
Synthesizing a Talking Child Avatar to Train Interviewers Working with Maltreated Children

 , , , , ,
, , , , ,  , , , , ,
, , , , ,  and
and 
Abstract
:1. Introduction
- An investigation of the potential learning effects and user experience with the system.
- An investigation of the realism of the synthetic voices compared to natural voices.
- An examination of emotion extraction with different models based on children’s answers in investigative interviews.
- An investigation of the realism of several methods for generating the appearance of the talking avatar.
- An investigation of the system architecture regarding the integration and interaction of various system components.
2. Related Work
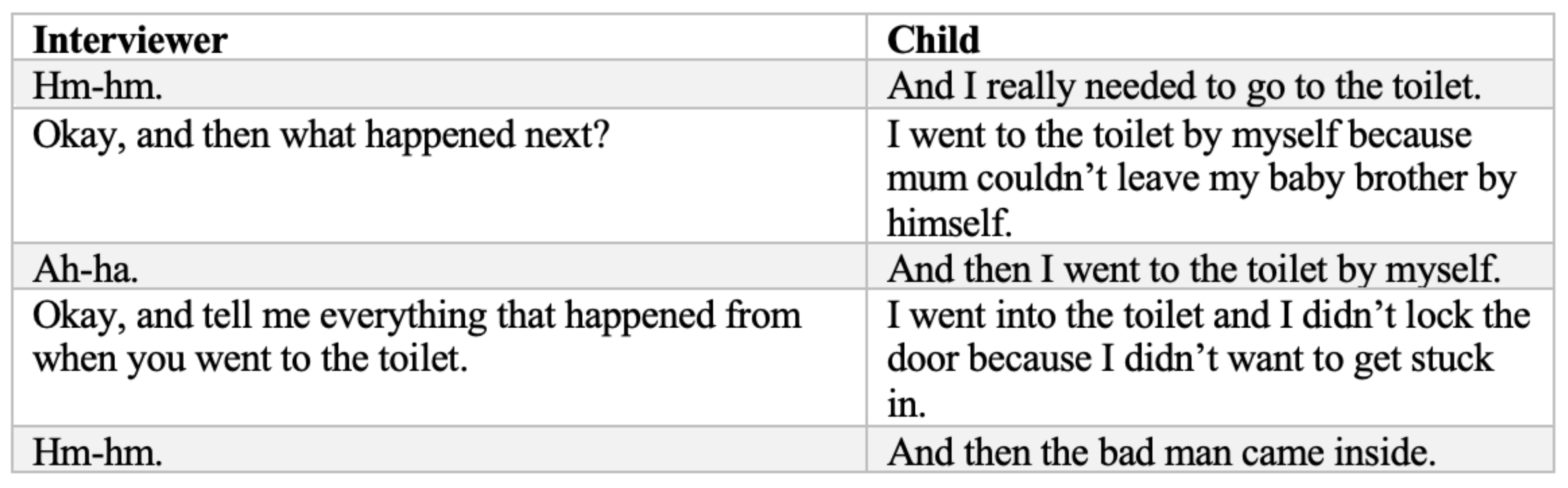
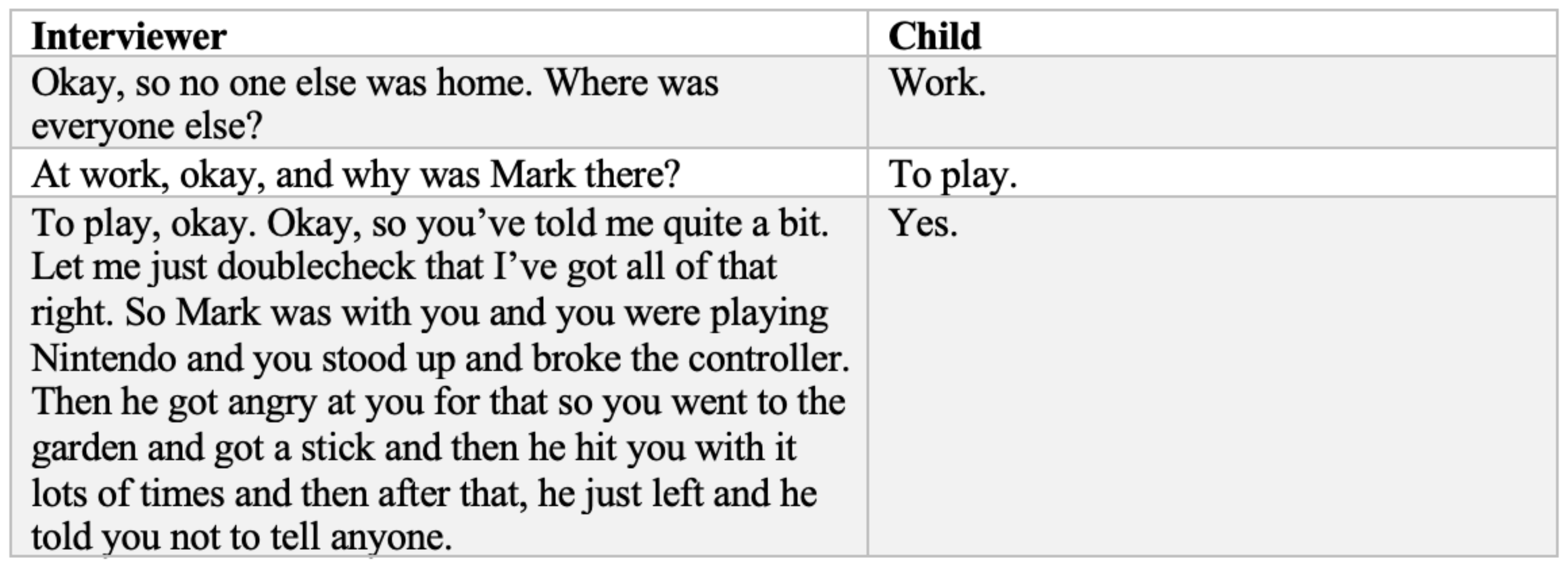
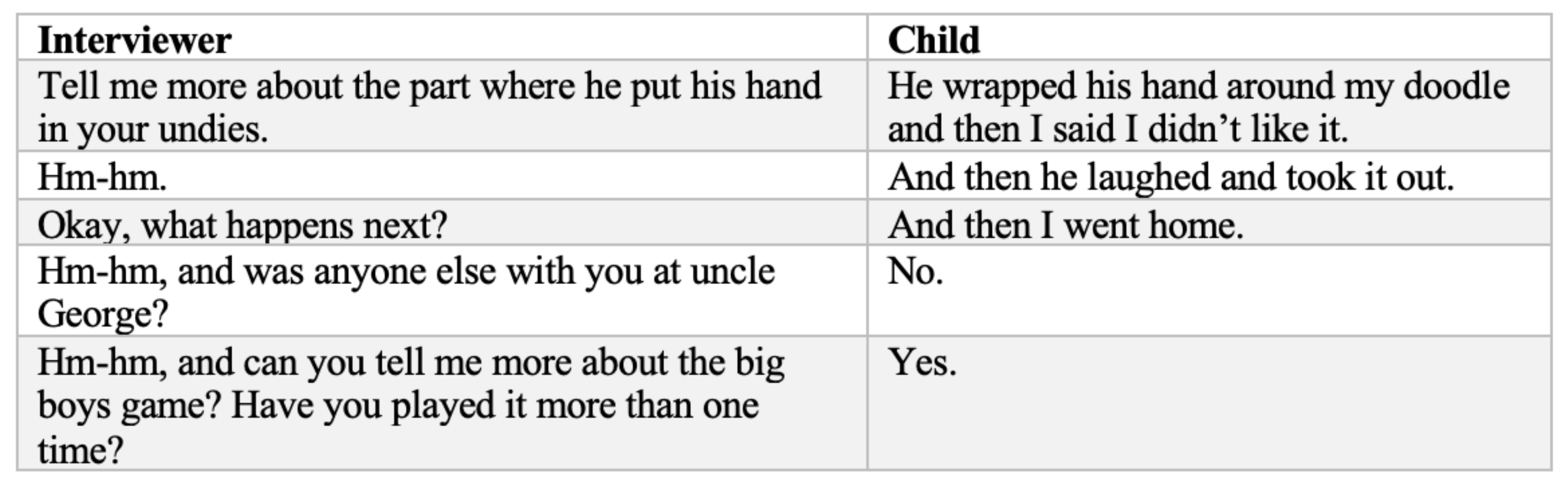
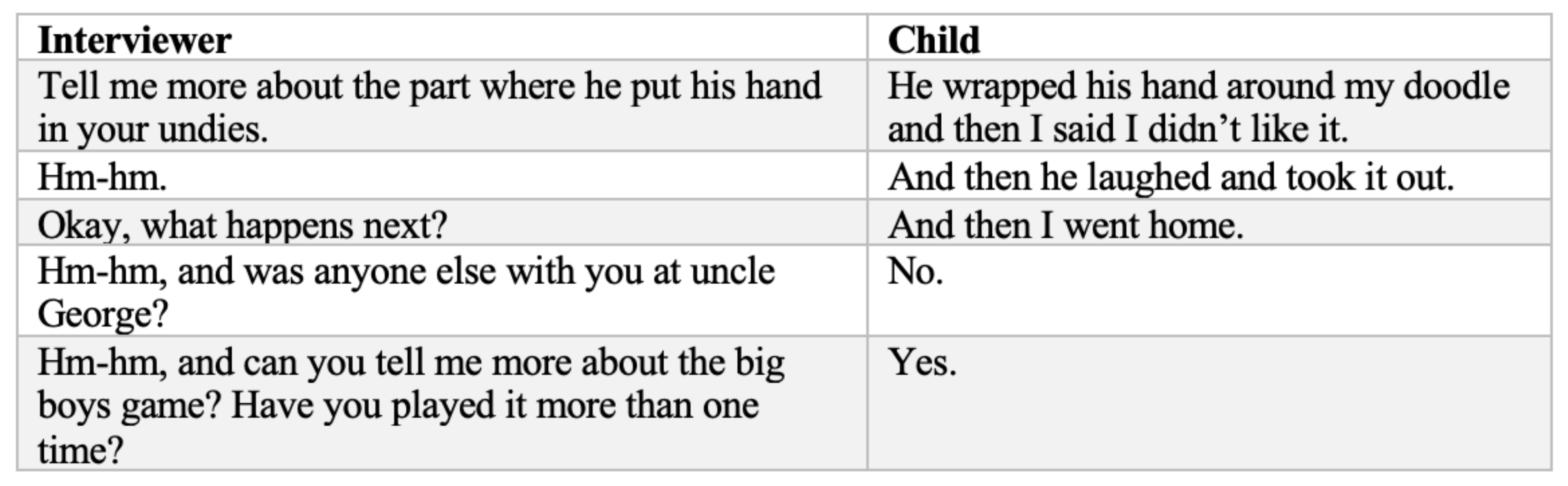
2.1. Investigative Interview Training
2.2. Emotions
2.3. Chatbot
2.4. Auditory
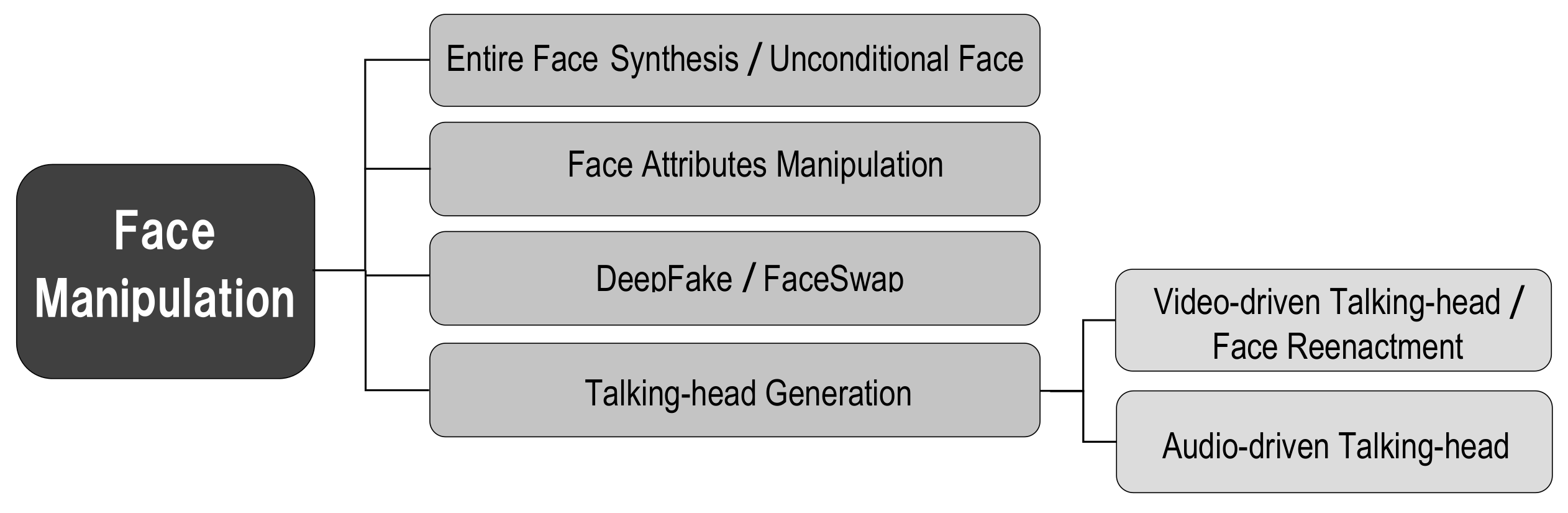
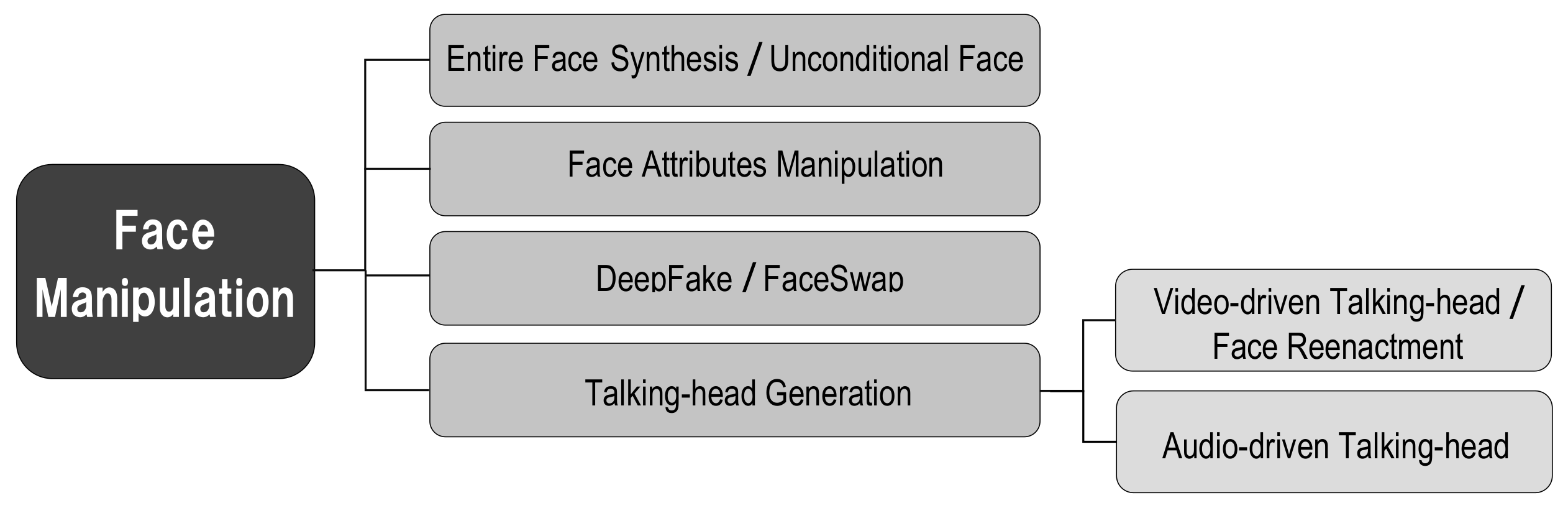
2.5. Visual
2.6. Child Interview Training Avatars
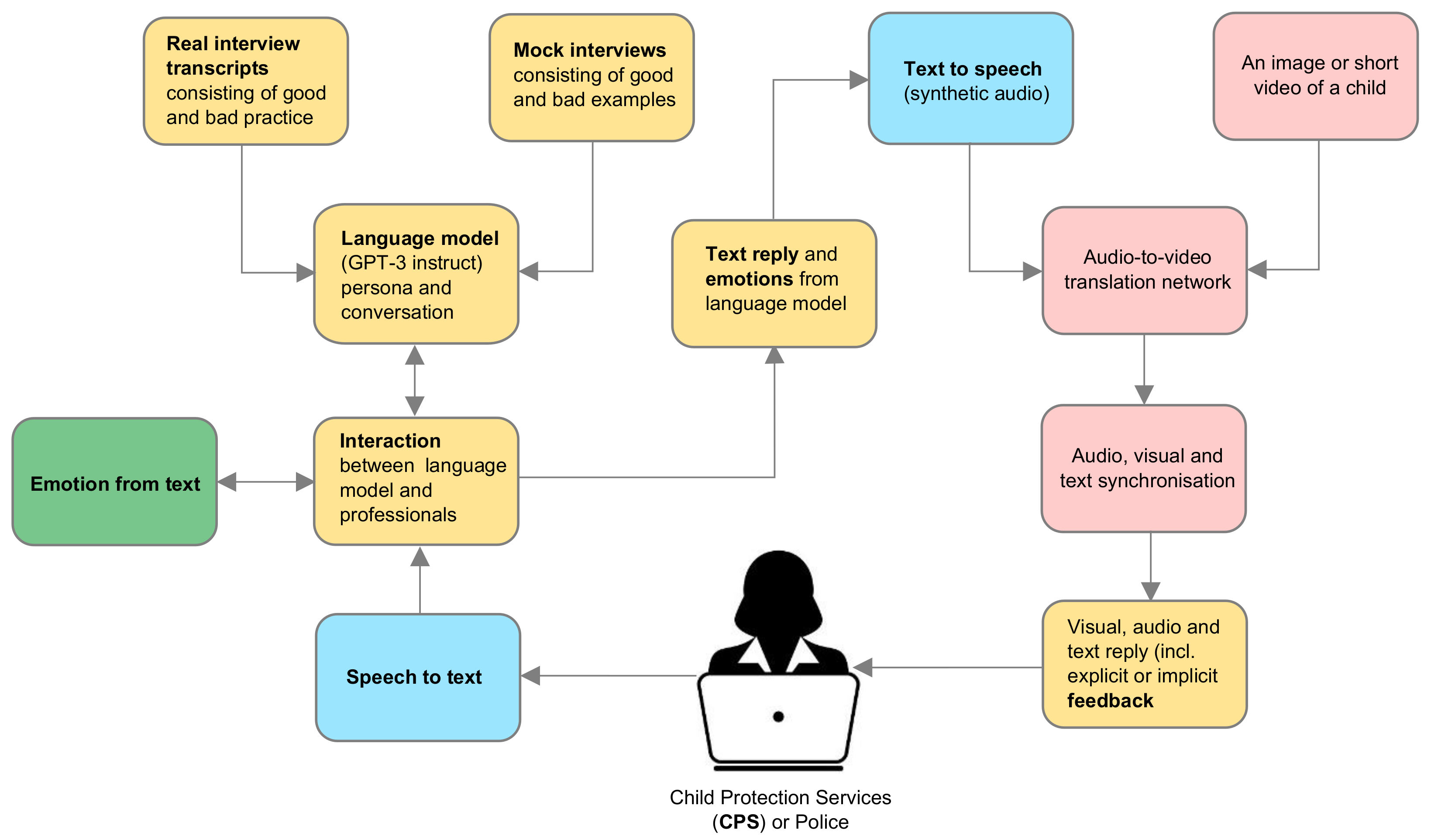
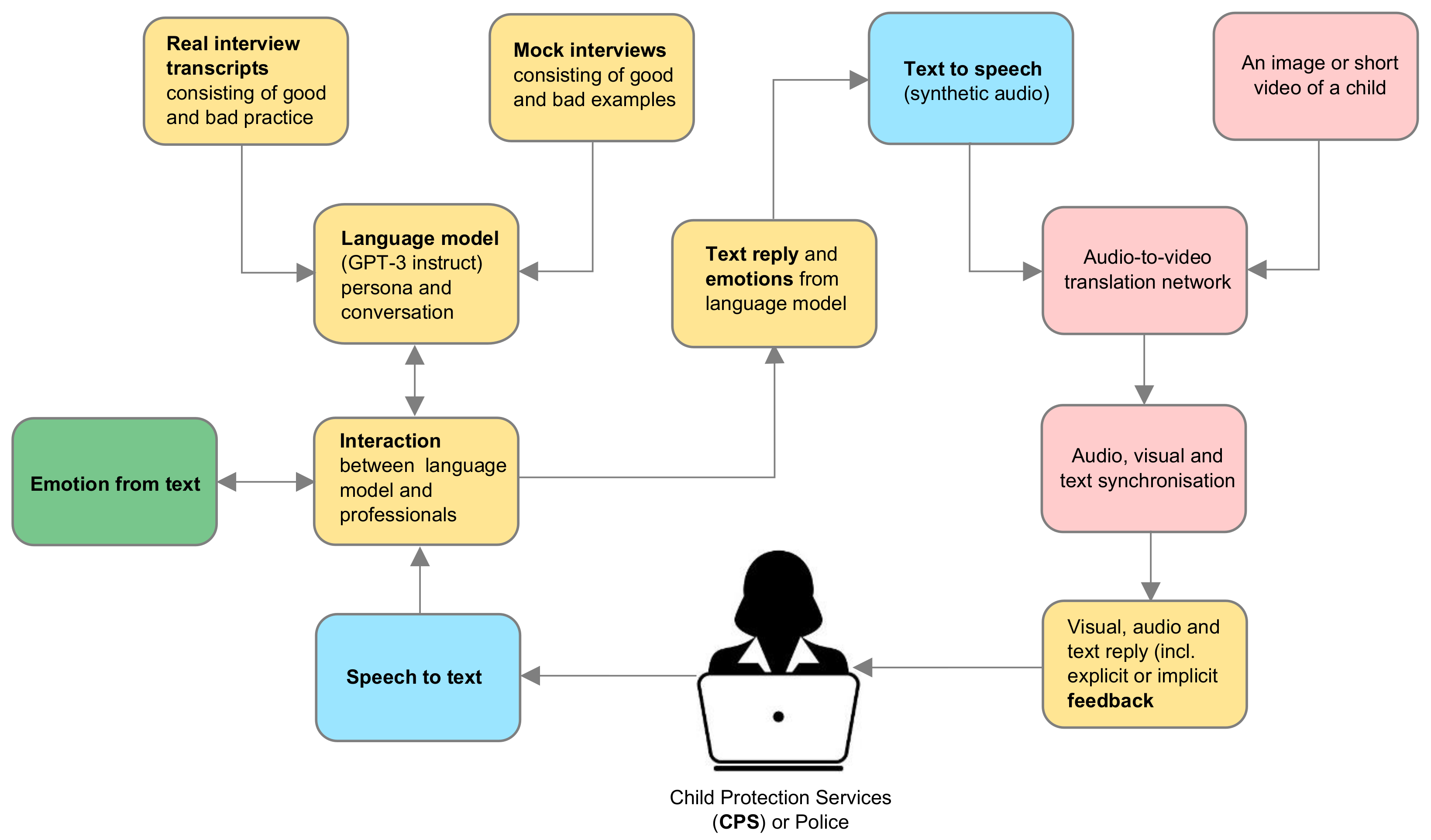
3. Materials and Methods
3.1. Language
3.2. Auditory
3.3. Emotions
3.4. Visual
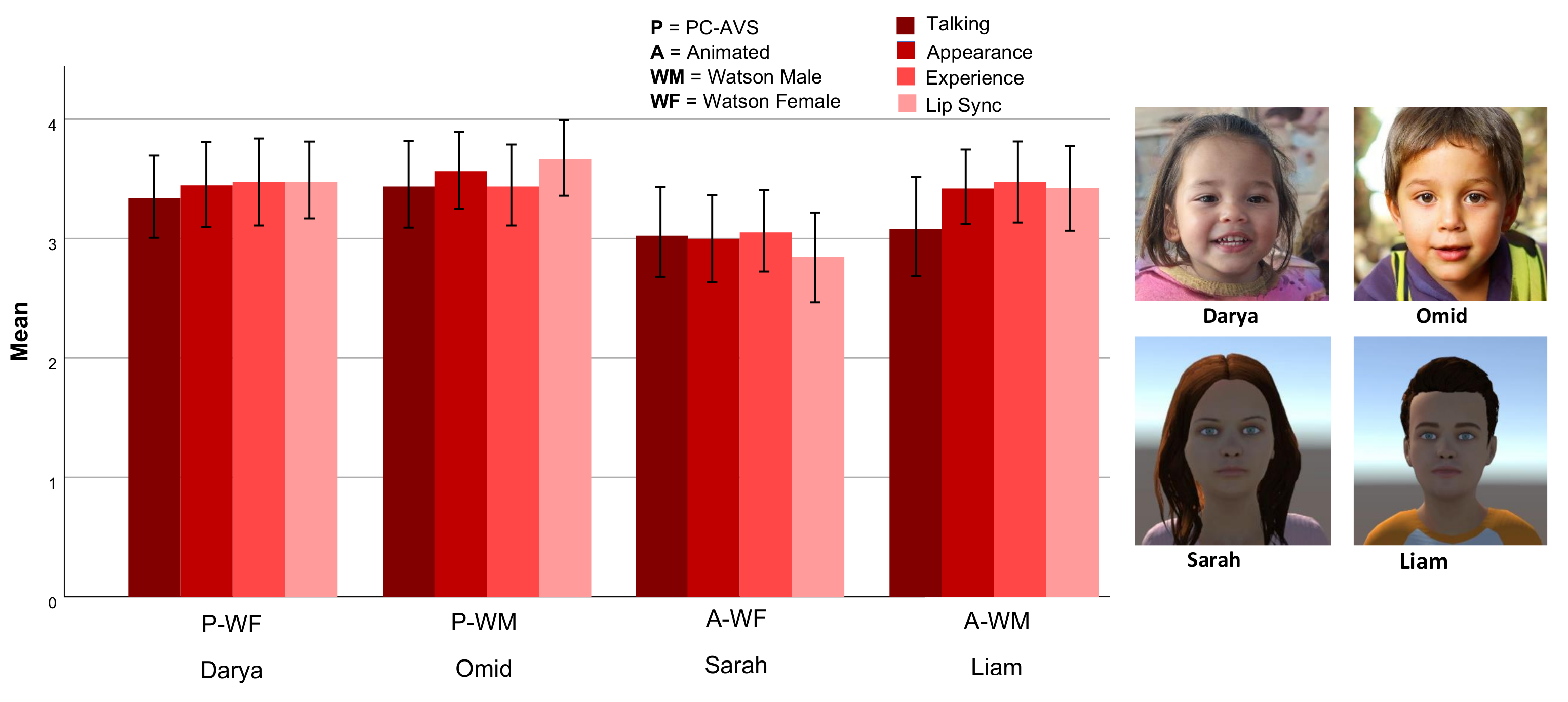
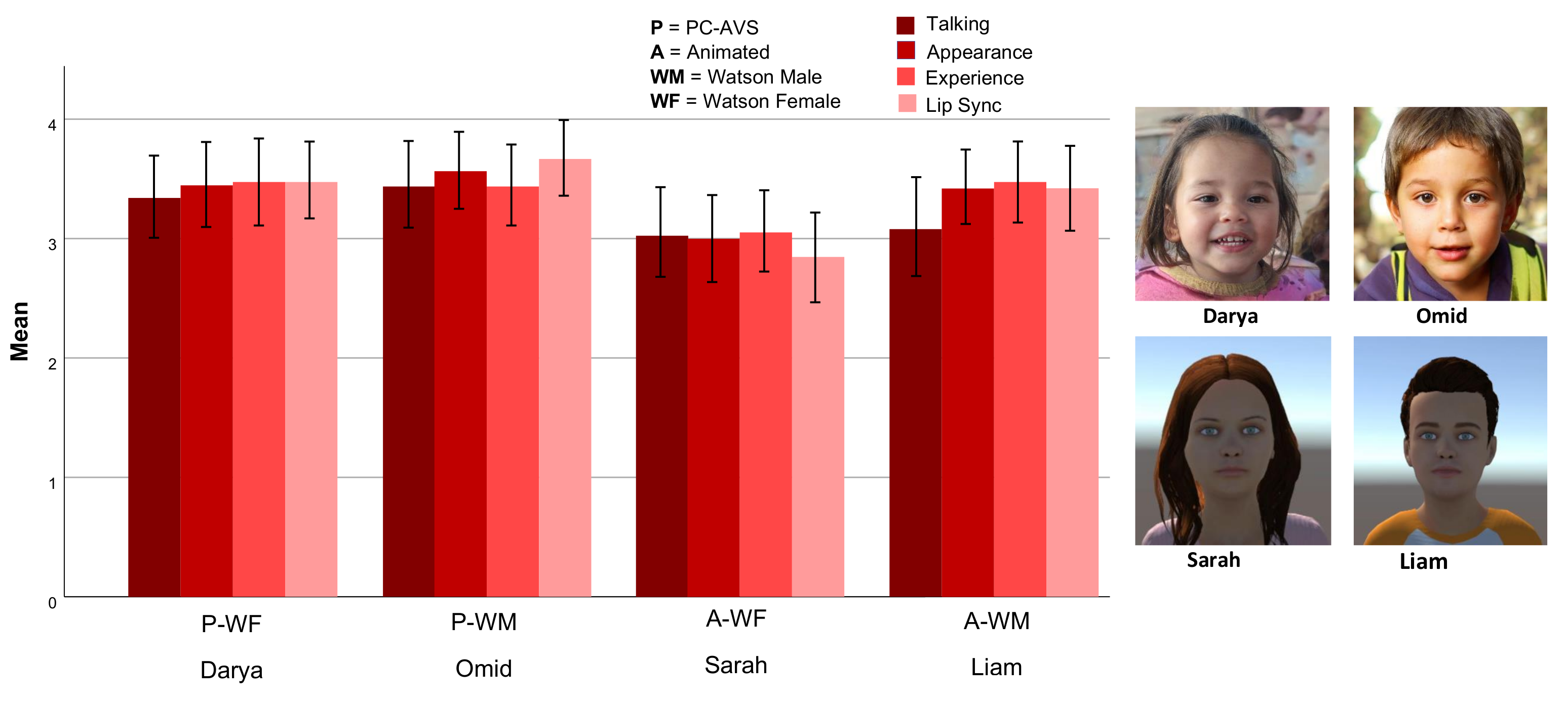
4. Results
4.1. Language
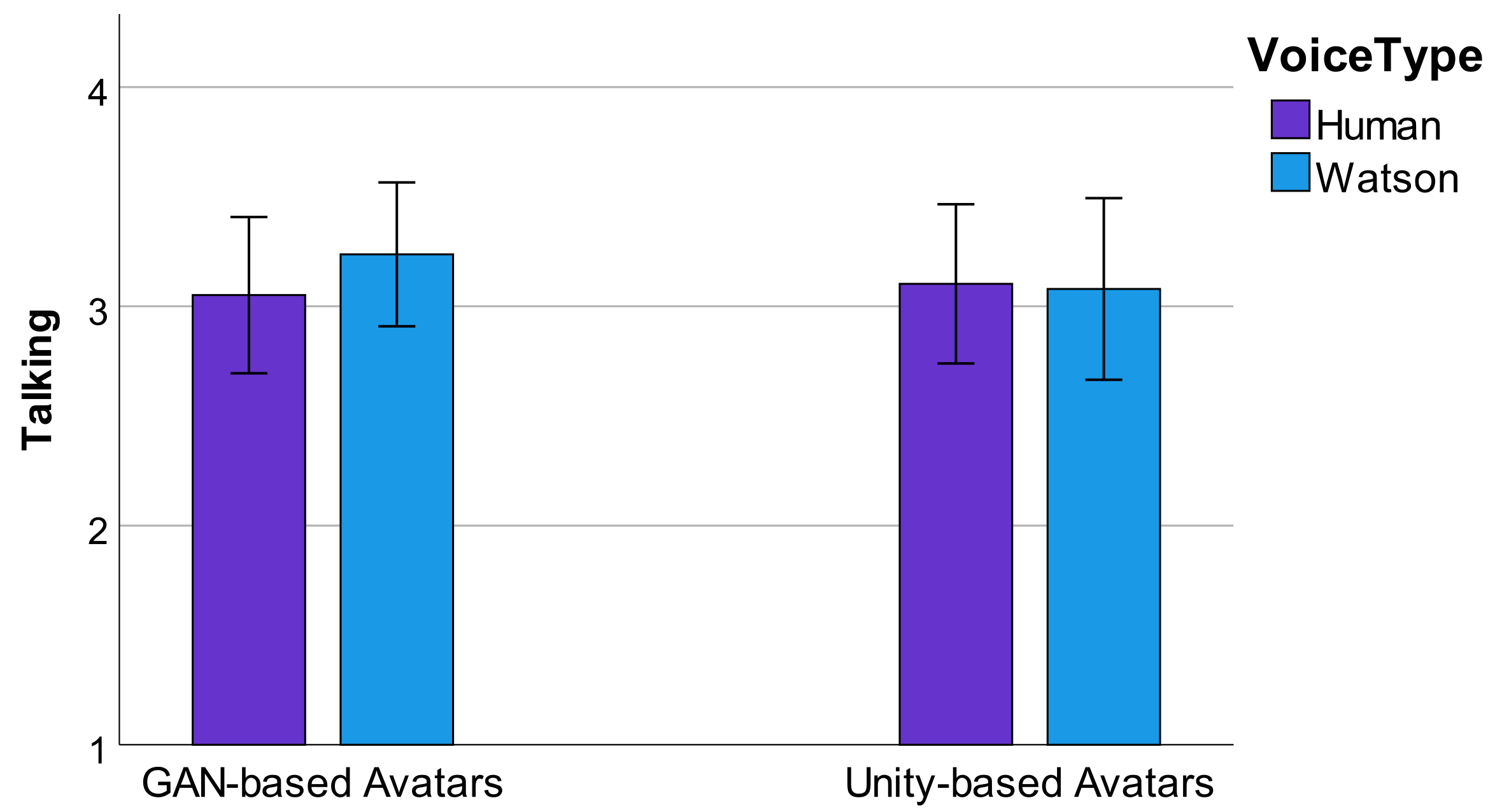
4.2. Auditory
4.3. Emotions
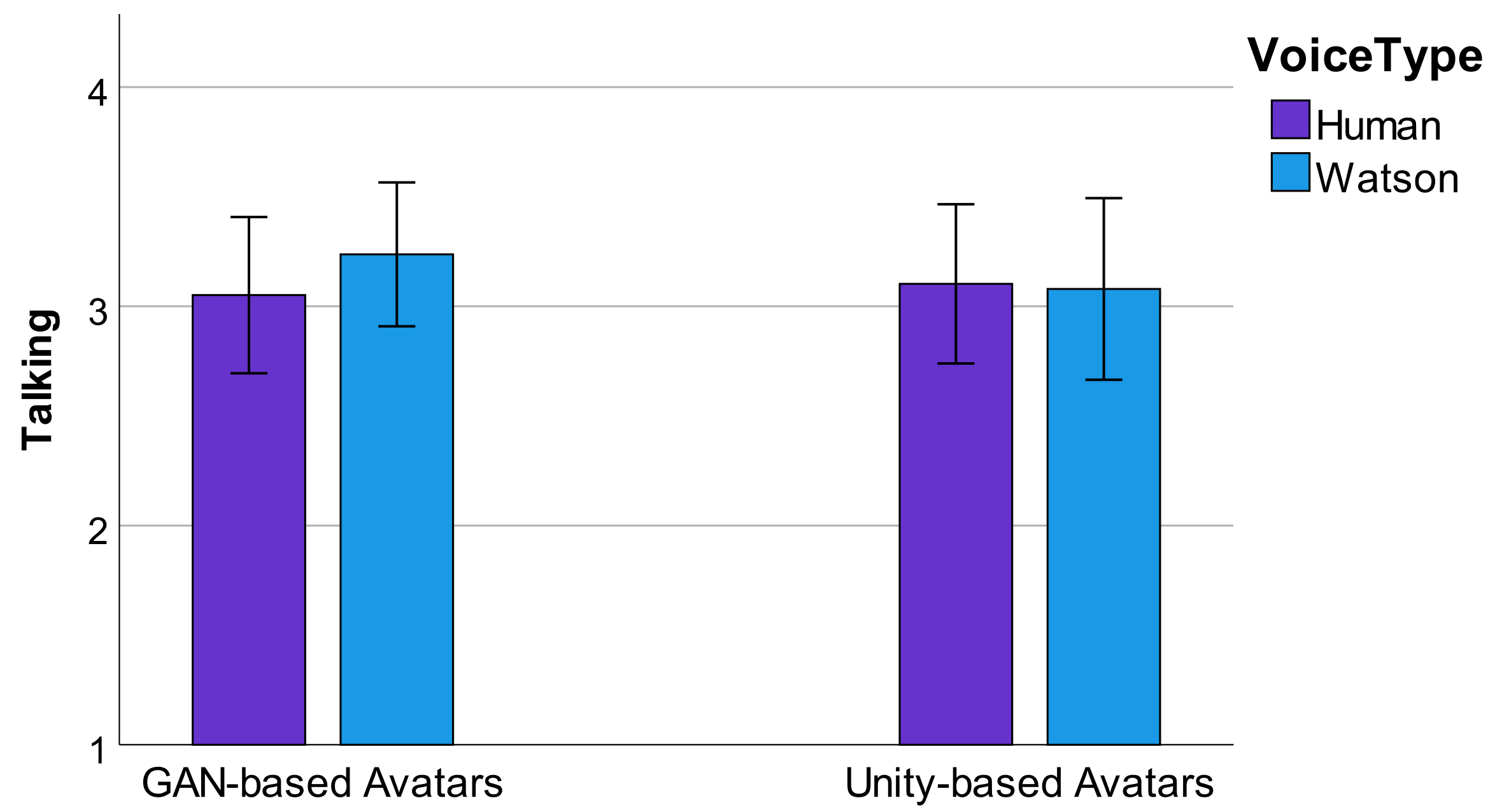
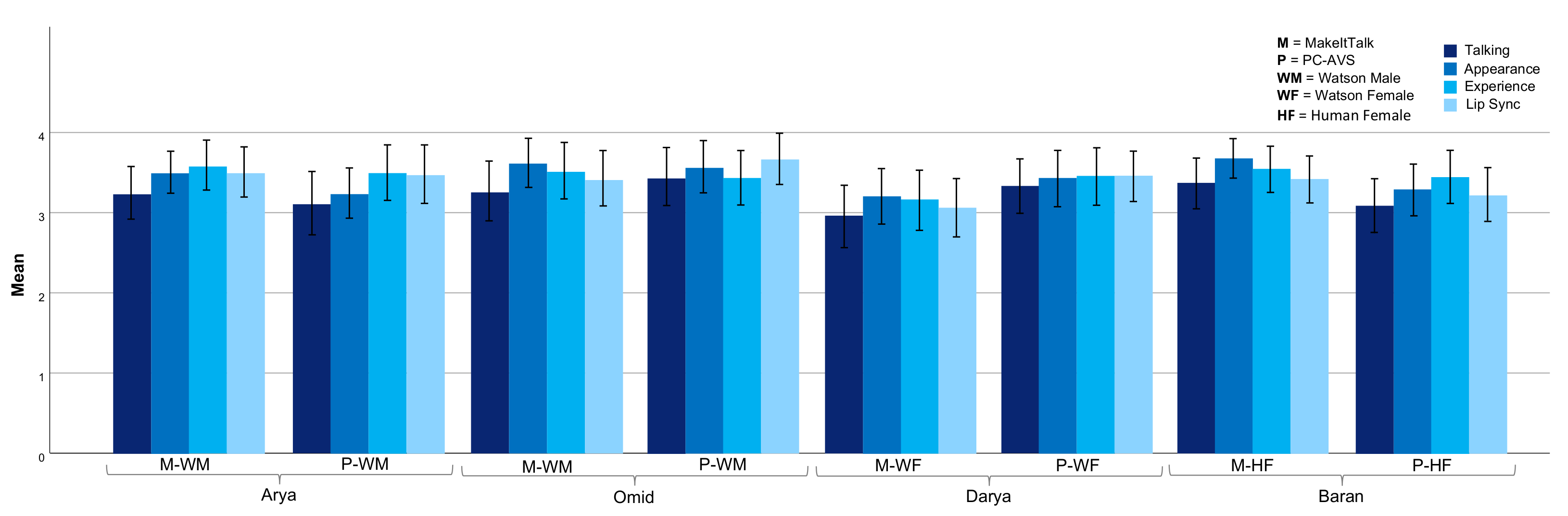
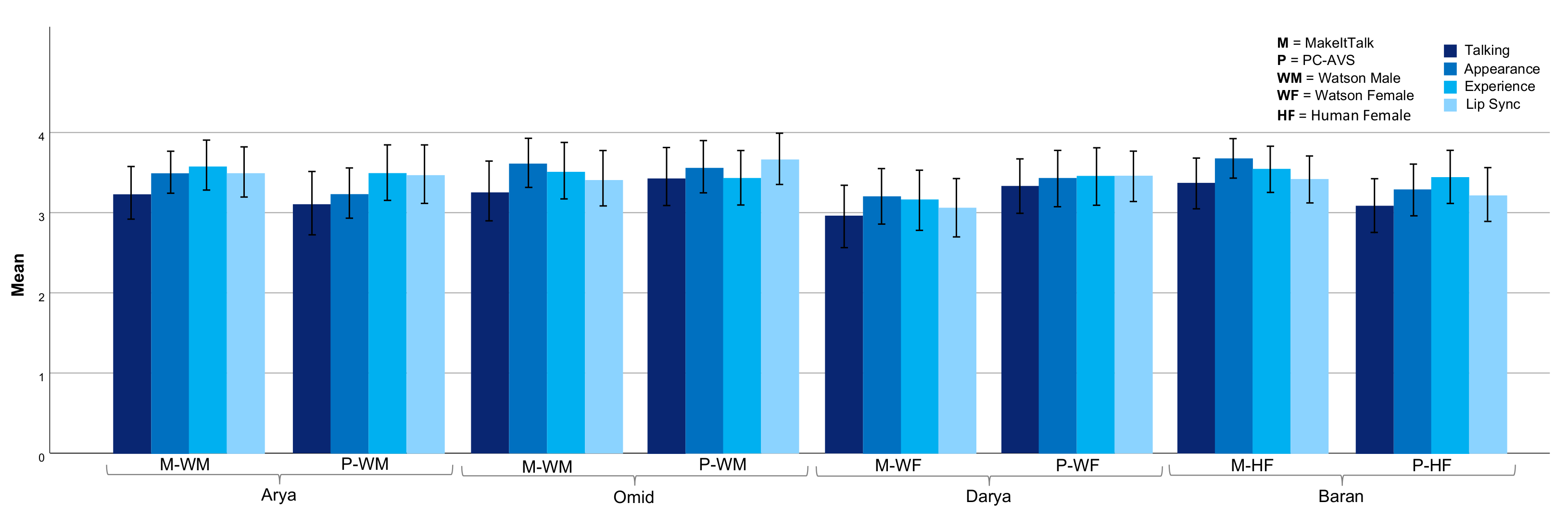
4.4. Visual
5. Discussions and Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sethi, D.; Bellis, M.; Hughes, K.; Gilbert, R.; Mitis, F.; Galea, G. European Report on Preventing Child Maltreatment; World Health Organization, Regional Office for Europe: Geneva, Switzerland, 2013. [Google Scholar]
- Widom, C.S. Longterm consequences of child maltreatment. In Handbook of Child Maltreatment; Springer: Berlin/Heidelberg, Germany, 2014; pp. 225–247. [Google Scholar]
- World Health Organization. Global Health Risks: Mortality and Burden of Disease Attributable to Selected Major Risks; World Health Organization: Geneva, Switzerland, 2009. [Google Scholar]
- Dixon, L.; Perkins, D.F.; Hamilton-Giachritsis, C.; Craig, L.A. The Wiley Handbook of What Works in Child Maltreatment: An Evidence-Based Approach to Assessment and Intervention in Child Protection; John Wiley & Sons: Hoboken, NJ, USA, 2017. [Google Scholar]
- Brown, D.; Lamb, M. Forks in the road, routes chosen, and journeys that beckon: A selective review of scholarship on childrenss testimony. Appl. Cogn. Psychol. 2019, 33, 480–488. [Google Scholar] [CrossRef]
- Lamb, M.E.; La Rooy, D.J.; Malloy, L.C.; Katz, C. Children’s Testimony: A Handbook of Psychological Research and Forensic Practice; John Wiley & Sons: Hoboken, NJ, USA, 2011; Volume 53. [Google Scholar]
- Adams, J.A.; Farst, K.; Kellogg, N.D. Interpretation of Medical Findings in Suspected Child Sexual Abuse: An Update for 2018. J. Pediatr. Adolesc. Gynecol. 2018, 31, 225–231. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Newlin, C.; Steele, L.C.; Chamberlin, A.; Anderson, J.; Kenniston, J.; Russell, A.; Stewart, H.; Vaughan-Eden, V. Child Forensic Interviewing: Best Practices; US Department of Justice, Office of Justice Programs, Office of Juvenile: Washington, DC, USA, 2015.
- Lamb, M.E.; Brown, D.A.; Hershkowitz, I.; Orbach, Y.; Esplin, P.W. Tell Me What Happened: Questioning Children about Abuse; John Wiley & Sons: Hoboken, NJ, USA, 2018. [Google Scholar]
- Lamb, M.E.; Orbach, Y.; Hershkowitz, I.; Esplin, P.W.; Horowitz, D. A structured forensic interview protocol improves the quality and informativeness of investigative interviews with children: A review of research using the NICHD Investigative Interview Protocol. Child Abus. Negl. 2007, 31, 1201–1231. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Powell, M.B.; Brubacher, S.P. The origin, experimental basis, and application of the standard interview method: An information-gathering framework. Aust. Psychol. 2020, 55, 645–659. [Google Scholar] [CrossRef]
- Lyon, T.D. Interviewing children. Annu. Rev. Law Soc. Sci. 2014, 10, 73–89. [Google Scholar] [CrossRef]
- Powell, M.B.; Hughes-Scholes, C.H.; Smith, R.; Sharman, S.J. The relationship between investigative interviewing experience and open-ended question usage. Police Pract. Res. 2014, 15, 283–292. [Google Scholar] [CrossRef] [Green Version]
- Lamb, M. Difficulties translating research on forensic interview practices to practitioners: Finding water, leading horses, but can we get them to drink? Am. Psychol. 2016, 71, 710–718. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Powell, M.B.; Guadagno, B.; Benson, M. Improving child investigative interviewer performance through computer-based learning activities. Polic. Soc. 2016, 26, 365–374. [Google Scholar] [CrossRef]
- Seymour, M.; Riemer, K.; Kay, J. Actors, avatars and agents: Potentials and implications of natural face technology for the creation of realistic visual presence. J. Assoc. Inf. Syst. 2018, 19, 4. [Google Scholar] [CrossRef]
- Hassan, S.Z.; Salehi, P.; Røed, R.K.; Halvorsen, P.; Baugerud, G.A.; Johnson, M.S.; Lison, P.; Riegler, M.; Lamb, M.E.; Griwodz, C.; et al. Towards an AI-Driven Talking Avatar in Virtual Reality for Investigative Interviews of Children. In Proceedings of the 2nd Edition of the Game Systems Workshop (GameSys ’22), Athlone, Ireland, 14–17 June 2022. [Google Scholar]
- Salehi, P.; Hassan, S.Z.; Sabet, S.S.; Baugerud, G.A.; Johnson, M.S.; Riegler, M.; Halvorsen, P. Is More Realistic Better? A Comparison of Game Engine and GAN-based Avatars for Investigative Interviews of Children. In Proceedings of the ICDAR Workshop, ACM ICMR 2022, Newark, NJ, USA, 27–30 June 2022. [Google Scholar]
- Cederborg, A.C.; Orbach, Y.; Sternberg, K.J.; Lamb, M.E. Investigative interviews of child witnesses in Sweden. Child Abus. Negl. 2000, 24, 1355–1361. [Google Scholar] [CrossRef]
- Baugerud, G.A.; Johnson, M.S.; Hansen, H.B.; Magnussen, S.; Lamb, M.E. Forensic interviews with preschool children: An analysis of extended interviews in Norway (2015–2017). Appl. Cogn. Psychol. 2020, 34, 654–663. [Google Scholar] [CrossRef]
- Korkman, J.; Santtila, P.; Sandnabba, N.K. Dynamics of verbal interaction between interviewer and child in interviews with alleged victims of child sexual abuse. Scand. J. Psychol. 2006, 47, 109–119. [Google Scholar] [CrossRef] [PubMed]
- Lamb, M.E.; Orbach, Y.; Sternberg, K.J.; Aldridge, J.; Pearson, S.; Stewart, H.L.; Esplin, P.W.; Bowler, L. Use of a structured investigative protocol enhances the quality of investigative interviews with alleged victims of child sexual abuse in Britain. Appl. Cogn. Psychol. Off. J. Soc. Appl. Res. Mem. Cogn. 2009, 23, 449–467. [Google Scholar] [CrossRef]
- Brubacher, S.P.; Shulman, E.P.; Bearman, M.J.; Powell, M.B. Teaching child investigative interviewing skills: Long-term retention requires cumulative training. Psychol. Public Policy Law 2021, 28, 123–136. [Google Scholar] [CrossRef]
- Krause, N.; Pompedda, F.; Antfolk, J.; Zappala, A.; Santtila, P. The Effects of Feedback and Reflection on the Questioning Style of Untrained Interviewers in Simulated Child Sexual Abuse Interviews. Appl. Cogn. Psychol. 2017, 31, 187–198. [Google Scholar] [CrossRef]
- Haginoya, S.; Yamamoto, S.; Pompedda, F.; Naka, M.; Antfolk, J.; Santtila, P. Online simulation training of child sexual abuse interviews with feedback improves interview quality in Japanese university students. Front. Psychol. 2020, 11, 998. [Google Scholar] [CrossRef]
- Haginoya, S.; Yamamoto, S.; Santtila, P. The combination of feedback and modeling in online simulation training of child sexual abuse interviews improves interview quality in clinical psychologists. Child Abus. Negl. 2021, 115, 105013. [Google Scholar] [CrossRef]
- Pompedda, F.; Zappalà, A.; Santtila, P. Simulations of child sexual abuse interviews using avatars paired with feedback improves interview quality. Psychol. Crime Law 2015, 21, 28–52. [Google Scholar] [CrossRef]
- Mayer, J.D.; Salovey, P. What is emotional intelligence? In Emotional Development and Emotional Intelligence: Educational Implications; Basic Books: New York, NY, USA, 1997; pp. 3–33. [Google Scholar]
- Joseph, D.L.; Newman, D.A. Emotional intelligence: An integrative meta-analysis and cascading model. J. Appl. Psychol. 2010, 95, 54–78. [Google Scholar] [CrossRef]
- Hochschild, A.R. The Managed Heart: Commercialization of Human Feeling; University of California Press: Berkeley, CA, USA; London, UK, 2012. [Google Scholar]
- Risan, P.; Binder, P.E.; Milne, R.J. Emotional Intelligence in Police Interviews—Approach, Training and the Usefulness of the Concept. J. Forensic Psychol. Pract. 2016, 16, 410–424. [Google Scholar] [CrossRef] [Green Version]
- Albaek, A.U.; Kinn, L.G.; Milde, A.M. Walking Children Through a Minefield: How Professionals Experience Exploring Adverse Childhood Experiences. Qual. Health Res. 2018, 28, 231–244. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ekman, P.; Friesen, W.V. A new pan-cultural facial expression of emotion. Motiv. Emot. 1986, 10, 159–168. [Google Scholar] [CrossRef] [Green Version]
- Ekman, P.; Heider, K.G. The universality of a contempt expression: A replication. Motiv. Emot. 1988, 12, 303–308. [Google Scholar] [CrossRef]
- Matsumoto, D. More evidence for the universality of a contempt expression. Motiv. Emot. 1992, 16, 363–368. [Google Scholar] [CrossRef]
- Katz, L.F.; Hunter, E.C. Maternal meta-emotion philosophy and adolescent depressive symptomatology. Soc. Dev. 2007, 16, 343–360. [Google Scholar] [CrossRef]
- Karni-Visel, Y.; Hershkowitz, I.; Lamb, M.E.; Blasbalg, U. Nonverbal Emotions While Disclosing Child Abuse: The Role of Interviewer Support. Child Maltreatment 2021, 29, 10775595211063497. [Google Scholar] [CrossRef]
- Kerig, P.K.; Bennett, D.C.; Chaplo, S.D.; Modrowski, C.A.; McGee, A.B. Numbing of Positive, Negative, and General Emotions: Associations with Trauma Exposure, Posttraumatic Stress, and Depressive Symptoms Among Justice-Involved Youth: Numbing of Positive, Negative, or General Emotions. J. Trauma. Stress 2016, 29, 111–119. [Google Scholar] [CrossRef]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent trends in deep learning based natural language processing. CIM 2018, 13, 55–75. [Google Scholar]
- Vinyals, O.; Le, Q. A neural conversational model. arXiv 2015, arXiv:1506.05869. [Google Scholar]
- Zhou, H.; Huang, M.; Zhang, T.; Zhu, X.; Liu, B. Emotional chatting machine: Emotional conversation generation with internal and external memory. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Zhou, L.; Gao, J.; Li, D.; Shum, H.Y. The Design and Implementation of XiaoIce, an Empathetic Social Chatbot. arXiv 2019, arXiv:1812.08989. [Google Scholar] [CrossRef]
- Li, J.; Galley, M.; Brockett, C.; Spithourakis, G.P.; Gao, J.; Dolan, B. A persona-based neural conversation model. arXiv 2016, arXiv:1603.06155. [Google Scholar]
- Tachibana, H.; Uenoyama, K.; Aihara, S. Efficiently trainable text-to-speech system based on deep convolutional networks with guided attention. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 4784–4788. [Google Scholar]
- Amberkar, A.; Awasarmol, P.; Deshmukh, G.; Dave, P. Speech recognition using recurrent neural networks. In Proceedings of the 2018 International Conference on Current Trends towards Converging Technologies (ICCTCT), Coimbatore, India, 1–3 March 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–4. [Google Scholar]
- Xiong, W.; Droppo, J.; Huang, X.; Seide, F.; Seltzer, M.L.; Stolcke, A.; Yu, D.; Zweig, G. Toward Human Parity in Conversational Speech Recognition. IEEE/ACM Trans. Audio Speech Lang. Proc. 2017, 25, 2410–2423. [Google Scholar] [CrossRef]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. Specaugment: A simple data augmentation method for automatic speech recognition. arXiv 2019, arXiv:1904.08779. [Google Scholar]
- Sadjadi, O.; Greenberg, C.; Singer, E.; Mason, L.; Reynolds, D. NIST 2021 Speaker Recognition Evaluation Plan; NIST: Gaithersburg, MD, USA, 2021.
- Zhang, Y.; Qin, J.; Park, D.S.; Han, W.; Chiu, C.C.; Pang, R.; Le, Q.V.; Wu, Y. Pushing the limits of semi-supervised learning for automatic speech recognition. arXiv 2020, arXiv:2010.10504. [Google Scholar]
- Chung, Y.A.; Zhang, Y.; Han, W.; Chiu, C.C.; Qin, J.; Pang, R.; Wu, Y. W2v-bert: Combining contrastive learning and masked language modeling for self-supervised speech pre-training. arXiv 2021, arXiv:2108.06209. [Google Scholar]
- Busso, C.; Bulut, M.; Lee, C.C.; Kazemzadeh, A.; Mower Provost, E.; Kim, S.; Chang, J.; Lee, S.; Narayanan, S. IEMOCAP: Interactive emotional dyadic motion capture database. Lang. Resour. Eval. 2008, 42, 335–359. [Google Scholar] [CrossRef]
- Zhao, J.; Mao, X.; Chen, L. Speech emotion recognition using deep 1D & 2D CNN LSTM networks. Biomed. Signal Process. Control 2019, 47, 312–323. [Google Scholar] [CrossRef]
- Fayek, H.; Lech, M.; Cavedon, L. Evaluating deep learning architectures for Speech Emotion Recognition. Neural Netw. 2017, 92, 60–68. [Google Scholar] [CrossRef]
- Shen, J.; Pang, R.; Weiss, R.J.; Schuster, M.; Jaitly, N.; Yang, Z.; Chen, Z.; Zhang, Y.; Wang, Y.; Skerrv-Ryan, R.; et al. Natural tts synthesis by conditioning wavenet on mel spectrogram predictions. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 4779–4783. [Google Scholar]
- Prenger, R.; Valle, R.; Catanzaro, B. Waveglow: A flow-based generative network for speech synthesis. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–19 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 3617–3621. [Google Scholar]
- Kalchbrenner, N.; Elsen, E.; Simonyan, K.; Noury, S.; Casagrande, N.; Lockhart, E.; Stimberg, F.; Oord, A.V.D.; Dieleman, S.; Kavukcuoglu, K. Efficient Neural Audio Synthesis. arXiv 2018, arXiv:1802.08435. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of gans for improved quality, stability, and variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 8110–8119. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8789–8797. [Google Scholar]
- Agarwal, S.; Farid, H.; Gu, Y.; He, M.; Nagano, K.; Li, H. Protecting World Leaders Against Deep Fakes. In Proceedings of the CVPR Workshops, Long Beach, CA, USA, 16–20 June 2019; Volume 1. [Google Scholar]
- Perov, I.; Gao, D.; Chervoniy, N.; Liu, K.; Marangonda, S.; Umé, C.; Dpfks, M.; Facenheim, C.S.; RP, L.; Jiang, J.; et al. DeepFaceLab: Integrated, flexible and extensible face-swapping framework. arXiv 2020, arXiv:2005.05535. [Google Scholar]
- Suwajanakorn, S.; Seitz, S.M.; Kemelmacher-Shlizerman, I. Synthesizing obama: Learning lip sync from audio. ACM Trans. Graph. ToG 2017, 36, 1–13. [Google Scholar] [CrossRef]
- Chen, L.; Maddox, R.K.; Duan, Z.; Xu, C. Hierarchical cross-modal talking face generation with dynamic pixel-wise loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7832–7841. [Google Scholar]
- Zhou, Y.; Han, X.; Shechtman, E.; Echevarria, J.; Kalogerakis, E.; Li, D. Makelttalk: Speaker-aware talking-head animation. ACM Trans. Graph. TOG 2020, 39, 1–15. [Google Scholar] [CrossRef]
- Meshry, M.; Suri, S.; Davis, L.S.; Shrivastava, A. Learned Spatial Representations for Few-shot Talking-Head Synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 13829–13838. [Google Scholar]
- Lu, Y.; Chai, J.; Cao, X. Live speech portraits: Real-time photorealistic talking-head animation. ACM Trans. Graph. TOG 2021, 40, 1–17. [Google Scholar] [CrossRef]
- Yi, R.; Ye, Z.; Zhang, J.; Bao, H.; Liu, Y.J. Audio-driven talking face video generation with learning-based personalized head pose. arXiv 2020, arXiv:2002.10137. [Google Scholar]
- Thies, J.; Elgharib, M.; Tewari, A.; Theobalt, C.; Nießner, M. Neural voice puppetry: Audio-driven facial reenactment. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 716–731. [Google Scholar]
- Chen, L.; Cui, G.; Liu, C.; Li, Z.; Kou, Z.; Xu, Y.; Xu, C. Talking-head generation with rhythmic head motion. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 35–51. [Google Scholar]
- Richard, A.; Lea, C.; Ma, S.; Gall, J.; De la Torre, F.; Sheikh, Y. Audio-and gaze-driven facial animation of codec avatars. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 11 August 2021; pp. 41–50. [Google Scholar]
- Song, L.; Wu, W.; Qian, C.; He, R.; Loy, C.C. Everybody’s talkin’: Let me talk as you want. IEEE Trans. Inf. Forensics Secur. 2022, 17, 585–598. [Google Scholar] [CrossRef]
- Thies, J.; Zollhofer, M.; Stamminger, M.; Theobalt, C.; Nießner, M. Face2face: Real-time face capture and reenactment of rgb videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2387–2395. [Google Scholar]
- Tripathy, S.; Kannala, J.; Rahtu, E. Icface: Interpretable and controllable face reenactment using gans. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2020; pp. 3385–3394. [Google Scholar]
- Zhou, H.; Sun, Y.; Wu, W.; Loy, C.C.; Wang, X.; Liu, Z. Pose-controllable talking face generation by implicitly modularized audio-visual representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4176–4186. [Google Scholar]
- Zhou, H.; Liu, Y.; Liu, Z.; Luo, P.; Wang, X. Talking face generation by adversarially disentangled audio-visual representation. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9299–9306. [Google Scholar]
- Wiles, O.; Koepke, A.; Zisserman, A. X2face: A network for controlling face generation using images, audio, and pose codes. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 670–686. [Google Scholar]
- Ha, S.; Kersner, M.; Kim, B.; Seo, S.; Kim, D. Marionette: Few-shot face reenactment preserving identity of unseen targets. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 10893–10900. [Google Scholar]
- Bansal, A.; Ma, S.; Ramanan, D.; Sheikh, Y. Recycle-gan: Unsupervised video retargeting. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 119–135. [Google Scholar]
- Kim, H.; Garrido, P.; Tewari, A.; Xu, W.; Thies, J.; Niessner, M.; Pérez, P.; Richardt, C.; Zollhöfer, M.; Theobalt, C. Deep video portraits. ACM Trans. Graph. TOG 2018, 37, 1–14. [Google Scholar] [CrossRef]
- Pompedda, F.; Antfolk, J.; Zappalà, A.; Santtila, P. A combination of outcome and process feedback enhances performance in simulations of child sexual abuse interviews using avatars. Front. Psychol. 2017, 8, 1474. [Google Scholar] [CrossRef] [Green Version]
- Pompedda, F.; Palu, A.; Kask, K.; Schiff, K.; Soveri, A.; Antfolk, J.; Santtila, P. Transfer of simulated interview training effects into interviews with children exposed to a mock event. Nordic Psychol. 2020, 73, 43–67. [Google Scholar] [CrossRef]
- Pompedda, F.; Zhang, Y.; Haginoya, S.; Santtila, P. A Mega-Analysis of the Effects of Feedback on the Quality of Simulated Child Sexual Abuse Interviews with Avatars. J. Police Crim. Psychol. 2022, 1–14. [Google Scholar] [CrossRef]
- Dalli, K.C. Technological Acceptance of an Avatar Based Interview Training Application: The Development and Technological Acceptance Study of the AvBIT Application. Master’s Thesis, Linnaeus University, Växjö, Sweden, 2021. [Google Scholar]
- Johansson, D. Design and Evaluation of an Avatar-Mediated System for Child Interview Training. Master’s Thesis, Line University, Kanagawa, Japan, 2015. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Bunk, T.; Varshneya, D.; Vlasov, V.; Nichol, A. Diet: Lightweight language understanding for dialogue systems. arXiv 2020, arXiv:2004.09936. [Google Scholar]
- ITU-T Recommendation P.809. Subjective Evaluation Methods for Gaming Quality; International Telecommunication Union: Geneva, Switzerland, 2018. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. arXiv 2019, arXiv:1910.13461. [Google Scholar] [CrossRef]
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, Brussels, Belgium, 1 November 2018; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 353–355. [Google Scholar] [CrossRef] [Green Version]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Jack, R.E.; Garrod, O.G.B.; Schyns, P.G. Dynamic Facial Expressions of Emotion Transmit an Evolving Hierarchy of Signals over Time. Curr. Biol. 2014, 24, 187–192. [Google Scholar] [CrossRef] [Green Version]
- Deepfakes. github. 2019. Available online: https://github.com/deepfakes/faceswap (accessed on 20 May 2022).
- Sha, T.; Zhang, W.; Shen, T.; Li, Z.; Mei, T. Deep Person Generation: A Survey from the Perspective of Face, Pose and Cloth Synthesis. arXiv 2021, arXiv:2109.02081. [Google Scholar]
- Zhu, H.; Luo, M.; Wang, R.; Zheng, A.; He, R. Deep audio-visual learning: A survey. Int. J. Autom. Comput. 2021, 18, 351–376. [Google Scholar] [CrossRef]
- Tolosana, R.; Vera-Rodriguez, R.; Fierrez, J.; Morales, A.; Ortega-Garcia, J. Deepfakes and beyond: A survey of face manipulation and fake detection. Inf. Fusion 2020, 64, 131–148. [Google Scholar] [CrossRef]
- Kumar, R.; Sotelo, J.; Kumar, K.; de Brébisson, A.; Bengio, Y. ObamaNet: Photo-realistic lip-sync from text. arXiv 2018, arXiv:1801.01442. [Google Scholar]
- Baugerud, G.A.; Johnson, M.S.; Klingenberg Røed, R.; Lamb, M.E.; Powell, M.; Thambawita, V.; Hicks, S.A.; Salehi, P.; Hassan, S.Z.; Halvorsen, P.; et al. Multimodal virtual avatars for investigative interviews with children. In Proceedings of the 2021 Workshop on Intelligent Cross-Data Analysis and Retrieval, Taipei, Taiwan, 21 August 2021; pp. 2–8. [Google Scholar]
- Chung, J.S.; Nagrani, A.; Zisserman, A. Voxceleb2: Deep speaker recognition. arXiv 2018, arXiv:1806.05622. [Google Scholar]
- Koo, T.K.; Li, M.Y. A Guideline of Selecting and Reporting Intraclass Correlation Coefficients for Reliability Research. J. Chiropr. Med. 2016, 15, 155–163. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–19 June 2019; pp. 4401–4410. [Google Scholar]
- Mori, M.; MacDorman, K.F.; Kageki, N. The uncanny valley [from the field]. IEEE Robot. Autom. Mag. 2012, 19, 98–100. [Google Scholar] [CrossRef]
- MacDorman, K.F.; Green, R.D.; Ho, C.C.; Koch, C.T. Too real for comfort? Uncanny responses to computer generated faces. Comput. Hum. Behav. 2009, 25, 695–710. [Google Scholar] [CrossRef] [Green Version]
- Brunnström, K.; Beker, S.A.; De Moor, K.; Dooms, A.; Egger, S.; Garcia, M.N.; Hossfeld, T.; Jumisko-Pyykkö, S.; Keimel, C.; Larabi, M.C.; et al. Qualinet white Paper on Definitions of Quality of Experience; HAL: Bengaluru, India, 2013. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salehi, P.; Hassan, S.Z.; Lammerse, M.; Sabet, S.S.; Riiser, I.; Røed, R.K.; Johnson, M.S.; Thambawita, V.; Hicks, S.A.; Powell, M.; et al. Synthesizing a Talking Child Avatar to Train Interviewers Working with Maltreated Children. Big Data Cogn. Comput. 2022, 6, 62. https://doi.org/10.3390/bdcc6020062
Salehi P, Hassan SZ, Lammerse M, Sabet SS, Riiser I, Røed RK, Johnson MS, Thambawita V, Hicks SA, Powell M, et al. Synthesizing a Talking Child Avatar to Train Interviewers Working with Maltreated Children. Big Data and Cognitive Computing. 2022; 6(2):62. https://doi.org/10.3390/bdcc6020062
Chicago/Turabian StyleSalehi, Pegah, Syed Zohaib Hassan, Myrthe Lammerse, Saeed Shafiee Sabet, Ingvild Riiser, Ragnhild Klingenberg Røed, Miriam S. Johnson, Vajira Thambawita, Steven A. Hicks, Martine Powell, and et al. 2022. "Synthesizing a Talking Child Avatar to Train Interviewers Working with Maltreated Children" Big Data and Cognitive Computing 6, no. 2: 62. https://doi.org/10.3390/bdcc6020062
APA StyleSalehi, P., Hassan, S. Z., Lammerse, M., Sabet, S. S., Riiser, I., Røed, R. K., Johnson, M. S., Thambawita, V., Hicks, S. A., Powell, M., Lamb, M. E., Baugerud, G. A., Halvorsen, P., & Riegler, M. A. (2022). Synthesizing a Talking Child Avatar to Train Interviewers Working with Maltreated Children. Big Data and Cognitive Computing, 6(2), 62. https://doi.org/10.3390/bdcc6020062