1. Introduction
Frictional unemployment is linked to informational imperfections, due to the costs of collecting, processing, and disseminating information, as well as to the asymmetry of information between suppliers and applicants, and the cognitive limitations of individuals. These imperfections are one of the reasons why some jobs remain unoccupied even though significant unemployment is observed in the same employment sectors.
Although the problems of job search and of finding potential candidates are identical from an abstract point of view, they nevertheless differ greatly in practice. Classically, a job seeker writes a resume that will be sent to the human resources (HR) departments of the hundreds of companies to which he or she applies. The quality of a resume plays a decisive role in recruitment, particularly in the context of high unemployment, where an HR director receives hundreds of resumes for each open position. The situation has evolved with the influx of companies, particularly on the Web (LinkedIn, Indeed, Monster, Qapa, MeteoJob, Keljob), offering employment access assistance services.
Several recommendations based on job descriptions and resumes using keywords or information retrieval techniques have been proposed (e.g., [
1,
2,
3,
4,
5,
6]). The problems encountered are linked, among other things, to the different nature of the languages used to describe the users (job seekers) and the objects (job offers). One solution involves defining standard skills, ideally constituting a common language between offers and resumes.
However, this list of skills only partially answers the problem posed. First of all, it is a list that evolves more slowly than the professions and skills required in all sectors (from low-skilled social professions to high-tech professions). Secondly, the identification by users of terms corresponding to their real skills leads to some noise; symmetrically, recruiters may also only partially identify the relevant skills for the positions to be filled.
In addition, other factors come into play during a direct match between resumes and offers. Indeed, offers and resumes involve semi-structured information, containing, in addition to skills and experience, geographical notions, a salary range, and development prospects. The importance of this information depends on the context, the sector of employment and the position to be filled.
Following this analysis of the need and the evolution of uses, the implementation of systems of personalized reciprocal recommendation of job offers to job seekers and potential candidates to recruiters thus appear as one of the keys to combat frictional unemployment.
Our work is based on the idea that better access to information would improve the situation in terms of finding jobs for job seekers and potential candidates for recruiters, would reduce the cost in terms of time and opportunity, and would make it possible to remedy to a certain extent the phenomenon of frictional unemployment.
The main contributions of this article can be summarized as:
Helping job seekers to find how their skills stack up against the most sought jobs and also recommend job postings that match the skills reflected in their resumes.
Offering recruiters an engine that facilitates the identification and hiring of candidates.
Improving the matching between candidates and job offers.
Improving the computerized recruitment process.
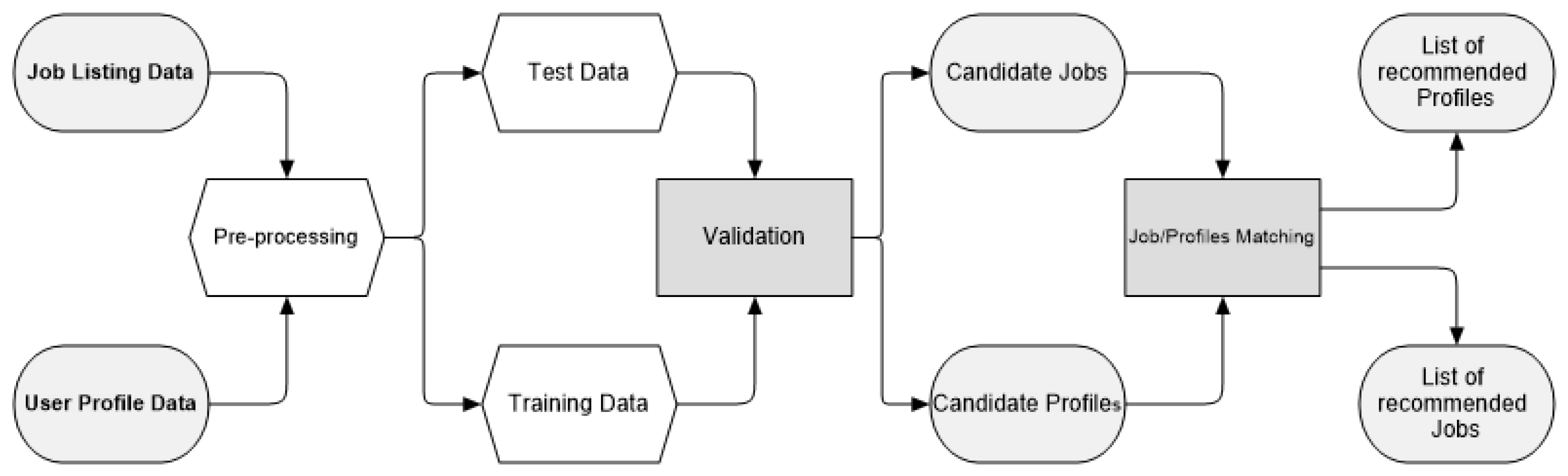
Figure 1 shows the flowchart of the bi-directional recommender system. The inputs of our process are job listing and user profiles data. Pre-processing and training are performed to generate candidate profiles and jobs. Finally, matching is performed to generate a list of recommended jobs for job seekers and a list of recommended profiles for employers.
The remainder of this paper consists of seven sections. Related work is highlighted in
Section 2. Natural Language Processing (NLP) and representations are presented in
Section 3. The proposed bi-directional recommender system is detailed in
Section 4. The methods used for building the recommender model are presented and subsequently described in
Section 5. Discussion is presented in
Section 6 followed by a brief summary of the paper’s contributions and future works.
2. Related Work
Recommender systems are designed to reduce the amount of information that a user has to wade through to find the information or item that he is interested in; which could be frustrating [
7,
8].
The literature has proposed a variety of approaches to recommendation, but we are mainly focusing on the most recent recommendations.
The collaborative filtering (CF) system identifies neighbors who have similar expectations and offers items based on their ratings [
9,
10]. In online bookstores, for example, users will be offered book suggestions based on what their closest neighbors are interested in, what they have purchased, and what they have rated [
11,
12,
13].
Recruiters can use this strategy if they want more candidates. Their preferences would be analyzed for a few candidates and more candidates would be offered to the recruiters. Other recruiters would retain these candidates if they share the recruiter’s preferences.
An expectation-maximization (EM) algorithm was used by the authors in [
13] as the basis for their bi-directional collaborative filtering method. Through iteration of this process, they combined user ratings with item ratings to build a general rating matrix.
In order to provide relevant elements to the user, content-based filtering (CBF) relies heavily on the information the user provides (his profile, for example) [
14,
15,
16,
17,
18]. This is the approach we used in our study.
In these systems, a set of items and/or descriptions previously preferred by a user is analyzed, and a model is developed based on those items’ characteristics to model the user’s interests [
19,
20].
In traditional recommendation systems like CF and CBF models, item interactions are static and only capture the user’s general preferences, but in the sequential recommendation system (SRS), the item interaction is a dynamic sequence [
21,
22,
23,
24,
25]. To model user behavior sequences, the authors of [
24] proposed a sequential recommendation model that employs deep bidirectional self-attention. In e-commerce, these systems can be used to predict the continuous change in preferences based on a person’s history.
The conversational recommender system (CRS) allows users and the system to interact in real-time through natural language interactions, giving users [
26,
27,
28] unprecedented opportunities to explicitly find out what users prefer. In a conversational recommendation, users can communicate more efficiently with the system by using natural language conversations to find or recommend the most relevant information [
7,
27,
29,
30].
Whatever recommendation approach (CF, CBF, SRS, or CRS) is applied, each type of system is based on quite different data structures and each has its behavior, so the choice of the approach to adopt is mainly linked to the use case study and the specifics of the data to be processed.
3. Natural Language Processing & Representations
This section focuses on the representation of texts in natural language except for many other applications of NLP.
3.1. Usual Pre-Processing
After data acquisition, the first phase of processing consists of cleaning the text. Below, we list the different usual pre-processing methods:
Clean Tags: Remove special, unrecognized characters and HTML tags.
Tokenization: Segmentation of data into meaningful units: terms, sometimes called tokens. Words are character strings separated by spaces and punctuation marks. A term is defined as a word or a series of consecutive words. More generally, n-gram designates a term formed of n consecutive words.
Lemmatization: Normalization of terms in order to disregard variations in inflection (essentially related to conjugation, capital letters, and declension). We keep the masculine singular for an adjective and the infinitive for a conjugated verb. Lemmatization makes it possible to unify the different inflections of the same word (at the risk of unifying independent words, for example, the conjugated verb “played” and the noun “played”). Lemmatization also causes a loss of information; for example, words can have different meanings depending on whether they are singular or plural.
Stop words: filtering of terms containing no semantic information (e.g., “of”, “and”, “or”, “but”, “we”, “for”); the list of these tool words is determined manually for each language. The pruning of the most frequent terms (terms present in all the texts and therefore without impact on their characterization) is also carried out; the only frequency is a hyper-parameter of the approach.
Pre-processing natural language documents often use methods such as: (i) morpho-syntactic tagging (part-of-speech tagging) associating each term with its grammatical category (noun, verb, determiner) in the statement or (ii) identification of the syntactic relations or dependencies of the terms in the sentence (subject, object, complement). These two methods are not considered in the rest of the paper, because the sentences of job offers and resumes are often short, with poor grammar (see
Table 1).
3.2. Vector Representation—Bag of Words
The phase following the cleaning phase associates a vector representation with a sequence of terms. Two approaches are distinguished. The first considers bags of words (or bags of terms), where the order of the terms is not taken into account. The second approach keeps the sequential information in the sentences.
In the bag of words approach, a set of documents, called a corpus, is represented by a × matrix denoted D, where a row corresponds to a document and a column to a term. The cell of this matrix represents the number of occurrences of the term j in the document i (or a binary value of the presence of the term in the document).
3.3. Language Model
A language model is a probability distribution over a sequence of symbols. It is an alternative approach to bags of words, taking into account the order of terms. A language model is used to assess the plausibility of a sentence. It can also be used to generate a sequence of words or the next word in a sentence. The first language models are based on n-gram statistics [
31,
39,
40].
However, these models do not generate vector representations for words or documents. The first continuous language model proposed in 2003 is based on neural networks [
41]. This approach generates a vector representation for each word. Recent language models emphasize the representation of words [
35]. These word representations are then evaluated on the target task, or used for continuous document representation. Note that some approaches directly define a continuous representation of documents.
A classic evaluation of the quality of a language model is based on the corpus “One Billion Words” [
42]. In this case, the models must find the randomly removed words in the corpus. The n-gram statistical approach [
31] remains a good reference measure, but is overtaken by neural approaches [
41].
Word embedding is an encoding method that aims to represent the words or sentences of a text by vectors of real numbers, described in a vector model (or vector space model) [
43]. It is then possible to make an inventory of all the words used in the text to create a dictionary. The text will therefore be represented in the form of a vector which will indicate the frequency at which each of the words appears. This step is decisive for the performance of NLP.
Word2Vec is a family of model architectures and optimizations that can be used to determine word embeddings from large datasets. Two very popular architectures belonging to this family are the Continuous Bag-of-Words (CBOW) and the skip-gram [
44].
With the CBOW model, we start by choosing a word (the
word) and then we select a certain number of neighbors (on the left and on the right), and we try to train the model of so that it would be able to predict word number “
i” if given only its neighbors [
45]. Indeed, these neighboring words represent the context, it means that to predict any word, its neighbors are taken into consideration, so the projection keeps the information and the context of the word (see
Figure 2).
The skip-gram model is very similar, the model seeks to determine the associated context.
Skip-gram works well when the training data is not enough and it represents rare words or phrases very well. Conversely, CBOW is faster in training than skip-gram and is more accurate for frequent words [
44].
4. Methodology
We aim at analyzing the explicit property of the content using the NLP technique. All the words in the job description were scraped from sa.indeed.com and jib seekers resumes.
4.1. Model Overview
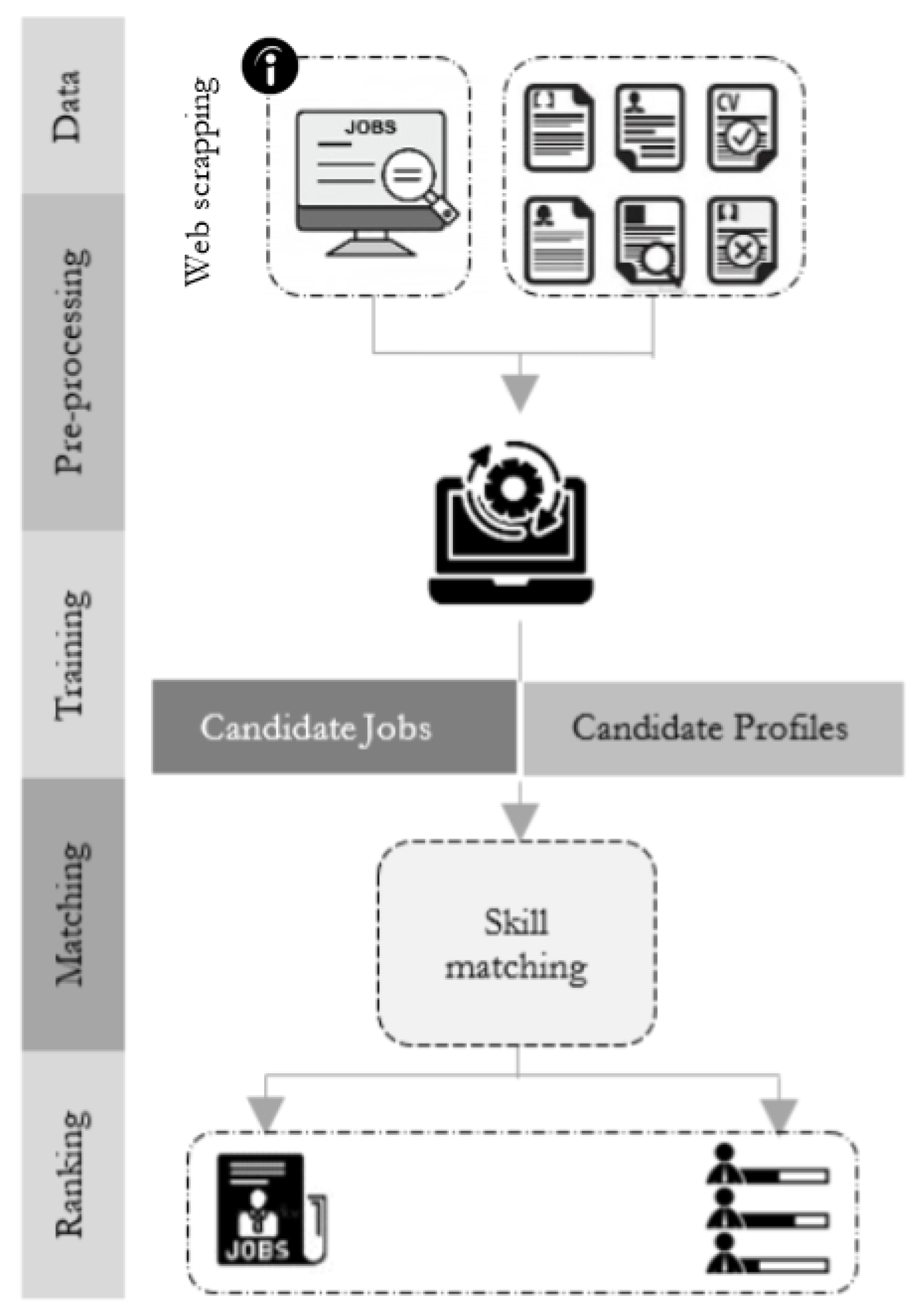
Figure 3 shows the overview of the proposed bi-directional recommender system. Four steps distinguish the proposed system:
4.2. Data Scrapping
Web scraper collects data from web sources and stores it locally in many formats so they can be used for further analysis [
46].
Due to the fact that every website has its own structure, it is nearly impossible to generalize the method of web scraping for every website. To accomplish this, we use Python programming to automate or create web crawlers. Data is parsed using BeautifulSoup.
We scraped
PHP Developer,
Data Scientist,
Data Engineer,
Java Developer, and
Back-end Developer job profiles from
https://sa.indeed.com (accessed on 1 September 2022). We gathered jobs posted in the last 30 days (1 September 2022–1 October 2022), in 3 major Saudi Arabia regions (Jeddah, Riyadh, and Dammam). We used Selenium Webdriver to automate web scraping and save results in a local JSON file.
4.3. Pre-Processing
A major concern of any research project is to collect data that is beneficial to the research project at hand. Internet data can be found in different forms a variety of formats such as tables, comments, articles, job postings, together with different HTML tags that are embedded within them. In order to collect data, we use methods such as web scraping. Using web scraping, descriptive data is collected, as well as user data (from resumes).
Due to the fact that both data do not seem to have any history of previous interactions between them, the study continued to analyze the content explicitly in an attempt to find any obvious associations.
To categorize all the job listings into different categories, as well as compare user data and job listing data to identify similarities, the current study required a method to analyze text data.
The collected dataset has an attributes-filled string column with symbols and stop words. Especially in the column where skill details are present in both datasets (resumes and jobs). Data cleaning is our first process (see
Figure 4).
4.4. Training the Model to Auto-Detect Named Entities
The named-entity recognition (NER) process entails identifying the entities discussed in a text and categorizing them according to predefined categories in accordance with their significance to the text [
47]. In our approach, categories could be entities like
Name,
Location,
Skills, and
Education.
spaCy is used in extracting these named entities from the job description and resumes [
47,
48].
Figure 5 shows the NLP-based training diagram.
Training is an iterative process in which the model’s predictions are compared against the reference annotations to estimate the gradient of the loss [
47]. The gradient of the loss is then used to calculate the gradient of the weights through back-propagation. The gradients indicate how the weight values should be changed so that the model’s predictions become more similar to the reference labels over time.
4.5. Validating the Model
Predictive accuracy is measured based on the difference between the observed values and predicted values. Decision support metrics quantify recommendation success and error rates, considering that a recommender system generates a list of object recommendations for each user. The following metrics are used [
49]:
The
Precision allows to know the number of positive predictions well made. In other words, it is the number of well-predicted positives (True Positives (
TP)) divided by all the predicted positives (True Positives (
TP) + False Positives (
FP)). It is given by Equation (
1).
The
Recall metric makes it possible to know the percentage of positives well predicted by our model. In other words, it is the number of well-predicted positives (True Positives (
TP)) divided by all the positives (True Positives (
TP) + False Negatives (
FN)). It is given by Equation (
2).
The
is a metric used to evaluate the performance of classification models with 2 or more classes. It summarizes the values of
Precision and
Recall in a single metric. Mathematically, this measure is defined as the harmonic mean of
Precision and
Recall. It is given by Equation (
3).
4.6. Bi-Directional Matching between Resumes and Jobs
Figure 6 shows an overview of matching jobs and candidate profiles using the trained model.
Word2vec is used to retrieve terms that are based on a similarity between two terms. Then, using cosine similarity to measure the similarity within these two terms can be used to retrieve terms that are found using a similarity between these two terms [
44,
50]. It produces a vector space with dimensions in hundreds based on a large set of words, called the corpus. To measure the distance between words, we can generate a vector space model, and then we use the similarity measuring method.
5. Results
5.1. Datasets Description
We collected data from two different sources for this study. We have two sets of data, one relating to user profiles and another relating to job profiles. We train the model with 138 resume data and test it on 25 resume data and 250 job descriptions.
As job listing data was scraped from published jobs in sa.indeed.com, the extracted data was then saved to JSON files. There are five files, each containing nearly 50 job descriptions for one IT job (from our selected jobs) published during a month. Job descriptions contain six key pieces of information: the job URL link, the company name, the location, the salary, and the full job description text.
Figure 8 shows the job dataset’s structure.
The information from job specifications will be extracted and analyzed using NLP based on NER techniques to find skills.
5.2. Testing the Model and Validating the Prediction
A predictive model’s performance can be easily evaluated by calculating the percentage of its predictions that are accurate [
51]. A model’s accuracy is a metric used to measure how many predictions it correctly predicted. Essentially, this value is calculated based on the ground truth classes and the predictions of the model. It is calculated by dividing the number of correct predictions by the total prediction number (Equation (
4)).
Since our predictive model deals with multi-class classification, the accuracy algorithm steps are as follows:
Get predictions from the model.
Calculate the number of correct predictions.
Divide it by the total prediction number.
Analyze the obtained value.
The higher the metric value, the better the prediction. The best possible value is 1 (if a model made all the predictions correctly), and the worst is 0 (if a model did not make a single correct prediction).
Table 2 presents the decision support metrics for
Name,
Location,
Skills, and
Education entities.
The obtained results show good values of accuracy for the Name (99.88%), Location (99.77%), Skills (99.08%), and Education (100%) entities. These values show how many times our ML model was correct overall.
Precision values are also very satisfying. This also proves how good our model is at predicting Name (∼1), Location (∼1), Skills (∼1), and Education (0.99) entities.
Recall values (∼1) obtained for Name, Location, Skills, and Education proves that the proposed model was able to detect these entities.
As mentioned previously,
PHP Developer,
Data Scientist,
Data Engineer,
Java Developer, and
Back-end Developer job profile descriptions are scrapped from
sa.indeed.com then trained to create a list of skills associated to each job. As presented in
Table 3, the skills of the
Data Scientist and
Data Engineer job profiles are very similar and overlap, we will show that the proposed bi-directional recommendation system can distinguishes between job roles with close similarity even if their skills overlap.
5.3. Finding Most Matching Jobs
The most matching jobs for 25 resumes are listed in
Table 4.
According to
Table 4, the similarity of the resumes varies according to the job profiles. The value 0 obtained for the resumes 21, 22, 23, 24, and 25 for
Data Scientist means that the job seekers having these resumes cannot succeed as
Data Scientist and can strongly succeed as
PHP Developer, moderately successful as
Data Engineer and
Back-end Developer profiles, and they will very low successful as
Java Developer.
Job seekers with resumes, 2, and 3 cannot be successful as Java Developer (0%) and PHP Developer (0%). They can be successful as Data Scientist (40%) and Back-end Developer (31.43%). They will not be very successful as Data Engineer (15.35%).
From this table, we can conclude that the Data Engineer profile in Saudi Arabia is open to almost all job seekers who have Data Scientist, Back-end Developer, Data Engineer, PHP Developer, and Java Developer profiles with different similarities.
5.4. Finding Most Matching Resumes
The most matching resumes for
Data Engineer,
Java Developer, and
Back End Developer profiles are listed in
Table 5.
According to
Table 5, Saudi recruiters who search for
PHP Developer can strongly consider resumes 23 (100%), 22 (88.54%), and 21 (75.89%). If they seek Java developer profiles, they can consider resume 19.
Recruiters who seek Data Scientist profiles can consider resumes 6 (100%), 13 (95.03%), 12 (85.03%), 11 (82.85%), 20 (80.78%), and 3 (80.78%).
Recruiters who seek Data Engineer profiles can strongly consider resumes 23 (80%), 22 (77.78%), and 19 (76.19%).
If recruiters are looking for a profile that can be a PHP Developer, Java developer, Back-end Developer, and Data Engineer, they can consider 19 resumes (17.86%, 57.14%, 57.14%, and 76.19 resp.), 23 (100%, 14.4%, 40%, and 80% resp.), and 18 (12.5%, 40%, 40%, and 53.33% resp.).
Given the overlap of the Data Scientist and Data Engineer profiles, recruiters will have the choice between a pure Data Scientist or a Data Engineer who can exercise the profession of a Data Scientist profile. For example, resumes 2, 3, 5, and 13 can help the company find these two types of profiles.
5.5. Recommender System Evaluation
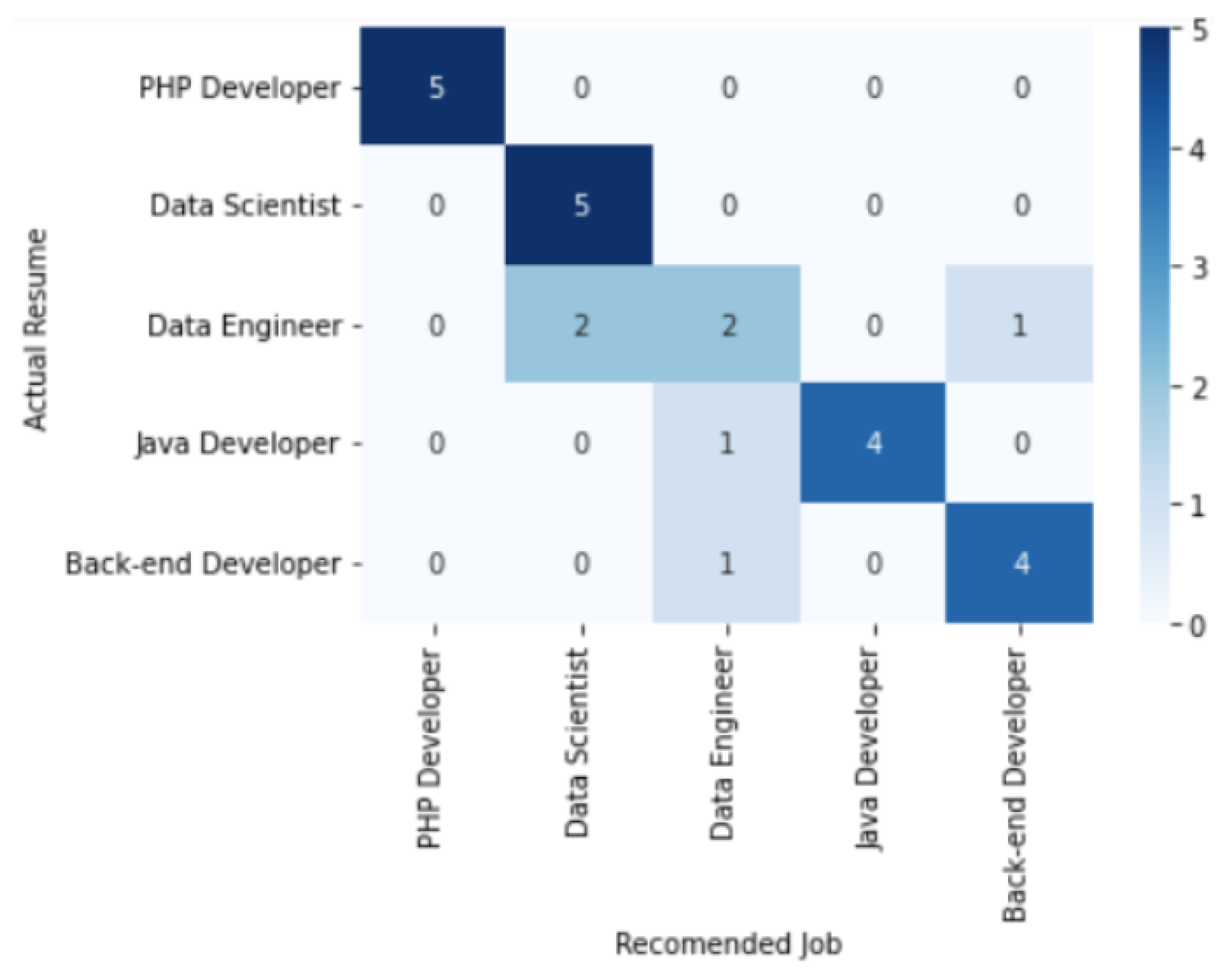
To validate the prediction, we have used the confusion matrix to highlight not only the correct and incorrect predictions but, also, to give us an indication of the type of errors made. We find good recommendations on the diagonal of the confusion matrix (see
Figure 9).
The results show that:
Five resumes have been classified as belonging to the PHP Developer job profile out of a total of five resumes, which is very satisfactory.
For the Data Scientist job profile, five out of five were identified as belonging to this job profile, which is very satisfactory.
For the Data Engineer job profile, two out of five resumes have been identified. This is due to the natural overlap between the skills of these two profiles.
Four out of five resumes have been classified as belonging to the Java Developer, which is quite satisfactory.
Four resumes have been classified as belonging to the Back-end Developer job profile out of a total of five, which is also quite satisfactory.
The number of TP is therefore 20 out of a total of 25 resumes, which is very satisfactory.
We also calculated metrics necessary for the analysis of this matrix such as precision, recall, F1-score, and accuracy.
According to
Table 6, we can observe a precision of one for the PHP and Java Developer profiles. This proves that the proposed system succeeded in the recommendation since the skills required for these two profiles do not overlap. The precision value obtained for the
Data Engineer profile is a bit low (0.5). This is due to the strong overlap of skills with the
Data Scientist profile and a weak overlap with the
Back-end Developer profile. The
Data Scientist profile has an acceptable precision of 0.71 given the prediction obtained from the resumes belonging to the
Data Engineer profile, but which were predicted in this profile.
Because all PHP Developer and Data Scientist resumes were predicted as belonging to these same two profiles, the obtained recall values are equal to 1. Contrary, for Data Engineer, Java Developer, and Back-end Developer, two, four, and four resumes, respectively, were correctly assigned out of five, five, and five resumes and which gave us a recall of 0.4, 0.8, and 0.8, respectively.
The overall accuracy of 0.8 is obtained by our recommendation system. This value shows how the proposed recommender system was correct overall.
6. Discussion
The proposed NLP-based recommender system is based on the idea that better access to information would improve the situation in terms of finding jobs for job seekers and potential candidates for recruiters, would reduce the cost in terms of time and opportunity, and would make it possible to remedy a certain extent the phenomenon of frictional unemployment.
Because ML is at the core of many recent advances in science and technology, the proposed recommender system is evaluated using a resume/job offer dataset. The performance of generated recommendations is evaluated using ML such as accuracy, precision, recall, and F1-score.
The obtained results in matching resumes to Saudi jobs and Saudi job offers to profiles are very encouraging for job seekers as well as for Saudi recruiters. The proposed system is part of a framework for improving the computerized recruitment process. It can help job seekers to find how their skills stack up against the most sought jobs and also recommend job postings that match the skills reflected in their resumes. It also offers recruiters an engine that facilitates the identification and hiring of candidates.
This work will benefit from several improvements. In particular, we will have to study the dates of the relevant experience for the offer in order not to offer profiles with too old an experience. The detection of skills in an offer will benefit from the work presented in [
52], who have developed a system that automatically builds a skills ontology for a certain number of jobs, distributed by universe. Geo-location could also extend to neighboring towns of those sought.
7. Conclusions and Future Works
Recruitment is one of the most important tasks in job seekers’ and also organizations’ point of view. If there could be a model that could recommend the possibility of a job seeker being recruited or placed in an organization or not, it can save a lot of time for HR managers, staffs and placement committees.
The proposed bi-directional JRS would ease the burden of a recruiter by reducing the number of irrelevant applicants and a job seeker by offering recommended jobs. It focused on a resumes/job offers (resp. job offers/potential candidates) matching task while helping recruiters and job seekers to support their work through recommendations and help job seekers to find suitable job offers. Potential candidates are identified for recruiters and job offers are recommended for job seekers. Model prediction is evaluated decision support metrics such as accuracy, precision, recall, and F1-score.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}