4.4.1. Data Analysis
Figure 8,
Figure 9 and
Figure 10 depict a high-level overview of the system metrics and their usage by server. These system metrics, illustrated in
Figure 8,
Figure 9 and
Figure 10, were chosen based on their mean and standard deviation values; three from SMART metrics and three from others system metrics. The overview of system metrics in
Figure 8,
Figure 9 and
Figure 10 provides an analysis by the server. The analysis based on the server is taken into account in order to comprehend the server’s resource utilisation. This is because our study is devoted to predicting server failures. In all the figures, we present the hashed server information in a numeric format. This is done to aid in visualisation.
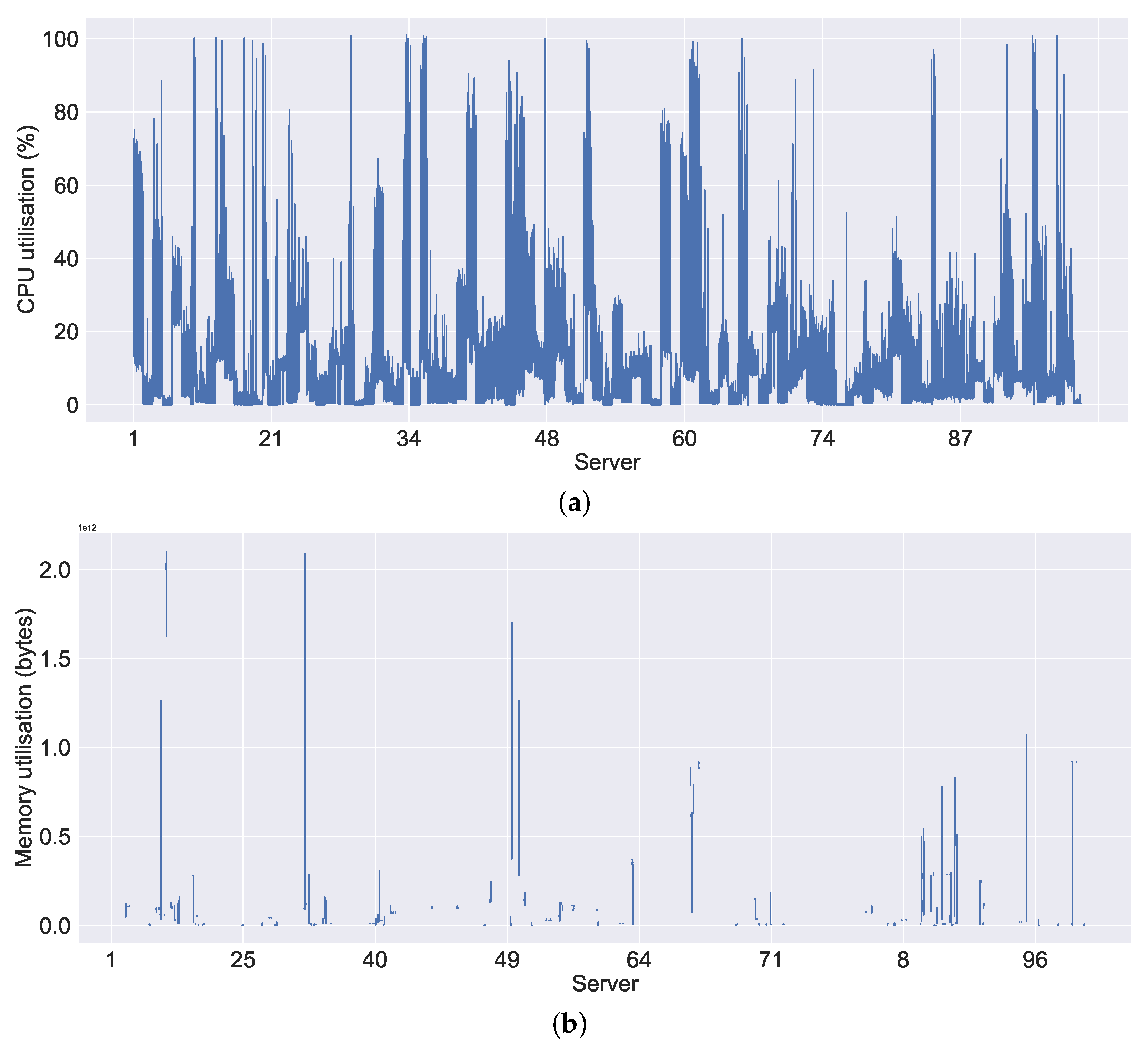
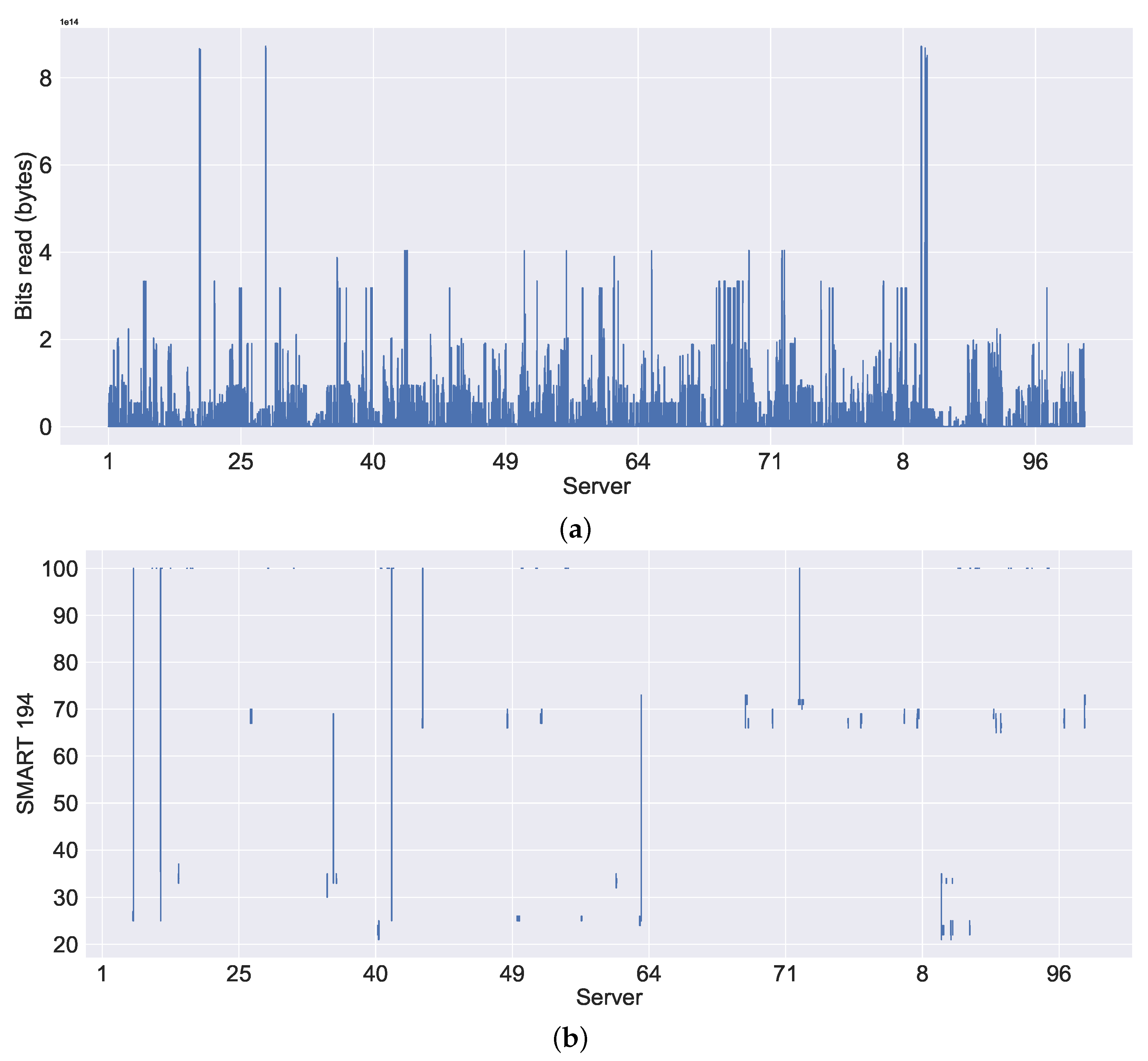
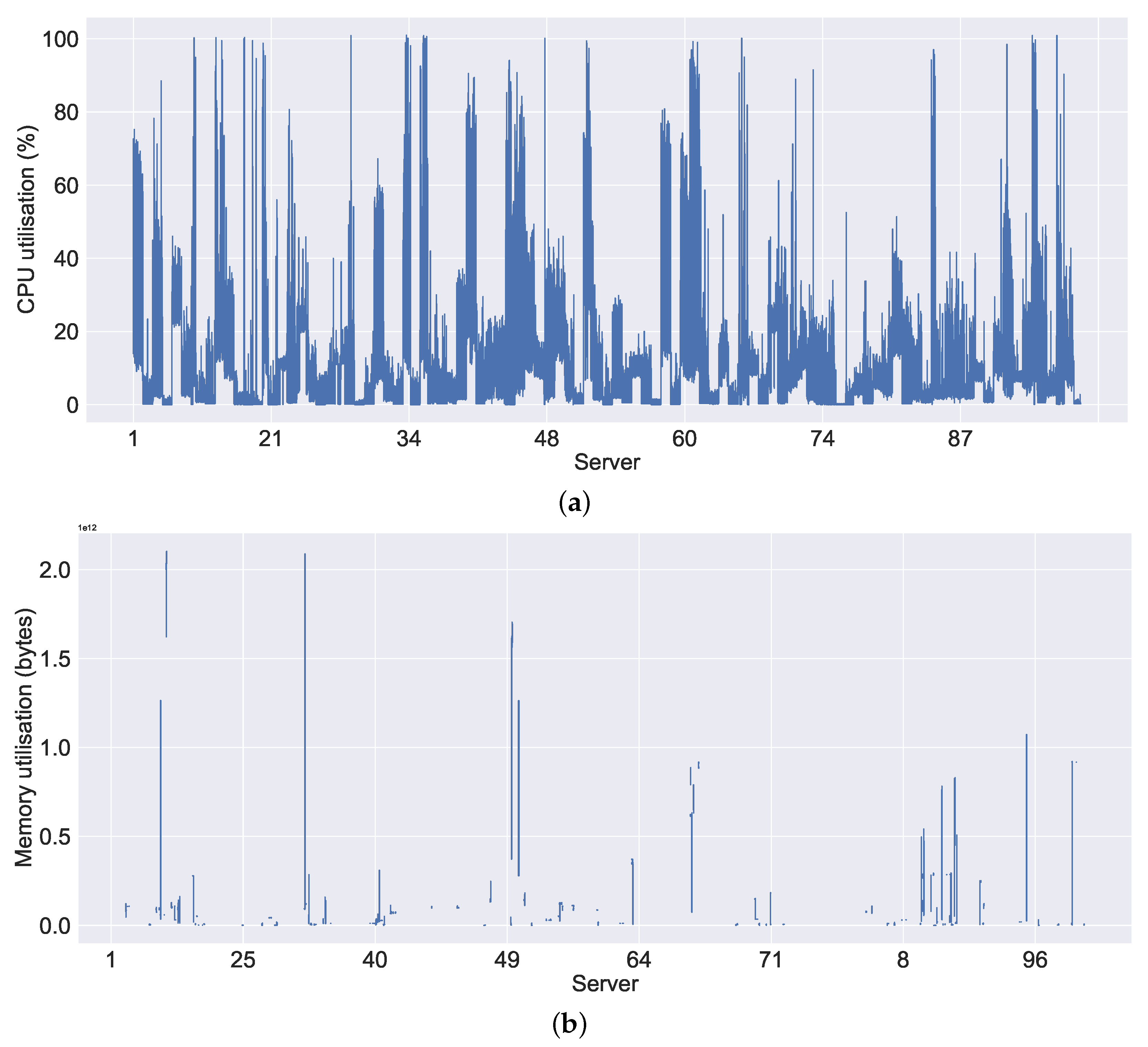
Figure 8a shows the CPU utilisation, where we considered only the CPU utilisation within the non-failure threshold (see
Section 3.3). This is because of the observed high difference, which we present later in the cumulative distribution function (CDF) report. As shown in
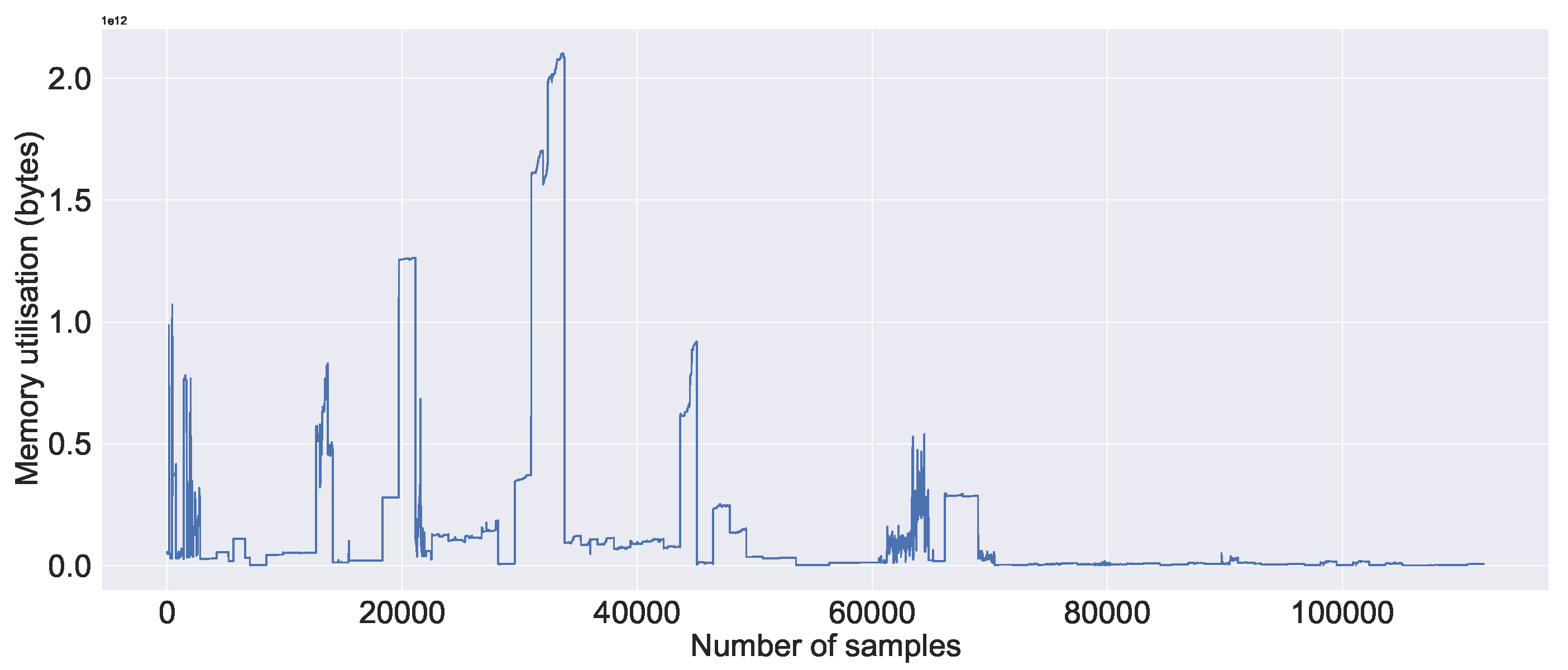
Figure 8a, we can observe the high CPU usage on all servers in general compared to the memory usage, which is shown in
Figure 8b. In most cases, the servers are not making extensive use of the memory compared to the CPU. We can observe a similar pattern to that in memory usage in the system metrics bits read in
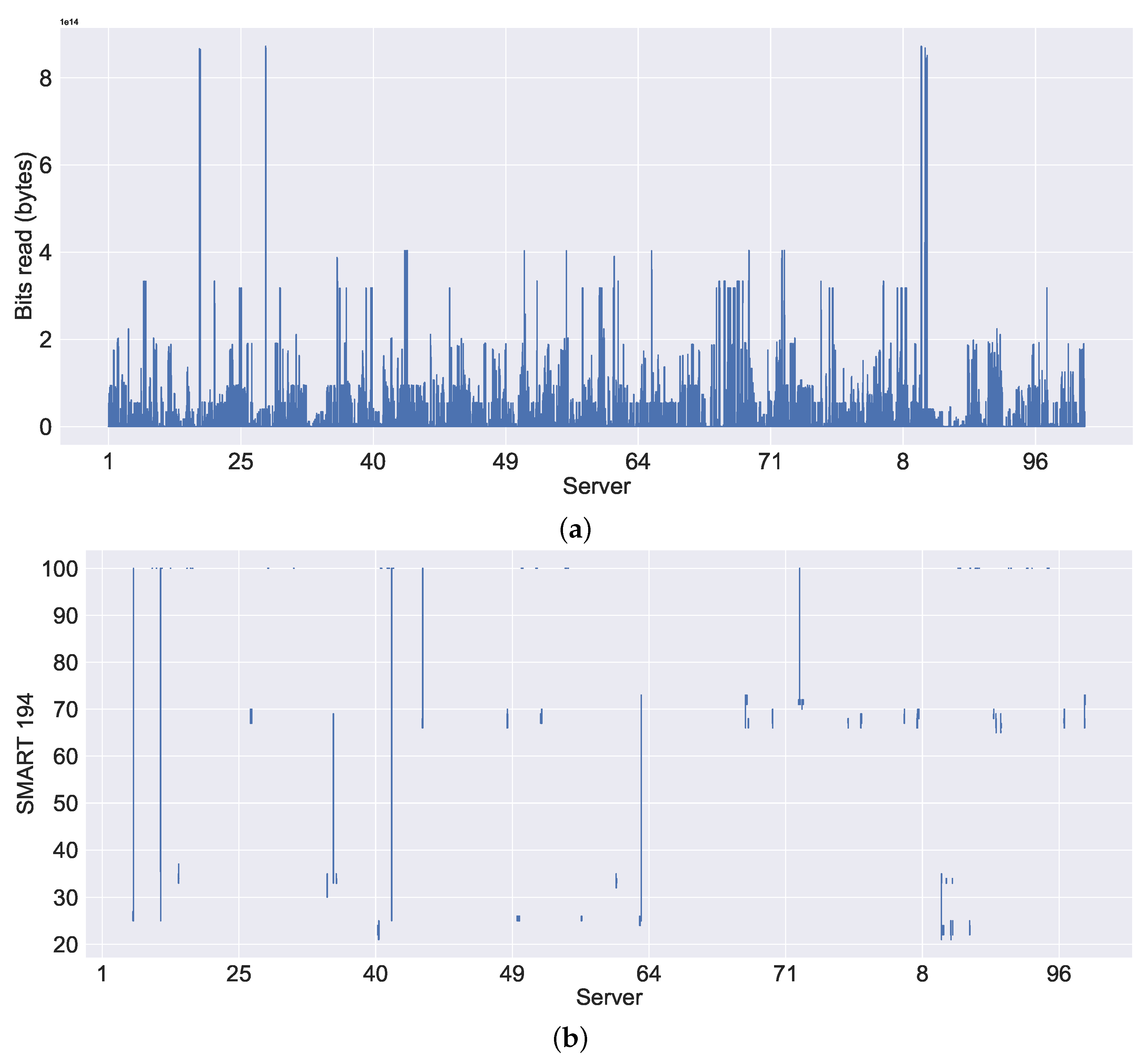
Figure 9a. Moreover, we can also observe some gaps (or disconnections) in
Figure 8b. This is because of the empty (or NaN) values, which could be either that the data were not available during the data collection (i.e., downloading) or that the values were missing (i.e., they were not recorded properly by the server). Similarly,
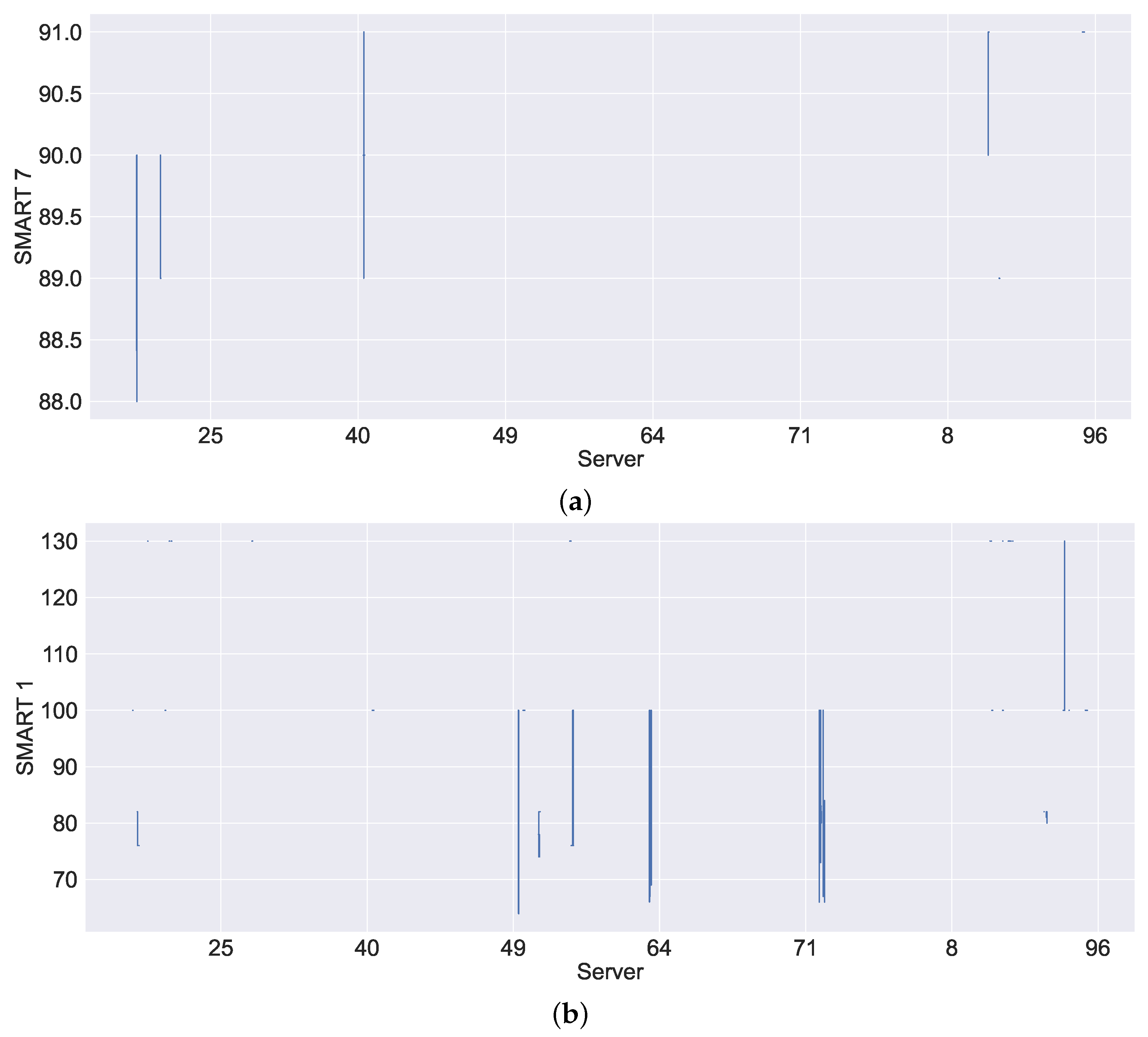
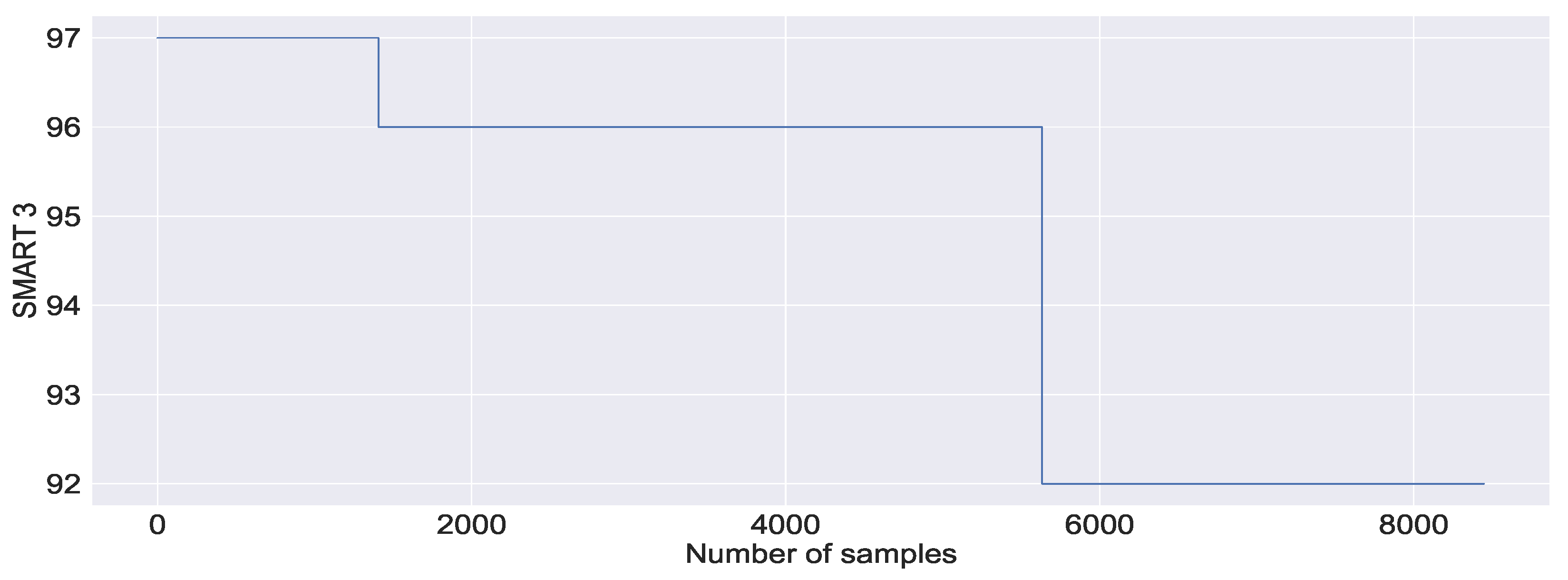
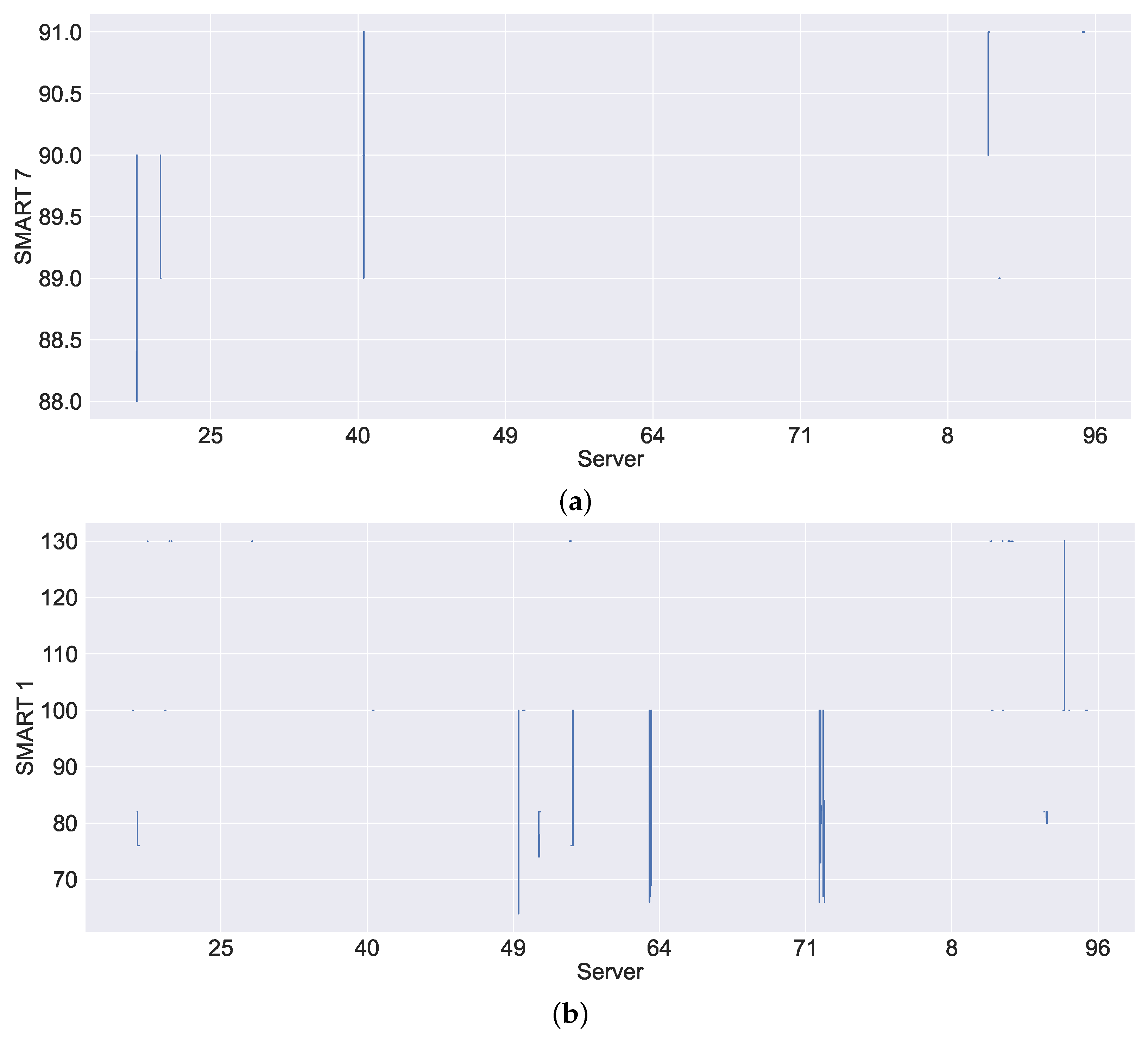
Figure 10a,b shows the visualisation of SMART 7 and SMART 1 system metrics, which monitor the state of the hard drive. In
Figure 10a,b, we can observe similar patterns of disconnections to memory utilisation, resulting in NaNs.
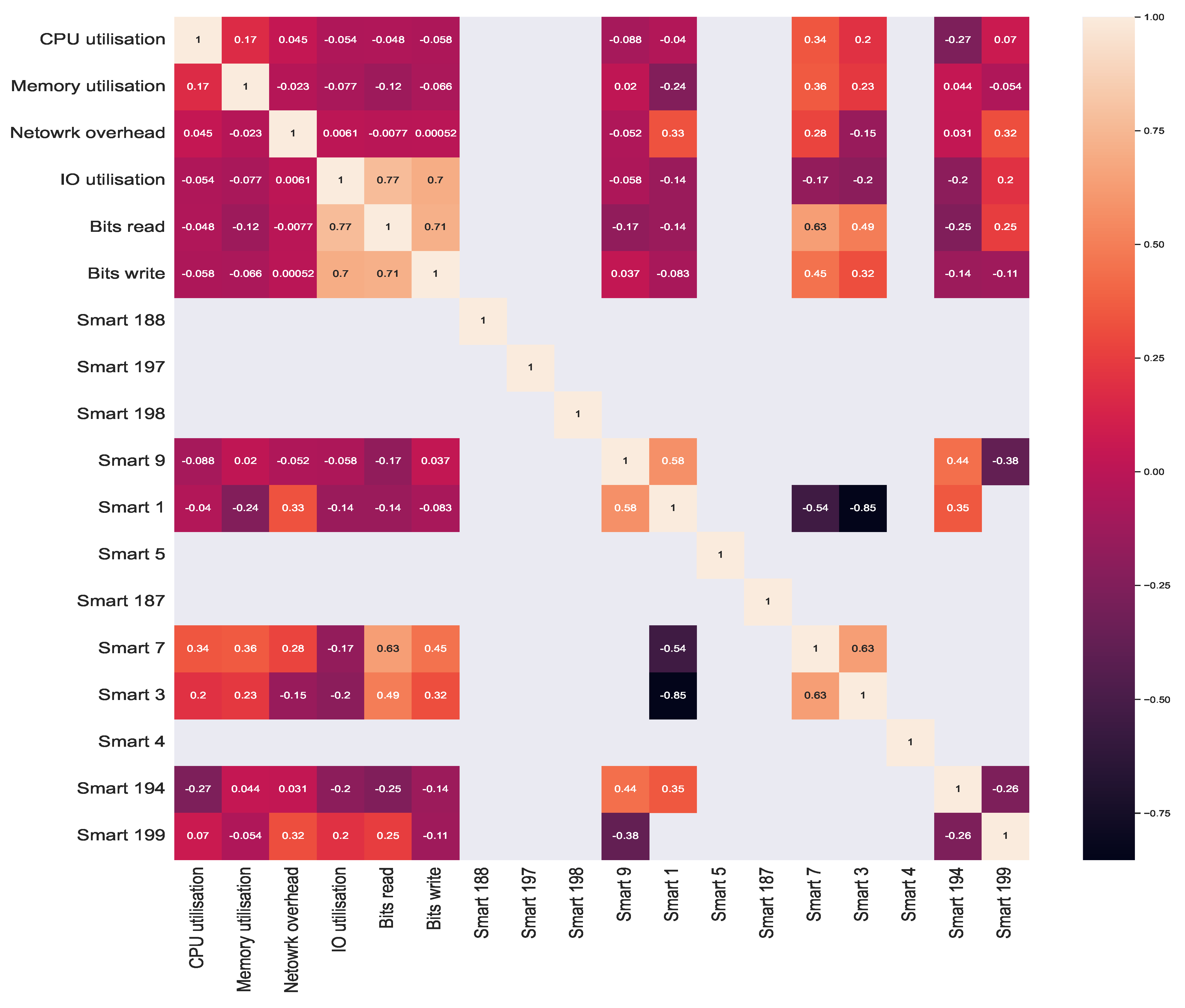
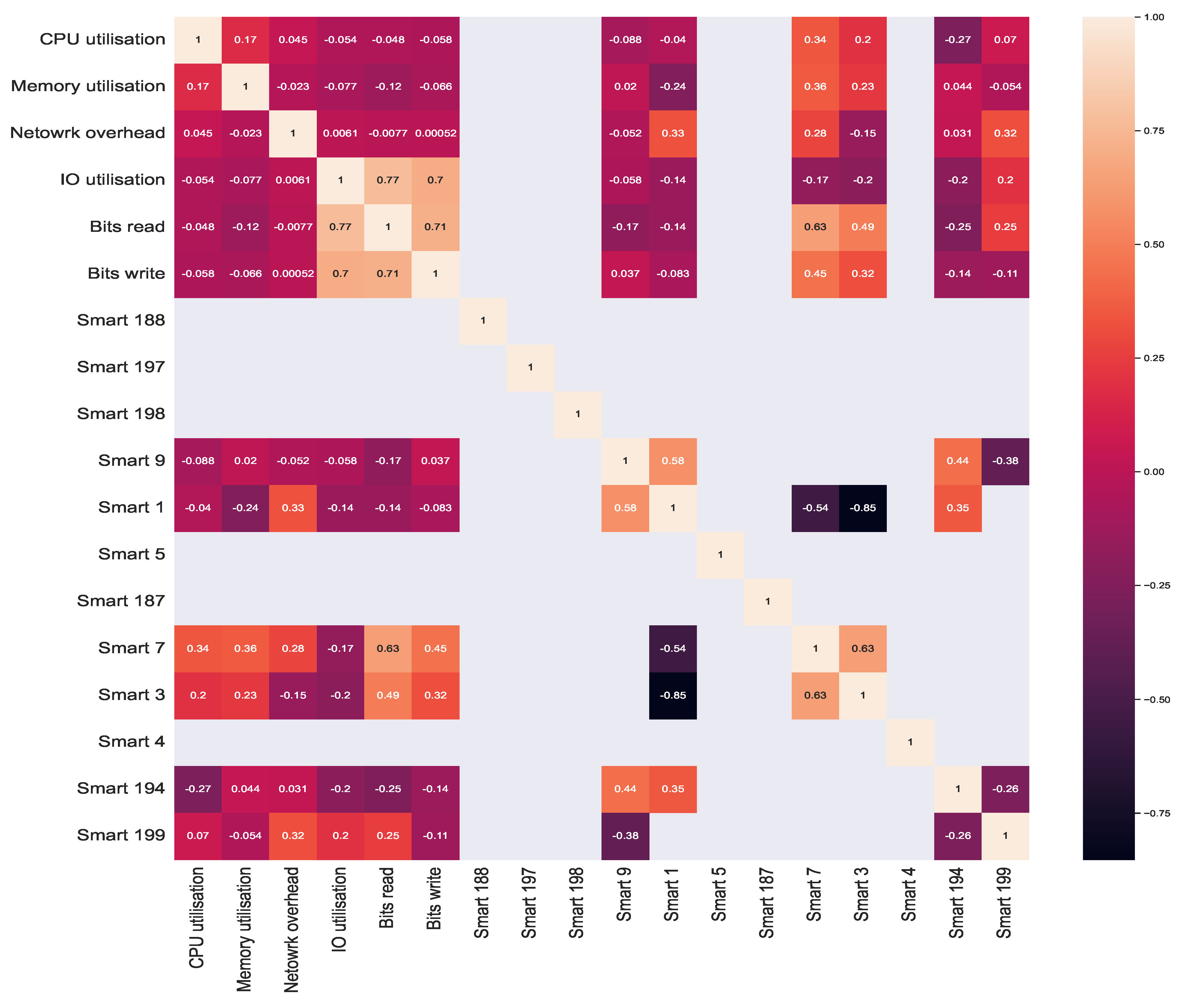
In addition, we performed a correlation analysis to better understand the relationships between the system metrics, providing for the first time a correlation analysis between the SMART system metrics and other system metrics. We used Kendall’s tau correlation coefficients for the correlation analysis. Kendall’s tau correlations for the system metrics are visualised in
Figure 11. Kendall’s tau was chosen due to its mechanism of operation, which is based on comparing the rankings of values in two random variables, rather than comparing the values themselves [
95]. Additionally, other correlation coefficients, such as the Pearson correlation coefficient, were not considered because they are only useful when the data are normally distributed [
95]. In
Figure 11, a correlation factor of 1.0 indicates a positive relationship, a factor of close to −1.0 indicates a negative relationship, and factors of 0.0 or empty values indicate that there is no correlation (i.e., no relationships).
The first observation we make is that there is a positive correlation between CPU and memory utilisation, a finding that is consistent with that of Shen et al. [
96]. As with CPU and memory usage, a strong positive correlation exists between the system metrics of bits read, bits write, and IO utilisation, with a correlation factor greater than 0.7 (or 70 percent). Additionally, we observe a high correlation between the SMART 7 system metrics and other system metrics, such as bits read and bits write with a correlation factor of 0.63 for bits read and 0.45 for bits write. This relationship between SMART 7 and bits read and bits write corresponds to the functionality of SMART 7, which monitors the hard drive’s seek error rate. The other observation is that the correlations between SMART 7 and CPU and memory utilisation are also positive, with a correlation factor of 0.34 for CPU and 0.36 for memory utilisation. Similar to SMART 7, SMART 1 correlates positively with network overhead, as does SMART 3, which monitors the hard drive spin up time with bits read and bits write. Because both the bits read and bits write correspond to the hard drive, the correlation is logical, while the correlation between other SMART metrics and system metrics, such as memory utilisation, is either very low, negative, or non-existent. This observation, on the other hand, is consistent with our expectations. The reason for this is that SMART metrics track the state of the hard drive, as opposed to system metrics, such as memory usage and network overhead. In the case of SMART metrics, we can observe a high correlation between SMART 1 and SMART 9 and SMART 7 and SMART 3, with correlation factors of 0.58 and 0.63, respectively. The correlation between the remaining SMART metrics is very low or non-existent, similar to the correlation between SMART metrics and other system metrics.
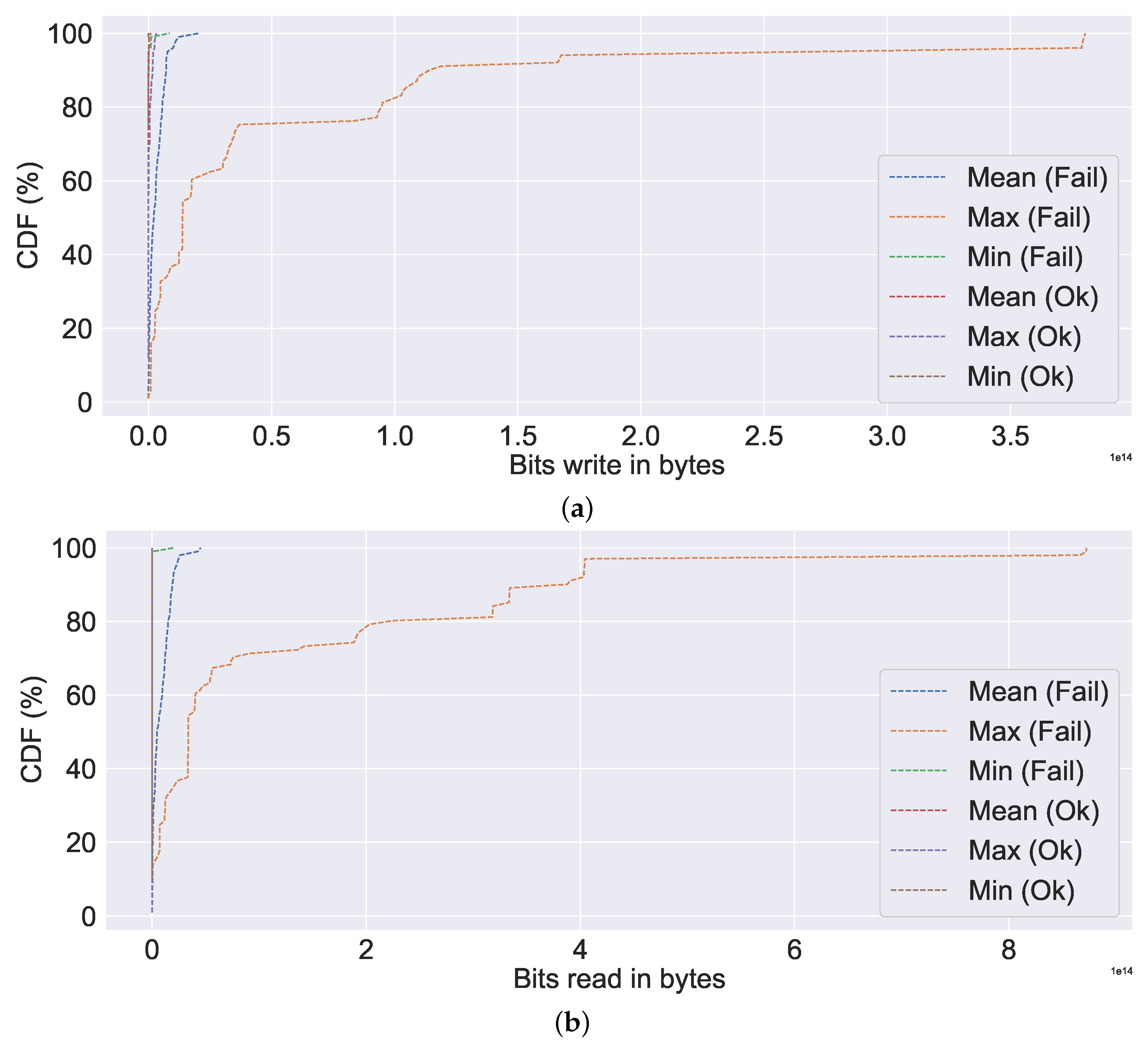
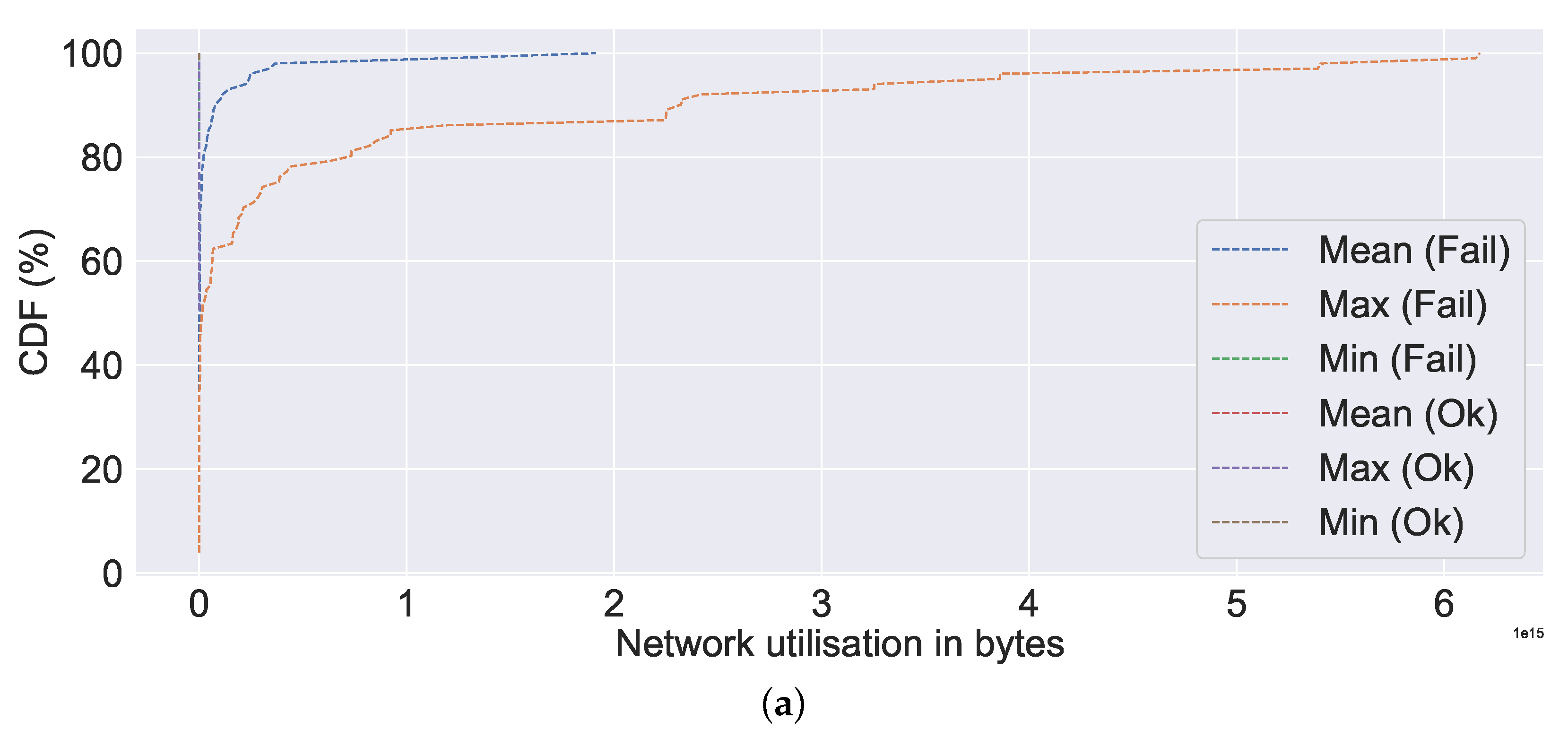
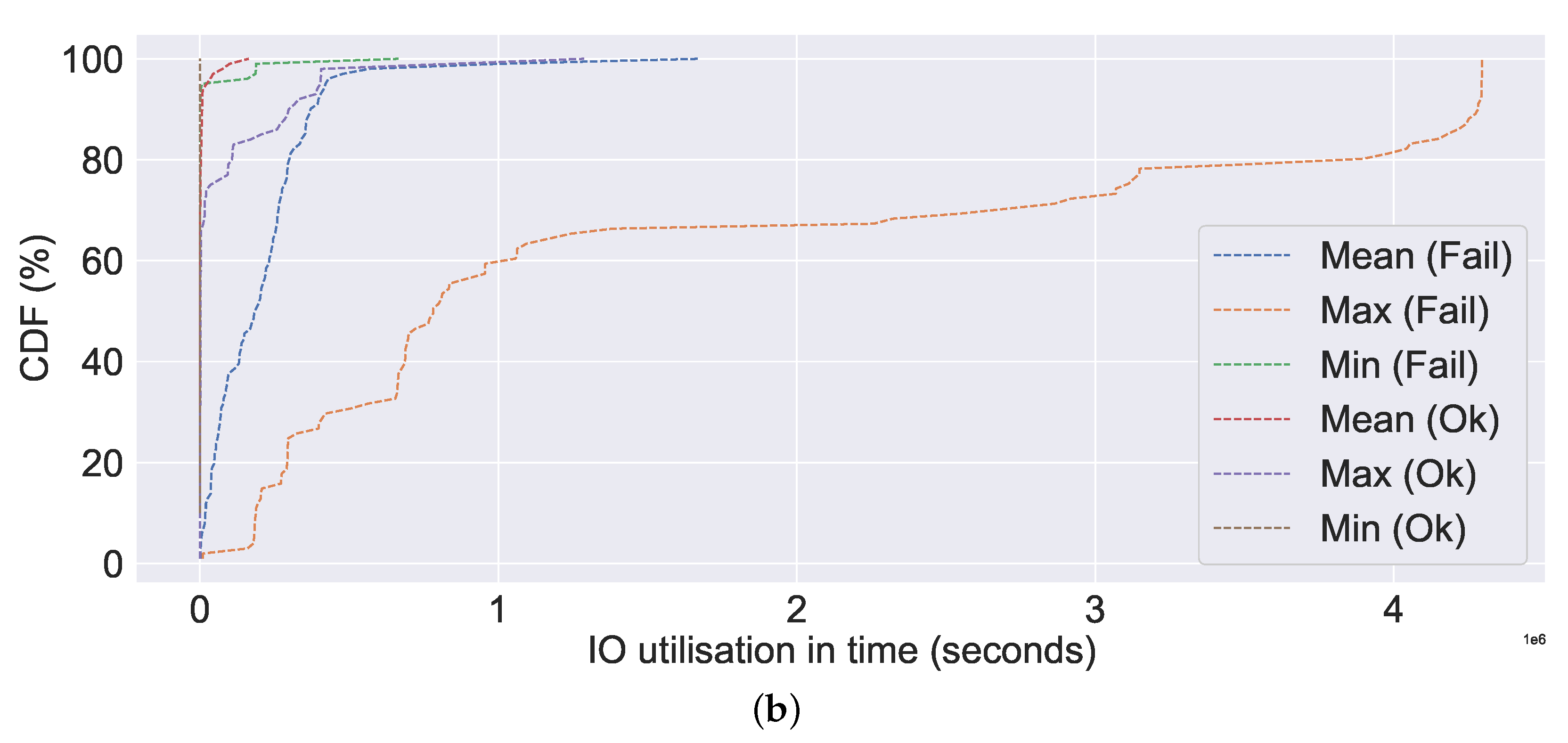
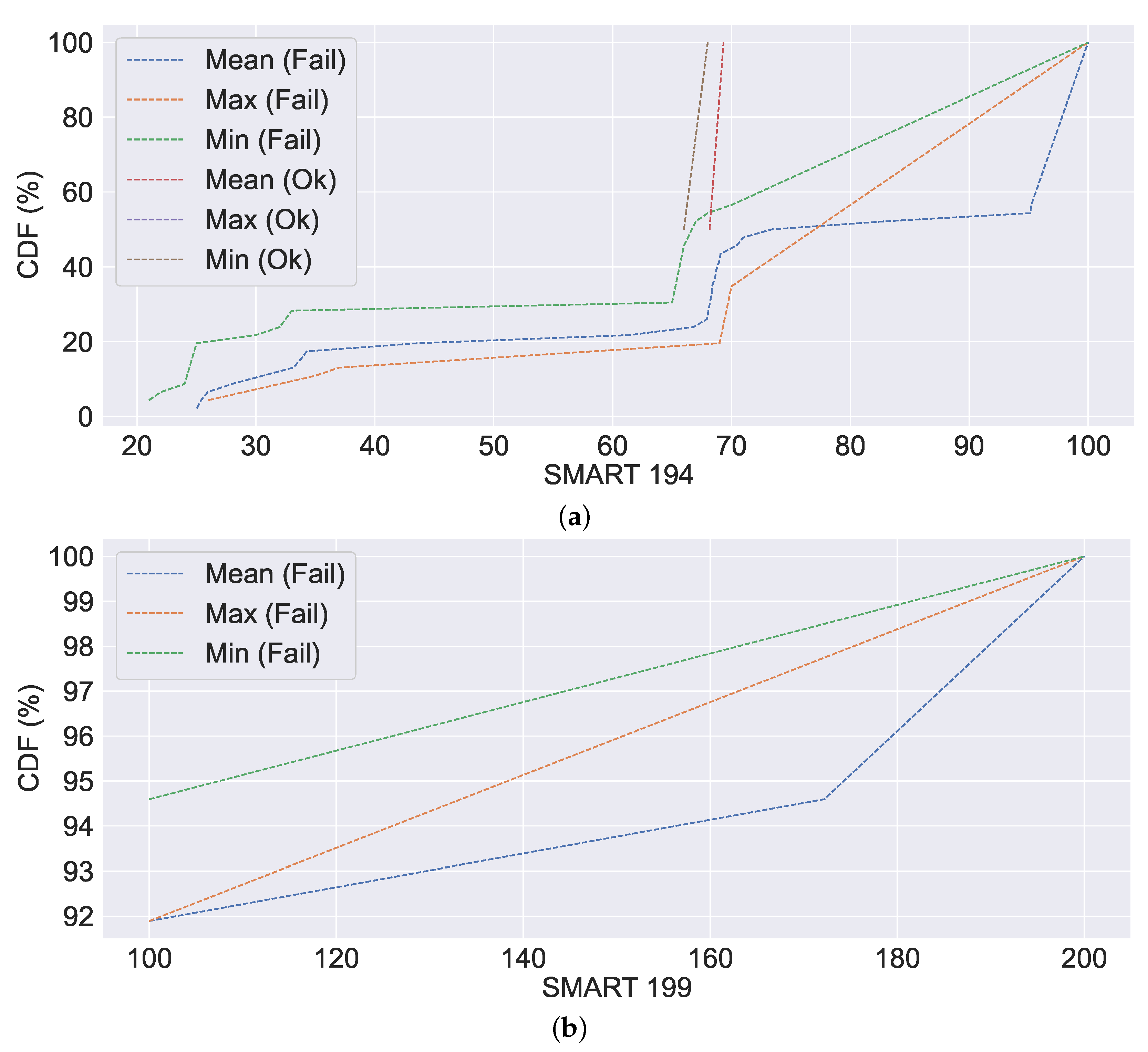
Apart from performing a correlation analysis between system metrics and generating an overview of system metrics, we also computed the CDF of the system metrics.
Figure 12,
Figure 13,
Figure 14 and
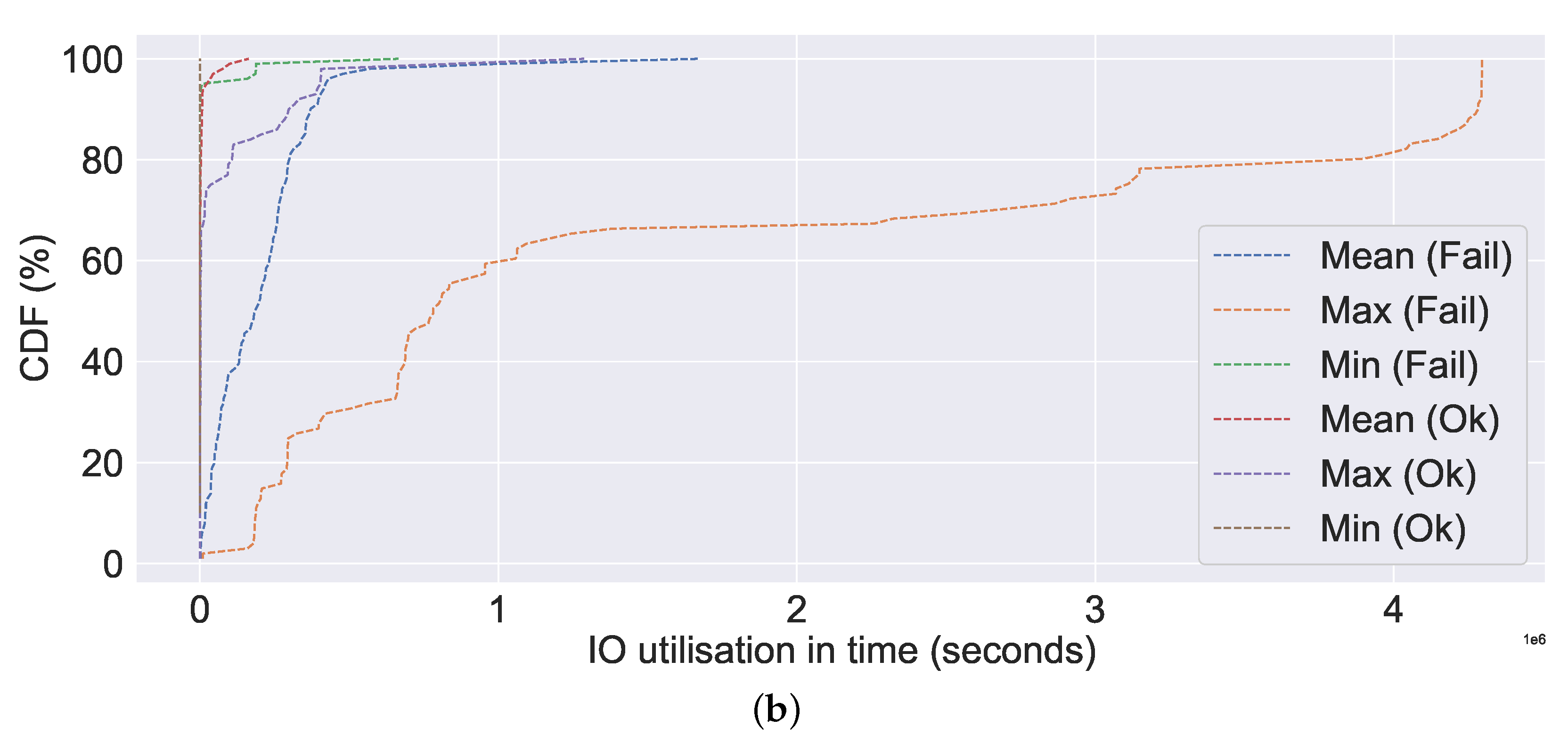
Figure 15 show the CDF visualisation of the system metrics, which were selected based on their standard deviation value (high), similar to the selection of system metrics for overview analysis. In contrast to previous analyses, such as the overview of system metrics, which focused on the server, the CDF analysis focuses on failures (or non-failures). Further, we omit system metrics with a standard deviation of zero from our CDF analysis, as this indicates that the data are centred around the mean (i.e., there is no spread). The CDF analysis summarises the mean, maximum (or max), and minimum (or min) distributions of values, which are then classified according to their failure characteristics (i.e., failure or non-failure).
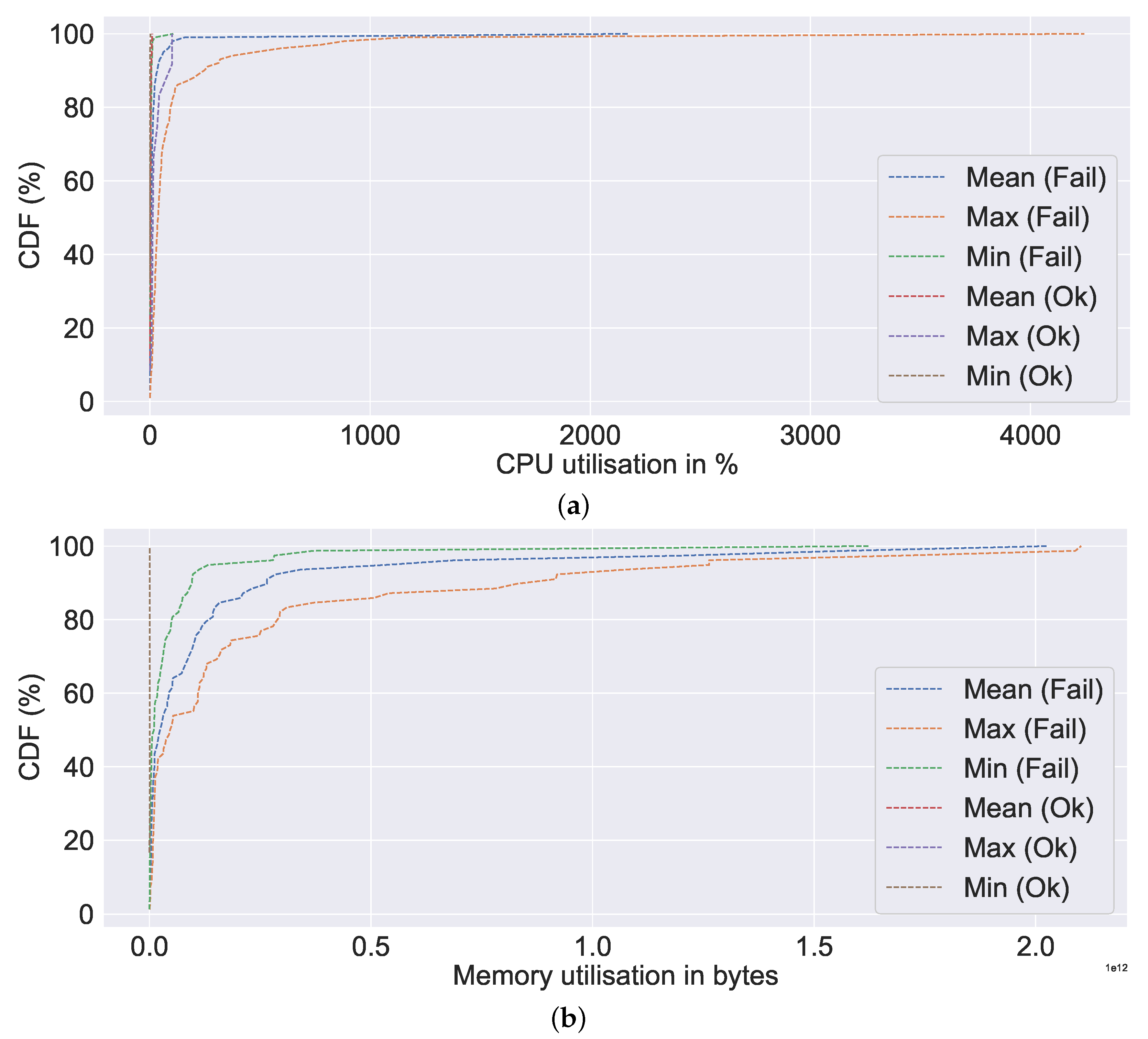
Figure 12a depicts the CPU utilisation CDF. As illustrated in
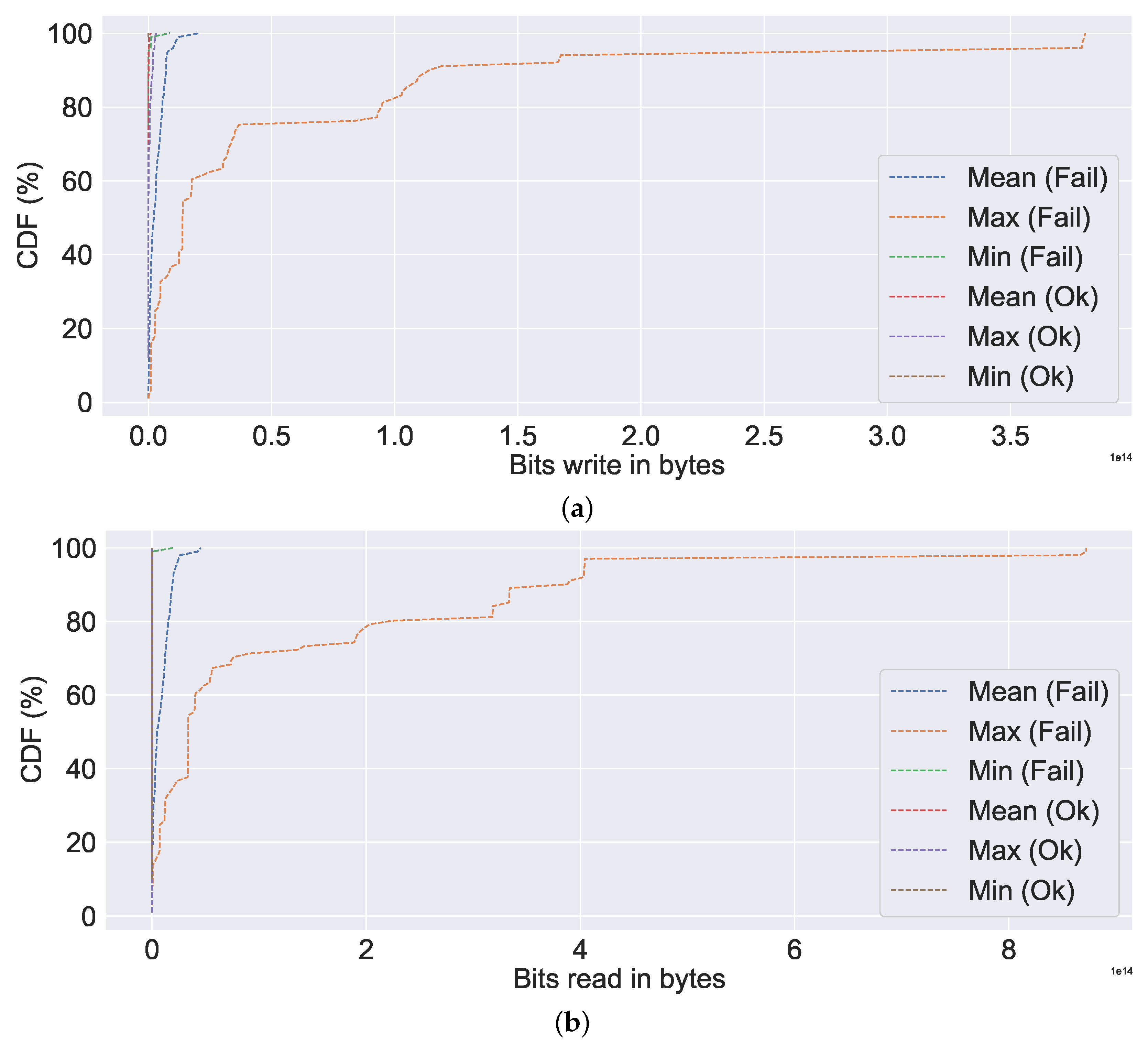
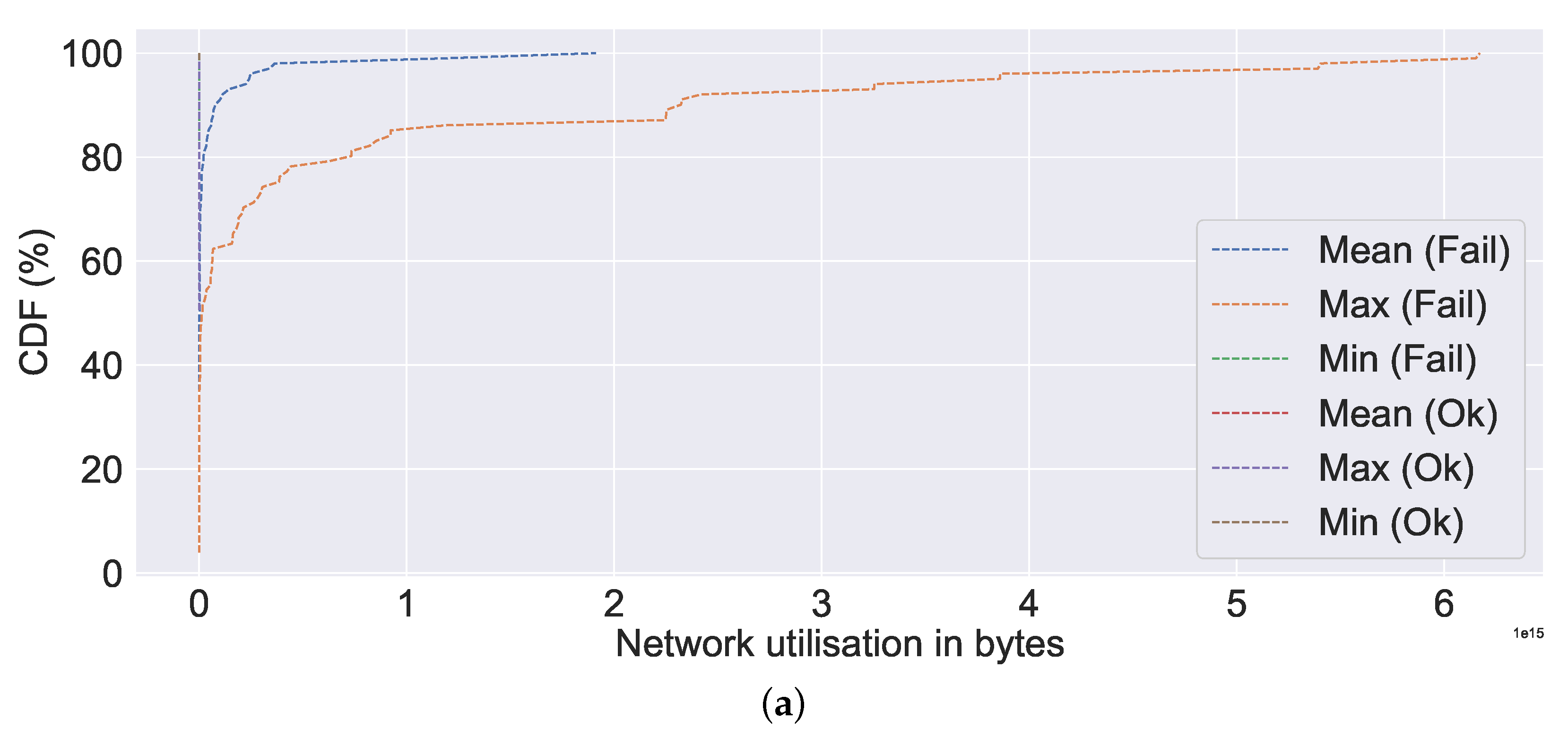
Figure 12a, the mean, min, and max values for the failed server are all extremely high compared to non-failures (represented by ok in the figure). Nearly all (100% CDF) of the failed ones have very high CPU utilisation, as high as 4000%. A similar observation can be made about memory utilisation, bit write, bit read, network utilisation, and IO utilisation, all of which indicate excessive resource utilisation in the event of a failure in
Figure 12b,
Figure 13a,b and
Figure 14a,b, respectively. Additionally, we can observe a very similar pattern for data distribution in the event of failure in the case of bits read and bits write. The abnormally high CPU utilisation value observed in our study for the failure case is consistent with the findings of Xu et al. [
20], wherein in the event of a failure, a value as high as three times the normal value was observed. The observed high resource usage, such as CPU, memory, data written into and out of the disk, network usage, and increased time for IO usage in the event of failure in
Figure 12,
Figure 13 and
Figure 14 is coherent with the failure characteristics identified by Jassas et al. [
36], who observed high resource usage prior to failure. In the absence of failure, we can observe that resource utilisation is limited and relatively low. The similar failure traits can also be observed in the case of the SMART system metrics from
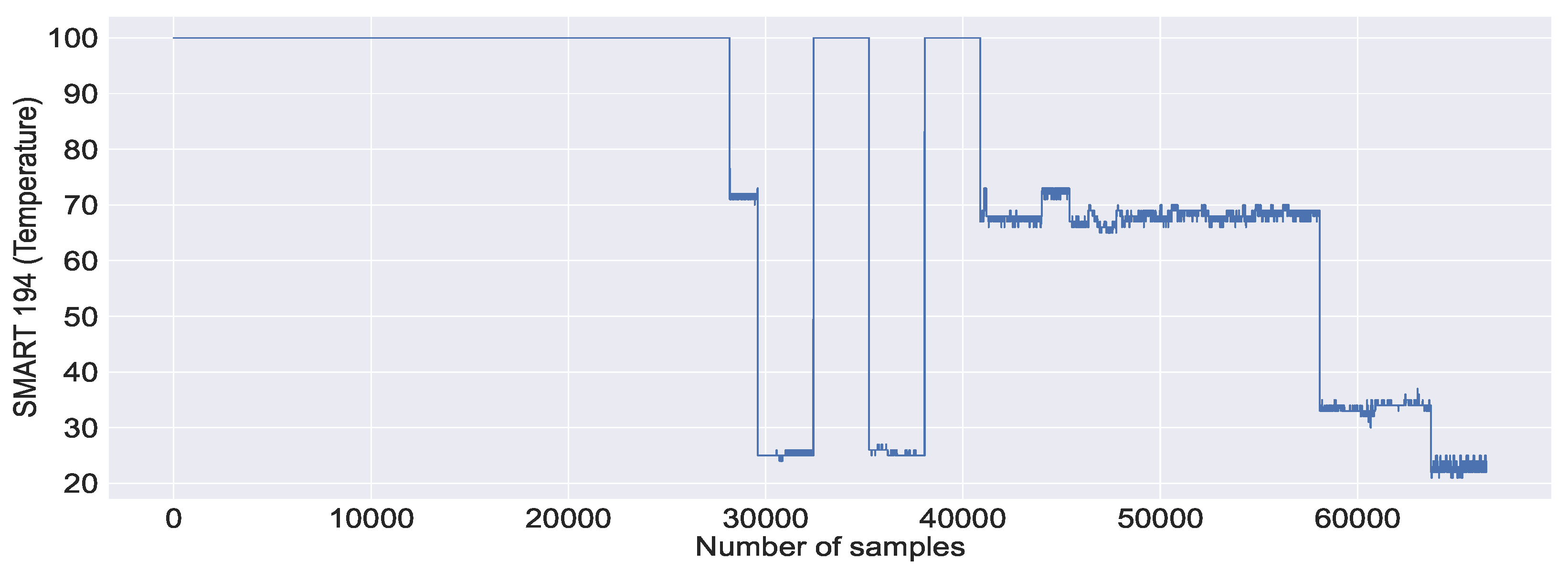
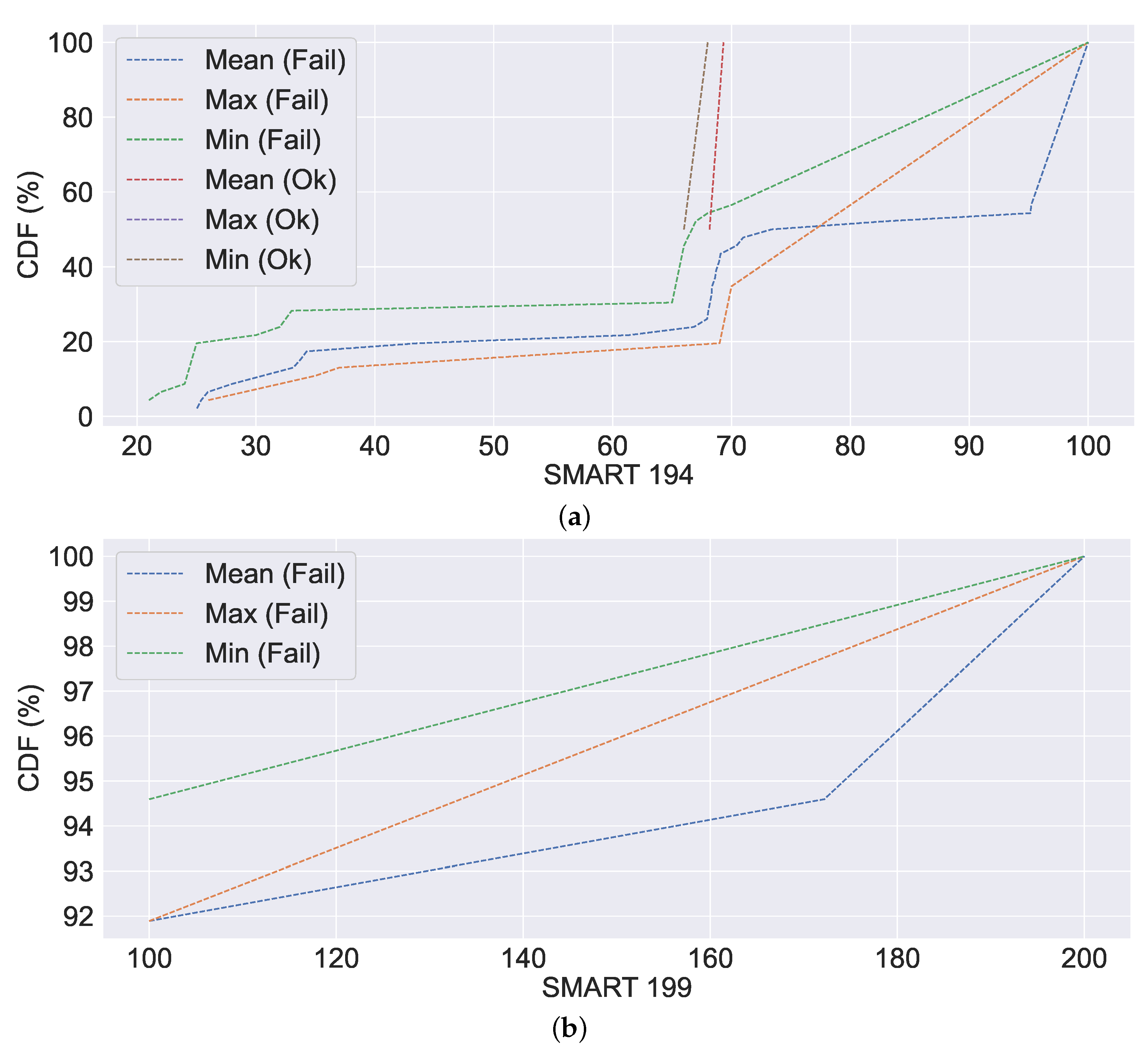
Figure 15. As illustrated in
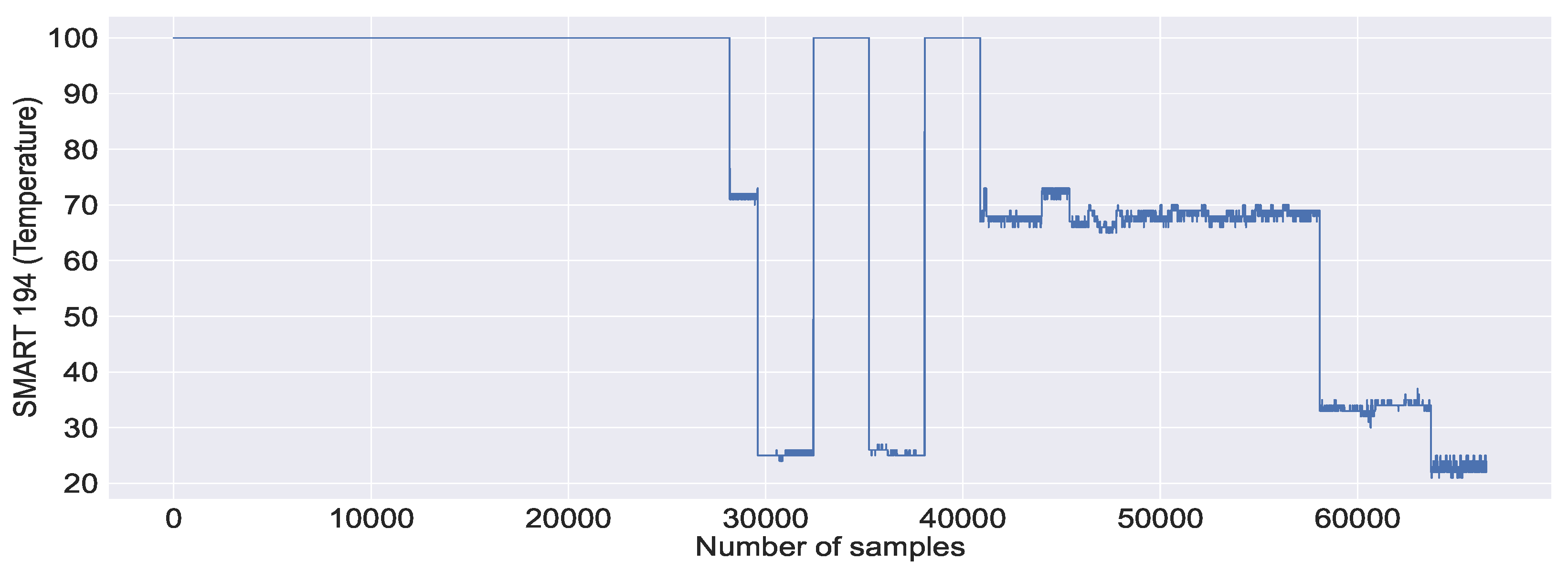
Figure 15a, the mean and min values of SMART 194 are relatively stable in non-failure cases, in contrast to the failure case, which fluctuates rapidly. Similar to SMART 194, in the case of SMART 199, we can observe high mean, min and max values in
Figure 15b. Certain SMART 194 values are identical in failure to those in non-failure in
Figure 15a. This is due to the failure caused by the other system metrics, where SMART metrics are reported normally. Further, we observe no CDF for SMART 199, which is not a failure. This is either because the SMART reported a failure or because other system metrics reported a failure.
We draw the following conclusions from our analysis of the data: The first conclusion is based on the overview of the server’s system metrics. We conclude that the majority of the time, resources are not fully utilised. For example, CPU utilisation is frequently less than 60%. The second is constructed using correlation analysis. Correlations between SMART system metrics and other system metrics are minimal. The third is based on an analysis of the CDF data. Resource consumption is typically high in the event of or prior to failure. Finally, the data analysis demonstrates the benefits of combining SMART metrics with other system metrics, as observed in CDF, where SMART does not report failures but other system metrics do.
4.4.2. Experimental Result
Table 8 presents our experimental results and also a comparison to the state-of-the-art. Overall, we observe high accuracy, precision, recall, and F1-score with all four of the algorithms tested, using our combined system metrics approach, with results averaging at least 95% for each algorithm. The consistent high values of all evaluation metrics with all four selected algorithms, despite the unevenly distributed data (see
Section 3.2), demonstrates the benefits of the combined system metrics approach, validating our claim.
However, when we examine the results at a finer level, we can see that RF outperforms GB, LSTM, and GRU. The GB comes in second on the list, with accuracy being as close to RF as possible. The GB, on the other hand, falls short in precision by nearly 4% when compared to the RF. LSTM and GRU have comparable performance, but GB and RF outperform them by about 4–5% in terms of accuracy and precision and by about 2–3% in terms of the F1-score. In terms of recall, we can see that all four algorithms produced the same result.
In our study, RF outperformed all other algorithms evaluated. The reason for RF’s superior performance is its ability to generalise across diverse datasets with less hyperparameter tuning than techniques such as GB. A similar conclusion was made by Fernández-Delgado et al. [
97] after evaluating 179 classifiers from 17 different families, such as decision trees, boosting, and other ensemble models on the
whole UCI dataset [
98]. Moreover, given the small difference between RF and GB performance, further hyperparameter tuning may result in improved GB performance. However, neural network-based models that can model arbitrary decision boundaries, such as RF, are more powerful when a large amount of data is available [
99]. The lower performance of LSTM and GRU in our study compared to RF and GB could be attributed to data size. In the case of the larger datasets, LSTM and GRU can outperform RF because of their superior ability to learn patterns.
Furthermore, to understand where we stand in comparison to the most recent studies, we compared our findings to [
19,
21,
22,
29,
91], which were chosen based on their recentness (2018 and later), relevancy, and the similarity of the evaluation metrics used. Additionally, when multiple algorithms were used in the comparison studies, we used the result from the best performing algorithm. In terms of accuracy, our combined system metrics approach outperforms others by up to 11% and recall by up to 32%, compared to the state-of-the-art studies. Similar observations can be made in terms of other evaluation metrics, such as precision and F1 score. Further, our combined system approach demonstrates competitive results by nearly 5% in terms of F1 score against state-of-the-art studies and precision by up to 10%. The studies FACS and DESH used LSTM as in our study. Based on the findings of these two studies, our proposed combined system approach continues to outperform the competition. However, when we compare our LSTM and GRU (i.e., a similar technique) results to the maximum DESH result, we see that DESH outperforms our proposed combined system metrics in terms of precision by up to 3%.
Finally, the results from our experiment and comparison to state-of-the-art studies substantiate our claim that using SMART metrics in conjunction with other system metrics, such as CPU and memory utilisation, can improve failure prediction. Furthermore, with improved failure prediction, we can detect potential failures accurately before they occur, allowing us to take proactive action and, as a result, improve reliability.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}