1. Introduction
Complex networks are used to model real-world systems such as social networks, biological entities, ecological systems, or communication networks. Citation networks, friendship networks, airline networks, mobile communication networks, and protein–protein interactions networks are a few examples of complex networks [
1,
2]. These systems have certain distinct characteristics. Firstly, they are very large, comprising thousands to even millions of entities. Secondly, the entities tend to interact with each other and evolve over time in ways that are difficult to predict. Thirdly, entities exhibit multiple behaviors. Lastly, entities share multiple relationships among themselves. The evolution of complex networks has been a topic of great importance since it is fundamental to correct the characterization of real-world systems. In other words, a complex network serves as a good model only to the extent that its evolution reflects the evolution of real-world systems, thereby allowing the use of the model to predict the real-world. Since the entities and their interconnections turn out to be complex in these networks, predicting the evolution of complex networks remains a challenging task. At a more fundamental level, evolution can be viewed as a series of changes within the network, wherein new entities appear, existing entities disappear, and two non-interacting existing entities start an interaction. The pace at which these changes happen also contributes to the complexity [
3,
4].
Graphs are fundamental data structures to represent any network. Mathematically, a graph,
G =
, where the vertex set is denoted by
V, where
, and the edges are denoted by
E, where
. The vertices represent the entities, and the edges represent the relationship between the entities. Complex networks comprise multiple subsystems, and hence, a simple graph representation is not sufficient. Consider a citation network with different kinds of entities papers, authors, citations, keywords, publication year, and several other characteristics.
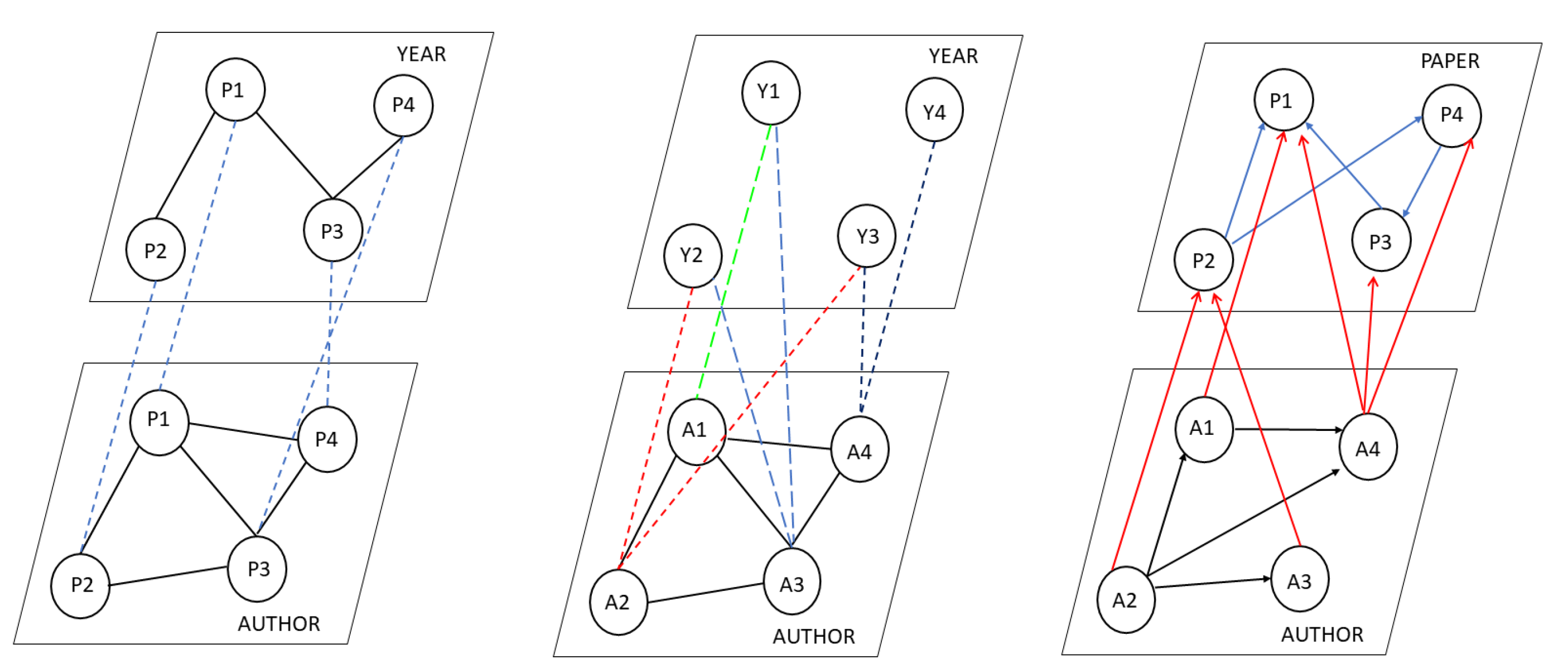
Figure 1 provides three different representations of citation networks of such a network arranged hierarchically in the form of layers. For simplicity, the representations consider only a couple of characteristics. In the first representation given in
Figure 1 (left), every layer consists of the same set of nodes, i.e., papers. The intra-layer links depict the relationship based on a specific aspect such as the author or publication year. For example, the link between two publications at the author layer could indicate that they share a common author. The inter-layer links depict the common aspects between the entities. It should be noted that we associate meaning with the intra- and inter-links. In the second representation given in
Figure 1 (middle), each layer consists of different sets of nodes. The lower layer is the authors, and the higher layer is the publication year. Again, the meaning of intra- and inter-layer links is associated by us. Both are multilayered representations.
There needs to be more than the monoplex network representation of the objects and the relations, for instance hosting objects and relations of different scales, called
multilayer networks. A multilayer network is defined as a set of nodes, edges, and layers, where the layers’ interpretation depends on the model’s implementation. Kivelä et al. [
5] defined a multilayer network as a quadruple,
, in which the network is a collection of elementary layers
stacked together. A layer is associated with a layer number and an aspect
d.
represents the set of vertices in each layer. Let
be a layer; the set of vertices of layer
is denoted as
. The set of all vertices in the network is represented as
V. Mathematically,
. The interconnection of vertices is represented as
.
It turns out that working with directed multilayer networks requires certain additional considerations as opposed to undirected networks [
6]. To appreciate this, consider the network given in
Figure 1 (right). It is a directed multilayer network with two layers with the aspects being the authors and papers. The entities in the author layer denote the authors, and the entities in the paper layer denote the published paper. The links among the authors depict the author–author collaboration. A directed edge from the author layer to the paper layer depicts the paper published by the authors. The interrelationship among the papers elaborates the details of the citations. For instance, an edge from P2 to P1 means that paper P2 cites P1. The multilayer networks can represent:
The relationship among the different nodes in the same layer;
The relationships among the nodes that (possibly) belong to different layers;
Each layer exhibiting a common aspect.
Complex networks, such as the WWW, airline transportation networks, and Twitter, have directed edges. The challenge in such networks is that not all nodes are reachable from a given node. Such complex networks exhibit that incoming and outgoing edges could follow different scaling laws. Studying such large-sized directed networks paves the way toward other topological structures. Detailed structural analyses of the network are crucial to obtain the out-degree distribution with a power-law behavior. The multilayer network deploys tensor algebra for representation. A multi-linear graph represents a product of two vector spaces,
. It is a linear combination of
, where
and
:
Link prediction plays a prominent role in suggesting the future or the missing links in a social–biological complex network. Link prediction also has a wide range of applications in different industries [
7]. Link prediction finds its application in the domains of social networks for friend recommendation, citation networks for future citations, and the biological network for protein–protein interaction [
8,
9,
10].
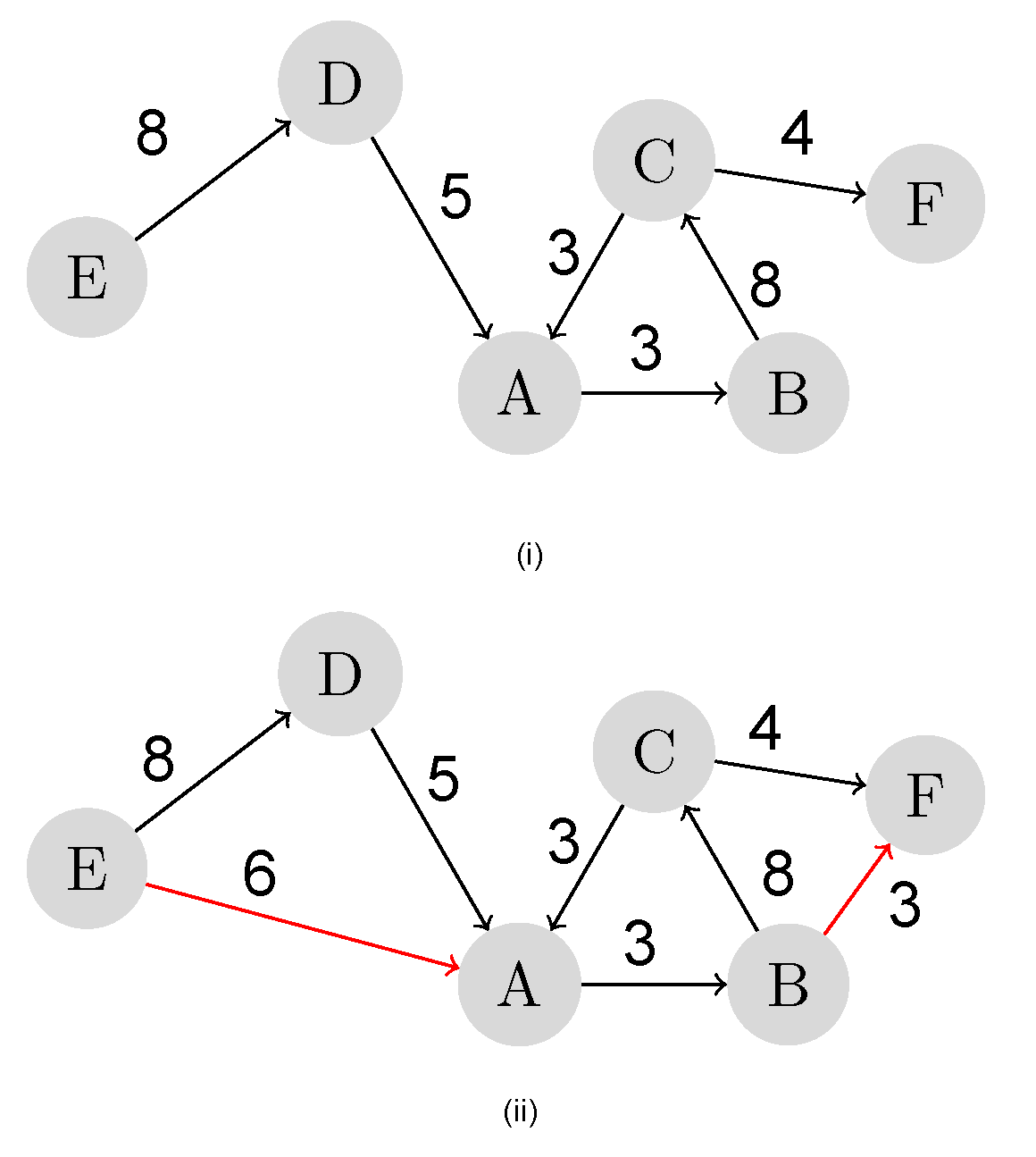
Figure 2i is a snapshot of a weighted directed network, and the possible future links among the nodes are identified and established based on the least path weight, as depicted in
Figure 2ii. Link prediction is an approach to detect such potential relations among individuals in social networks.
In real-time, the complex network comprises thousands of nodes. The major challenge in link prediction is retrieving the proper amount of information to perform the prediction and the enhanced algorithmic techniques to provide accurate predictions. Limitations in the availability of the attributes of the nodes redirect the link prediction algorithms to focus on the underlying network topology, which is based solely on the network structure. Most research focuses on the structural similarity indices classified as local and global.
In the local structural similarity approach, we considered the node link strengths to compute the similarity between the nodes so that they might have a link [
11,
12]. The local-path-based link prediction considers the structural information and the fixed distance between the nodes. The information of the nodes that lie on the set of all possible paths of a smaller length was considered [
13,
14]. The standard framework of link prediction methods is the similarity-based algorithm, where each pair of nodes,
x and
y, is assigned a score
, defined as the similarity between
x and
y. We computed the scores between the non-observed nodes. The higher the score, the higher the likelihood of links in the future is. The local and global indices use the network properties, such as
node centrality, edge count, or edge weights, among many others. Similarity measures such as the Common Neighbors (CNs) [
15], Jaccard’s Coefficient (JACC), Preferential Attachment (PA) [
16], Adamic–Adar index (AA) [
17,
18], and Cosine Similarity (CS) [
19] use topological information for link prediction. As the properties of the networks vary, the link prediction methods also vary. These methods cannot be more accurate since they exploit limited information. The main drawback of local indices is that local information restricts the set of nodes’ similarity to be computed at two nodes’ distance.
Many traditional algorithms that aim to compute pairwise similarities between vertices of such a big graph need to be more accurate. Random walk utilizes a Markov chain, which describes the sequence of nodes visited by a random walker. The transition probability matrix can describe this process. Indices use the entire network’s topological information to score each link. Global indices such as the Katz index and Random Walk with Restart (RWR) can provide much more accurate predictions than the local ones. The main disadvantages of the global indices are that (i) the calculation of a global index is time-consuming, (ii) it might not be feasible for large-scale networks, and (iii) the global topological information is not available. The local and global indices are applied to undirected networks.
Extensive research is currently being carried out to overcome the drawbacks of link prediction using network structure alone.
Section 2 discusses this more. New approaches utilize the statistical and probabilistic approach toward link prediction. These approaches necessitate the network structure by maximizing the likelihood of the observed structure. Then, the likelihood of any non-observed link is calculated according to the newly inferred information.
This article proposes an enhanced link prediction framework. Broadly, we considered the real-time situations of predicting the future links in the network. A link may originate in the future between two entities belonging to two different groups or block in an entire network emerging (inter-community). The term
block refers to the group of nodes exhibiting a common behavior. Our framework was tailored to consider the global network structure of directed multilayered complex networks and applies a suitable probabilistic approach to predict the likelihood of the occurrence of a link. This enabled us to acquire deeper insights into the network’s organization, which cannot be gained from similarity-based algorithms. Hence, the significant contributions of this article are proposing the stochastic block modeling approach for link prediction by (i) an improvised algorithm to identify influential nodes in the directed multilayered complex network using
m-PageRank, (ii) the
global clustering of the influential nodes by extending the correlation to inter-layer nodes, (iii) predicting the probability of occurrence of future links in the network using the
maximum likelihood estimation (MLE), and (iv) empirically proving the improved accuracy and precision with social, biological, and ecological datasets. This article is organized as follows:
Section 2 surveys the related work in this area. The link prediction using stochastic block modeling is illustrated in
Section 3. The experimentation and implementation of the model are illustrated in
Section 4. Finally, the article is concluded in
Section 5.
2. Background Study
Predicting the likelihood of a link between two unconnected nodes is an interesting problem. Social network applications such as Facebook, Instagram, and Twitter require link prediction to suggest friends to a user. Link prediction also predicts missing links in a network [
20,
21,
22].
Local indices are most suitable for undirected large-scale networks, as they consider the local information by comparing the degree of overlap among the nodes. Global indices take the properties of the whole social network into account. Random walk techniques [
23,
24,
25,
26] and PageRank techniques [
27,
28] are a few prominent metrics among them. On the other hand, semi-local indices omit information that makes little contribution to improving the prediction algorithm [
29]. The global similarity indices depend on the amount of reachability between the nodes. Hence, the link prediction occurs only for prominent nodes and is, therefore, not wholly reliable.
In today’s era of data explosion, many large-scale social networks need to be processed and analyzed urgently, and predictions are needed based on the similarity of local nodes. Large-scale networks also demand that the algorithm be highly efficient and time-saving. The classical clustering algorithms measure local information such as Common Neighbors (CNs), the Jaccard Coefficient (JACC), and the Adamic–Adar index (AA). These algorithms mainly consider the degree or number of common neighbor nodes. The local measures such as the common neighbors, Adamic–Adar index, and resource allocation lack performance in a directed network. These algorithms are not suitable for a scale-free network. The drawbacks of local measures are:
- -
The local measures based on the common neighborhood will prevent the likelihood of prediction of link establishment.
- -
The local measures fail to consider the proximity of direction. Hence, prediction fails for directed graphs.
Much research has been carried out for link prediction using score-based approaches, machine learning approaches, and probabilistic approaches. Predicting the links by analyzing the topological structures of the underlying network adopts a score-based approach. This approach predicts a link by calculating the similarity score for every pair of nodes.
The researchers in [
30,
31] used the local main path degree index to predict the probability of a link between two nodes. The degree distribution and path strength between nodes are also used to find similarity information. In [
32,
33], the authors considered the entropy information of the shortest path between node pairs and proposed the Path Entropy (PE) indicator for predicting links.
The link prediction is posed as a binary classification problem. The supervised and unsupervised machine learning approaches are widely used for link prediction. In the supervised ML approach, the prediction task is carried by a classifier and uses approaches such as naïve Bayes, neural networks, decision trees, Support Vector Machine (SVM), k-nearest neighbors, bagging, boosting, and logistic regression [
34,
35]. On the other hand, in unsupervised machine learning, clustering techniques are used to predict the links. The probabilistic approach uses the Bayesian graphical model by considering the joint probability among the nodes in a network to predict the link. When the network sizes increase with the increase of the nodes and edges, the machine learning approach to link prediction suffers from computational complexities.
Methods such as the edge convolution operation [
36], binary classification [
37], and light gradient-boosted machine classification [
38] approaches are adopted in deep learning models for predicting the links. To improve the link prediction performance, these deep learning models adopt more features such as the node’s interaction with neighbors, the self-degree, the out-degree, and the in-degree. Such considerations elaborate that the deep learning models also depend on the local indices. In the articles [
39,
40,
41], the authors identified the local influencers to predict the link. The authors in [
42] considered vertex ordering using the network topology information for the link predictions.
3. Stochastic Block Modeling
We propose a Stochastic Block Model (SBM) framework for solving the link prediction in directed complex networks. A block refers to a smaller group of connected nodes exhibiting a common property, which could be local or global, such as attributes and closeness. A block model or generative model refers to the collection of such blocks exhibiting some property on the data analysis performed. In the SBM, we provide a stochastic generalization of the blocks using a statistical or probabilistic approach. We formulated an estimation technique for establishing a relationship within the nodes in the network. The block model helps the distribution of the relationship between nodes. Such assumed relationships are dependent on the blocks to which the nodes belong. The relationship is established using a probabilistic estimation—the maximum likelihood estimation—to establish the relation, thereby predicting the links. It is a three-stage approach comprising:
- i.
Designing an improvised algorithm to identify the influential nodes in the directed multilayered complex network using m-PageRank.
- ii.
Performing global clustering of the influential nodes by extending the correlation to inter-layer nodes.
- iii.
Predicting the probability of occurrence of future links in the network using the maximum likelihood estimation.
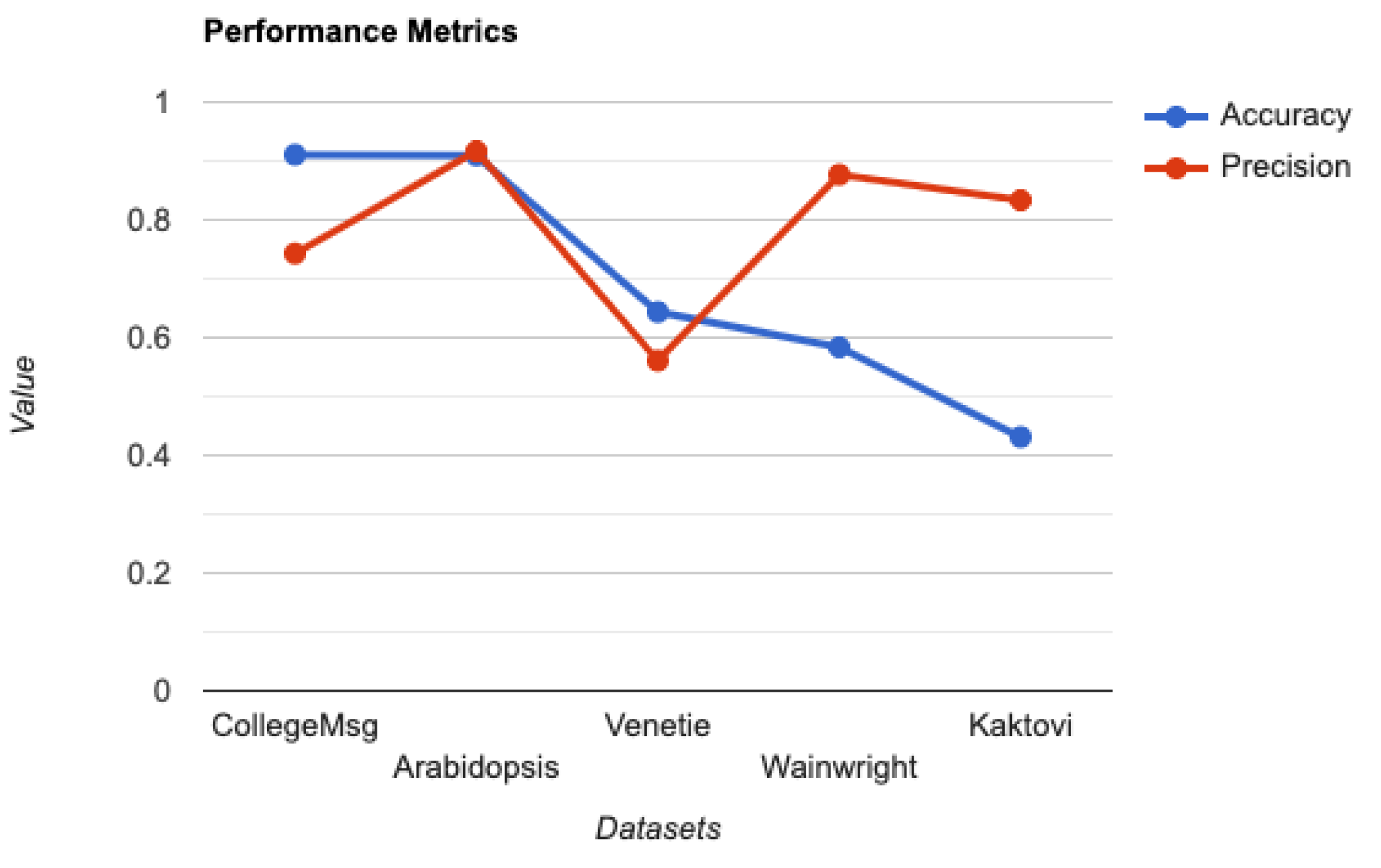
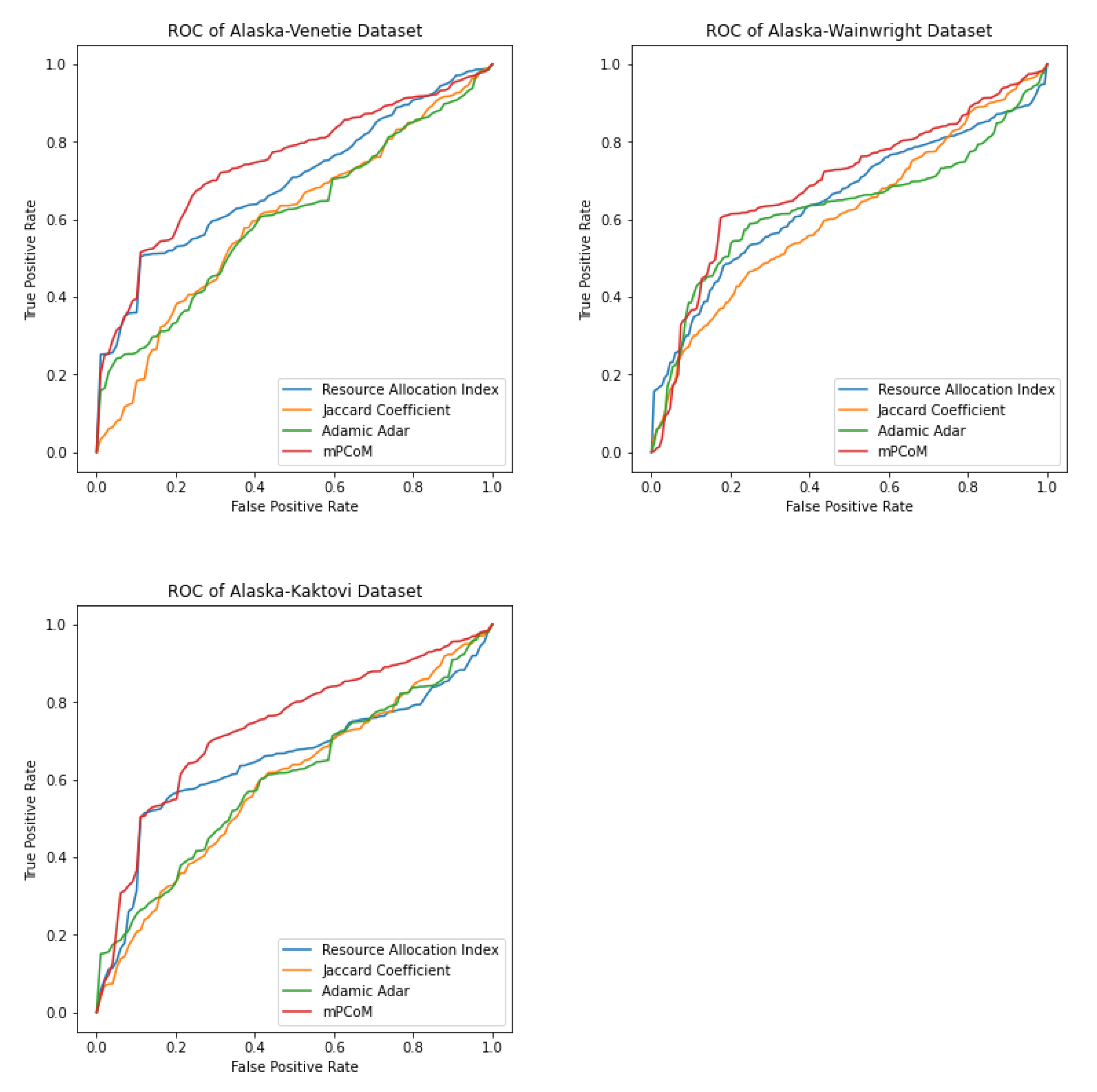
We refer to this stochastic block modeling approach as mPCoM, where mP refers to m-PageRank, Co refers to the clustering Coefficient, and M refers to the Maximum likelihood estimation. We validated the mPCoM using three different datasets from the social, biological, and ecological domains.
3.1. Identifying Influencers Using m-PageRank
An
influencer in a network is a central node with more incoming edges. Influencers in the complex network help shape the network’s dynamics [
43,
44]. In a social network that exhibits a
follower–followee relationship, the nodes may establish a relationship with a highly influential node. In a social network, the node with more incoming edges represents an influencer, since it refers to an entity (person, product, or web page) with more followers. Identifying influencers helps in various real-world tasks, such as viral marketing, epidemic outbreaks, and cascading failure. Centrality measures such as the degree, k-core, closeness, betweenness, eigenvector, and PageRank are used to identify potential influencers in complex networks.
A network or a sub-network may have one or more influencers. The nodes in a network tend to establish a link to the influencers more often than to other nodes. There needs to be more than this definition of an influencer in a multilayer network. In a multilayer network, the incoming edges of a node v can come from either the same or different layers. In the former case, v is an influencer in that layer (local influencer). In the latter case, v is an influencer globally. We focused on identifying global influencers. Furthermore, there can exist more than one influencer in a layer.
To identify the global influencer, more weight is given to an incoming edge if it comes from another layer. Furthermore, the weight of the layers differs. Since we considered a directed multilayer network, a PageRank algorithm for a multilayer network will enable us to identify the influencers. We selected the
m-PageRank algorithm for this purpose [
45,
46]. The nodes with higher PageRank values will be the influencers. In a multilayer network, we associated a weight for the layers for computing the PageRank. The layer weight increases with an increase in active nodes. Usually, the layer weights are assumed from the ground truth of the dataset, or we assumed that, initially, all layers have equal weights.
The computation of the PageRank of a vertex in a multilayer network is broadly a two-phase process. (1) The PageRank of all nodes is computed considering the incoming edges from that layer only. (2) The PageRank of all nodes is re-computed by a two-step iterative process. (a) The layer weights are initialized to 1, and the PageRank of all the nodes is computed based on the layer weights and the current PageRank. (b) This PageRank is used to re-compute the layer weights. This layer weight and PageRank re-computation process is continued for all layers and nodes, respectively, until the PageRank converges. The nodes with higher ranks are higher influencers. The top influencers are picked based on the threshold specified by the user.
Now, we proceed to describe the m-PageRank computation in more detail. Initially, we establish the definitions of important terms.
Definition 1. Let v be the node such that in a network, and the PageRank of node v, , is the ratio of incoming edges of v to the total number of edges. For simplicity, we initialized the PageRank of all nodes to , where N is the total number of nodes in the network.
Definition 2. Let L represent the stack of layers in the network such that …. The layer weight denotes the importance of the layer, computed by the cumulative weight of the nodes in an individual layer. We initialized the weight of all the layers to 1. The weight of the layer increases with more active nodes in the layer.
Definition 3. The PageRank of node v in the lth layer, , is computed as the product of the layer weight (weight of the lth layer containing the node v) and the PageRank of v in the lth layer, , i.e., .
Definition 4. We define the damping factor d, which represents the probability with the proportion of time that the vertex will randomly follow a vertex . The value of the damping factor affects the convergence rate of PageRank. A low damping factor means that the relative PageRank will be determined by the PageRank received from external nodes A high damping factor will result in the node’s total PageRank growing higher. Ideally, the value of the damping factor is .
The layers with more active nodes of a high PageRank and high in-strength are given more weights. Hence, we computed the inter-layer adjacency matrix for all
V. This is again an iterative process. The adjacency matrix is computed as
Hence, the PageRank in a multilayer network
is computed iteratively considering the initial PageRank of all the vertices in the network cumulated with the product of the layer weight to the PageRank of every vertex and normalized by the damping factor. This is equated as
We illustrate the same with an example. Consider a multilayer network with two layers and seven nodes, as shown in
Figure 3. We computed the m-PageRank for all the nodes using Equation (
3). The ranking after 14 iterations is captured in
Table 1. From the computation, it was observed that
and
have the highest PageRank. The incoming links from the above layer contributed to this.
Algorithm 1 elaborates the steps for identifying the influencers in the multilayer network.
When the m-PageRank calculations have settled down, the
normalized probability distribution, which is the
average m-PageRank for each node, will be
. The high PageRank-valued nodes above a threshold were selected as the
influencers. A link is more often established from a node as an influencer.
| Algorithm 1 Influencers’ identification using m-PageRank. |
| Input:, |
Output:- 1:
procedureinfluencer-idef(G) - 2:
Initialize - 3:
for do - 4:
- 5:
end for - 6:
for each do - 7:
- 8:
end for - 9:
return I - 10:
end procedure
|
3.2. Building Blocks Using Correlation
We built the set of blocks around the influencers, I. For that, from the set of influencers, we calculated the correlation between the influencer and every pair of nodes to form the blocks. This was performed using the global clustering coefficient. A clustering coefficient is a measure of the degree to which nodes in a graph tend to cluster together. At least three nodes are needed to form a cluster or block. The basic idea of forming a block is as follows.
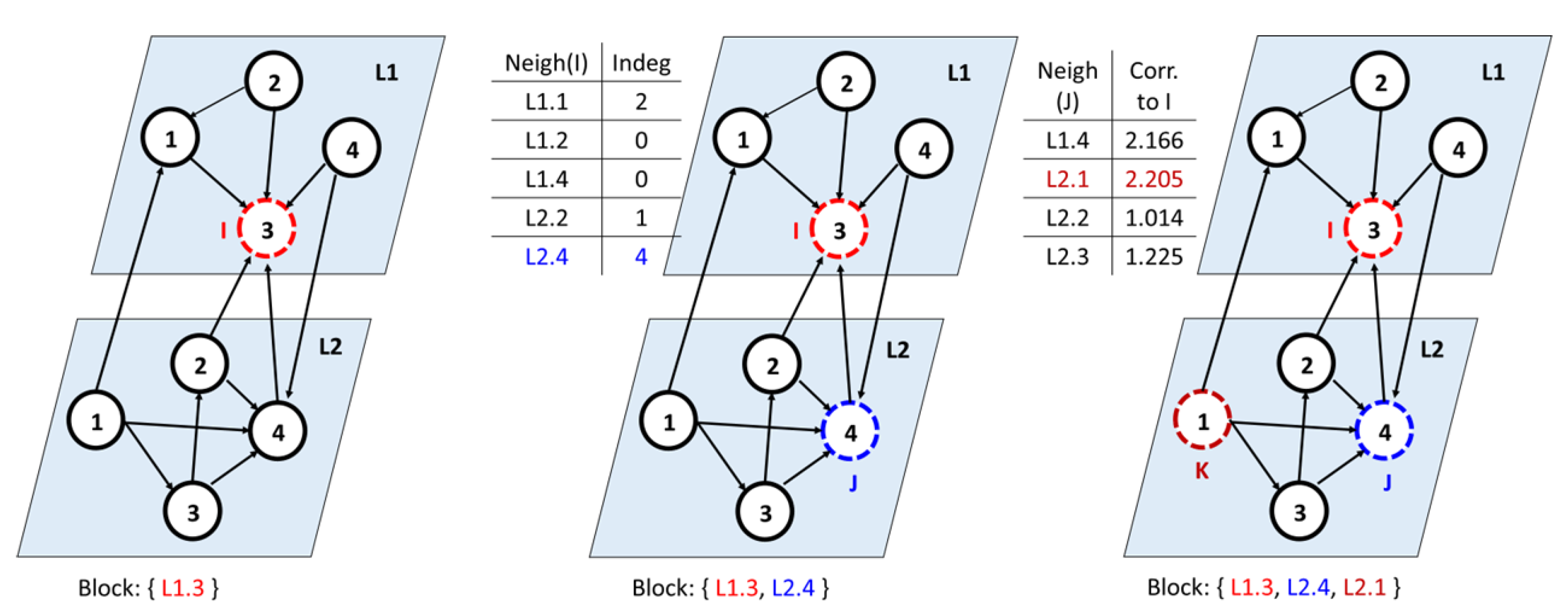
Consider the complex network with two layers, in which the nodes with the highest in-degree are an identified influencer
I.
Figure 4 shows an example of a multilayer network with Node 3 as the influencer from Layer 1. Among all the neighboring nodes of
I, we determined a node with the highest in-degree, denoted as
j. This is because in-degree(j) = 4 > in-degree(
). Now,
j is added to
I’s block. Next, for all neighbors of
j, compute the correlation with
I using the global clustering coefficient. To this end, we picked each neighbor
k of node
j and computed the correlation with
I. The node
k is added to the block if it has a higher correlation. Ideally, the nodes
exhibit a closed triad structure, as shown in the figure. We continued with all the other influencers and constructed the blocks.
Hence, to formally define clustering coefficients in a multilayer context, we first define the triangle structure or
triad structure [
47].
Definition 5. We define a triad of nodes lying up to three different layers such that the vertices in the triangles are connected by inter- or intra-layer arcs, irrespective of their orientation. This way, we can consider all possible closed triads in the inter- or intra-layer directions.
The global clustering coefficient depends on the relation between the degree of the node in the layer and the total degree of all nodes in the layer.
Definition 6. Let L represent the stack of layers in the network such that …, be the degree of node v, and represent the nodes directly connected between the neighbor nodes of node v, then the clustering coefficient, , is Definition 7. Let be between node x and y, and let be the node centrality of v; α and β are adjustable parameters such that , is the set of neighbor nodes of node v, and is the clustering coefficient of v, then We start by taking each influencer in its blocks and merging the highly correlated blocks. We stop the process when the desired number of clusters is formed. If the nodes in the highest correlated pair belong to different blocks, we merge these two blocks into a single one using a
Merge function; otherwise, we move to the next-highest correlated pair. This process is elaborated in Algorithm 2. Thus, we obtain different blocks from the complex network. Now, we predict the links among the nodes belonging to such different blocks.
| Algorithm 2 Block formation using correlation. |
| Input: |
| Output: Blocks B; |
- 1:
procedureBlock formation() - 2:
Initialize - 3:
- 4:
for do - 5:
- 6:
return B - 7:
break - 8:
end for - 9:
end procedure - 10:
procedureMerge() - 11:
if then - 12:
- 13:
end if - 14:
end procedure
|
3.3. Link Prediction Using Maximum Likelihood Estimation
The identification of influencers followed by determining the blocks around them ensures both the global and local information form the basis for link prediction. The next goal is to predict the future links between pairs of blocks. To this end, we picked each pair of blocks and determined the links between the nodes of one block and the nodes of the other. Assuming n blocks, we have a total of n*(n − 1) block pairs. Among these block pairs, we determined the pair that has the highest likelihood using the maximum likelihood estimation. Let the network be now partitioned into multiple blocks B, such that . We computed the probability of the existence among two nodes a and b, such that each node belongs to a different block.
Definition 8. Let be the number of edges between the nodes in the block and . Assume to be the edge between node x and node y, such that and , and is the number of pairs between the nodes of blocks , . Then, the probability of the existence of a link between x and y is found as We compute the likelihood of the existence of a link,
, among the blocks as:
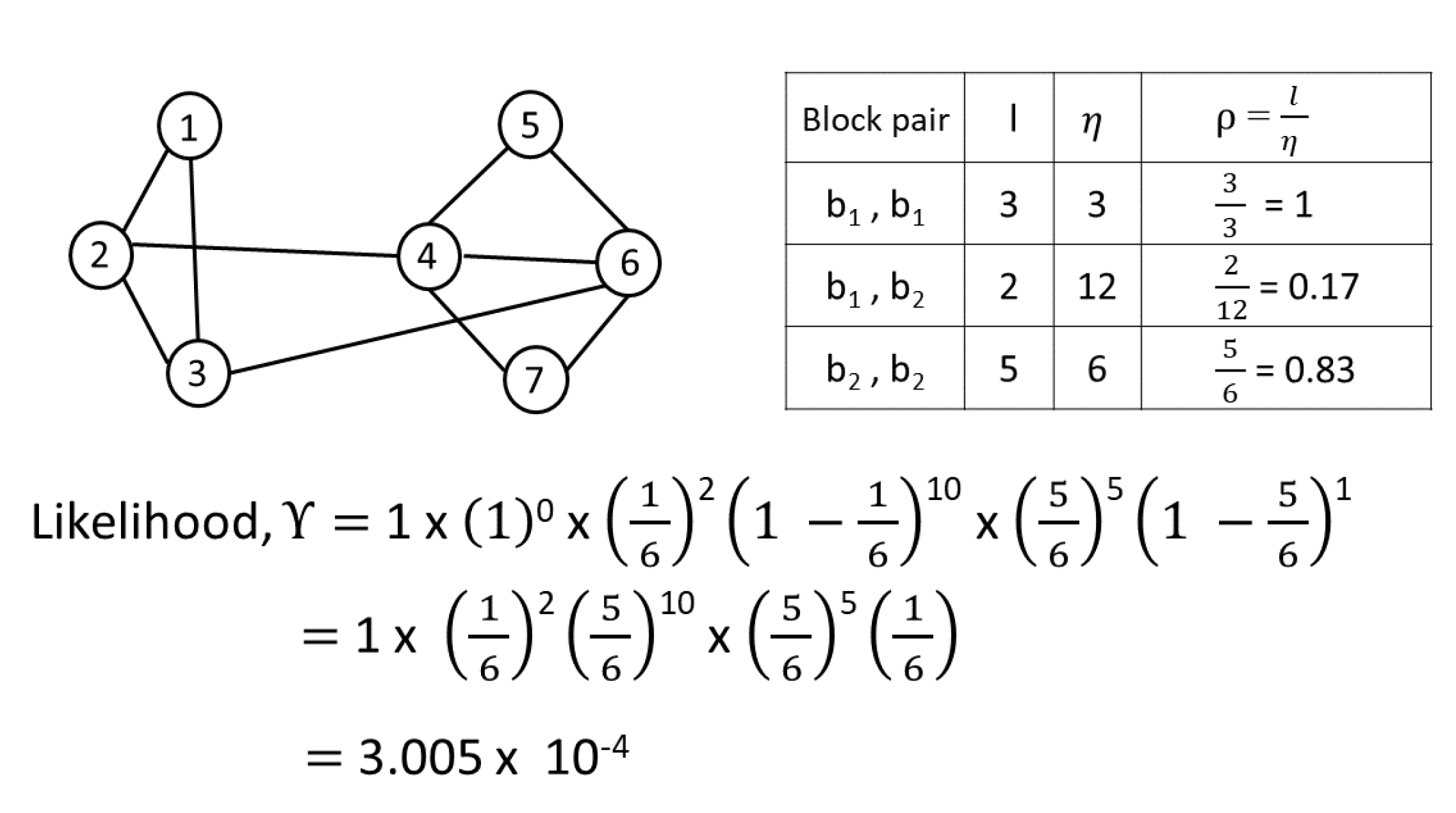
Consider the network given in
Figure 5, with two blocks. The computations of
are performed as per Equations (
6) and (
7). Considering all pairs of blocks,
, the probability of a link with maximum likelihood
can be computed as:
The higher the likelihood, the higher the probability of link formation between two nodes is. Algorithm 3 elaborates the link prediction process using the maximum likelihood estimation.
| Algorithm 3 Link prediction using MLE. |
| Input: Blocks ; ; nodes: ; threshold: ;
|
| Output: probability values; |
- 1:
procedureLinkPrediction() - 2:
for do - 3:
- 4:
end for - 5:
if then - 6:
Return values - 7:
end if - 8:
end procedure
|
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}