeweg, B. Food modelling strategies and approaches for knowledge transfer. Trends Food Sci. Technol. 2022, 120, 363–373. [Google Scholar] [CrossRef]
- Waring, J.; Lindvall, C.; Umeton, R. Automated machine learning: Review of the state-of-the-art and opportunities for healthcare. Artif. Intell. Med. 2020, 104, 101822. [Google Scholar] [CrossRef]
- Baduge, S.K.; Thilakarathna, S.; Perera, J.S.; Arashpour, M.; Sharafi, P.; Teodosio, B.; Shringi, A.; Mendis, P. Artificial intelligence and smart vision for building and construction 4.0: Machine and deep learning methods and applications. Autom. Constr. 2022, 141, 104440. [Google Scholar] [CrossRef]
- Christin, S.; Hervet, É.; Lecomte, N. Going further with model verification and deep learning. Methods Ecol. Evol. 2021, 12, 130–134. [Google Scholar] [CrossRef]
- Akin, M.; Eyduran, E.; Reed, B.M. Use of RSM and CHAID data mining algorithm for predicting mineral nutrition of hazelnut. Plant Cell Tissue Organ Cult. (PCTOC) 2017, 128, 303–316. [Google Scholar] [CrossRef]
- Elavarasan, D.; Vincent, D.R.; Sharma, V.; Zomaya, A.Y.; Srinivasan, K. Forecasting yield by integrating agrarian factors and machine learning models: A survey. Comput. Electron. Agric. 2018, 155, 257–282. [Google Scholar] [CrossRef]
- Coble, K.H.; Mishra, A.K.; Ferrell, S.; Griffin, T. Big data in agriculture: A challenge for the future. Appl. Econ. Perspect. Policy 2018, 40, 79–96. [Google Scholar] [CrossRef]
- Akin, M.; Eyduran, S.P.; Eyduran, E.; Reed, B.M. Analysis of macro nutrient related growth responses using multivariate adaptive regression splines. Plant Cell Tissue Organ Cult. (PCTOC) 2020, 140, 661–670. [Google Scholar] [CrossRef]
- Jabbar, H.; Khan, R.Z. Methods to avoid over-fitting and under-fitting in supervised machine learning (comparative study). Comput. Sci. Commun. Instrum. Devices 2015, 70, 163–172. [Google Scholar]
- Dong, G.; Liu, H. Feature Engineering for Machine Learning and Data Analytics; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Khare, S.K.; Acharya, U.R. An explainable and interpretable model for attention deficit hyperactivity disorder in children using EEG signals. Comput. Biol. Med. 2023, 155, 106676. [Google Scholar] [CrossRef] [PubMed]
- Williams, N.; Zander, S.; Armitage, G. A preliminary performance comparison of five machine learning algorithms for practical IP traffic flow classification. ACM Sigcomm. Comput. Commun. Rev. 2006, 36, 5–16. [Google Scholar] [CrossRef]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef]
- Noble, W.S. What is a support vector machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef]
- Suthaharan, S.; Suthaharan, S. Support vector machine. Machine learning models and algorithms for big data classification: Thinking with examples for effective learning. Integr. Ser. Inf. Syst. 2016, 36, 207–235. [Google Scholar]
- Peterson, L.E. K-nearest neighbor. Scholarpedia 2009, 4, 1883. [Google Scholar] [CrossRef]
- Cunningham, P.; Delany, S.J. k-Nearest neighbour classifiers—A Tutorial. ACM Comput. Surv. (CSUR) 2021, 54, 1–25. [Google Scholar] [CrossRef]
- Kingsford, C.; Salzberg, S.L. What are decision trees? Nat. Biotechnol. 2008, 26, 1011–1013. [Google Scholar] [CrossRef] [PubMed]
- Kotsiantis, S.B. Decision trees: A recent overview. Artif. Intell. Rev. 2013, 39, 261–283. [Google Scholar] [CrossRef]
- Su, X.; Yan, X.; Tsai, C.L. Linear regression. Wiley Interdiscip. Rev. Comput. Stat. 2012, 4, 275–294. [Google Scholar] [CrossRef]
- Gross, J.; Groß, J. Linear Regression; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2003; Volume 175. [Google Scholar]
- LaValley, M.P. Logistic regression. Circulation 2008, 117, 2395–2399. [Google Scholar] [CrossRef] [PubMed]
- Nick, T.G.; Campbell, K.M. Logistic regression. In Topics in Biostatistics; Humana Press: New York, NY, USA, 2007; pp. 273–301. [Google Scholar]
- Kleinbaum, D.G.; Dietz, K.; Gail, M.; Klein, M.; Klein, M. Logistic Regression; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Agatonovic-Kustrin, S.; Beresford, R. Basic concepts of artificial neural network (ANN) modeling and its application in pharmaceutical research. J. Pharm. Biomed. Anal. 2000, 22, 717–727. [Google Scholar] [CrossRef]
- Aribisala, B.; Odusanya, O.; Olabanjo, O.; Wahab, E.; Atilola, O.; Saheed, A. Development of an Artificial Neural Network Model for Detection of COVID-19. Int. J. Sci. Adv. 2022, 3, 377–385. [Google Scholar] [CrossRef]
- Olabanjo, O.A.; Wusu, A.S.; Manuel, M. A Machine Learning Prediction of Academic Performance of Secondary School Students Using Radial Basis Function Neural Network. Trends Neurosci. Educ. 2022, 29, 100190. [Google Scholar] [CrossRef]
- Leung, K.M. Naive bayesian classifier. Polytech. Univ. Dep. Comput. Sci. Risk Eng. 2007, 2007, 123–156. [Google Scholar]
- Macaulay, B.O.; Aribisala, B.S.; Akande, S.A.; Akinnuwesi, B.A.; Olabanjo, O.A. Breast cancer risk prediction in African women using random forest classifier. Cancer Treat. Res. Commun. 2021, 28, 100396. [Google Scholar] [CrossRef]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobotics 2013, 7, 21. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
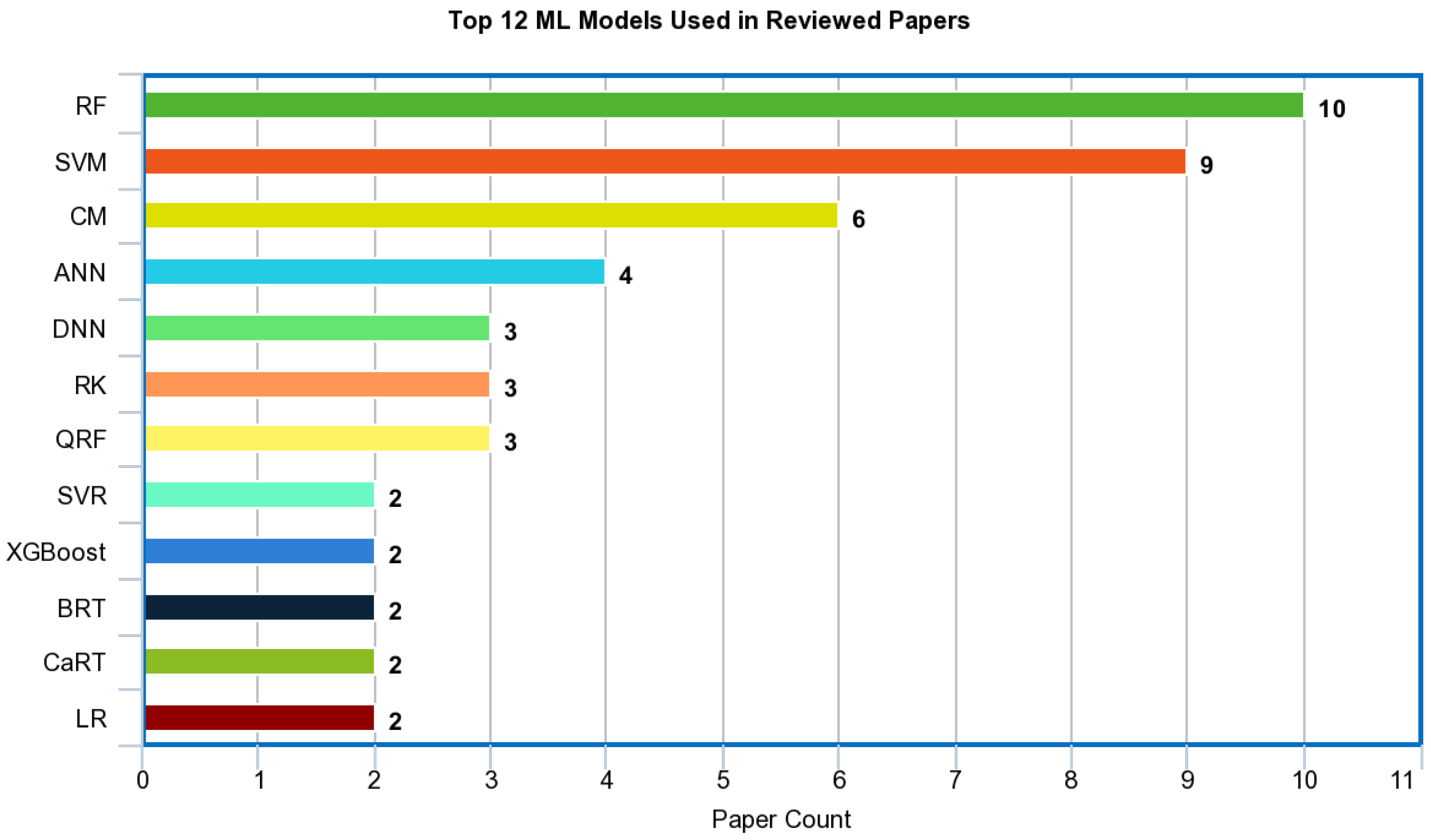{kind=link}
| Symbol | Meaning | Units | SPT |
|---|---|---|---|
| N | Nitrogen | % | SN |
| P | Phosphorus | mg | SN |
| K | Potassium | cmol | SN |
| Ca | Calcium | cmol | SN |
| Mg | Magnesium | cmol | SN |
| S | Sulphur | ppm | SN |
| Fe | Iron | ppm | TE |
| Mn | Manganese | ppm | TE |
| Cu | Copper | ppm | TE |
| Zn | Zinc | ppm | TE |
| B | Boron | ppm | TE |
| Mo | Molybdenum | ppm | TE |
| ESP | Exchangeable sodium percentage | % | SN |
| CEC | Cation exchange capacity | cmol | SN |
| Reference | Problem Addressed | AI Methods | Metric | Accuracy | Dataset Types | Limitations |
|---|---|---|---|---|---|---|
| [50] | DSM to inform gully erosion mitigation measures | MNLR, CM | KC,, RMSE | 68% | Covariate and climate data, land type maps | Soil depth map not a good representation of reality (covariate layer map required) |
| [51] | Assessment of the soil fertility status using DSM and ML | QRF, CM | , CCC, RMSE, MAE | High and average accuracy | Soil dataset (SOC, OM, Kech,, Pass, CEC, SumBas, BS) | Model accuracy was limited for some of the soil properties, such as N and Kech |
| [52,53] | Improved machine learning models accuracy in DSM | CM, RM, ANFIS, EGB, ERT, ANN, SVR, MARS, KNN, GP | RMSE, MAE, , CCC, F-score | High accuracy | Clay, sand, CaCO3, SOC, SEC, pH, K, Ca + Mg, Na, SAR, EF, MWD | Uncertainty was observed in the predicted values. Small dataset used |
| [54] | Prediction of soil depth using DSM | QRF, RK | RMSE, , CCC | 30% | Covariates dataset | Lower accuracy rate achieved due to the error in locating old coordinates |
| [55] | Soil maps for a wide range of soil properties using ML | RF, QRF, CM, SVM | Bias, , RMSE | Best accuracy achieved with QRF | Gravel, clay, sand, density, pH, SOC and soil depths (0–200 cm) 0–5, 5–15, 15–30, 30–60, 60–100 and 100–200 cm | Overestimation was observed for some probability values |
| [56] | Review on DSM algorithms and covariates for SOC mapping | RK, MLR, RF, CM, NN, BRT, SVM, GWR | - | RF performed better than others | Environmental covariates, parent material, climate factor, organic activity, topography | Performance metrics or evaluation methods not reported |
| [57] | Spatial prediction of soil aggregate using ML algorithms and environmental variables | RF, SVM, kNN, and ANN and ensemble modelling | RMSE, MAE, , and normalized RMSE | Ensemble achieved high accuracy for all soil targets | Soil properties, remote sensing data, legacy soil maps, and DEM derivatives | Lower accuracy achieved for SOC categories |
| [58,59,60] | Prediction of SOC and soil total nitrogen using DSM and ML algorithms | RF, BRT, SVM and Bagged-CART | RMSE, MAE and | BRT model performed best in predicting SOC and STN | DEM derivatives, multi-temporal Sentinel data, environmental data | Investigation using other soil properties is required |
| [61] | Predicting and mapping of SOC using ML algorithms | SVM, ANN, RF, XGBoost, CM, RT, DNN | RMSE, MAE, and CCC | DNN mapped SOC contents more accurately | Terrain attributes, remote sensing data, climatic data, categorical data | Further investigation on the dataset using hybrid algorithms is required |
| [62] | Soil moisture prediction using multi-sensor data and ML algorithm | RFR, XGBoost, SVM, CBR and GA for feature selection | RMSE and | XGBR-GA hybrid model yielded the highest performance ( = 0. 891; RMSE = 0.875%) | DEM derivatives, Sentinel-1 and Sentinel-2 data. | Testing the framework in large-scale areas with various land-use characteristics is required |
| [63] | Supervised maps for predicting soil moisture | Unsupervised SOM, supervised SOM, semi-Supervised SOM, and RF | , accuracy, and Cohen’s KC | Higher accuracy achieved with the SOM methods | Soil moisture and land cover dataset | RMSE and MAE factors are not considered in the performance evaluation |
| [64] | Predictive mapping using semi-supervised ML | Decision trees, logistic regression (LR), SVMs and graph-based semi-supervised ML (GS-ML) | Mean accuracy (%), accuracy range (%), accuracy standard deviation (%) | GS-ML achieved higher accuracy | Environmental covariate data | Improvement is required for parameter setting, RMSE, and MAE evaluations are not considered |
| [37] | ML for predicting soil classes in semi-arid landscapes | Multiple classifications and regression ML | Kappa analysis, Brier scores and confusion index | - | Environmental covariates | Model accuracy was obtained when there are few soil classes, limited dataset to investigate “rare” soil classes |
| [65] | Mapping of soil water erosion using ML models | Weighted subspace random forest, Gaussian process and naive Bayes (NB) ML methods | Accuracy, Kappa index and probability of detection | - | Soil texture, land and climate dataset | The data collection and sampling of them were not on the same scale. Also, RMSE, and MAE factors are not considered in the performance evaluation |
| [66] | Digital mapping of soil carbon fractions using ML | RF, SVM, CaRT, BaRT, BoRT, RK, OK | Mean, standard deviations, prediction error, and | RF achieved the best accuracy | Soil data (0–20 cm), carbon | Further investigation required on the use of more sophisticated predictors |
| [67] | Multi-scale DSM with DL | DL-ANN, RF | DL achieved 4–7 % than RF | Silt, clay, ZC, SFP, DEM resolution | The model is not tested with some environmental data such as climate, lithology, or land cover | |
| [68] | Semi-supervised DNN regression for spatial soil properties prediction | DNN, GA, SVR and regression methods | RMSE, MAE, , Bias, ratio of performance to inter-quartile distance | DNN achieved the highest accuracy | Hyperspectral remote sensing image data | Sensitive to the quality of the initial training dataset and model not tested with a large number of samples |
| [69] | Assessment of landslide susceptibility using DL with semi-supervised learning | DNN, SVM and LR. | Accuracy, Kappa index, predictive rate curves (AUC), and information gain ratio (IGR) | DNN achieved higher accuracy with AUC of 0.898 | Land cover and soil data | The K-means algorithm was tested using fixed value and limitation by the accuracy of layers and sampling process observed |
| Source | Solution | Soil Dataset |
|---|---|---|
| [97] | Prediction of clay soil expansion using ML models and meta-heuristic dichotomous ensemble classifier | Soil swelling and soil properties data. |
| [98] | Predicting crop yield on a particular soil using IoT | Nutritional value of soil data. |
| [99] | ML approach to simulate soil fluxes under cropping systems | Soil classification and temperature data. |
| [100] | Predicting Africa soil properties using ML techniques | Soil sample measures, soil depth (topsoil or subsoil) and climate data. |
| [101] | Soil analysis of micro-nutrients using ML and IoT | Soil micro-nutrient and soil pH data. |
| [102] | Estimation of the moisture of vineyard soils from digital photography using ML. | Soil sample and photographic data. |
| [103] | Prediction of soil shear strength parameters using ML algorithms | Soil properties and cone penetration test data. |
| [104] | Analysis of ML methods for agricultural soil health management | Secondary data. |
| [105] | Crops yield prediction based on mL models in West African countries | Climate, yields, pesticides and chemical data. |
| Source | Application Name | Year | Functions |
|---|---|---|---|
| [106] | SQAPP | 2015 | Sustainability of SM and high productivity |
| [107] | SoilWeb | 1999 | Instantaneous soil information |
| [108] | AgriApp | 2014 | Crop advisory, soil testing and drone services |
| [109] | LandPKS | 2020 | Soil health monitoring and land management |
| [110] | Crop App Index | 2017 | Agricultural decision support tool |
| [111] | MySoil Test Kit | Not Specified | Information to improve soil and plant health |
| [112] | SIFSS | 2017 | Provides indication scores for soil types. |
| [113] | Soil Test Pro | 2019 | Soil nutrient management system |
| [114] | SoilScapes | Not Specified | Digital smart information system |
| [115] | SoilInfo App | 2017 | Generate open soil data |
| [116] | SoilCares | 2021 | Smart application for monitoring soil nutrients and soil fertility |
| ML Technique | Strengths | Weaknesses |
|---|---|---|
| Support Vector Machine [132,133] | Effective in high-dimensional spaces, less prone to overfitting, versatile kernel functions, effective with small to medium datasets, insensitive to irrelevant features | Performs poorly with large or noisy data. Highly sensitive to hyparameter tuning |
| k-Nearest Neighbours [134,135] | Simple, highly intuitive, non-parametric, flexible decision boundaries, considers the local structure of the data, can be effective with both linear and non-linear relationships, handles outliers relatively more efficiently | There is high computational complexity during prediction phase, distance metric selection may be ambiguous, sensitive to the curse of dimensionality, struggles with imbalance data, has storage issues during prediction |
| Decision Trees [136,137] | Offers good explainability and interpretability, cognaissant to feature importance, handles non-linear relationships among features relatively well, good for mixed data (categorical + non-categorical), has low computational complexity, handles outliers well | Prone to overfitting, highly unstable, especially to a slight variation in the training set, makes locally optimal decisions without considering the global optimal structure, tends to favour features with a large number of categories or high cardinality, not well-suited for problems where classes are linearly separable, struggle to represent complex relationships that require global knowledge or long-range dependencies in the data |
| Linear Regression [138,139] | Interpretable, simple, resource efficient, robust feature importance identification, often useful as a baseline model for comparison with more complex algorithms | Often assumes a linear relationship between the input features and the target variable, does not handle outliers efficiently, relatively limited predictive power, naive assumption of homoscedasticity, also sensitive to multicollinearity |
| Logistic Regression [140,141,142] | Interpretability, efficiency, probabilistic problems, less prone to overfitting and allows for internal feature selection | Assumes linearity like the linear counterpart, handles limited complexity, cannot handle outliers, limited for binary classification, and can be afftected by imbalance dataset |
| Artificial Neural Network [143,144,145] | Ability to learn complex patterns, flexible architecture, automatically learn relevant features, supports parallel processing and has high generalization power thereby reducing fitting problems | Requires large amount of data, has high computational complexity, they lack good interpretability because of their black-box nature, sensitive to hyperparameter tuning |
| Naive Bayes [146] | Efficient with large datasets, scalable, robust to irrelavant features, effective with limited training sets, interpretable | Sensitive to skewness, does not capture complex relationships between features, highly sensitive to scaling problems |
| Random Forest [147] | Known for high accuracy, handles outliers and noisy data, handles high cardinality, good with variable importance, resistant to overfitting | Lacks explainability, computationally expensive, requires good hyperparameter tunning for optimal performance, biased towards majority classes |
| Gradient Boosting [148] | High predictive accuracy, high flexibility in handling mixed data types, provides insights into feature importance, handles outliers internally, handles missing data, can be parrallelized efficiently | Computationally expensive, has a potential problem of overfitting, difficult to interpret, relies heavuly on the order (or sequence) of the training data |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Folorunso, O.; Ojo, O.; Busari, M.; Adebayo, M.; Joshua, A.; Folorunso, D.; Ugwunna, C.O.; Olabanjo, O.; Olabanjo, O. Exploring Machine Learning Models for Soil Nutrient Properties Prediction: A Systematic Review. Big Data Cogn. Comput. 2023, 7, 113. https://doi.org/10.3390/bdcc7020113
Folorunso O, Ojo O, Busari M, Adebayo M, Joshua A, Folorunso D, Ugwunna CO, Olabanjo O, Olabanjo O. Exploring Machine Learning Models for Soil Nutrient Properties Prediction: A Systematic Review. Big Data and Cognitive Computing. 2023; 7(2):113. https://doi.org/10.3390/bdcc7020113
Chicago/Turabian StyleFolorunso, Olusegun, Oluwafolake Ojo, Mutiu Busari, Muftau Adebayo, Adejumobi Joshua, Daniel Folorunso, Charles Okechukwu Ugwunna, Olufemi Olabanjo, and Olusola Olabanjo. 2023. "Exploring Machine Learning Models for Soil Nutrient Properties Prediction: A Systematic Review" Big Data and Cognitive Computing 7, no. 2: 113. https://doi.org/10.3390/bdcc7020113
APA StyleFolorunso, O., Ojo, O., Busari, M., Adebayo, M., Joshua, A., Folorunso, D., Ugwunna, C. O., Olabanjo, O., & Olabanjo, O. (2023). Exploring Machine Learning Models for Soil Nutrient Properties Prediction: A Systematic Review. Big Data and Cognitive Computing, 7(2), 113. https://doi.org/10.3390/bdcc7020113