
GeoLOD: A Spatial Linked Data Catalog and Recommender



Abstract
1. Introduction
- A user searches for datasets that cover a specific geographical area (e.g., a country);
- A linked data publisher searches for datasets containing georeferenced information in order to georeference their data;
- A linked data publisher searches for datasets that contain related instances to their own datasets in order to establish links between instances; and
- A geographical information systems (GIS) professional wants to enrich their spatial data with linked data.
- It is the first catalog of linked data spatial datasets and classes provided through SPARQL endpoints, offering services for describing spatial aspects of their content and map-based search;
- It introduces GeoVoID, an automatically generated dataset description vocabulary that extends VoID, to express spatial metadata and statistics of datasets;
- It provides a comprehensive list of recommended pairs of datasets and classes that may contain related instances, along with automatically generated SILK and LIMES configuration files and machine-readable recommendation lists so as to be used as input in (batch) link discovery processes; and
- It allows on-the-fly recommendations for user-defined SPARQL endpoints and spatial datasets in GeoJSON and Shapefile format.
2. Related Work
2.1. Dataset Description
2.2. Dataset Catalogs
2.3. Dataset Recommenders for Link Discovery
3. Design and Methods
3.1. The Catalog
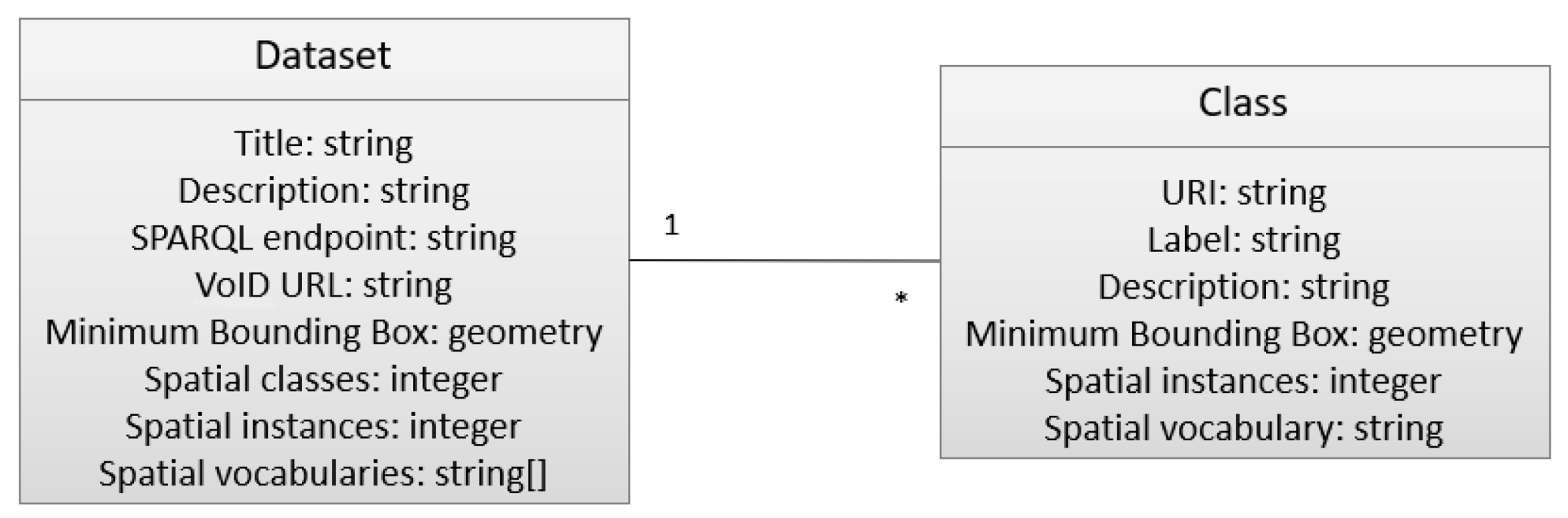
3.1.1. Definitions
3.1.2. Data Collection
3.1.3. Item Metadata and GeoVoID
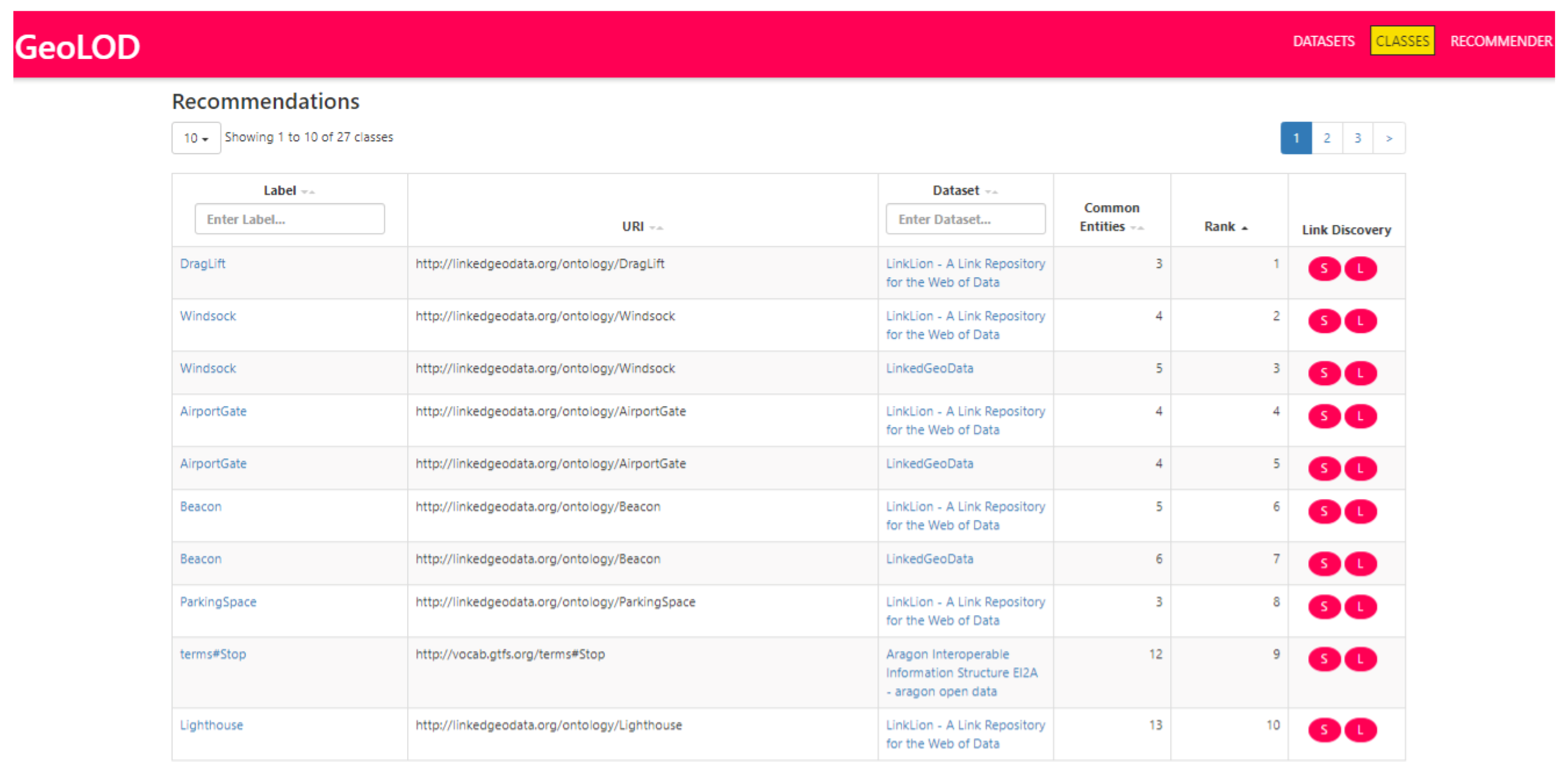
3.2. The Recommender
4. The GeoLOD Application
4.1. Implementation
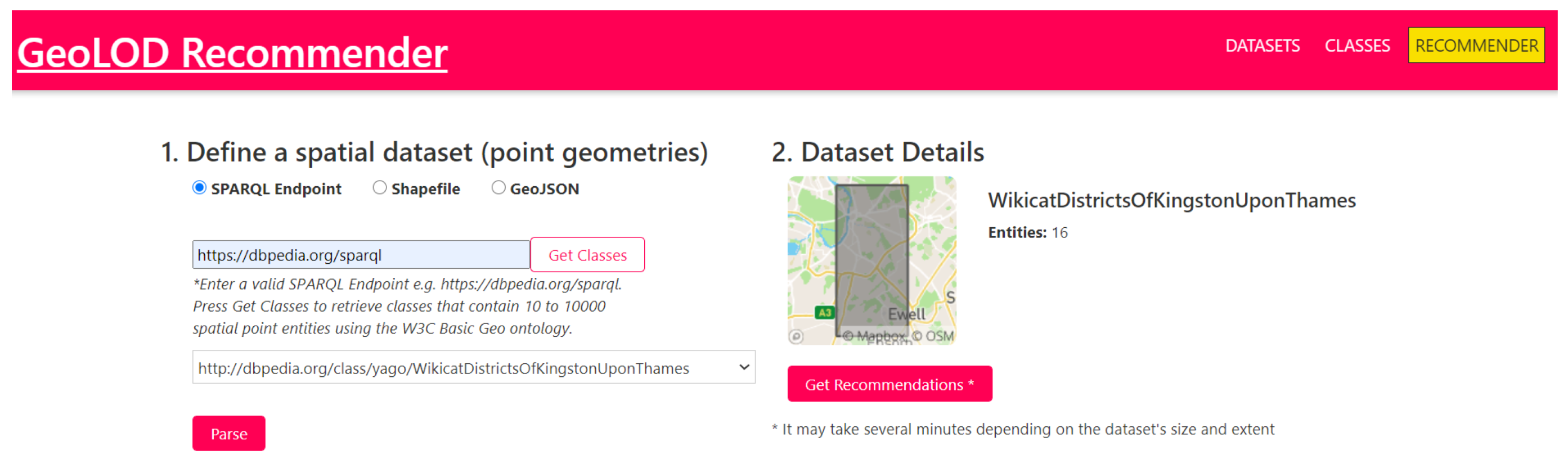
4.2. Use Cases
4.3. REST API
5. Results
5.1. Catalog Statistics
5.2. Recommender Statistics
5.3. Recommender Applicability Assessment
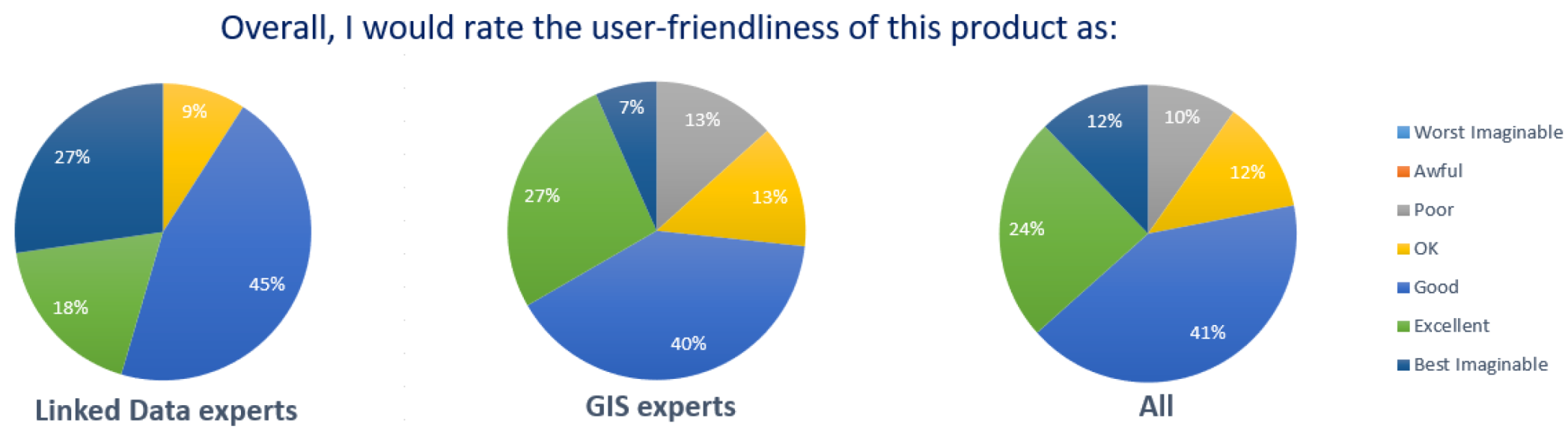
5.4. Usability Study
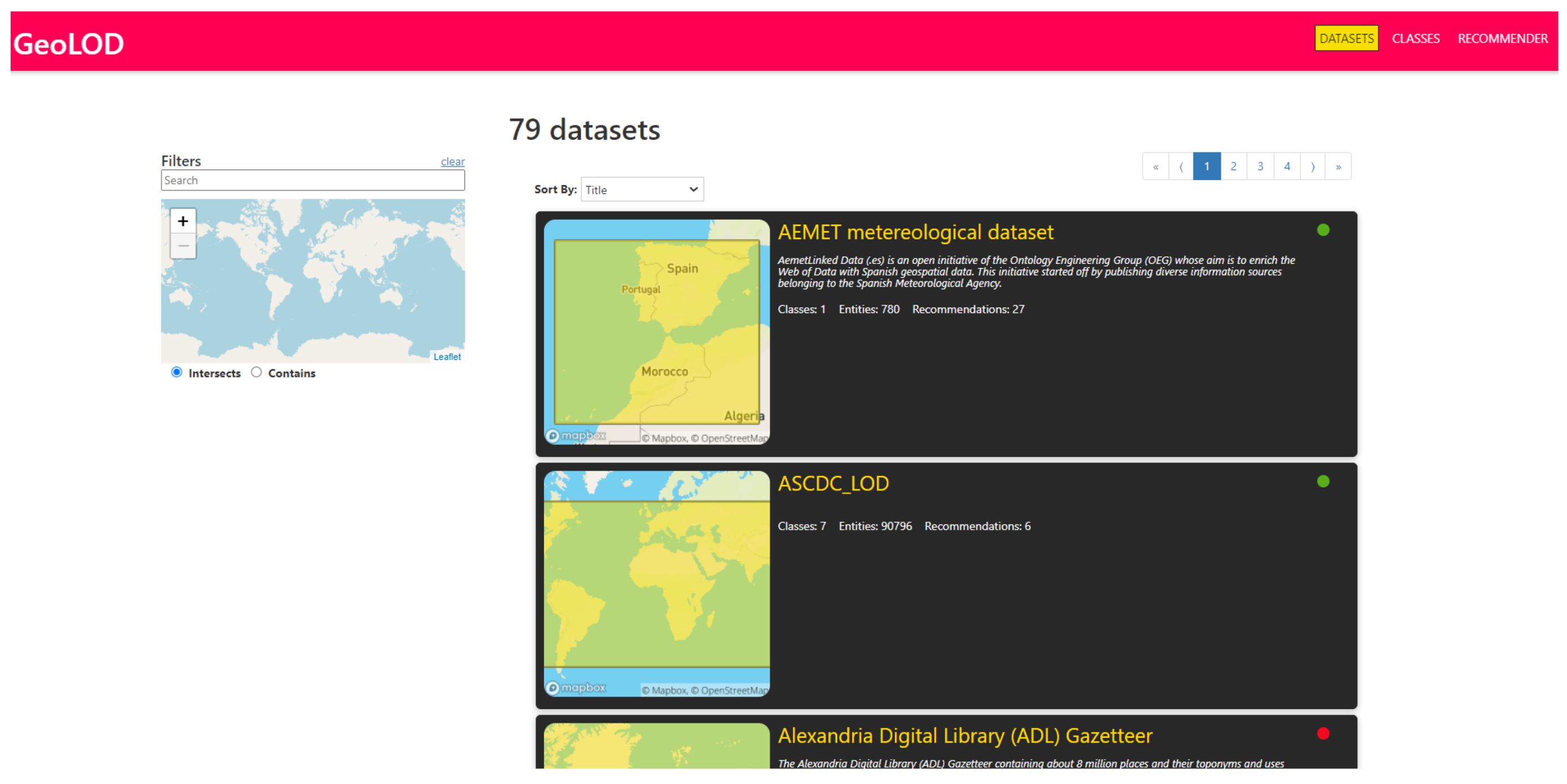
- Search for datasets that contain data in a specific geographic area (e.g., Spain);
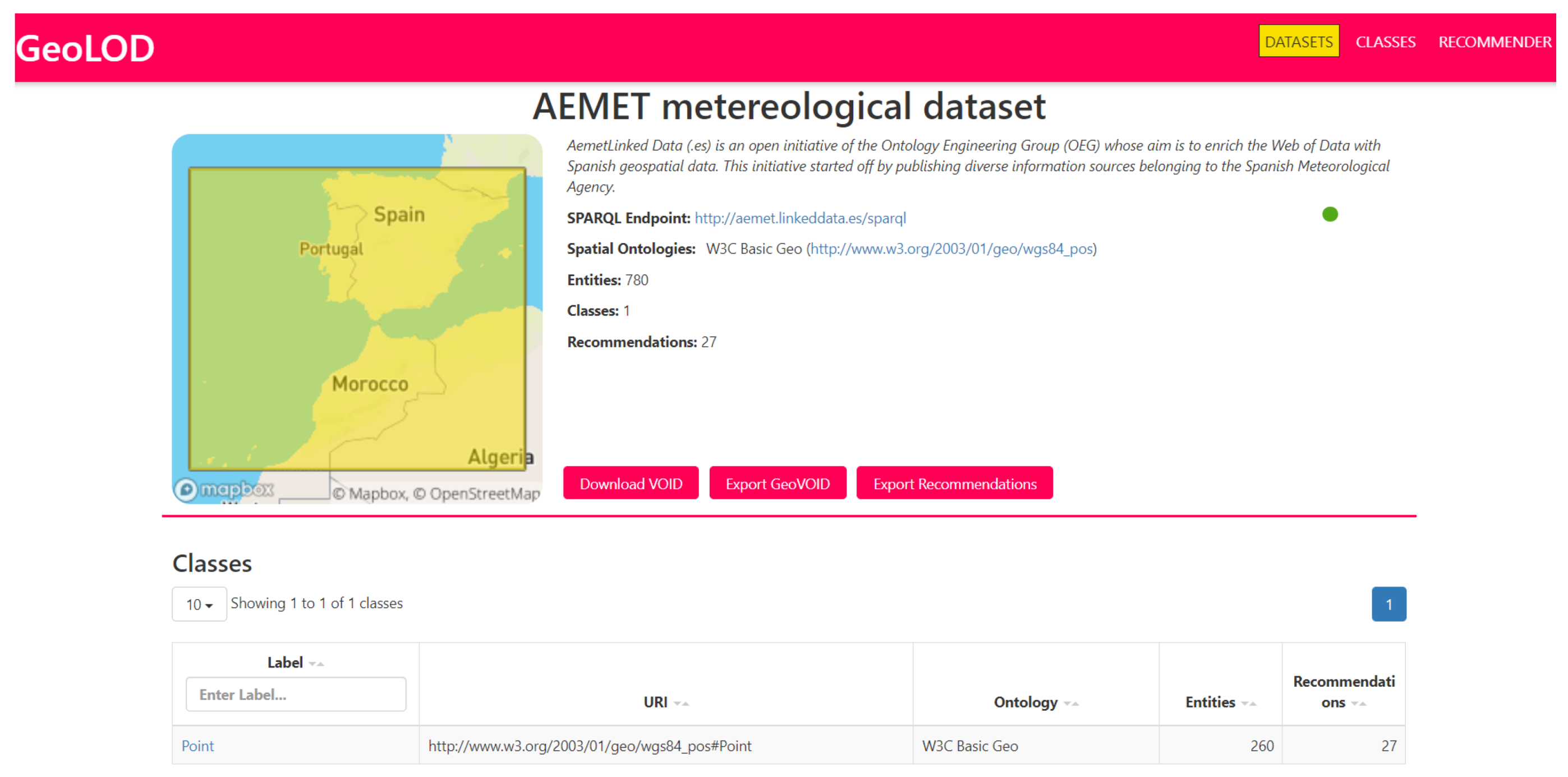
- View the description and the list of classes of a dataset of their choice;
- View the description and the list of recommendations of a class of their choice;
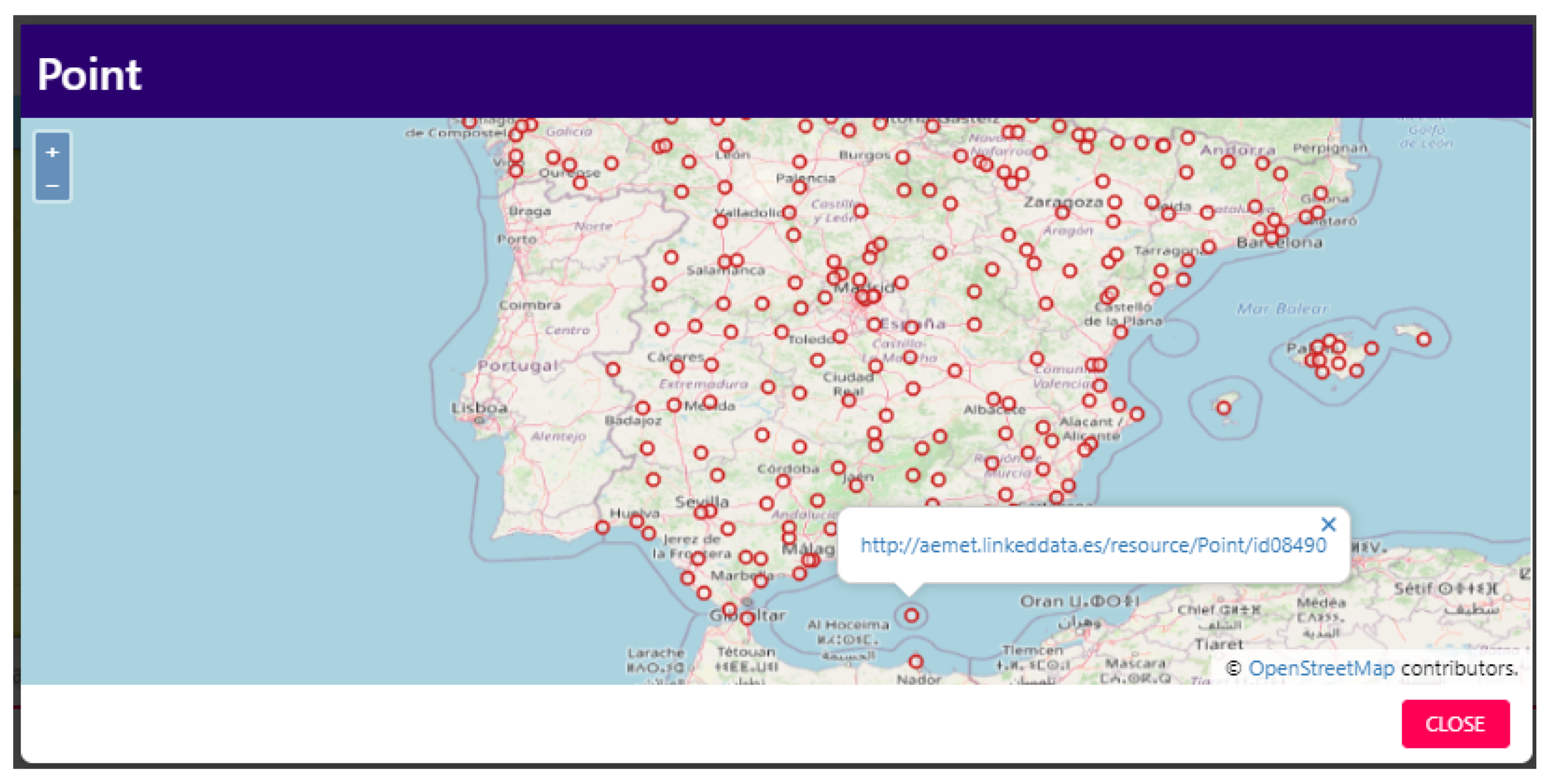
- View the instances of their selected class on the map;
- Get recommendations for a uncatalogued endpoint, for example https://dbpedia.org/sparql (only for linked data experts);
- Get recommendations for a shapefile that they own (only for GIS experts).
6. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Berners-Lee, T. Linked Data—Design Issues. Available online: https://www.w3.org/DesignIssues/LinkedData.html (accessed on 24 December 2020).
- Unger, C.; Freitas, A.; Cimiano, P. An introduction to question answering over linked data. In Reasoning Web International Summer School; Springer: Berlin/Heidelberg, Germany, 2014; pp. 100–140. [Google Scholar]
- Lopez, V.; Unger, C.; Cimiano, P.; Motta, E. Evaluating question answering over linked data. J. Web Semant. 2013, 21, 3–13. [Google Scholar] [CrossRef]
- Höffner, K.; Walter, S.; Marx, E.; Usbeck, R.; Lehmann, J.; Ngonga Ngomo, A.C. Survey on challenges of Question Answering in the Semantic Web. Semant. Web 2017, 8, 895–920. [Google Scholar] [CrossRef]
- Dimitrakis, E.; Sgontzos, K.; Tzitzikas, Y. A survey on question answering systems over linked data and documents. J. Intell. Inf. Syst. 2020, 55, 233–259. [Google Scholar] [CrossRef]
- Saleem, M.; Khan, Y.; Hasnain, A.; Ermilov, I.; Ngonga Ngomo, A.C. A fine-grained evaluation of SPARQL endpoint federation systems. Semant. Web 2014. [Google Scholar] [CrossRef]
- Vidal, M.E.; Castillo, S.; Acosta, M.; Montoya, G.; Palma, G. On the Selection of SPARQL Endpoints to Efficiently Execute Federated SPARQL Queries. In Transactions on Large-Scale Data- and Knowledge-Centered Systems XXV; Hameurlain, A., Kung, J., Wagner, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; pp. 109–149. [Google Scholar]
- Harth, A.; Hose, K.; Karnstedt, M.; Polleres, A.; Sattler, K.U.; Umbrich, J. Data Summaries for On-demand Queries over Linked Data. In Proceedings of the 19th International Conference on World Wide Web, WWW ’10, Raleigh, NC, USA, 26–30 April 2010; ACM: New York, NY, USA, 2010; pp. 411–420. [Google Scholar] [CrossRef]
- Quilitz, B.; Leser, U. Querying Distributed RDF Data Sources with SPARQL. In The Semantic Web: Research and Applications; Bechhofer, S., Hauswirth, M., Hoffmann, J., Koubarakis, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 524–538. [Google Scholar]
- Schwarte, A.; Haase, P.; Hose, K.; Schenkel, R.; Schmidt, M. FedX: Optimization Techniques for Federated Query Processing on Linked Data. In Proceedings of the International Semantic Web Conference, Bonn, Germany, 23–27 October 2011. [Google Scholar]
- Görlitz, O.; Staab, S. SPLENDID: SPARQL Endpoint Federation Exploiting VOID Descriptions. In Proceedings of the Second International Conference on Consuming Linked Data—Volume 782, COLD’11, Heraklion, Greece, 23 October 2011; pp. 13–24. [Google Scholar]
- DBpedia. Available online: https://wiki.dbpedia.org/ (accessed on 20 March 2021).
- MusicBrainz. Available online: https://musicbrainz.org/ (accessed on 20 March 2021).
- GeoNames. Available online: https://www.geonames.org (accessed on 20 March 2021).
- Adida, B.; Birbeck, M.; McCaron, S.; Herman, I. RDFa Core 1.1—Third Edition. 2014. Available online: https://www.w3.org/TR/rdfa-core/ (accessed on 24 December 2020).
- Oren, E.; Delbru, R.; Catasta, M.; Cyganiak, R.; Stenzhorn, H.; Tummarello, G. Sindice.com: A document-oriented lookup index for open linked data. IJMSO 2008, 3, 37–52. [Google Scholar] [CrossRef]
- Harth, A.; Hogan, A.; Umbrich, J.; Kinsella, S.; Polleres, A.; Decker, S. Searching and Browsing Linked Data with SWSE. In Semantic Search over the Web; Virgilio, R.D., Guerra, F., Velegrakis, Y., Eds.; Data-Centric Systems and Applications; Springer: Berlin/Heidelberg, Germany, 2012; pp. 361–414. [Google Scholar]
- The Linked Open Data Cloud. Available online: https://lod-cloud.net/ (accessed on 20 March 2021).
- DataHub. Available online: https://old.datahub.io (accessed on 20 March 2021).
- Volz, J.; Bizer, C.; Gaedke, M.; Kobilarov, G. Silk—A Link Discovery Framework for the Web of Data. In Proceedings of the LDOW, Madrid, Spain, 20 April 2009; Bizer, C., Heath, T., Berners-Lee, T., Idehen, K., Eds.; Volume 538. [Google Scholar]
- Ngonga Ngomo, A.C.; Sherif, M.A.; Georgala, K.; Hassan, M.; Dreßler, K.; Lyko, K.; Obraczka, D.; Soru, T. LIMES–A Framework for Link Discovery on the Semantic Web. Künstl. Intell. 2018. [Google Scholar] [CrossRef]
- Nikolov, A.; d’Aquin, M. Identifying relevant sources for data linking using a semantic web index. In Proceedings of the WWW2011 Workshop: Linked Data on the Web (LDOW 2011) at 20th International World Wide Web Conference (WWW 2011), Hyderabad, India, 29 March 2011. [Google Scholar]
- Caraballo, A.A.M.; Arruda, N.M.; Nunes, B.P.; Lopes, G.R.; Casanova, M.A. TRTML—A Tripleset Recommendation Tool Based on Supervised Learning Algorithms. In Proceedings of the Semantic Web: ESWC 2014 Satellite Events, Anissaras, Crete, Greece, 25–29 May 2014; Presutti, V., Blomqvist, E., Troncy, R., Sack, H., Papadakis, I., Tordai, A., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 413–417. [Google Scholar]
- Molli, P.; Skaf-Molli, H.; Grall, A. SemCat: Source Selection Services for Linked Data; Research Report; Universite de Nantes: Nantes, France, 2020. [Google Scholar]
- Schmachtenberg, M.; Bizer, C.; Paulheim, H. Adoption of the Linked Data Best Practices in Different Topical Domains. In Proceedings of the Semantic Web—ISWC 2014, Riva del Garda, Italy, 19–23 October 2014; Mika, P., Tudorache, T., Bernstein, A., Welty, C., Knoblock, C., Vrandečić, D., Groth, P., Noy, N., Janowicz, K., Goble, C., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 245–260. [Google Scholar]
- Polleres, A.; Kamdar, M.R.; Fernández, J.D.; Tudorache, T.; Musen, M.A. A more decentralized vision for Linked Data. Semant. Web 2020, 11, 101–113. [Google Scholar] [CrossRef]
- LOD Laundromat | SEMANTiCS 2018. Available online: https://2018.semantics.cc/lod-laundromat (accessed on 20 March 2021).
- Röder, M.; Ngonga Ngomo, A.C.; Ermilov, I.; Both, A. Detecting Similar Linked Datasets Using Topic Modelling. In Proceedings of the 13th International Conference on The Semantic Web. Latest Advances and New Domains—Volume 9678, Heraklion, Greece, 29 May–2 June 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 3–19. [Google Scholar]
- Glaser, H.; Jaffri, A.; Millard, I. Managing Co-reference on the Semantic Web. In Proceedings of the WWW2009 Workshop: Linked Data on the Web (LDOW2009), Madrid, Spain, 20 April 2009. [Google Scholar]
- Nentwig, M.; Soru, T.; Ngomo, A.C.N.; Rahm, E. LinkLion: A Link Repository for the Web of Data. In Proceedings of the ESWC (Satellite Events), Anissaras, Greece, 25–29 May 2014; Presutti, V., Blomqvist, E., Troncy, R., Sack, H., Papadakis, I., Tordai, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; Volume 8798, pp. 439–443. [Google Scholar]
- Mountantonakis, M.; Tzitzikas, Y. LODsyndesis: Global Scale Knowledge Services. Heritage 2018, 1, 23. [Google Scholar] [CrossRef]
- Alexander, K.; Cyganiak, R.; Hausenblas, M.; Zhao, J. Describing Linked Datasets—On the Design and Usage of voiD, the ’Vocabulary of Interlinked Datasets’. In Proceedings of the WWW 2009 Workshop: Linked Data on the Web (LDOW2009), Madrid, Spain, 20 April 2009. [Google Scholar]
- Kopsachilis, V.; Vaitis, M.; Mamoulis, N.; Kotzinos, D. Recommending Geo-semantically Related Classes for Link Discovery. J. Data Semant. 2021, 9, 151–177. [Google Scholar] [CrossRef]
- W3C. Data Catalog Vocabulary (DCAT). Available online: https://www.w3.org/TR/2020/SPSD-vocab-dcat-20200204/ (accessed on 20 March 2021).
- Akar, Z.; Halaç, T.G.; Ekinci, E.E.; Dikenelli, O. Querying the Web of Interlinked Datasets using VOID Descriptions. In Proceedings of the CEUR Workshop Proceedings, LDOW, Lyon, France, 16 April 2012; Bizer, C., Heath, T., Berners-Lee, T., Hausenblas, M., Eds.; Volume 937. [Google Scholar]
- Böhm, C.; Lorey, J.; Naumann, F. Creating voiD descriptions for Web-scale data. J. Web Semant. 2011, 9, 339–345. [Google Scholar] [CrossRef]
- voiD Store. Available online: http://void.rkbexplorer.com/ (accessed on 20 March 2021).
- Langegger, A.; Woss, W. RDFStats—An Extensible RDF Statistics Generator and Library. In Proceedings of the 2009 20th International Workshop on Database and Expert Systems Application, Linz, Austria, 31 August–4 September 2009; pp. 79–83. [Google Scholar] [CrossRef]
- Khatchadourian, S.; Consens, M. ExpLOD: Summary-Based Exploration of Interlinking and RDF Usage in the Linked Open Data Cloud. In The Semantic Web: Research and Applications; Springer: Berlin/Heidelberg, Germany, 2010; pp. 272–287. [Google Scholar]
- Demter, J.; Auer, S.; Martin, M.; Lehmann, J. LODStats—An Extensible Framework for High-performance Dataset Analytics. In Proceedings of the EKAW2012, Galway City, Ireland, 8–12 October 2012; Lecture Notes in Computer Science (LNCS); Springer: Berlin/Heidelberg, Germany, 2012; p. 7603, 29% acceptance rate. [Google Scholar]
- Mäkelä, E. Aether—Generating and Viewing Extended VoID Statistical Descriptions of RDF Datasets. In Proceedings of the SemanticWeb: ESWC 2014 Satellite Events, Anissaras, Greece, 25–29 May 2014; Presutti, V., Blomqvist, E., Troncy, R., Sack, H., Papadakis, I., Tordai, A., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 429–433. [Google Scholar]
- Mihindukulasooriya, N.; Poveda-Villalón, M.; García-Castro, R.; Gómez-Pérez, A. Loupe—An Online Tool for Inspecting Datasets in the Linked Data Cloud. In Proceedings of the International Semantic Web Conference (Posters and Demos), Bethlehem, PA, USA, 11–15 October 2015; Villata, S., Pan, J.Z., Dragoni, M., Eds.; Volume 1486. [Google Scholar]
- Palmonari, M.; Rula, A.; Porrini, R.; Maurino, A.; Spahiu, B.; Ferme, V. ABSTAT: Linked Data Summaries with ABstraction and STATistics. In Proceedings of the ESWC (Satellite Events), Portoroz, Slovenia, 31 May–4 June 2015; Gandon, F., Guéret, C., Villata, S., Breslin, J.G., Faron-Zucker, C., Zimmermann, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2015; Volume 9341, pp. 128–132. [Google Scholar]
- Abedjan, Z.; Grütze, T.; Jentzsch, A.; Naumann, F. Profiling and mining RDF data with ProLOD++. In Proceedings of the ICDE, Chicago, IL, USA, 31 March–4 April 2014; Cruz, I.F., Ferrari, E., Tao, Y., Bertino, E., Trajcevski, G., Eds.; pp. 1198–1201. [Google Scholar]
- Benedetti, F.; Bergamaschi, S.; Po, L. Visual Querying LOD sources with LODeX. In Proceedings of the 8th International Conference on Knowledge Capture, K-CAP, Palisades, NY, USA, 7–10 October 2015; Barker, K., Gómez-Pérez, J.M., Eds.; pp. 12:1–12:8. [Google Scholar]
- Neto, C.B.; Kontokostas, D.; Hellmann, S.; Müller, K.; Brümmer, M. LODVader: An Interface to LOD Visualization, Analytics and DiscovERy in Real-time. In Proceedings of the 25th WWW Conference, Montreal, QC, Canada, 11–15 April 2016. [Google Scholar]
- Pietriga, E.; Gözükan, H.; Appert, C.; Destandau, M.; Cebiric, S.; Goasdoué, F.; Manolescu, I. Browsing Linked Data Catalogs with LODAtlas. In Proceedings of the International Semantic Web Conference (2), Monterey, CA, USA, 8–12 October 2018; Vrandecic, D., Bontcheva, K., Suárez-Figueroa, M.C., Presutti, V., Celino, I., Sabou, M., Kaffee, L.A., Simperl, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11137, pp. 137–153. [Google Scholar]
- DCMI Metadata Terms. Available online: https://www.dublincore.org/specifications/dublin-core/dcmi-terms/ (accessed on 20 March 2021).
- Beek, W.; Rietveld, L.; Bazoobandi, H.R.; Wielemaker, J.; Schlobach, S. LOD Laundromat: A Uniform Way of Publishing Other People’s Dirty Data. In Proceedings of the International SemanticWeb Conference (1), Riva del Garda, Trento, Italy, 19–23 October 2014; Mika, P., Tudorache, T., Bernstein, A., Welty, C., Knoblock, C.A., Vrandecic, D., Groth, P., Noy, N.F., Janowicz, K., Goble, C.A., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; Volume 8796, pp. 213–228. [Google Scholar]
- Vandenbussche, P.Y.; Umbrich, J.; Matteis, L.; Hogan, A.; Aranda, C.B. SPARQLES: Monitoring public SPARQL endpoints. Semant. Web 2017, 8, 1049–1065. [Google Scholar] [CrossRef]
- Hasnain, A.; Mehmood, Q.; e Zainab, S.S.; Hogan, A. SPORTAL: Profiling the Content of Public SPARQL Endpoints. Int. J. Semant. Web Inf. Syst. 2016, 12, 134–163. [Google Scholar] [CrossRef]
- Baron Neto, C.; Kontokostas, D.; Kirschenbaum, A.; Publio, G.; Esteves, D.; Hellmann, S. IDOL: Comprehensive & Complete LOD Insights. In Proceedings of the 13th International Conference on Semantic Systems (SEMANTiCS 2017), Amsterdam, The Netherlands, 11–14 September 2017. [Google Scholar]
- re3data.org. Available online: http://re3data.org (accessed on 20 March 2021).
- Hasnain, A.; Decker, S.; Deus, H.F. Cataloguing and Linking Life Sciences LOD Cloud. 2012. Available online: https://aran.library.nuigalway.ie/bitstream/handle/10379/4841/Cataloguing_and_linking_Life_Sciences_LOD_cloud%28Final_Resubmission%29.pdf?sequence=1&isAllowed=y (accessed on 20 March 2021).
- Umaka Data. Available online: https://yummydata.org/ (accessed on 20 March 2021).
- Nentwig, M.; Hartung, M.; Ngonga Ngomo, A.C.; Rahm, E. A survey of current Link Discovery frameworks. Semant. Web 2015, 8, 419–436. [Google Scholar] [CrossRef]
- Leme, L.A.P.P.; Lopes, G.R.; Nunes, B.P.; Casanova, M.A.; Dietze, S. Identifying Candidate Datasets for Data Interlinking. In Proceedings of theWeb Engineering, Aalborg, Denmark, 8–12 July 2013; Daniel, F., Dolog, P., Li, Q., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 354–366. [Google Scholar]
- Ben Ellefi, M.; Bellahsene, Z.; Dietze, S.; Todorov, K. Dataset Recommendation for Data Linking: An Intensional Approach. In Proceedings of the 13th International Conference on The SemanticWeb. Latest Advances and New Domains–Volume 9678, Heraklion, Crete, Greece, 29 May–2 June 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 36–51. [Google Scholar]
- Mehdi, M.; Iqbal, A.; Hogan, A.; Hasnain, A.; Khan, Y.; Decker, S.; Sahay, R. Discovering Domain-specific Public SPARQL Endpoints: A Life-sciences Use-case. In Proceedings of the 18th International Database Engineering & Applications Symposium, Porto, Portugal, July 14; IDEAS ’14; ACM: New York, NY, USA, 2014; pp. 39–45. [Google Scholar] [CrossRef]
- Emaldi, M.; Corcho, Ó.; de Ipiña, D.L. Detection of Related Semantic Datasets Based on Frequent Subgraph Mining. IESD@ISWC 2014, 5, 7. [Google Scholar]
- Liu, H.; Wang, T.; Tang, J.; Ning, H.; Wei, D.; Xie, S.; Liu, P. Identifying Linked Data Datasets for sameAs Interlinking Using Recommendation Techniques. In Proceedings of theWeb-Age Information Management, Nanchang, China, 3–5 June 2016; Cui, B., Zhang, N., Xu, J., Lian, X., Liu, D., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 298–309. [Google Scholar]
- Mountantonakis, M.; Tzitzikas, Y. Scalable Methods for Measuring the Connectivity and Quality of Large Numbers of Linked Datasets. J. Data Inf. Qual. 2018, 9, 15:1–15:49. [Google Scholar] [CrossRef]
- Mera Caraballo, A.A.; Nunes, B.P.; Lopes, G.R.; Paes Leme, L.A.P.; Casanova, M.A.; Dietze, S. TRT—A Tripleset Recommendation Tool. In Proceedings of the 12th International Semantic Web Conference (ISWC2013), Sydney, Australia, 21–25 October 2013. [Google Scholar]
- Wagner, A.; Haase, P.; Rettinger, A.; Lamm, H. Entity-Based Data Source Contextualization for Searching the Web of Data. In Proceedings of the SemanticWeb: ESWC 2014 Satellite Events, Anissaras, Greece, 25–29 May 2014; Presutti, V., Blomqvist, E., Troncy, R., Sack, H., Papadakis, I., Tordai, A., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 25–41. [Google Scholar]
- Group, W.S.W.I. Basic Geo (WGS84 Lat/Long) Vocabulary. Available online: https://www.w3.org/2003/01/geo (accessed on 20 March 2021).
- GeoVocab.org. Available online: http://geovocab.org/ (accessed on 20 March 2021).
- OGC. GeoSPARQL—A Geographic Query Language for RDF Data. Available online: https://www.ogc.org/standards/geosparql (accessed on 20 March 2021).
- GeoNames Ontology. Available online: http://www.geonames.org/ontology (accessed on 20 March 2021).
- W3C Geospatial Vocabulary. Available online: https://www.w3.org/2005/Incubator/geo/XGR-geo (accessed on 20 March 2021).
- Linked Open Vocabularies. Available online: https://lov.linkeddata.es/dataset/lov (accessed on 20 March 2021).
- Linked Open Vocabularies for Internet of Things (IoT). Available online: https://lov4iot.appspot.com/?p=lov4iot-location (accessed on 20 March 2021).
- CKAN API Guide. Available online: https://docs.ckan.org/en/2.9/api/ (accessed on 20 March 2021).
- React A JavaScript Library for Building User Interfaces. Available online: https://reactjs.org/ (accessed on 20 March 2021).
- Node.js. Available online: https://nodejs.org/en/ (accessed on 20 March 2021).
- Fetch-Sparql-Endpoint. Available online: https://www.npmjs.com/package/fetch-sparql-endpoint (accessed on 20 March 2021).
- Mapbox. Static Images. Available online: https://docs.mapbox.com/api/maps/static-images (accessed on 20 March 2021).
- React Leaflet. Available online: https://react-leaflet.js.org/ (accessed on 20 March 2021).
- OpenLayers. Available online: https://openlayers.org/ (accessed on 20 March 2021).
- PostGIS—Spatial and Geographic Objects for PostgreSQL. Available online: https://postgis.net/ (accessed on 20 March 2021).
- Ngomo, A.C.N.; Auer, S.; Lehmann, J.; Zaveri, A. Introduction to Linked Data and Its Lifecycle on theWeb. In Reasoning on the Web in the Big Data Era. Reasoning Web 2014; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2011; Volume 6848, pp. 250–325. [Google Scholar]
- Brooke, J. SUS-A Quick and Dirty Usability Scale. Usability Evaluation in Industry; CRC Press: Boca Raton, FL, USA, 1996; ISBN 9780748404605. [Google Scholar]
- Bangor, A.; Kortum, P.; Miller, J. Determining What Individual SUS Scores Mean: Adding an Adjective Rating Scale. J. Usability Stud. 2009, 4, 114–123. [Google Scholar]
- Buil-Aranda, C.; Hogan, A.; Umbrich, J.; Vandenbussche, P.Y. SPARQL Web-Querying Infrastructure: Ready for Action? In Proceedings of the SemanticWeb—ISWC 2013, Sydney, NSW, Australia, 21–25 October 2013; Alani, H., Kagal, L., Fokoue, A., Groth, P., Biemann, C., Parreira, J.X., Aroyo, L., Noy, N., Welty, C., Janowicz, K., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 277–293. [Google Scholar]
- Janowicz, K.; Hu, Y.; McKenzie, G.; Gao, S.; Regalia, B.; Mai, G.; Zhu, R.; Adams, B.; Taylor, K.L. Moon Landing or Safari? A Study of Systematic Errors and Their Causes in Geographic Linked Data. In Proceedings of the Annual International Conference on Geographic Information Science, GIScience, Montreal, QC, Canada, 27–30 September 2016; Miller, J.A., O’Sullivan, D., Wiegand, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9927, pp. 275–290. [Google Scholar]
- OGC. Web Feature Service. Available online: https://www.ogc.org/standards/wfs (accessed on 20 March 2021).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Spatial Vocabulary | SELECT Query |
|---|---|
| GeoVocab | SELECT DISTINCT ?class { ?geom <http://www.w3.org/2003/01/geo/wgs84_pos#long> ?x. ?geom <http://www.w3.org/2003/01/geo/wgs84_pos#lat> ?y. ?s <http://geovocab.org/geometry#geometry> ?geom. ?s <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> ?class} |
| GeoSPARQL | SELECT DISTINCT ?class { ?s <http://www.opengis.net/ont/geosparql#hasGeometry> ?geom. ?geom <http://www.opengis.net/ont/geosparql#asWKT> ?wkt. ?s <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> ?class} |
| GeoNames | SELECT DISTINCT ?class { ?s <http://www.w3.org/2003/01/geo/wgs84_pos#long> ?x. ?s <http://www.w3.org/2003/01/geo/wgs84_pos#lat>?y. ?s <http://www.geonames.org/ontology#featureClass> ?class.} |
| W3C Basic Geo | SELECT DISTINCT ?class { ?s <http://www.w3.org/2003/01/geo/wgs84_pos#long> ?x. ?s <http://www.w3.org/2003/01/geo/wgs84_pos#lat> ?y. ?s <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> ?class.} |
| GeoRSS | SELECT DISTINCT ?class { ?s <http://www.georss.org/georss/point> ?point. ?s <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> ?class} |
| Service Name | Request URI | Description |
|---|---|---|
| GeoLOD Description | /api/download/dcat | Returns a DCAT-compliant turtle file that contains general information about GeoLOD and the list of the datasets in the Catalog |
| Dataset List | /api/datasets | Returns, in JSON, the list of datasets with their metadata (including internal dataset IDs) in the GeoLOD Catalog |
| Dataset Description | /api/datasets/<ID> | Returns, in JSON, the specified dataset metadata with the list of its classes. The dataset ID is a variable corresponding to the internal dataset ID. (e.g., http://snf-661343.vm.okeanos.grnet.gr/api/datasets/915 accessed on 16 April 2021, returns the metadata for the AEMET dataset) |
| Class List | /api/classes | Returns, in JSON, the list of classes with their metadata (including internal classes IDs) in the GeoLOD Catalog. |
| Class Description | /api/classes/<ID> | Returns, in JSON, the specified class metadata with the list of its recommended classes. The class ID is a variable corresponding to the internal class ID. (e.g., http://snf-661343.vm.okeanos.grnet.gr/api/classes/139090 accessed on 16 April 2021, returns the metadata for the CaveEntrance class of Linklion dataset). |
| Dataset GeoVoID | /api/download/geovoid/<ID> | Returns, in turtle format, the GeoVoID description of the specified dataset. |
| Dataset Recommendations | /api/download/ datasetrecommendations/<ID> | Returns, in JSON, the list of recommendations for all specified dataset classes. |
| Class Recommenations | api/download/ classesrecommendations/<ID> | Returns, in JSON, the list of recommendations for the specified class. |
| SN | DATASET | CLASSES | INSTANCES | ||
|---|---|---|---|---|---|
| TOTAL | SPATIAL | TOTAL | SPATIAL | ||
| 1 | AEMET metereological dataset | 35 | 1 | N/A | 260 |
| 2 | AragoDBPedia - aragon open data | 164 | 1 | N/A | 357,678 |
| 3 | Datos.bcn.cl | 500 | 6 | 5,303,750 | 830 |
| 4 | DBpedia in Basque | 223 | 20 | 1,168,342 | 51,547 |
| 5 | DBpedia in Dutch | 666 | 142 | 6,718,584 | 252,310 |
| 6 | DBpedia in French | 442 | 188 | 6,015,375 | 225,030 |
| 7 | DBpedia in German | 557 | 123 | 6,682,441 | N/A |
| 8 | DBpedia in Greek | 14,439 | 245 | 2,852,513 | 12,609 |
| 9 | DBpedia in Japanese | 727 | 100 | 4,254,851 | 36,827 |
| 10 | DBpedia in Spanish | 748 | 126 | 5,249,003 | 36,800 |
| 11 | Dutch Ships and Sailors | 92 | 11 | N/A | 42,810 |
| 12 | El Viajero’s tourism dataset | 67 | 1 | 1,019,390 | 643 |
| 13 | Environment Agency Bathing Water Quality | 93 | 7 | 801,310 | 1216 |
| 14 | European Nature Information System | 629 | 13 | N/A | 1,129,574 |
| 15 | European Pollutant Release and Transfer Register | 375 | 10 | 78,719,353 | 3,325,006 |
| 16 | EuroVoc | 413 | 1 | 91,726,256 | 672 |
| 17 | Geological Survey of Austria (GBA)—Thesaurus | 23 | 1 | 3004 | 130 |
| 18 | Indicators Academic Process 2017 | 79 | 7 | 516,097 | 159 |
| 19 | Isidore | 62 | 4 | 20,662,124 | 4101 |
| 20 | ISPRA—The administrative divisions of Italy | 99 | 4 | 449,218 | 23,211 |
| 21 | Linked Logainm | 114 | 38 | 214,423 | 108,065 |
| 22 | LinkedGeoData | 1908 | 952 | N/A | 48,249,489 |
| 23 | LinkLion | 1137 | 902 | 138,806,633 | 20,006,546 |
| 24 | Lotico | 23 | 7 | N/A | N/A |
| 25 | MONDIS | 662 | 3 | 12,855 | 10 |
| 26 | MORElab | 223 | 20 | 1,168,342 | 51,547 |
| 27 | Open Data Communities—Lower layer Super Output Areas | 334 | 14 | 7,912,454 | 2,694,723 |
| 28 | OpenMobileNetwork | 156 | 1 | 934,551 | 357,298 |
| 29 | OxPoints (University of Oxford) | 106 | 5 | 114,813 | 1457 |
| 30 | Serendipity | 607 | 109 | N/A | 61,845 |
| 31 | Shoah victims? names | 200 | 35 | 1,956,021 | 13,974 |
| 32 | Social Semantic Web Thesaurus | 521 | 16 | 14,214 | 54 |
| 33 | Spanish Linguistic Datasets | 57 | 1 | 2,977,659 | 764 |
| 34 | Suface Forestire Mondiale 1990–2016 | 4188 | 2 | 187,608 | 100 |
| 35 | TAXREF-LD: Linked Data French Taxonomic Register | 1921 | 10 | 8,255,730 | 996 |
| 36 | Test Site, LOD Lab 317 | 98 | 4 | 5,669,728 | 115,225 |
| 37 | URIBurner | 33,656 | 262 | 22,175,094 | 456,360 |
| 38 | Verrijkt Koninkrijk | 52 | 12 | 329,621 | 42,831 |
| 39 | WarSampo | 90 | 10 | 1,797,432 | 33,685 |
| 40 | World War 1 as Linked Open Data | 85 | 4 | 14,644 | 883 |
| SUM | 66,571 | 3418 | 424,674,433 | 77,697,265 | |
| Spatial Extent (Km) | Datasets | Classes |
|---|---|---|
| City-level (<1 K) | 1 | 54 |
| Region level (1 K–100 K) | 3 | 218 |
| Country level (100 K–1000 K) | 5 | 183 |
| Continent level (1000 K–50,000 K) | 17 | 1316 |
| World level (>50,000 K) | 14 | 1647 |
| SN | DATASET | DC | DCR | OCR | ODR |
|---|---|---|---|---|---|
| 1 | AEMET metereological dataset | 1 | 1 | 26 | 5 |
| 2 | AragoDBPedia—aragon open data | 1 | 1 | 31 | 7 |
| 3 | Datos.bcn.cl | 6 | 6 | 777 | 7 |
| 4 | DBpedia in Basque | 20 | 20 | 1380 | 19 |
| 5 | DBpedia in Dutch | 142 | 102 | 1620 | 19 |
| 6 | DBpedia in French | 188 | 144 | 4569 | 26 |
| 7 | DBpedia in German | 123 | 98 | 1881 | 22 |
| 8 | DBpedia in Greek | 245 | 174 | 1864 | 25 |
| 9 | DBpedia in Japanese | 100 | 92 | 2407 | 15 |
| 10 | DBpedia in Spanish | 126 | 116 | 1857 | 11 |
| 11 | Dutch Ships and Sailors | 11 | 11 | 349 | 15 |
| 12 | El Viajero’s tourism dataset | 1 | 1 | 135 | 11 |
| 13 | Environment Agency Bathing Water Quality | 7 | 7 | 125 | 4 |
| 14 | European Nature Information System | 13 | 13 | 628 | 23 |
| 15 | European Pollutant Release and Transfer Register | 10 | 10 | 891 | 26 |
| 16 | EuroVoc | 1 | 1 | 89 | 10 |
| 17 | Geological Survey of Austria (GBA)—Thesaurus | 1 | 1 | 38 | 4 |
| 18 | Indicators Academic Process 2017 | 7 | 1 | 2 | 2 |
| 19 | Isidore | 4 | 4 | 146 | 13 |
| 20 | ISPRA—The administrative divisions of Italy | 4 | 4 | 200 | 10 |
| 21 | Linked Logainm | 38 | 31 | 573 | 13 |
| 22 | LinkedGeoData | 952 | 900 | 28,603 | 34 |
| 23 | LinkLion | 902 | 885 | 28,610 | 37 |
| 24 | Lotico | 7 | 7 | 455 | 25 |
| 25 | MONDIS | 3 | 3 | 18 | 2 |
| 26 | MORElab | 20 | 20 | 1380 | 19 |
| 27 | Open Data Communities—Lower layer Super Output Areas | 14 | 14 | 362 | 7 |
| 28 | OpenMobileNetwork | 1 | 1 | 117 | 8 |
| 29 | OxPoints (University of Oxford) | 5 | 5 | 48 | 5 |
| 30 | Serendipity | 109 | 107 | 2889 | 19 |
| 31 | Shoah victims? names | 35 | 20 | 643 | 13 |
| 32 | Social Semantic Web Thesaurus | 16 | 10 | 59 | 5 |
| 33 | Spanish Linguistic Datasets | 1 | 1 | 10 | 3 |
| 34 | Suface Forestire Mondiale 1990–2016 | 2 | 0 | 0 | 0 |
| 35 | TAXREF-LD: Linked Data French Taxonomic Register | 10 | 4 | 30 | 3 |
| 36 | Test Site, LOD Lab 317 | 4 | 4 | 58 | 4 |
| 37 | URIBurner | 262 | 186 | 3052 | 22 |
| 38 | Verrijkt Koninkrijk | 12 | 11 | 373 | 15 |
| 39 | WarSampo | 10 | 10 | 621 | 10 |
| 40 | World War 1 as Linked Open Data | 4 | 3 | 82 | 9 |
| SUM | 3418 | 3029 | 86,998 | 530 | |
| AVERAGE | 85.45 | 75.73 | 2175.00 | 13.25 |
| (2) LIMES Executions | (3) Hits | (4) Hits (%) | (5) Average Instance Links Per Hit | |
|---|---|---|---|---|
| (Default) GeoLOD recommendations | 5000 | 2799 | 55.98% | 4003 |
| Top-1 GeoLOD recommendations | 2799 | 1947 | 69.56% | 9339 |
| Strict GeoLOD recommendations | 3858 | 2650 | 68.68% | 13,119 |
| Random Pairs of Classes (Baseline) | 5000 | 344 | 6.88% | 303 |
| Focus Group | Participants | Min SUS | Max SUS | Mean SUS | Mean Adj. Rating (1–7) |
|---|---|---|---|---|---|
| Linked Data experts | 11 | 55 | 100 | 81.36 | 5.64 |
| GIS experts | 30 | 40 | 97.5 | 63.75 | 5.00 |
| All | 41 | 40 | 100 | 68.48 | 5.17 |
| Question | Linked Data Experts | GIS Experts | All |
|---|---|---|---|
| 1. I think that I would like to use this system frequently. | 3.82 | 3.03 | 3.24 |
| 2. I found the system unnecessarily complex. | 1.64 | 2.07 | 1.95 |
| 3. I thought the system was easy to use. | 4.27 | 3.33 | 3.59 |
| 4. I think that I would need the support of a technical person to be able to use this system. | 2.09 | 2.30 | 2.24 |
| 5. I found the various functions in the system were well integrated. | 4.18 | 3.77 | 3.88 |
| 6. I thought there was too much inconsistency in this system. | 1.45 | 2.10 | 1.93 |
| 7. I imagine that most people would learn to use this system very quickly. | 4.55 | 3.33 | 3.66 |
| 8. I found the system very awkward to use. | 1.82 | 1.83 | 1.83 |
| 9. I felt very confident using the system. | 4.18 | 3.30 | 3.54 |
| 10. I needed to learn a lot of things before I could get going with this system. | 1.45 | 2.97 | 2.56 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kopsachilis, V.; Vaitis, M. GeoLOD: A Spatial Linked Data Catalog and Recommender. Big Data Cogn. Comput. 2021, 5, 17. https://doi.org/10.3390/bdcc5020017
Kopsachilis V, Vaitis M. GeoLOD: A Spatial Linked Data Catalog and Recommender. Big Data and Cognitive Computing. 2021; 5(2):17. https://doi.org/10.3390/bdcc5020017
Chicago/Turabian StyleKopsachilis, Vasilis, and Michail Vaitis. 2021. "GeoLOD: A Spatial Linked Data Catalog and Recommender" Big Data and Cognitive Computing 5, no. 2: 17. https://doi.org/10.3390/bdcc5020017
APA StyleKopsachilis, V., & Vaitis, M. (2021). GeoLOD: A Spatial Linked Data Catalog and Recommender. Big Data and Cognitive Computing, 5(2), 17. https://doi.org/10.3390/bdcc5020017