
Cognitive Networks Extract Insights on COVID-19 Vaccines from English and Italian Popular Tweets: Anticipation, Logistics, Conspiracy and Loss of Trust



Abstract
:1. Introduction
1.1. Reconstructing Perceptions with Artificial Intelligence and Complex Networks
1.2. Innovative Contributions of This Work: Cognitive Networks Operationalise Semantic Frame Theory in COVID-19 Social Discourse with Text and Pictures
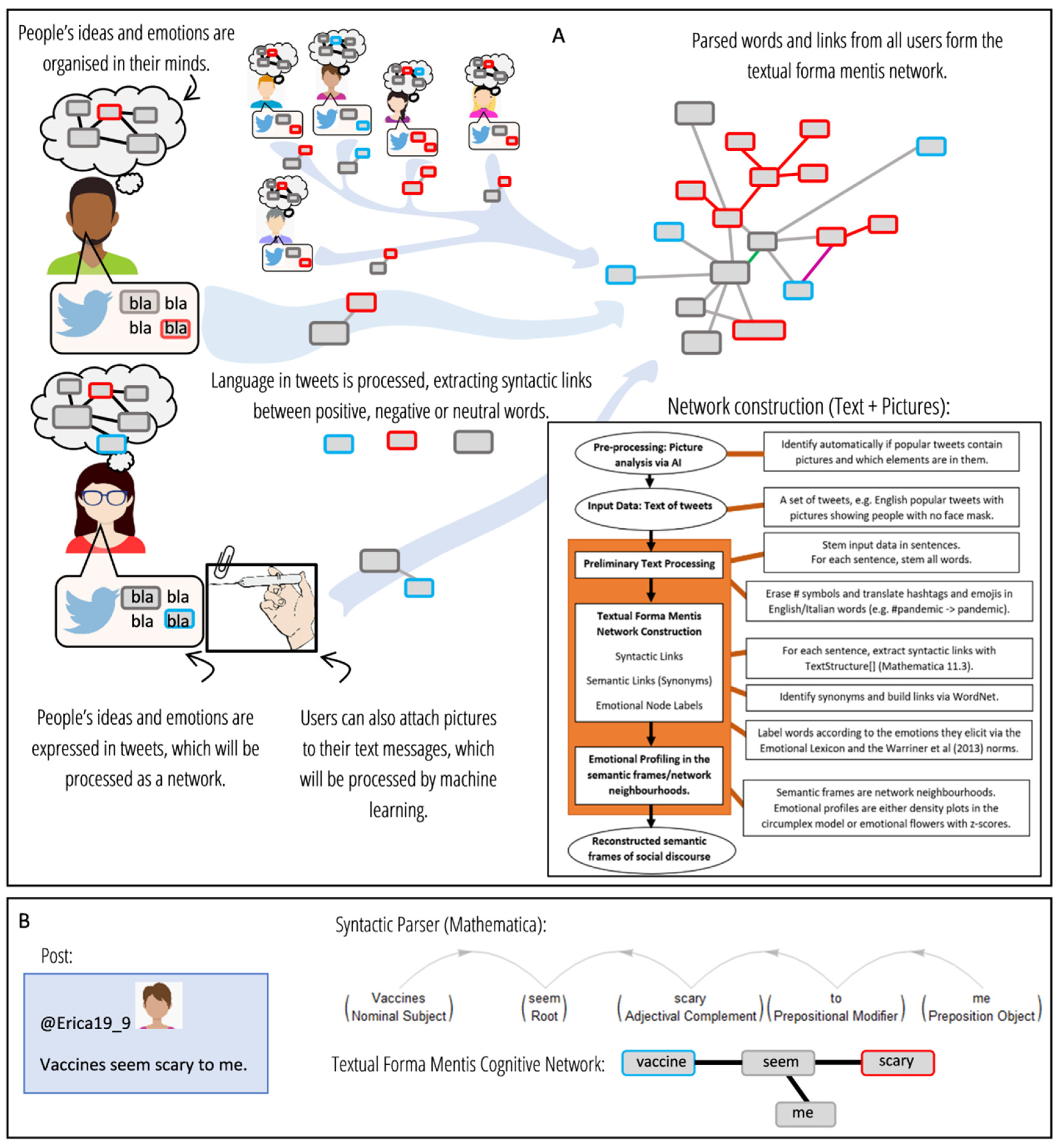
2. Materials and Methods
2.1. Twitter Dataset and Data Ethics
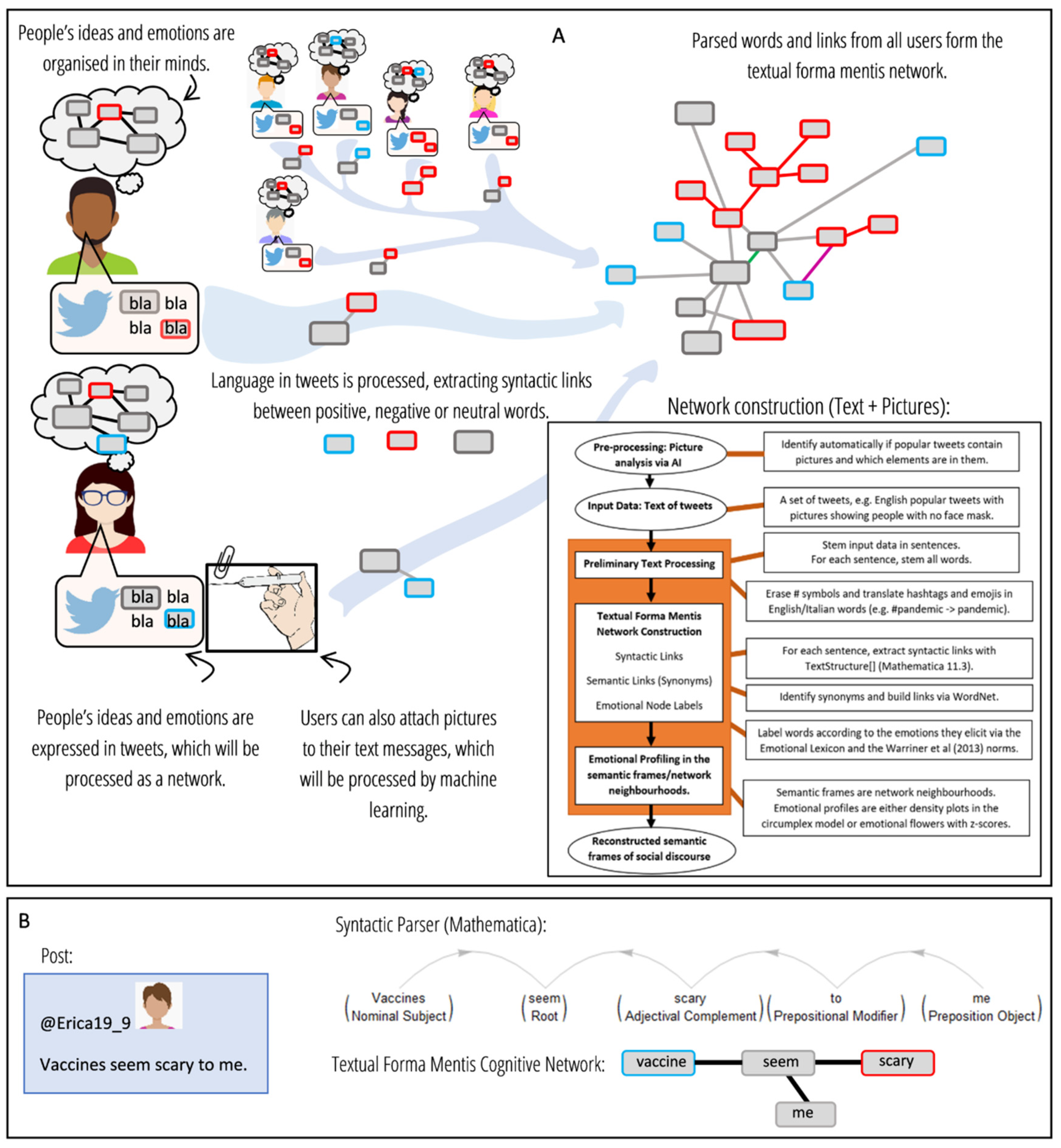
2.2. Language Processing and Network Construction
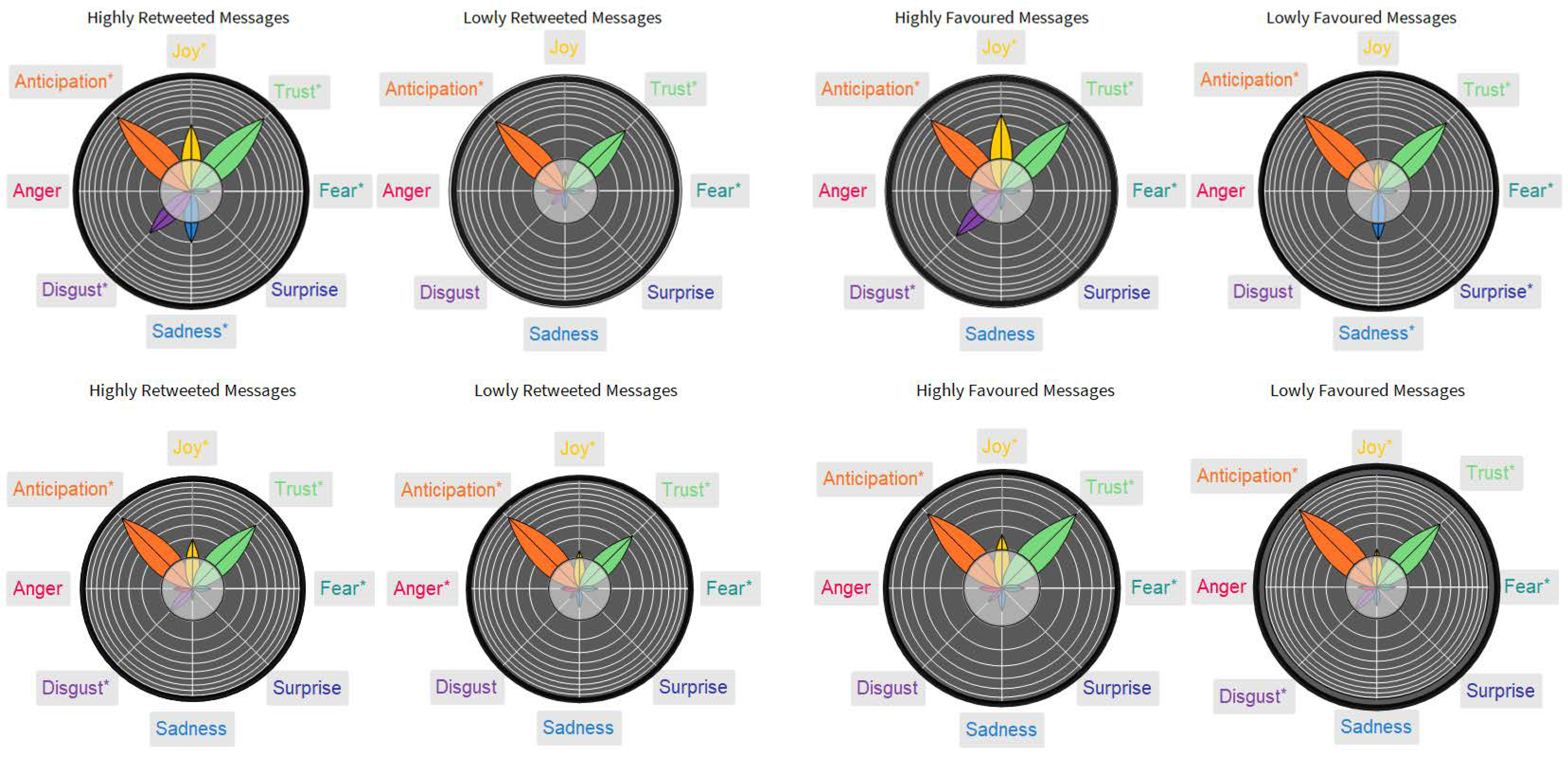
2.3. Cognitive Datasets and Emotional Profiling
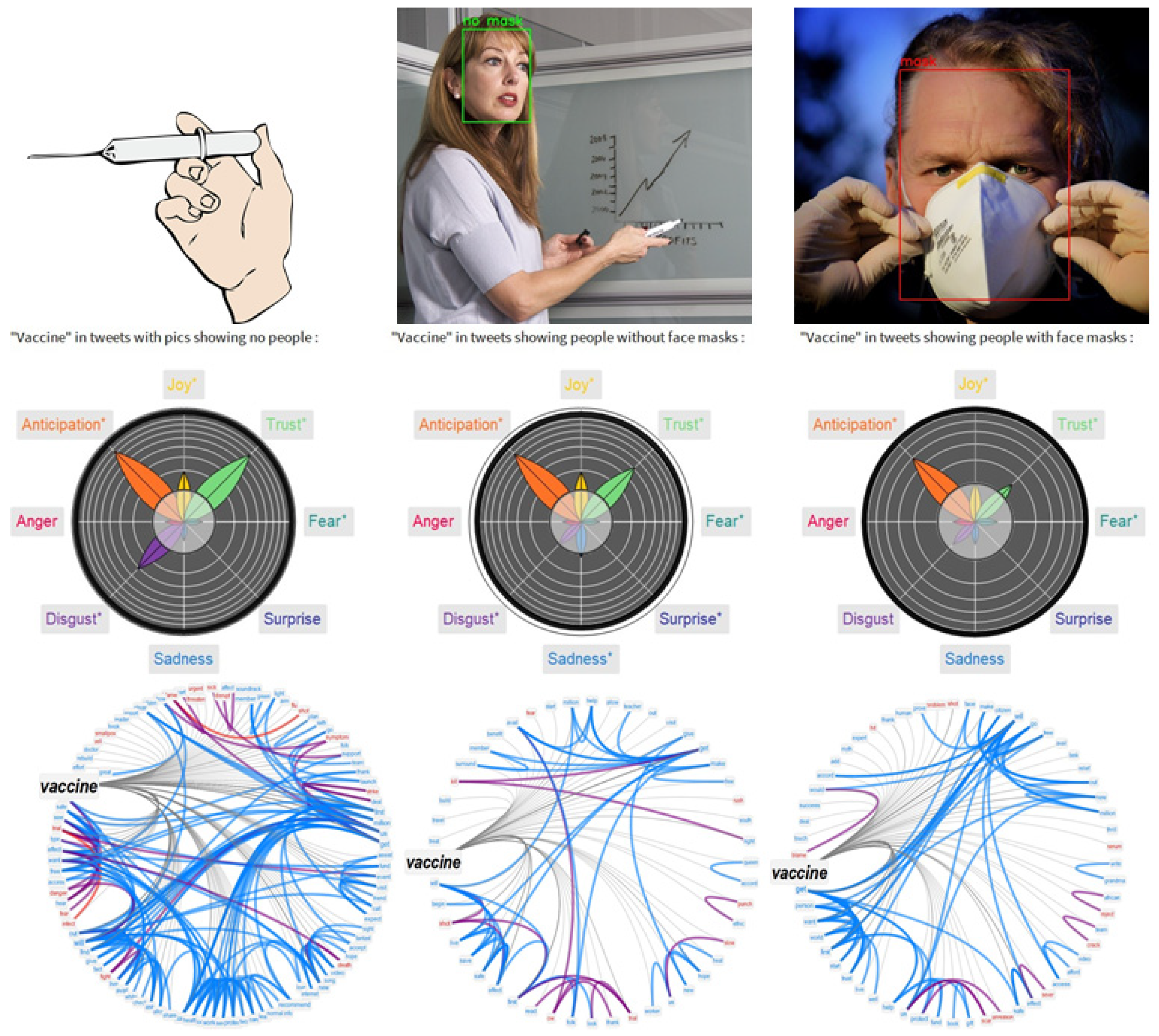
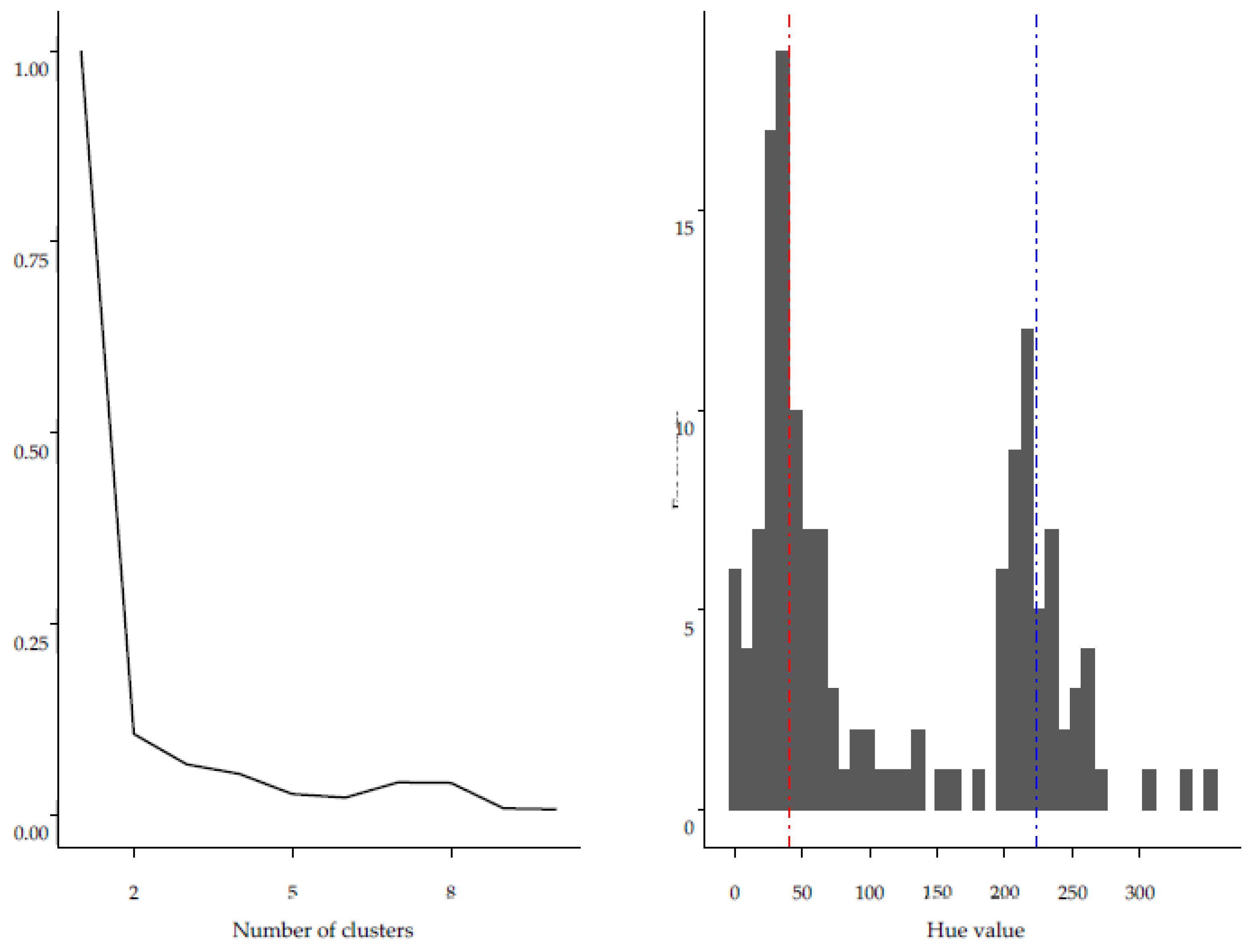
2.4. Enriching Text Analysis with Multimedia Features of Tweets
3. Results
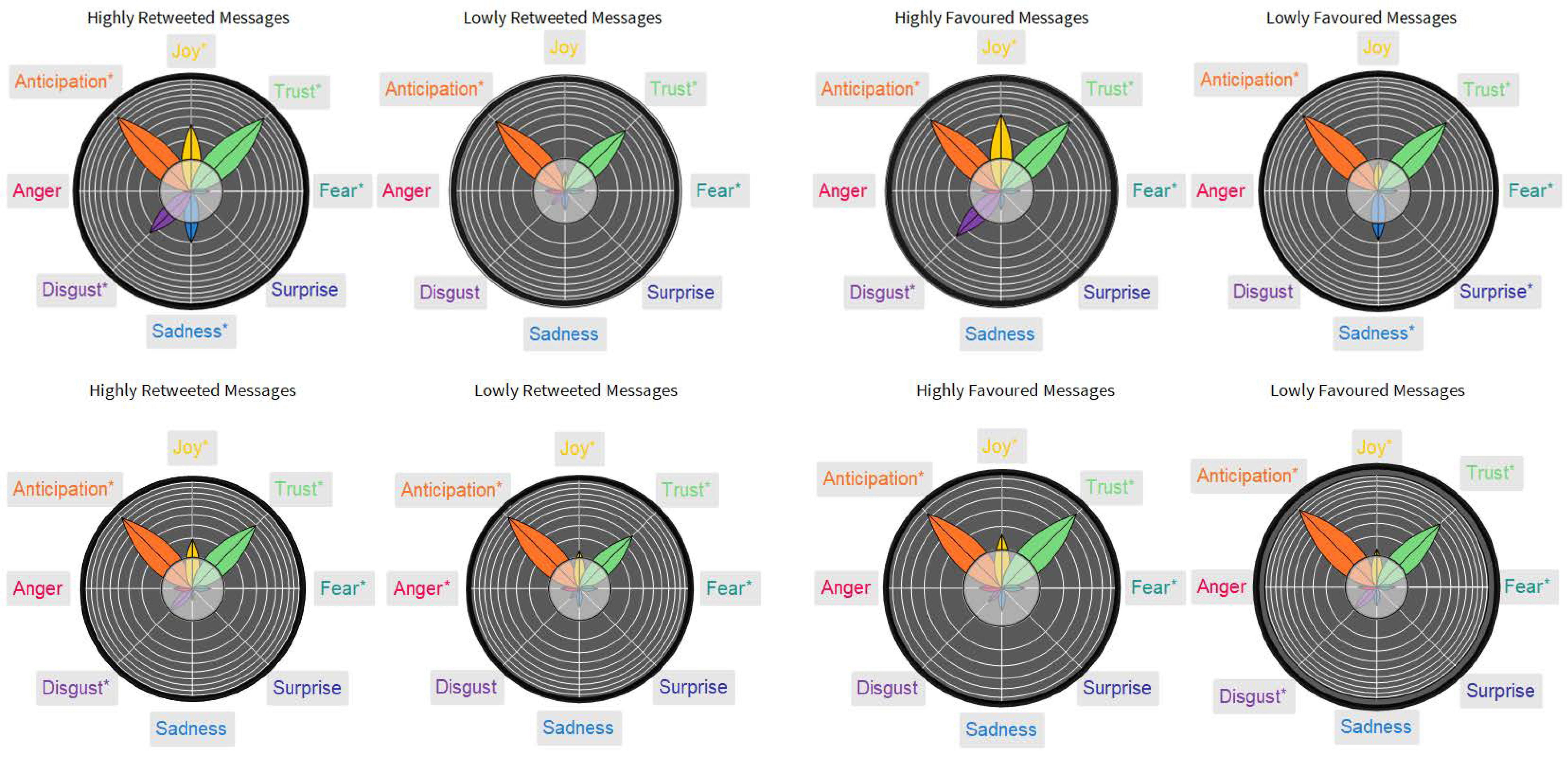
3.1. Prominent Concepts Captured by Frequency and Network Centrality
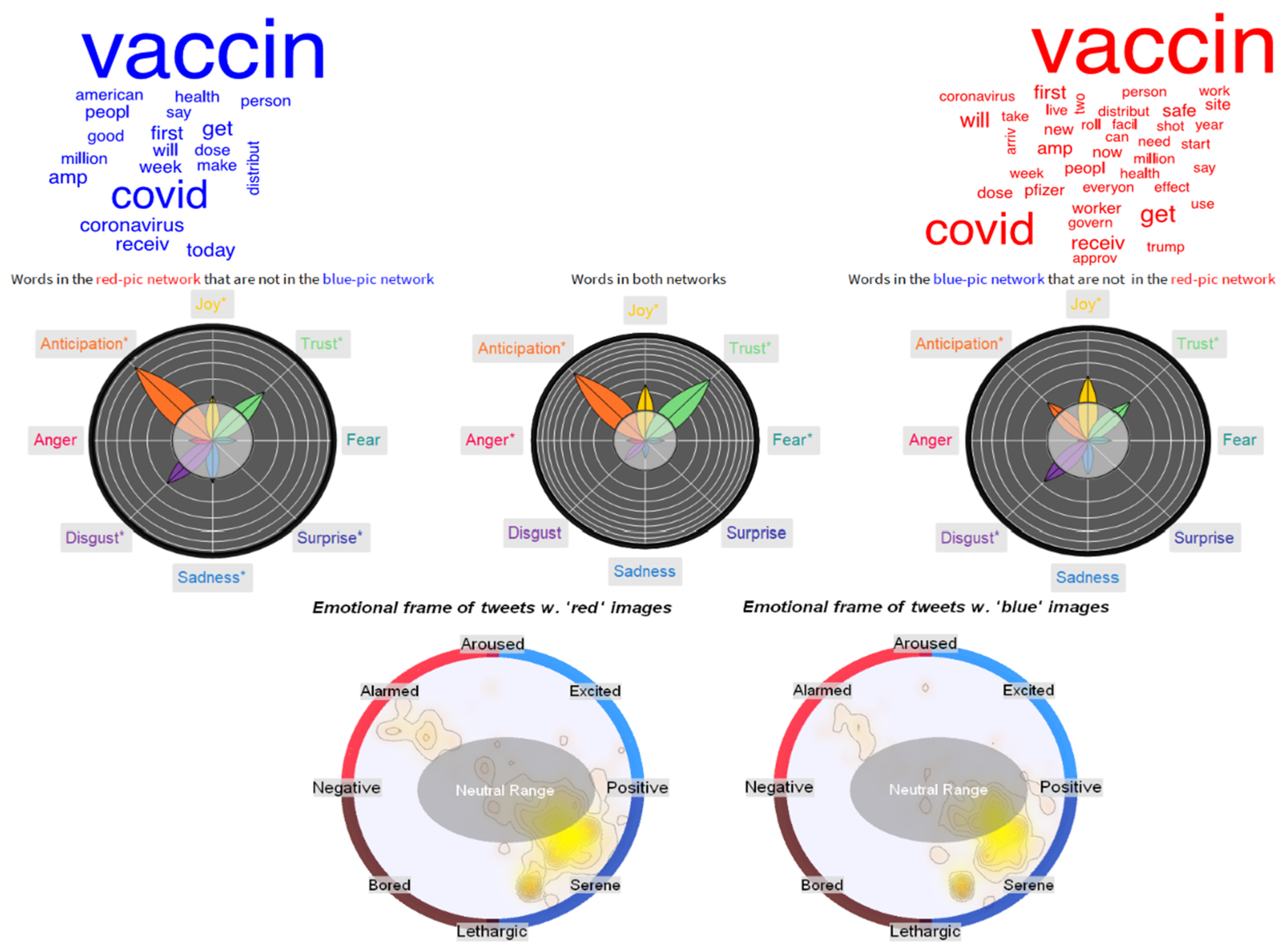
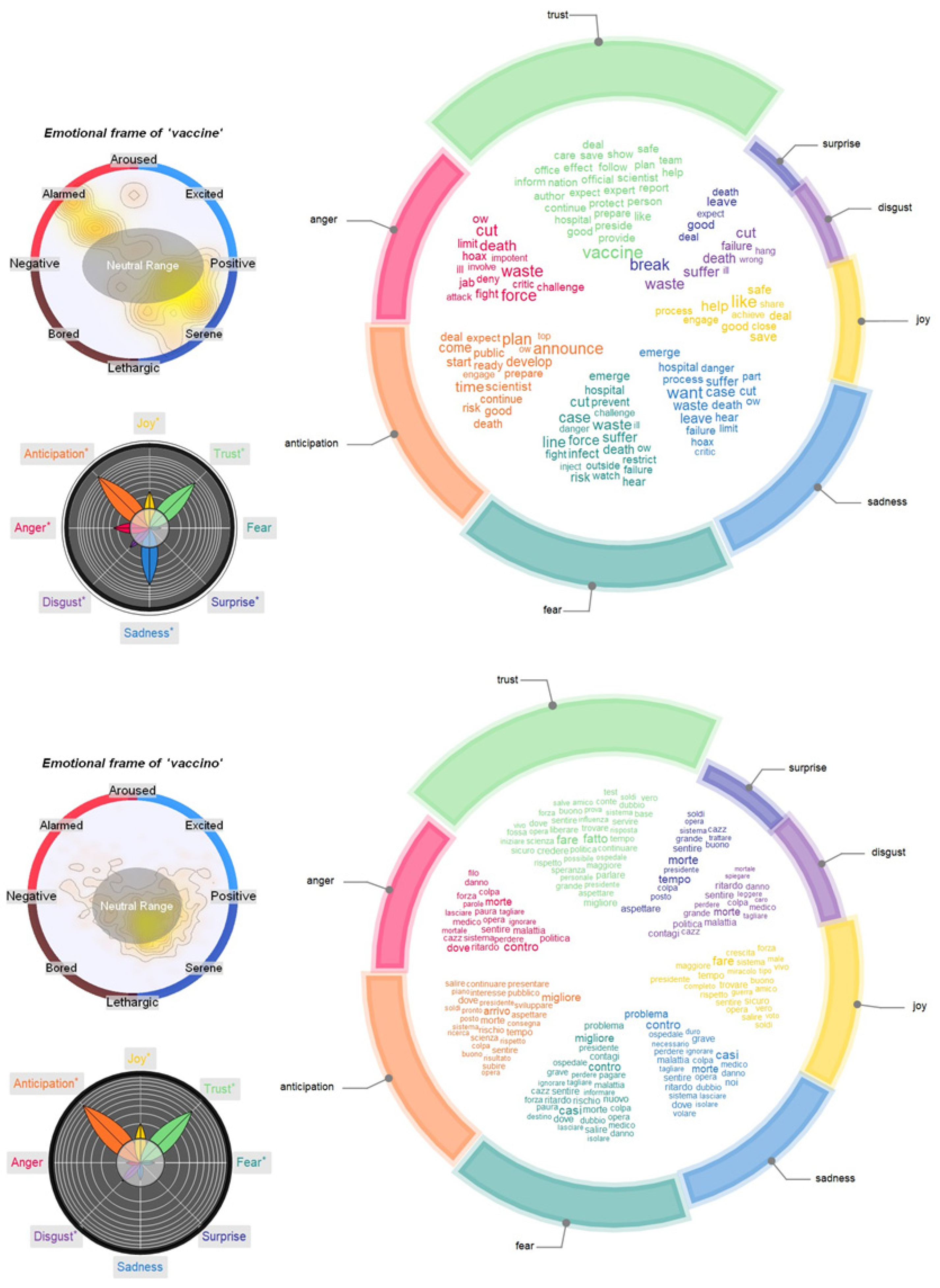
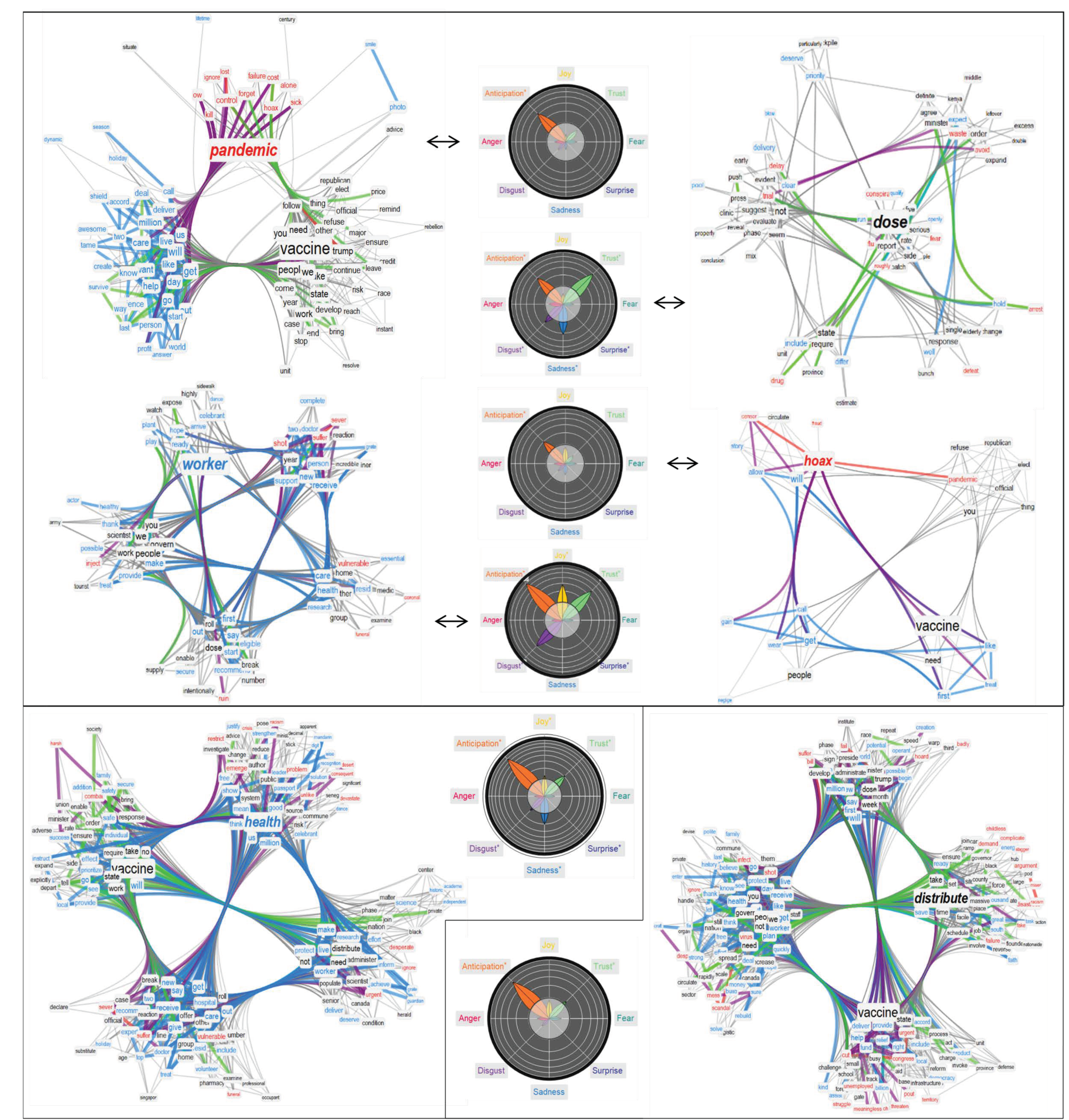
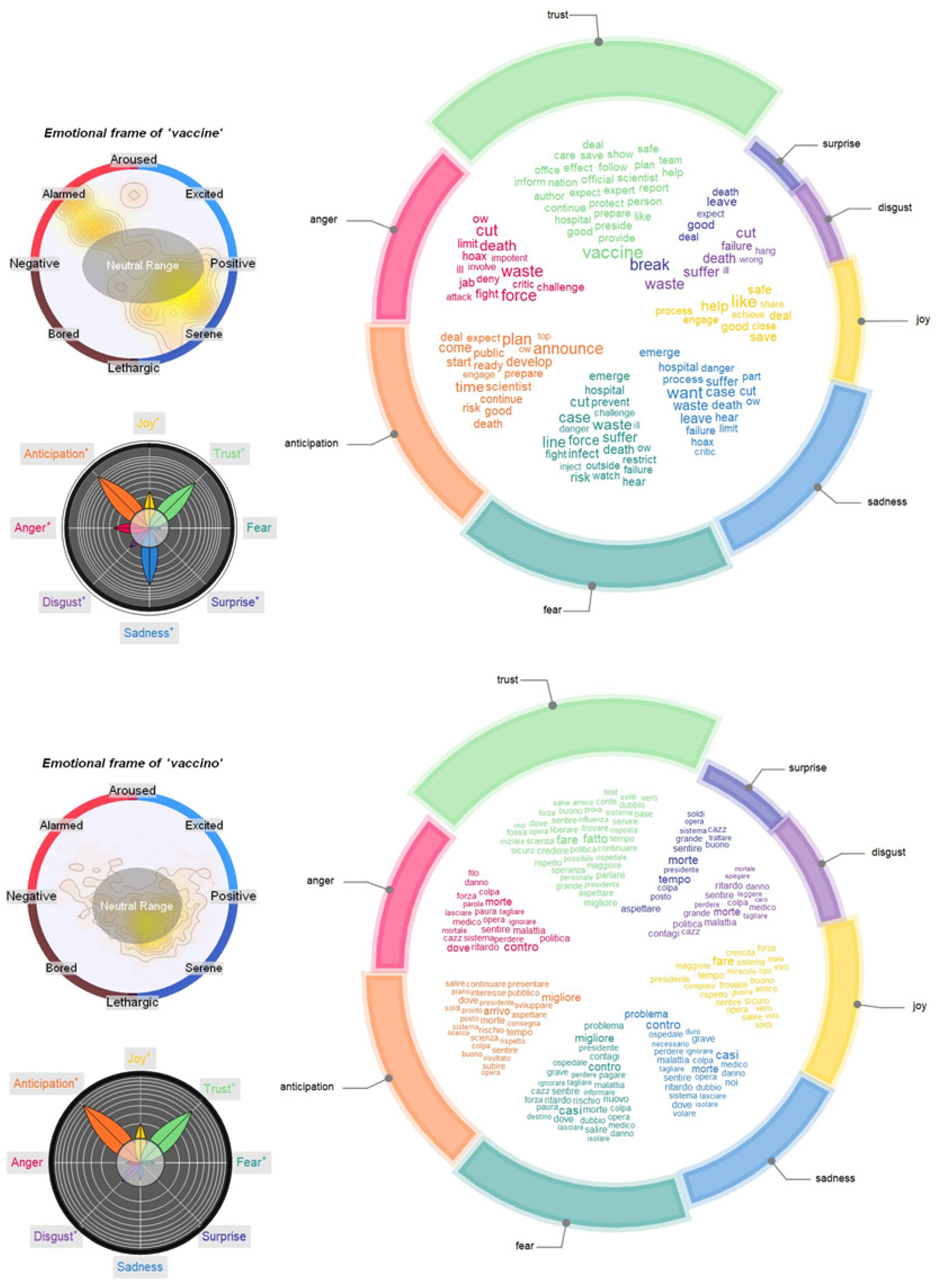
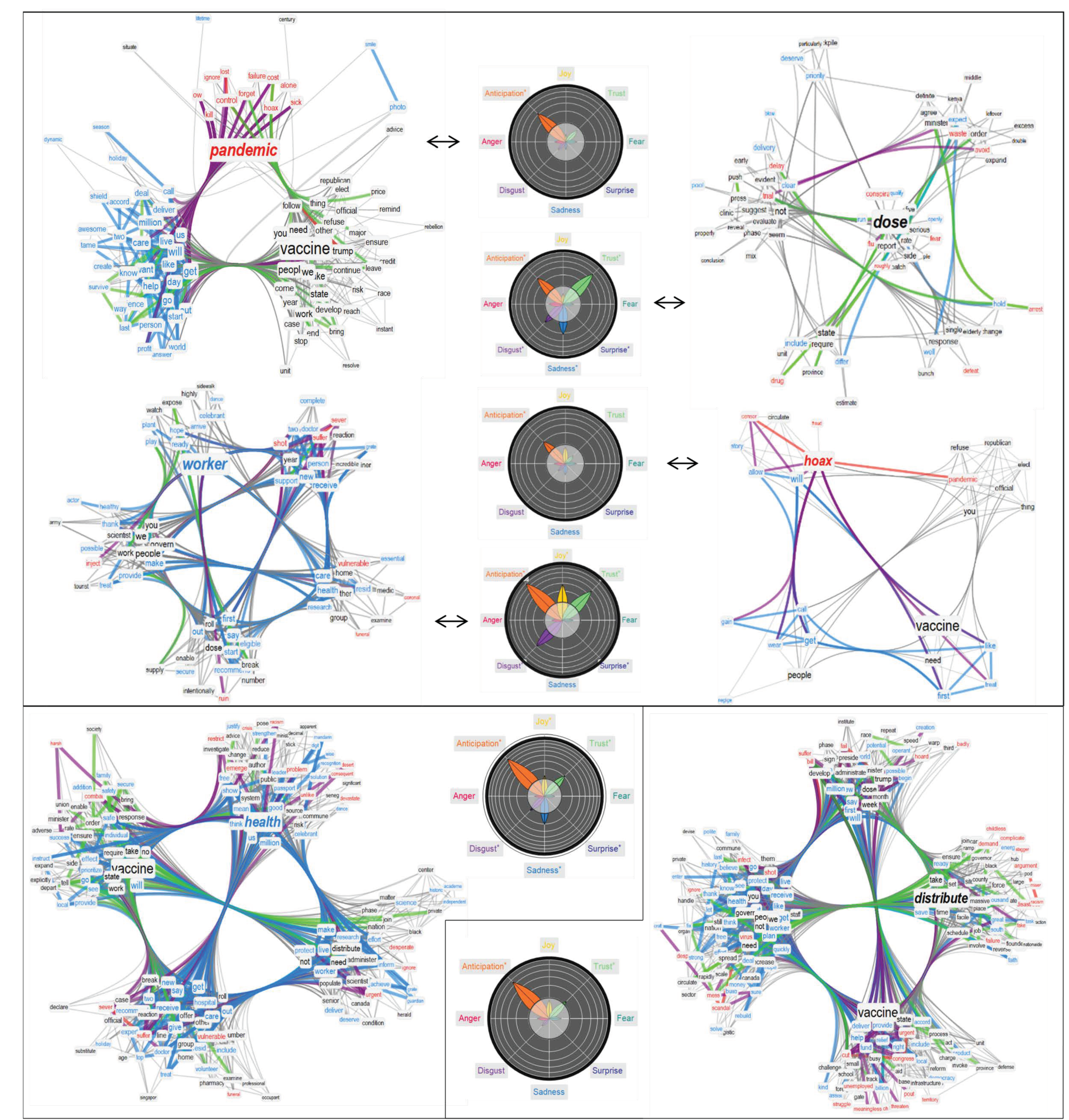
3.2. Semantic Frames for “Vaccine”: Logistics, Content Sharing, Trump and Hoaxes
- The associations attributed to “dose” identified aspects such as “delay”, “trial”, “waste”, “fear” and “conspiracy”, highlighting concern about the validity of a dose of vaccine.
- Sadness around “workers” had as semantic associations “vulnerable”, “expose”, “funeral”, “essential”, “suffer” and “severe”, indicating how popular tweets highlighted the importance for exposed workers to receive a vaccine.
- The above trend co-existed with positive emotions originating from celebratory jargon (“thanks”, “celebrate”), identifying the importance of workers during the pandemic.
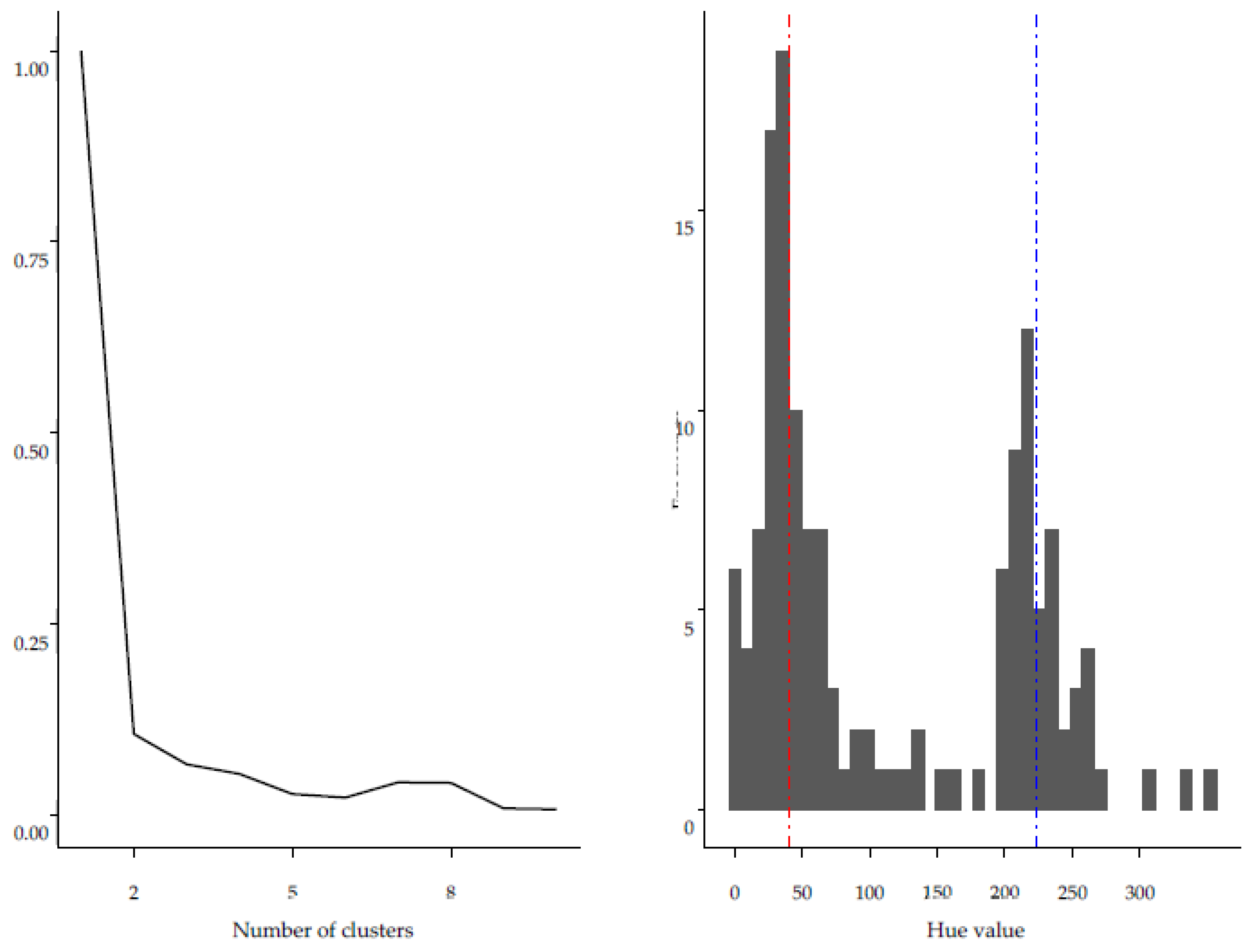
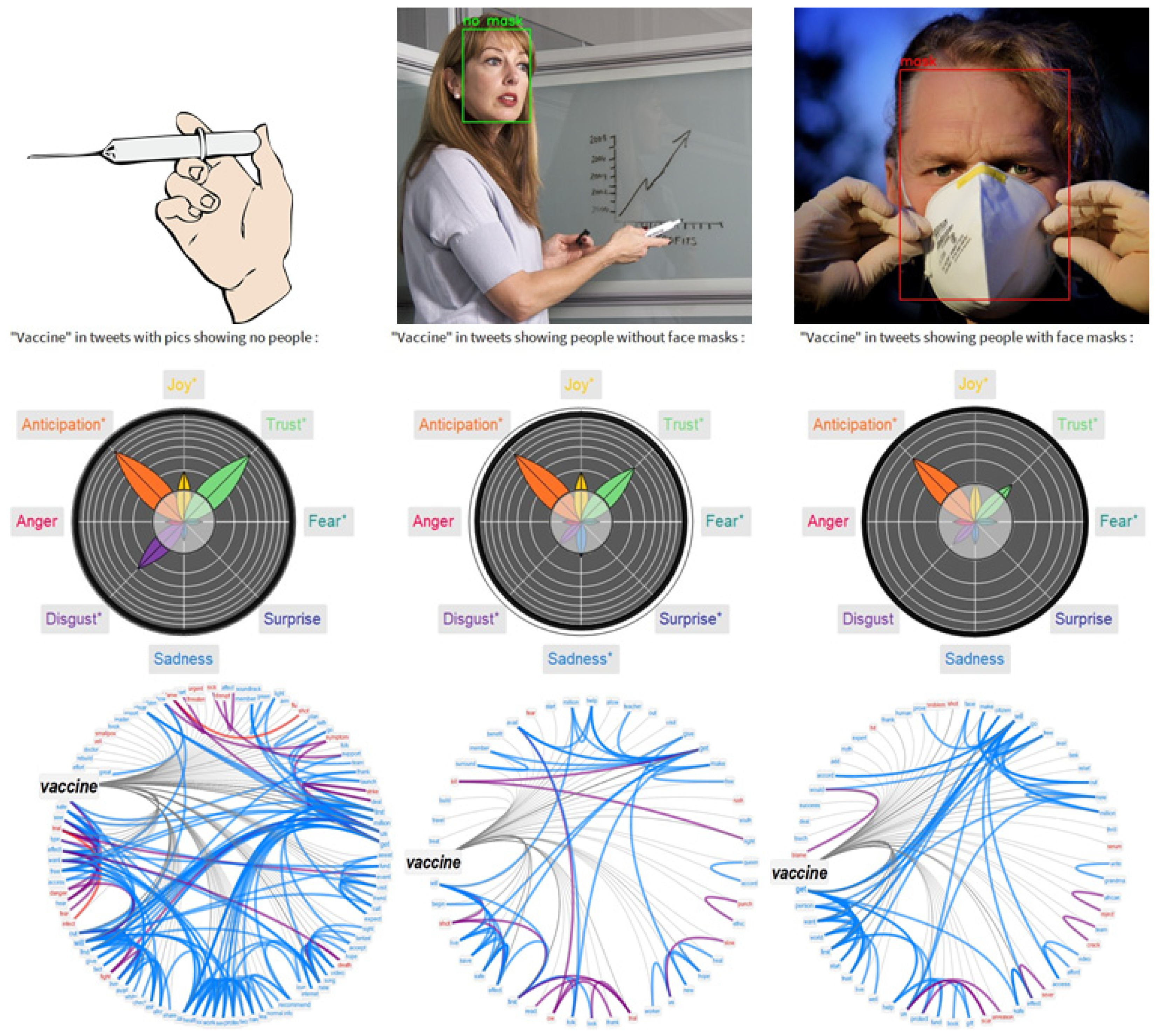
3.3. Extracting the Emotional Profiles of Face Masks with Machine Learning
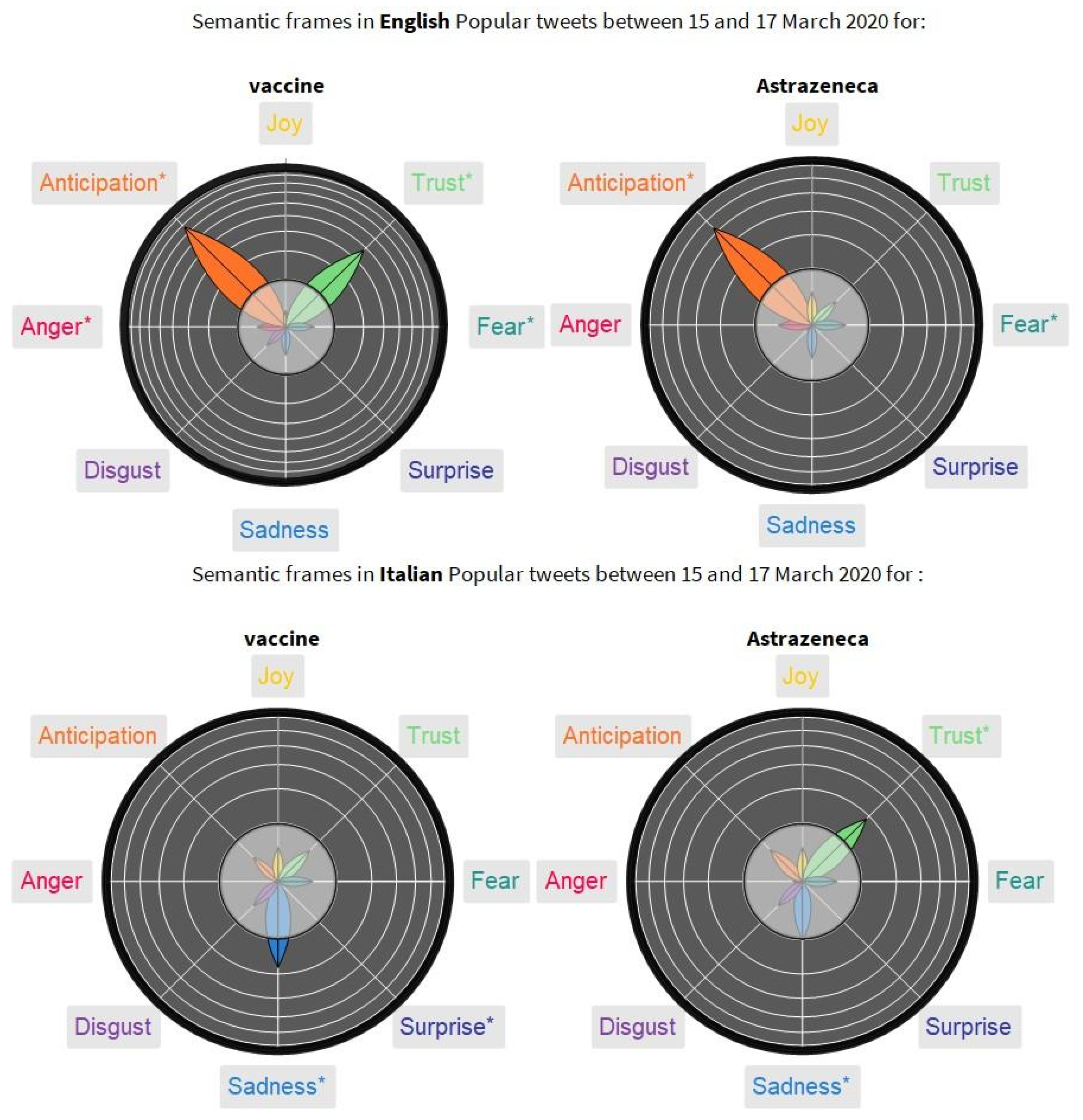
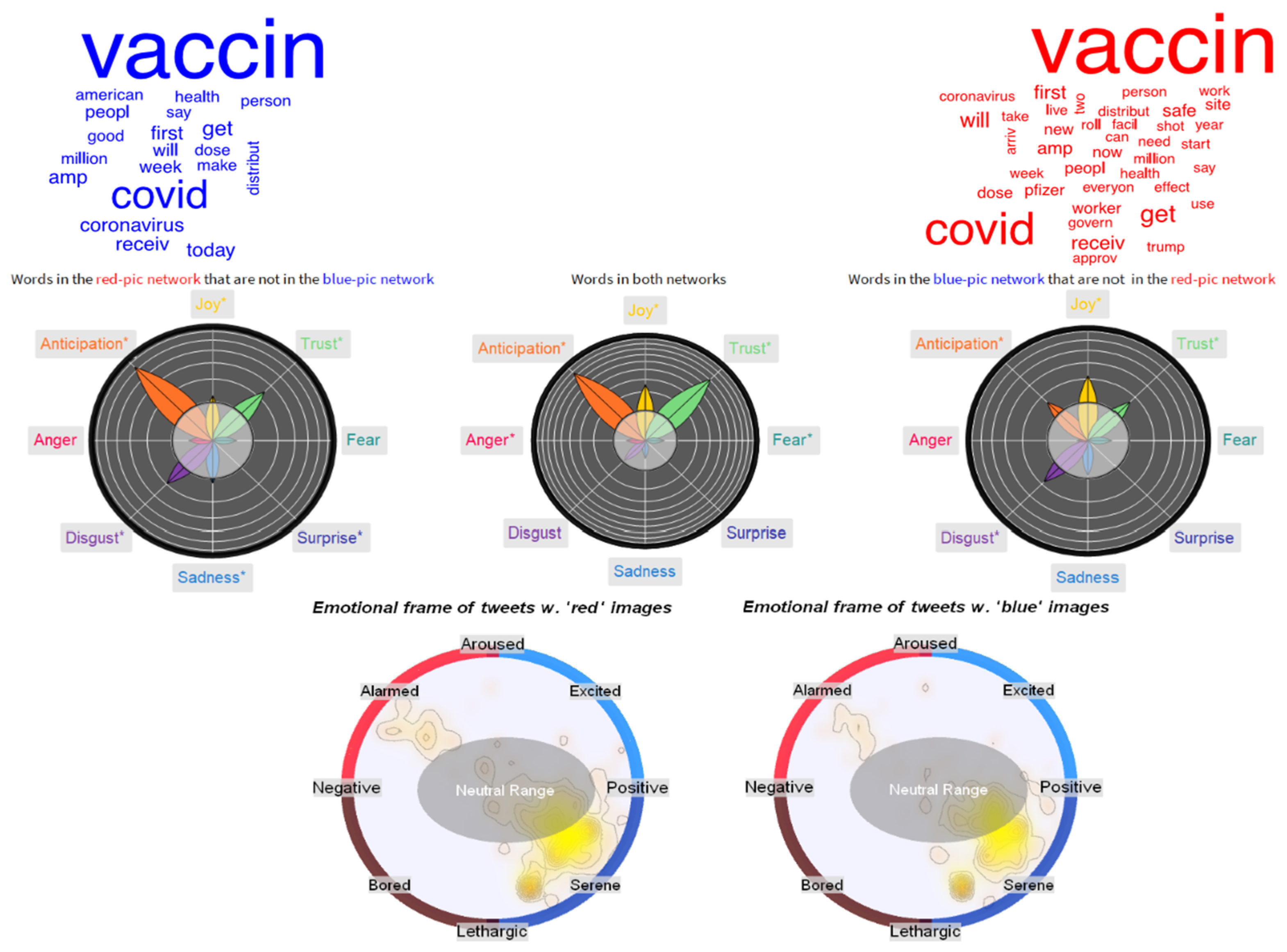
3.4. Aftermath of AstraZeneca’s Suspension: Loss of Trust in the Italian Twittersphere
4. Discussion
Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
References
- Stella, M.; Ferrara, E.; De Domenico, M. Bots increase exposure to negative and inflammatory content in online social systems. Proc. Natl. Acad. Sci. USA 2018, 115, 12435–12440. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mehler, A.; Gleim, R.; Gaitsch, R.; Hemati, W.; Uslu, T. From topic networks to distributed cog-nitive maps: Zipfian topic universes in the area of volunteered geographic information. arXiv 2020, arXiv:2002.01454. [Google Scholar]
- Bovet, A.; Morone, F.; Makse, H.A. Validation of Twitter opinion trends with national polling aggregates: Hillary Clinton vs. Donald Trump. Sci. Rep. 2018, 8, 8673. [Google Scholar] [CrossRef] [PubMed]
- Bessi, A.; Ferrara, E. Social bots distort the 2016 U.S. Presidential election online discussion. First Monday 2016, 21, 7090. [Google Scholar] [CrossRef]
- Ferrara, E.; Yang, Z. Quantifying the effect of sentiment on information diffusion in social media. PeerJ Comput. Sci. 2015, 1, e26. [Google Scholar] [CrossRef] [Green Version]
- González-Bailón, S.; De Domenico, M. Bots are less central than verified accounts during contentious political events. Proc. Natl. Acad. Sci. USA 2021, 118, e2013443118. [Google Scholar] [CrossRef]
- Onur, V.; Ismail, U. Journalists on Twitter: Self-branding, audiences, and involvement of bots. J. Comput. Soc. Sci. 2020, 3, 83–101. [Google Scholar]
- Stella, M. Cognitive Network Science for Understanding Online Social Cognitions: A Brief Review. Top. Cogn. Sci. 2021, 14, 143–162. [Google Scholar] [CrossRef]
- Vitevitch, M. Can network science connect mind, brain, and behavior. Netw. Sci. Cogn. Psychol. 2019, 26, 184. [Google Scholar]
- Hills, T.T. The Dark Side of Information Proliferation. Perspect. Psychol. Sci. 2019, 14, 323–330. [Google Scholar] [CrossRef]
- Saif, M.M.; Turney, P.D. Emotions evoked by common words and phrases: Using mechanical turk to create an emotion lexicon. In Proceedings of the NAACL HLT 2010 Workshop on Computational Approaches to Analysis and Generation of Emotion in Text, 26–34, Los Angeles, CA, USA, 10 June 2010; Association for Computational Linguistics: Los Angeles, CA, USA, 2010. [Google Scholar]
- Fillmore, C.J. Frame semantics. Cogn. Linguist. Basic Read 2006, 34, 373–400. [Google Scholar]
- Dyer, J.; Kolic, B. Public risk perception and emotion on Twitter during the COVID-19 pandemic. Appl. Netw. Sci. 2020, 5, 99. [Google Scholar] [CrossRef] [PubMed]
- Yang, S.; Jiang, J.; Pal, A.; Yu, K.; Chen, F.; Yu, S. Analysis and Insights for Myths Circulating on Twitter During the COVID-19 Pandemic. IEEE Open J. Comput. Soc. 2020, 1, 209–219. [Google Scholar] [CrossRef]
- Stella, M.; Restocchi, V.; De Deyne, S. #lockdown: Network-Enhanced Emotional Profiling in the Time of COVID-19. Big Data Cogn. Comput. 2020, 4, 14. [Google Scholar] [CrossRef]
- Pierri, F.; Tocchetti, A.; Corti, L.; di Giovanni, M.; Pavanetto, S.; Brambilla, M.; Ceri, S. Vaccinitaly: Monitoring Italian conversations around vaccines on Twitter and Facebook. arXiv 2021, arXiv:2101.03757. [Google Scholar]
- Siew, C.S.Q.; Wulff, D.U.; Beckage, N.M.; Kenett, Y.N.; Meštrović, A. Cognitive Network Science: A Review of Research on Cognition through the Lens of Network Representations, Processes, and Dynamics. Complexity 2019, 2019, 2108423. [Google Scholar] [CrossRef]
- Stella, M.; De Nigris, S.; Aloric, A.; Siew, C.S.Q. Forma mentis networks quantify crucial differences in STEM perception between students and experts. PLoS ONE 2019, 14, e0222870. [Google Scholar] [CrossRef] [Green Version]
- Fiorillo, A.; Sampogna, G.; Giallonardo, V.; Del Vecchio, V.; Luciano, M.; Albert, U.; Carmassi, C.; Carrà, G.; Cirulli, F.; Dell’Osso, B.; et al. Effects of the lockdown on the mental health of the general population during the COVID-19 pandemic in Italy: Results from the COMET collaborative network. Eur. Psychiatry 2020, 63, E87. [Google Scholar] [CrossRef]
- Aiello, L.M.; Quercia, D.; Zhou, K.; Constantinides, M.; Šćepanović, S.; Joglekar, S. How epidemic psychology works on Twitter: Evolution of responses to the COVID-19 pandemic in the U.S. Humanit. Soc. Sci. Commun. 2021, 8, 179. [Google Scholar] [CrossRef]
- Jagiello, R.D.; Hills, T.T. Bad News Has Wings: Dread Risk Mediates Social Amplification in Risk Communication. Risk Anal. 2018, 38, 2193–2207. [Google Scholar] [CrossRef]
- Kalimeri, K.; Beiró, M.G.; Urbinati, A.; Bonanomi, A.; Rosina, A.; Cattuto, C. Human Values and Attitudes towards Vaccination in Social Media. In Proceedings of the 2019 World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 248–254. [Google Scholar] [CrossRef] [Green Version]
- Mazzuca, C.; Falcinelli, I.; Michalland, A.H.; Tummolini, L.; Borghi, A.M. Differences and similarities in the conceptualization of COVID-19 and other diseases in the first Italian lockdown. Sci. Rep. 2021, 11, 18303. [Google Scholar] [CrossRef] [PubMed]
- Montefinese, M.; Ambrosini, E.; Angrilli, A. Online search trends and word-related emotional response during COVID-19 lockdown in Italy: A cross-sectional online study. PeerJ 2021, 9, e11858. [Google Scholar] [CrossRef] [PubMed]
- Dilek, K.; Fazli, C. Stance detection: A survey. ACM Comput. Surv. (CSUR) 2020, 53, 1–37. [Google Scholar]
- Saif, M.M. Sentiment analysis: Detecting valence, emotions, and other affectual states from text. In Emotion Measurement; Elsevier: Amsterdam, The Netherlands, 2016; pp. 201–237. [Google Scholar]
- de Arruda, H.F.; Marinho, V.Q.; Costa, L.D.F.; Amancio, D.R. Paragraph-based representation of texts: A complex networks approach. Inf. Process. Manag. 2019, 56, 479–494. [Google Scholar] [CrossRef] [Green Version]
- Amancio, D.R. Probing the Topological Properties of Complex Networks Modeling Short Written Texts. PLoS ONE 2015, 10, e0118394. [Google Scholar] [CrossRef]
- Stella, M. Text-mining forma mentis networks reconstruct public perception of the STEM gender gap in social media. PeerJ Comput. Sci. 2020, 6, e295. [Google Scholar] [CrossRef]
- Stella, M.; Zaytseva, A. Forma mentis networks map how nursing and engineering students enhance their mindsets about innovation and health during professional growth. PeerJ Comput. Sci. 2020, 6, e255. [Google Scholar] [CrossRef] [Green Version]
- Carley, K.M. Coding Choices for Textual Analysis: A Comparison of Content Analysis and Map Analysis. Sociol. Methodol. 1993, 23, 75. [Google Scholar] [CrossRef]
- Carley, K.M. Extracting team mental models through textual analysis. J. Organ. Behav. 1997, 18, 533–558. [Google Scholar] [CrossRef]
- Yazdavar, A.H.; Mahdavinejad, M.S.; Bajaj, G.; Romine, W.; Monadjemi, A.; Thirunarayan, K.; Sheth, A.; Pathak, J. Fusing visual, textual and connectivity clues for studying mental health. arXiv 2019, arXiv:1902.06843. [Google Scholar]
- Comito, C. How COVID-19 information spread in US The Role of Twitter as Early Indicator of Epidemics. IEEE Trans. Serv. Comput. 2021. [Google Scholar] [CrossRef]
- Comito, C.; Pizzuti, C. Artificial intelligence for forecasting and diagnosing COVID-19 pandemic: A focused review. Artif. Intell. Med. 2022, 128, 102286. [Google Scholar] [CrossRef] [PubMed]
- Steinert, J.I.; Sternberg, H.; Prince, H.; Fasolo, B.; Galizzi, M.M.; Büthe, T.; Veltri, G.A. COVID-19 vaccine hesitancy in eight Eu-ropean countries: Prevalence, determinants, and heterogeneity. Sci Adv. 2022, 29, eabm9825. [Google Scholar] [CrossRef]
- Briand, S.C.; Cinelli, M.; Nguyen, T.; Lewis, R.; Prybylski, D.; Valensise, C.M.; Colizza, V.; Tozzi, A.E.; Perra, N.; Baronchelli, A.; et al. Infodemics: A new challenge for public health. Cell 2021, 184, 6010–6014. [Google Scholar] [CrossRef] [PubMed]
- Ulhaq, A.; Born, J.; Khan, A.; Gomes, D.P.S.; Chakraborty, S.; Paul, M. COVID-19 control by computer vision approaches: A. survey. IEEE Access 2020, 8, 179437–179456. [Google Scholar] [CrossRef] [PubMed]
- Schmidt, A.L.; Peruzzi, A.; Scala, A.; Cinelli, M.; Pomerantsev, P.; Applebaum, A.; Gaston, S.; Fusi, N.; Peterson, Z.; Severgnini, G.; et al. Measuring social response to different journalistic techniques on Facebook. Humanit. Soc. Sci. Commun. 2020, 7, 17. [Google Scholar] [CrossRef]
- Martinelli, M.; Veltri, G.A. Do cognitive styles affect vaccine hesitancy? A dual-process cognitive framework for vaccine hesitancy and the role of risk perceptions. Soc. Sci. Med. 2021, 289, 114403. [Google Scholar] [CrossRef]
- Rossetti, G.; Milli, L.; Citraro, S.; Morini, V. UTLDR: An agent-based framework for modeling infectious diseases and public interventions. J. Intell. Inf. Syst. 2021, 57, 347–368. [Google Scholar] [CrossRef]
- Dóczi, B. An Overview of Conceptual Models and Theories of Lexical Representation in the Mental Lexicon. In The Routledge Handbook of Vocabulary Studies; Routledge: London, UK, 2019; pp. 46–65. [Google Scholar] [CrossRef]
- Miller, G.A. WordNet: An Electronic Lexical Database; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Warriner, A.B.; Kuperman, K.; Brysbaert, M. Norms of valence, arousal, and dominance for 13,915 english lemmas. Behav. Res. Methods 2013, 45, 1191–1207. [Google Scholar] [CrossRef] [Green Version]
- Posner, J.; Russell, J.A.; Peterson, B.S. The circumplex model of affect: An integrative approach to affective neuroscience, cognitive development, and psychopathology. Dev. Psychopathol. 2005, 17, 715–734. [Google Scholar] [CrossRef]
- Ekman, P.E.; Davidson, R.J. The Nature of Emotion: Fundamental Questions; Oxford University Press: Oxford, UK, 1994. [Google Scholar]
- Deng, J.; Guo, J.; Ververas, E.; Kotsia, I.; Zafeiriou, S. Retinaface: Single-stage dense face localisation in the wild. arXiv 2019, arXiv:1905.00641. [Google Scholar]
- Reece, A.G.; Danforth, C.M. Instagram photos reveal predictive markers of depression. EPJ Data Sci. 2017, 6, 15. [Google Scholar] [CrossRef] [Green Version]
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 2018, P10008. [Google Scholar] [CrossRef] [Green Version]
- Murphy, J.; Vallières, F.; Bentall, R.P.; Shevlin, M.; McBride, O.; Hartman, T.K.; McKay, R.; Bennett, K.; Mason, L.; Gibson-Miller, J.; et al. Psychological characteristics associated with covid-19 vaccine hesitancy and resistance in Ireland and the United kingdom. Nat. Commun. 2021, 12, 1. [Google Scholar] [CrossRef]
- Radicioni, T.; Squartini, T.; Pavan, E.; Saracco, F. Networked partisanship and framing: A socio-semantic network analysis of the Italian debate on migration. arXiv 2021, arXiv:2103.04653. [Google Scholar] [CrossRef] [PubMed]
- Perra, N. Non-pharmaceutical interventions during the COVID-19 pandemic: A review. Phys. Rep. 2021, 913, 1–52. [Google Scholar] [CrossRef]
- Featherstone, J.D.; Zhang, J. Feeling angry: The effects of vaccine misinformation and refutational messages on negative emotions and vaccination attitude. J. Health Commun. 2020, 25, 692–702. [Google Scholar] [CrossRef]
- Vilella, S.; Semeraro, A.; Paolotti, D.; Ruffo, G. The Impact of Disinformation on a Controversial Debate on Social Media. arXiv 2021, arXiv:2106.15968. [Google Scholar]
- Semeraro, A.; Vilella, S.; Ruffo, G.; Stella, M. Writing about COVID-19 vaccines: Emotional profiling unravels how mainstream and alternative press framed AstraZeneca, Pfizer and vaccination campaigns. arXiv 2022, arXiv:2201.07538. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rank | Degree | Frequency | Rank | Degree | Frequency |
|---|---|---|---|---|---|
| 1 | vaccine | vaccine | 1 | vaccino | vaccino |
| 2 | will | we | 2 | prima (first) | dose |
| 3 | get | COVID | 3 | dose | contro (against) |
| 4 | people | will | 4 | stato (state) | più (plus) |
| 5 | dose | get | 5 | tutti (all) | COVID |
| 6 | take | people | 6 | contro (against) | prima (first) |
| 7 | say | first | 7 | fatto (fact) | Pfizer |
| 8 | receive | now | 8 | chi (who) | Italia |
| 9 | first | all | 9 | persona (person) | tutti (all) |
| 10 | new | dose | 10 | casi (cases) | tempo (time) |
| 11 | make | take | 11 | dati (data) | Moderna |
| 12 | trump | coronavirus | 12 | virus | fatto (fact) |
| 13 | govern | million | 13 | medico (doctor) | solo (only) |
| 14 | out | when | 14 | tempo (time) | virus |
| 15 | worker | new | 15 | prendere (take) | ora (now/hour) |
| 16 | distribute | need | 16 | parte (part) | giorno (day) |
| 17 | work | 17 | morti (deaths) | ansa | |
| 18 | million | after | 18 | paese (country) | oggi (today) |
| 19 | week | rollout | 19 | passare (transit) | dati (data) |
| 20 | need | virus | 20 | arrivare (arrive) | effetti (effects) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stella, M.; Vitevitch, M.S.; Botta, F. Cognitive Networks Extract Insights on COVID-19 Vaccines from English and Italian Popular Tweets: Anticipation, Logistics, Conspiracy and Loss of Trust. Big Data Cogn. Comput. 2022, 6, 52. https://doi.org/10.3390/bdcc6020052
Stella M, Vitevitch MS, Botta F. Cognitive Networks Extract Insights on COVID-19 Vaccines from English and Italian Popular Tweets: Anticipation, Logistics, Conspiracy and Loss of Trust. Big Data and Cognitive Computing. 2022; 6(2):52. https://doi.org/10.3390/bdcc6020052
Chicago/Turabian StyleStella, Massimo, Michael S. Vitevitch, and Federico Botta. 2022. "Cognitive Networks Extract Insights on COVID-19 Vaccines from English and Italian Popular Tweets: Anticipation, Logistics, Conspiracy and Loss of Trust" Big Data and Cognitive Computing 6, no. 2: 52. https://doi.org/10.3390/bdcc6020052
APA StyleStella, M., Vitevitch, M. S., & Botta, F. (2022). Cognitive Networks Extract Insights on COVID-19 Vaccines from English and Italian Popular Tweets: Anticipation, Logistics, Conspiracy and Loss of Trust. Big Data and Cognitive Computing, 6(2), 52. https://doi.org/10.3390/bdcc6020052